Graph Transfer Learning via Shared Latent Geometry: Theory and Applications
Pith reviewed 2026-06-28 19:13 UTC · model grok-4.3
The pith
An asymmetric two-pathway architecture enables certified zero-shot transfer of inference across changing graph topologies by sharing a stable latent geometry.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
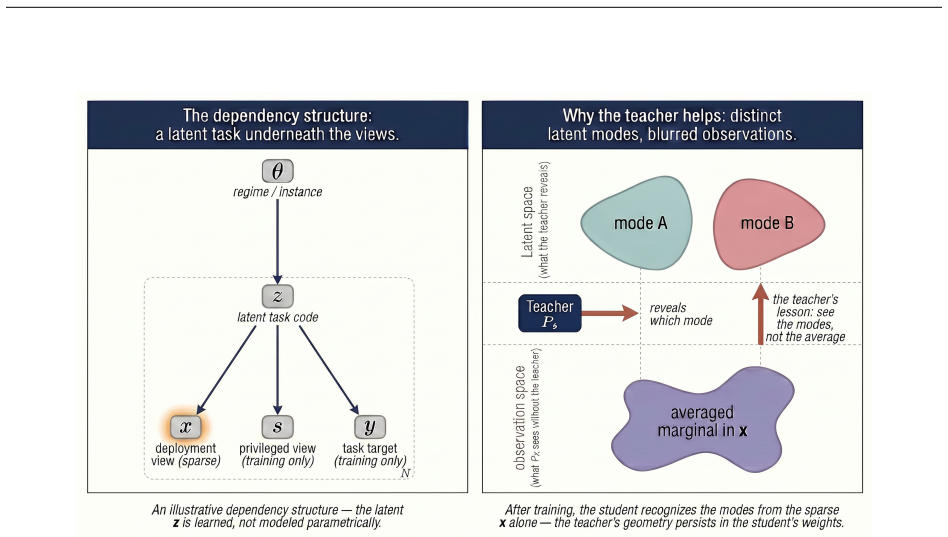
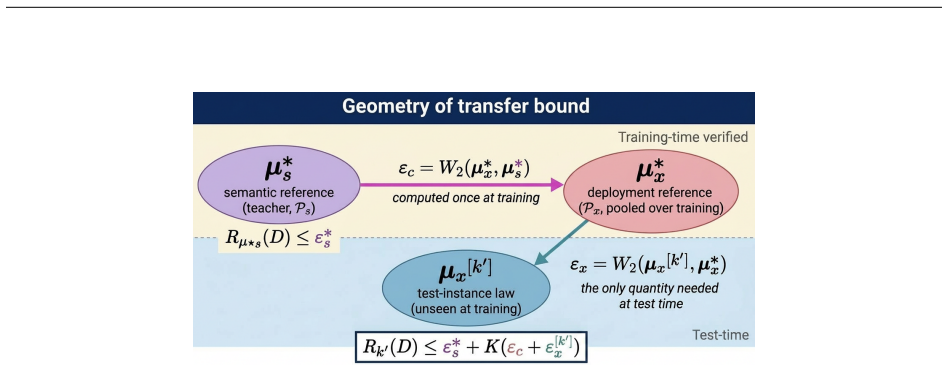
The central claim is that transfer conditions via Wasserstein proximity between the latent laws of the two encoders yield a zero-shot error bound, supported by a finite-sample certification protocol with active expansion, under the condition that the latent task stays fixed while topology and operator change.
What carries the argument
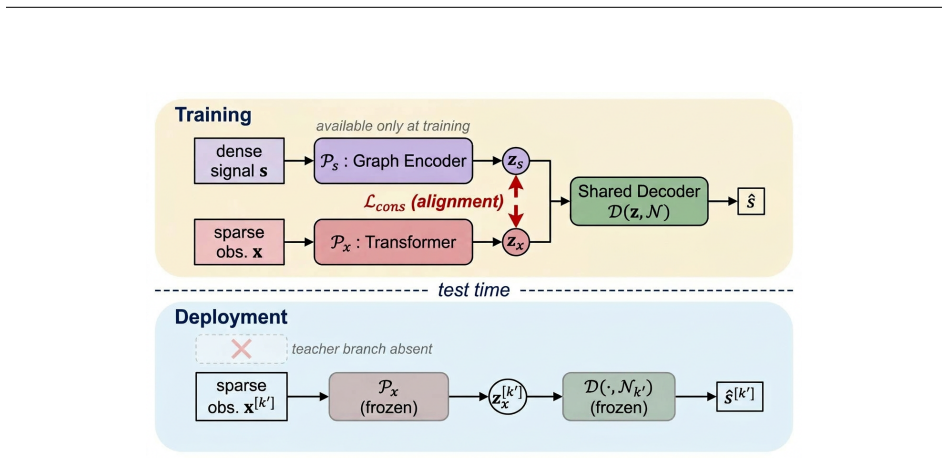
Asymmetric teacher-student encoders sharing operator-polynomial features that are stable under spectral perturbation.
