Decoupled Behavioral Cloning for Scalable Inductive Generalization in RL from Specifications
Pith reviewed 2026-06-28 18:24 UTC · model grok-4.3
The pith
Decoupling per-task RL from evolution-function learning replaces noisy rewards with dense supervision and improves stability plus zero-shot generalization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
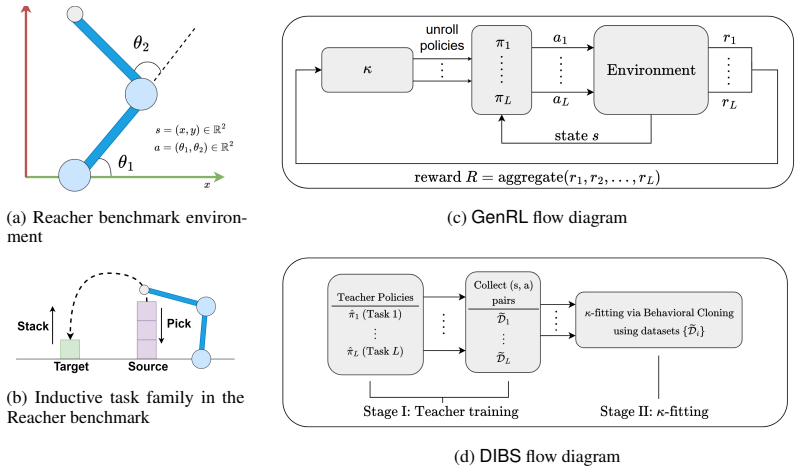
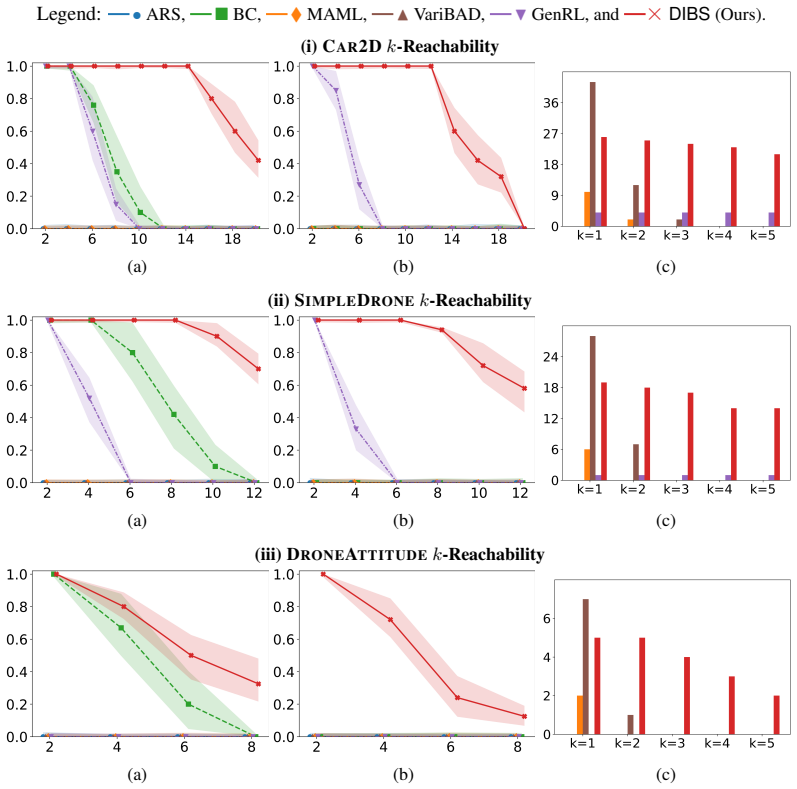
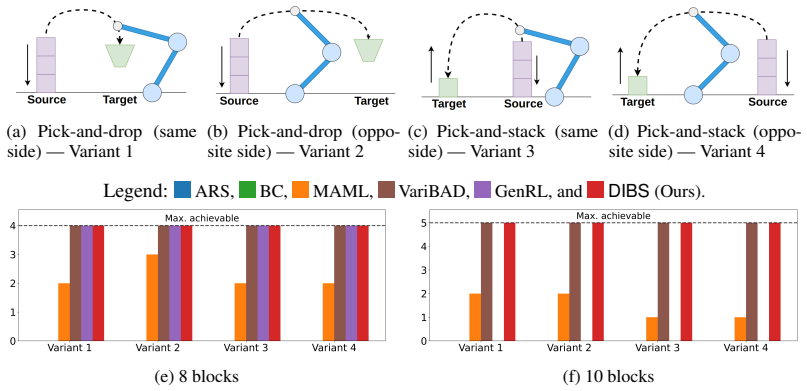
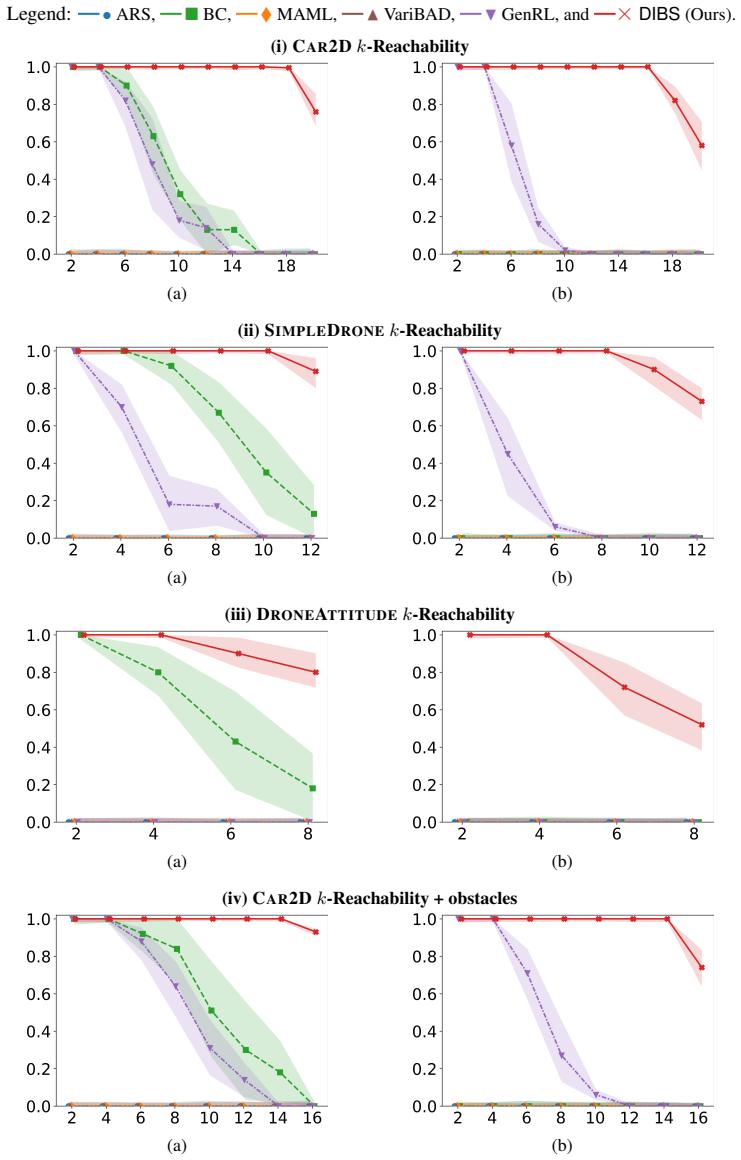
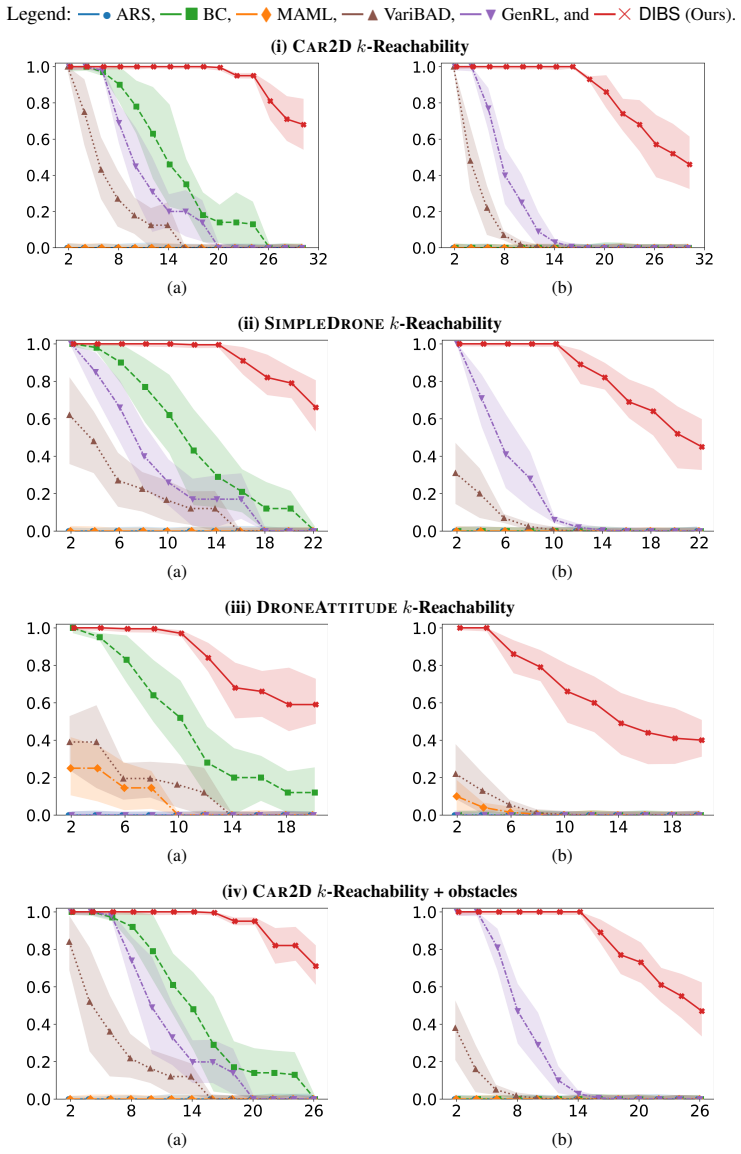
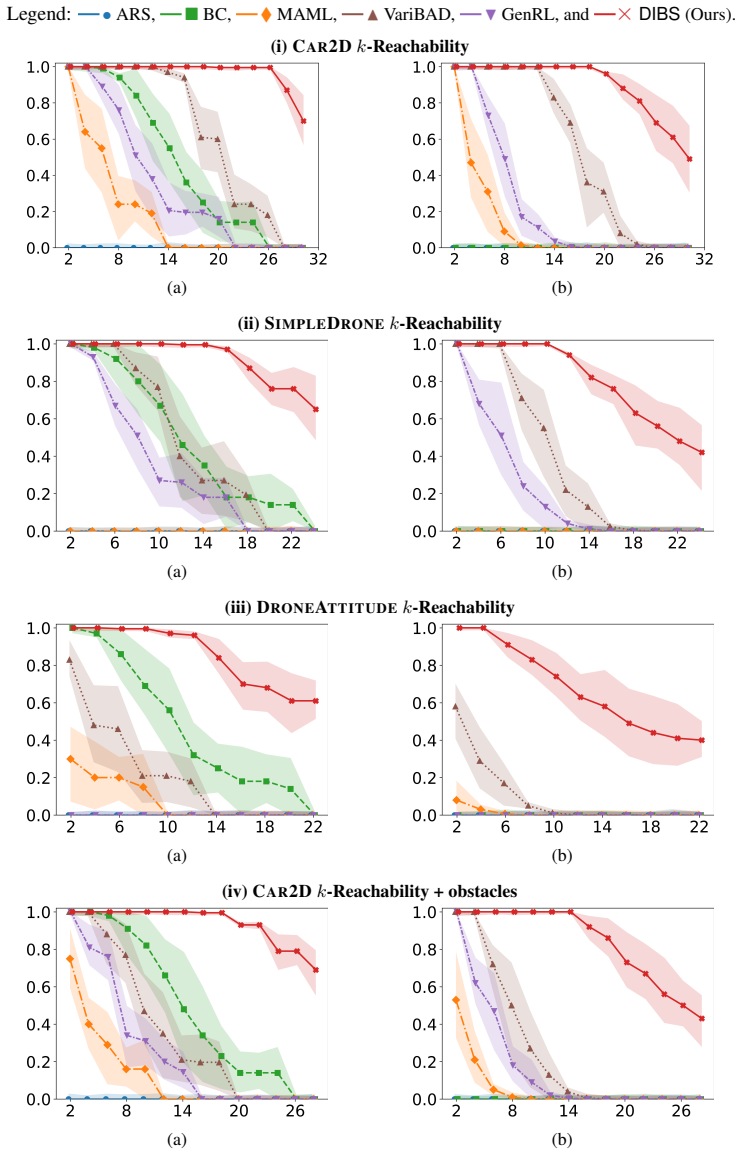
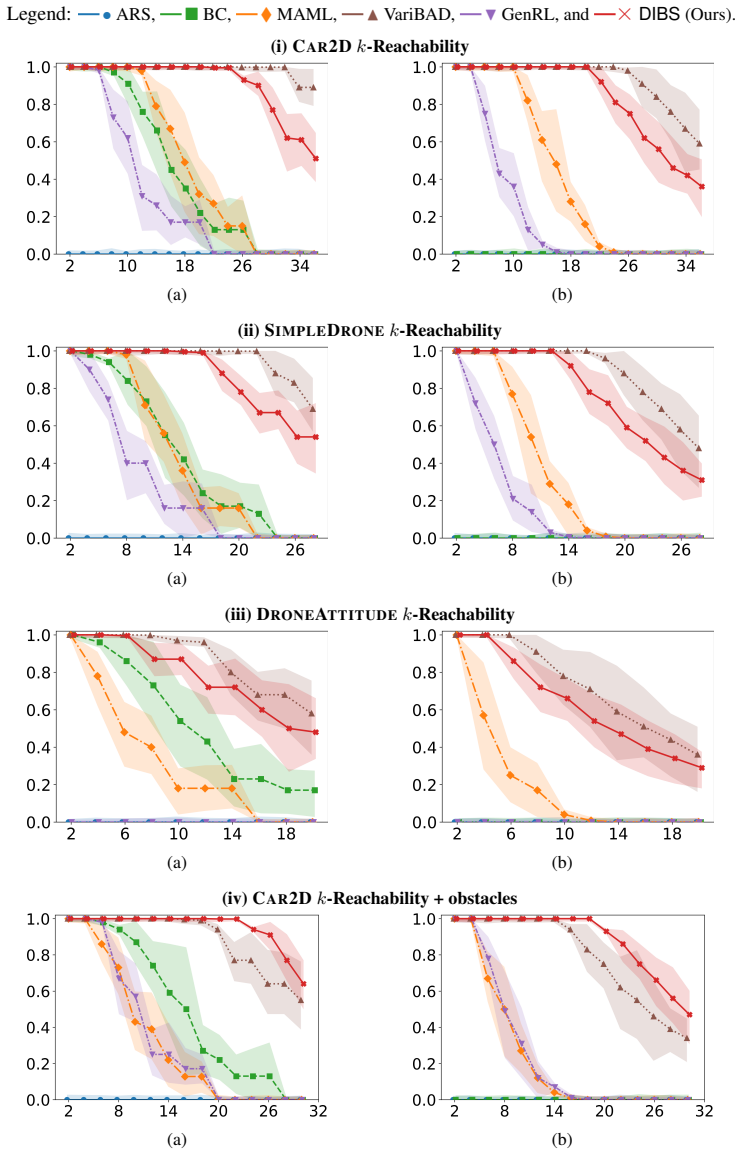
DIBS decouples the learning of task-specific policies from the learning of the policy-evolution function: individual teacher policies are obtained via ordinary per-task RL, after which the evolution function is fit by behavioral cloning on the teacher-generated state-action pairs, substituting dense stable supervision for noisy aggregated rewards.
