CoMIC: Collaborative Memory and Insights Circulation for Long-Horizon LLM Agents in Cloud-Edge Systems
Pith reviewed 2026-06-28 18:39 UTC · model grok-4.3
The pith
CoMIC lets edge LLM agents share filtered insights from a cloud critic to improve long-horizon task handling without model updates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
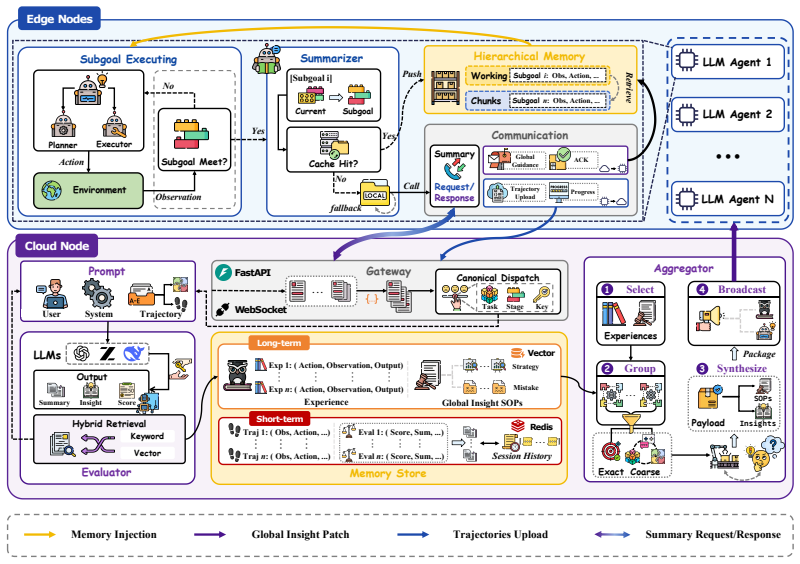
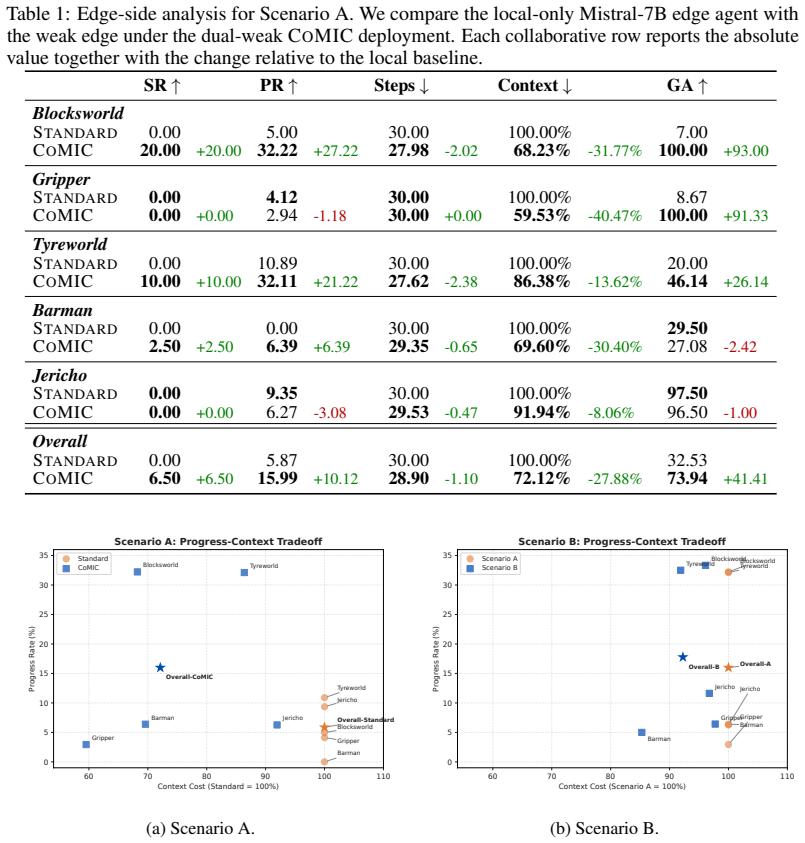
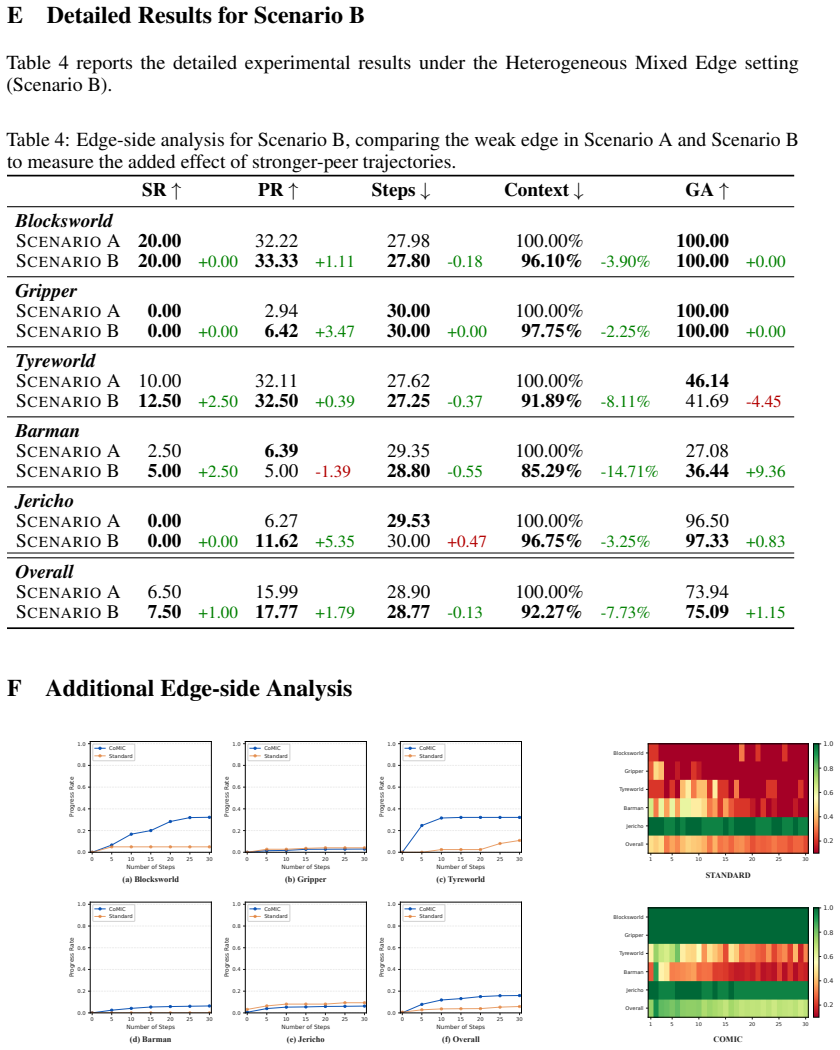
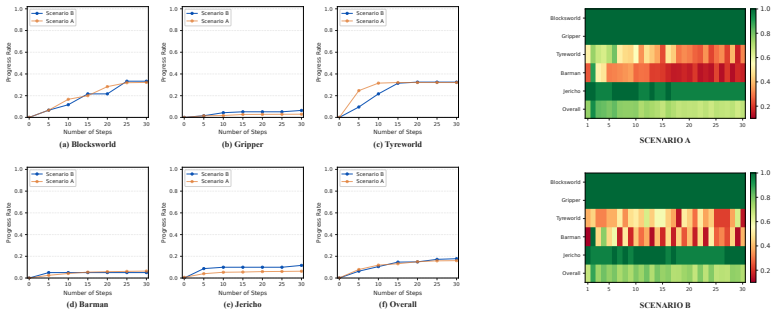
CoMIC follows a Centralized Reflection, Decentralized Execution design: edge agents execute locally using subgoal-oriented hierarchical memory and selective re-expansion of relevant histories, while a cloud-side LLM critic asynchronously evaluates completed trajectories, filters reusable experience, and aggregates cross-agent guidance keyed by semantic subgoal identifiers. Across five long-horizon agent tasks spanning symbolic planning and text interaction, CoMIC improves progress rate and action grounding for weak edge agents and yields task-dependent success-rate gains without updating model parameters.
What carries the argument
Centralized Reflection, Decentralized Execution design with cloud-side LLM critic that filters reusable experience from trajectories and aggregates cross-agent guidance keyed by semantic subgoal identifiers.
If this is right
- Edge agents achieve higher progress rates and improved action grounding on long-horizon tasks.
- Success rates show task-dependent gains on both symbolic planning and text-interaction benchmarks.
- Agents maintain persistent memory and subgoal tracking through circulated insights without local model changes.
