Safe-Subspace Pseudo-Label Refinement for Source-Free Graph Domain Adaptation
Pith reviewed 2026-06-28 19:18 UTC · model grok-4.3
The pith
A safe subspace lets source-free graph adaptation use reliable pseudo-labels by restricting hard supervision to samples with both semantic and structural support.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that a confidence-consistent safe subspace exists on which pseudo-label noise can be controlled under restricted posterior discrepancy, and that applying hard supervision only inside this subspace while using noise-tolerant soft regularization on the uncertain remainder produces robust adaptation without any source-graph access.
What carries the argument
The confidence-consistent safe subspace, which isolates target samples supported by both semantic committee evidence and intrinsic structural consistency so that hard pseudo-labels remain reliable.
If this is right
- Hard pseudo-label supervision is applied only where semantic reliability and neighborhood consistency both hold.
- Source graphs remain inaccessible throughout adaptation.
- Uncertain samples receive soft regularization instead of unreliable hard labels.
- The resulting method reports competitive accuracy on image and real-world graph benchmarks under multiple domain-shift types.
Where Pith is reading between the lines
- The safe-subspace selection principle could be tested in non-graph source-free adaptation settings.
- The approach may reduce reliance on source data in privacy-restricted applications.
- Dynamic re-estimation of the safe subspace across training epochs is a natural next measurement.
Load-bearing premise
A confidence-consistent safe subspace exists on which pseudo-label noise stays controllable under restricted posterior discrepancy.
What would settle it
An experiment in which no identifiable subspace yields lower adaptation error than applying hard pseudo-labels to the entire target set.
Figures
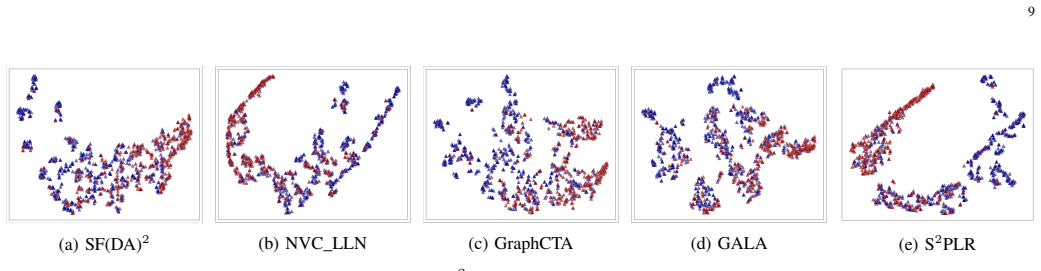
read the original abstract
Source-free graph domain adaptation (SF-GDA) aims to adapt source-trained graph models to unlabeled target graphs when source graphs are no longer accessible. A central obstacle is pseudo-label reliability: under feature and topological shifts, source-induced predictions may become confidently wrong, and indiscriminate self-training can amplify systematic errors through graph message passing. This paper studies SF-GDA from a selective pseudo-labeling perspective. Instead of assuming globally bounded pseudo-label noise over the entire target domain, we identify a confidence-consistent safe subspace on which pseudo-label noise can be controlled under restricted posterior discrepancy, and derive a target-risk decomposition that separates safe-subspace fitting error, selected-label noise, and uncertain-set risk. Guided by this analysis, we propose SafeSubspace Pseudo-Label Refinement (S$^2$PLR), a source-free graph adaptation framework that applies hard pseudo-label supervision only to target graphs supported by both semantic and structural evidence. Specifically, S$^2$PLR estimates semantic reliability using source-committee confidence and disagreement, learns a targetintrinsic structural representation via graph contrastive learning, verifies pseudo-labels through neighborhood consistency, and exploits the remaining uncertain samples with noise-tolerant soft regularization rather than unreliable hard labels. Experiments on image and real-world graph benchmarks under different domain shifts demonstrate that S$^2$PLR achieves robust and competitive performance across diverse source-free transfer settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Safe-Subspace Pseudo-Label Refinement (S²PLR) for source-free graph domain adaptation. It identifies a confidence-consistent safe subspace on target graphs using source-committee confidence and disagreement together with target-intrinsic checks (graph contrastive learning and neighborhood consistency). A target-risk decomposition is derived that separates safe-subspace fitting error, selected-label noise, and uncertain-set risk; hard pseudo-label supervision is applied only inside the safe subspace while uncertain samples receive noise-tolerant soft regularization. Experiments on image and real-world graph benchmarks under various domain shifts report competitive performance.
Significance. If the risk decomposition and safe-subspace construction are valid, the work supplies a principled selective mechanism for controlling pseudo-label noise in SF-GDA without source data access. The explicit separation of risk terms and the combination of semantic and structural evidence are potentially useful contributions to graph domain adaptation.
major comments (1)
- [§3.2] §3.2 (target-risk decomposition): the claim that pseudo-label noise is controlled under restricted posterior discrepancy in the identified safe subspace is load-bearing for cleanly separating the three risk terms. The construction (committee confidence + contrastive learning + neighborhood consistency) does not include explicit bounds showing that topological shifts cannot produce large posterior discrepancy even on high-confidence nodes; without such bounds or a verification procedure the decomposition's separation guarantee is not established.
minor comments (2)
- [Abstract] Abstract: 'targetintrinsic' should be hyphenated as 'target-intrinsic'.
