Learning to Retrieve: Dual-Level Long-Term Memory for Text-to-SQL Agents
Pith reviewed 2026-06-28 19:03 UTC · model grok-4.3
The pith
MERIT learns dual-level retrieval policies to reuse past experiences in multi-turn text-to-SQL tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
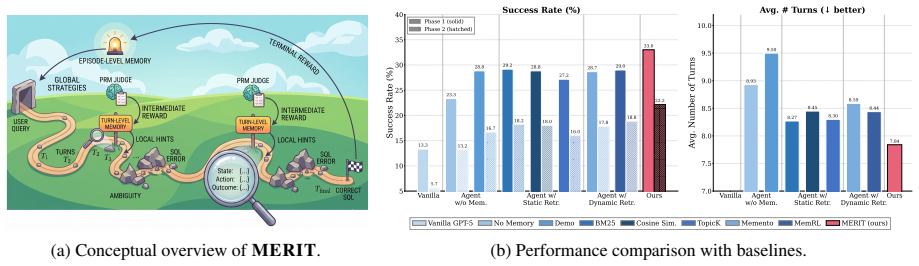
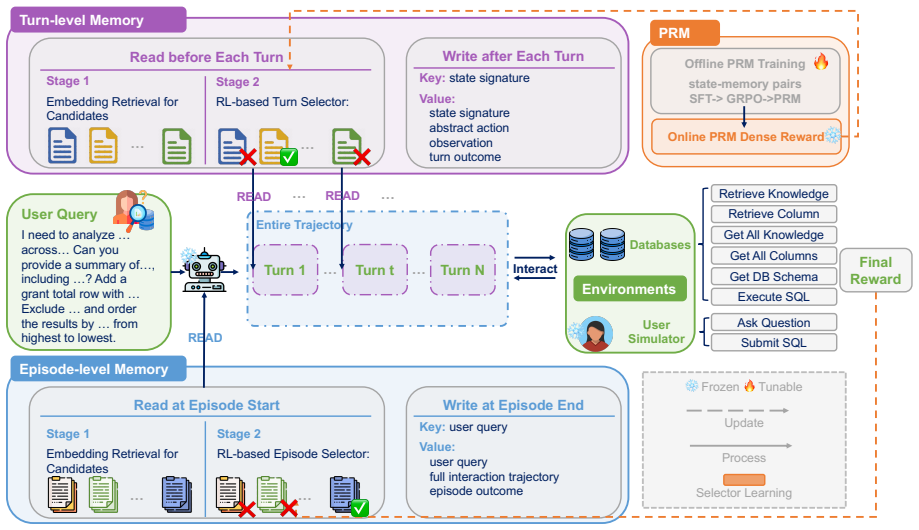
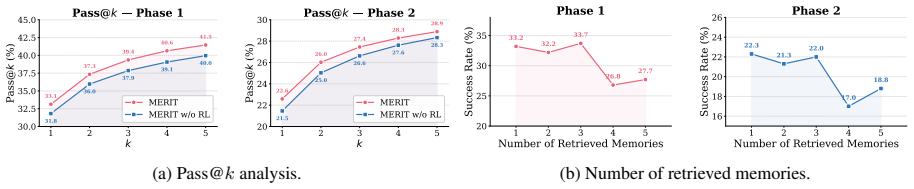
MERIT maintains episode-level memory for global strategic guidance and turn-level memory for local decision support, with both levels using learned retrieval policies optimized via reinforcement learning. A lightweight Process Reward Model supplies dense proxy rewards to train the turn-level policy despite sparse intermediate supervision. On BIRD-Interact, this yields higher success rates and fewer interaction turns than baselines, with positive transfer to Spider2-Snow.
What carries the argument
Dual-level memory retrieval with reinforcement learning policies and a Process Reward Model for proxy rewards.
If this is right
- Agents can reuse memories useful for initial planning separately from those for local execution.
- RL-optimized retrieval improves over fixed similarity heuristics.
- Cross-benchmark transfer is possible without specific tuning.
- Multi-horizon retrieval reduces average interaction turns while increasing success.
Where Pith is reading between the lines
- Similar dual-level memory could apply to other interactive agent tasks beyond text-to-SQL.
