Idleness is Relative: Exploiting Tool-Call Idle Windows for Offloading in Agentic Systems with MORI
Pith reviewed 2026-06-28 17:28 UTC · model grok-4.3
The pith
MORI ranks agent programs by continuous relative idleness to assign KV cache between GPU HBM and CPU DRAM, matching hardware capacity ratios.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
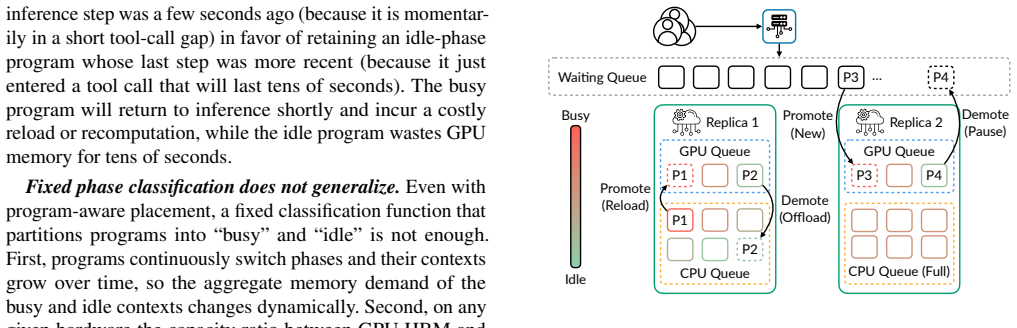
MORI is an agent serving system whose central mechanism ranks every active program by a continuous, relative idleness score derived from its recent tool-call pattern, assigns the busiest programs to GPU HBM and the most idle to CPU DRAM, shifts the partition point on the fly to equalize load with hardware capacity ratios, and applies admission control at each tier so that tool-call duration differences no longer cause wasteful migrations.
What carries the argument
Continuous relative idleness ranking across all programs, which dynamically sets the GPU-CPU partition boundary to match hardware capacity.
If this is right
- Memory tiers stay balanced without one sitting idle while the other evicts.
- KV cache placements remain stable across short tool calls inside a busy phase.
- Admission control prevents oversubscription at either tier even when the busy-idle mix changes.
- The same ranking works across different GPU sizes and model KV footprints without retuning.
Where Pith is reading between the lines
- The ranking could be combined with intra-tier eviction policies to further reduce migrations inside GPU or CPU.
- Similar relative-spectrum placement might apply to other two-tier systems such as local versus remote storage in distributed serving.
- Workloads without clear busy-idle phases would need an alternative signal to keep the ranking useful.
Load-bearing premise
Agentic programs exhibit a two-phase structure of rapid short calls and long-running calls that a single continuous idleness ranking can capture and align with hardware capacity ratios.
What would settle it
A workload trace in which replacing the relative idleness ranking with either LRU or a fixed binary label produces throughput and TTFT identical to MORI.
Figures

read the original abstract
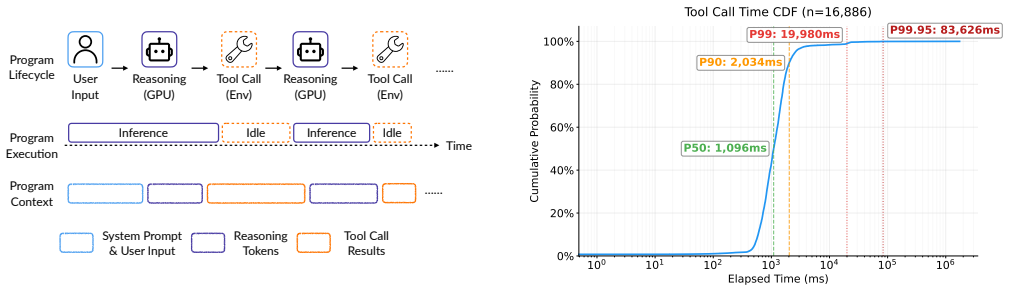
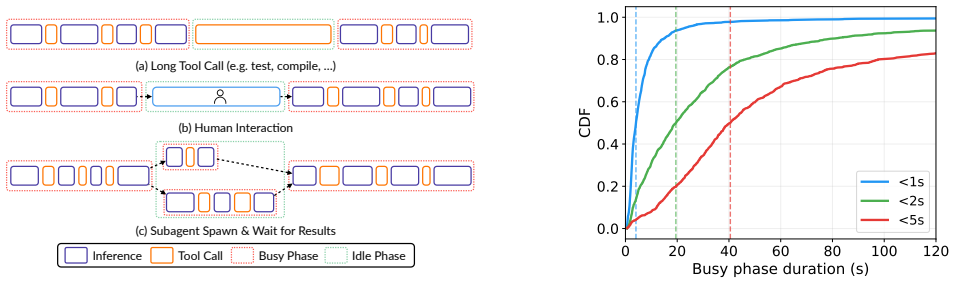
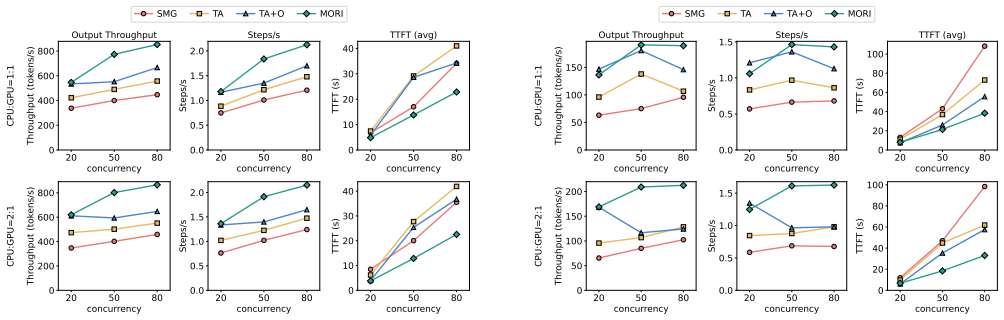
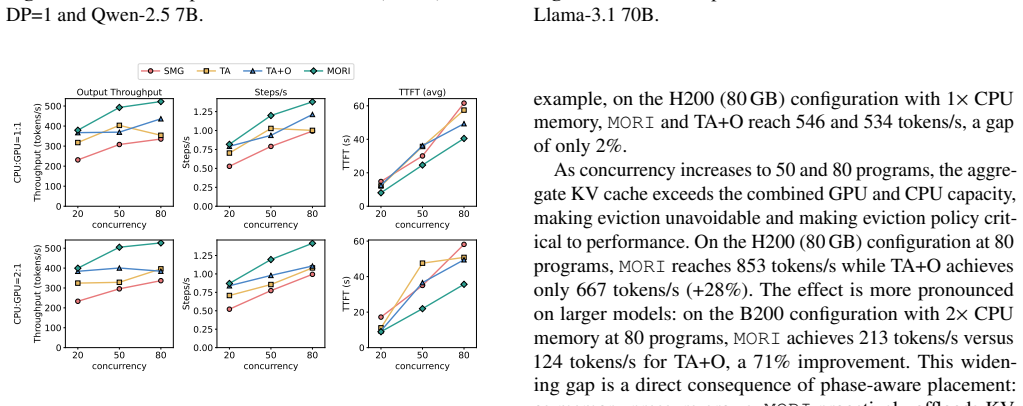
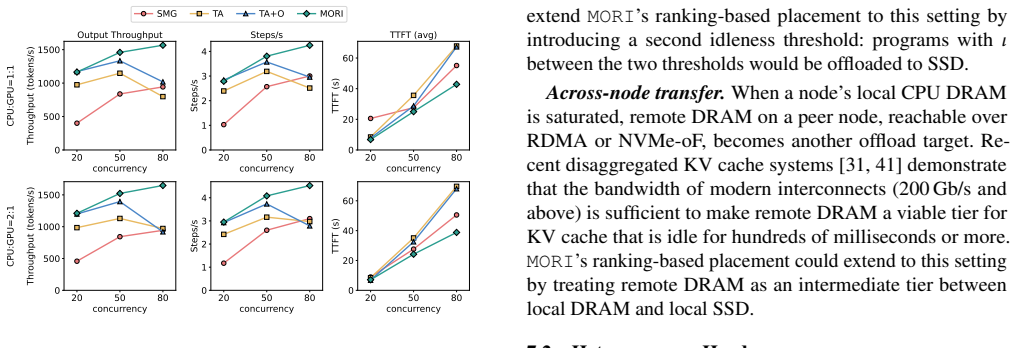
Modern LLM serving systems increasingly host agentic workloads, whose sessions issue tens of model invocations interleaved with tool calls, accumulating KV cache that can be reused across steps. As requests' total KV cache size easily exceeds GPU HBM capacity, researchers offload them to CPU DRAM. However, tool-call durations span orders of magnitude, and the cost of transferring KV cache between tiers makes it impractical to re-place entries on every call. We observe that agentic programs exhibit a two-phase structure: busy phases of rapid short tool calls and idle phases dominated by long-running calls. Current eviction policies such as LRU fail to capture