Libra: Efficient Resource Management for Agentic RL Post-Training
Pith reviewed 2026-06-28 10:59 UTC · model grok-4.3
The pith
Libra uses an elastic GPU pool and causality-driven scheduling to manage resources in agentic RL post-training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
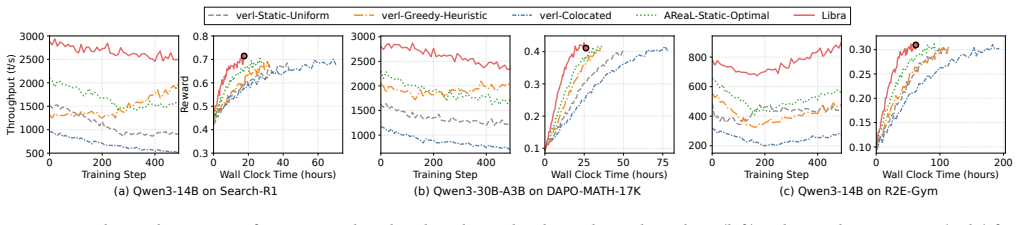
Libra is a resource management system that jointly optimizes GPU allocation across rollout and training via an elastic hybrid pool and routes rollout requests using a causality-driven multi-level feedback queue based on tool-return signals, achieving up to 3x throughput and 2.5x faster reward convergence on 48 GPUs.
What carries the argument
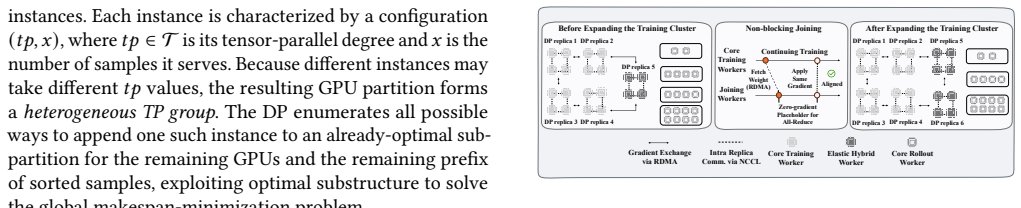
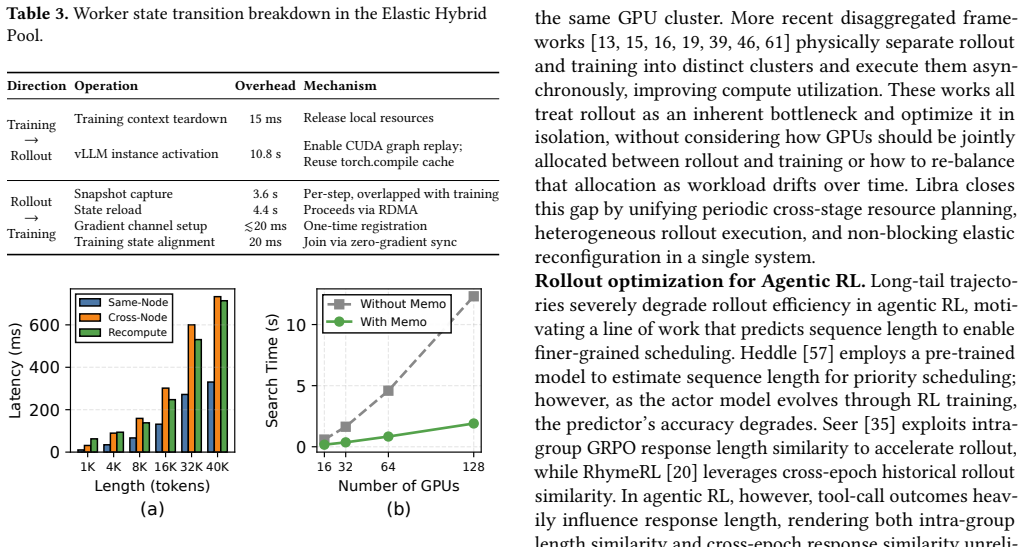
The global resource planner with elastic hybrid pool and the causality-driven multi-level feedback queue (C-MLFQ) scheduler, which together enable dynamic reallocation and adaptive scheduling without length predictions.
If this is right
- Dynamic GPU reallocation between stages reduces makespan dominated by long-tail trajectories.
- Using causal signals from tool returns avoids errors from length predictions in non-stationary environments.
- Joint optimization across rollout and training clusters improves overall efficiency in agentic RL.
