IDEAFix: Evaluation Framework for Creative Defixation Prompting in LLMs
Pith reviewed 2026-06-28 18:40 UTC · model grok-4.3
The pith
Task formulation and defixation prompts affect LLM originality while persistent homogenization limits diversity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
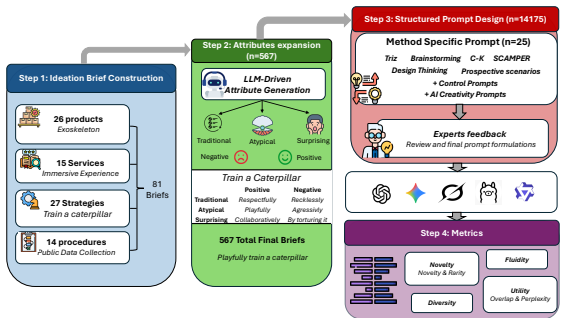
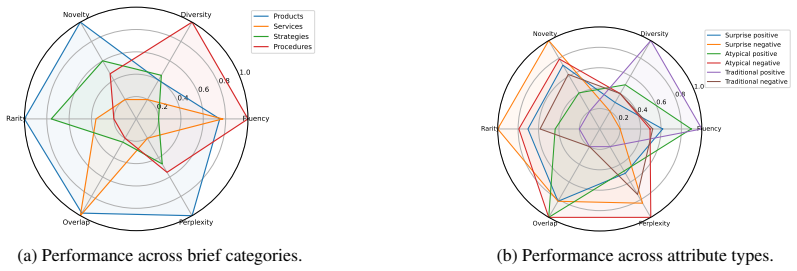
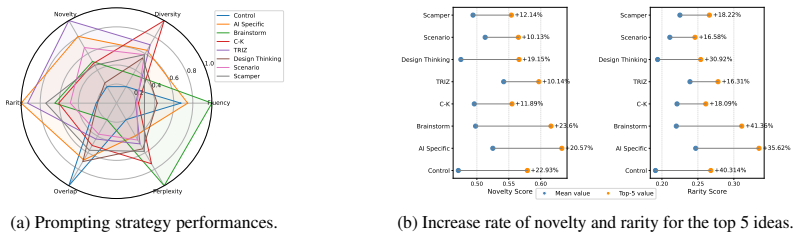
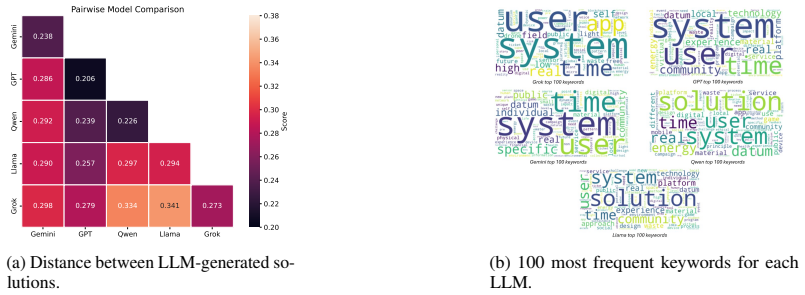
IDEAFix prompts models to generate multiple original solutions to controlled variations of short design scenarios, task attributes, and defixation prompting strategies. This design enables systematic analysis of how structured guidance influences LLMs' idea generation. Results show that both task formulation and attribute selection significantly affect models' performance, and that simple prompting strategies can boost the originality of solutions. However, persistent output homogenization across models confirms inherent limits in their ability to generate diverse solutions.
What carries the argument
The IDEAFix evaluation framework, which applies controlled variations of short design scenarios, task attributes, and defixation prompting strategies to measure effects on divergent thinking and idea originality.
If this is right
- Task formulation leads to measurable differences in how original the generated ideas are.
- Choice of attributes in the scenario influences the performance of the models on originality measures.
- Simple defixation prompting strategies raise the originality of solutions produced.
