A Comparative Analysis of Machine Learning Algorithms for Multi-Task Prediction of the Parameters of the Pectin Hydrolysis--Extraction Process
Pith reviewed 2026-06-28 19:13 UTC · model grok-4.3
The pith
CatBoost reaches average R-squared of 0.946 on multi-task prediction of pectin yield, acid content, molecular weight, and esterification from 1000 experiments.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
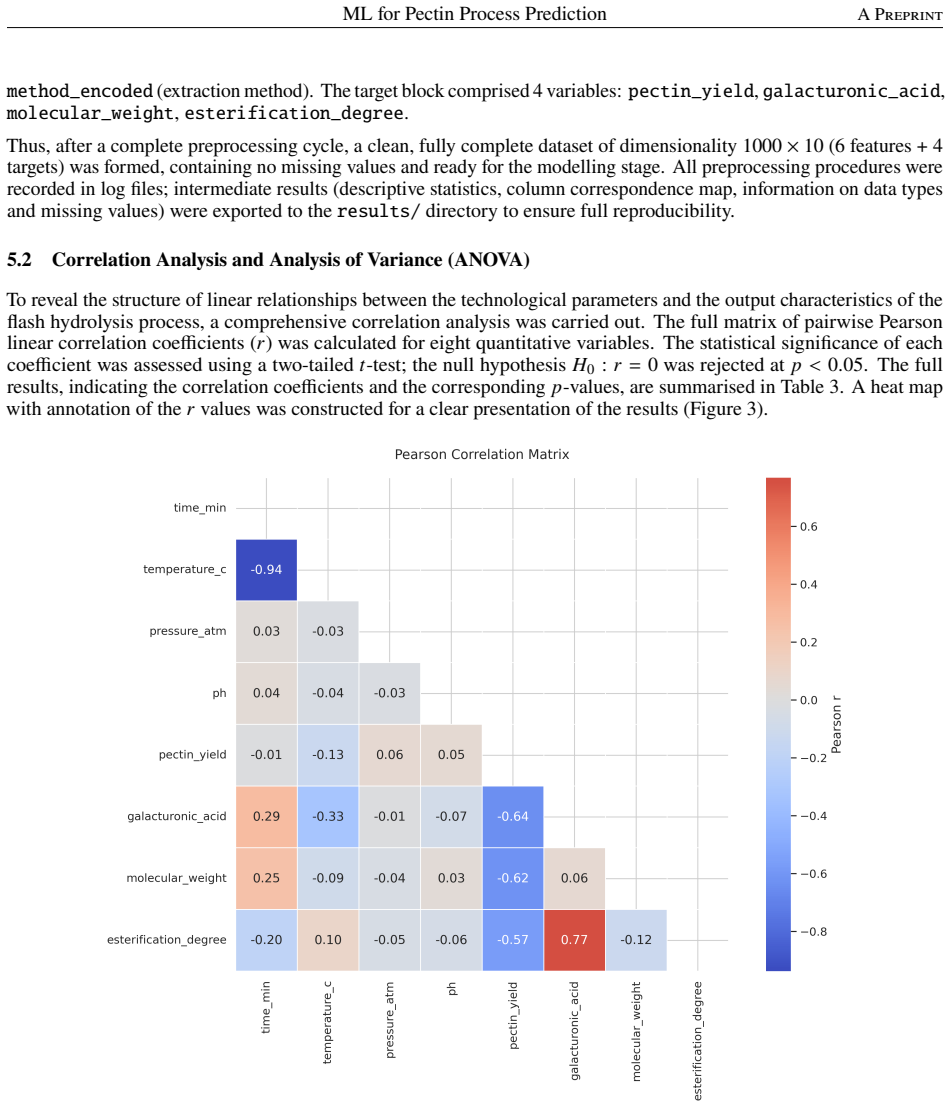
Training and evaluating eleven algorithms on the 1000-experiment pectin database shows that CatBoost delivers the best multi-task regression performance, attaining an average R-squared of approximately 0.946, while feature importance analysis identifies raw material type as the dominant input.
What carries the argument
CatBoost applied to multi-task regression on the four-factor, seven-material experimental database for simultaneous prediction of the four pectin outputs.