If this is right
- Provides a zero-shot error bound for inference on unseen topologies.
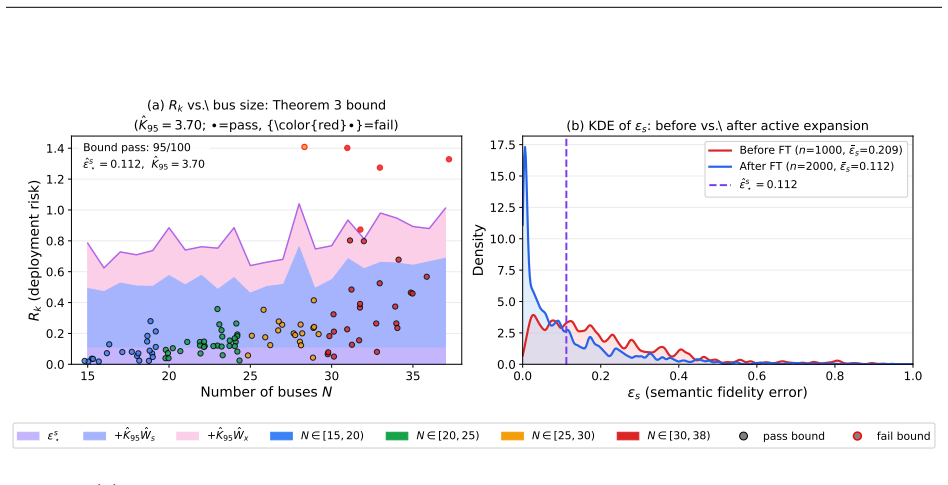
- Achieves 95% certificate pass rate on power-system estimation across 100 unseen topologies.
- Delivers accuracy competitive with Newton-Raphson methods at sub-millisecond speeds.
- Enables single forward pass inference after discarding the teacher.
Where Pith is reading between the lines
- The method could generalize to control problems in networked systems beyond estimation.
- Active expansion in certification might reduce data requirements in other transfer learning settings.
- If spectral stability holds more broadly, similar anchors could be used in non-physical graph domains.
Load-bearing premise
The latent task stays the same across instances even as topology and operator change, and the operator-polynomial features remain stable under spectral perturbation.
What would settle it
Observing transfer error larger than the Wasserstein-derived bound when latent laws are close but the underlying task differs would falsify the transfer guarantee.