- [§3] Notation for the safe-subspace indicator and the posterior-discrepancy term should be introduced once with a clear definition before being used in the risk decomposition.
Simulated Author's Rebuttal
We thank the referee for the constructive comment on the target-risk decomposition. We address the concern point by point below.
read point-by-point responses
-
Referee: [§3.2] §3.2 (target-risk decomposition): the claim that pseudo-label noise is controlled under restricted posterior discrepancy in the identified safe subspace is load-bearing for cleanly separating the three risk terms. The construction (committee confidence + contrastive learning + neighborhood consistency) does not include explicit bounds showing that topological shifts cannot produce large posterior discrepancy even on high-confidence nodes; without such bounds or a verification procedure the decomposition's separation guarantee is not established.
Authors: The decomposition is explicitly derived under the assumption of restricted posterior discrepancy within the safe subspace, which enables separation of the three risk terms. The multi-signal construction (committee confidence/disagreement, contrastive learning, neighborhood consistency) is intended to identify nodes satisfying this assumption in practice. We do not provide explicit theoretical bounds proving that the criteria prevent large posterior discrepancy under arbitrary topological shifts; the separation guarantee therefore rests on the modeling assumption rather than a proven bound. In revision we will clarify this assumption in §3.2 and add an explicit statement that formal bounds are not derived. revision: partial
Circularity Check
No significant circularity detected
full rationale
The provided abstract and context describe a target-risk decomposition that separates safe-subspace fitting error, selected-label noise, and uncertain-set risk under an assumption of restricted posterior discrepancy on an identified subspace. The subspace is constructed explicitly via source-committee confidence/disagreement, graph contrastive learning, and neighborhood consistency checks. No equations or self-citations are available to exhibit a reduction of any prediction or result to its inputs by construction (e.g., no fitted parameter renamed as prediction, no self-definitional loop, no load-bearing self-citation chain). The derivation supplies independent analytical content guiding selective pseudo-labeling rather than tautologically restating the method inputs. This is the normal case of a self-contained framework.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A confidence-consistent safe subspace exists on which pseudo-label noise can be controlled under restricted posterior discrepancy.
Reference graph
Works this paper leans on
-
[1]
Transferable representation learning with deep adapta- tion networks,
M. Long, Y . Cao, Z. Cao, J. Wang, and M. I. Jordan, “Transferable representation learning with deep adapta- tion networks,”IEEE transactions on pattern analysis and machine intelligence, vol. 41, no. 12, pp. 3071–3085, 2018
2018
-
[2]
A comprehensive survey on graph neural networks,
Z. Wu, S. Pan, F. Chen, G. Long, C. Zhang, and S. Y . Philip, “A comprehensive survey on graph neural networks,”IEEE Transactions on Neural Networks and Learning Systems, vol. 32, no. 1, pp. 4–24, 2020
2020
-
[3]
Self- supervised learning of graph neural networks: A unified review,
Y . Xie, Z. Xu, J. Zhang, Z. Wang, and S. Ji, “Self- supervised learning of graph neural networks: A unified review,”IEEE transactions on pattern analysis and ma- chine intelligence, vol. 45, no. 2, pp. 2412–2429, 2022
2022
-