If this is right
- The developed pipeline can support real-time intelligent control of pectin hydrolysis-extraction without repeated physical trials.
- Raw material type should receive priority in future experimental designs because it drives 63.6 percent of the importance.
- Ensemble methods with hyperparameter tuning outperform single models and linear baselines on this multi-output task.
- The exported production-ready model enables deployment as an interactive web tool for process operators.
Where Pith is reading between the lines
- The same comparative workflow could be transferred to other multi-parameter extraction or hydrolysis processes that generate similar tabular experimental data.
- Collecting targeted trials on underrepresented raw materials would most efficiently improve model coverage.
- Interpretable feature rankings from the winning model can guide which process variables merit tighter control in scaled production.
Load-bearing premise
The 1000 trials on seven raw materials with the stated ranges of temperature, pressure, time, and pH cover the variations needed for reliable predictions across the process.
What would settle it
Running the trained model on a fresh set of experiments that uses an eighth raw material type or process conditions outside the recorded ranges and checking whether the R-squared remains near 0.946.
Figures


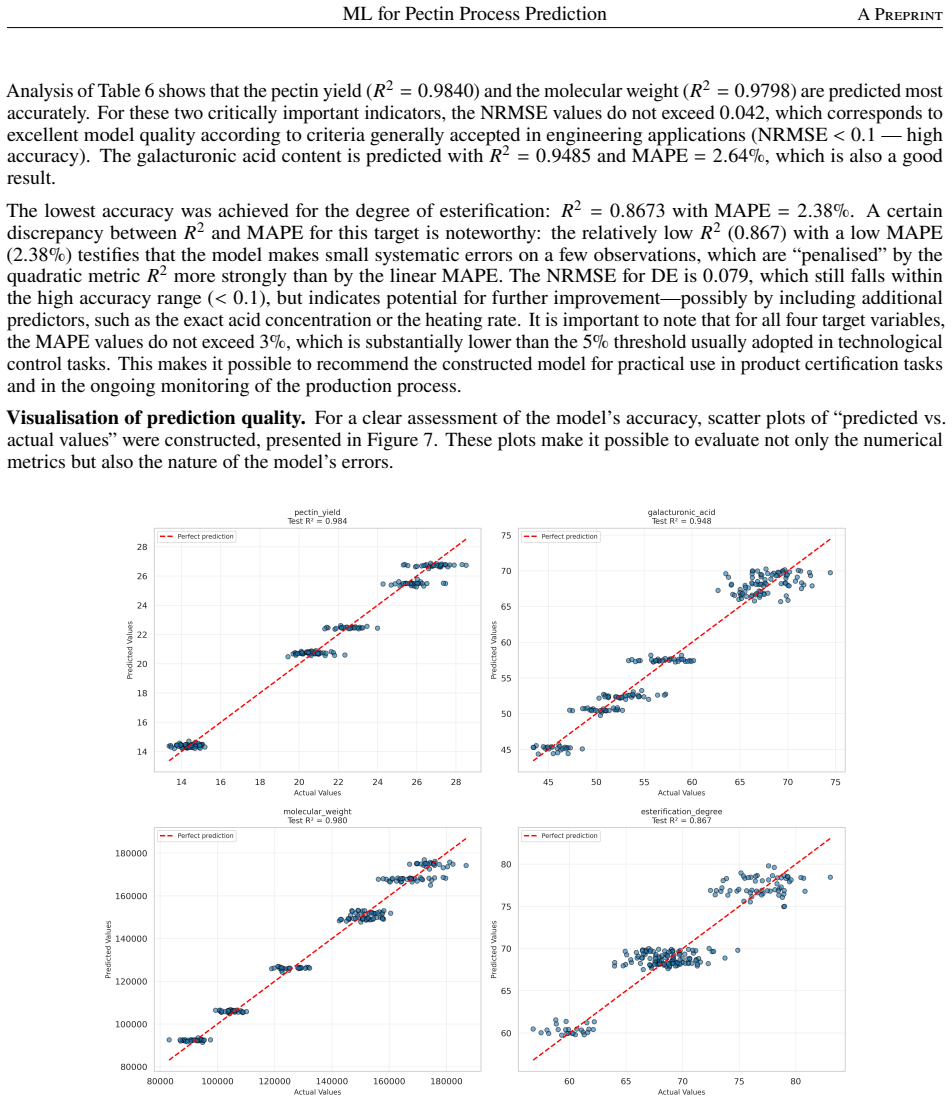
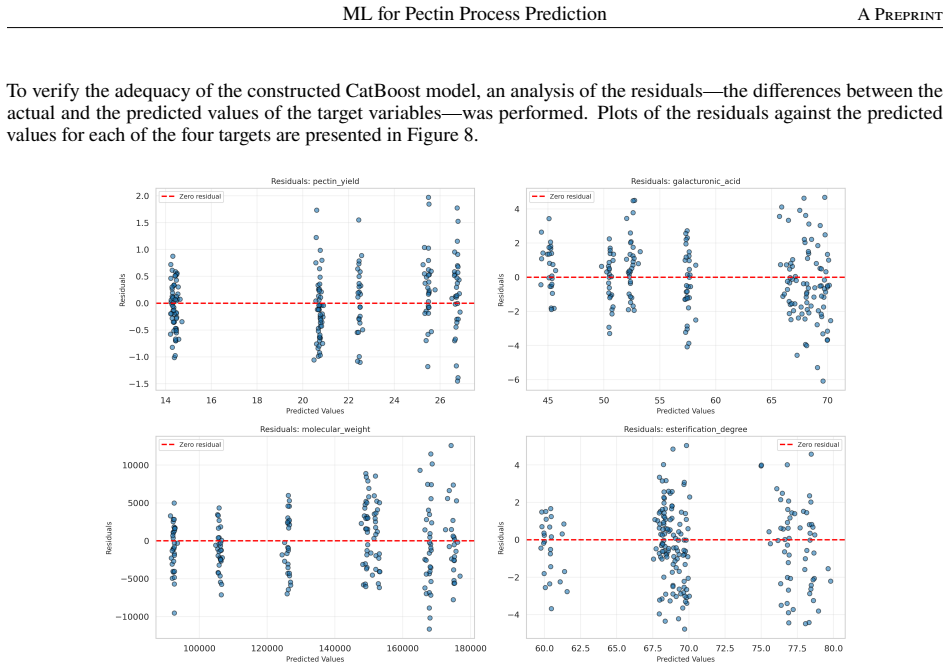
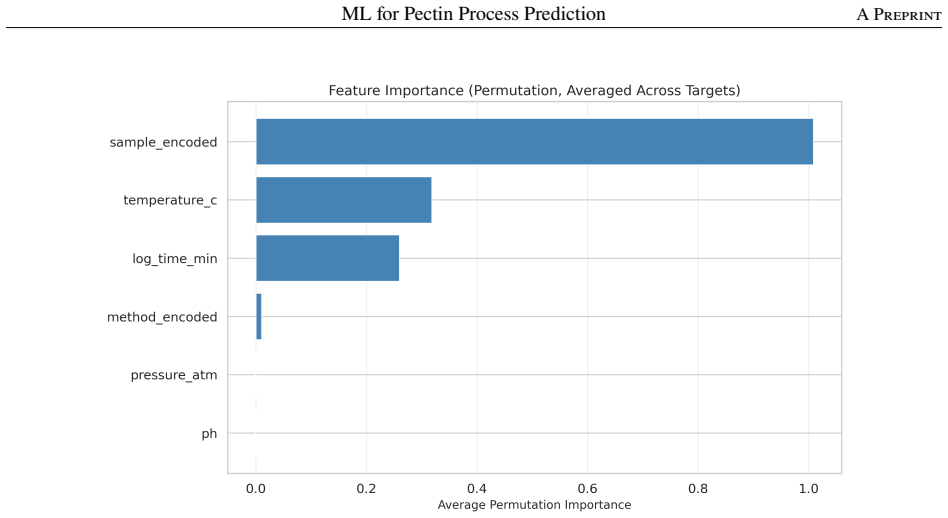
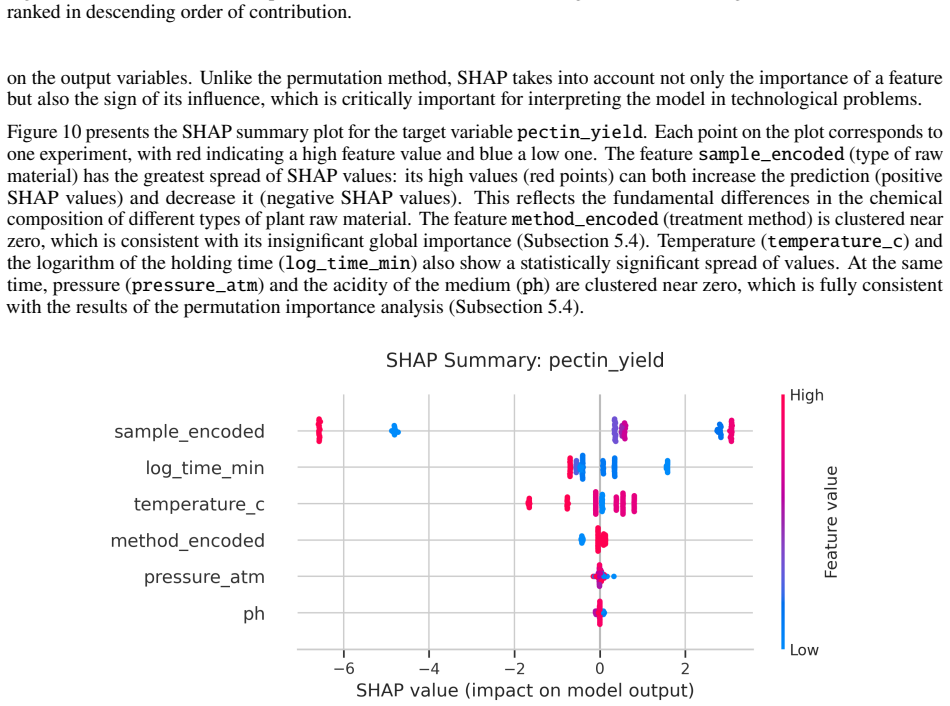
read the original abstract
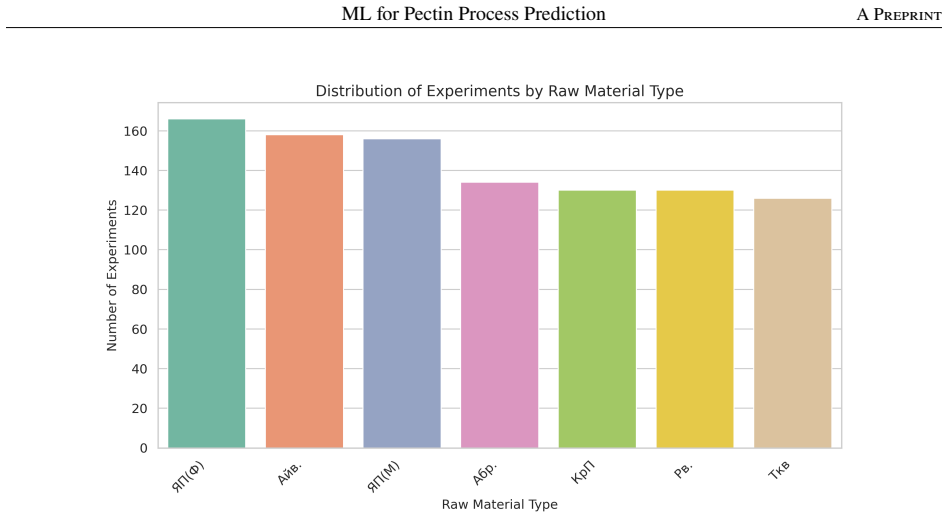
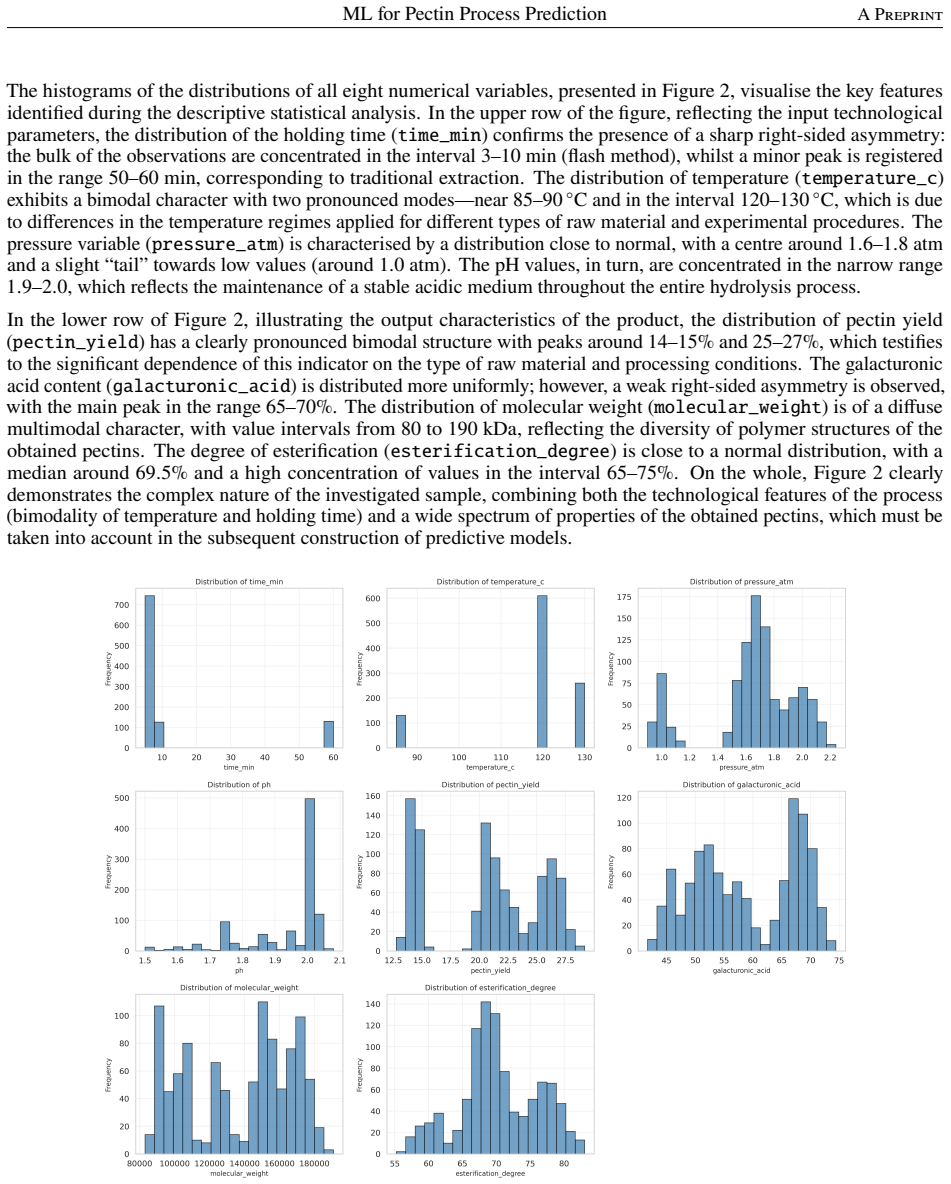
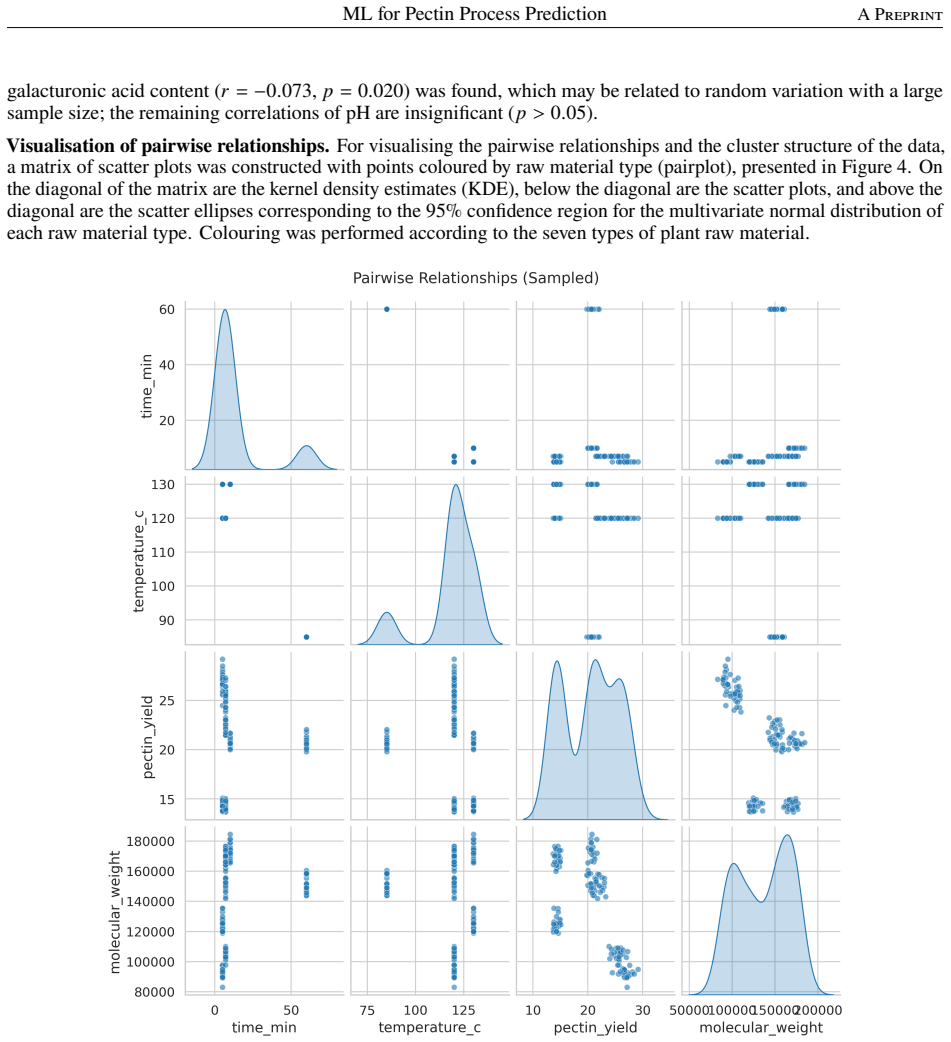
This study addresses the challenge of controlling a complex, multi-parameter technological process -- pectin hydrolysis--extraction -- using machine learning methods. The experimental