Physical Object Understanding with a Physically Controllable World Model
Pith reviewed 2026-06-28 19:29 UTC · model grok-4.3
The pith
Autoregressive world models extract objects and enable 3D manipulation by correlating motions across their own generated futures.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
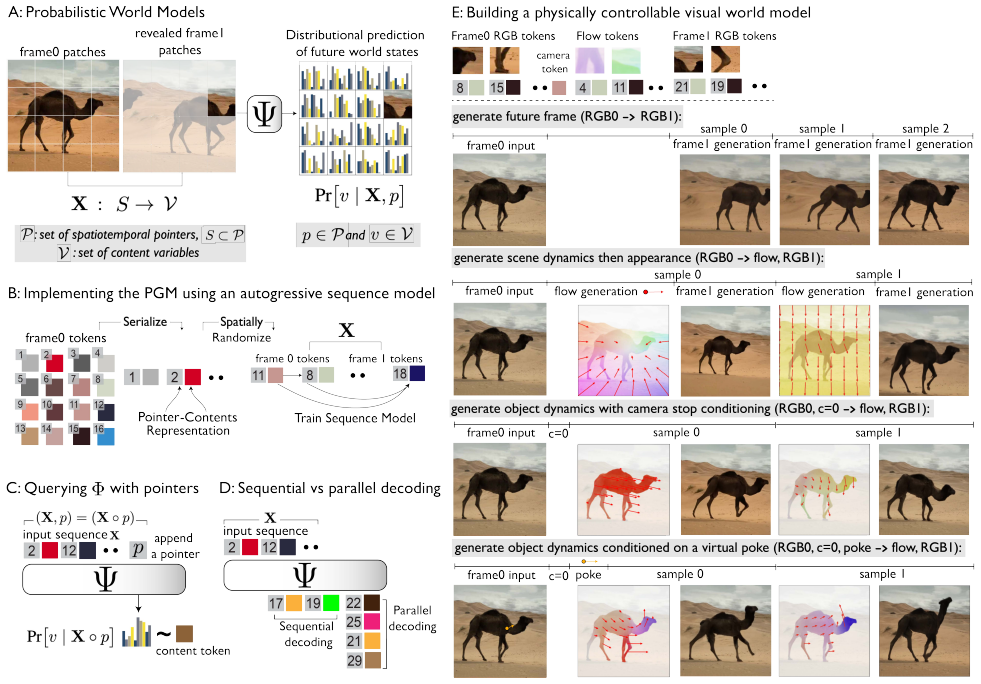
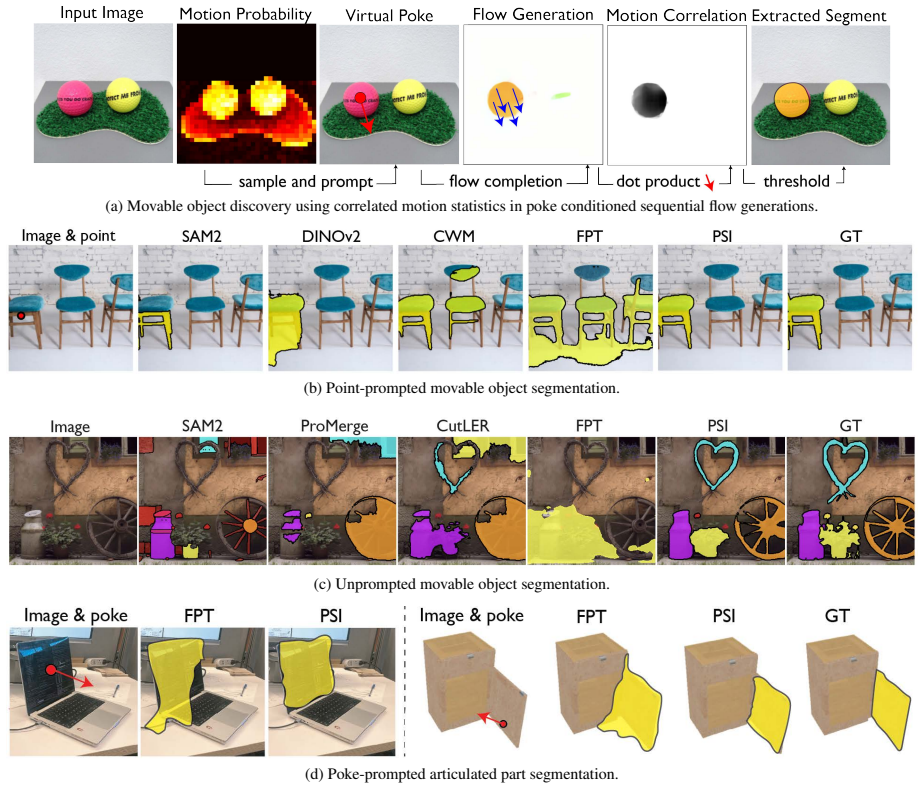
Autoregressive probabilistic world models trained on video sequences support estimation of any visual variable conditioned on any other; generating multiple futures from the model and computing motion correlations across them yields object boundaries and articulated subparts; the identical model then permits 3D manipulation of those objects and calculation of physical relationships such as those required for Visual Jenga.
