ProtStructQA: A Denotation Threshold in Protein Structural Reasoning
Pith reviewed 2026-06-28 19:23 UTC · model grok-4.3
The pith
Protein structural QA crosses a denotation threshold at 4B parameters where chain-of-thought overtakes tool use.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
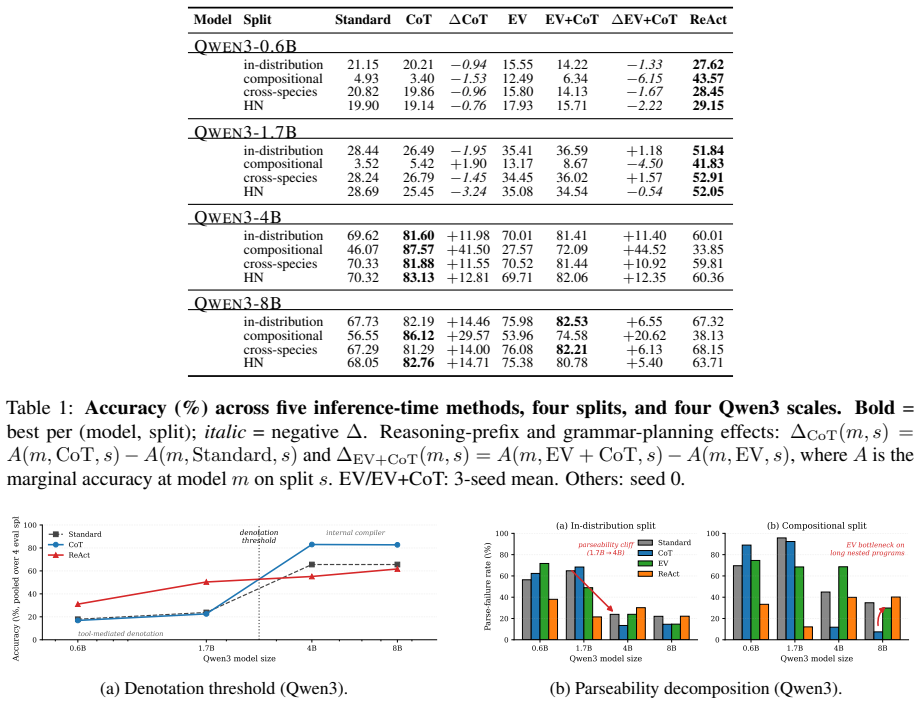
The central claim is that a capability-dependent denotation threshold exists between Qwen3-1.7B and Qwen3-4B such that below it tool-mediated ReAct dominates because models fail to produce executable denotations while above it chain-of-thought becomes the strongest strategy on most splits. The threshold marks a transition from unparseable language to executable structural denotation, with grammar and execution remaining selectively valuable for PAE and secondary-structure queries.
What carries the argument
The denotation threshold, the model-size transition point at which outputs shift from unparseable language to executable structural denotations that can be verified by program execution on protein structures.
If this is right
- Tool-mediated ReAct is required for reliable performance on structural questions when models sit below the denotation threshold.
- Chain-of-thought becomes optimal and superior to tool use once models cross the threshold on most query types.
- Grammar-constrained executable voting and execution feedback provide selective gains for PAE and secondary-structure queries even above the threshold.
- Parse-failure rates drop as capability increases past the threshold, enabling direct mapping from language to measurements.
- The benchmark serves as a diagnostic testbed for when models can compile language into executable 3D structural measurements.
Where Pith is reading between the lines
- The same threshold pattern may appear in other quantitative scientific domains that require models to output verifiable measurements rather than text.
- Testing additional model sizes around 2-5B parameters could locate the transition more precisely and test whether it moves with further scaling.
- The hidden-program approach for generating ground truth could extend to chemistry or materials questions that also reduce to executable simulations.
- Models just above the threshold may still gain from hybrid tool-plus-reasoning strategies on the hard-negative robustness pool.
