How Neural Losses Shape VAE Latents
Pith reviewed 2026-06-28 18:52 UTC · model grok-4.3
The pith
Augmenting VAE reconstruction with perceptual and adversarial losses reduces information stored in the latent representations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
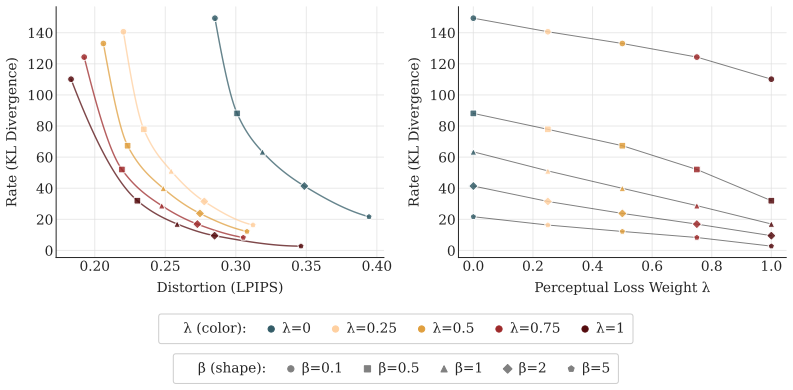
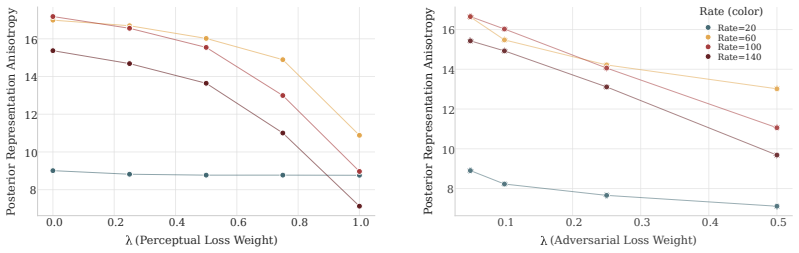
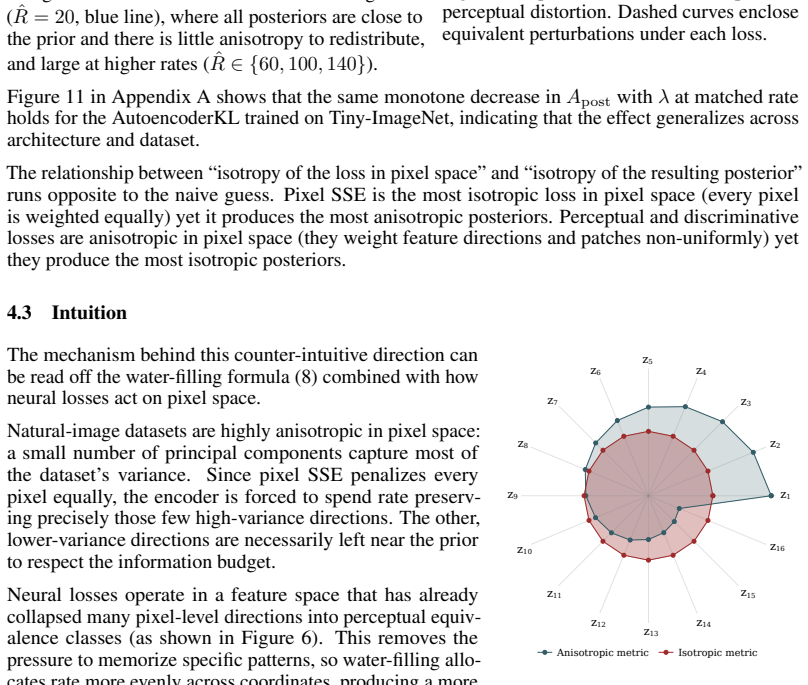
Augmenting pointwise reconstruction with neural terms reduces the amount of information stored in the latent representations. Neural reconstruction losses systematically change the geometry of the latent space: they make representations more isotropic and distribute uncertainty more evenly across latent dimensions, producing different posterior variance profiles. The rate-distortion tradeoff is not a comprehensive lens to understand VAE behavior.