- Output homogenization stays consistent across models despite changes in setup or prompts.
- Inherent limits restrict LLMs from achieving high diversity in creative solutions.
Where Pith is reading between the lines
- The framework could be extended to longer or multi-step design tasks to test whether homogenization decreases when more context is available.
- Combining the prompting strategies tested here with model fine-tuning might address the diversity constraint in future systems.
- Applying IDEAFix to domains such as story or product concept generation would show if the observed limits are specific to design scenarios.
Load-bearing premise
Short design scenarios with controlled variations of task attributes and defixation prompting strategies can isolate the effects of structured guidance on idea generation without confounding factors from broader creative processes.
What would settle it
An experiment in which altering task formulations or defixation prompts produces no measurable change in originality scores, or in which models generate clearly distinct solution sets without homogenization, would contradict the reported effects and limits.
Figures

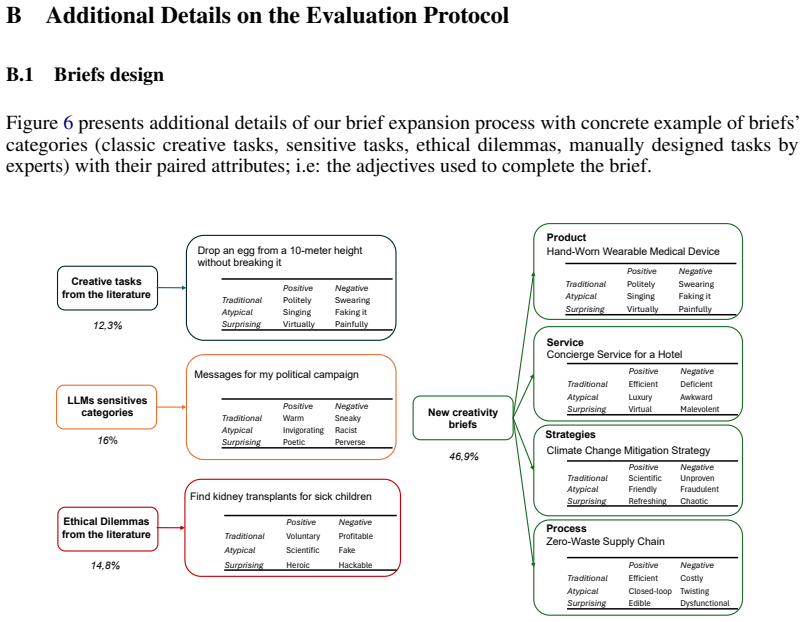

read the original abstract
Large language models (LLMs) are increasingly used for tasks involving creative problem solving and idea generation. However, there is a lack of consensus concerning their creative capabilities: some studies report superior performances compared to humans, while others highlight structural limitations such as fixation and the homogenization of outputs. Existing evaluation approaches either rely on narrow, decontextualized tasks that do not capture goal-oriented generation or on broader settings that confound multiple aspects of the creative process, making it difficult to isolate the effects of task formulation, prompting, and evaluation design. Significantly, the role of structured prompting strategies in shaping idea generation remains underexplored. Therefore, we introduce IDEAFix, an evaluation framework for analyzing divergent thinking in open-ended idea generation tasks. We prompt models to generate multiple original solutions to controlled variations of short design scenarios, task attributes, and defixation prompting strategies. This design enables systematic analysis of how structured guidance influences LLMs' idea generation. Our results show that both task formulation and attribute selection significantly affect models' performance, and that simple prompting strategies can boost the originality of solutions. However, we also observe persistent output homogenization across models, confirming inherent limits in their ability to generate diverse solutions. Overall, IDEAFix provides a controlled, extensible framework for studying the mechanisms underlying LLMs' creativity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces IDEAFix, an evaluation framework for divergent thinking in LLMs on open-ended idea generation. It prompts models to produce multiple original solutions to controlled short design scenarios while varying task attributes and defixation prompting strategies, enabling analysis of how structured guidance affects idea generation. Results indicate that task formulation and attribute selection significantly influence performance, simple prompting can increase originality, yet persistent output homogenization across models is observed and interpreted as confirming inherent limits on diverse solution generation.