this property. A binary busy/idle label also falls short because the ratio of busy to idle programs may not match the hardware's GPU-to-CPU capacity ratio. When it does not, one tier sits underutilized while the other is oversubscribed, wasting memory or forcing unnecessary evictions. We present MORI, an agent serving system that solves the above problem. Our key insight is that idleness is a continuous, relative spectrum. MORI ranks all active programs by idleness, assigns the busiest to GPU HBM and the most idle to CPU DRAM, dynamically shifts the partition boundary to match hardware capacity, and enforces admission control at each memory tier. Evaluated on real coding agent workloads collected from Claude Code across four GPU and model pairs, MORI delivers 20--71% higher throughput and 18--43% lower TTFT than the best baseline with offloading.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents MORI, a system for serving agentic LLM workloads that offloads KV cache between GPU HBM and CPU DRAM. It observes that such workloads exhibit busy phases of short tool calls and idle phases of long-running calls, and proposes ranking active programs on a continuous relative idleness spectrum to dynamically set the GPU/CPU partition boundary to match hardware capacity ratios while enforcing per-tier admission control. On real coding-agent workloads from Claude Code across four GPU/model pairs, it reports 20--71% higher throughput and 18--43% lower TTFT versus the best baseline that uses offloading.
Significance. If the central empirical claims hold after the design details are fully specified and the evaluation is expanded, the work would be significant for memory management in LLM serving systems. The insight that idleness is relative rather than binary, and the use of real agentic traces, are strengths; the approach could improve utilization when KV-cache footprints exceed HBM without requiring per-call migrations.
major comments (2)
- [Design / Algorithm description (referenced in abstract)] The algorithm or formula used to compute the continuous relative idleness ranking (the load-bearing mechanism that is claimed to align program placement with hardware capacity ratios) is not provided. Without an explicit definition or pseudocode, it is impossible to determine whether the ranking can be computed from past observations alone or requires lookahead/oracle knowledge of tool-call durations, directly affecting the validity of the two-phase exploitation claim.
- [Evaluation section] The evaluation reports aggregate throughput and TTFT gains but provides no description of the baseline offloading implementations, workload statistics (e.g., distribution of tool-call durations, number of programs, KV sizes), number of runs, or variance. This makes it impossible to assess whether the 20--71% and 18--43% improvements are robust or sensitive to post-hoc choices.
minor comments (1)