What carries the argument
The policy-evolution function fitted by behavioral cloning on teacher-labeled state-action pairs.
If this is right
- Training stability holds as the number of tasks grows because reward aggregation is removed.
- Zero-shot success on new tasks rises because the evolution function receives cleaner training data.
- The method applies to any inductive family once per-task teachers can be obtained.
- It outperforms both direct RL and meta-RL baselines on the reported metrics.
Where Pith is reading between the lines
- The same decoupling could be tested in settings where the evolution function must be learned from partial rather than full trajectories.
- If teacher policies are allowed to share parameters, the approach might further reduce total compute while preserving the dense-supervision benefit.
- The framework naturally extends to any higher-order structure whose direct RL training suffers from reward interference.
Load-bearing premise
The separately trained teacher policies must be of sufficient quality and coverage to supply unbiased, dense supervision for the evolution function.
What would settle it
Run the same suite of tasks with deliberately degraded teacher policies (e.g., early-stopped or low-coverage RL) and measure whether DIBS still outperforms the RL and meta-RL baselines on stability and zero-shot success.
Figures

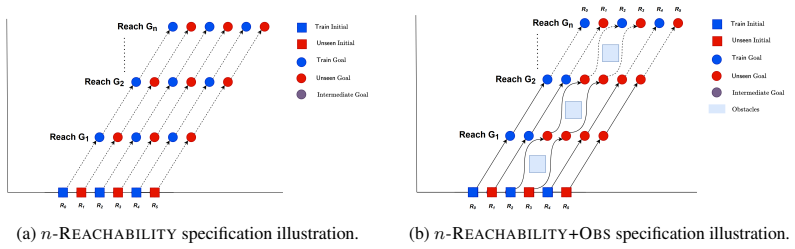
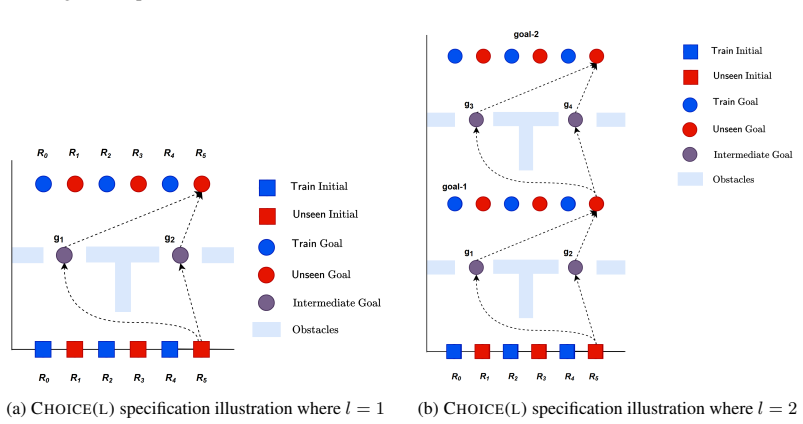
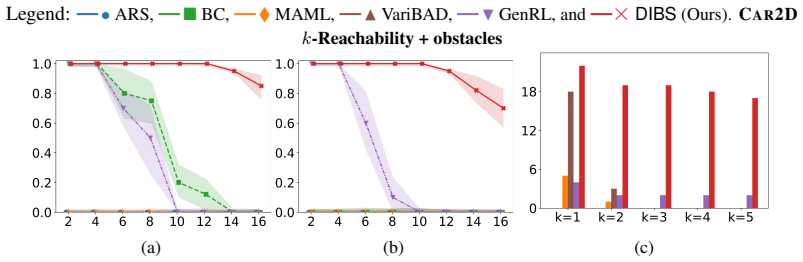

read the original abstract
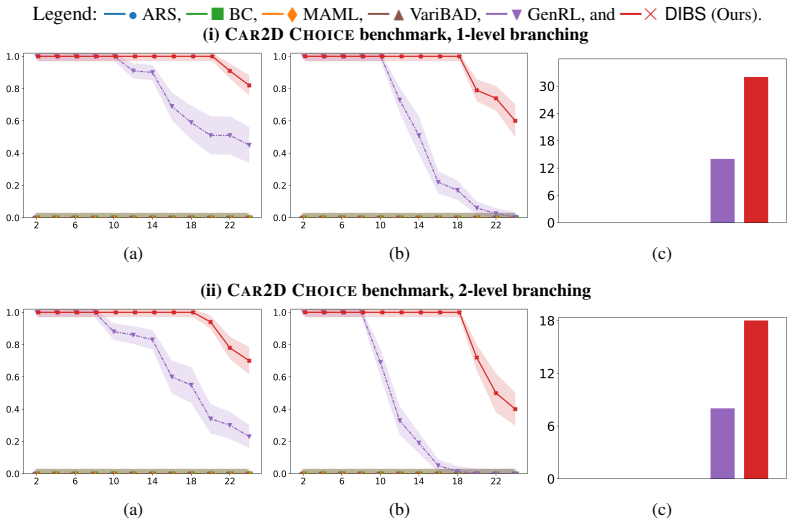
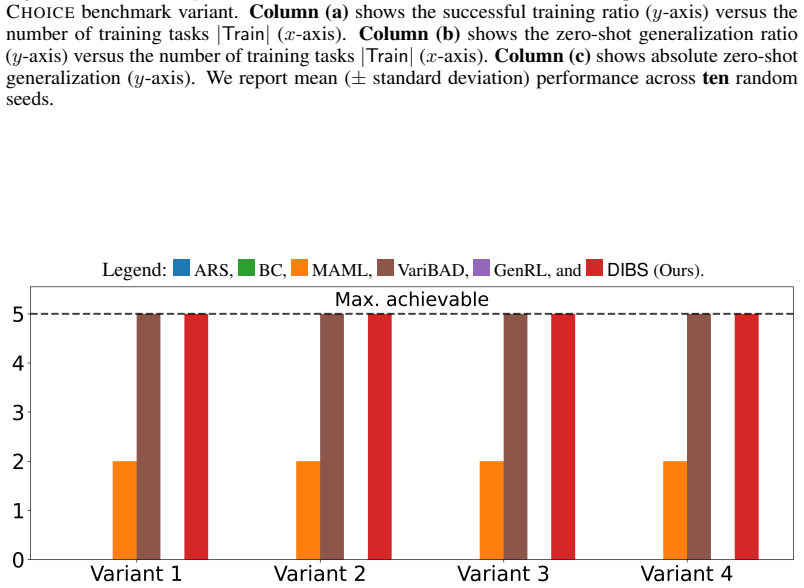
Inductive generalization is a framework for reinforcement learning (RL) generalization in which inductively related task instances admit inductively related policies. Prior work captures this structure via a higher-order policy-evolution