What carries the argument
the rate-distortion optimization problem, reshaped by the choice of distortion metric from pointwise to neural reconstruction losses
If this is right
- Neural losses produce different posterior variance profiles than pointwise reconstruction.
- The standard rate-distortion lens fails to capture how distortion metric choice affects learned representations.
- A mechanistic investigation of how each distortion metric reshapes the optimization is required instead.
- Latent space properties can be steered by loss choice without changing the model architecture.
Where Pith is reading between the lines
- This suggests that practitioners could select losses to achieve desired latent properties like isotropy for downstream tasks such as interpolation.
- Similar effects may appear in other generative models that combine reconstruction with perceptual objectives.
- The findings motivate experiments that isolate the contribution of each neural loss term to the observed geometry changes.
Load-bearing premise
The observed changes in information content and latent geometry are caused by the neural losses altering the rate-distortion problem rather than by optimizer dynamics, regularization schedules, or other training details.
What would settle it
Training identical VAE architectures with neural losses but under controlled optimizer and schedule conditions that match the pointwise baseline, then measuring whether the reduction in latent information and increase in isotropy still occur.
Figures
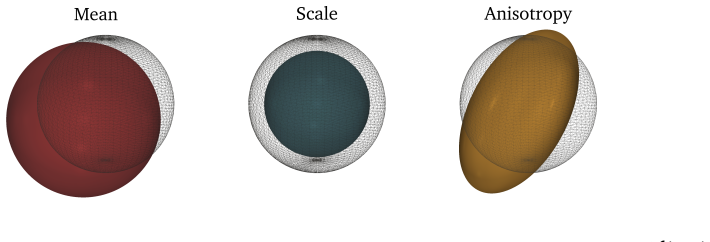

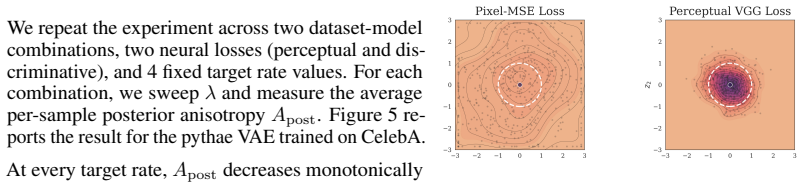
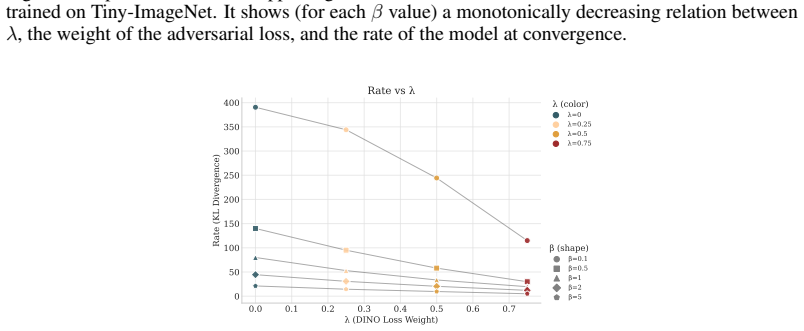
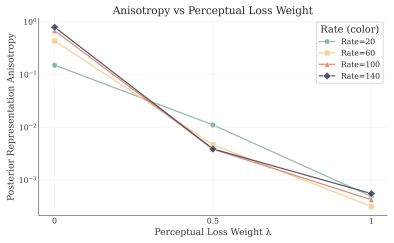

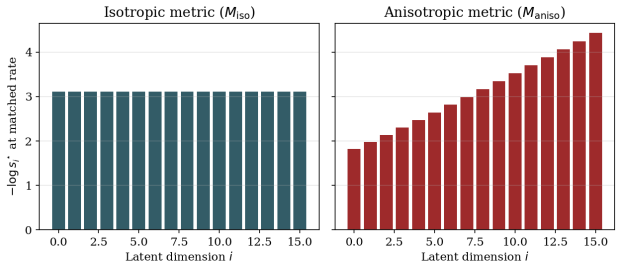
read the original abstract
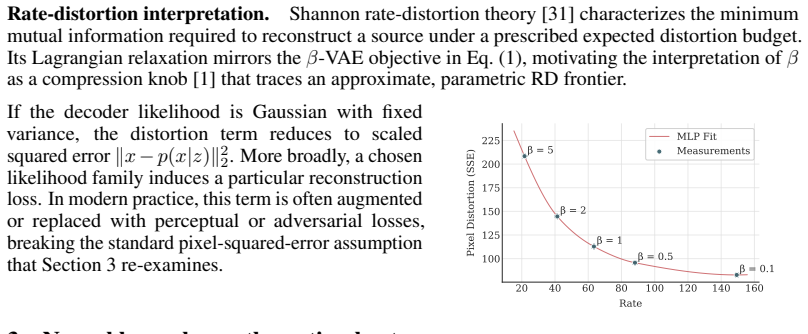
Modern VAEs are rarely trained with the pointwise likelihood implied by the standard $\beta$-VAE objective. In practice, pointwise reconstruction is often combined with perceptual and adversarial losses, despite a lack of understanding of how this changes the latent dynamics of the model. We show that the choice of reconstruction loss reshapes the rate-distortion problem itself, altering both the information content and the geometry of the learned latent space in ways that may be invisible from reconstructions alone. First, we prove and verify empirically that augmenting pointwise reconstruction with neural terms, such as perceptual and adversarial objectives, reduces the amount of information stored in the latent representations. Second, we show that neural reconstruction losses systematically change the geometry of the latent space: they make representations more isotropic and distribute uncertainty more evenly across latent dimensions, producing different posterior variance profiles. These findings highlight how the rate-distortion tradeoff is not a comprehensive lens to understand the behavior of VAEs, and we propose a more mechanistic approach to investigate how the choice of a distortion metric reshapes the optimization problem.