- The system handles continuous drift in sequence length distribution effectively.
- Results in faster policy convergence due to reduced idle time.
Where Pith is reading between the lines
- This approach could extend to other multi-stage RL pipelines with asymmetric workloads.
- The scheduler might improve performance in environments with variable tool latencies.
- Scaling to larger GPU clusters could amplify the benefits if reallocation overhead remains low.
- It suggests that causal feedback is more robust than predictive models for scheduling in evolving policies.
Load-bearing premise
The assumption that sequence length distribution drifts continuously as the policy evolves, making any fixed resource split suboptimal over time.
What would settle it
A comparison experiment where sequence lengths remain stationary after initial training, showing no performance gain from dynamic allocation over static baselines.
Figures






read the original abstract
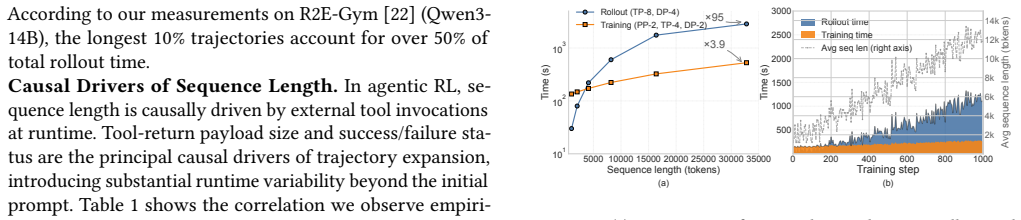
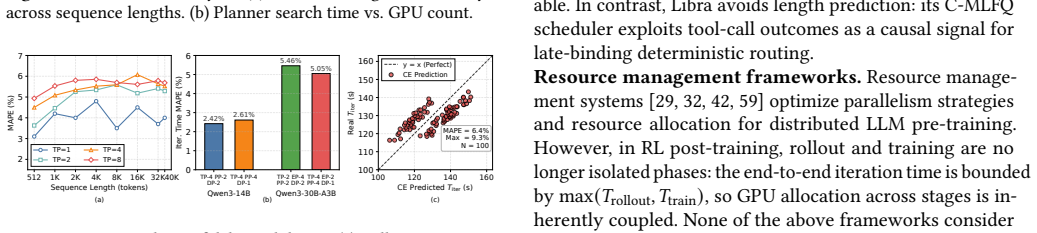
Reinforcement learning (RL) has emerged as a standard post-training paradigm for shaping large language models (LLMs) into capable agents. In agentic RL, the rollout stage generates trajectories while invoking tools, producing long-tailed and non-stationary workloads that expose two fundamental challenges in resource management. First, due to the long-tail distribution, a small fraction of trajectories dominates rollout makespan. Second, rollout and training are subject to cross-stage imbalance, as they exhibit strong asymmetry in compute patterns, memory demands, and sensitivity to sequence length. Compounding this asymmetry, the sequence length distribution drifts continuously as the policy evolves, rendering any static resource split progressively suboptimal. We present Libra, a resource management system to address both challenges via two core mechanisms. The first is a global resource planner that jointly optimizes GPU allocation across rollout and training clusters. It leverages an elastic hybrid pool to enable lightweight, non-blocking worker reallocation between stages. The second is a causality-driven multi-level feedback queue (C-MLFQ) scheduler, which routes requests to heterogeneous rollout buckets based on causal signals derived from tool-return outcomes, rather than relying on fragile length predictions. Evaluated on 48 A800 GPUs, Libra achieves up to 3.0x higher throughput and converges up to 2.5x faster in reward compared to the baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Libra, a resource management system for agentic RL post-training of LLMs. It targets two challenges: long-tailed non-stationary rollout workloads that make a small fraction of trajectories dominate makespan, and cross-stage imbalance between rollout and training due to differing compute/memory patterns and sequence-length sensitivity. The proposed mechanisms are a global resource planner that uses an elastic hybrid pool for non-blocking GPU reallocation between stages, and a causality-driven multi-level feedback queue (C-MLFQ) scheduler that routes based on tool-return outcomes rather than length predictions. On 48 A800 GPUs the system is reported to deliver up to 3.0× higher throughput and 2.5× faster reward convergence relative to baselines.
