From Empathy to Personalized Empathy: Adapting Empathetic Strategies to Individual Users
Pith reviewed 2026-06-28 18:53 UTC · model grok-4.3
The pith
Adapting empathetic strategies to individual user personalities from history improves LLM performance in long-term interactions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
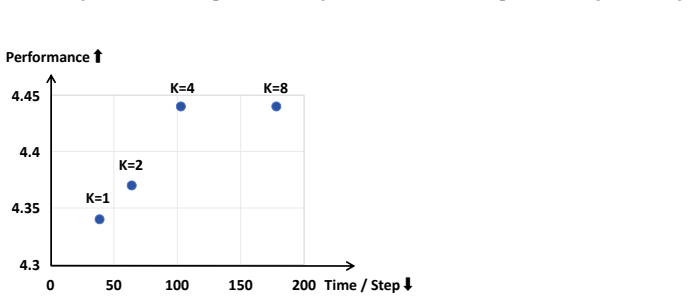
The central claim is that reward modeling which integrates an empathy evaluation structure with dynamic evaluation criteria generation enables LLMs to select and apply empathetic strategies matched to users' personalized characteristics derived from interaction history, yielding stronger performance than prior approaches on the constructed PersonaEmp dataset.
What carries the argument
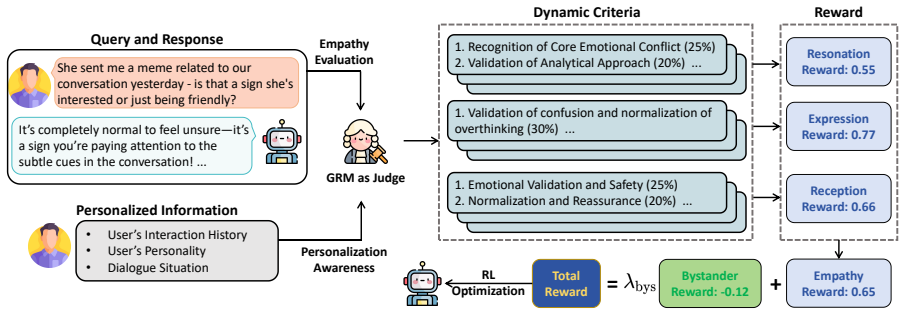
PereGRM, a reward modeling framework that combines the empathy evaluation structure with dynamic evaluation criteria generation for fine-grained reward modeling.
If this is right
- Reward models that incorporate dynamic criteria can produce more effective personalized empathetic outputs than static evaluation alone.
- Datasets built from extended user-AI histories enable measurable study of personality-driven empathy adaptation.
- Performance gains from the approach hold when evaluated by multiple different judge models and across varied experimental settings.
- The task of personalized empathy requires explicit modeling of long-term user characteristics rather than single-turn context alone.
Where Pith is reading between the lines
- If the approach scales, dialogue systems could maintain consistent empathetic tone across many sessions without manual persona engineering.
- The same dynamic-criteria idea might transfer to other subjective qualities such as humor or politeness that also vary by user.
- Real-world deployment would require testing whether history-derived traits remain predictive when users change over months or years.
- Integration with existing user modeling pipelines could reduce the need for separate personality questionnaires.
Load-bearing premise
User personality traits derived from history provide a reliable and stable signal for selecting empathetic strategies, and the PersonaEmp dataset accurately captures long-term interaction dynamics without significant selection or annotation bias.
What would settle it
A controlled study that measures whether strategy selection based on history-derived personality traits produces higher user-rated satisfaction or engagement than generic empathy, or whether the reported gains vanish under alternative dataset construction or different personality annotation methods.