What carries the argument
The autoregressive world model that performs sequential inference to generate multiple plausible futures, combined with motion-correlation analysis performed on those futures to segment objects.
If this is right
- The model captures the physical laws that govern how objects move.
- Objects and articulated subparts emerge from motion correlations across multiple futures.
- Discovered objects can be manipulated directly in 3D using the world model.
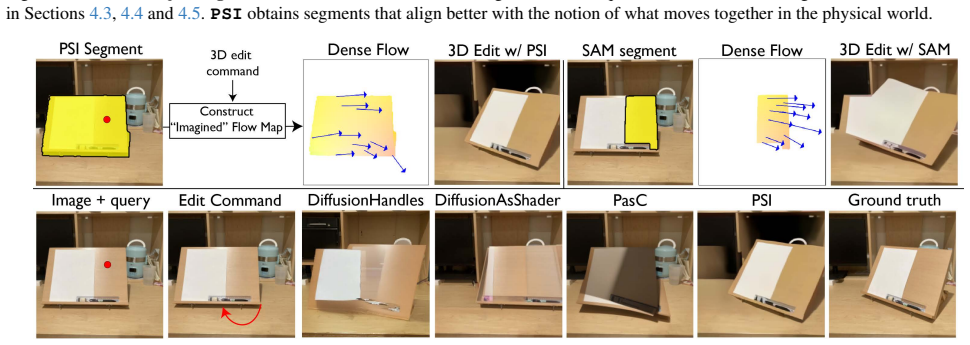
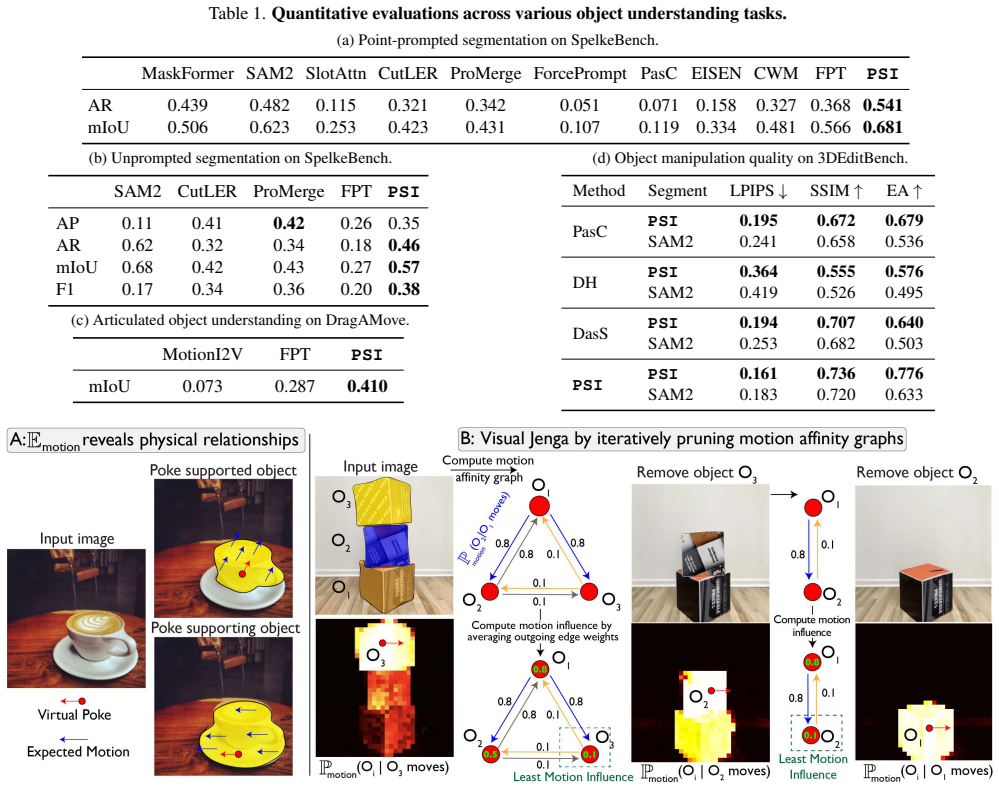
- Physical relationships between objects become computable, supporting tasks such as Visual Jenga.
Where Pith is reading between the lines
- The same correlation technique might be applied to other prediction tasks, such as audio or language sequences, to discover latent structure.
- Integrating the model with real robotic control loops could test whether the extracted objects support closed-loop physical planning.
- Comparing correlation-derived objects against those obtained from optical flow or point tracking on the same videos would clarify what the model adds beyond existing motion cues.