- [Abstract] The abstract states performance numbers but does not indicate whether the reported gains include confidence intervals or are from single runs.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The two major comments identify genuine gaps in the manuscript's presentation of the core algorithm and evaluation details. We will revise to address both.
read point-by-point responses
-
Referee: [Design / Algorithm description (referenced in abstract)] The algorithm or formula used to compute the continuous relative idleness ranking (the load-bearing mechanism that is claimed to align program placement with hardware capacity ratios) is not provided. Without an explicit definition or pseudocode, it is impossible to determine whether the ranking can be computed from past observations alone or requires lookahead/oracle knowledge of tool-call durations, directly affecting the validity of the two-phase exploitation claim.
Authors: We agree the manuscript lacks an explicit formula or pseudocode for the relative idleness ranking. This omission prevents readers from verifying that the mechanism relies only on past observations. In the revision we will add a precise definition of the idleness score (derived from each program's observed tool-call duration history), the ranking procedure, the dynamic boundary adjustment logic, and pseudocode. The ranking uses only historical data; no lookahead or oracle information is required. revision: yes
-
Referee: [Evaluation section] The evaluation reports aggregate throughput and TTFT gains but provides no description of the baseline offloading implementations, workload statistics (e.g., distribution of tool-call durations, number of programs, KV sizes), number of runs, or variance. This makes it impossible to assess whether the 20--71% and 18--43% improvements are robust or sensitive to post-hoc choices.
Authors: We agree that the evaluation section is missing these required details. The current manuscript reports only aggregate results without describing the baseline implementations, workload characteristics, run counts, or variance. In the revision we will expand the evaluation section to include full descriptions of the baselines, workload statistics (tool-call duration distributions, program counts, KV-cache sizes), number of runs, and standard deviations or confidence intervals for the reported throughput and TTFT gains. revision: yes
Circularity Check
No circularity; purely empirical system design and evaluation
full rationale
The paper contains no equations, derivations, fitted parameters, or self-citations. Its core claims rest on an empirical observation of workload structure followed by a system implementation (MORI) whose performance is measured against baselines on real Claude Code workloads. The idleness-ranking insight is presented as a design principle without any mathematical formalization that could reduce to its own inputs. No load-bearing step reduces by construction to a prior result or fit.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Agentic programs exhibit a two-phase structure: busy phases of rapid short tool calls and idle phases dominated by long-running calls.