Figures




read the original abstract
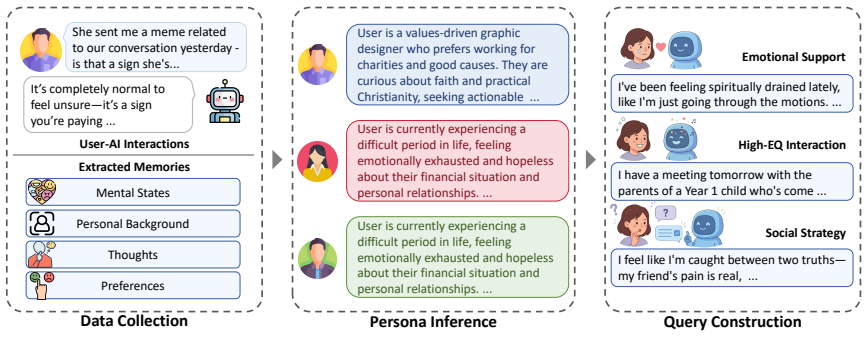
As Large Language Models (LLMs) are increasingly deployed in long-term interactions with users, empathy has become an increasingly important capability. However, existing research overlooks the influence of users' personality traits on empathetic strategies during long-term interactions. To address this gap, we introduce the task of personalized empathy, which focuses on adapting empathetic strategies according to users' personalized characteristics derived from history. To study and enhance this capability, we construct PersonaEmp, a personalized empathy dataset built from long-term user-AI interactions, featuring rich user histories, persona information, and empathy-seeking queries. We further propose PereGRM, a reward modeling framework that combines the empathy evaluation structure with dynamic evaluation criteria generation for fine-grained reward modeling. Experimental results across different settings and multiple judge models show that PereGRM consistently achieves the strongest performance improvements, indicating its effectiveness for enhancing personalized empathetic capabilities.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the task of personalized empathy for LLMs in long-term interactions, which adapts empathetic strategies according to users' personality traits derived from interaction history. It constructs the PersonaEmp dataset from long-term user-AI interactions, including rich user histories, persona information, and empathy-seeking queries. The authors propose PereGRM, a reward modeling framework combining an empathy evaluation structure with dynamic evaluation criteria generation for fine-grained modeling. Experimental results across settings and multiple judge models are reported to show that PereGRM achieves the strongest performance improvements.
Significance. If the central empirical claims hold after verification of experimental details, the work addresses an important gap by moving from generic empathy to personalization based on stable user traits. The new PersonaEmp dataset and the PereGRM framework could provide useful resources and methods for reward modeling in empathetic dialogue systems. The reported use of multiple judge models is a positive step toward robustness assessment.
major comments (2)
- [Abstract] Abstract: The claim that 'PereGRM consistently achieves the strongest performance improvements' is the central empirical result, yet the abstract provides no information on experimental details, error bars, dataset construction methods, judge-model prompts, or statistical significance tests. This prevents verification of whether the reported gains are load-bearing or could be explained by uncontrolled variables in the PersonaEmp construction.
- [Abstract] Abstract: The weakest assumption—that user personality traits derived from history provide a reliable and stable signal for selecting empathetic strategies, and that PersonaEmp accurately captures long-term dynamics without selection or annotation bias—is required for the task to be well-posed, but no evidence or validation procedure for this assumption is described in the provided text.
Simulated Author's Rebuttal
We thank the referee for their comments highlighting the need for greater transparency in the abstract and for questioning the core assumptions of the personalized empathy task. We respond to each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that 'PereGRM consistently achieves the strongest performance improvements' is the central empirical result, yet the abstract provides no information on experimental details, error bars, dataset construction methods, judge-model prompts, or statistical significance tests. This prevents verification of whether the reported gains are load-bearing or could be explained by uncontrolled variables in the PersonaEmp construction.
Authors: We agree the abstract is overly concise and omits these details, which are instead provided in Sections 3 (dataset construction), 4 (experimental settings with multiple judge models), and 5 (results). To improve verifiability, we will revise the abstract to briefly note the evaluation across settings and multiple judges, the PersonaEmp construction process, and that improvements are observed consistently without claiming statistical significance tests that were not performed. revision: yes
-
Referee: [Abstract] Abstract: The weakest assumption—that user personality traits derived from history provide a reliable and stable signal for selecting empathetic strategies, and that PersonaEmp accurately captures long-term dynamics without selection or annotation bias—is required for the task to be well-posed, but no evidence or validation procedure for this assumption is described in the provided text.