[4]
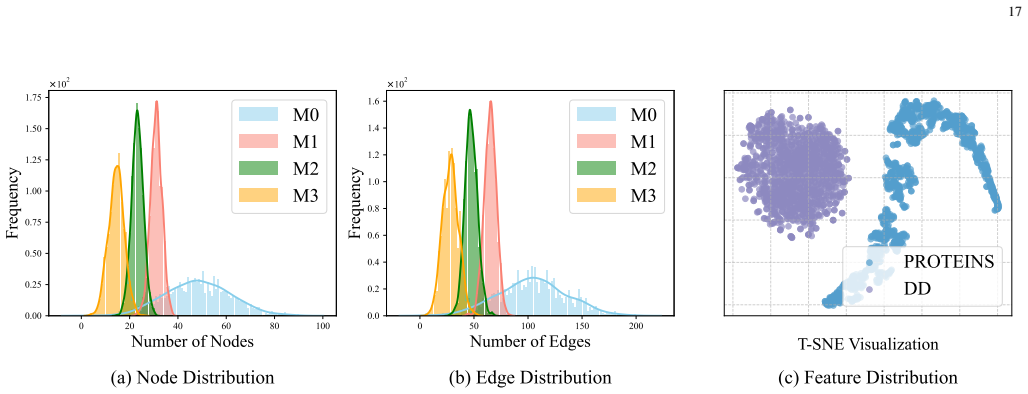
Empowering graph rep- resentation learning with test-time graph transformation
W. Jin, T. Zhao, J. Ding, Y . Liu, J. Tang, and N. Shah, “Empowering graph representation learning with test-time graph transformation,”arXiv preprint arXiv:2210.03561, 2022
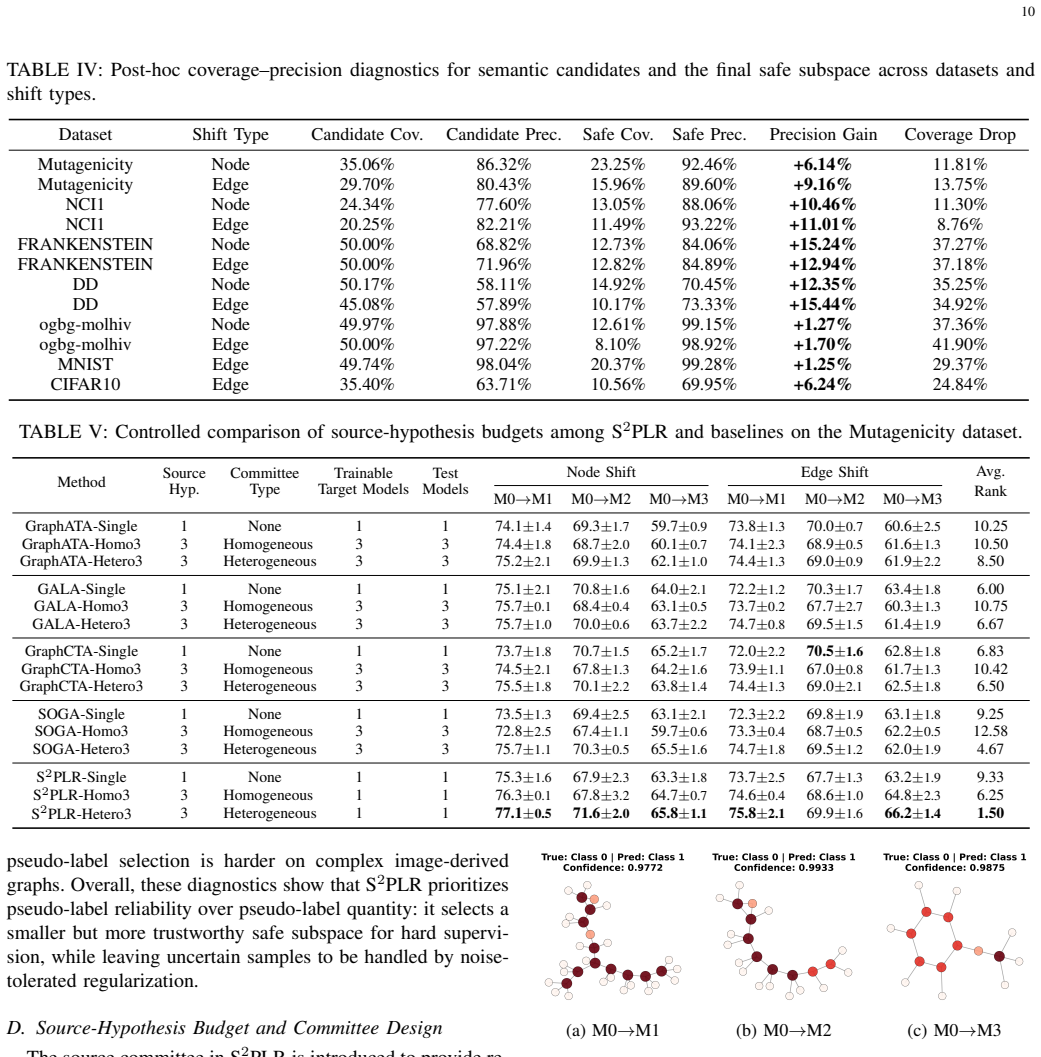
-
[5]
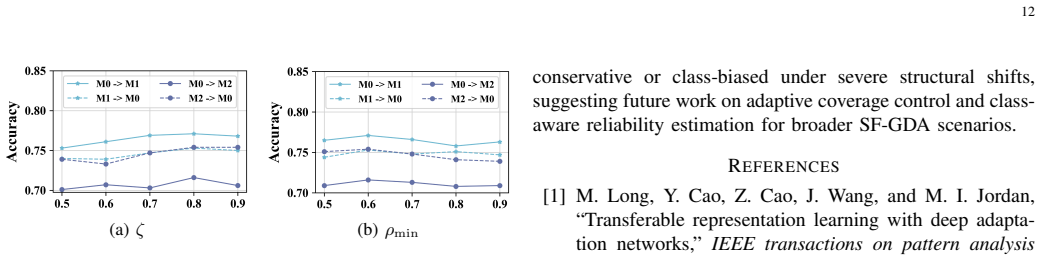
Graph structure learning for robust graph neural networks,
W. Jin, Y . Ma, X. Liu, X. Tang, S. Wang, and J. Tang, “Graph structure learning for robust graph neural networks,” inProceedings of the International ACM SIGKDD Conference on Knowledge Discovery & Data Mining, 2020, pp. 66–74
2020
-
[6]
Degree distribution based spiking graph networks for domain adaptation,
Y . Wang, S. Liu, M. Wang, S. Liang, and N. Yin, “Degree distribution based spiking graph networks for domain adaptation,”arXiv preprint arXiv:2410.06883, 2024
-
[7]
Revisiting, benchmarking and understanding unsuper- vised graph domain adaptation,
M. Liu, Z. Zhang, J. Tang, J. Bu, B. He, and S. Zhou, “Revisiting, benchmarking and understanding unsuper- vised graph domain adaptation,”Proceedings of the Conference on Neural Information Processing Systems, vol. 37, pp. 89 408–89 436, 2024
2024
-
[8]
Coco: A coupled contrastive frame- work for unsupervised domain adaptive graph classifica- tion,
N. Yin, L. Shen, M. Wang, L. Lan, Z. Ma, C. Chen, X.-S. Hua, and X. Luo, “Coco: A coupled contrastive frame- work for unsupervised domain adaptive graph classifica- tion,” inProceedings of the International Conference on Machine Learning, 2023, pp. 40 040–40 053
2023
-
[9]
DSBD: Dual-Aligned Structural Basis Distillation for Graph Domain Adaptation
Y . Wang, K. Zhang, J. Huang, M. Wang, M. Xiao, S. Gao, and N. Yin, “Dsbd: Dual-aligned structural basis distillation for graph domain adaptation,”arXiv preprint arXiv:2604.03154, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[10]
DisRFM: Polar Riemannian Flow Matching for Structure-Preserving Graph Domain Adaptation
Y . Wang, X. Liu, M. Wang, S. Gao, and N. Yin, “Rie- mannian flow matching for disentangled graph domain adaptation,”arXiv preprint arXiv:2602.00656, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[11]
A com- prehensive survey on source-free domain adaptation,
J. Li, Z. Yu, Z. Du, L. Zhu, and H. T. Shen, “A com- prehensive survey on source-free domain adaptation,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 46, no. 8, pp. 5743–5762, 2024
2024
-
[12]
Stable neighbor denoising for source-free domain adaptive segmentation,
D. Zhao, S. Wang, Q. Zang, L. Jiao, N. Sebe, and Z. Zhong, “Stable neighbor denoising for source-free domain adaptive segmentation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 23 416–23 427
2024
-
[13]
Source-free domain adaptation with frozen multimodal foundation model,
S. Tang, W. Su, M. Ye, and X. Zhu, “Source-free domain adaptation with frozen multimodal foundation model,” 13 inThe IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 23 711–23 720
2024
-
[14]
Domain adaptation without source data,
Y . Kim, D. Cho, K. Han, P. Panda, and S. Hong, “Domain adaptation without source data,”IEEE Transactions on Artificial Intelligence, vol. 2, no. 6, pp. 508–518, 2021
2021
-
[15]
Source free graph unsupervised domain adaptation,
H. Mao, L. Du, Y . Zheng, Q. Fu, Z. Li, X. Chen, S. Han, and D. Zhang, “Source free graph unsupervised domain adaptation,” inProceedings of the International ACM Conference on Web Search & Data Mining, 2024, pp. 520–528
2024
-
[16]
Gala: Graph diffusion-based alignment with jigsaw for source-free domain adaptation,