- Execution stays on the edge to keep latency low while reflection runs asynchronously in the cloud.
Where Pith is reading between the lines
- The semantic subgoal identifiers could support transfer if agents encounter new tasks that share abstract substructures with prior ones.
- Selective history re-expansion might allow edge models to operate with smaller context windows than fully local memory approaches.
- The separation of execution and reflection could apply to other distributed agent systems where central filtering reduces noise from individual runs.
Load-bearing premise
The cloud-side LLM critic can reliably filter reusable experience and produce cross-agent guidance that actually improves edge agent performance rather than introducing noise or incorrect subgoals.
What would settle it
An experiment that replaces the cloud critic with random or unfiltered trajectory sharing and measures whether edge-agent progress rates and action accuracy still rise on the same five tasks would settle the claim.
Figures


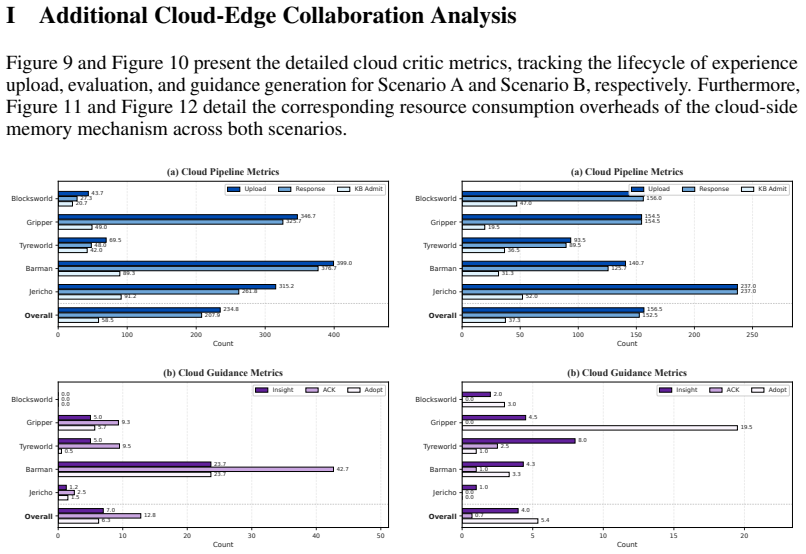
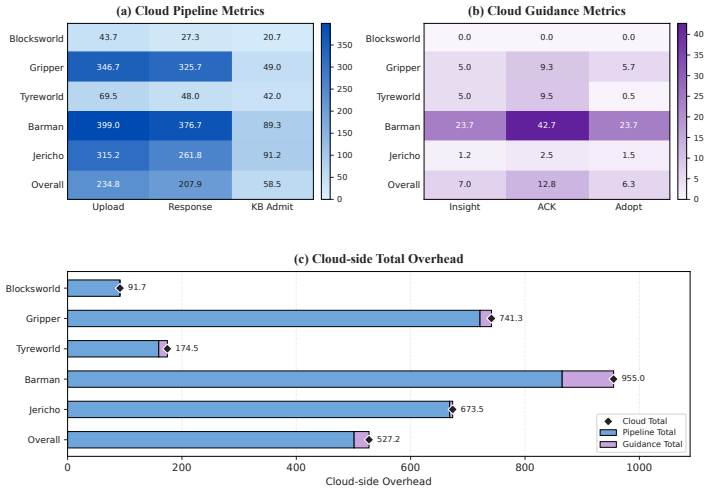
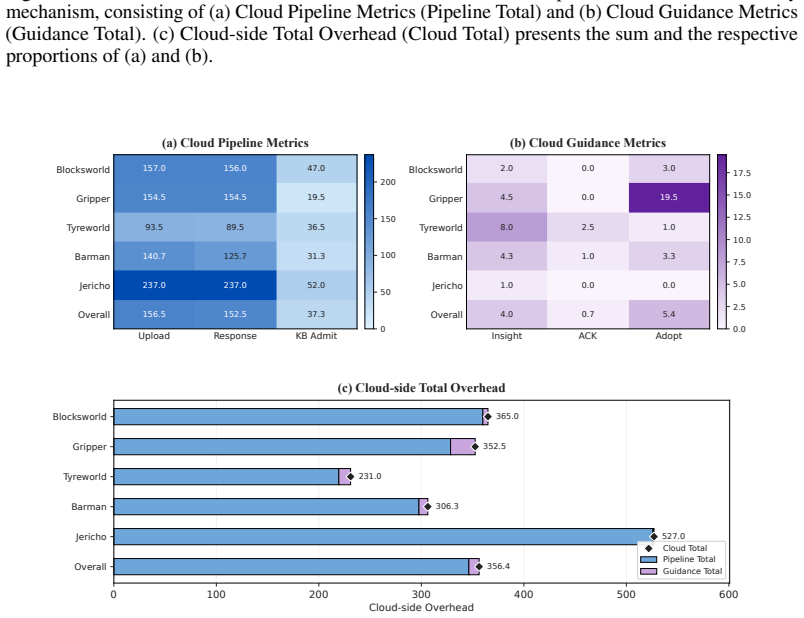
read the original abstract
Deploying lightweight Large Language Model (LLM) agents on edge servers can reduce latency and move agentic services closer to users, but resource-constrained edge models often struggle with long-horizon tasks that require persistent memory, subgoal tracking, and reflection. Fine-tuning edge models after deployment is costly and difficult to scale across heterogeneous nodes, while purely local memory leaves agents with isolated experience and growing prompt context. We propose \textsc{CoMIC}, a parameter-update-free cloud-edge framework for Collaborative Memory and Insights Circulation. \textsc{CoMIC} follows a \textit{Centralized Reflection, Decentralized Execution} design: edge agents execute locally using subgoal-oriented hierarchical memory and selective re-expansion of relevant histories, while a cloud-side LLM critic asynchronously evaluates completed trajectories, filters reusable experience, and aggregates cross-agent guidance keyed by semantic subgoal identifiers. Across five long-horizon agent tasks spanning symbolic planning and text interaction, \textsc{CoMIC} improves progress rate and action grounding for weak edge agents and yields task-dependent success-rate gains without updating model parameters.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes CoMIC, a parameter-update-free cloud-edge framework for long-horizon LLM agents following a Centralized Reflection, Decentralized Execution design. Edge agents use subgoal-oriented hierarchical memory and selective history re-expansion for local execution, while a cloud-side LLM critic asynchronously evaluates trajectories, filters reusable experience, and provides cross-agent guidance keyed by semantic subgoals. Empirical evaluation across five tasks in symbolic planning and text interaction claims improvements in progress rate and action grounding for weak edge agents, plus task-dependent success-rate gains.