Significance. If the empirical claims hold after the requested clarifications, the work would provide a concrete, deployable solution to a practical bottleneck in scaling RL post-training for tool-using agents. The elastic pool and causal scheduler constitute a targeted response to workload non-stationarity that is not addressed by conventional static partitioning or generic schedulers.
major comments (1)
- [Evaluation] The central performance claims (3.0× throughput, 2.5× faster convergence) are attributed to the dynamic mechanisms that respond to continuous drift in sequence-length distributions. The manuscript does not report measurements of length-distribution shift across training steps, nor does it include an ablation that compares the dynamic planner against a well-tuned static split on the same trajectories. Without such evidence it is impossible to determine whether the reported gains arise from adaptation to non-stationarity or from other implementation details.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the evaluation. We address the major comment below and will incorporate revisions to strengthen the empirical support for our claims.
read point-by-point responses
-
Referee: [Evaluation] The central performance claims (3.0× throughput, 2.5× faster convergence) are attributed to the dynamic mechanisms that respond to continuous drift in sequence-length distributions. The manuscript does not report measurements of length-distribution shift across training steps, nor does it include an ablation that compares the dynamic planner against a well-tuned static split on the same trajectories. Without such evidence it is impossible to determine whether the reported gains arise from adaptation to non-stationarity or from other implementation details.
Authors: We agree that direct measurements of sequence-length distribution shift and a targeted ablation against a static split would provide clearer evidence isolating the benefit of adaptation. In the revised manuscript we will add (i) plots of sequence-length distributions at multiple training checkpoints to quantify the drift and (ii) an ablation that fixes GPU allocation to a static split tuned on the initial distribution and compares it to Libra on identical trajectories. These additions will allow readers to assess how much of the reported gains derive from handling non-stationarity versus other system details. The current text already motivates the non-stationary workload from policy evolution, but the requested data will make this concrete. revision: yes
Circularity Check
No circularity: purely empirical systems evaluation with no derivations or fitted predictions.
full rationale
The paper presents Libra as a resource management system with two mechanisms (global resource planner and C-MLFQ scheduler) motivated by stated challenges in agentic RL workloads. All central claims are performance numbers from direct evaluation on 48 A800 GPUs (3.0x throughput, 2.5x faster convergence). No equations, parameters fitted to subsets then re-predicted, self-citations used as load-bearing uniqueness theorems, or ansatzes appear in the provided text. The description of sequence-length drift is presented as an empirical observation rather than a derived result that reduces to its own inputs. The derivation chain is therefore self-contained against external benchmarks and receives score 0.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Megatron-LM
2025. Megatron-LM. (2025). https://github.com/NVIDIA/Megatron- LM. 12
2025
-
[2]
Amey Agrawal, Nitin Kedia, Jayashree Mohan, Ashish Panwar, Nipun Kwatra, Bhargav S Gulavani, Ramachandran Ramjee, and Alexey Tu- manov. 2024. Vidur: A Large-Scale Simulation Framework for LLM Inference.Proceedings of Machine Learning and Systems6 (2024), 351–366
2024
-
[3]
Amey Agrawal, Nitin Kedia, Ashish Panwar, Jayashree Mohan, Nipun Kwatra, Bhargav Gulavani, Alexey Tumanov, and Ramachandran Ram- jee. 2024. Taming Throughput-Latency Tradeoff in LLM Inference with Sarathi-Serve. In18th USENIX symposium on operating systems design and implementation (OSDI 24). 117–134
2024
-
[4]
AMD ROCm. 2025. The vLLM MoE Playbook: A Practical Guide to TP, DP, PP and Expert Parallelism.https://rocm.blogs.amd.com/software- tools-optimization/vllm-moe-guide/README.html
2025
-
[5]
Yuntao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova DasSarma, Dawn Drain, Stanislav Fort, Deep Ganguli, Tom Henighan, Nicholas Joseph, Saurav Kadavath, Jackson Kernion, Tom Conerly, Sheer El-Showk, Nelson Elhage, Zac Hatfield-Dodds, Danny Hernandez, Tristan Hume, Scott Johnston, Shauna Kravec, Liane Lovitt, Neel Nanda, Catherine Olsson, ...