function learned directly with RL, but suffers from poor training scalability: as training tasks grow, aggregated reward feedback becomes noisy and conflicting, destabilizing training and weakening generalization. We propose DIBS, a decoupled behavioral cloning approach that separates learning task-specific policies from learning the evolution function. We first learn individual teacher policies per task via standard RL, then fit the evolution function via behavioral cloning on teacher-labeled state-action pairs. This replaces noisy reward aggregation with dense, stable supervision. DIBS achieves significant improvements in both training stability and zero-shot generalization against existing RL and meta-RL algorithms.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DIBS, a decoupled behavioral cloning approach for inductive generalization in RL from specifications. It first obtains task-specific teacher policies independently via standard RL, then learns the higher-order policy-evolution function by behavioral cloning on the resulting state-action pairs. This is presented as replacing noisy aggregated reward feedback with dense supervision, yielding claimed gains in training stability and zero-shot generalization over prior RL and meta-RL methods.
Significance. If the empirical claims are substantiated, the decoupling strategy could address a scalability bottleneck in learning inductive policy structures by avoiding conflicting reward signals, offering a practical alternative for generalization in specification-based RL.
major comments (2)
- [Abstract] Abstract: the headline claim that 'DIBS achieves significant improvements in both training stability and zero-shot generalization' is asserted without any quantitative results, baseline details, experimental protocol, or statistical evidence, rendering the central performance claim unverifiable from the manuscript.