Figures
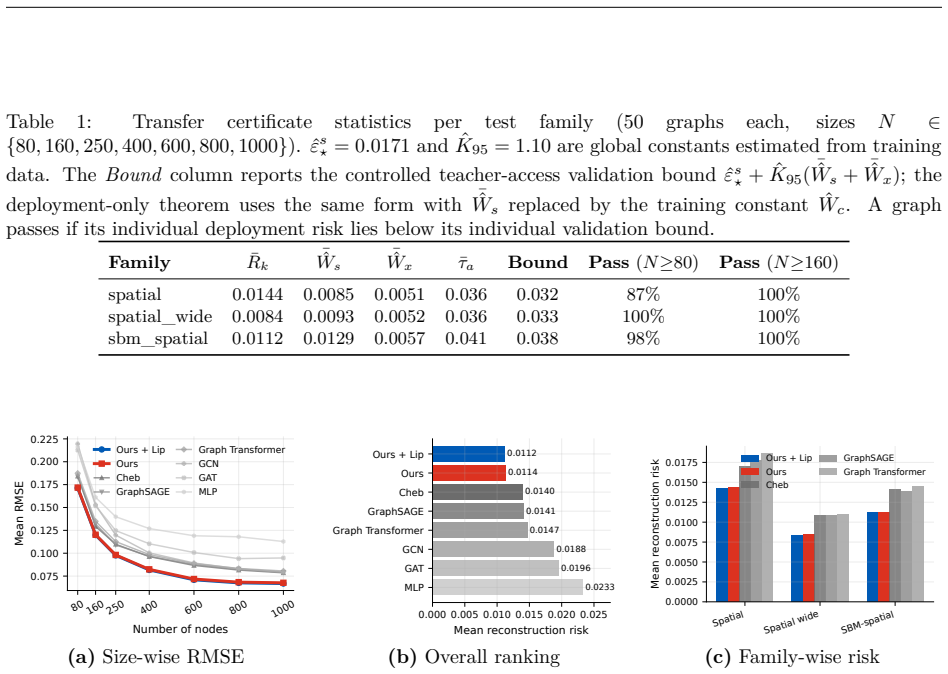
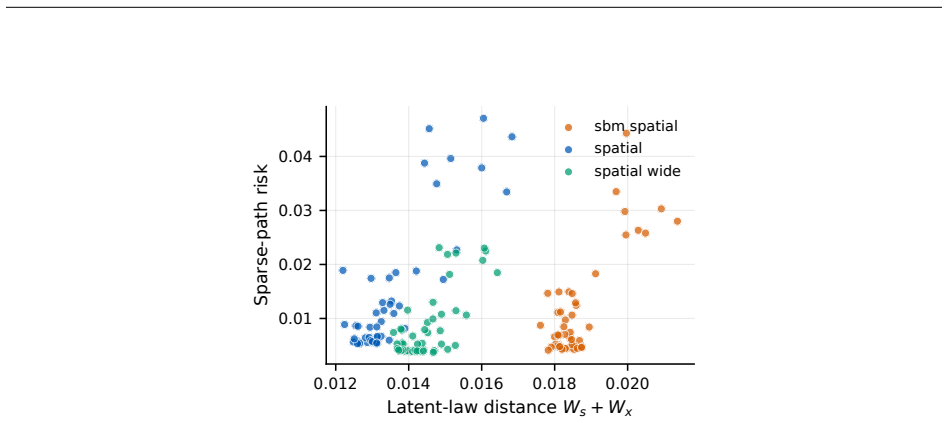
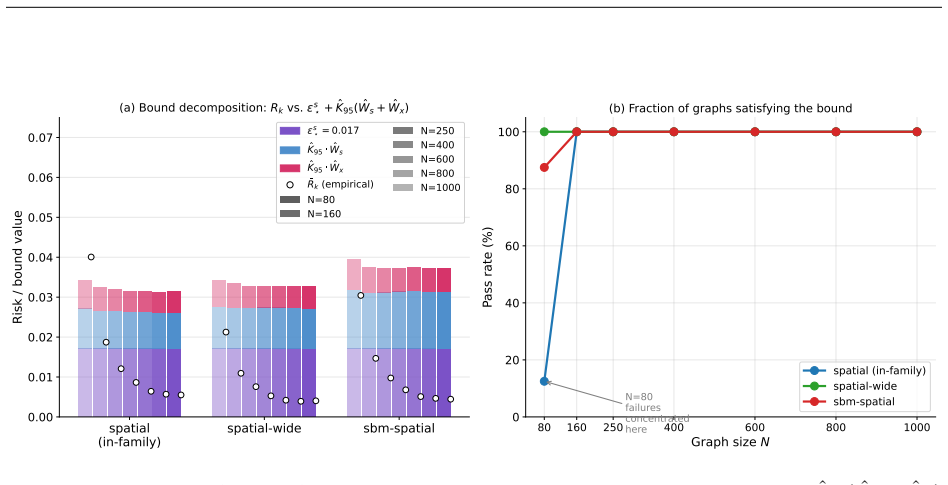
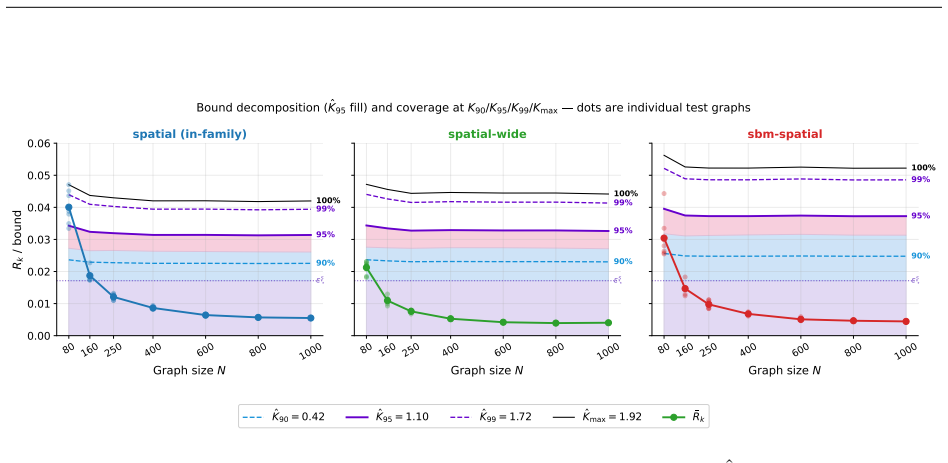
read the original abstract
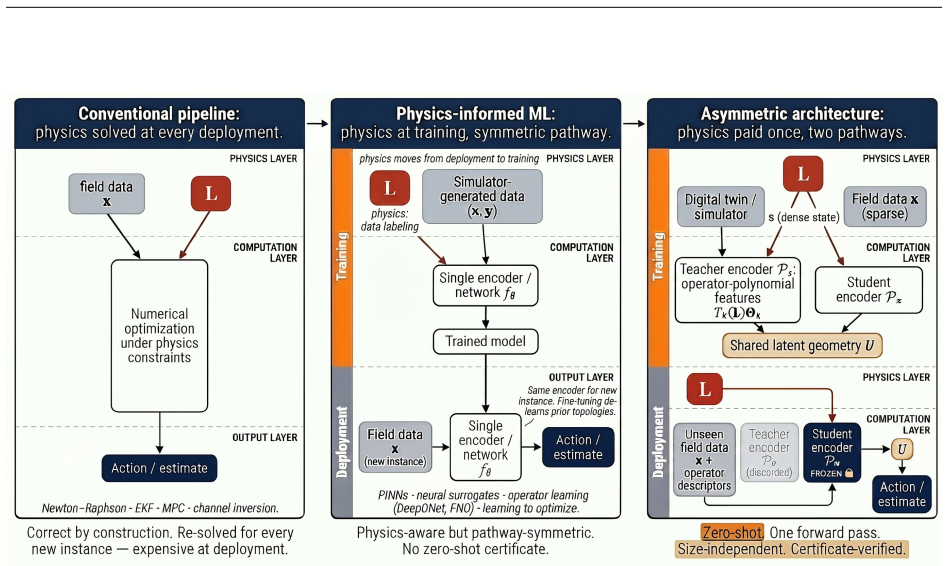
Inference and control in engineered physical systems pay a heavy physics cost at deployment: state estimators, inverse-problem solvers, model-predictive controllers, schedulers, and observers are often not closed-form and must re-solve a numerical optimization per instance, with the operator re-supplied each time. Physics-informed learning moves this cost to training, but uses a single encoder pathway whose latent geometry de-learns under fine-tuning and admits no quantitative transfer guarantee. We propose an asymmetric two-pathway architecture that resolves both issues. A teacher encoder consumes privileged dense states from a high-fidelity simulator and represents the system through operator-polynomial features stable under spectral perturbation; a student encoder learns the same latent geometry from sparse field data and operator descriptors. At deployment the teacher is discarded, and the frozen student runs in a single forward pass with a transfer certificate. The design connects to privileged-information learning, knowledge distillation, and cross-modal distillation, but targets cross-instance transfer rather than fixed-instance prediction: topology and operator may change, while the latent task does not. We establish sufficient and near-necessary transfer conditions via Wasserstein proximity between latent laws, yielding a zero-shot error bound, and develop a finite-sample certification protocol with active expansion when coverage is incomplete. The framework applies wherever a system admits an operator with reportable spectrum. On power-system estimation, it achieves zero-shot transfer to 100 unseen topologies, a 95% certificate pass rate, accuracy competitive with topology-aware Newton--Raphson, and sub-millisecond inference. These results suggest asymmetric pathways plus operator-anchored latent geometry provide a foundation for certified zero-shot inference and control.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces an asymmetric teacher-student architecture for zero-shot graph transfer learning in physical systems. The teacher extracts operator-polynomial features from privileged dense simulator states, claimed to be stable under spectral perturbations; the student learns the same latent geometry from sparse field data and operator descriptors. Central claims include sufficient and near-necessary transfer conditions via Wasserstein proximity of latent laws (yielding a zero-shot error bound), a finite-sample certification protocol with active expansion, and empirical success on power-system estimation with transfer to 100 unseen topologies, 95% certificate pass rate, and sub-millisecond inference competitive with Newton-Raphson.