Load-bearing premise
Executing the hidden DSL programs on AlphaFold-predicted structures produces reliable ground-truth answers for the structural questions.
What would settle it
Replicating the evaluation and finding that chain-of-thought does not become the strongest strategy for models at or above 4B parameters, or that ReAct does not dominate for models at or below 1.7B on the held-out splits.
Figures



read the original abstract
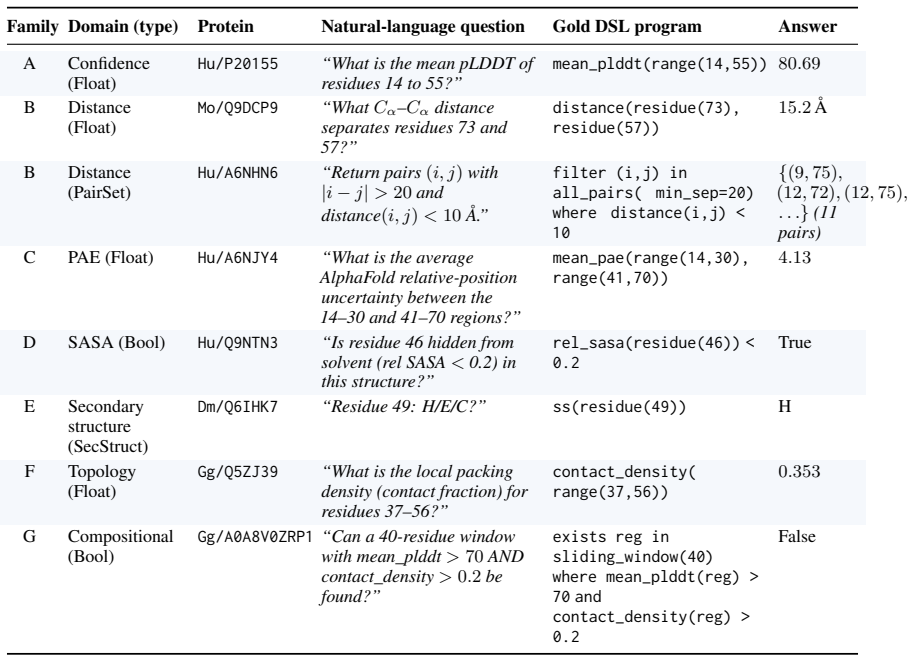
Protein-language systems are often evaluated by whether they generate plausible biological text, but a structural question has a sharper semantics: it denotes a measurement in a 3D coordinate system. We introduce ProtStructQA, an executable benchmark for protein structural question answering in which each natural-language question is generated from a hidden typed domain-specific language (DSL) program and the answer is obtained by executing that program on an AlphaFold-predicted structure. ProtStructQA releases 382.2K questions covering confidence, distances, predicted aligned error (PAE), solvent exposure, secondary structure, topology and contacts, and held-out compositions: a 330K active benchmark over 10K proteins from four species, plus a 52.2K hard-negative robustness pool. Without fine-tuning, we evaluate Qwen3 models from 0.6B to 8B under direct prompting, chain-of-thought, grammar-constrained executable voting, executable voting with chain-of-thought, and multi-turn ReAct-style tool use, and replicate the headline finding on Gemma-3-1B and Gemma-3-12B. We find a capability-dependent denotation threshold between Qwen3-1.7B and Qwen3-4B: below it, tool-mediated ReAct dominates because models often fail to produce executable denotations; above it, chain-of-thought flips from mostly harmful to strongly beneficial and becomes the strongest strategy on most splits. Parse-failure and family-level analyses show that the threshold is a transition from unparseable language to executable structural denotation, while grammar and execution remain selectively valuable for PAE and secondary-structure queries. ProtStructQA reframes scientific QA as compilation from language to measurement and provides a diagnostic testbed for when language models can map words to executable 3D structural measurements.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces ProtStructQA, an executable benchmark with 382.2K natural-language questions generated from hidden typed DSL programs; ground-truth answers are obtained by executing those programs on AlphaFold-predicted structures. The benchmark covers confidence, distances, PAE, solvent exposure, secondary structure, topology and contacts, with a 330K active set over 10K proteins and a 52.2K hard-negative pool. Without fine-tuning, Qwen3 models (0.6B–8B) are evaluated under direct prompting, chain-of-thought, grammar-constrained executable voting, and multi-turn ReAct tool use; the headline result is replicated on Gemma-3-1B and Gemma-3-12B. The central claim is a capability-dependent denotation threshold between Qwen3-1.7B and Qwen3-4B: below the threshold ReAct dominates because models fail to produce executable denotations; above it, chain-of-thought becomes the strongest strategy on most splits. Parse-failure and family-level analyses are offered to characterize the transition.