foundation is a unique database comprising 1,000 laboratory experiments conducted under controlled conditions on seven types of plant raw material with four variable process factors (temperature 85--130 C, pressure 0.9--2.2 atm, holding time 3--10 min, pH 1.5--2.0). Four output characteristics were recorded: pectin yield, galacturonic acid content, molecular weight, and degree of esterification. To solve the multi-task regression problem, 11 algorithms were trained and compared: regularised linear models, ensemble methods (Random Forest, Gradient Boosting, XGBoost, CatBoost, Extra Trees), k-nearest neighbours, support vector regression, and a multilayer perceptron. The best results were demonstrated by CatBoost (average R-squared approximately 0.946 after hyperparameter optimisation). Feature importance analysis revealed the dominant role of the raw material type (63.6% of total importance), followed by temperature and holding time. The developed pipeline was exported in a production-ready format and deployed as an interactive web interface. The findings demonstrate that ensemble methods combined with rigorous statistical analysis and interpretable AI significantly reduce the need for physical experiments and form the basis for intelligent pectin production control.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript conducts a comparative analysis of 11 machine learning algorithms (including regularized linear models, ensembles like Random Forest, XGBoost, CatBoost, and others, plus kNN, SVR, and MLP) for multi-task regression predicting four outputs (pectin yield, galacturonic acid content, molecular weight, degree of esterification) from 1000 experiments on seven raw materials using four input factors (temperature, pressure, time, pH). It reports CatBoost as the best performer with average R² ≈ 0.946 after hyperparameter tuning, notes raw-material type as the dominant feature (63.6% importance), and describes export of a production-ready pipeline with a web interface.
Significance. If the performance metrics hold under proper out-of-sample validation, the work illustrates a practical application of ensemble methods to model a complex multi-parameter chemical process, potentially reducing reliance on physical trials. The combination of comparative benchmarking, feature importance, and deployed interface provides concrete value for process optimization in pectin production.
major comments (2)
- [Abstract] Abstract and results: No details are given on the validation strategy, train/test partitioning, cross-validation procedure, or whether the reported R-squared values (including the average 0.946 for CatBoost) are computed on held-out test data versus training data. This directly undermines assessment of the central performance claim.