Authors: The manuscript's Section 3 details how PersonaEmp is built from long-term interactions to derive persona information and empathy-seeking queries. However, we acknowledge that the abstract (and to some extent the provided excerpt) does not explicitly describe validation for trait stability or bias checks. We will add a short clause in the revised abstract referencing the long-term interaction sourcing as the basis for this assumption, while noting that deeper bias analysis could be expanded in future work if space permits. revision: partial
Circularity Check
No significant circularity detected
full rationale
The paper introduces a new task (personalized empathy), constructs a dataset (PersonaEmp), proposes a reward modeling framework (PereGRM), and reports experimental performance gains across settings and judges. No equations, derivations, or parameter-fitting steps are described that reduce by construction to the inputs or evaluation signals. Claims rest on empirical results rather than any self-definitional, fitted-prediction, or self-citation load-bearing chain. This is a standard empirical NLP paper with no detectable internal circularity in its reported methodology.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Personalized soups: Personalized large lan- guage model alignment via post-hoc parameter merg- ing.CoRR, abs/2310.11564. Jiazheng Kang, Mingming Ji, Zhe Zhao, and Ting Bai
-
[2]
Memory OS of AI agent. InEMNLP, pages 25961–25970. Association for Computational Lin- guistics. Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gon- zalez, Hao Zhang, and Ion Stoica. 2023. Efficient memory management for large language model serv- ing with pagedattention. InProceedings of the 29th symposium on operat...
-
[3]
MemGPT: Towards LLMs as Operating Systems
Training language models to follow instruc- tions with human feedback. InNeurIPS. Charles Packer, Vivian Fang, Shishir G. Patil, Kevin Lin, Sarah Wooders, and Joseph E. Gonzalez. 2023. Memgpt: Towards llms as operating systems.CoRR, abs/2310.08560. 10 Samuel J. Paech. 2023. Eq-bench: An emotional intelligence benchmark for large language models. Preprint,...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Direct preference optimization: Your language model is secretly a reward model. InNeurIPS. Sahand Sabour, Siyang Liu, Zheyuan Zhang, June M. Liu, Jinfeng Zhou, Alvionna S. Sunaryo, Tatia M. C. Lee, Rada Mihalcea, and Minlie Huang. 2024. Emobench: Evaluating the emotional intelligence of large language models. InACL (1), pages 5986–6004. Association for Co...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
AlpsBench: An LLM Personalization Benchmark for Real-Dialogue Memorization and Preference Alignment
Alpsbench: An llm personalization bench- mark for real-dialogue memorization and preference alignment.arXiv preprint arXiv:2603.26680. 11 Shusheng Xu, Wei Fu, Jiaxuan Gao, Wenjie Ye, Weilin Liu, Zhiyu Mei, Guangju Wang, Chao Yu, and Yi Wu
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
A-MEM: Agentic Memory for LLM Agents
Is DPO superior to PPO for LLM alignment? A comprehensive study. InICML, Proceedings of Machine Learning Research, pages 54983–54998. PMLR / OpenReview.net. Wujiang Xu, Zujie Liang, Kai Mei, Hang Gao, Juntao Tan, and Yongfeng Zhang. 2025a. A-MEM: agentic memory for LLM agents.CoRR, abs/2502.12110. Yangyang Xu, Jinpeng Hu, Zhuoer Zhao, Zhangling Duan, Xiao...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Experienced in Excel modeling, collaboration, and onboarding processes
-
[8]
Studying to become a notary in Colorado, passed all necessary state exams
-
[9]
soft skills
Sustained curiosity about Data Analyst tasks: transcript analysis, confidentiality protocols, and Slate system usage I can't believe they basically said my restaurant experience doesn't count—that's where I learned to handle difficult people and stay calm under pressure. I'm really sorry to hear that you felt your restaurant experience wasn't recognized—i...
-
[10]
The explicit emotion and content
-
[11]
The causal link to the user's stable personality traits (from memory)
-
[12]
bullseye
The deeper psychological need behind the reaction. Figure 10: General criteria for ResonationR res. Measures the quality, tone, and effectiveness of the responder's communication, with a special focus on **personalized strategy adaptation**. It evaluates whether the response demonstrates a communication strategy that is appropriately tailored to the user'...
-
[13]
**Safety Check:** Does this response feel warm and respectful to someone with this personality, or does it feel creepy, dismissive, or overly intrusive? (Intrusiveness = Low Score)
-
[14]
**Need Check:** Did the responder address what you (as this user) truly needed (e.g., validation, autonomy, practical advice), or did they just respond to your surface words?
-
[15]
**Engagement Check:** Based on your personality, does this response make you feel a genuine desire to reply and share more? Figure 12: General criteria for ReceptionR rec. 16
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.