Forward citations
Cited by 1 Pith paper
-
Libra: Efficient Resource Management for Agentic RL Post-Training
Libra optimizes GPU allocation across rollout and training in agentic RL via an elastic hybrid pool and C-MLFQ scheduler based on tool-return causal signals, claiming up to 3.0x throughput and 2.5x faster reward conve...
Reference graph
Works this paper leans on
-
[1]
Reyna Abhyankar, Zijian He, Vikranth Srivatsa, Hao Zhang, and Yiying Zhang. 2024. InferCept: Efficient Intercept Support for Augmented Large Language Model Inference. arXiv:2402.01869 [cs.LG]https: //arxiv.org/abs/2402.01869
arXiv 2024
-
[2]
Amey Agrawal, Nitin Kedia, Ashish Panwar, Jayashree Mohan, Nipun Kwatra, Bhargav Gulavani, Alexey Tumanov, and Ramachandran Ram- jee. 2024. Taming {Throughput-Latency} tradeoff in {LLM} inference with {Sarathi-Serve}. In18th USENIX symposium on operating systems design and implementation (OSDI 24). 117–134
2024
-
[3]
Joshua Ainslie, James Lee-Thorp, Michiel de Jong, Yury Zemlyanskiy, Federico Lebrón, and Sumit Sanghai. 2023. GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP)
2023
-
[4]
Anthropic. 2025. Best Practices for Claude Code: Subagents and Paral- lel Exploration.https://code.claude.com/docs/en/best-practices. Accessed: 2026-05-14
2025
-
[5]
Anthropic. 2025. Claude Code.https://www.anthropic.com/claude- code. Accessed: 2026-05-13
2025
-
[6]
Anthropic. 2025. Claude Code Model Configuration.https://code. claude.com/docs/en/model-config. Accessed: 2026-05-14
2025
-
[7]
Anysphere. 2024. Cursor: The AI Code Editor.https://cursor.com/. Accessed: 2026-05-13
2024
-
[8]
Anysphere. 2025. Subagents in Cursor.https://cursor.com/docs/ subagents. Accessed: 2026-05-14
2025
-
[9]
Mert Cemri, Melissa Z Pan, Shuyi Yang, Lakshya A Agrawal, Bhavya Chopra, Rishabh Tiwari, Kurt Keutzer, Aditya Parameswaran, Dan Klein, Kannan Ramchandran, et al . 2025. Why do multi-agent llm systems fail?Advances in Neural Information Processing Systems38 (2025)
2025
-
[10]
Xiang Deng, Jeff Da, Edwin Pan, Yannis Yiming He, Charles Ide, Kanak Garg, Niklas Lauffer, Andrew Park, Nitin Pasari, Chetan Rane, et al. 2025. Swe-bench pro: Can ai agents solve long-horizon software engineering tasks?arXiv preprint arXiv:2509.16941(2025)
Pith/arXiv arXiv 2025
-
[11]
Ishan Dhanani and Matej Kosec. 2026. Full-Stack Op- timizations for Agentic Inference with NVIDIA Dynamo. https://developer.nvidia.com/blog/full-stack-optimizations- for-agentic-inference-with-nvidia-dynamo/. NVIDIA Technical Blog. Accessed: 2026-05-15
2026
-
[12]
Bin Gao, Zhuomin He, Puru Sharma, Qingxuan Kang, Djordje Jevdjic, Junbo Deng, Xingkun Yang, Zhou Yu, and Pengfei Zuo. 2024. Cost- Efficient Large Language Model Serving for Multi-turn Conversations with CachedAttention. InProceedings of the 2024 USENIX Annual Technical Conference (ATC)
2024
-
[13]
In Gim, Zhiyao Ma, Seung-seob Lee, and Lin Zhong. 2025. Pie: A programmable serving system for emerging llm applications. InPro- ceedings of the ACM SIGOPS 31st Symposium on Operating Systems Principles. 415–430
2025
-
[14]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. 2024. The llama 3 herd of models. arXiv preprint arXiv:2407.21783(2024)
Pith/arXiv arXiv 2024
-
[15]
Tyler Griggs, Xiaoxuan Liu, Jiaxiang Yu, Doyoung Kim, Wei-Lin Chiang, Alvin Cheung, and Ion Stoica. 2024. Mélange: Cost Efficient Large Language Model Serving by Exploiting GPU Heterogeneity. arXiv preprint arXiv:2404.14527(2024)
arXiv 2024
-
[16]