J. Luo, Y . Gu, X. Luo, W. Ju, Z. Xiao, Y . Zhao, J. Yuan, and M. Zhang, “Gala: Graph diffusion-based alignment with jigsaw for source-free domain adaptation,”IEEE Transactions on Pattern Analysis and Machine Intelli- gence, vol. 46, no. 12, pp. 9038–9051, 2024
2024
-
[17]
Rank and align: Towards effec- tive source-free graph domain adaptation,
J. Luo, Z. Xiao, Y . Wang, X. Luo, J. Yuan, W. Ju, L. Liu, and M. Zhang, “Rank and align: Towards effec- tive source-free graph domain adaptation,”arXiv preprint arXiv:2408.12185, 2024
-
[18]
Nested graph pseudo-label refinement for noisy label domain adaptation learning,
Y . Wang, M. Wang, Z. Huang, S. Liu, and N. Yin, “Nested graph pseudo-label refinement for noisy label domain adaptation learning,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 40, no. 31, 2026, pp. 26 697–26 705
2026
-
[19]
When source-free domain adap- tation meets learning with noisy labels,
L. Yi, G. Xu, P. Xu, J. Li, R. Pu, C. Ling, A. I. McLeod, and B. Wang, “When source-free domain adap- tation meets learning with noisy labels,”arXiv preprint arXiv:2301.13381, 2023
-
[20]
Unraveling the mysteries of label noise in source-free domain adaptation: Theory and practice,
G. Xu, L. Yi, P. Xu, J. Li, R. Pu, C. Shui, C. Ling, A. I. McLeod, and B. Wang, “Unraveling the mysteries of label noise in source-free domain adaptation: Theory and practice,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
2025
-
[21]
Tackling noisy labels with network parameter additive decomposition,
J. Wang, X. Xia, L. Lan, X. Wu, J. Yu, W. Yang, B. Han, and T. Liu, “Tackling noisy labels with network parameter additive decomposition,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 46, no. 9, pp. 6341–6354, 2024
2024
-
[22]
Ex- ploiting the intrinsic neighborhood structure for source- free domain adaptation,
S. Yang, J. Van de Weijer, L. Herranz, S. Juiet al., “Ex- ploiting the intrinsic neighborhood structure for source- free domain adaptation,”Advances in neural information processing systems, vol. 34, pp. 29 393–29 405, 2021
2021
-
[23]
Universal source-free domain adaptation,
J. N. Kundu, N. Venkat, R. V . Babuet al., “Universal source-free domain adaptation,” inThe IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, 2020, pp. 4544–4553
2020
-
[24]
Generalized source-free domain adaptation,
S. Yang, Y . Wang, J. Van De Weijer, L. Herranz, and S. Jui, “Generalized source-free domain adaptation,” in The IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 8978–8987
2021
-
[25]
Fg- plfa: Fine-grained pseudo-labeling and feature alignment for source-free unsupervised domain adaptation,
Z. Wen, Q. Li, Y . Wang, H. Shao, and G. Sun, “Fg- plfa: Fine-grained pseudo-labeling and feature alignment for source-free unsupervised domain adaptation,”IEEE Transactions on Neural Networks and Learning Systems, 2025
2025
-
[26]
Lead: Learning decomposition for source- free universal domain adaptation,
S. Qu, T. Zou, L. He, F. R ¨ohrbein, A. Knoll, G. Chen, and C. Jiang, “Lead: Learning decomposition for source- free universal domain adaptation,” inThe IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 23 334–23 343
2024
-
[27]
arXiv preprint arXiv:2602.08431 (2026)
Y . Wang, K. Zhang, M. Wang, S. Gao, and N. Yin, “Usbd: Universal structural basis distillation for source-free graph domain adaptation,”arXiv preprint arXiv:2602.08431, 2026
-
[28]
Sf(da) 2: Source-free domain adaptation through the lens of data augmentation,
U. Hwang, J. Lee, J. Shin, and S. Yoon, “Sf(da) 2: Source-free domain adaptation through the lens of data augmentation,”arXiv preprint arXiv:2403.10834, 2024
-
[29]
Adaptive adversar- ial network for source-free domain adaptation,