Load-bearing premise
Motion correlations computed inside the model's own generated futures correspond to genuine physical object boundaries rather than artifacts of the training distribution.
What would settle it
Running the extraction procedure on a dataset of videos with known ground-truth object segmentations and finding that the motion-correlation segments fail to align with the ground truth would falsify the central claim.
Figures










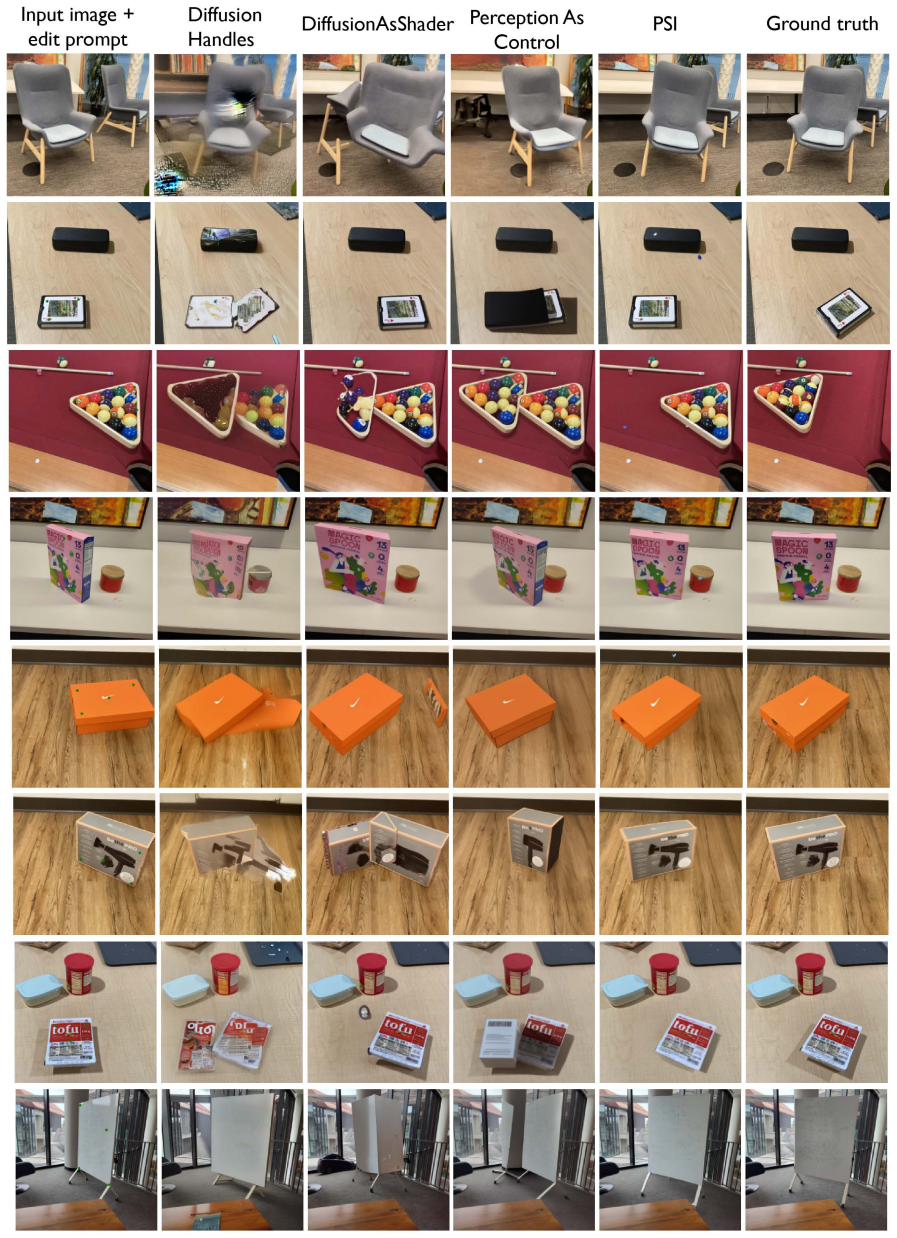


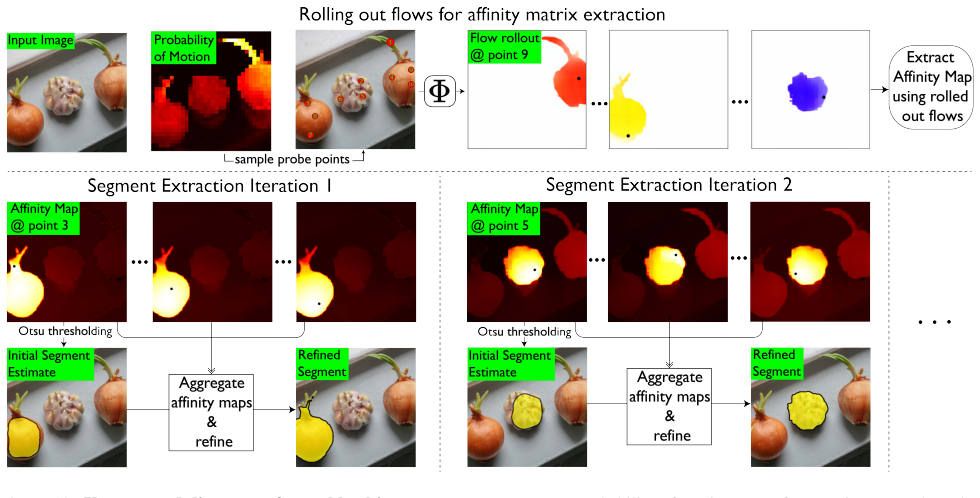
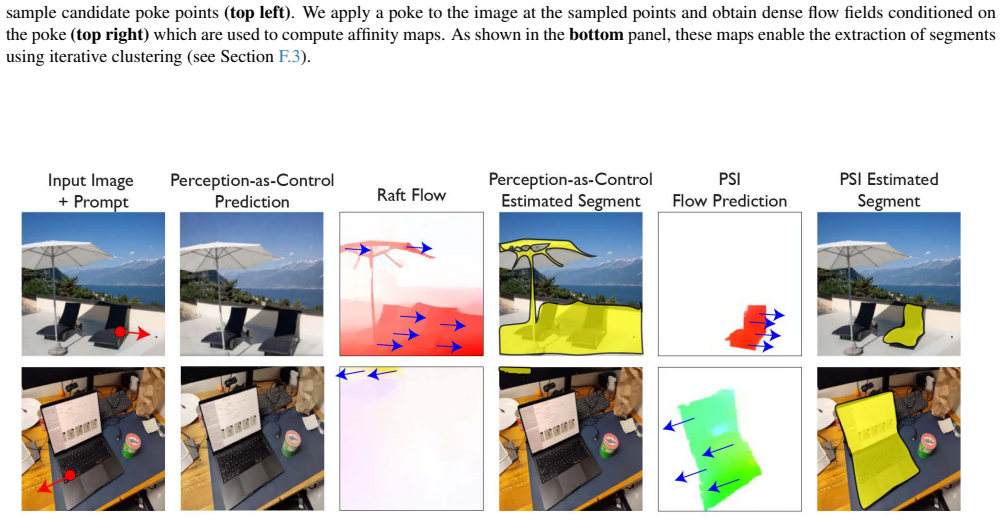
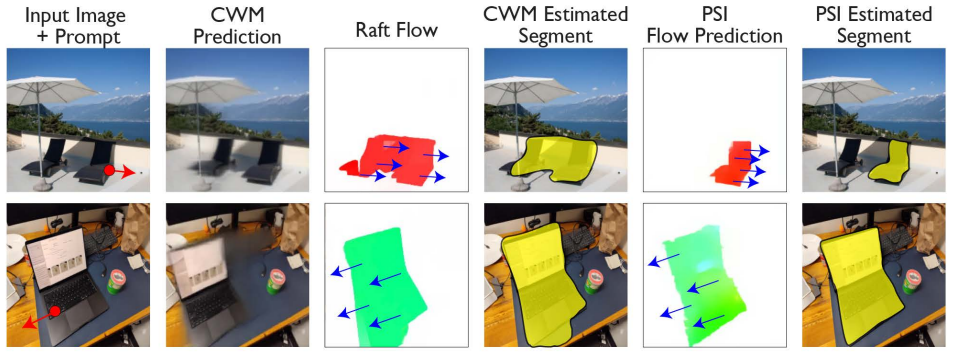
read the original abstract
A central challenge in visual intelligence is learning the physical structure of scenes from raw videos: how regions form objects and the laws that govern their interactions. Solving these tasks requires world models capable of inferring distributional states of the world from partial observations - capabilities that current architectures do not provide. We introduce a new class of probabilistic world models that support estimation of the probability of any visual variable, such as appearance and dynamics, conditioned on any other variables. Here, we identify that these models can be trained efficiently with autoregressive sequence modeling, yielding world models from which rich object understanding emerges. First, we demonstrate that our model captures the physical laws governing how objects move by generating multiple plausible future states of the world through sequential inference. Then, by analyzing motion correlations across these futures, we extract objects and articulated object subparts. Having discovered these objects, we show that our world model can manipulate them in 3D. Finally, we demonstrate how physical relationships between objects can be computed from the world model, enabling applications such as Visual Jenga.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a class of probabilistic world models trained via autoregressive sequence modeling on raw videos. It claims these models enable estimation of conditional distributions over visual variables, from which physical object understanding emerges: multiple futures are sampled to capture dynamics, motion correlations across futures are used to extract objects and articulated subparts, the model supports 3D manipulation of discovered objects, and physical relationships (e.g., for Visual Jenga) can be computed directly from the model.
