TAPS: Target-Aware Prefix Tree Selection for Diffusion-Drafted Speculative Decoding
Pith reviewed 2026-06-28 19:11 UTC · model grok-4.3
The pith
TAPS converts diffusion marginals into path-conditioned estimates to select compact prefix-closed draft subtrees that improve the acceptance-verification tradeoff in speculative decoding.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
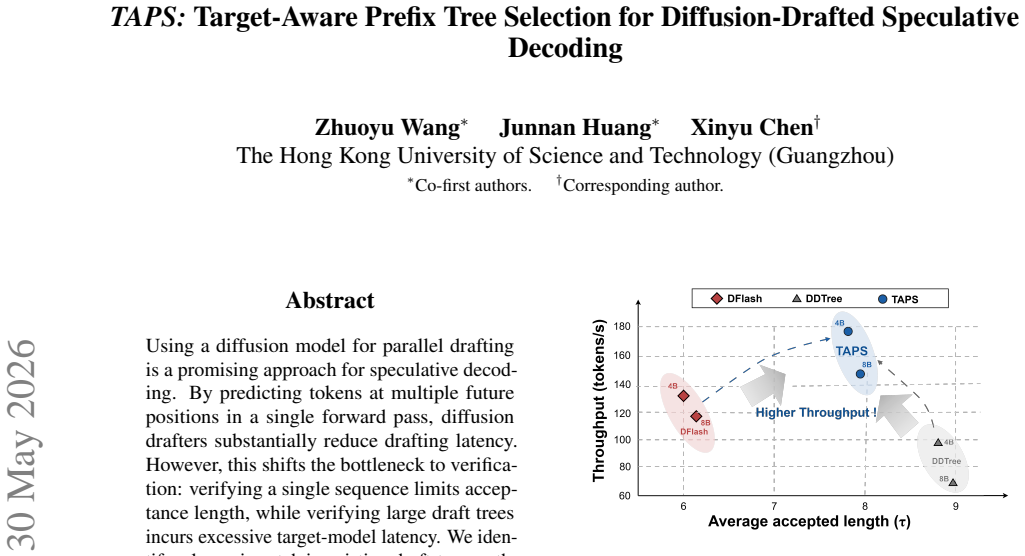
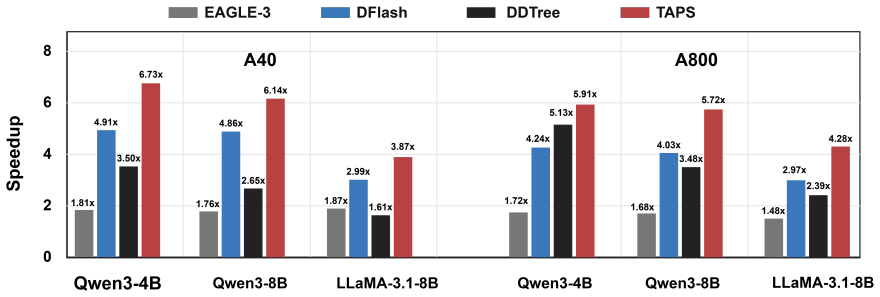
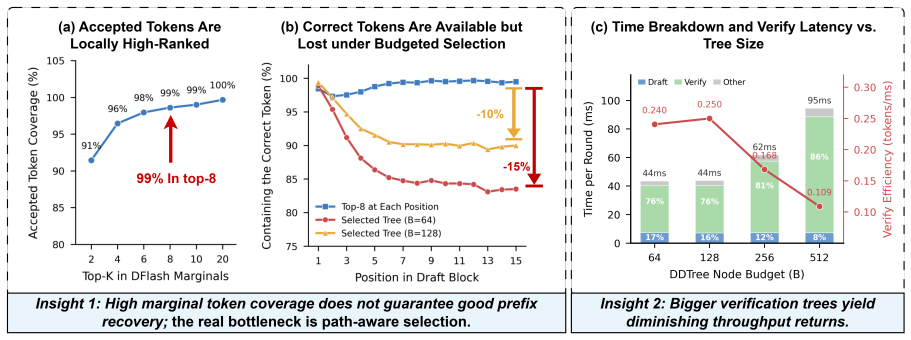
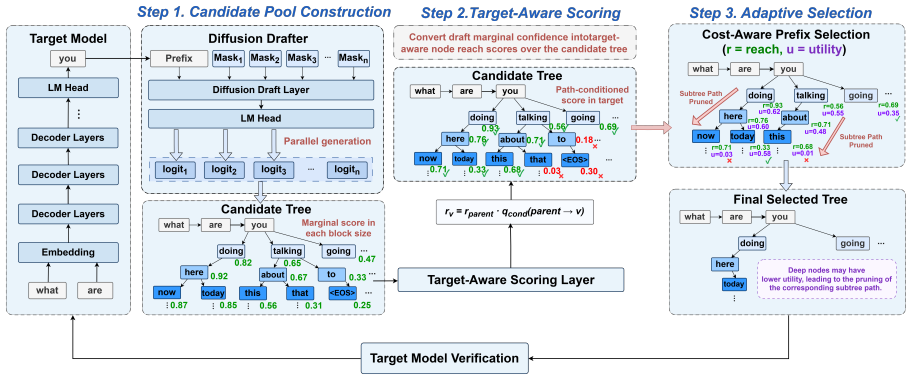
Existing diffusion-tree methods rank nodes by marginal probability and therefore spend verification budget on unreachable descendants of rejected prefixes. TAPS instead derives path-conditioned acceptance estimates from the same diffusion marginals, then selects a compact prefix-closed subtree that respects a fixed verification budget. This selection improves the acceptance-length versus target-latency tradeoff, yielding up to 7.9 times lossless end-to-end speedup over autoregressive decoding and outperforming prior diffusion-tree baselines.