H. Xia, H. Zhao, and Z. Ding, “Adaptive adversar- ial network for source-free domain adaptation,” inThe IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 9010–9019
2021
-
[30]
Uncertainty-guided source-free domain adaptation,
S. Roy, M. Trapp, A. Pilzer, J. Kannala, N. Sebe, E. Ricci, and A. Solin, “Uncertainty-guided source-free domain adaptation,” inEuropean conference on computer vision. Springer, 2022, pp. 537–555
2022
-
[31]
Samgpt: Text-free graph foundation model for multi- domain pre-training and cross-domain adaptation,
X. Yu, Z. Gong, C. Zhou, Y . Fang, and H. Zhang, “Samgpt: Text-free graph foundation model for multi- domain pre-training and cross-domain adaptation,” in Proceedings of the ACM Web Conference, 2025, pp. 1142–1153
2025
-
[32]
Aggregate to adapt: Node-centric aggregation for multi-source-free graph domain adapta- tion,
Z. Zhang and B. He, “Aggregate to adapt: Node-centric aggregation for multi-source-free graph domain adapta- tion,” inProceedings of the ACM Web Conference, 2025, pp. 4420–4431
2025
-
[33]
Robust cross supervision with target mining for source-free graph domain adaptation,
J. Luo, H. Tao, X. Luo, Y . Zhao, Z. Xiao, D. He, W. Ju, C. Chen, X.-S. Hua, and M. Zhang, “Robust cross supervision with target mining for source-free graph domain adaptation,”IEEE Transactions on Knowledge and Data Engineering, 2026
2026
-
[34]
Source-free progressive graph learning for open-set domain adaptation,
Y . Luo, Z. Wang, Z. Chen, Z. Huang, and M. Bak- tashmotlagh, “Source-free progressive graph learning for open-set domain adaptation,”IEEE Transactions on Pat- tern Analysis and Machine Intelligence, vol. 45, no. 9, pp. 11 240–11 255, 2023
2023
-
[35]
To-ugda: target-oriented unsupervised graph domain adaptation,
Z. Zeng, J. Xie, Z. Yang, T. Ma, and D. Chen, “To-ugda: target-oriented unsupervised graph domain adaptation,” Scientific Reports, vol. 14, no. 1, p. 9165, 2024
2024
-
[36]
Smoothness really matters: A simple yet effective approach for unsupervised graph domain adaptation,
W. Chen, G. Ye, Y . Wang, Z. Zhang, L. Zhang, D. Wang, Z. Zhang, and F. Zhuang, “Smoothness really matters: A simple yet effective approach for unsupervised graph domain adaptation,” inProceedings of the AAAI Confer- ence on Artificial Intelligence, vol. 39, no. 15, 2025, pp. 15 875–15 883
2025
-
[37]
A parametrical model for instance-dependent label noise,
S. Yang, S. Wu, E. Yang, B. Han, Y . Liu, M. Xu, G. Niu, and T. Liu, “A parametrical model for instance-dependent label noise,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 45, no. 12, pp. 14 055–14 068, 2023
2023
-
[38]
Robust node classification on graph data with graph and label noise,
Y . Zhu, L. Feng, Z. Deng, Y . Chen, R. Amor, and M. Witbrock, “Robust node classification on graph data with graph and label noise,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 38, 2024, pp. 17 220–17 227
2024
-
[39]
Learning from noisy labels with deep neural networks: A survey,
H. Song, M. Kim, D. Park, Y . Shin, and J.-G. Lee, “Learning from noisy labels with deep neural networks: A survey,”IEEE transactions on neural networks and 14 learning systems, vol. 34, no. 11, pp. 8135–8153, 2022
2022
-
[40]
A survey of label-noise representa- tion learning: Past, present and future,
B. Han, Q. Yao, T. Liu, G. Niu, I. W. Tsang, J. T. Kwok, and M. Sugiyama, “A survey of label-noise representa- tion learning: Past, present and future,”arXiv preprint arXiv:2011.04406, 2020
-
[41]
Sport: A subgraph perspective on graph classification with label noise,
N. Yin, L. Shen, C. Chen, X.-S. Hua, and X. Luo, “Sport: A subgraph perspective on graph classification with label noise,”ACM Transactions on Knowledge Discovery from Data, vol. 18, no. 9, pp. 1–20, 2024