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that replacing or augmenting pointwise reconstruction in VAEs with neural losses (perceptual, adversarial) reshapes the underlying rate-distortion objective. It proves that such augmentation reduces the mutual information stored in the latent variables and empirically demonstrates that the resulting posteriors become more isotropic with flatter variance profiles across dimensions. The work concludes that the standard rate-distortion lens is insufficient and advocates a mechanistic view of how the distortion metric alters optimization.
Significance. If the theoretical reduction in latent information and the geometric effects are robustly isolated from training artifacts, the result would be significant: it supplies both a proof and concrete empirical signatures (isotropy, variance profiles) showing that widely used perceptual/adversarial objectives change VAE latents in ways invisible to reconstruction metrics alone. This would motivate new analysis tools beyond β-VAE theory and affect how reconstruction losses are chosen in practice.
major comments (2)
- [Empirical verification sections] The central empirical claim—that observed isotropy and even uncertainty distribution arise from rate-distortion reshaping rather than optimizer dynamics, regularization schedules, or implementation details—lacks the necessary isolation experiments. No description of matched hyperparameter sweeps, fixed-optimizer ablations, or controlled training procedures is referenced, leaving open the possibility that the geometry changes are artifacts of those factors rather than the modified objective.
- [Theoretical proof section] The proof that neural augmentation of the distortion term reduces latent mutual information is load-bearing for the first claim. Without the explicit derivation steps, assumptions on the form of the neural loss, and verification that the reduction holds independently of the variational family or optimization path, it is impossible to assess whether the result is parameter-free or relies on implicit regularizers introduced by the neural terms.
minor comments (1)
- Notation for the augmented distortion term and the precise definition of 'neural reconstruction loss' should be introduced early and used consistently to avoid ambiguity between perceptual, adversarial, and other neural objectives.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important areas for strengthening the empirical isolation and theoretical presentation. We address each major comment below and will incorporate revisions to improve clarity and robustness.
read point-by-point responses
-
Referee: [Empirical verification sections] The central empirical claim—that observed isotropy and even uncertainty distribution arise from rate-distortion reshaping rather than optimizer dynamics, regularization schedules, or implementation details—lacks the necessary isolation experiments. No description of matched hyperparameter sweeps, fixed-optimizer ablations, or controlled training procedures is referenced, leaving open the possibility that the geometry changes are artifacts of those factors rather than the modified objective.