Significance. If the Wasserstein-based bounds and feature stability hold with explicit moduli, the framework would provide a principled, certifiable approach to cross-instance transfer where topology and operators vary while the latent task remains fixed. This could impact physics-informed ML, control, and estimation in domains like power systems by enabling reliable single-pass inference without per-instance optimization or retraining.
major comments (1)
- [Transfer theorem] Transfer theorem (main theoretical section): The stability of operator-polynomial features under spectral perturbation of the operator and topology is invoked directly to control the Wasserstein distance in the zero-shot error bound and near-necessary condition, yet no quantitative perturbation modulus or explicit sensitivity bound on the feature map is supplied. This is load-bearing; without it the guarantee does not extend beyond the tested power-system regime if feature sensitivity grows faster than linear.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for identifying a load-bearing aspect of the transfer theorem. We address the comment below and will revise the manuscript to strengthen the result.
read point-by-point responses
-
Referee: The stability of operator-polynomial features under spectral perturbation of the operator and topology is invoked directly to control the Wasserstein distance in the zero-shot error bound and near-necessary condition, yet no quantitative perturbation modulus or explicit sensitivity bound on the feature map is supplied. This is load-bearing; without it the guarantee does not extend beyond the tested power-system regime if feature sensitivity grows faster than linear.
Authors: We agree that an explicit quantitative perturbation modulus is needed to make the transfer guarantee fully general. The current manuscript establishes stability of the operator-polynomial features but does not derive or state a modulus controlling the feature-map sensitivity to spectral changes in the operator or topology. In the revised version we will insert a new lemma (in the main theoretical section) that supplies a Lipschitz-type bound on the feature map with respect to the spectral perturbation norm. The bound will be expressed in terms of the polynomial degree, the operator norm, and the spectral gap; it will be used to make the constants in the zero-shot Wasserstein error bound and the near-necessary condition fully explicit. This revision directly addresses the concern that sensitivity could grow faster than linear and will extend the certified regime beyond the power-system experiments. revision: yes
Circularity Check
No circularity: transfer bound derived from Wasserstein proximity with stability stated as enabling property
full rationale
The abstract presents operator-polynomial features as stable under spectral perturbation and derives sufficient/near-necessary transfer conditions from Wasserstein proximity of latent laws to obtain a zero-shot error bound. No equation or claim reduces by construction to its own inputs, no fitted parameter is relabeled as a prediction, and no self-citation chain is invoked to justify the central premise. The derivation chain remains self-contained against the stated assumptions without self-referential collapse.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Systems admit an operator with reportable spectrum
Reference graph
Works this paper leans on
-
[1]
Learning nonlinear operators via
Lu, Lu and Jin, Pengzhan and Pang, Guofei and Zhang, Zhongqiang and Karniadakis, George Em , journal =. Learning nonlinear operators via
-
[2]
Journal of Machine Learning Research , volume=
Homeomorphic projection to ensure neural-network solution feasibility for constrained optimization , author=. Journal of Machine Learning Research , volume=
-
[3]
International Conference on Learning Representations , year =
Fourier Neural Operator for Parametric Partial Differential Equations , author =. International Conference on Learning Representations , year =
-
[4]
International Conference on Learning Representations , year =
Unifying distillation and privileged information , author =. International Conference on Learning Representations , year =
-
[5]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pages =
Cross modal distillation for supervision transfer , author =. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pages =
-
[6]
Romero, Adriana and Ballas, Nicolas and Kahou, Samira Ebrahimi and Chassang, Antoine and Gatta, Carlo and Bengio, Yoshua , booktitle =
-
[7]
IEEE signal processing magazine , volume=
The emerging field of signal processing on graphs: Extending high-dimensional data analysis to networks and other irregular domains , author=. IEEE signal processing magazine , volume=. 2013 , publisher=