Significance. If the result holds after addressing ground-truth validation, the work supplies a large-scale, executable diagnostic for when language models can compile natural language into verifiable 3D structural measurements rather than plausible text. The explicit identification of a model-size threshold at which prompting strategy dominance reverses, together with the public release of the 382K-question artifact and cross-family replication, would constitute a concrete testbed for scientific reasoning capabilities in LLMs.
major comments (2)
- [Abstract] Abstract: The headline denotation-threshold claim is scored against answers obtained by executing hidden DSL programs on AlphaFold-predicted structures. No cross-check against experimental PDB coordinates, no sensitivity analysis to per-residue pLDDT or PAE uncertainty, and no quantification of label noise in flexible regions or interfaces are reported. Because the observed flip in ReAct vs. CoT dominance between the 1.7B and 4B models is defined relative to these proxy labels, systematic discrepancies could artifactually produce the threshold rather than reflect a genuine transition in executable denotation.
- [Abstract] Abstract / headline result: The benchmark construction and the capability-threshold finding are presented without error bars, statistical tests for the strategy-dominance reversal, or explicit exclusion criteria for the splits. This absence makes it impossible to judge whether the reported transition is robust to sampling variation or particular protein families.
minor comments (1)
- The figure of merit 382.2K is given with one decimal; clarify whether this is an exact count or a rounded value.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on ProtStructQA. The two major comments raise valid concerns about reliance on AlphaFold-derived labels and the statistical presentation of the denotation threshold. We respond point-by-point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline denotation-threshold claim is scored against answers obtained by executing hidden DSL programs on AlphaFold-predicted structures. No cross-check against experimental PDB coordinates, no sensitivity analysis to per-residue pLDDT or PAE uncertainty, and no quantification of label noise in flexible regions or interfaces are reported. Because the observed flip in ReAct vs. CoT dominance between the 1.7B and 4B models is defined relative to these proxy labels, systematic discrepancies could artifactually produce the threshold rather than reflect a genuine transition in executable denotation.
Authors: We acknowledge the limitation. ProtStructQA is deliberately constructed on AlphaFold predictions to enable a large-scale (382K-question), consistently executable benchmark; experimental PDB cross-validation at this scale is not feasible. In revision we will add a dedicated Limitations subsection discussing AF uncertainty, a sensitivity analysis restricted to residues with pLDDT > 90, and explicit quantification of performance variance in flexible regions and interfaces. These additions will clarify that the observed threshold reflects model denotation capability rather than solely label artifacts. revision: yes
-
Referee: [Abstract] Abstract / headline result: The benchmark construction and the capability-threshold finding are presented without error bars, statistical tests for the strategy-dominance reversal, or explicit exclusion criteria for the splits. This absence makes it impossible to judge whether the reported transition is robust to sampling variation or particular protein families.