Authors: We agree that additional controls are needed to more rigorously isolate the contribution of the modified distortion metric. In the revised version, we will add a dedicated subsection detailing matched hyperparameter sweeps (e.g., identical learning rates, batch sizes, and optimizer settings across loss variants), fixed-optimizer ablations, and explicit descriptions of the controlled training procedures used. These will demonstrate that the isotropy and variance profile changes persist under matched conditions. revision: yes
-
Referee: [Theoretical proof section] The proof that neural augmentation of the distortion term reduces latent mutual information is load-bearing for the first claim. Without the explicit derivation steps, assumptions on the form of the neural loss, and verification that the reduction holds independently of the variational family or optimization path, it is impossible to assess whether the result is parameter-free or relies on implicit regularizers introduced by the neural terms.
Authors: We acknowledge that the proof section would benefit from greater explicitness. The manuscript currently presents a high-level argument; the revision will include the full step-by-step derivation, state the assumptions on the neural loss (specifically that it depends on the reconstruction output but introduces no direct latent dependence beyond the decoder), and add a short verification argument showing the mutual information reduction holds under the variational bound independently of the optimization trajectory. revision: yes
Circularity Check
No significant circularity; claims derived from modified objective and independent verification
full rationale
The paper derives its central results from the standard VAE rate-distortion objective after augmenting the distortion term with neural losses, proving reduced mutual information directly from the modified objective and verifying geometry changes empirically. No load-bearing steps reduce by construction to fitted parameters, self-citations, or renamed inputs; the proof and observations are self-contained against standard VAE theory without circular reductions.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math The standard beta-VAE ELBO and rate-distortion formulation applies as the baseline for comparison.
Reference graph
Works this paper leans on
-
[1]
Alemi, Ben Poole, Ian Fischer, Joshua V
Alexander A. Alemi, Ben Poole, Ian Fischer, Joshua V . Dillon, Rif A. Saurous, and Kevin Murphy. Fixing a broken ELBO. In Jennifer G. Dy and Andreas Krause, editors,Proceedings of the 35th International Conference on Machine Learning, ICML 2018, Stockholmsmässan, Stockholm, Sweden, July 10-15, 2018, volume 80 ofProceedings of Machine Learning Research, pa...
2018
-
[2]
Zhang, Michael Ruan, Eric Wang, So Hasegawa, Jimmy Ba, and Roger Grosse
Juhan Bae, Michael R. Zhang, Michael Ruan, Eric Wang, So Hasegawa, Jimmy Ba, and Roger Grosse. Multi-rate vae: Train once, get the full rate-distortion curve, 2023. URL https://arxiv.org/abs/2212.03905
-
[3]
The perception-distortion tradeoff
Yochai Blau and Tomer Michaeli. The perception-distortion tradeoff. In2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6228–6237, 2018. doi: 10. 1109/CVPR.2018.00652
-
[4]
Rethinking lossy compression: The rate-distortion-perception tradeoff, 2019
Yochai Blau and Tomer Michaeli. Rethinking lossy compression: The rate-distortion-perception tradeoff, 2019. URLhttps://arxiv.org/abs/1901.07821
-
[5]
Understanding disentangling in $\beta$-VAE
Christopher P. Burgess, Irina Higgins, Arka Pal, Loic Matthey, Nick Watters, Guillaume Desjardins, and Alexander Lerchner. Understanding disentangling in β-vae, 2018. URL https://arxiv.org/abs/1804.03599
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[6]
Pythae: Unifying generative autoencoders in python - a benchmarking use case
Clément Chadebec, Louis Vincent, and Stephanie Allassonniere. Pythae: Unifying generative autoencoders in python - a benchmarking use case. In S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, editors,Advances in Neural Information Processing Systems, volume 35, pages 21575–21589. Curran Associates, Inc., 2022
2022
-
[7]
Masked autoencoders are effective tokenizers for diffusion models