- [Results] Feature importance analysis: Raw material type is assigned 63.6% of total importance, with only seven discrete categorical levels and four continuous factors. No cross-material validation, leave-one-material-out testing, or evaluation on unseen raw materials or factor combinations is described, so the multi-task generalization claim rests on an untested assumption about dataset coverage.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major point below and commit to revisions that will strengthen the presentation of our methods and results.
read point-by-point responses
-
Referee: [Abstract] Abstract and results: No details are given on the validation strategy, train/test partitioning, cross-validation procedure, or whether the reported R-squared values (including the average 0.946 for CatBoost) are computed on held-out test data versus training data. This directly undermines assessment of the central performance claim.
Authors: We agree that the submitted manuscript does not provide sufficient detail on the validation strategy in either the abstract or results sections. In the revised manuscript we will expand the methods section to describe the train/test partitioning, the cross-validation procedure used during hyperparameter tuning and evaluation, and explicitly state that the reported R-squared values (including the CatBoost average of approximately 0.946) are computed on held-out test data. revision: yes
-
Referee: [Results] Feature importance analysis: Raw material type is assigned 63.6% of total importance, with only seven discrete categorical levels and four continuous factors. No cross-material validation, leave-one-material-out testing, or evaluation on unseen raw materials or factor combinations is described, so the multi-task generalization claim rests on an untested assumption about dataset coverage.
Authors: The reported feature importances were obtained from the model trained on the complete dataset. We acknowledge that no leave-one-material-out or cross-material validation was performed or described. In the revision we will add leave-one-material-out experiments to quantify performance on unseen raw-material types and will report the corresponding metrics to support the generalization claims. revision: yes
Circularity Check
No significant circularity in empirical ML comparison
full rationale
The paper conducts a standard empirical comparison of 11 machine learning algorithms trained on an experimental dataset of 1000 trials. Reported metrics such as CatBoost's average R-squared of approximately 0.946 are obtained via hyperparameter optimization and evaluation on the data (presumably via train/test splits or cross-validation), not by construction from the inputs. Feature importance (e.g., 63.6% for raw material type) is a post-hoc analysis of fitted models. No self-definitional steps, fitted inputs renamed as predictions, self-citation load-bearing claims, uniqueness theorems, or ansatzes appear in the derivation chain. The results are direct empirical outcomes and self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- Hyperparameters of the 11 ML models
axioms (1)
- domain assumption The laboratory experiments are independent and representative of the process
Reference graph
Works this paper leans on
-
[1]
doi:10.1214/aos/1013203451. L. Breiman. Random forests.Machine Learning, 45(1):5–32,
-
[2]
doi:10.1023/A:1010933404324. M. L. Fishman, P. N. Walker, H. K. Chau, and A. T. Hotchkiss. Flash extraction of pectin from orange albedo by steam injection.Biomacromolecules, 4(4):880–889,
-
[3]
doi:10.1021/bm020122e. Sh. Yo. Kholov, N. I. Yunusov, A. S. Jonmurodov, et al. Modeling of technological processes for pectin production from apple pomace.Reports of the Academy of Sciences of the Republic of Tajikistan, 60(3-4):178–183,
-
[4]
doi:10.1016/j.carbpol.2016.11.013. Riyamol, J. G. Chengaiyan, S. S. Rana, et al. Recent advances in the extraction of pectin from various sources and industrial applications.ACS Omega, 8(49):46309–46324,
-
[5]