What carries the argument
TAPS (target-aware prefix selection), the procedure that converts diffusion marginal probabilities into path-conditioned acceptance estimates and then extracts a compact prefix-closed subtree under a verification budget.
If this is right
- Up to 7.9x lossless end-to-end speedup over vanilla autoregressive decoding.
- 1.36x improvement over DFlash and 1.74x improvement over DDTree.
- Higher acceptance length for a given verification budget across diverse datasets and model families.
- Reduced waste from verifying nodes behind rejected prefixes.
Where Pith is reading between the lines
- The same path-conditioning step could be applied to any drafter that outputs position-wise marginals rather than full trees.
- The fixed-budget subtree selection may allow deeper drafts in memory-limited settings without proportional latency increase.
- If the acceptance estimates remain accurate at larger batch sizes, the method could extend to batched inference workloads.
Load-bearing premise
Path-conditioned acceptance estimates derived from diffusion marginals will produce a subtree whose acceptance length versus verification cost tradeoff is strictly better than marginal-probability ranking without introducing offsetting overhead.
What would settle it
On the same diffusion drafter and target models, a marginal-ranked draft tree achieves equal or higher average accepted tokens per unit of target verification time than the TAPS-selected subtree.
Figures



read the original abstract
Using a diffusion model for parallel drafting is a promising approach for speculative decoding. By predicting tokens at multiple future positions in a single forward pass, diffusion drafters substantially reduce drafting latency. However, this shifts the bottleneck to verification: verifying a single sequence limits acceptance length, while verifying large draft trees incurs excessive target-model latency. We identify a key mismatch in existing draft-tree methods: existing diffusion-tree methods rank nodes by the marginal probability, ignoring that verification is prefix-conditioned. As a result, they may verify unreachable descendants of rejected prefixes, increasing latency with limited acceptance gains. To address this, we propose TAPS, a target-aware prefix selection method that turns diffusion marginals into path-conditioned acceptance estimates. TAPS then selects a compact prefix-closed subtree under a fixed verification budget, improving the acceptance-cost tradeoff rather than simply expanding the draft tree. Experiments across diverse datasets and model families demonstrate that TAPS achieves up to 7.9x lossless end-to-end speedup over vanilla autoregressive decoding, outperforming state-of-the-art DFlash and DDTree by 1.36x and 1.74x respectively. Our work is available at https://anonymous.4open.science/r/TAPS-EMNLP2026-53DD
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes TAPS, a target-aware prefix tree selection method for diffusion-drafted speculative decoding. It identifies that existing diffusion-tree methods rank nodes by marginal probability, which can lead to verifying unreachable descendants, and instead converts diffusion marginals into path-conditioned acceptance estimates to select a compact prefix-closed subtree under a fixed verification budget. This is claimed to improve the acceptance-cost tradeoff, yielding up to 7.9x lossless end-to-end speedup over vanilla autoregressive decoding and outperforming DFlash and DDTree by 1.36x and 1.74x respectively, with experiments across diverse datasets and model families.