- [Method description] Method overview (abstract and skeptic note on weakest assumption): the approach depends on per-task RL producing near-optimal, high-coverage teacher policies to supply unbiased dense supervision for the behavioral cloning step; no analysis, ablation, or scaling experiments are described to validate that teacher quality remains adequate as task count or difficulty increases, which directly underpins the stability and generalization claims.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We respond to each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline claim that 'DIBS achieves significant improvements in both training stability and zero-shot generalization' is asserted without any quantitative results, baseline details, experimental protocol, or statistical evidence, rendering the central performance claim unverifiable from the manuscript.
Authors: We agree the abstract states the performance claims at a high level. The body of the paper reports the supporting quantitative results, baselines, protocols, and statistics. We will revise the abstract to include brief references to the key metrics (e.g., stability and generalization deltas) while preserving conciseness. revision: partial
-
Referee: [Method description] Method overview (abstract and skeptic note on weakest assumption): the approach depends on per-task RL producing near-optimal, high-coverage teacher policies to supply unbiased dense supervision for the behavioral cloning step; no analysis, ablation, or scaling experiments are described to validate that teacher quality remains adequate as task count or difficulty increases, which directly underpins the stability and generalization claims.
Authors: The referee correctly notes that the approach assumes per-task RL yields sufficiently high-quality teachers. The manuscript does not contain dedicated ablations or scaling studies that vary task count or difficulty to measure degradation in teacher quality. We will add a discussion of this assumption together with a targeted ablation on teacher quality in the revision. revision: yes
Circularity Check
No significant circularity; algorithmic proposal is self-contained
full rationale
The paper describes an algorithmic decoupling: per-task RL to obtain teacher policies, followed by behavioral cloning to fit an evolution function. No derivation, equation, or fitted quantity is shown to reduce by construction to its own inputs. No self-citation load-bearing steps, uniqueness theorems, or ansatzes are invoked in the provided text. The central claim rests on the empirical performance of the proposed procedure rather than a mathematical identity or renamed input. This is the expected non-finding for a methods paper whose contribution is a change in training procedure.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Q-learning for robust satisfaction of signal temporal logic specifications
Aksaray, D., Jones, A., Kong, Z., Schwager, M., and Belta, C. Q-learning for robust satisfaction of signal temporal logic specifications. InConference on Decision and Control (CDC), pp. 6565–6570. IEEE, 2016
2016
-
[2]
A framework for transforming specifica- tions in reinforcement learning
Alur, R., Bansal, S., Bastani, O., and Jothimurugan, K. A framework for transforming specifica- tions in reinforcement learning. InPrinciples of Systems Design: Essays Dedicated to Thomas A. Henzinger on the Occasion of His 60th Birthday, pp. 604–624. Springer, 2022
2022
-
[3]
Specification-guided reinforcement learning.Communications of the ACM, 69(2):80–87, 2026
Alur, R., Bansal, S., Bastani, O., and Jothimurugan, K. Specification-guided reinforcement learning.Communications of the ACM, 69(2):80–87, 2026
2026
-
[4]
Verifiable reinforcement learning via policy extraction
Bastani, O., Pu, Y ., and Solar-Lezama, A. Verifiable reinforcement learning via policy extraction. Advances in neural information processing systems, 31, 2018
2018
-
[5]
LTLf/LDLf non-markovian rewards
Brafman, R., De Giacomo, G., and Patrizi, F. LTLf/LDLf non-markovian rewards. InProceed- ings of the AAAI Conference on Artificial Intelligence, volume 32, 2018
2018
-
[6]
GALOIS: boosting deep reinforcement learning via generalizable logic synthesis.Advances in Neural Information Processing Systems, 35:19930–19943, 2022
Cao, Y ., Li, Z., Yang, T., Zhang, H., Zheng, Y ., Li, Y ., Hao, J., and Liu, Y . GALOIS: boosting deep reinforcement learning via generalizable logic synthesis.Advances in Neural Information Processing Systems, 35:19930–19943, 2022
2022
-
[7]
Quantifying generalization in reinforcement learning
Cobbe, K., Klimov, O., Hesse, C., Kim, T., and Schulman, J. Quantifying generalization in reinforcement learning. InInternational conference on machine learning, pp. 1282–1289. PMLR, 2019
2019
-
[8]
Leveraging procedural generation to benchmark reinforcement learning
