FlowOVD: Learning Generative Latent Flows for Zero-shot Open-vocabulary Detection
Pith reviewed 2026-06-28 19:08 UTC · model grok-4.3
The pith
Modeling decoder queries as a continuous latent transport process yields more expressive alignments and higher open-vocabulary detection scores.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
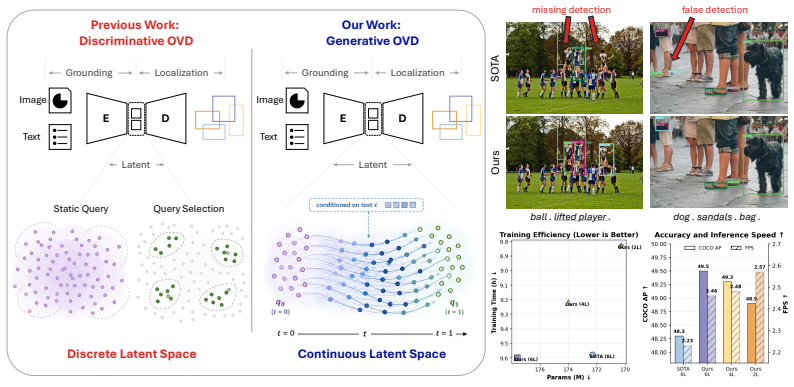
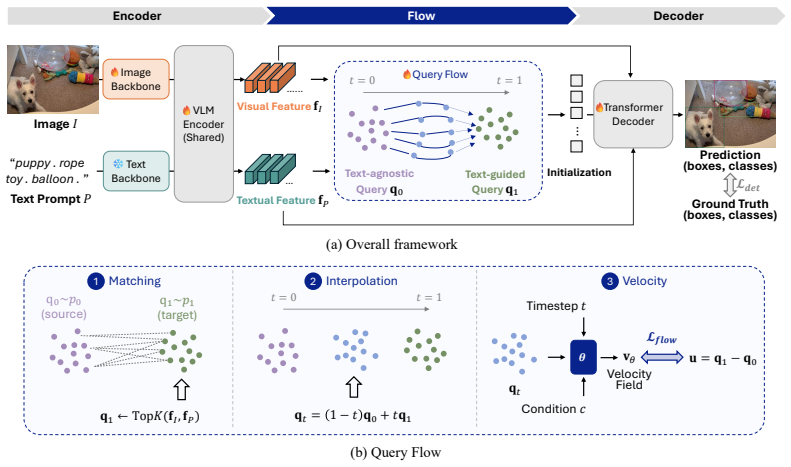
FlowOVD treats decoder query generation as a rectified-flow transport in latent space that transforms text-agnostic queries into text-guided queries; the resulting queries are fed to a VLM-based detector and produce 49.5 AP on COCO and 31.5 AP on LVIS, exceeding the discrete-query baseline GroundingDINO by 1.2 and 4.1 points respectively.
What carries the argument
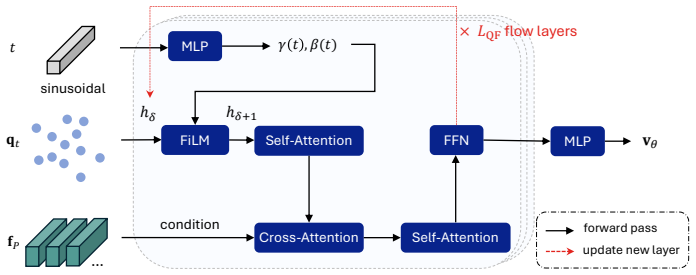
Rectified flow for text-conditioned query generation, which performs a continuous deterministic transport from a text-agnostic latent state to a text-guided state.
If this is right
- The same continuous query generation can be inserted into other query-based VLM detectors without changing their training data.
- Performance gains are largest on long-tailed category sets, suggesting the flow improves coverage of rare semantic concepts.
- No extra pre-training data is required, so the method can be applied on top of existing VLM checkpoints.
- The progressive nature of the transport avoids the need for manual design of discrete query sets or selection heuristics.
Where Pith is reading between the lines
- The flow formulation could be extended to other query-dependent tasks such as referring expression comprehension or visual grounding by reusing the same latent transport.
- Because the transport is continuous, intermediate states along the flow might serve as an explicit representation of query refinement that could be inspected or regularized.
- The method's reliance on a deterministic flow rather than stochastic diffusion leaves open whether adding controlled noise would further increase query diversity on extremely rare categories.
Load-bearing premise
The flow can be trained to produce queries whose semantic alignment is strictly more expressive than static or encoder-initialized queries without creating new failure modes or requiring additional data.