- The Process Reward Model approach might generalize to other RL settings with sparse rewards.
- Testing on more diverse databases could reveal limits of the transfer.
Load-bearing premise
The lightweight Process Reward Model provides accurate enough dense proxy rewards for training the turn-level retrieval policy without direct intermediate supervision.
What would settle it
If removing the Process Reward Model or using only sparse final rewards leads to no improvement or worse performance than single-level dynamic retrieval on BIRD-Interact, the central claim would be falsified.
Figures
read the original abstract
Interactive text-to-SQL agents solve database tasks through multi-turn interactions involving schema exploration, query execution, feedback interpretation, and decision revision. Long-term memory helps agents reuse past experiences, but existing retrieval methods remain limited. Static methods rely on fixed similarity heuristics that do not optimize downstream utility, while dynamic methods often learn from sparse final outcomes and retrieve memories at a single decision horizon. This is insufficient when memory usefulness changes across interaction stages, since memories useful for initial planning may differ from those needed for local, state-conditioned execution. We propose MERIT, a dynamic multi-horizon memory retrieval framework. MERIT maintains episode-level memory for global strategic guidance and turn-level memory for local decision support. Both levels use learned retrieval policies optimized with reinforcement learning. To train turn-level retrieval despite limited intermediate supervision, MERIT uses a lightweight Process Reward Model to provide dense proxy rewards for local memory selection. Experiments on BIRD-Interact show that MERIT outperforms no-memory, static-retrieval, and dynamic-retrieval baselines in success rate while reducing average interaction turns. Transfer results on Spider2-Snow further show positive cross-benchmark transfer without benchmark-specific tuning. These results suggest that multi-horizon retrieval improves experience reuse in interactive text-to-SQL agents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes MERIT, a dual-level long-term memory framework for interactive text-to-SQL agents. It maintains episode-level memory for global strategic guidance and turn-level memory for local, state-conditioned decisions. Both levels use reinforcement learning to optimize retrieval policies; a lightweight Process Reward Model supplies dense proxy rewards to train the turn-level policy in the absence of intermediate supervision. Experiments claim that MERIT outperforms no-memory, static-retrieval, and dynamic-retrieval baselines on BIRD-Interact (higher success rate, fewer turns) and shows positive transfer to Spider2-Snow without benchmark-specific tuning.
Significance. If the empirical gains are reproducible and the Process Reward Model proxies prove sufficiently accurate, the multi-horizon retrieval approach would advance experience reuse in multi-turn agents beyond single-horizon or heuristic methods, with potential impact on interactive database interfaces.
major comments (1)
- [Process Reward Model and turn-level RL training] Abstract and the section describing the turn-level policy (likely §3.2 or equivalent): the central claim that the RL-trained local retrieval policy improves over dynamic-retrieval baselines rests on the assumption that the lightweight Process Reward Model supplies sufficiently accurate dense proxy rewards correlated with downstream utility. No training data, architecture, accuracy metrics, or ablation results for this PRM are provided, leaving open the possibility that noisy proxies yield no genuine improvement.
minor comments (1)
- [Abstract] The abstract states outperformance and transfer results but supplies no numerical values, error bars, baseline details, or dataset sizes, reducing immediate verifiability of the strongest_claim.
Simulated Author's Rebuttal
We thank the referee for the constructive comment on the Process Reward Model. We agree that additional details are required to support the claims about the turn-level retrieval policy.
read point-by-point responses
-
Referee: [Process Reward Model and turn-level RL training] Abstract and the section describing the turn-level policy (likely §3.2 or equivalent): the central claim that the RL-trained local retrieval policy improves over dynamic-retrieval baselines rests on the assumption that the lightweight Process Reward Model supplies sufficiently accurate dense proxy rewards correlated with downstream utility. No training data, architecture, accuracy metrics, or ablation results for this PRM are provided, leaving open the possibility that noisy proxies yield no genuine improvement.