Authors: We agree that statistical support is required. The revised manuscript will include bootstrap-derived error bars on all accuracy results, a formal statistical test (bootstrap confidence intervals on the performance difference between ReAct and CoT) confirming the dominance reversal between the 1.7B and 4B models, and explicit exclusion criteria for the active set and hard-negative pool (sequence-length filters, species balance, and family-level hold-outs). These will appear in the main results section and appendix. revision: yes
Circularity Check
No circularity: new benchmark and empirical threshold are independent artifacts
full rationale
The paper constructs ProtStructQA as a fresh benchmark (questions from hidden DSL programs executed on AlphaFold structures) and reports an observed capability threshold between Qwen3-1.7B and 4B from direct model evaluations under multiple strategies. No equations, fitted parameters, or self-citations are present that reduce the threshold or any headline result to a definition or input by construction. The derivation chain consists of new data generation plus independent prompting experiments and is therefore self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption AlphaFold-predicted structures provide sufficiently accurate 3D coordinates for the structural measurements (distances, PAE, contacts, etc.) used in the benchmark.
Reference graph
Works this paper leans on
-
[1]
Computer Applications in the Biosciences , volume =
Labesse, Gilles and Colloc'h, Nathalie and Pothier, Jo. Computer Applications in the Biosciences , volume =. 1997 , doi =
1997
-
[2]
Advances in Neural Information Processing Systems (NeurIPS) , volume =
Chain-of-thought prompting elicits reasoning in large language models , author =. Advances in Neural Information Processing Systems (NeurIPS) , volume =. 2022 , url =
2022
-
[3]
International Conference on Learning Representations (ICLR) , year =
Self-Consistency Improves Chain of Thought Reasoning in Language Models , author =. International Conference on Learning Representations (ICLR) , year =
-
[4]
Advances in Neural Information Processing Systems (NeurIPS) , volume =
Large language models are zero-shot reasoners , author =. Advances in Neural Information Processing Systems (NeurIPS) , volume =. 2022 , url =
2022
-
[5]
Eikema, Bryan and Aziz, Wilker , booktitle =. Is. 2020 , url =
2020
-
[6]
Grammar-constrained decoding for structured
Geng, Saibo and Josifoski, Martin and Peyrard, Maxime and West, Robert , booktitle =. Grammar-constrained decoding for structured. 2023 , url =
2023
-
[7]
2023 , eprint =
Efficient Guided Generation for Large Language Models , author =. 2023 , eprint =
2023
-
[8]
Proceedings of the First Conference on Language Modeling (COLM) , year =
Automata-based constraints for language model decoding , author =. Proceedings of the First Conference on Language Modeling (COLM) , year =
-
[9]
2024 , howpublished =
2024
-
[10]
Transactions on Machine Learning Research , issn =
Program of Thoughts Prompting: Disentangling Computation from Reasoning for Numerical Reasoning Tasks , author =. Transactions on Machine Learning Research , issn =. 2023 , url =
2023
-
[11]
2023 , url =
Gao, Luyu and Madaan, Aman and Zhou, Shuyan and Alon, Uri and Liu, Pengfei and Yang, Yiming and Callan, Jamie and Neubig, Graham , booktitle =. 2023 , url =
2023
-
[12]
2023 , url =
Yao, Shunyu and Zhao, Jeffrey and Yu, Dian and Du, Nan and Shafran, Izhak and Narasimhan, Karthik and Cao, Yuan , booktitle =. 2023 , url =
2023
-
[13]
2023 , url =
Shinn, Noah and Cassano, Federico and Gopinath, Ashwin and Narasimhan, Karthik and Yao, Shunyu , booktitle =. 2023 , url =