Significance. If the central empirical claims hold after addressing experimental reporting gaps, the work would provide a concrete improvement to speculative decoding pipelines that use diffusion drafters by better aligning subtree selection with the prefix-conditioned nature of verification. The identification of the marginal-vs-path-conditioned mismatch is a useful observation that could influence follow-on work on tree-based drafting.
major comments (3)
- [Abstract] Abstract and Experiments section: The performance numbers (7.9x, 1.36x, 1.74x) are stated without any description of experimental controls, number of runs, statistical significance tests, or safeguards against post-hoc dataset/model selection; this directly affects verifiability of the central speedup claim.
- [§3] §3 (method description): The conversion from diffusion marginals to path-conditioned acceptance estimates is introduced but no quantitative validation (e.g., calibration plots or error analysis) is provided showing that the estimates are sufficiently accurate to produce a strictly superior acceptance-cost tradeoff versus marginal ranking; if approximation error is comparable to the reported gains, the claimed improvement does not follow.
- [§4] §4 (experiments): No ablation or direct comparison is reported that isolates whether the budgeted subtree selection algorithm yields a measurably better operating point than simpler marginal-probability ranking (as in DDTree) once selection overhead is included; the 1.36–1.74× margins are therefore not yet shown to survive this check.
minor comments (2)
- [Abstract] The abstract refers to 'diverse datasets and model families' without listing them; adding an explicit enumeration in the experiments section would improve reproducibility.
- [§3] Notation for path-conditioned acceptance probability is introduced without a clear equation reference or comparison to the marginal probability used in prior work; a single displayed equation would clarify the distinction.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to improve experimental reporting and add requested analyses where feasible.
read point-by-point responses
-
Referee: [Abstract] Abstract and Experiments section: The performance numbers (7.9x, 1.36x, 1.74x) are stated without any description of experimental controls, number of runs, statistical significance tests, or safeguards against post-hoc dataset/model selection; this directly affects verifiability of the central speedup claim.
Authors: We agree that additional details are required for verifiability. In the revised manuscript we will expand the Experiments section with a full description of controls (fixed hardware, pre-specified model/dataset list, single forward-pass drafting), number of runs per configuration, and any variance observed. The reported figures are peak observed speedups across the tested settings; we will also report averages with standard deviations. revision: yes
-
Referee: [§3] §3 (method description): The conversion from diffusion marginals to path-conditioned acceptance estimates is introduced but no quantitative validation (e.g., calibration plots or error analysis) is provided showing that the estimates are sufficiently accurate to produce a strictly superior acceptance-cost tradeoff versus marginal ranking; if approximation error is comparable to the reported gains, the claimed improvement does not follow.
Authors: The conversion follows directly from conditioning the diffusion marginals on the verified prefix path and is therefore exact under the diffusion model's output distribution. We will add a short derivation in §3 clarifying this and include calibration plots in the appendix comparing estimated vs. observed acceptance rates on held-out sequences to quantify any residual discrepancy. revision: yes
-
Referee: [§4] §4 (experiments): No ablation or direct comparison is reported that isolates whether the budgeted subtree selection algorithm yields a measurably better operating point than simpler marginal-probability ranking (as in DDTree) once selection overhead is included; the 1.36–1.74× margins are therefore not yet shown to survive this check.