Significance. If substantiated, the approach would offer a unified autoregressive framework for unsupervised extraction of physical structure and controllable 3D reasoning, potentially advancing world-model-based visual intelligence beyond current supervised or heuristic methods. The linkage between future sampling, correlation-based discovery, and downstream physical tasks is conceptually coherent.
major comments (2)
- [Abstract] Abstract (paragraph on object extraction): the claim that motion correlations across autoregressive futures isolate true physical objects and subparts lacks any quantitative validation, ground-truth comparison, or controlled ablation (e.g., on a synthetic simulator with known masks); without such tests the procedure risks circularity with respect to model-induced correlations rather than physical boundaries.
- [Abstract] Abstract (demonstrations of 3D manipulation and Visual Jenga): no metrics, baselines, error bars, or statistical comparisons are reported for controllability or physical-relationship computation; the central claims of emergent physical understanding therefore rest entirely on unquantified qualitative examples whose reproducibility and robustness cannot be evaluated.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the need for quantitative support of the emergent physical understanding claims. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract (paragraph on object extraction): the claim that motion correlations across autoregressive futures isolate true physical objects and subparts lacks any quantitative validation, ground-truth comparison, or controlled ablation (e.g., on a synthetic simulator with known masks); without such tests the procedure risks circularity with respect to model-induced correlations rather than physical boundaries.
Authors: We agree that the current presentation relies on qualitative demonstrations of object and subpart extraction via motion correlations. To address the concern of circularity and provide direct validation against physical boundaries, the revised manuscript will include a new controlled experiment on a synthetic simulator (e.g., with known ground-truth segmentation masks). We will report quantitative metrics such as Adjusted Rand Index (ARI) and Intersection-over-Union (IoU) comparing the correlation-based extraction to ground truth, along with an ablation removing the multi-future sampling to isolate its contribution. revision: yes
-
Referee: [Abstract] Abstract (demonstrations of 3D manipulation and Visual Jenga): no metrics, baselines, error bars, or statistical comparisons are reported for controllability or physical-relationship computation; the central claims of emergent physical understanding therefore rest entirely on unquantified qualitative examples whose reproducibility and robustness cannot be evaluated.
Authors: We acknowledge that the 3D manipulation and Visual Jenga results are presented qualitatively without accompanying metrics or statistical analysis. In the revision we will add quantitative evaluations: for 3D controllability we will report success rates and mean squared error on target pose achievement across multiple trials with error bars; for physical relationship inference we will provide accuracy metrics on tasks such as stability prediction in Visual Jenga, including comparisons against simple baselines (e.g., optical-flow heuristics) and results from repeated runs to demonstrate robustness. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The abstract describes training an autoregressive probabilistic world model on raw videos, generating multiple futures via sequential inference, and then applying motion correlation analysis as a post-processing step to extract objects. No equations, self-citations, or fitted parameters are presented that reduce the object extraction or physical relationship computation to the inputs by construction. The central claims rest on the model's ability to capture dynamics from data and the subsequent analysis, which constitutes independent content rather than a definitional loop or renamed fit. This is the most common honest finding for papers whose core procedure is not shown to collapse into its own training targets.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Cosmos World Foundation Model Platform for Physical AI
Niket Agarwal, Arslan Ali, Maciej Bala, Yogesh Balaji, Erik Barker, Tiffany Cai, Prithvijit Chattopadhyay, Yongxin Chen, Yin Cui, Yifan Ding, et al. Cosmos world foun- dation model platform for physical ai.arXiv preprint arXiv:2501.03575, 2025. 1, 2, 11