Pith/arXiv arXiv 2022
-
[6]
Zhuohang Bian, Feiyang Wu, Teng Ma, and Youwei Zhuo. 2025. Token- cake: A KV-Cache-centric Serving Framework for LLM-based Multi- Agent Applications.arXiv preprint arXiv:2510.18586(2025)
Pith/arXiv arXiv 2025
-
[7]
Haoyu Chen, Xue Li, Kun Qian, Yu Guan, Jin Zhao, and Xin Wang. 2026. Amoeba: Runtime Tensor Parallel Transformation for LLM Inference Services. arXiv:2509.19729 [cs.DC]https://arxiv.org/abs/2509.19729
Pith/arXiv arXiv 2026
-
[8]
Paul F Christiano, Jan Leike, Tom Brown, Miljan Martic, Shane Legg, and Dario Amodei. 2017. Deep Reinforcement Learning from Human Preferences.Advances in neural information processing systems30 (2017)
2017
-
[9]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. 2025. Gemini 2.5: Pushing the Frontier with Advanced Reasoning, Multimodality, Long Context, and Next Genera- tion Agentic Capabilities.arXiv preprint arXiv:2507.06261(2025)
Pith/arXiv arXiv 2025
-
[10]
Jiazhan Feng, Shijue Huang, Xingwei Qu, Ge Zhang, Yujia Qin, Bao- quan Zhong, Chengquan Jiang, Jinxin Chi, and Wanjun Zhong. 2025. ReTool: Reinforcement Learning for Strategic Tool Use in LLMs. arXiv:2504.11536 [cs.CL]https://arxiv.org/abs/2504.11536
Pith/arXiv arXiv 2025
-
[11]
Yicheng Feng, Yuetao Chen, Kaiwen Chen, Jingzong Li, Tianyuan Wu, Peng Cheng, Chuan Wu, Wei Wang, Tsung-Yi Ho, and Hong Xu. 2024. Echo: Simulating Distributed Training At Scale. arXiv:2412.12487 [cs.LG]https://arxiv.org/abs/2412.12487
arXiv 2024
-
[12]
Yicheng Feng, Xin Tan, Yangtao Deng, Yimin Jiang, Yibo Zhu, and Hong Xu. 2026. Frontier: Towards Comprehensive and Accurate LLM Inference Simulation.arXiv preprint arXiv:2605.21312(2026)
Pith/arXiv arXiv 2026
-
[13]
Wei Fu, Jiaxuan Gao, Xujie Shen, Chen Zhu, Zhiyu Mei, Chuyi He, Shusheng Xu, Guo Wei, Jun Mei, Jiashu Wang, et al. 2026. Areal: A Large-Scale Asynchronous Reinforcement Learning System for Lan- guage Reasoning.Advances in Neural Information Processing Systems 38 (2026), 36256–36282
2026
-
[14]
Wei Gao, Yuheng Zhao, Dakai An, Tianyuan Wu, Lunxi Cao, Shaopan Xiong, Ju Huang, Weixun Wang, Siran Yang, Wenbo Su, et al. 2025. RollPacker: Mitigating Long-Tail Rollouts for Fast, Synchronous RL Post-Training.arXiv preprint arXiv:2509.21009(2025)
arXiv 2025
-
[15]
Wei Gao, Yuheng Zhao, Dilxat Muhtar, Dakai An, Xuchun Shang, Tianyuan Wu, Lunxi Cao, Shaopan Xiong, Weixun Wang, Ju Huang, Teng Ma, Siran Yang, Jiamang Wang, Lin Qu, Bo Zheng, and Wei Wang
-
[16]
arXiv:2605.06534 [cs.DC]https://arxiv.org/abs/2605.06534
ROSE: Rollout On Serving GPUs via Cooperative Elasticity for Agentic RL. arXiv:2605.06534 [cs.DC]https://arxiv.org/abs/2605.06534
-
[17]
Wei Gao, Yuheng Zhao, Tianyuan Wu, Shaopan Xiong, Weixun Wang, Dakai An, Lunxi Cao, Dilxat Muhtar, Zichen Liu, Haizhou Zhao, Ju Huang, Siran Yang, Yongbin Li, Wenbo Su, Jiamang Wang, Lin Qu, Bo Zheng, and Wei Wang. 2025. RollArt: Scaling Agentic RL Training via Disaggregated Infrastructure. arXiv:2512.22560 [cs.DC]https: //arxiv.org/abs/2512.22560
arXiv 2025
-
[18]
Zhibin Gou, Zhihong Shao, Yeyun Gong, Yujiu Yang, Minlie Huang, Nan Duan, Weizhu Chen, et al. 2024. Tora: A Tool-Integrated Reason- ing Agent for Mathematical Problem Solving. InInternational Confer- ence on Learning Representations, Vol. 2024. 48362–48395
2024
-
[19]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, Xiaokang Zhang, Xingkai Yu, Yu Wu, Z. F. Wu, Zhibin Gou, Zhihong Shao, Zhuoshu Li, Ziyi Gao, Aixin Liu, Bing Xue, Bingxuan Wang, Bochao Wu, Bei Feng, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chong Ruan, Damai Dai, Deli Chen, Dongjie Ji, ...