What would settle it
A controlled ablation that disables the flow (replacing it with static or encoder-initialized queries) while keeping every other component identical and still matches or exceeds the reported AP numbers on both COCO and LVIS would falsify the necessity of the continuous dynamics.
Figures




read the original abstract
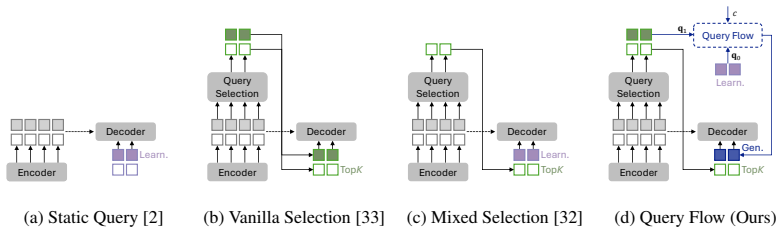
Open-vocabulary object detection (OVD) has achieved remarkable progress through large-scale vision-language pre-training. Existing methods, however, typically formulate OVD as a discriminative prediction problem, where decoder queries are either static or initialized from encoder features, thus limiting their diversity and flexibility. In this paper, we introduce a generative perspective by modeling decoder query generation as a continuous transport process in latent space. We propose FlowOVD, a text-conditioned query generation framework based on rectified flow that progressively transforms text-agnostic queries into text-guided queries. By introducing continuous latent query dynamics into a vision-language model (VLM) based detector, our method avoids heuristic discrete query construction and enables more expressive semantic alignment for open-vocabulary detection. Without requiring additional training data, FlowOVD achieves 49.5 AP on COCO and 31.5 AP on LVIS, outperforming GroundingDINO by +1.2 AP (+2.5 %) and +4.1 AP (+15.0 %), respectively. The larger gain on the challenging long-tailed LVIS benchmark further highlights the effectiveness of continuous query generation for open-vocabulary generalization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes FlowOVD, a framework that reformulates decoder query generation in VLM-based open-vocabulary detectors as a text-conditioned continuous transport process in latent space using rectified flow. Starting from text-agnostic queries, the method progressively generates text-guided queries to achieve more expressive semantic alignment, avoiding discrete heuristic query construction. It reports 49.5 AP on COCO and 31.5 AP on LVIS, outperforming GroundingDINO by +1.2 AP and +4.1 AP respectively, without additional training data, with larger gains on the long-tailed LVIS benchmark.
Significance. If the performance gains are robustly attributable to the continuous latent dynamics rather than implementation details, the work offers a generative modeling perspective on query construction that could improve flexibility and generalization in open-vocabulary detection, especially for challenging distributions. The absence of additional data requirements is a positive aspect.
major comments (2)
- [Abstract] Abstract: the reported AP improvements (+1.2 on COCO, +4.1 on LVIS) are presented as evidence for the superiority of continuous query generation, yet the abstract supplies no experimental protocol, training details, baseline configurations, error bars, ablation studies, or statistical tests. This information is load-bearing for validating the central claim that the rectified-flow transport yields strictly more expressive alignment.
- The core modeling assumption—that a rectified-flow process from text-agnostic to text-guided queries produces semantic alignment that is more expressive than static or encoder-initialized queries without introducing new failure modes—is not accompanied by direct comparisons or failure-case analysis in the provided description. This leaves the attribution of gains to the continuous dynamics unverified.
minor comments (1)
- [Abstract] The abstract would benefit from a brief statement of the number of parameters or training compute to contextualize the 'without requiring additional training data' claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comments point-by-point below, drawing on details from the full manuscript (experimental sections, tables, and ablations). We clarify that the abstract is a high-level summary while supporting evidence appears in the body.
read point-by-point responses
-
Referee: [Abstract] Abstract: the reported AP improvements (+1.2 on COCO, +4.1 on LVIS) are presented as evidence for the superiority of continuous query generation, yet the abstract supplies no experimental protocol, training details, baseline configurations, error bars, ablation studies, or statistical tests. This information is load-bearing for validating the central claim that the rectified-flow transport yields strictly more expressive alignment.
Authors: The abstract is intentionally concise and focuses on the core contribution and headline results. Full experimental protocols, training details, baseline configurations (including identical settings to GroundingDINO without extra data), and ablation studies isolating the rectified-flow component are provided in Sections 3 and 4, with quantitative results in Tables 1-3 and Section 4.3. Error bars and formal statistical tests are not included, consistent with standard practice in the field; however, the gains are consistent across COCO and the more challenging LVIS benchmark. We can add a brief clause to the abstract referencing the evaluation protocol if space permits. revision: partial
-
Referee: The core modeling assumption—that a rectified-flow process from text-agnostic to text-guided queries produces semantic alignment that is more expressive than static or encoder-initialized queries without introducing new failure modes—is not accompanied by direct comparisons or failure-case analysis in the provided description. This leaves the attribution of gains to the continuous dynamics unverified.