Authors: The end-to-end comparison against DDTree already incorporates selection overhead for both methods. To isolate the budgeted selection component, we will add an ablation in the revised §4 that runs marginal-probability ranking and TAPS under identical verification budgets, reporting acceptance length, total latency, and selection time separately. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper introduces TAPS as a novel algorithm that converts diffusion marginal probabilities into path-conditioned acceptance estimates and then selects a budgeted prefix-closed subtree. Performance results (speedups and comparisons to DFlash/DDTree) are presented as outcomes of empirical evaluation on diverse datasets and model families rather than quantities derived by construction from the same inputs. No equations, self-citations, or fitted-parameter renamings are visible in the provided text that would reduce the central claims to tautological inputs. The method is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[2]
Publications Manual , year = "1983", publisher =
1983
-
[3]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[4]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[5]
Dan Gusfield , title =. 1997
1997
-
[6]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[7]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[8]
Proceedings of the 40th International Conference on Machine Learning , pages =
Fast Inference from Transformers via Speculative Decoding , author =. Proceedings of the 40th International Conference on Machine Learning , pages =. 2023 , editor =
2023
-
[9]
Accelerating Large Language Model Decoding with Speculative Sampling
Accelerating Large Language Model Decoding with Speculative Sampling , author =. arXiv preprint arXiv:2302.01318 , year =. doi:10.48550/arXiv.2302.01318 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2302.01318
-
[10]
Miao, Xupeng and Oliaro, Gabriele and Zhang, Zhihao and Cheng, Xinhao and Wang, Zeyu and Zhang, Zhengxin and Wong, Rae Ying Yee and Zhu, Alan and Yang, Lijie and Shi, Xiaoxiang and Shi, Chunan and Chen, Zhuoming and Arfeen, Daiyaan and Abhyankar, Reyna and Jia, Zhihao , booktitle =. 2024 , publisher =. doi:10.1145/3620666.3651335 , url =
-
[11]
2024 , editor =
Li, Yuhui and Wei, Fangyun and Zhang, Chao and Zhang, Hongyang , booktitle =. 2024 , editor =
2024
-
[12]
2024 , doi =
Chen, Zhuoming and May, Avner and Svirschevski, Ruslan and Huang, Yuhsun and Ryabinin, Max and Jia, Zhihao and Chen, Beidi , booktitle =. 2024 , doi =
2024
-
[13]
Li, Yuhui and Wei, Fangyun and Zhang, Chao and Zhang, Hongyang , editor =. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , month = nov, year =. doi:10.18653/v1/2024.emnlp-main.422 , url =
-
[14]
2026 , doi =
Chen, Jian and Liang, Yesheng and Liu, Zhijian , journal =. 2026 , doi =
2026
-
[15]
Accelerating Speculative Decoding with Block Diffusion Draft Trees
Accelerating Speculative Decoding with Block Diffusion Draft Trees , author =. arXiv preprint arXiv:2604.12989 , year =. doi:10.48550/arXiv.2604.12989 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.12989
-
[16]
2026 , doi =
Liu, Fuliang and Li, Xue and Zhao, Ketai and Gao, Yinxi and Zhou, Ziyan and Zhang, Zhonghui and Wang, Zhibin and Dou, Wanchun and Zhong, Sheng and Tian, Chen , journal =. 2026 , doi =
2026
-
[17]
2025 , doi =
Cheng, Zicong and Yang, Guo-Wei and Li, Jia and Deng, Zhijie and Guo, Meng-Hao and Hu, Shi-Min , journal =. 2025 , doi =
2025
-
[18]
2025 , doi =
Xu, Chenkai and Jin, Yijie and Li, Jiajun and Tu, Yi and Long, Guoping and Tu, Dandan and Song, Mingcong and Si, Hongjie and Hou, Tianqi and Yan, Junchi and Deng, Zhijie , journal =. 2025 , doi =
2025
-
[19]
Fail Fast, Win Big: Rethinking the Drafting Strategy in Speculative Decoding via Diffusion
Pan, Rui and Chen, Zhuofu and Liu, Hongyi and Krishnamurthy, Arvind and Netravali, Ravi , journal =. Fail Fast, Win Big: Rethinking the Drafting Strategy in Speculative Decoding via Diffusion. 2025 , doi =
2025
-
[20]
Draft Model Knows When to Stop: Self-Verification Speculative Decoding for Long-Form Generation , author =. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , month = nov, year =. doi:10.18653/v1/2025.emnlp-main.844 , url =
-
[21]
and Chen, Deming and Dao, Tri , booktitle =
Cai, Tianle and Li, Yuhong and Geng, Zhengyang and Peng, Hongwu and Lee, Jason D. and Chen, Deming and Dao, Tri , booktitle =. 2024 , volume =
2024
-
[22]
2024 , doi =
Ankner, Zachary and Parthasarathy, Rishab and Nrusimha, Aniruddha and Rinard, Christopher and Ragan-Kelley, Jonathan and Brandon, William , journal =. 2024 , doi =
2024
-
[23]
arXiv preprint arXiv:2403.09919 , year =