doi:10.1021/acsomega.3c04010. K. Santosh, K. Jyotismita, P. M. Das, et al. Current progress in valorization of food processing waste and by-products for pectin extraction.International Journal of Biological Macromolecules, 239:124332,
-
[6]
doi:10.1016/j.ijbiomac.2023.124332. L. Barrera-Chamorro, A. Fernandez-Prior, F. Rivero-Pino, et al. A comprehensive review on the functionality and biological relevance of pectin and the use in the food industry.Carbohydrate Polymers, 348:122794,
-
[7]
doi:10.1016/j.carbpol.2024.122794. S. Ruder. An overview of multi-task learning in deep neural networks,
-
[8]
URLhttps://arxiv.org/abs/1706. 05098. arXiv:1706.05098. Accessed: 2024-11-19. N. M. Shahani, X. Zheng, X. Guo, and X. Wei. Machine learning-based intelligent prediction of elastic modulus of rocks at thar coalfield.Sustainability, 14(6):3689,
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
doi:10.3390/su14063689. G.-W. Cha, H. J. Moon, and Y.-C. Kim. A hybrid machine-learning model for predicting the waste generation rate of building demolition projects.Journal of Cleaner Production, 375:134096,
-
[10]
doi:10.1016/j.jclepro.2022.134096. V. Sudarshan and W. D. Seider. Advancing machine learning in industry 4.0: Benchmark framework for rare-event prediction in chemical processes.Computers & Chemical Engineering, 194:108929,
-
[11]
doi:10.1016/j.compchemeng.2024.108929. M. K. Arabov and Sh. E. Kholov. Pectinproductionpredicator. Certificate of State Registration of Computer Programme No. 2026610973,
-
[12]
23.12.2025; publ
Appl. 23.12.2025; publ. 16.01.2026. Applicant: Kazan Federal University. EDN FMIFMD. Arabov’s AI Lab. Pectin production models,
2025
-
[13]
Accessed: 2024-11-19
URLhttps://huggingface.co/spaces/arabovs-ai-lab/ pectinproductionmodels-demo. Accessed: 2024-11-19. P. Siejak, K. Przybyl, L. Masewicz, et al. The prediction of pectin viscosity using machine learning based on physical characteristics—case study: Aglupectin hs-mr.Sustainability, 16(14):5877,
2024
-
[14]
doi:10.3390/su16145877. R. J. M. Yapias, F. O. Areche, G. D. L. C. Calderon, et al. Optimized extraction of high-purity pectin from orange biowaste using synergistic ultrasound-microwave-assisted green technologies.Current Research in Nutrition and Food Science, 13(2),
-
[15]
doi:10.12944/CRNFSJ.13.2.15. M. Fan, K. Xiao, L. Sun, et al. Automated hyperparameter optimization of gradient boosting decision tree approach for goldmineralprospectivitymappinginthexiong’ershanarea.Minerals,12(12):1621,2022. doi:10.3390/min12121621. F.Pedregosa, G.Varoquaux, A.Gramfort, etal. Scikit-learn: Machinelearninginpython.Journal of Machine Lear...
-
[16]
Prokhorenkova, G
L. Prokhorenkova, G. Gusev, A. Vorobev, A. V. Dorogush, and A. Gulin. CatBoost: unbiased boosting with categorical features. InAdvances in Neural Information Processing Systems 31 (NeurIPS 2018), pages 6639–6649, Montréal, Canada,
2018
-
[17]
25 ML for Pectin Process PredictionA Preprint P.Zhou, X.Li, Y.Lu, Z.Jiang, andL.Shen
doi:10.1016/j.measurement.2023.114024. 25 ML for Pectin Process PredictionA Preprint P.Zhou, X.Li, Y.Lu, Z.Jiang, andL.Shen. Anovelapproachandmechanisticinsightintotheco-extractionofessential oilandpectinfromCitrus aurantiuml.var.amaraengl.basedonmachinelearningandDFTcalculations.Sustainable Chemistry and Pharmacy, 39:101570,
-
[18]
doi:10.1016/j.scp.2024.101570. S. M. Lundberg and S. I. Lee. A unified approach to interpreting model predictions. InAdvances in Neural Information Processing Systems 30, pages 4765–4774,
-
[19]
A Unified Approach to Interpreting Model Predictions
doi:10.48550/arXiv.1705.07874. M. T. Ribeiro, S. Singh, and C. Guestrin. “Why Should I Trust You?”: Explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pages 1135–1144,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1705.07874
-
[20]
doi:10.1145/2939672.2939778. C. Vuppalapati, A. Ilapakurti, S. Kedari, et al. Crossing the artificial intelligence (AI) chasm, albeit using constrained IoT edges and tiny ML, for creating a sustainable food future. InAdvances in Intelligent Systems and Computing, volume 1184, pages 540–553,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.