Hao Chen, Yujin Han, Fangyi Chen, Xiang Li, Yidong Wang, Jindong Wang, Ze Wang, Zicheng Liu, Difan Zou, and Bhiksha Raj. Masked autoencoders are effective tokenizers for diffusion models. InForty-second International Conference on Machine Learning, 2025
2025
-
[8]
Ricky T. Q. Chen, Xuechen Li, Roger Grosse, and David Duvenaud. Isolating sources of disentanglement in variational autoencoders, 2019. URL https://arxiv.org/abs/1802. 04942
2019
-
[9]
Xi Chen, Diederik P. Kingma, Tim Salimans, Yan Duan, Prafulla Dhariwal, John Schulman, Ilya Sutskever, and Pieter Abbeel. Variational lossy autoencoder, 2017. URL https://arxiv. org/abs/1611.02731
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[10]
Wiley, 2nd editio edition, 2009
Thomas Cover and Joy Thomas.Elements of Information Theory. Wiley, 2nd editio edition, 2009
2009
-
[11]
High Fidelity Neural Audio Compression
Alexandre Défossez, Jade Copet, Gabriel Synnaeve, and Yossi Adi. High fidelity neural audio compression.arXiv preprint arXiv:2210.13438, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[12]
Imagenet: A large- scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large- scale hierarchical image database. In2009 IEEE conference on computer vision and pattern recognition, pages 248–255. IEEE, 2009
2009
-
[13]
Generative modelling in latent space, 2025
Sander Dieleman. Generative modelling in latent space, 2025. URL https://sander.ai/ 2025/04/15/latents.html
2025
-
[14]
Leo D’Amato, Gian Luca Lancia, and Giovanni Pezzulo. The geometry of efficient codes: How rate-distortion trade-offs distort the latent representations of generative models.PLOS Computational Biology, 21(5):1–30, 05 2025. doi: 10.1371/journal.pcbi.1012952. URL https://doi.org/10.1371/journal.pcbi.1012952
-
[15]
beta-V AE: Learning basic visual concepts with a constrained variational framework
Irina Higgins, Loic Matthey, Arka Pal, Christopher Burgess, Xavier Glorot, Matthew Botvinick, Shakir Mohamed, and Alexander Lerchner. beta-V AE: Learning basic visual concepts with a constrained variational framework. InInternational Conference on Learning Representations,
-
[16]
URLhttps://openreview.net/forum?id=Sy2fzU9gl. 10
-
[17]
Xianxu Hou, Linlin Shen, Ke Sun, and Guoping Qiu. Deep feature consistent variational autoencoder. In2017 IEEE Winter Conference on Applications of Computer Vision (WACV), pages 1133–1141, 2017. doi: 10.1109/W ACV .2017.131
work page doi:10.1109/w 2017
-
[18]
Phillip Isola, Jun-Yan Zhu, Tinghui Zhou, and Alexei A. Efros. Image-to-image translation with conditional adversarial networks, 2018. URLhttps://arxiv.org/abs/1611.07004
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[19]
Perceptual Losses for Real-Time Style Transfer and Super-Resolution
Justin Johnson, Alexandre Alahi, and Li Fei-Fei. Perceptual losses for real-time style transfer and super-resolution, 2016. URLhttps://arxiv.org/abs/1603.08155
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[20]
Auto-Encoding Variational Bayes
Diederik P. Kingma and Max Welling. Auto-encoding variational bayes. In Yoshua Bengio and Yann LeCun, editors,2nd International Conference on Learning Representations, ICLR 2014, Banff, AB, Canada, April 14-16, 2014, Conference Track Proceedings, 2014. URL http://arxiv.org/abs/1312.6114
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[21]
Eq-vae: Equivariance regularized latent space for improved generative image modeling, 2025
Theodoros Kouzelis, Ioannis Kakogeorgiou, Spyros Gidaris, and Nikos Komodakis. Eq-vae: Equivariance regularized latent space for improved generative image modeling, 2025. URL https://arxiv.org/abs/2502.09509
-
[22]
V ARIATIONAL INFERENCE OF DISENTANGLED LATENT CONCEPTS FROM UNLABELED OBSERV ATIONS
Abhishek Kumar, Prasanna Sattigeri, and Avinash Balakrishnan. V ARIATIONAL INFERENCE OF DISENTANGLED LATENT CONCEPTS FROM UNLABELED OBSERV ATIONS. In International Conference on Learning Representations, 2018. URL https://openreview. net/forum?id=H1kG7GZAW
2018
-
[23]
Autoencoding beyond pixels using a learned similarity metric
Anders Boesen Lindbo Larsen, Søren Kaae Sønderby, Hugo Larochelle, and Ole Winther. Autoencoding beyond pixels using a learned similarity metric. In Maria-Florina Balcan and Kilian Q. Weinberger, editors,Proceedings of the 33nd International Conference on Machine Learning, ICML 2016, New York City, NY, USA, June 19-24, 2016, volume 48 ofJMLR Workshop and ...