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
What if: Understanding motion through sparse interactions
Stefan Andreas Baumann, Nick Stracke, Timy Phan, and Bj¨orn Ommer. What if: Understanding motion through sparse interactions. InProceedings of the IEEE/CVF In- ternational Conference on Computer Vision, pages 10286– 10296, 2025. 2, 6, 10, 15
2025
-
[3]
Bear, Kevin Feigelis, Honglin Chen, Wanhee Lee, Rahul Venkatesh, Klemen Kotar, Alex Durango, and Daniel L
Daniel M. Bear, Kevin Feigelis, Honglin Chen, Wanhee Lee, Rahul Venkatesh, Klemen Kotar, Alex Durango, and Daniel L. K. Yamins. Unifying (machine) vision via counterfactual world modeling, 2023. 11, 13
2023
-
[4]
Anand Bhattad, Konpat Preechakul, and Alexei A Efros. Vi- sual jenga: Discovering object dependencies via counterfac- tual inpainting.arXiv preprint arXiv:2503.21770, 2025. 2, 5, 8
-
[5]
Ge- nie: Generative interactive environments
Jake Bruce, Michael D Dennis, Ashley Edwards, Jack Parker-Holder, Yuge Shi, Edward Hughes, Matthew Lai, Aditi Mavalankar, Richie Steigerwald, Chris Apps, et al. Ge- nie: Generative interactive environments. InForty-first Inter- national Conference on Machine Learning, 2024. 1, 2
2024
-
[6]
Unsupervised segmentation in real-world images via spelke object inference
Honglin Chen, Rahul Venkatesh, Yoni Friedman, Jiajun Wu, Joshua B Tenenbaum, Daniel LK Yamins, and Daniel M Bear. Unsupervised segmentation in real-world images via spelke object inference. InEuropean Conference on Com- puter Vision, pages 719–735. Springer, 2022. 6
2022
-
[7]
Yingjie Chen, Yifang Men, Yuan Yao, Miaomiao Cui, and Liefeng Bo. Perception-as-control: Fine-grained control- lable image animation with 3d-aware motion representation. arXiv preprint arXiv:2501.05020, 2025. 2, 6, 8, 14, 26
-
[8]
Open X-Embodiment: Robotic Learning Datasets and RT-X Models
Open X-Embodiment Collaboration, Abby O’Neill, Abdul Rehman, Abhinav Gupta, Abhiram Maddukuri, Abhishek Gupta, Abhishek Padalkar, Abraham Lee, Acorn Pooley, Agrim Gupta, Ajay Mandlekar, Ajinkya Jain, and et al. Open X-Embodiment: Robotic learning datasets and RT-X models. https://arxiv.org/abs/2310.08864, 2023. 11, 12
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[9]
Abhimanyu Dubey, Abhinav Jauhri, and Abhinav Pandey et.al. The llama 3 herd of models.ArXiv, abs/2407.21783,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Taming transformers for high-resolution image synthesis
Patrick Esser, Robin Rombach, and Bj ¨orn Ommer. Taming transformers for high-resolution image synthesis. InPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 12873–12883, 2021. 11
2021
-
[11]
Adap- tive slot attention: Object discovery with dynamic slot num- ber
Ke Fan, Zechen Bai, Tianjun Xiao, Tong He, Max Horn, Yanwei Fu, Francesco Locatello, and Zheng Zhang. Adap- tive slot attention: Object discovery with dynamic slot num- ber. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition, pages 23062–23071,
-
[12]
Learning Graphical Models of Images, Videos and Their Spatial Transformations
Brendan J Frey and Nebojsa Jojic. Learning graphical mod- els of images, videos and their spatial transformations.arXiv preprint arXiv:1301.3854, 2013. 2
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[13]
Nate Gillman, Charles Herrmann, Michael Freeman, Daksh Aggarwal, Evan Luo, Deqing Sun, and Chen Sun. Force prompting: Video generation models can learn and gen- eralize physics-based control signals.arXiv preprint arXiv:2505.19386, 2025. 2, 6, 14
-
[14]
Something Something
Raghav Goyal, Samira Ebrahimi Kahou, Vincent Michal- ski, Joanna Materzynska, Susanne Westphal, Heuna Kim, Valentin Haenel, Ingo Fruend, Peter Yianilos, Moritz MuellerFreitag, Florian Hoppe, Christian Thurau, Ingo Bax, and Roland Memisevic. The “Something Something” Video Database for Learning and Evaluating Visual Common Sense. InProceedings of the IEEE ...
2017
-
[15]
Diffusion as shader: 3d- aware video diffusion for versatile video generation control,
Zekai Gu, Rui Yan, Jiahao Lu, Peng Li, Zhiyang Dou, Chenyang Si, Zhen Dong, Qifeng Liu, Cheng Lin, Ziwei Liu, Wenping Wang, and Yuan Liu. Diffusion as shader: 3d- aware video diffusion for versatile video generation control,
-
[16]
David Ha and J ¨urgen Schmidhuber. World models.arXiv preprint arXiv:1803.10122, 2(3):440, 2018. 2
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[17]