Dongxin Guo, Jikun Wu, and Siu-Ming Yiu. 2026. SAGA: Workflow- Atomic Scheduling for AI Agent Inference on GPU Clusters.arXiv preprint arXiv:2605.00528(2026)
Pith/arXiv arXiv 2026
-
[17]
Taicheng Guo, Xiuying Chen, Yaqi Wang, Ruidi Chang, Shichao Pei, Nitesh V Chawla, Olaf Wiest, and Xiangliang Zhang. 2024. Large lan- guage model based multi-agents: A survey of progress and challenges. arXiv preprint arXiv:2402.01680(2024)
Pith/arXiv arXiv 2024
-
[18]
Sirui Hong, Mingchen Zhuge, Jonathan Chen, Xiawu Zheng, Yuheng Cheng, Jinlin Wang, Ceyao Zhang, Steven Yau, Zijuan Lin, Liyang Zhou, et al . 2024. MetaGPT: Meta programming for a multi-agent collaborative framework. InInternational Conference on Learning Representations, V ol. 2024. 23247–23275
2024
-
[19]
Cheng-Ping Hsieh, Simeng Sun, Samuel Kriman, Shantanu Acharya, Dima Rekesh, Fei Jia, Yang Zhang, and Boris Ginsburg. 2024. RULER: What’s the real context size of your long-context language models? arXiv preprint arXiv:2404.06654(2024)
Pith/arXiv arXiv 2024
-
[20]
Cunchen Hu, Heyang Huang, Junhao Hu, Jiang Xu, Xusheng Chen, Tao Xie, Chenxi Wang, Sa Wang, Yungang Bao, Ninghui Sun, and Yizhou Shan. 2024. MemServe: Context Caching for Disaggregated LLM Serving with Elastic Memory Pool.arXiv preprint arXiv:2406.17565 (2024)
arXiv 2024
-
[21]
Xuanlin Jiang, Yang Zhou, Shiyi Cao, Ion Stoica, and Minlan Yu. 2025. NEO: Saving GPU Memory Crisis with CPU Offloading for Online LLM Inference. InProceedings of Machine Learning and Systems (MLSys)
2025
-
[22]
Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. 2024. SWE-bench: Can Language Models Resolve Real-World GitHub Issues?. InProceedings of the International Conference on Learning Representations (ICLR)
2024
-
[23]
David S Johnson. 1974. Fast algorithms for bin packing.J. Comput. System Sci.8, 3 (1974), 272–314
1974
-
[24]
Hao Kang, Ziyang Li, Xinyu Yang, Weili Xu, Yinfang Chen, Junxiong Wang, Beidi Chen, Tushar Krishna, Chenfeng Xu, and Simran Arora
-
[25]
ThunderAgent: A Simple, Fast and Program-Aware Agentic Inference System.arXiv preprint arXiv:2602.13692(2026)
arXiv 2026
-
[26]
Gonzalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. 13
-
[27]
InProceedings of the 29th ACM Symposium on Operating Systems Principles (SOSP)
Efficient Memory Management for Large Language Model Serv- ing with PagedAttention. InProceedings of the 29th ACM Symposium on Operating Systems Principles (SOSP). 611–626
-
[28]
Wonbeom Lee, Jungi Lee, Junghwan Seo, and Jaewoong Sim. 2024. InfiniGen: Efficient Generative Inference of Large Language Models with Dynamic KV Cache Management. InProceedings of the 18th USENIX Symposium on Operating Systems Design and Implementation (OSDI)
2024
-
[29]
Hanchen Li, Runyuan He, Qiuyang Mang, Qizheng Zhang, Huanzhi Mao, Xiaokun Chen, Hangrui Zhou, Alvin Cheung, Joseph Gonzalez, and Ion Stoica. 2025. Continuum: Efficient and Robust Multi-Turn LLM Agent Scheduling with KV Cache Time-to-Live.arXiv preprint arXiv:2511.02230(2025)
Pith/arXiv arXiv 2025
-
[30]
Hanchen Li, Runyuan He, Qizheng Zhang, Changxiu Ji, Qiuyang Mang, Xiaokun Chen, Lakshya A Agrawal, Wei-Liang Liao, Eric Yang, Alvin Cheung, James Zou, Kunle Olukotun, Ion Stoica, and Joseph E. Gonzalez. 2026. Combee: Scaling Prompt Learning for Self-Improving Language Model Agents. arXiv:2604.04247 [cs.AI] https://arxiv.org/abs/2604.04247
Pith/arXiv arXiv 2026
-
[31]
Hanchen Li, Yuhan Liu, Yihua Cheng, Kuntai Du, and Junchen Jiang
-
[32]
arXiv:2503.14647 [cs.NI]https://arxiv