Authors: The full manuscript contains direct comparisons in Tables 1 and 2 against both static query baselines and encoder-initialized variants (e.g., GroundingDINO), with larger relative gains on long-tailed LVIS supporting the benefit of continuous dynamics. Section 4.3 presents ablations that isolate the rectified-flow transport from other components. Qualitative failure-case analysis and limitations are discussed in Section 5 and the supplementary material. We can expand the failure-mode discussion in the revision to strengthen attribution. revision: partial
Circularity Check
No significant circularity detected
full rationale
The paper presents FlowOVD as an independent modeling choice that replaces static or encoder-initialized decoder queries with a rectified-flow transport process in latent space to generate text-guided queries. No equations, fitted parameters, or self-citations are shown in the provided text that reduce the claimed performance gains or the generative formulation to a re-expression of the input data or prior results by construction. The central claim rests on the architectural decision to model query generation as continuous dynamics, which is not tautological with the OVD task definition or the reported benchmarks. This is the most common honest finding for papers that introduce a new generative mechanism without internal reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Enis Baty, CP Bridges, and Simon Hadfield. Flowdet: Unifying object detection and generative transport flows.arXiv preprint arXiv:2512.16771, 2025
-
[2]
End-to-end object detection with transformers
Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko. End-to-end object detection with transformers. InEuropean conference on computer vision, pages 213–229. Springer, 2020
2020
-
[3]
Diffusiondet: Diffusion model for object detection
Shoufa Chen, Peize Sun, Yibing Song, and Ping Luo. Diffusiondet: Diffusion model for object detection. InProceedings of the IEEE/CVF international conference on computer vision, pages 19830–19843, 2023
2023
-
[4]
Yolo- world: Real-time open-vocabulary object detection
Tianheng Cheng, Lin Song, Yixiao Ge, Wenyu Liu, Xinggang Wang, and Ying Shan. Yolo- world: Real-time open-vocabulary object detection. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16901–16911, 2024
2024
-
[5]
Dynamic head: Unifying object detection heads with attentions
Xiyang Dai, Yinpeng Chen, Bin Xiao, Dongdong Chen, Mengchen Liu, Lu Yuan, and Lei Zhang. Dynamic head: Unifying object detection heads with attentions. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 7373–7382, 2021
2021
-
[6]
Bert: Pre-training of deep bidirectional transformers for language understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. InProceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers), pages 4171–4186, 2019
2019
-
[7]
Generative adversarial nets.Advances in neural information processing systems, 27, 2014
Ian J Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets.Advances in neural information processing systems, 27, 2014
2014
-
[8]
Lvis: A dataset for large vocabulary instance segmentation
Agrim Gupta, Piotr Dollar, and Ross Girshick. Lvis: A dataset for large vocabulary instance segmentation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5356–5364, 2019
2019
-
[9]
Mask r-cnn
Kaiming He, Georgia Gkioxari, Piotr Dollár, and Ross Girshick. Mask r-cnn. InProceedings of the IEEE international conference on computer vision, pages 2961–2969, 2017
2017
-
[10]
Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
2020
-
[11]
Mdetr-modulated detection for end-to-end multi-modal understanding
Aishwarya Kamath, Mannat Singh, Yann LeCun, Gabriel Synnaeve, Ishan Misra, and Nicolas Carion. Mdetr-modulated detection for end-to-end multi-modal understanding. InProceedings of the IEEE/CVF international conference on computer vision, pages 1780–1790, 2021
2021
-
[12]
Grounded language-image pre-training
Liunian Harold Li, Pengchuan Zhang, Haotian Zhang, Jianwei Yang, Chunyuan Li, Yiwu Zhong, Lijuan Wang, Lu Yuan, Lei Zhang, Jenq-Neng Hwang, et al. Grounded language-image pre-training. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10965–10975, 2022
2022
-
[13]
Focal loss for dense object detection
Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, and Piotr Dollár. Focal loss for dense object detection. InProceedings of the IEEE international conference on computer vision, pages 2980–2988, 2017
2017
-
[14]
Microsoft coco: Common objects in context
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco: Common objects in context. InEuropean conference on computer vision, pages 740–755. Springer, 2014
2014
-
[15]
Flow Matching for Generative Modeling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[16]
Grounding dino: Marrying dino with grounded pre-training for open-set object detection