2016
-
[24]
Repa-e: Unlocking vae for end-to-end tuning of latent diffusion transformers
Xingjian Leng, Jaskirat Singh, Yunzhong Hou, Zhenchang Xing, Saining Xie, and Liang Zheng. Repa-e: Unlocking vae for end-to-end tuning of latent diffusion transformers. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 18262–18272, 2025
2025
-
[25]
Deep learning face attributes in the wild
Ziwei Liu, Ping Luo, Xiaogang Wang, and Xiaoou Tang. Deep learning face attributes in the wild. InProceedings of International Conference on Computer Vision (ICCV), December 2015
2015
-
[26]
Disentangling Disentanglement in Variational Autoencoders
Emile Mathieu, Tom Rainforth, N. Siddharth, and Yee Whye Teh. Disentangling disentangle- ment in variational autoencoders, 2019. URLhttps://arxiv.org/abs/1812.02833
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[27]
High-fidelity generative image compression, 2020
Fabian Mentzer, George Toderici, Michael Tschannen, and Eirikur Agustsson. High-fidelity generative image compression, 2020. URLhttps://arxiv.org/abs/2006.09965
-
[28]
Spectral Normalization for Generative Adversarial Networks
Takeru Miyato, Toshiki Kataoka, Masanori Koyama, and Yuichi Yoshida. Spectral normalization for generative adversarial networks, 2018. URLhttps://arxiv.org/abs/1802.05957
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[29]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision.arXiv preprint arXiv:2304.07193, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[30]
Danilo Jimenez Rezende and Fabio Viola. Taming vaes.CoRR, abs/1810.00597, 2018. URL http://arxiv.org/abs/1810.00597
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[31]
High-Resolution Image Synthesis with Latent Diffusion Models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High- resolution image synthesis with latent diffusion models, 2022. URL https://arxiv.org/ abs/2112.10752
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[32]
C. E. Shannon. A mathematical theory of communication.The Bell System Technical Journal, 27(3):379–423, 1948. doi: 10.1002/j.1538-7305.1948.tb01338.x
-
[33]
Improving the diffusability of autoencoders, 2025
Ivan Skorokhodov, Sharath Girish, Benran Hu, Willi Menapace, Yanyu Li, Rameen Abdal, Sergey Tulyakov, and Aliaksandr Siarohin. Improving the diffusability of autoencoders, 2025. URLhttps://arxiv.org/abs/2502.14831. 11
-
[34]
Diffusers: State-of-the-art diffusion models
Patrick von Platen, Suraj Patil, Anton Lozhkov, Pedro Cuenca, Nathan Lambert, Kashif Rasul, Mishig Davaadorj, Dhruv Nair, Sayak Paul, William Berman, Yiyi Xu, Steven Liu, and Thomas Wolf. Diffusers: State-of-the-art diffusion models. https://github.com/huggingface/ diffusers, 2022
2022
-
[35]
Reconstruction vs