2025
-
[20]
Zhenyu Han, Ansheng You, Haibo Wang, Kui Luo, Guang Yang, Wenqi Shi, Menglong Chen, Sicheng Zhang, Zeshun Lan, Chunshi Deng, et al
-
[21]
AsyncFlow: An Asynchronous Streaming RL Framework for Efficient LLM Post-Training.arXiv preprint arXiv:2507.01663(2025)
arXiv 2025
-
[22]
Jingkai He, Tianjian Li, Erhu Feng, Dong Du, Qian Liu, Tao Liu, Yu- bin Xia, and Haibo Chen. 2025. History Rhymes: Accelerating LLM Reinforcement Learning with RhymeRL. arXiv:2508.18588 [cs.LG] https://arxiv.org/abs/2508.18588
arXiv 2025
-
[23]
Jian Hu, Xibin Wu, Wei Shen, Jason Klein Liu, Zilin Zhu, Weixun Wang, Songlin Jiang, Haoran Wang, Hao Chen, Bin Chen, Weikai Fang, Xianyu, Yu Cao, Haotian Xu, and Yiming Liu. 2025. OpenRLHF: An Easy-to-use, Scalable and High-performance RLHF Framework. arXiv:2405.11143 [cs.AI]https://arxiv.org/abs/2405.11143
Pith/arXiv arXiv 2025
-
[24]
Naman Jain, Jaskirat Singh, Manish Shetty, Liang Zheng, Koushik Sen, and Ion Stoica. 2025. R2E-Gym: Procedural Environments 13 and Hybrid Verifiers for Scaling Open-Weights SWE Agents. arXiv:2504.07164 [cs.SE]https://arxiv.org/abs/2504.07164
arXiv 2025
-
[25]
Dongfu Jiang, Yi Lu, Zhuofeng Li, Zhiheng Lyu, Ping Nie, Haozhe Wang, Alex Su, Hui Chen, Kai Zou, Chao Du, et al. 2025. VerlTool: To- wards Holistic Agentic Reinforcement Learning with Tool Use.arXiv preprint arXiv:2509.01055(2025)
arXiv 2025
-
[26]
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. 2024. Swe-bench: Can Language Models Resolve Real-World Github Issues?. InInternational Conference on Learning Representations, Vol. 2024. 54107–54157
2024
-
[27]
Bowen Jin, Hansi Zeng, Zhenrui Yue, Jinsung Yoon, Sercan Arik, Dong Wang, Hamed Zamani, and Jiawei Han. 2025. Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning. arXiv:2503.09516 [cs.CL]https://arxiv.org/abs/2503.09516
Pith/arXiv arXiv 2025
-
[28]
Komal Kumar, Tajamul Ashraf, Omkar Thawakar, Rao Muhammad Anwer, Hisham Cholakkal, Mubarak Shah, Ming-Hsuan Yang, Phillip H. S. Torr, Fahad Shahbaz Khan, and Salman Khan. 2025. LLM Post-Training: A Deep Dive into Reasoning Large Language Mod- els. arXiv:2502.21321 [cs.CL]https://arxiv.org/abs/2502.21321
arXiv 2025
-
[29]
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica
-
[30]
InProceedings of the 29th symposium on operating systems principles
Efficient Memory Management for Large Language Model Serving with PagedAttention. InProceedings of the 29th symposium on operating systems principles. 611–626
-
[31]
Hanchen Li, Runyuan He, Qiuyang Mang, Qizheng Zhang, Huanzhi Mao, Xiaokun Chen, Hangrui Zhou, Alvin Cheung, Joseph Gon- zalez, and Ion Stoica. 2026. Continuum: Efficient and Robust Multi-Turn LLM Agent Scheduling with KV Cache Time-to-Live. arXiv:2511.02230 [cs.OS]https://arxiv.org/abs/2511.02230
Pith/arXiv arXiv 2026
-
[32]
Jiamin Li, Hong Xu, Yibo Zhu, Zherui Liu, Chuanxiong Guo, and Cong Wang. 2023. Lyra: Elastic Scheduling for Deep Learning Clusters. InProceedings of the Eighteenth European Conference on Computer Systems. 835–850
2023
-
[33]
MAA. 2025. American Invitational Mathematics Examination - AIME. https://huggingface.co/datasets/di-zhang-fdu/AIME_1983_2024
2025
-
[34]
Zhiyu Mei, Wei Fu, Kaiwei Li, Guangju Wang, Huanchen Zhang, and Yi Wu. 2025. ReaL: Efficient RLHF Training of Large Language Models with Parameter Reallocation.Proceedings of Machine Learning and Systems7 (2025)
2025
-
[35]
Xupeng Miao, Yujie Wang, Youhe Jiang, Chunan Shi, Xiaonan Nie, Hailin Zhang, and Bin Cui. 2022. Galvatron: Efficient Transformer Training over Multiple GPUs Using Automatic Parallelism.Proc. VLDB Endow.16, 3 (Nov. 2022), 470–479. doi:10.14778/3570690.3570697
-
[36]
Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wain- wright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Chris- tiano, Jan Leike, and Ryan Lowe. 2022. Training language models to follow instructions with human...