2013
-
[8]
Proceedings of the IEEE , volume=
Graph signal processing: Overview, challenges, and applications , author=. Proceedings of the IEEE , volume=. 2018 , publisher=
2018
-
[9]
IEEE Transactions on Knowledge and Data Engineering , volume=
A survey on transfer learning , author=. IEEE Transactions on Knowledge and Data Engineering , volume=. 2010 , publisher=
2010
-
[10]
Journal of machine learning research , volume=
Domain-adversarial training of neural networks , author=. Journal of machine learning research , volume=
-
[11]
International Conference on Learning Representations , year=
Semi-supervised classification with graph convolutional networks , author=. International Conference on Learning Representations , year=
-
[12]
Advances in Neural Information Processing Systems , year=
Convolutional neural networks on graphs with fast localized spectral filtering , author=. Advances in Neural Information Processing Systems , year=
-
[13]
Advances in Neural Information Processing Systems , year=
Do transformers really perform badly for graph representation? , author=. Advances in Neural Information Processing Systems , year=
-
[14]
International Conference on Machine Learning , year=
Neural message passing for quantum chemistry , author=. International Conference on Machine Learning , year=
-
[15]
Advances in Neural Information Processing Systems , year=
Graph meta learning via local subgraphs , author=. Advances in Neural Information Processing Systems , year=
-
[16]
International Conference on Learning Representations , year=
Handling Distribution Shifts on Graphs: An Invariance Perspective , author=. International Conference on Learning Representations , year=
-
[17]
Hu, Weihua and others , booktitle=
-
[18]
IEEE/CVF International Conference on Computer Vision , year=
Homeomorphic alignment for unsupervised domain adaptation , author=. IEEE/CVF International Conference on Computer Vision , year=
-
[19]
International Conference on Machine Learning , year=
Topological autoencoders , author=. International Conference on Machine Learning , year=
-
[20]
Transactions on Machine Learning Research arXiv:2601.09025 , year=
Universal Latent Homeomorphic Manifolds: Cross-Domain Representation Learning via Homeomorphism Verification , author=. Transactions on Machine Learning Research arXiv:2601.09025 , year=
-
[21]
Geometric Pareto Control: Riemannian Gradient Flow of Energy Function via Lie Group Homotopy
Geometric Pareto Control: Riemannian Gradient Flow of Energy Function via Lie Group Homotopy , author=. arXiv preprint arXiv:2605.09824 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
International Conference on Learning Representations , year=
Deep complex networks , author=. International Conference on Learning Representations , year=
-
[23]
2004 , publisher=
Power System State Estimation: Theory and Implementation , author=. 2004 , publisher=
2004
-
[24]
IEEE Transactions on Power Delivery , volume=
Optimal capacitor placement on radial distribution systems , author=. IEEE Transactions on Power Delivery , volume=. 1989 , publisher=
1989
-
[25]
IEEE Transactions on Signal Processing , volume=
Real-time power system state estimation and forecasting via deep unrolled neural networks , author=. IEEE Transactions on Signal Processing , volume=. 2019 , publisher=
2019
-
[26]
Advances in Neural Information Processing Systems , year=
To trust or not to trust a classifier , author=. Advances in Neural Information Processing Systems , year=
-
[27]
International Conference on Artificial Neural Networks , year=
Neighborhood preservation in nonlinear projection methods: An experimental study , author=. International Conference on Artificial Neural Networks , year=
-
[28]
Neural Networks , volume=
A new learning paradigm: Learning using privileged information , author=. Neural Networks , volume=. 2009 , publisher=
2009
-
[29]
Distilling the Knowledge in a Neural Network
Distilling the knowledge in a neural network , author=. NIPS 2014 Deep Learning Workshop arXiv:1503.02531 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[30]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Distilling knowledge from graph convolutional networks , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[31]
Yan, Bencheng and Wang, Chaokun and Guo, Gaoyang and Lou, Yunkai , booktitle=
-
[32]
Journal of Computational Physics , volume=
Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations , author=. Journal of Computational Physics , volume=. 2019 , publisher=
2019
-
[33]
Electric Power Systems Research , volume=