Towards More Economical Context-Augmented LLM Generation by Reusing Stored KV Cache. arXiv:2503.14647 [cs.NI]https://arxiv. org/abs/2503.14647
-
[33]
Chaofan Lin, Zhenhua Han, Chengruidong Zhang, Yuqing Yang, Fan Yang, Chen Chen, and Lili Qiu. 2024. Parrot: Efficient serving of {LLM-based} applications with semantic variable. In18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24). 929–945
2024
-
[34]
Yuhan Liu, Yihua Cheng, Jiayi Yao, Yuwei An, Xiaokun Chen, Shaot- ing Feng, Yuyang Huang, Samuel Shen, Rui Zhang, Kuntai Du, et al
-
[35]
Lmcache: An efficient KV cache layer for enterprise-scale LLM inference.arXiv preprint arXiv:2510.09665(2025)
arXiv 2025
-
[36]
Yuhan Liu, Hanchen Li, Yihua Cheng, Siddhant Ray, Yuyang Huang, Qizheng Zhang, Kuntai Du, Jiayi Yao, Shan Lu, Ganesh Anantha- narayanan, et al. 2024. Cachegen: Kv cache compression and stream- ing for fast large language model serving. InProceedings of the ACM SIGCOMM 2024 Conference. 38–56
2024
-
[37]
Michael Luo, Xiaoxiang Shi, Colin Cai, Tianjun Zhang, Justin Wong, Yichuan Wang, Chi Wang, Yanping Huang, Zhifeng Chen, Joseph E Gonzalez, and Ion Stoica. 2025. Autellix: An efficient serving engine for llm agents as general programs.arXiv preprint arXiv:2502.13965 (2025)
arXiv 2025
-
[38]
Yixuan Mei, Yonghao Zhuang, Xupeng Miao, Juncheng Yang, Zhihao Jia, and Rashmi Vinayak. 2025. Helix: Serving Large Language Models over Heterogeneous GPUs and Network via Max-Flow. InProceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS)
2025
-
[39]
NVIDIA. 2023. NVIDIA H100 Tensor Core GPU Architec- ture Whitepaper.https://resources.nvidia.com/en-us-hopper- architecture/nvidia-h100-tensor-c. Accessed: 2026-05-13
2023
-
[40]
OpenAI. 2025. Codex CLI: OpenAI’s Coding Agent in the Terminal. https://github.com/openai/codex. Accessed: 2026-05-13
2025
-
[41]
OpenAI. 2026. Why we no longer evaluate SWE-bench Veri- fied.https://openai.com/index/why-we-no-longer-evaluate-swe- bench-verified/. Accessed: 2026-05-11
2026
-
[42]
Zaifeng Pan, Ajjkumar Patel, Zhengding Hu, Yipeng Shen, Yue Guan, Wan-Lu Li, Lianhui Qin, Yida Wang, and Yufei Ding. 2025. KVFlow: Efficient Prefix Caching for Accelerating LLM-Based Multi-Agent Workflows. InAdvances in Neural Information Processing Systems (NeurIPS)
2025
-
[43]
Pratyush Patel, Esha Choukse, Chaojie Zhang, Aashaka Shah, Í nigo Goiri, Saeed Maleki, and Ricardo Bianchini. 2024. Splitwise: Efficient Generative LLM Inference Using Phase Splitting. InProceedings of the 51st Annual International Symposium on Computer Architecture (ISCA)
2024
-
[44]
Chen Qian, Wei Liu, Hongzhang Liu, Nuo Chen, Yufan Dang, Jiahao Li, Cheng Yang, Weize Chen, Yusheng Su, Xin Cong, et al. 2024. Chatdev: Communicative agents for software development. InProceedings of the 62nd annual meeting of the association for computational linguistics (volume 1: Long papers). 15174–15186
2024
-
[45]
Ruoyu Qin, Zheming Li, Weiran He, Mingxing Zhang, Yongwei Wu, Weimin Zheng, and Xinran Xu. 2024. Mooncake: A KVCache- Centric Disaggregated Architecture for LLM Serving.arXiv preprint arXiv:2407.00079(2024)
arXiv 2024
-
[46]
SGLang. 2026. SGLang Model Gateway.https://docs.sglang.io/docs/ advanced_features/sgl_model_gateway. SGLang Documentation. Accessed: 2026-05-15
2026
-
[47]
Noam Shazeer. 2019. Fast Transformer Decoding: One Write-Head is All You Need.arXiv preprint arXiv:1911.02150(2019)
Pith/arXiv arXiv 2019
-
[48]
Yongliang Shen, Kaitao Song, Xu Tan, Dongsheng Li, Weiming Lu, and Yueting Zhuang. 2023. Hugginggpt: Solving ai tasks with chatgpt and its friends in hugging face.Advances in Neural Information Processing Systems36 (2023), 38154–38180