Authors: We agree that the submitted manuscript does not provide the requested details on the Process Reward Model (PRM). The description mentions its use for dense proxy rewards but omits training data, architecture, accuracy metrics, and ablations, which weakens support for the claim of improvement over dynamic-retrieval baselines. In the revised version we will add a dedicated subsection (in §3.2 or an appendix) covering: the PRM architecture and training procedure, the dataset used to train it, quantitative accuracy metrics (including correlation with downstream task success), and ablation results isolating the PRM's contribution to turn-level policy performance. These additions will allow direct evaluation of whether the proxy rewards are sufficiently accurate and correlated with utility. revision: yes
Circularity Check
No circularity: empirical gains validated against external baselines without reduction to self-defined quantities
full rationale
The paper presents MERIT as an empirical framework using dual-level memory with RL-trained retrieval policies and a lightweight PRM for proxy rewards in the absence of intermediate supervision. Reported success-rate gains and reduced interaction turns are measured via direct comparisons to no-memory, static-retrieval, and dynamic-retrieval baselines on BIRD-Interact plus cross-benchmark transfer on Spider2-Snow. No equations, derivations, or self-citations are shown that would make performance metrics equivalent to fitted parameters or prior author results by construction. The central claims rest on external experimental outcomes rather than internal redefinitions.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Reinforcement learning can learn retrieval policies that optimize downstream task utility rather than surface similarity.
- domain assumption A lightweight process reward model can approximate intermediate rewards for local memory selection when only final outcomes are available.
invented entities (1)
-
MERIT dual-level memory framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
InFindings of the Association for Computational Linguistics: EMNLP 2020, pages 4870–4888, Online
Bridging textual and tabular data for cross- domain text-to-SQL semantic parsing. InFindings of the Association for Computational Linguistics: EMNLP 2020, pages 4870–4888, Online. Association for Computational Linguistics. Jiaqi Liu, Yaofeng Su, Peng Xia, Siwei Han, Zeyu Zheng, Cihang Xie, Mingyu Ding, and Huaxiu Yao
2020
-
[2]
SimpleMem: Efficient Lifelong Memory for LLM Agents
Simplemem: Efficient lifelong memory for llm agents.arXiv preprint arXiv:2601.02553. Junru Lu, Siyu An, Mingbao Lin, Gabriele Pergola, Yu- lan He, Di Yin, Xing Sun, and Yunsheng Wu. 2023. Memochat: Tuning llms to use memos for consis- tent long-range open-domain conversation.arXiv preprint arXiv:2308.08239. Adyasha Maharana, Dong-Ho Lee, Sergey Tulyakov, ...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), pages 13851– 13870
Evaluating very long-term conversational memory of llm agents. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), pages 13851– 13870. Mahmoud Mohammadi, Yipeng Li, Jane Lo, and Wendy Yip. 2025. Evaluation and benchmarking of llm agents: A survey. InProceedings of the 31st ACM SIGKDD Conferen...
2025
-
[4]
Meminsight: Autonomous memory augmen- tation for llm agents. InProceedings of the 2025 Conference on Empirical Methods in Natural Lan- guage Processing, pages 33124–33140. Zhihui Shao, Shubin Cai, Rongsheng Lin, and Zhong Ming. 2025. Enhancing text-to-sql with question classification and multi-agent collaboration. InFind- ings of the Association for Compu...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Qwen3 technical report.arXiv preprint arXiv:2505.09388. Tao Yu, Zifan Li, Zilin Zhang, Rui Zhang, and Dragomir Radev. 2018. TypeSQL: Knowledge-based type- aware neural text-to-SQL generation. InProceedings of the 2018 Conference of the North American Chap- ter of the Association for Computational Linguistics: Human Language Technologies, V olume 2 (Short ...
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[6]
Seq2SQL: Generating Structured Queries from Natural Language using Reinforcement Learning
Seq2sql: Generating structured queries from natural language using reinforcement learning.arXiv preprint arXiv:1709.00103. Huichi Zhou, Yihang Chen, Siyuan Guo, Xue Yan, Kin Hei Lee, Zihan Wang, Ka Yiu Lee, Guchun Zhang, Kun Shao, Linyi Yang, and 1 others. 2025. Memento: Fine-tuning llm agents without fine-tuning llms.arXiv preprint arXiv:2508.16153. 11 A...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
The user will test your SQL correctness and give you feedback
Interact with the user to ask clarifying questions to understand their request better or submit the SQL query to the user. The user will test your SQL correctness and give you feedback
-
[8]
Observation
Interact with the {setting} environment (postgresql db, column meaning file, external knowledge, and so on) to explore the database and get db relevant information. - Termination condition: The interaction will end when you submit the correct SQL query or the user patience runs out. - Cost of your action: each your action will cost a certain amount of use...