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Qing Jiang, Chunyuan Li, Jianwei Yang, Hang Su, et al. Grounding dino: Marrying dino with grounded pre-training for open-set object detection. InEuropean conference on computer vision, pages 38–55. Springer, 2024. 10
2024
-
[17]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow.arXiv preprint arXiv:2209.03003, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[18]
Swin transformer: Hierarchical vision transformer using shifted windows
Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. Swin transformer: Hierarchical vision transformer using shifted windows. InProceedings of the IEEE/CVF international conference on computer vision, pages 10012–10022, 2021
2021
-
[19]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[20]
Dynamic-dino: Fine-grained mixture of experts tuning for real-time open-vocabulary object detection
Yehao Lu, Minghe Weng, Zekang Xiao, Rui Jiang, Wei Su, Guangcong Zheng, Ping Lu, and Xi Li. Dynamic-dino: Fine-grained mixture of experts tuning for real-time open-vocabulary object detection. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 20847–20856, 2025
2025
-
[21]
Film: Visual reasoning with a general conditioning layer
Ethan Perez, Florian Strub, Harm De Vries, Vincent Dumoulin, and Aaron Courville. Film: Visual reasoning with a general conditioning layer. InProceedings of the AAAI conference on artificial intelligence, volume 32, 2018
2018
-
[22]
You only look once: Unified, real-time object detection
Joseph Redmon, Santosh Divvala, Ross Girshick, and Ali Farhadi. You only look once: Unified, real-time object detection. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 779–788, 2016
2016
-
[23]
Yolo9000: better, faster, stronger
Joseph Redmon and Ali Farhadi. Yolo9000: better, faster, stronger. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 7263–7271, 2017
2017
-
[24]
Faster r-cnn: Towards real-time object detection with region proposal networks.Advances in neural information processing systems, 28, 2015
Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun. Faster r-cnn: Towards real-time object detection with region proposal networks.Advances in neural information processing systems, 28, 2015
2015
-
[25]
Tianhe Ren, Qing Jiang, Shilong Liu, Zhaoyang Zeng, Wenlong Liu, Han Gao, Hongjie Huang, Zhengyu Ma, Xiaoke Jiang, Yihao Chen, et al. Grounding dino 1.5: Advance the" edge" of open-set object detection.arXiv preprint arXiv:2405.10300, 2024
-
[26]
Generalized intersection over union: A metric and a loss for bounding box regression
Hamid Rezatofighi, Nathan Tsoi, JunYoung Gwak, Amir Sadeghian, Ian Reid, and Silvio Savarese. Generalized intersection over union: A metric and a loss for bounding box regression. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 658–666, 2019
2019
-
[27]
Variational inference with normalizing flows
Danilo Rezende and Shakir Mohamed. Variational inference with normalizing flows. In International conference on machine learning, pages 1530–1538. PMLR, 2015
2015
-
[28]
Objects365: A large-scale, high-quality dataset for object detection
Shuai Shao, Zeming Li, Tianyuan Zhang, Chao Peng, Gang Yu, Xiangyu Zhang, Jing Li, and Jian Sun. Objects365: A large-scale, high-quality dataset for object detection. InProceedings of the IEEE/CVF international conference on computer vision, pages 8430–8439, 2019
2019
-
[29]
Benchmarking object detectors with coco: A new path forward
Shweta Singh, Aayan Yadav, Jitesh Jain, Humphrey Shi, Justin Johnson, and Karan Desai. Benchmarking object detectors with coco: A new path forward. InEuropean Conference on Computer Vision, pages 279–295. Springer, 2024
2024
-
[30]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017
2017
-
[31]
Zanyi Wang, Dengyang Jiang, Liuzhuozheng Li, Sizhe Dang, Chengzu Li, Harry Yang, Guang Dai, Mengmeng Wang, and Jingdong Wang. Deforming videos to masks: Flow matching for referring video segmentation.arXiv preprint arXiv:2510.06139, 2025
-
[32]
DINO: DETR with Improved DeNoising Anchor Boxes for End-to-End Object Detection
Hao Zhang, Feng Li, Shilong Liu, Lei Zhang, Hang Su, Jun Zhu, Lionel M Ni, and Heung- Yeung Shum. Dino: Detr with improved denoising anchor boxes for end-to-end object detection. arXiv preprint arXiv:2203.03605, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[33]
Deformable DETR: Deformable Transformers for End-to-End Object Detection
Xizhou Zhu, Weijie Su, Lewei Lu, Bin Li, Xiaogang Wang, and Jifeng Dai. Deformable detr: Deformable transformers for end-to-end object detection.arXiv preprint arXiv:2010.04159, 2020. 11 A Additional Details A.1 Dataset Details Our FlowOVD is evaluated on diverse benchmarks in a zero-shot setting. The COCO [14] dataset is a widely used benchmark. It conta...
work page internal anchor Pith review Pith/arXiv arXiv 2010
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.