Jingfeng Yao, Bin Yang, and Xinggang Wang. Reconstruction vs. generation: Taming optimiza- tion dilemma in latent diffusion models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 15703–15712, 2025
2025
-
[36]
Representation Alignment for Generation: Training Diffusion Transformers Is Easier Than You Think
Sihyun Yu, Sangkyung Kwak, Huiwon Jang, Jongheon Jeong, Jonathan Huang, Jinwoo Shin, and Saining Xie. Representation alignment for generation: Training diffusion transformers is easier than you think.arXiv preprint arXiv:2410.06940, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[37]
The Unreasonable Effectiveness of Deep Features as a Perceptual Metric
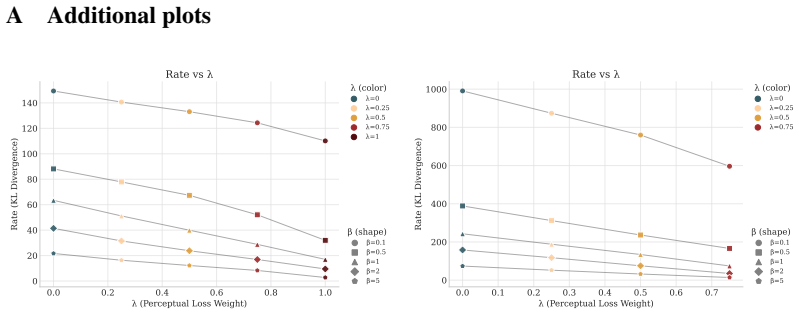
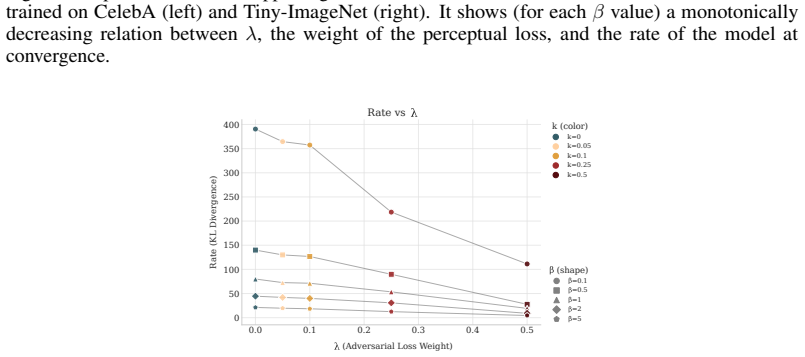
Richard Zhang, Phillip Isola, Alexei A. Efros, Eli Shechtman, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric, 2018. URL https: //arxiv.org/abs/1801.03924. 12 A Additional plots 0.0 0.2 0.4 0.6 0.8 1.0 (Perceptual Loss Weight) 0 20 40 60 80 100 120 140Rate (KL Divergence) Rate vs (color) =0 =0.25 =0.5 =0.75 =1 (shap...
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[38]
variance- KL budget
Multiply by wℓ and sum over ℓ∈ L. This pointwise domination implies that any reconstruction rule meeting a pixel-MSE budget also meets an appropriately rescaled feature-matching budget. The corresponding RD ordering is an immediate application of Theorem 11. Corollary 28(RD ordering for feature matching vs. pixel MSE).Under Assumption 26, for all ∆≥0, RdF...
-
[39]
ForZ∼ N(µ,diag(s)), E[dM(x, Z)] = (x−W µ) ⊤G(x−W µ) + DX i=1 cisi = const(x, µ) + DX i=1 cisi.(44)
-
[40]
The objective can be written as LM,β(s) = const(x, µ) + DX i=1 ℓi(si), ℓ i(s) :=c is+βg(s).(45) Each ℓi is strictly convex on (0,∞) , hence LM,β has a unique minimizer s∗(M, β)∈ (0,∞) D
-
[41]
, D.(46) Proof.WriteZ=µ+εwithε∼ N 0,diag(s) and expand dM(x, Z) = (x−W µ−W ε) ⊤G(x−W µ−W ε)
The minimizer is given in closed form by s∗ i (M, β) = 1 1 + 2ci/β = β β+ 2c i , i= 1, . . . , D.(46) Proof.WriteZ=µ+εwithε∼ N 0,diag(s) and expand dM(x, Z) = (x−W µ−W ε) ⊤G(x−W µ−W ε). The cross term vanishes in expectation, and E[ε⊤Bε] = tr Bdiag(s) =P i cisi, which yields (44) and the separable form (45). Since g′′(s) = 1/(2s2)>0 for s >0 , each ℓi is ...
-
[42]
If all ci are equal, then all s∗ i (M, β) coincide and Apost s∗(M, β) = 0 (isotropic posterior)
-
[43]
TargetP i g(s∗ i )
If the coefficients ci are not all equal, then the entries of s∗(M, β) are not all equal and Apost s∗(M, β) >0(anisotropic posterior). We now show that, for a fixed distortionM, every positive target value of the variance part of the KL can be obtained by a suitable choice ofβ. Theorem 41(Surjectivity of the variance-KL map). FixW, Mand assume at least on...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.