Pith/arXiv arXiv 2022
-
[37]
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, Alban Desmaison, Andreas Köpf, Edward Yang, Zach DeVito, Martin Raison, Alykhan Tejani, Sasank Chil- amkurthy, Benoit Steiner, Lu Fang, and Soumith Chintala. 2019. Py- Torch: An Imperative Style, High-Performanc...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1912.01703 2019
-
[38]
Ruoyu Qin, Weiran He, Weixiao Huang, Yangkun Zhang, Yikai Zhao, Bo Pang, Xinran Xu, Yingdi Shan, Yongwei Wu, and Mingxing Zhang
-
[39]
Seer: Online Context Learning for Fast Synchronous LLM Rein- forcement Learning.arXiv preprint arXiv:2511.14617(2025)
Pith/arXiv arXiv 2025
-
[40]
Omkar Salpekar, Rohan Varma, Kenny Yu, Vladimir Ivanov, Yang Wang, Ahmed Sharif, Min Si, Shawn Xu, Feng Tian, Shengbao Zheng, Tristan Rice, Ankush Garg, Shangfu Peng, Shreyas Siravara, Wenyin Fu, Rodrigo de Castro, Adithya Gangidi, Andrey Obraztsov, Sha- ran Narang, Sergey Edunov, Maxim Naumov, Chunqiang Tang, and Mathew Oldham. 2026. Training LLMs with F...
arXiv 2026
-
[41]
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. 2017. Proximal Policy Optimization Algorithms. arXiv:1707.06347 [cs.LG]https://arxiv.org/abs/1707.06347
Pith/arXiv arXiv 2017
-
[42]
Rana Shahout, Eran Malach, Chunwei Liu, Weifan Jiang, Minlan Yu, and Michael Mitzenmacher. 2025. Don’t Stop Me Now: Embedding Based Scheduling for LLMs. InInternational Conference on Learning Representations, Vol. 2025. 63345–63368
2025
-
[43]
Guangming Sheng, Yuxuan Tong, Borui Wan, Wang Zhang, Chaobo Jia, Xibin Wu, Yuqi Wu, Xiang Li, Chi Zhang, Yanghua Peng, Haibin Lin, Xin Liu, and Chuan Wu. 2025. Laminar: A Scalable Asynchronous RL Post-Training Framework. arXiv:2510.12633 [cs.LG]https://arxiv. org/abs/2510.12633
arXiv 2025
-
[44]
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. 2025. Hybrid- Flow: A Flexible and Efficient RLHF Framework. InProceedings of the Twentieth European Conference on Computer Systems(Rotterdam, Netherlands)(EuroSys ’25). Association for Computing Machinery, New York, NY, USA, 1279–1297. doi:1...
-
[45]
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. 2023. Reflexion: language agents with verbal reinforcement learning. InAdvances in Neural Information Processing Systems, A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine (Eds.), Vol. 36. Curran Associates, Inc., 8634–8652.https://proceedings.neurips.cc/p...