2023
-
[14]
Advances in Neural Information Processing Systems (NeurIPS) , volume =
Tree of Thoughts: Deliberate problem solving with large language models , author =. Advances in Neural Information Processing Systems (NeurIPS) , volume =. 2023 , url =
2023
-
[15]
2023 , url =
Madaan, Aman and Tandon, Niket and Gupta, Prakhar and Hallinan, Skyler and Gao, Luyu and Wiegreffe, Sarah and Alon, Uri and Dziri, Nouha and Prabhumoye, Shrimai and Yang, Yiming and Gupta, Shashank and Majumder, Bodhisattwa Prasad and Hermann, Katherine and Welleck, Sean and Yazdanbakhsh, Amir and Clark, Peter , booktitle =. 2023 , url =
2023
-
[16]
Proceedings of the 35th International Conference on Machine Learning (ICML) , series =
Generalization without systematicity: On the compositional skills of sequence-to-sequence recurrent networks , author =. Proceedings of the 35th International Conference on Machine Learning (ICML) , series =. 2018 , url =
2018
-
[17]
International Conference on Learning Representations (ICLR) , year =
Measuring compositional generalization: A comprehensive method on realistic data , author =. International Conference on Learning Representations (ICLR) , year =
-
[18]
Lawrence and Girshick, Ross , booktitle =
Johnson, Justin and Hariharan, Bharath and van der Maaten, Laurens and Fei-Fei, Li and Zitnick, C. Lawrence and Girshick, Ross , booktitle =. 2017 , doi =
2017
-
[19]
and Manning, Christopher D
Hudson, Drew A. and Manning, Christopher D. , booktitle =. 2019 , doi =
2019
-
[20]
Highly accurate protein structure prediction with
Jumper, John and Evans, Richard and Pritzel, Alexander and Green, Tim and Figurnov, Michael and Ronneberger, Olaf and Tunyasuvunakool, Kathryn and Bates, Russ and. Highly accurate protein structure prediction with. Nature , volume =. 2021 , doi =
2021
-
[21]
Nucleic Acids Research , volume =
Varadi, Mihaly and Anyango, Stephen and Deshpande, Mandar and Nair, Sreenath and Natassia, Cindy and Yordanova, Galabina and Yuan, David and Stroe, Oana and Wood, Gemma and Laydon, Agata and. Nucleic Acids Research , volume =. 2022 , doi =
2022
-
[22]
Psychometrika , volume =
Note on the sampling error of the difference between correlated proportions or percentages , author =. Psychometrika , volume =. 1947 , doi =
1947
-
[23]
1994 , doi =
An introduction to the bootstrap , author =. 1994 , doi =
1994
-
[24]
Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (ACL) , pages =
The hitchhiker's guide to testing statistical significance in natural language processing , author =. Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (ACL) , pages =. 2018 , url =
2018
-
[25]
2025 , doi =
Nucleic Acids Research , volume =. 2025 , doi =
2025
-
[26]
Nucleic Acids Research , volume =
Bertoni, Damian and Tsenkov, Maxim and Magana, Paulyna and Nair, Sreenath and Pidruchna, Ivanna and Afonso, Marcelo Querino Lima and Midlik, Adam and Paramval, Urmila and Lawal, Dare and Tanweer, Ahsan and Last, Meera and Patel, Risha and Laydon, Agata and Lasecki, Dariusz and Dietrich, Nick and Tomlinson, Hamish and. Nucleic Acids Research , volume =. 20...
2026
-
[27]
Biopolymers , volume =
Dictionary of protein secondary structure: pattern recognition of hydrogen-bonded and geometrical features , author =. Biopolymers , volume =. 1983 , doi =
1983
-
[28]
Yang, An and Li, Anfeng and Yang, Baosong and Zhang, Beichen and Hui, Binyuan and Zheng, Bo and Yu, Bowen and Gao, Chang and Huang, Chengen and Lv, Chenxu and Zheng, Chujie and Liu, Dayiheng and Zhou, Fan and Huang, Fei and Hu, Feng and Ge, Hao and Wei, Haoran and Lin, Huan and Tang, Jialong and Yang, Jian and Tu, Jianhong and Zhang, Jianwei and Yang, Jia...