W Ji, J Li, Q Bi, W Li, and L Cheng. Segment any- thing is not always perfect: An investigation of sam on dif- ferent real-world applications. arxiv 2023.arXiv preprint arXiv:2304.05750. 2
-
[18]
The Kinetics Human Action Video Dataset
Will Kay, Joao Carreira, Karen Simonyan, Brian Zhang, Chloe Hillier, Sudheendra Vijayanarasimhan, Fabio Viola, Tim Green, Trevor Back, Paul Natsev, Mustafa Suleyman, and Andrew Zisserman. The kinetics human action video dataset.arXiv preprint arXiv:1705.06950, 2017. Dataset: Kinetics-400. 11
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[19]
MIT press, 2009
Daphne Koller and Nir Friedman.Probabilistic graphical models: principles and techniques. MIT press, 2009. 2
2009
-
[20]
World modeling with probabilistic struc- ture integration, 2025
Klemen Kotar, Wanhee Lee, Rahul Venkatesh, Honglin Chen, Daniel Bear, Jared Watrous, Simon Kim, Khai Loong Aw, Lilian Naing Chen, Stefan Stojanov, Kevin Feigelis, Im- ran Thobani, Alex Durango, Khaled Jedoui, Atlas Kazemian, and Dan Yamins. World modeling with probabilistic struc- ture integration, 2025. 2
2025
-
[21]
Wanhee Lee, Klemen Kotar, Rahul Mysore Venkatesh, Jared Watrous, Honglin Chen, Khai Loong Aw, and Daniel LK Yamins. 3d scene understanding through local random ac- cess sequence modeling.arXiv preprint arXiv:2504.03875,
-
[22]
Promerge: Prompt and merge for unsupervised instance segmentation
Dylan Li and Gyungin Shin. Promerge: Prompt and merge for unsupervised instance segmentation. InEuropean Con- ference on Computer Vision (ECCV), 2024. 2, 6, 10, 14
2024
-
[23]
Dragapart: Learning a part-level motion prior for articulated objects
Ruining Li, Chuanxia Zheng, Christian Rupprecht, and An- drea Vedaldi. Dragapart: Learning a part-level motion prior for articulated objects. InEuropean Conference on Com- puter Vision, pages 165–183. Springer, 2024. 6
2024
-
[24]
Video-llava: Learning united visual repre- sentation by alignment before projection
Bin Lin, Yang Ye, Bin Zhu, Jiaxi Cui, Munan Ning, Peng Jin, and Li Yuan. Video-llava: Learning united visual repre- sentation by alignment before projection. InProceedings of the 2024 Conference on Empirical Methods in Natural Lan- guage Processing, pages 5971–5984, 2024. 2
2024
-
[25]
Lawrence Zitnick, and Piotr Doll ´ar
Tsung-Yi Lin, Michael Maire, Serge Belongie, Lubomir Bourdev, Ross Girshick, James Hays, Pietro Perona, Deva 28 Ramanan, C. Lawrence Zitnick, and Piotr Doll ´ar. Microsoft coco: Common objects in context, 2015. 12
2015
-
[26]
Finite Scalar Quantization: VQ-VAE Made Simple
Fabian Mentzer, David Minnen, Eirikur Agustsson, and Michael Tschannen. Finite scalar quantization: Vq-vae made simple.arXiv preprint arXiv:2309.15505, 2023. 11
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[27]
Spelkebench.https://github.com/ neuroailab/SpelkeBench, 2024
NeuroAILab. Spelkebench.https://github.com/ neuroailab/SpelkeBench, 2024. 2, 6, 12
2024
-
[28]
Maxime Oquab, Timoth ´ee Darcet, Theo Moutakanni, Huy V . V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Rus- sell Howes, Po-Yao Huang, Hu Xu, Vasu Sharma, Shang- Wen Li, Wojciech Galuba, Mike Rabbat, Mido Assran, Nico- las Ballas, Gabriel Synnaeve, Ishan Misra, Herve Jegou, Julien Mairal, Patri...
2023
-
[29]
Diffusion handles enabling 3d edits for diffusion models by lifting ac- tivations to 3d
Karran Pandey, Paul Guerrero, Matheus Gadelha, Yannick Hold-Geoffroy, Karan Singh, and Niloy J Mitra. Diffusion handles enabling 3d edits for diffusion models by lifting ac- tivations to 3d. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7695– 7704, 2024. 2, 6, 8
2024
-
[30]
High-quality entity segmentation
Lu Qi, Jason Kuen, Tiancheng Shen, Jiuxiang Gu, Weidong Guo, Jiaya Jia, Zhe Lin, and Ming-Hsuan Yang. High-quality entity segmentation. InInternational Conference on Com- puter Vision (ICCV), 2023. 12, 13
2023
-
[31]
Improving language understanding by gen- erative pre-training
Alec Radford, Karthik Narasimhan, Tim Salimans, Ilya Sutskever, et al. Improving language understanding by gen- erative pre-training. 2018. 1
2018
-
[32]
Learning transferable visual models from natural language supervision, 2021
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision, 2021. 11
2021
-
[33]
SAM 2: Segment Anything in Images and Videos
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman R¨adle, Chloe Rolland, Laura Gustafson, Eric Mintun, Junt- ing Pan, Kalyan Vasudev Alwala, Nicolas Carion, Chao- Yuan Wu, Ross Girshick, Piotr Doll´ar, and Christoph Feicht- enhofer. Sam 2: Segment anything in images and videos. arXiv preprint arXiv:...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[34]