Recurrent Drafter for Fast Speculative Decoding in Large Language Models , author =. arXiv preprint arXiv:2403.09919 , year =. doi:10.48550/arXiv.2403.09919 , url =
-
[24]
He, Zhenyu and Zhong, Zexuan and Cai, Tianle and Lee, Jason and He, Di , editor =. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , month = jun, year =. doi:10.18653/v1/2024.naacl-long.88 , url =
-
[25]
arXiv preprint arXiv:2405.04304 , year =
Dynamic Speculation Lookahead Accelerates Speculative Decoding of Large Language Models , author =. arXiv preprint arXiv:2405.04304 , year =. doi:10.48550/arXiv.2405.04304 , url =
-
[26]
Advances in Neural Information Processing Systems , volume =
Structured Denoising Diffusion Models in Discrete State-Spaces , author =. Advances in Neural Information Processing Systems , volume =. 2021 , url =
2021
-
[27]
, booktitle =
Li, Xiang Lisa and Thickstun, John and Gulrajani, Ishaan and Liang, Percy and Hashimoto, Tatsunori B. , booktitle =. Diffusion-. 2022 , url =
2022
-
[28]
Large Language Diffusion Models
Large Language Diffusion Models , author =. arXiv preprint arXiv:2502.09992 , year =. doi:10.48550/arXiv.2502.09992 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2502.09992
-
[29]
2025 , url =
Liu, Tianyu and Li, Yun and Lv, Qitan and Liu, Kai and Zhu, Jianchen and Hu, Winston and Sun, Xiao , booktitle =. 2025 , url =
2025
-
[30]
2024 , doi =
Agrawal, Sudhanshu and Jeon, Wonseok and Lee, Mingu , journal =. 2024 , doi =
2024
-
[31]
Distilling the Knowledge in a Neural Network
Distilling the Knowledge in a Neural Network , author =. arXiv preprint arXiv:1503.02531 , year =. doi:10.48550/arXiv.1503.02531 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1503.02531
-
[32]
Proceedings of the 22nd International Conference on Machine Learning , pages =
Learning to Rank using Gradient Descent , author =. Proceedings of the 22nd International Conference on Machine Learning , pages =. 2005 , publisher =. doi:10.1145/1102351.1102363 , url =
-
[33]
Kwon, Woosuk and Li, Zhuohan and Zhuang, Siyuan and Sheng, Ying and Zheng, Lianmin and Yu, Cody Hao and Gonzalez, Joseph E. and Zhang, Hao and Stoica, Ion , booktitle =. Efficient Memory Management for Large Language Model Serving with. 2023 , publisher =. doi:10.1145/3600006.3613165 , url =
-
[34]
and Barrett, Clark and Sheng, Ying , booktitle =
Zheng, Lianmin and Yin, Liangsheng and Xie, Zhiqiang and Sun, Chuyue and Huang, Jeff and Yu, Cody Hao and Cao, Shiyi and Kozyrakis, Christos and Stoica, Ion and Gonzalez, Joseph E. and Barrett, Clark and Sheng, Ying , booktitle =. 2024 , doi =
2024
-
[35]
2025 , howpublished =
2025
-
[36]
Training Verifiers to Solve Math Word Problems
Training Verifiers to Solve Math Word Problems , author =. arXiv preprint arXiv:2110.14168 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[37]
International Conference on Learning Representations , year =
Let's Verify Step by Step , author =. International Conference on Learning Representations , year =
-
[38]
Evaluating Large Language Models Trained on Code
Evaluating Large Language Models Trained on Code , author =. arXiv preprint arXiv:2107.03374 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[39]
2025 , url =
Jain, Naman and Han, King and Gu, Alex and Li, Wen-Ding and Yan, Fanjia and Zhang, Tianjun and Wang, Sida and Solar-Lezama, Armando and Sen, Koushik and Stoica, Ion , booktitle =. 2025 , url =
2025
-
[40]
Program Synthesis with Large Language Models
Program Synthesis with Large Language Models , author =. arXiv preprint arXiv:2108.07732 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[41]
and Zhang, Hao and Gonzalez, Joseph E
Zheng, Lianmin and Chiang, Wei-Lin and Sheng, Ying and Zhuang, Siyuan and Wu, Zhanghao and Zhuang, Yonghao and Lin, Zi and Li, Zhuohan and Li, Dacheng and Xing, Eric P. and Zhang, Hao and Gonzalez, Joseph E. and Stoica, Ion , booktitle =. Judging. 2023 , url =
2023
-
[42]
2025 , doi =
Yang, An and Li, Anfeng and Yang, Baosong and Zhang, Beichen and Hui, Binyuan and Zheng, Bo and Yu, Bowen and Gao, Chang and Huang, Chengen and Lv, Chenxu and Zheng, Chujie and Liu, Dayiheng and Zhou, Fan and Huang, Fei and Hu, Feng and Ge, Hao and Wei, Haoran and Lin, Huan and Tang, Jialong and Yang, Jian and Tu, Jianhong and Zhang, Jianwei and Yang, Jia...
2025
-
[43]
Grattafiori, Aaron and others , journal =. The. 2024 , doi =
2024
-
[44]
2025 , url =
Li, Yuhui and Wei, Fangyun and Zhang, Chao and Zhang, Hongyang , booktitle =. 2025 , url =
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.