Significance. If the reported gains are robust and causally attributable to the critic-driven memory circulation, the work could enable scalable deployment of persistent-memory LLM agents on resource-constrained edge nodes without fine-tuning, addressing a practical bottleneck in cloud-edge agentic systems.
major comments (2)
- [Experiments] Experiments section: no ablation isolates the cloud critic (e.g., random guidance, critic-disabled, or noisy-filter baselines). This is load-bearing for the central claim, as the design explicitly depends on the critic reliably filtering reusable experience and producing useful cross-agent guidance; without these controls the attribution of progress-rate and grounding gains to CoMIC cannot be verified.
- [Abstract and Experiments] Abstract and Experiments section: the manuscript provides no details on baselines, controls, statistical significance testing, or trajectory evaluation protocol. This prevents assessment of whether the claimed improvements on the five tasks are supported by the data.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important aspects of experimental validation that we will address in the revision to strengthen the attribution of results to the proposed framework.
read point-by-point responses
-
Referee: [Experiments] Experiments section: no ablation isolates the cloud critic (e.g., random guidance, critic-disabled, or noisy-filter baselines). This is load-bearing for the central claim, as the design explicitly depends on the critic reliably filtering reusable experience and producing useful cross-agent guidance; without these controls the attribution of progress-rate and grounding gains to CoMIC cannot be verified.
Authors: We agree that isolating the cloud critic's contribution is necessary to support the central claim. In the revised manuscript, we will add ablations including a critic-disabled baseline (local execution only) and a random-guidance baseline (unfiltered or randomized cross-agent insights). These controls will directly test whether the observed gains in progress rate and action grounding stem from the critic-driven filtering and circulation mechanism. revision: yes
-
Referee: [Abstract and Experiments] Abstract and Experiments section: the manuscript provides no details on baselines, controls, statistical significance testing, or trajectory evaluation protocol. This prevents assessment of whether the claimed improvements on the five tasks are supported by the data.