Neural networks for power flow: Graph neural solver , author=. Electric Power Systems Research , volume=. 2020 , publisher=
2020
-
[34]
Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing , pages=
Optimal power flow using graph neural networks , author=. Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing , pages=
-
[35]
IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=
Representation learning: A review and new perspectives , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=. 2013 , publisher=
2013
-
[36]
Journal of the American Mathematical Society , volume=
Testing the manifold hypothesis , author=. Journal of the American Mathematical Society , volume=
-
[37]
1997 , publisher=
Matrix Analysis , author=. 1997 , publisher=
1997
-
[38]
Proceedings of the International Conference on Learning Representations , year=
Sign and basis invariant networks for spectral graph representation learning , author=. Proceedings of the International Conference on Learning Representations , year=
-
[39]
IEEE Transactions on Signal Processing , volume=
Graphon signal processing , author=. IEEE Transactions on Signal Processing , volume=. 2021 , publisher=
2021
-
[40]
IEEE Transactions on Signal Processing , volume=
Transferability properties of graph neural networks , author=. IEEE Transactions on Signal Processing , volume=. 2023 , publisher=
2023
-
[41]
Advances in neural information processing systems , volume=
Generalization analysis of message passing neural networks on large random graphs , author=. Advances in neural information processing systems , volume=
-
[42]
Advances in Neural Information Processing Systems , volume=
Graphon neural networks and the transferability of graph neural networks , author=. Advances in Neural Information Processing Systems , volume=
-
[43]
IEEE Transactions on Knowledge and Data Engineering , volume =
Graph Transfer Learning via Adversarial Domain Adaptation with Graph Convolution , author =. IEEE Transactions on Knowledge and Data Engineering , volume =. 2022 , doi =
2022
-
[44]
International Conference on Learning Representations , year =
Handling Distribution Shifts on Graphs: An Invariance Perspective , author =. International Conference on Learning Representations , year =
-
[45]
International Conference on Learning Representations , year =
Graph Domain Adaptation via Theory-Grounded Spectral Regularization , author =. International Conference on Learning Representations , year =
-
[46]
Proceedings of the AAAI Conference on Artificial Intelligence , pages =
Adversarial Deep Network Embedding for Cross-Network Node Classification , author =. Proceedings of the AAAI Conference on Artificial Intelligence , pages =. 2020 , doi =
2020
-
[47]
IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages =
Stability of Graph Neural Networks to Relative Perturbations , author =. IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages =. 2020 , doi =
2020
-
[48]
Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining , pages =
Stability and Generalization of Graph Convolutional Neural Networks , author =. Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining , pages =. 2019 , doi =
2019
-
[49]
Neurocomputing , volume =
The Generalization Error of Graph Convolutional Networks May Enlarge with More Layers , author =. Neurocomputing , volume =. 2021 , doi =
2021
-
[50]
Liao, Renjie and Urtasun, Raquel and Zemel, Richard , booktitle =. A. 2021 , url =
2021
-
[51]
Advances in Neural Information Processing Systems , volume =
Learning Theory Can (Sometimes) Explain Generalisation in Graph Neural Networks , author =. Advances in Neural Information Processing Systems , volume =. 2021 , url =
2021
-
[52]
Proceedings of the 36th International Conference on Machine Learning , series =
Connectivity-Optimized Representation Learning via Persistent Homology , author =. Proceedings of the 36th International Conference on Machine Learning , series =. 2019 , publisher =
2019
-
[53]
International Conference on Artificial Intelligence and Statistics , series =
Carri. International Conference on Artificial Intelligence and Statistics , series =. 2020 , publisher =
2020
-
[54]
International Conference on Learning Representations , year=
Graph Attention Networks , author=. International Conference on Learning Representations , year=
-
[55]
Advances in Neural Information Processing Systems , pages=
Inductive Representation Learning on Large Graphs , author=. Advances in Neural Information Processing Systems , pages=
-
[56]
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A
Masked Label Prediction: Unified Message Passing Model for Semi-Supervised Classification , author=. arXiv preprint arXiv:2009.03509 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.