2023
-
[49]
Fu, Zhiqiang Xie, Beidi Chen, Clark Barrett, Joseph E
Ying Sheng, Lianmin Zheng, Binhang Yuan, Zhuohan Li, Max Ryabinin, Daniel Y . Fu, Zhiqiang Xie, Beidi Chen, Clark Barrett, Joseph E. Gonzalez, Percy Liang, Christopher Ré, Ion Stoica, and Ce Zhang. 2023. FlexGen: High-Throughput Generative Inference of Large Language Models with a Single GPU. InProceedings of the 40th International Conference on Machine L...
2023
-
[50]
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. 2023. Reflexion: Language agents with verbal rein- forcement learning.Advances in neural information processing systems 36 (2023), 8634–8652
2023
-
[51]
Vikranth Srivatsa, Zijian He, Reyna Abhyankar, Dongming Li, and Yiying Zhang. 2025. Preble: Efficient distributed prompt scheduling for llm serving. InInternational conference on learning representations, V ol. 2025. 37057–37082
2025
-
[52]
Yifan Sui, Han Zhao, Rui Ma, Zhiyuan He, Hao Wang, Jianxun Li, and Yuqing Yang. 2026. Act While Thinking: Accelerating LLM Agents via Pattern-Aware Speculative Tool Execution.arXiv preprint arXiv:2603.18897(2026)
Pith/arXiv arXiv 2026
-
[53]
Biao Sun, Ziming Huang, Hanyu Zhao, Wencong Xiao, Xinyi Zhang, Yong Li, and Wei Lin. 2024. Llumnix: Dynamic scheduling for large language model serving. In18th USENIX symposium on operating systems design and implementation (OSDI 24). 173–191
2024
-
[54]
Hanshi Sun, Li-Wen Chang, Wenlei Bao, Size Zheng, Ningxin Zheng, Xin Liu, Harry Dong, Yuejie Chi, and Beidi Chen. 2024. ShadowKV: KV Cache in Shadows for High-Throughput Long-Context LLM Infer- ence.arXiv preprint arXiv:2410.21465(2024)
arXiv 2024
-
[55]
Xin Tan, Yimin Jiang, Yitao Yang, and Hong Xu. 2024. Teola: Towards end-to-end optimization of llm-based applications.arXiv preprint arXiv:2407.00326(2024)
arXiv 2024
-
[56]
Xin Tan, Yimin Jiang, Yitao Yang, and Hong Xu. 2025. Towards End-to-End Optimization of LLM-based Applications with Ayo. In Proceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2(Rotterdam, Netherlands)(ASPLOS ’25). Association for Computing Machinery, New York, NY , USA, 130...
-
[57]
Gomez, Łukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. At- tention Is All You Need. InAdvances in Neural Information Processing Systems (NeurIPS). 5998–6008
2017
-
[58]
Noppanat Wadlom, Junyi Shen, and Yao Lu. 2026. Efficient LLM Serving for Agentic Workflows: A Data Systems Perspective.arXiv preprint arXiv:2603.16104(2026)
arXiv 2026
-
[59]
Xingyao Wang, Boxuan Li, Yufan Song, Frank F Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, 14 et al. 2025. Openhands: An open platform for ai software developers as generalist agents. InInternational Conference on Learning Repre- sentations, V ol. 2025. 65882–65919
2025
-
[60]
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Shaokun Zhang, Jiale Liu, et al. 2024. Autogen: Enabling next-gen LLM applications via multi-agent conver- sations. InFirst conference on language modeling
2024
-
[61]
Jackson, Zhifei Li, Jiarong Xing, Scott Shenker, and Ion Stoica
Tian Xia, Ziming Mao, Jamison Kerney, Ethan J. Jackson, Zhifei Li, Jiarong Xing, Scott Shenker, and Ion Stoica. 2026. SkyWalker: A Locality-Aware Cross-Region Load Balancer for LLM Inference. In Proceedings of the 21st European Conference on Computer Systems (McEwan Hall/The University of Edinburgh, Edinburgh, Scotland UK) (EUROSYS ’26). Association for C...