Com- mon objects in 3d: Large-scale learning and evaluation of real-life 3d category reconstruction
Jeremy Reizenstein, Roman Shapovalov, Philipp Henzler, Luca Sbordone, Patrick Labatut, and David Novotny. Com- mon objects in 3d: Large-scale learning and evaluation of real-life 3d category reconstruction. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2021. Dataset: CO3D. 11
2021
-
[35]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022. 1
2022
-
[36]
Motion-i2v: Consistent and controllable image-to-video generation with explicit motion modeling
Xiaoyu Shi, Zhaoyang Huang, Fu-Yun Wang, Weikang Bian, Dasong Li, Yi Zhang, Manyuan Zhang, Ka Chun Cheung, Simon See, Hongwei Qin, et al. Motion-i2v: Consistent and controllable image-to-video generation with explicit motion modeling. InACM SIGGRAPH 2024 Conference Papers, pages 1–11, 2024. 6
2024
-
[37]
Gemma Team, Aishwarya Kamath, Johan Ferret, Shreya Pathak, Nino Vieillard, Ramona Merhej, Sarah Perrin, Ta- tiana Matejovicova, Alexandre Ram ´e, Morgane Rivi `ere, et al. Gemma 3 technical report.arXiv preprint arXiv:2503.19786, 2025. 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
Llama: Open and efficient foundation lan- guage models, 2023
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timoth´ee Lacroix, Baptiste Rozi`ere, Naman Goyal, Eric Hambro, Faisal Azhar, Aure- lien Rodriguez, Armand Joulin, Edouard Grave, and Guil- laume Lample. Llama: Open and efficient foundation lan- guage models, 2023. 1
2023
-
[39]
Neural discrete representation learning
Aaron Van Den Oord, Oriol Vinyals, et al. Neural discrete representation learning. InAdvances in neural information processing systems, 2017. 11
2017
-
[40]
Understanding physical dynamics with counterfactual world modeling
Rahul Venkatesh, Honglin Chen, Kevin Feigelis, Daniel M Bear, Khaled Jedoui, Klemen Kotar, Felix Binder, Wan- hee Lee, Sherry Liu, Kevin A Smith, et al. Understanding physical dynamics with counterfactual world modeling. In European Conference on Computer Vision, pages 368–387. Springer, 2024. 6, 15
2024
-
[41]
Cut and learn for unsupervised object detection and instance segmentation
Xudong Wang, Rohit Girdhar, Stella X Yu, and Ishan Misra. Cut and learn for unsupervised object detection and instance segmentation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 3124– 3134, 2023. 2, 6, 10, 14
2023
-
[42]
SEA-RAFT: Sim- ple, efficient, accurate raft for optical flow
Yihan Wang, Lahav Lipson, and Jia Deng. SEA-RAFT: Sim- ple, efficient, accurate raft for optical flow. InProceedings of the European Conference on Computer Vision (ECCV),
-
[43]
Understanding warmup-stable-decay learning rates: A river valley loss landscape perspective
Kaiyue Wen, Zhiyuan Li, Jason Wang, David Hall, Percy Liang, and Tengyu Ma. Understanding warmup-stable-decay learning rates: A river valley loss landscape perspective. arXiv preprint arXiv:2410.05192, 2024. 4
-
[44]
Physical scene understanding.AI Magazine, 45 (1):156–164, 2024
Jiajun Wu. Physical scene understanding.AI Magazine, 45 (1):156–164, 2024. 2
2024
-
[45]
Draganything: Motion control for any- thing using entity representation, 2024
Weijia Wu, Zhuang Li, Yuchao Gu, Rui Zhao, Yefei He, David Junhao Zhang, Mike Zheng Shou, Yan Li, Tingting Gao, and Di Zhang. Draganything: Motion control for any- thing using entity representation, 2024. 2
2024
-
[46]
Depth any- thing v2, 2024
Lihe Yang, Bingyi Kang, Zilong Huang, Zhen Zhao, Xiao- gang Xu, Jiashi Feng, and Hengshuang Zhao. Depth any- thing v2, 2024. 14
2024
-
[47]
ScanNet++: A high-fidelity dataset of 3d in- door scenes
Chandan Yeshwanth, Yueh-Cheng Liu, Matthias Nießner, and Angela Dai. ScanNet++: A high-fidelity dataset of 3d in- door scenes. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2023. Dataset: ScanNet++. 11
2023
-
[48]
Understanding segment anything model: Sam is biased towards texture rather than shape
Chaoning Zhang, Yu Qiao, Shehbaz Tariq, Sheng Zheng, Chenshuang Zhang, Chenghao Li, Hyundong Shin, and Choong Seon Hong. Understanding segment anything model: Sam is biased towards texture rather than shape. arXiv preprint arXiv:2311.11465, 2023. 2
-
[49]
Stereo magnification: Learning view syn- thesis using multiplane images
Tinghui Zhou, Richard Tucker, John Flynn, Graham Fyffe, and Noah Snavely. Stereo magnification: Learning view syn- thesis using multiplane images. InACM SIGGRAPH Confer- ence Proceedings, 2018. Dataset: RealEstate-10K. 11 29
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.