Authors: We acknowledge the absence of these details in the current version. The revised Experiments section will explicitly describe the baselines (including standard LLM agent configurations without CoMIC), the full trajectory evaluation protocol, the controls employed, and statistical significance testing (e.g., results across multiple independent runs with reported means, variances, and p-values where appropriate). revision: yes
Circularity Check
No circularity: empirical system proposal without derivations or fitted predictions
full rationale
The manuscript describes an architectural framework (Centralized Reflection, Decentralized Execution) and reports task-dependent empirical gains on five agent benchmarks. No equations, first-principles derivations, parameter-fitting steps, or predictions that reduce to inputs by construction appear in the text. Claims rest on external experimental outcomes rather than self-referential definitions or self-citation chains that close the argument. The central assumption about critic reliability is an untested empirical premise, not a circular reduction. This is the normal case of a self-contained systems paper evaluated against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Introducing apple’s on-device and server foundation models, 2025
Accessed April. Introducing apple’s on-device and server foundation models, 2025
2025
-
[2]
Cosmac: A benchmark for evaluating communication and coordination in llm-based agents
Anatolii Borzilov, Alexey Skrynnik, and Aleksandr Panov. Cosmac: A benchmark for evaluating communication and coordination in llm-based agents. InLLM-based Multi-Agent Systems: Towards Responsible, Reliable, and Scalable Agentic Systems, 2025
2025
-
[3]
Agentboard: An analytical evaluation board of multi-turn llm agents.Advances in neural information processing systems, 37:74325–74362, 2024
Ma Chang, Junlei Zhang, Zhihao Zhu, Cheng Yang, Yujiu Yang, Yaohui Jin, Zhenzhong Lan, Lingpeng Kong, and Junxian He. Agentboard: An analytical evaluation board of multi-turn llm agents.Advances in neural information processing systems, 37:74325–74362, 2024
2024
-
[4]
Devendra Singh Chaplot. Albert q. jiang, alexandre sablayrolles, arthur mensch, chris bamford, devendra singh chaplot, diego de las casas, florian bressand, gianna lengyel, guillaume lample, lucile saulnier, lélio renard lavaud, marie-anne lachaux, pierre stock, teven le scao, thibaut lavril, thomas wang, timothée lacroix, william el sayed.arXiv preprint ...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
Towards transmission-friendly and robust cnn models over cloud and device.IEEE Transactions on Mobile Computing, 22(10):6176–6189, 2022
Chuntao Ding, Zhichao Lu, Felix Juefei-Xu, Vishnu Naresh Boddeti, Yidong Li, and Jiannong Cao. Towards transmission-friendly and robust cnn models over cloud and device.IEEE Transactions on Mobile Computing, 22(10):6176–6189, 2022
2022
-
[6]
Hiagent: Hierarchical working memory management for solving long-horizon agent tasks with large lan- guage model
Mengkang Hu, Tianxing Chen, Qiguang Chen, Yao Mu, Wenqi Shao, and Ping Luo. Hiagent: Hierarchical working memory management for solving long-horizon agent tasks with large lan- guage model. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 32779–32798, 2025
2025
-
[7]
Yilong Li, Chen Qian, Yu Xia, Ruijie Shi, Yufan Dang, Zihao Xie, Ziming You, Weize Chen, Cheng Yang, Weichuan Liu, et al. Cross-task experiential learning on llm-based multi-agent collaboration.arXiv preprint arXiv:2505.23187, 2025
-
[8]
Optimizing ai service placement and resource allocation in mobile edge intelligence systems.IEEE Transactions on Wireless Communications, 20(11):7257–7271, 2021
Zehong Lin, Suzhi Bi, and Ying-Jun Angela Zhang. Optimizing ai service placement and resource allocation in mobile edge intelligence systems.IEEE Transactions on Wireless Communications, 20(11):7257–7271, 2021
2021
-
[9]
Mobilellm: Optimizing sub-billion parameter language models for on-device use cases
Zechun Liu, Changsheng Zhao, Forrest Iandola, Chen Lai, Yuandong Tian, Igor Fedorov, Yunyang Xiong, Ernie Chang, Yangyang Shi, Raghuraman Krishnamoorthi, et al. Mobilellm: Optimizing sub-billion parameter language models for on-device use cases. InForty-first International Conference on Machine Learning, 2024
2024
-
[10]