2024
-
[42]
Learning from noisy exam- ples,
D. Angluin and P. Laird, “Learning from noisy exam- ples,”Machine learning, vol. 2, no. 4, pp. 343–370, 1988
1988
-
[43]
Learning with noisy labels,
N. Natarajan, I. S. Dhillon, P. K. Ravikumar, and A. Tewari, “Learning with noisy labels,”Advances in neural information processing systems, vol. 26, 2013
2013
-
[44]
Gradient-based learning applied to document recogni- tion,
Y . LeCun, L. Bottou, Y . Bengio, and P. Haffner, “Gradient-based learning applied to document recogni- tion,”Proceedings of the IEEE, 2002
2002
-
[45]
Learning multiple layers of features from tiny images,
A. Krizhevsky, G. Hintonet al., “Learning multiple layers of features from tiny images,” 2009
2009
-
[46]
Dream: a dual variational framework for unsuper- vised graph domain adaptation,
N. Yin, L. Shen, M. Wang, X. Liu, C. Chen, and X.-S. Hua, “Dream: a dual variational framework for unsuper- vised graph domain adaptation,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
2025
-
[47]
Weisfeiler-lehman graph kernels
N. Shervashidze, P. Schweitzer, E. J. Van Leeuwen, K. Mehlhorn, and K. M. Borgwardt, “Weisfeiler-lehman graph kernels.”Journal of Machine Learning Research, vol. 12, no. 9, 2011
2011
-
[48]
Semi-supervised classifica- tion with graph convolutional networks,
T. N. Kipf and M. Welling, “Semi-supervised classifica- tion with graph convolutional networks,” inProceedings of the International Conference on Machine Learning, 2017
2017
-
[49]
How powerful are graph neural networks?
K. Xu, W. Hu, J. Leskovec, and S. Jegelka, “How powerful are graph neural networks?” inProceedings of the International Conference on Machine Learning, 2018
2018
-
[50]
Weisfeiler and lehman go cellular: Cw networks,
C. Bodnar, F. Frasca, N. Otter, Y . Wang, P. Lio, G. F. Montufar, and M. Bronstein, “Weisfeiler and lehman go cellular: Cw networks,”Proceedings of the Conference on Neural Information Processing Systems, vol. 34, pp. 2625–2640, 2021
2021
-
[51]
Accurate learning of graph representations with graph multiset pooling,
J. Baek, M. Kang, and S. J. Hwang, “Accurate learning of graph representations with graph multiset pooling,” arXiv preprint arXiv:2102.11533, 2021
-
[52]
Path neural networks: Expressive and accurate graph neural networks,
G. Michel, G. Nikolentzos, J. F. Lutzeyer, and M. Vazir- giannis, “Path neural networks: Expressive and accurate graph neural networks,” inProceedings of the Interna- tional Conference on Machine Learning. PMLR, 2023, pp. 24 737–24 755
2023
-
[53]
Revisiting source-free domain adaptation: a new per- spective via uncertainty control,
G. Xu, H. Guo, L. Yi, C. Ling, B. Wang, and G. Yi, “Revisiting source-free domain adaptation: a new per- spective via uncertainty control,” inProceedings of the International Conference on Learning Representations, vol. 2025, 2025, pp. 92 900–92 939
2025
-
[54]
Collaborate to adapt: Source-free graph domain adaptation via bi-directional adaptation,
Z. Zhang, M. Liu, A. Wang, H. Chen, Z. Li, J. Bu, and B. He, “Collaborate to adapt: Source-free graph domain adaptation via bi-directional adaptation,” inProceedings of the ACM Web Conference, 2024, pp. 664–675
2024
-
[55]
Deal: An unsupervised domain adaptive framework for graph-level classification,
N. Yin, L. Shen, B. Li, M. Wang, X. Luo, C. Chen, Z. Luo, and X.-S. Hua, “Deal: An unsupervised domain adaptive framework for graph-level classification,” in Proceedings of the ACM International Conference on Multimedia, 2022, pp. 3470–3479
2022
-
[56]
Distinguishing enzyme structures from non-enzymes without alignments,