2023
-
[46]
Foteini Strati, Zhendong Zhang, George Manos, Ixeia Sánchez Périz, Qinghao Hu, Tiancheng Chen, Berk Buzcu, Song Han, Pamela Delgado, and Ana Klimovic. 2025. Sailor: Automating Distributed Training over Dynamic, Heterogeneous, and Geo-distributed Clusters. InProceedings of the ACM SIGOPS 31st Symposium on Operating Systems Principles (Lotte Hotel World, Se...
arXiv 2025
-
[47]
Xin Tan, Yicheng Feng, Yu Zhou, Yimin Jiang, Yibo Zhu, and Hong Xu. 2026. OrchestrRL: Dynamic Compute and Network Orchestration for Disaggregated RL. arXiv:2601.01209 [cs.DC]https://arxiv.org/abs/ 2601.01209
arXiv 2026
-
[48]
Kimi Team, Angang Du, Bofei Gao, Bowei Xing, Changjiu Jiang, Cheng Chen, Cheng Li, Chenjun Xiao, Chenzhuang Du, Chonghua Liao, Chuning Tang, Congcong Wang, Dehao Zhang, Enming Yuan, Enzhe Lu, Fengxiang Tang, Flood Sung, Guangda Wei, Guokun Lai, Haiqing Guo, Han Zhu, Hao Ding, Hao Hu, Hao Yang, Hao Zhang, Haotian Yao, Haotian Zhao, Haoyu Lu, Haoze Li, Haoz...
Pith/arXiv arXiv 2025
-
[49]
Hanyin Wang, Zhenbang Wu, Gururaj Kolar, Hariprasad Korsapati, Brian Bartlett, Bryan Hull, and Jimeng Sun. 2026. Reinforcement Learn- ing for Out-of-Distribution Reasoning in LLMs: An Empirical Study on Diagnosis-Related Group Coding.Advances in Neural Information Processing Systems38 (2026), 43031–43065
2026
-
[50]
Taiyi Wang, Zhihao Wu, Jianheng Liu, Jianye Hao, Jun Wang, and Kun Shao. 2025. Distrl: An Asynchronous Distributed Reinforcement Learning Framework for On-Device Control Agent. InInternational Conference on Learning Representations, Vol. 2025. 74757–74782
2025
-
[51]
Weixun Wang, Shaopan Xiong, Gengru Chen, Wei Gao, Sheng Guo, Yancheng He, Ju Huang, Jiaheng Liu, Zhendong Li, Xiaoyang Li, Zichen Liu, Haizhou Zhao, Dakai An, Lunxi Cao, Qiyang Cao, Wanxi Deng, Feilei Du, Yiliang Gu, Jiahe Li, Xiang Li, Mingjie Liu, Yijia Luo, Zihe Liu, Yadao Wang, Pei Wang, Tianyuan Wu, Yanan Wu, Yuheng Zhao, Shuaibing Zhao, Jin Yang, Si...
arXiv 2025
-
[52]
Xizheng Wang, Qingxu Li, Yichi Xu, Gang Lu, Dan Li, Li Chen, Heyang Zhou, Linkang Zheng, Sen Zhang, Yikai Zhu, et al . 2025. SimAI: Unifying Architecture Design and Performance Tuning for Large-Scale Large Language Model Training with Scalability and Precision. In22nd USENIX Symposium on Networked Systems Design and Implementation (NSDI 25). 541–558
2025
-
[53]
Bo Wu, Sid Wang, Yunhao Tang, Jia Ding, Eryk Helenowski, Liang Tan, Tengyu Xu, Tushar Gowda, Zhengxing Chen, Chen Zhu, et al
-
[54]
LlamaRL: A Distributed Asynchronous Reinforcement Learning Framework for Efficient Large-scale LLM Training.arXiv preprint arXiv:2505.24034(2025)
arXiv 2025
-
[55]
Tian Xia, Hanchen Li, Zhifei Li, Xiaokun Chen, Hao Kang, Yifan Qiao, Yi Xu, and Ion Stoica. 2026. Idleness is Relative: Exploiting Tool- Call Idle Windows for Offloading in Agentic Systems with MORI. arXiv:2606.00866 [cs.OS]https://arxiv.org/abs/2606.00866
Pith/arXiv arXiv 2026
-
[56]
Violet Xiang, Chase Blagden, Rafael Rafailov, Nathan Lile, Sang Truong, Chelsea Finn, and Nick Haber. 2025. Just Enough Thinking: Efficient Reasoning with Adaptive Length Penalties Reinforcement Learning.arXiv preprint arXiv:2506.05256(2025)
arXiv 2025
-
[57]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. 2025. Qwen3 Technical Report.arXiv preprint arXiv:2505.09388(2025)
Pith/arXiv arXiv 2025
-
[58]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. 2023. ReAct: Synergizing Reasoning and Acting in Language Models. In11th International Conference on Learning Representations, ICLR 2023
2023
-
[59]
Zhewei Yao, Reza Yazdani Aminabadi, Olatunji Ruwase, Samyam Rajbhandari, Xiaoxia Wu, Ammar Ahmad Awan, Jeff Rasley, Minjia Zhang, Conglong Li, Connor Holmes, et al. 2023. DeepSpeed-Chat: Easy, Fast and Affordable RLHF Training of ChatGPT-like Models at All Scales.arXiv preprint arXiv:2308.01320(2023)
arXiv 2023
-
[60]
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, Xin Liu, Haibin Lin, Zhiqi Lin, Bole Ma, Guangming Sheng, Yuxuan Tong, Chi Zhang, Mofan Zhang, Wang Zhang, Hang Zhu, Jinhua Zhu, Jiaze Chen, Jiangjie Chen, Chengyi Wang, Hongli Yu, Yuxuan Song, Xiangpeng Wei, Hao Zhou, Jingjing Liu, W...