Cobbe, K., Hesse, C., Hilton, J., and Schulman, J. Leveraging procedural generation to benchmark reinforcement learning. InInternational conference on machine learning, pp. 2048–2056. PMLR, 2020
2048
-
[9]
Foundations for restraining bolts: Reinforcement learning with LTLf/LDLf restraining specifications
De Giacomo, G., Iocchi, L., Favorito, M., and Patrizi, F. Foundations for restraining bolts: Reinforcement learning with LTLf/LDLf restraining specifications. InProceedings of the International Conference on Automated Planning and Scheduling, volume 29, pp. 128–136, 2019
2019
-
[10]
Regular reinforcement learning
Dohmen, T., Perez, M., Somenzi, F., and Trivedi, A. Regular reinforcement learning. In Gurfinkel, A. and Ganesh, V . (eds.),Computer Aided Verification, pp. 184–208, Cham, 2024. Springer Nature Switzerland
2024
-
[11]
Impala: Scalable distributed deep-rl with importance weighted actor-learner architectures
Espeholt, L., Soyer, H., Munos, R., Simonyan, K., Mnih, V ., Ward, T., Doron, Y ., Firoiu, V ., Harley, T., Dunning, I., et al. Impala: Scalable distributed deep-rl with importance weighted actor-learner architectures. InInternational conference on machine learning, pp. 1407–1416. PMLR, 2018
2018
-
[12]
Model-agnostic meta-learning for fast adaptation of deep networks
Finn, C., Abbeel, P., and Levine, S. Model-agnostic meta-learning for fast adaptation of deep networks. InInternational conference on machine learning, pp. 1126–1135. PMLR, 2017
2017
-
[13]
Guo, Z., I¸ sık,˙I., Ahmad, H., and Li, W. One subgoal at a time: Zero-shot generalization to arbitrary linear temporal logic requirements in multi-task reinforcement learning.arXiv preprint arXiv:2508.01561, 2025
-
[14]
Logically-Constrained Reinforcement Learning
Hasanbeig, M., Abate, A., and Kroening, D. Logically-constrained reinforcement learning. arXiv preprint arXiv:1801.08099, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[15]
J., and Lee, I
Hasanbeig, M., Kantaros, Y ., Abate, A., Kroening, D., Pappas, G. J., and Lee, I. Reinforcement learning for temporal logic control synthesis with probabilistic satisfaction guarantees. In Conference on Decision and Control (CDC), pp. 5338–5343, 2019
2019
-
[16]
Meta-learning in neural networks: A survey.IEEE transactions on pattern analysis and machine intelligence, 44(9):5149–5169, 2021
Hospedales, T., Antoniou, A., Micaelli, P., and Storkey, A. Meta-learning in neural networks: A survey.IEEE transactions on pattern analysis and machine intelligence, 44(9):5149–5169, 2021
2021
-
[17]
A composable specification language for reinforce- ment learning tasks.Advances in Neural Information Processing Systems, 32, 2019
Jothimurugan, K., Alur, R., and Bastani, O. A composable specification language for reinforce- ment learning tasks.Advances in Neural Information Processing Systems, 32, 2019. 11
2019
-
[18]
Compositional reinforcement learning from logical specifications.Advances in Neural Information Processing Systems, 34:10026– 10039, 2021
Jothimurugan, K., Bansal, S., Bastani, O., and Alur, R. Compositional reinforcement learning from logical specifications.Advances in Neural Information Processing Systems, 34:10026– 10039, 2021
2021
-
[19]
Specification-guided learning of Nash equilibria with high social welfare
Jothimurugan, K., Bansal, S., Bastani, O., and Alur, R. Specification-guided learning of Nash equilibria with high social welfare. InInternational Conference on Computer Aided Verification, pp. 343–363. Springer, 2022
2022
-
[20]
A survey of zero-shot generalisation in deep reinforcement learning.Journal of Artificial Intelligence Research, 76:201–264, 2023
Kirk, R., Zhang, A., Grefenstette, E., and Rocktäschel, T. A survey of zero-shot generalisation in deep reinforcement learning.Journal of Artificial Intelligence Research, 76:201–264, 2023
2023
-
[21]
End-to-end training of deep visuomotor policies
Levine, S., Finn, C., Darrell, T., and Abbeel, P. End-to-end training of deep visuomotor policies. Journal of Machine Learning Research, 17(39):1–40, 2016
2016
-
[22]
Reinforcement learning with temporal logic rewards
Li, X., Vasile, C.-I., and Belta, C. Reinforcement learning with temporal logic rewards. In IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pp. 3834–3839. IEEE, 2017
2017
-
[23]
Goal-conditioned reinforcement learning: Problems and solutions.arXiv preprint arXiv:2201.08299,
Liu, M., Zhu, M., and Zhang, W. Goal-conditioned reinforcement learning: Problems and solutions.arXiv preprint arXiv:2201.08299, 2022
-
[24]
Constrained decision transformer for offline safe reinforcement learning
Liu, Z., Guo, Z., Yao, Y ., Cen, Z., Yu, W., Zhang, T., and Zhao, D. Constrained decision transformer for offline safe reinforcement learning. InInternational conference on machine learning, pp. 21611–21630. PMLR, 2023
2023
-
[25]
Regret-free reinforcement learning for temporal logic specifications
Majumdar, R., Salamati, M., and Soudjani, S. Regret-free reinforcement learning for temporal logic specifications. InForty-second International Conference on Machine Learning, 2025