P. D. Dobson and A. J. Doig, “Distinguishing enzyme structures from non-enzymes without alignments,”Jour- nal of molecular biology, vol. 330, no. 4, pp. 771–783, 2003
2003
-
[57]
Comparison of descriptor spaces for chemical compound retrieval and classification,
N. Wale, I. A. Watson, and G. Karypis, “Comparison of descriptor spaces for chemical compound retrieval and classification,”Knowledge and Information Systems, vol. 14, pp. 347–375, 2008
2008
-
[58]
Derivation and validation of toxicophores for mutagenicity prediction,
J. Kazius, R. McGuire, and R. Bursi, “Derivation and validation of toxicophores for mutagenicity prediction,” Journal of medicinal chemistry, vol. 48, no. 1, pp. 312– 320, 2005
2005
-
[59]
Graph invari- ant kernels,
F. Orsini, P. Frasconi, and L. De Raedt, “Graph invari- ant kernels,” inProceedings of the International Joint Conference on Artificial Intelligence, 2015
2015
-
[60]
Ogb-lsc: A large-scale challenge for machine learning on graphs,
W. Hu, M. Fey, H. Ren, M. Nakata, Y . Dong, and J. Leskovec, “Ogb-lsc: A large-scale challenge for machine learning on graphs,”arXiv preprint arXiv:2103.09430, 2021
-
[61]
Benchmarking graph neural networks,
V . P. Dwivedi, C. K. Joshi, A. T. Luu, T. Laurent, Y . Bengio, and X. Bresson, “Benchmarking graph neural networks,”The Journal of Machine Learning Research., 2023. 15 APPENDIX This appendix provides detailed proofs, implementation details, and additional experimental protocols for S 2PLR. The notation follows Sections III-E–IV. The purpose of the append...
2023
-
[62]
By the definition of the safe subspace in Eq
Proof of Theorem 2:Letx∈ H τ,ρ and denote its pseudo-label byc= ˜y(x). By the definition of the safe subspace in Eq. (1), we have pS(c|x) =s(x)≥τ.(21) Assumption 1 then gives pT (c|x)≥p S(c|x)−β τ(α)≥τ−β τ(α).(22) Sinceη(x) = Pr[˜y(x)̸=y|x] = 1−p T (c|x), we obtain η(x)≤1−τ+β τ(α),(23) which proves Eq. (2). We next prove the aggregate neighborhood certifi...
-
[63]
The empirical structural gate is ˆrτ(x) = 1 knn knnX i=1 Bi,(31) and its population counterpart isr τ(x) =E[B i]
Proof of Proposition 1:For a fixed target representationx, define the Bernoulli variable Bi =I[˜y(xi) = ˜y(x), s(xi)≥τ],(30) wherex i is thei-th sampled neighbor ofx. The empirical structural gate is ˆrτ(x) = 1 knn knnX i=1 Bi,(31) and its population counterpart isr τ(x) =E[B i]. Hoeffding’s inequality gives Pr [|ˆrτ(x)−r τ(x)| ≥ϵ]≤2 exp(−2k nnϵ2).(32) Se...
-
[64]
1 Ke KeX k=1 Zk ≥ 1 2 |x # ≤Pr
Proof of Corollary 2:Fixx∈ H τ,ρ. LetZ k =I[f k S(x)̸=y]be the error indicator of thek-th source expert. Under the idealized condition in Corollary 2, the variablesZ 1, . . . , ZKe are conditionally independent givenx, andE[Z k |x]≤¯e <1/2. Majority voting is wrong only when 1 Ke KeX k=1 Zk ≥ 1 2 .(34) Hoeffding’s inequality gives Pr " 1 Ke KeX k=1 Zk ≥ 1...
-
[65]
Proof of Proposition 2:LetU=X T \ Hτ,ρ. The target risk can be decomposed as RT (h) = Pr[h(x)̸=y, x∈ H τ,ρ] + Pr[h(x)̸=y, x∈ U](37) =π H Pr[h(x)̸=y|x∈ H τ,ρ] +π U RU(h).(38) On the safe subspace, the eventh(x)̸=yis contained in the union of the two eventsh(x)̸= ˜y(x)and˜y(x)̸=y. Hence Pr[h(x)̸=y|x∈ H τ,ρ]≤Pr[h(x)̸= ˜y(x)|x∈ H τ,ρ] + Pr[˜y(x)̸=y|x∈ H τ,ρ](...
-
[66]
For completeness, we state a standard finite-sample form that explains the empirical objective in Eq
A finite-sample variant:The previous proposition is a population decomposition. For completeness, we state a standard finite-sample form that explains the empirical objective in Eq. (20). Supposemselected target graphs are sampled fromH τ,ρ, and let bRH(h)be the empirical pseudo-label risk on them. For a bounded classification loss and a hypothesis class ...