Pith/arXiv arXiv 2025
-
[61]
Guibin Zhang, Hejia Geng, Xiaohang Yu, Zhenfei Yin, Zaibin Zhang, Zelin Tan, Heng Zhou, Zhongzhi Li, Xiangyuan Xue, Yijiang Li, et al
-
[62]
The Landscape of Agentic Reinforcement Learning for LLMs: A Survey.arXiv preprint arXiv:2509.02547(2025)
Pith/arXiv arXiv 2025
-
[63]
Zili Zhang, Yinmin Zhong, Chengxu Yang, Chao Jin, Bingyang Wu, Xinming Wei, Yuliang Liu, and Xin Jin. 2026. Heddle: A Distributed Orchestration System for Agentic RL Rollout. arXiv:2603.28101 [cs.LG] https://arxiv.org/abs/2603.28101
arXiv 2026
-
[64]
Yanli Zhao, Andrew Gu, Rohan Varma, Liang Luo, Chien-Chin Huang, Min Xu, Less Wright, Hamid Shojanazeri, Myle Ott, Sam Shleifer, et al. 2023. PyTorch FSDP: Experiences on Scaling Fully Sharded Data Parallel.Proceedings of the VLDB Endowment16, 12 (2023), 3848–3860
2023
-
[65]
Lianmin Zheng, Zhuohan Li, Hao Zhang, Yonghao Zhuang, Zhifeng Chen, Yanping Huang, Yida Wang, Yuanzhong Xu, Danyang Zhuo, Eric P Xing, et al. 2022. Alpa: Automating Inter- and Intra-Operator Parallelism for Distributed Deep Learning. In16th USENIX Symposium on Operating Systems Design and Implementation (OSDI 22). 559–578
2022
-
[66]
Yinmin Zhong, Shengyu Liu, Junda Chen, Jianbo Hu, Yibo Zhu, Xu- anzhe Liu, Xin Jin, and Hao Zhang. 2024. DistServe: Disaggregating Prefill and Decoding for Goodput-optimized Large Language Model Serving. In18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24). 193–210
2024
-
[67]
Yinmin Zhong, Zili Zhang, Xiaoniu Song, Hanpeng Hu, Chao Jin, Bingyang Wu, Nuo Chen, Yukun Chen, Yu Zhou, Changyi Wan, Hongyu Zhou, Yimin Jiang, Yibo Zhu, and Daxin Jiang. 2025. StreamRL: Scalable, Heterogeneous, and Elastic RL for LLMs with Disaggregated Stream Generation. arXiv:2504.15930 [cs.LG]https://arxiv.org/abs/ 2504.15930
arXiv 2025
-
[68]
Yinmin Zhong, Zili Zhang, Bingyang Wu, Shengyu Liu, Yukun Chen, Changyi Wan, Hanpeng Hu, Lei Xia, Ranchen Ming, Yibo Zhu, et al
-
[69]
In22nd USENIX Symposium on Networked Systems Design and Implementation (NSDI 25)
Optimizing RLHF Training for Large Language Models with Stage Fusion. In22nd USENIX Symposium on Networked Systems Design and Implementation (NSDI 25). 489–503
-
[70]
Zilin Zhu, Chengxing Xie, Xin Lv, and slime Contributors. 2025. slime: An LLM post-training framework for RL Scaling.https://github.com/ THUDM/slime. GitHub repository. Corresponding author: Xin Lv. A Rationale of Rollout Cluster Parallelism Design In Libra, the rollout cluster is designed with heterogeneous Tensor Parallelism (TP) as the primary parallel...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.