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
Efficient memory management for large language model serving with
Kwon, Woosuk and Li, Zhuohan and Zhuang, Siyuan and Sheng, Ying and Zheng, Lianmin and Yu, Cody Hao and Gonzalez, Joseph and Zhang, Hao and Stoica, Ion , booktitle =. Efficient memory management for large language model serving with. 2023 , doi =
2023
-
[30]
, booktitle =
Rao, Roshan and Bhattacharya, Nicholas and Thomas, Neil and Duan, Yan and Chen, Xi and Canny, John and Abbeel, Pieter and Song, Yun S. , booktitle =. Evaluating Protein Transfer Learning with. 2019 , url =
2019
-
[31]
2022 , url =
Xu, Minghao and Zhang, Zuobai and Lu, Jiarui and Zhu, Zhaocheng and Zhang, Yangtian and Ma, Chang and Liu, Runcheng and Tang, Jian , booktitle =. 2022 , url =
2022
-
[32]
, booktitle =
Notin, Pascal and Kollasch, Aaron and Ritter, Daniel and van Niekerk, Lood and Paul, Steffanie and Spinner, Han and Rollins, Nathan and Shaw, Ada and Orenbuch, Rose and Weitzman, Ruben and Frazer, Jonathan and Dias, Mafalda and Franceschi, Dinko and Gal, Yarin and Marks, Debora S. , booktitle =. 2023 , url =
2023
-
[33]
2024 , url =
Fang, Yin and Liang, Xiaozhuan and Zhang, Ningyu and Liu, Kangwei and Huang, Rui and Chen, Zhuo and Fan, Xiaohui and Chen, Huajun , booktitle =. 2024 , url =
2024
-
[34]
2024 , url =
Wang, Zeyuan and Zhang, Qiang and Ding, Keyan and Qin, Ming and Zhuang, Xiang and Li, Xiaotong and Chen, Huajun , booktitle =. 2024 , url =
2024
-
[35]
Wang, Chao and Fan, Hehe and Quan, Ruijie and Yang, Yi , year =. 2402.09649 , archivePrefix =
-
[36]
Advances in Neural Information Processing Systems (NeurIPS) , volume =
Language Models are Few-Shot Learners , author =. Advances in Neural Information Processing Systems (NeurIPS) , volume =. 2020 , url =
2020
-
[37]
Cock, Peter J. A. and Antao, Tiago and Chang, Jeffrey T. and Chapman, Brad A. and Cox, Cymon J. and Dalke, Andrew and Friedberg, Iddo and Hamelryck, Thomas and Kauff, Frank and Wilczynski, Bartek and. Bioinformatics , volume =. 2009 , doi =
2009
-
[38]
2016 , doi =
Mitternacht, Simon , journal =. 2016 , doi =
2016
-
[39]
2018 , doi =
Kunzmann, Patrick and Hamacher, Kay , journal =. 2018 , doi =
2018
-
[40]
Xiao, Yijia and Sun, Edward and Jin, Yiqiao and Wang, Qifan and Wang, Wei , year =. 2408.11363 , archivePrefix =
-
[41]
2025 , eprint =
Gemma 3 Technical Report , author =. 2025 , eprint =
2025
-
[42]
and Sharifzadeh, Sahand , year =
Carrami, Eli M. and Sharifzadeh, Sahand , year =. 2402.13653 , archivePrefix =
-
[43]
2024 , url =
Liu, Zhiyuan and Zhang, An and Fei, Hao and Zhang, Enzhi and Wang, Xiang and Kawaguchi, Kenji and Chua, Tat-Seng , booktitle =. 2024 , url =
2024
-
[44]
2025 , doi =
Wang, Zhicong and Ma, Zicheng and Cao, Ziqiang and Zhou, Changlong and Zhang, Jun and Gao, Yi Qin , journal =. 2025 , doi =
2025
-
[45]
2025 , eprint =
Geng, Saibo and Cooper, Hudson and Moskal, Micha. 2025 , eprint =
2025
-
[46]
Proceedings of the 42nd International Conference on Machine Learning (ICML) , series =
Flexible and Efficient Grammar-Constrained Decoding , author =. Proceedings of the 42nd International Conference on Machine Learning (ICML) , series =. 2025 , url =
2025
-
[47]
2026 , howpublished =
Introducing. 2026 , howpublished =
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.