-
[62]
Yuxing Xiang, Xue Li, Kun Qian, Wenyuan Yu, Ennan Zhai, and Xin Jin. 2025. ServeGen: Workload Characterization and Generation of Large Language Model Serving in Production. InProceedings of the 23rd USENIX Symposium on Networked Systems Design and Imple- mentation (NSDI)
2025
-
[63]
Zhiqiang Xie. 2025. SGLang HiCache: Fast Hierarchical KV Caching with Your Favorite Storage Backends.https://www.lmsys.org/blog/ 2025-09-10-sglang-hicache/
2025
-
[64]
Yi Xu, Ziming Mao, Xiangxi Mo, Shu Liu, and Ion Stoica. 2024. Pie: Pooling CPU Memory for LLM Inference. arXiv:2411.09317 [cs.LG] https://arxiv.org/abs/2411.09317
arXiv 2024
-
[65]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. 2025. Qwen3 technical report.arXiv preprint arXiv:2505.09388(2025)
Pith/arXiv arXiv 2025
-
[66]
An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, et al . 2024. Qwen2.5 technical report.arXiv preprint arXiv:2412.15115(2024)
Pith/arXiv arXiv 2024
-
[67]
John Yang, Carlos E Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. 2024. Swe-agent: Agent- computer interfaces enable automated software engineering.Advances in Neural Information Processing Systems37 (2024), 50528–50652
2024
-
[68]
Jiayi Yao, Hanchen Li, Yuhan Liu, Siddhant Ray, Yihua Cheng, Qizheng Zhang, Kuntai Du, Shan Lu, and Junchen Jiang. 2025. Cacheblend: Fast large language model serving for rag with cached knowledge fusion. In Proceedings of the twentieth European conference on computer systems. 94–109
2025
-
[69]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. 2023. ReAct: Synergizing Reasoning and Acting in Language Models.arXiv preprint arXiv:2210.03629(2023)
Pith/arXiv arXiv 2023
-
[70]
Zihao Ye, Lequn Chen, Ruihang Lai, Wuwei Lin, Yineng Zhang, Stephanie Wang, Tianqi Chen, Baris Kasikci, Vinod Grover, Arvind Krishnamurthy, et al. 2025. Flashinfer: Efficient and customizable attention engine for llm inference serving.Proceedings of Machine Learning and Systems7 (2025)
2025
-
[71]
Gyeong-In Yu, Joo Seong Jeong, Geon-Woo Kim, Soojeong Kim, and Byung-Gon Chun. 2022. Orca: A Distributed Serving System for Transformer-Based Generative Models. InProceedings of the 16th USENIX Symposium on Operating Systems Design and Implementation (OSDI). 521–538
2022
-
[72]
Gonzalez, Clark Barrett, and Ying Sheng
Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Chuyue Sun, Jeff Huang, Cody Hao Yu, Shiyi Cao, Christos Kozyrakis, Ion Stoica, Joseph E. Gonzalez, Clark Barrett, and Ying Sheng. 2024. SGLang: Ef- ficient Execution of Structured Language Model Programs. InAdvances in Neural Information Processing Systems (NeurIPS)
2024
-
[73]
Yinmin Zhong, Shengyu Liu, Junda Chen, Jianbo Hu, Yibo Zhu, Xu- anzhe Liu, Xin Jin, and Hao Zhang. 2024. {DistServe}: Disaggregating prefill and decoding for goodput-optimized large language model serv- ing. In18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24). 193–210
2024
-
[74]
Kan Zhu, Yufei Gao, Yilong Zhao, Liangyu Zhao, Gefei Zuo, Yile Gu, Dedong Xie, Zihao Ye, Keisuke Kamahori, Chien-Yu Lin, et al
-
[75]
In19th USENIX Symposium on Operating Systems Design and Implementation (OSDI 25)
{NanoFlow}: Towards optimal large language model serving throughput. In19th USENIX Symposium on Operating Systems Design and Implementation (OSDI 25). 749–765. 15
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.