-
[9]
**Success Strategies** - short bullet points (2-4) summarizing what the agent did right
-
[10]
**Failure Reasons** - short bullet points (2-4) describing what went wrong
-
[11]
gap_key":
**Key Insights** - a concise paragraph that integrates: - Whether the query was **read-only** or **CRUD**. - Whether it was **easy** or **difficult**. - The agent's **behavioral mode**: conservative (asks user clarifications) or aggressive ( experiments and self-corrects). - Guidance for future similar queries: when to clarify vs. when to explore. Additio...
-
[12]
- current_query_context: the query plus any clarifications so far
A CURRENT agent state (called CURRENT_STATE), with fields like: - initial_query: the original user question. - current_query_context: the query plus any clarifications so far. - prev_action: the last tool the agent used. - prev_observation: the last observation from the environment or user
-
[13]
TOOL:EXECUTE SQL:[...]
ONE step-wise memory from a past episode (called CANDIDATE_MEMORY_STEP), with: - trigger_state_raw: a compact signature of the state in which that past step occurred. - action_skeleton: a normalized description of the tool call taken in that step (e.g., "TOOL:EXECUTE SQL:[...]", "TOOL:ASK [CLARIFICATION]", "TOOL:GET_SCHEMA"). - action_result_raw: a short ...
-
[14]
- 0 = completely different situation; the memory comes from an unrelated context
state_match - How similar is the CURRENT_STATE to the trigger_state_raw of this memory? - Consider query intent, ambiguity, and the previous action/observation. - 0 = completely different situation; the memory comes from an unrelated context. - 5 = almost the same state; the memory was recorded in a very similar situation
-
[15]
- 0 = the memory provides essentially no actionable guidance here
actionability_value - If we SHOW this memory to the agent, how strongly does it provide useful behavioral guidance (either as something to imitate, or as something to avoid)? - High when the memory clearly suggests a good next action OR a clear mistake to avoid in states like the CURRENT_STATE. - 0 = the memory provides essentially no actionable guidance ...
-
[16]
- 5 = broadly applicable pattern for many similar Text-to-SQL situations
pattern_generalizability - How general is the pattern implied by this memory (either positive or negative)? - 0 = extremely specific to a single query/dataset/id; unlikely to transfer. - 5 = broadly applicable pattern for many similar Text-to-SQL situations
-
[17]
- 5 = clear and trustworthy signal
outcome_reliability - How reliable is this memory as evidence for what to do or avoid? - Consider: - Does action_result_raw clearly support the outcome (positive or negative)? - Does outcome_type match what actually happened? - 0 = noisy, ambiguous, or unreliable. - 5 = clear and trustworthy signal
-
[18]
tip text
clarity_for_agent - If we compress this step into 1-3 lines of "tip text" for the agent, how easy is it for the agent to understand what behavior is being recommended or avoided? - 0 = very hard to explain; cryptic or confusing. - 5 = crystal clear guidance or warning
-
[19]
- 0 = extremely uncertain; the scores above are mostly guesses
confidence_in_assessment - How confident are you in your own judgments for this memory, especially for state_match, actionability_value, and overall_utility, given the available information? - Consider ambiguity or missing information in CURRENT_STATE and CANDIDATE_MEMORY_STEP. - 0 = extremely uncertain; the scores above are mostly guesses. - 5 = very con...
-
[20]
do NOT repeat this mistake
overall_utility - Your overall judgment (0-5) of how valuable it is to retrieve THIS memory for THIS CURRENT_STATE. - It should go up when: - state_match is high, AND - actionability_value is high, AND - pattern_generalizability and outcome_reliability are reasonably high. - 0 = do not retrieve; essentially useless or risky. - 5 = very strong candidate to...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.