-
[67]
For structure-based domain shifts, we use real-world graph benchmarks and image-derived graph benchmarks
Dataset Description:We provide additional details of the datasets used in our experiments. For structure-based domain shifts, we use real-world graph benchmarks and image-derived graph benchmarks. For graph datasets, molecules are represented as graphs with atoms as nodes and chemical bonds as edges, while proteins are represented with amino acids as node...
-
[68]
Each graph is converted into a PyG data object, with the original node attributes or node labels used as input features when available
Data Processing:For real-world graph datasets from TUDataset 4, including DD, PROTEINS, Mutagenicity, NCI1, FRANKENSTEIN, BZR, BZR MD, COX2, and COX2 MD, we follow the standard preprocessing pipeline provided by PyTorch Geometric5. Each graph is converted into a PyG data object, with the original node attributes or node labels used as input features when ...
-
[69]
More performance comparison:In this section, we present additional performance comparisons between S 2PLR and all baseline methods on more graph benchmarks, as summarized in Tables XVI–XXV. The results cover node-density and 21 Algorithm 1Training Procedure of S 2PLR 1:Input:Source expertsM, target dataD t, thresholdsζ, ρ min, variance percentileq u, neig...
-
[70]
Specifically, we evaluate five ablated variants of S2PLR, including S 2PLR w/o ME, S 2PLR w/o CF, S 2PLR w/o TS, S 2PLR w/o NC, and S 2PLR w/o SR
More Ablation study:To further validate the effectiveness of each component in S 2PLR, we conduct additional ablation studies on the DD, NCI1, FRANKENSTEIN, and ogbg-molhiv datasets. Specifically, we evaluate five ablated variants of S2PLR, including S 2PLR w/o ME, S 2PLR w/o CF, S 2PLR w/o TS, S 2PLR w/o NC, and S 2PLR w/o SR. The corresponding experimen...
-
[71]
The results are shown in Fig
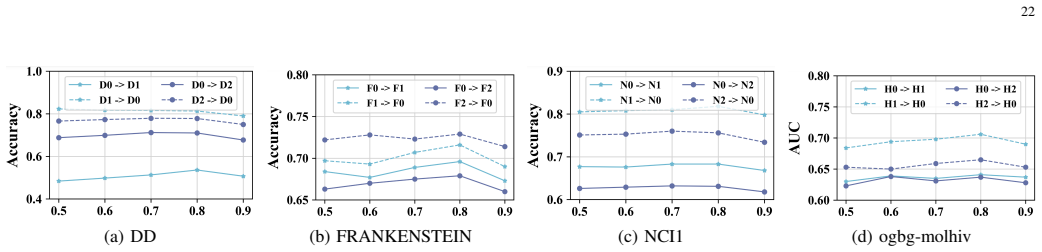
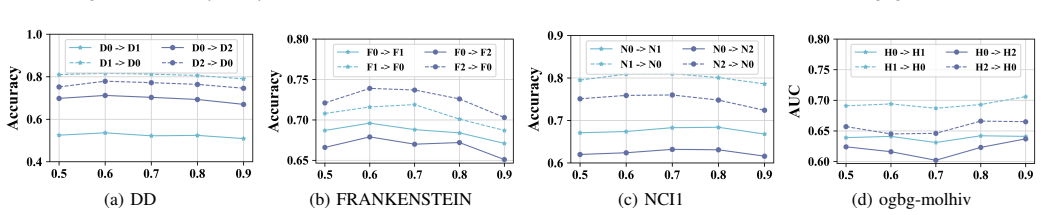
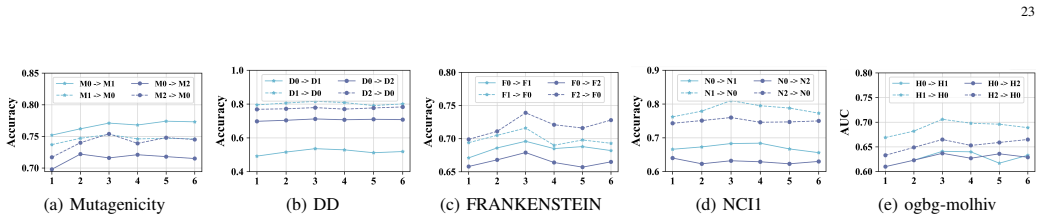
More Sensitivity Analysis:We further analyze the sensitivity of S 2PLR to the confidence thresholdζand the neighborhood- consistency thresholdρ min on DD, FRANKENSTEIN, NCI1, and ogbg-molhiv. The results are shown in Fig. 5 and 6, and the observed trends are consistent with the analysis in Section V-G. For each dataset, we vary one threshold at a time ove...
-
[72]
The goal is to examine whether the performance gains of S 2PLR come from a substantially larger adaptation budget or from the proposed reliability-guided refinement mechanism
Efficiency and Resource Consumption Analysis:In this section, we report the computational cost of S 2PLR and representative baselines, including GALA, GraphCTA, and SOGA, in Table XI. The goal is to examine whether the performance gains of S 2PLR come from a substantially larger adaptation budget or from the proposed reliability-guided refinement mechanis...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.