2025
-
[26]
Simple random search of static linear policies is competitive for reinforcement learning.Advances in neural information processing systems, 31, 2018
Mania, H., Guy, A., and Recht, B. Simple random search of static linear policies is competitive for reinforcement learning.Advances in neural information processing systems, 31, 2018
2018
-
[27]
J., Caterini, A
Naderian, P., Loaiza-Ganem, G., Braviner, H. J., Caterini, A. L., Cresswell, J. C., Li, T., and Garg, A. C-learning: Horizon-aware cumulative accessibility estimation.International Conference on Learning Representations, 2021
2021
-
[28]
Zero-shot task generalization with multi-task deep reinforcement learning
Oh, J., Singh, S., Lee, H., and Kohli, P. Zero-shot task generalization with multi-task deep reinforcement learning. InInternational Conference on Machine Learning, pp. 2661–2670. PMLR, 2017
2017
-
[29]
A., Abbeel, P., and Peters, J
Osa, T., Pajarinen, J., Neumann, G., Bagnell, J. A., Abbeel, P., and Peters, J. An algorithmic perspective on imitation learning.Foundations and Trends® in Robotics, 7(1-2):1–179, 2018
2018
-
[30]
Multi-task reinforcement learning with context-based representations
Sodhani, S., Zhang, A., and Pineau, J. Multi-task reinforcement learning with context-based representations. InInternational Conference on Machine Learning, pp. 9767–9779. PMLR, 2021
2021
-
[31]
Hierarchical reinforcement learning for zero-shot generalization with subtask dependencies.Advances in neural information processing systems, 31, 2018
Sohn, S., Oh, J., and Lee, H. Hierarchical reinforcement learning for zero-shot generalization with subtask dependencies.Advances in neural information processing systems, 31, 2018
2018
-
[32]
Inductive generalization in reinforce- ment learning from specifications
Subramanian, V ., Kushwah, R., Roy, S., and Bansal, S. Inductive generalization in reinforce- ment learning from specifications. InInternational Symposium on Automated Technology for Verification and Analysis, pp. 277–298. Springer, 2025
2025
-
[33]
S., Barto, A
Sutton, R. S., Barto, A. G., et al.Reinforcement learning: An introduction, volume 1. MIT press Cambridge, 1998
1998
-
[34]
Reinforcement learning from reachability specifica- tions: Pac guarantees with expected conditional distance
Svoboda, J., Bansal, S., and Chatterjee, K. Reinforcement learning from reachability specifica- tions: Pac guarantees with expected conditional distance. InForty-first International Conference on Machine Learning, 2024
2024
-
[35]
M., Quan, J., Kirkpatrick, J., Hadsell, R., Heess, N., and Pascanu, R
Teh, Y ., Bapst, V ., Czarnecki, W. M., Quan, J., Kirkpatrick, J., Hadsell, R., Heess, N., and Pascanu, R. Distral: Robust multitask reinforcement learning.Advances in neural information processing systems, 30, 2017. 12
2017
-
[36]
Behavioral Cloning from Observation
Torabi, F., Warnell, G., and Stone, P. Behavioral cloning from observation.arXiv preprint arXiv:1805.01954, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[37]
Programmatically interpretable reinforcement learning
Verma, A., Murali, V ., Singh, R., Kohli, P., and Chaudhuri, S. Programmatically interpretable reinforcement learning. InInternational Conference on Machine Learning, pp. 5045–5054. PMLR, 2018
2018
-
[38]
and Topcu, U
Xu, Z. and Topcu, U. Transfer of temporal logic formulas in reinforcement learning. In International Joint Conference on Artificial Intelligence, pp. 4010–4018, 7 2019
2019
-
[39]
Yang, C., Littman, M., and Carbin, M. On the (in) tractability of reinforcement learning for ltl objectives.arXiv preprint arXiv:2111.12679, 2021
-
[40]
Z., Hasanbeig, M., Abate, A., and Kroening, D
Yuan, L. Z., Hasanbeig, M., Abate, A., and Kroening, D. Modular deep reinforcement learning with temporal logic specifications.arXiv preprint arXiv:1909.11591, 2019
-
[41]
A Study on Overfitting in Deep Reinforcement Learning
Zhang, C., Vinyals, O., Munos, R., and Bengio, S. A study on overfitting in deep reinforcement learning.arXiv preprint arXiv:1804.06893, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[42]
An inductive synthesis framework for verifiable reinforcement learning
Zhu, H., Xiong, Z., Magill, S., and Jagannathan, S. An inductive synthesis framework for verifiable reinforcement learning. InProceedings of the 40th ACM SIGPLAN conference on programming language design and implementation, pp. 686–701, 2019
2019
-
[43]
pick” region (typically the top block of the source tower), then reaches a designated “place
Zintgraf, L., Shiarlis, K., Igl, M., Schulze, S., Gal, Y ., Hofmann, K., and Whiteson, S. Varibad: A very good method for bayes-adaptive deep rl via meta-learning. InInternational Conference on Learning Representations, 2019. 13 Appendix A Limitations Our approach improves inductive generalization by learning a shared policy-evolution template, but it com...
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.