R OpenAI. Gpt-4 technical report. arxiv 2303.08774.View in Article, 2(5):1, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[11]
Mobile edge intelligence for large language models: A contemporary survey.IEEE Communications Surveys & Tutorials, 2025
Guanqiao Qu, Qiyuan Chen, Wei Wei, Zheng Lin, Xianhao Chen, and Kaibin Huang. Mobile edge intelligence for large language models: A contemporary survey.IEEE Communications Surveys & Tutorials, 2025
2025
-
[12]
Reflexion: Language agents with verbal reinforcement learning.Advances in Neural Information Processing Systems, 36:8634–8652, 2023
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning.Advances in Neural Information Processing Systems, 36:8634–8652, 2023
2023
-
[13]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[14]
A survey on large language model based autonomous agents.Frontiers of Computer Science, 18(6):186345, 2024
Lei Wang, Chen Ma, Xueyang Feng, Zeyu Zhang, Hao Yang, Jingsen Zhang, Zhiyuan Chen, Jiakai Tang, Xu Chen, Yankai Lin, et al. A survey on large language model based autonomous agents.Frontiers of Computer Science, 18(6):186345, 2024
2024
-
[15]
Transactive memory: A contemporary analysis of the group mind
Daniel M Wegner. Transactive memory: A contemporary analysis of the group mind. In Theories of group behavior, pages 185–208. Springer, 1987
1987
-
[16]
The rise and potential of large language model based agents: A survey.Science China Information Sciences, 68(2):121101, 2025
Zhiheng Xi, Wenxiang Chen, Xin Guo, Wei He, Yiwen Ding, Boyang Hong, Ming Zhang, Junzhe Wang, Senjie Jin, Enyu Zhou, et al. The rise and potential of large language model based agents: A survey.Science China Information Sciences, 68(2):121101, 2025. 10
2025
-
[17]
Agentgym: Evaluating and training large language model-based agents across diverse environments
Zhiheng Xi, Yiwen Ding, Wenxiang Chen, Boyang Hong, Honglin Guo, Junzhe Wang, Xin Guo, Dingwen Yang, Chenyang Liao, Wei He, et al. Agentgym: Evaluating and training large language model-based agents across diverse environments. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 27914–27...
2025
-
[18]
Unleashing the power of edge-cloud generative ai in mobile networks: A survey of aigc services.IEEE Communications Surveys & Tutorials, 26(2):1127–1170, 2024
Minrui Xu, Hongyang Du, Dusit Niyato, Jiawen Kang, Zehui Xiong, Shiwen Mao, Zhu Han, Abbas Jamalipour, Dong In Kim, Xuemin Shen, et al. Unleashing the power of edge-cloud generative ai in mobile networks: A survey of aigc services.IEEE Communications Surveys & Tutorials, 26(2):1127–1170, 2024
2024
-
[19]
React: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. InThe eleventh international conference on learning representations, 2022
2022
-
[20]
Enhancing llm qos through cloud- edge collaboration: A diffusion-based multi-agent reinforcement learning approach.IEEE Transactions on Services Computing, 2025
Zhi Yao, Zhiqing Tang, Wenmian Yang, and Weijia Jia. Enhancing llm qos through cloud- edge collaboration: A diffusion-based multi-agent reinforcement learning approach.IEEE Transactions on Services Computing, 2025
2025
-
[21]
Agenttuning: Enabling generalized agent abilities for llms
Aohan Zeng, Mingdao Liu, Rui Lu, Bowen Wang, Xiao Liu, Yuxiao Dong, and Jie Tang. Agenttuning: Enabling generalized agent abilities for llms. InFindings of the Association for Computational Linguistics: ACL 2024, pages 3053–3077, 2024
2024
-
[22]
A survey on the memory mechanism of large language model-based agents
Zeyu Zhang, Quanyu Dai, Xiaohe Bo, Chen Ma, Rui Li, Xu Chen, Jieming Zhu, Zhenhua Dong, and Ji-Rong Wen. A survey on the memory mechanism of large language model-based agents. ACM Transactions on Information Systems, 43(6):1–47, 2025
2025
-
[23]
Zeyu Zhang, Quanyu Dai, Rui Li, Xiaohe Bo, Xu Chen, and Zhenhua Dong. Learn to memorize: Optimizing llm-based agents with adaptive memory framework.arXiv preprint arXiv:2508.16629, 2025
-
[24]
Lixi Zhu, Xiaowen Huang, and Jitao Sang. A llm-based controllable, scalable, human-involved user simulator framework for conversational recommender systems. InProceedings of the ACM on Web Conference 2025, pages 4653–4661, 2025. 11 A Related Work LLM Agents in Cloud-Edge Systems.Cloud-based large language models (LLMs) can lever- age abundant computationa...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.