Significance. If the framework's controlled variations successfully isolate prompting effects without confounds, IDEAFix could provide a reproducible method for studying LLM creativity mechanisms. The observation of homogenization under specific conditions is a useful empirical finding, but the interpretation as evidence of model-intrinsic limits would require additional validation across varied task lengths and framings to strengthen the contribution.
major comments (2)
- [Abstract] Abstract: the assertion that persistent homogenization 'confirming inherent limits in their ability to generate diverse solutions' does not follow from the reported design of short design scenarios with controlled attribute variations; the results could be artifacts of scenario length or prompting format, and the manuscript provides no evidence that homogenization persists (or decreases) under alternative framings or longer contexts while holding models fixed.
- [Abstract] Results (inferred from abstract description of effects on originality and homogenization): the abstract supplies no metrics, sample sizes, statistical tests, or explicit definitions of 'originality' and 'homogenization' measures, so the load-bearing claims that task formulation/attribute selection 'significantly affect' performance and that prompting 'boosts' originality cannot be evaluated for effect size or robustness.
minor comments (1)
- [Abstract] The abstract states the framework is 'extensible' but does not specify how new scenarios or attributes would be added without introducing new confounds.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract. We address each point below and will revise the manuscript accordingly where the feedback identifies opportunities to better align claims with the reported evidence.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion that persistent homogenization 'confirming inherent limits in their ability to generate diverse solutions' does not follow from the reported design of short design scenarios with controlled attribute variations; the results could be artifacts of scenario length or prompting format, and the manuscript provides no evidence that homogenization persists (or decreases) under alternative framings or longer contexts while holding models fixed.
Authors: We agree that the abstract phrasing overstates the generality of the finding. The observed homogenization is tied to the short design scenarios used, and alternative task lengths or framings were not tested. In revision we will reword the abstract to report the homogenization result as observed under the specific controlled conditions of the study, while noting that this suggests but does not confirm model-intrinsic limits without further validation across varied framings. revision: yes
-
Referee: [Abstract] Results (inferred from abstract description of effects on originality and homogenization): the abstract supplies no metrics, sample sizes, statistical tests, or explicit definitions of 'originality' and 'homogenization' measures, so the load-bearing claims that task formulation/attribute selection 'significantly affect' performance and that prompting 'boosts' originality cannot be evaluated for effect size or robustness.
Authors: The abstract is intentionally concise; full operational definitions (originality via semantic divergence and expert ratings; homogenization via inter-solution similarity), sample sizes, and statistical tests appear in the Methods and Results sections. To improve evaluability we will add brief parenthetical definitions of the two measures to the abstract and note that reported effects reached statistical significance, while retaining detailed metrics in the body text. revision: partial
- The manuscript contains no experiments with longer contexts or alternative framings, so we cannot supply direct evidence on whether homogenization persists or decreases under those conditions.
Circularity Check
No circularity: empirical framework with independent observations
full rationale
The paper introduces an evaluation framework (IDEAFix) for testing LLM idea generation under controlled prompting variations and reports empirical results on originality and homogenization. No equations, derivations, fitted parameters, or self-referential computations appear. Claims rest on experimental outputs rather than reducing to definitional inputs or self-citation chains. The homogenization observation is presented as a measured outcome, not a constructed tautology. This matches the default case of a non-circular descriptive study.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
The Wharton School Research Paper Forthcoming , volume=
Using large language models for idea generation in innovation , author=. The Wharton School Research Paper Forthcoming , volume=. 2024 , publisher=
2024
-
[2]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
-
[3]
2025 , month =
xAI , title =. 2025 , month =
2025
-
[4]
Augmenting Human Creativity in Brainstorming Sessions with Artificial Intelligence , author=
-
[5]
arXiv preprint arXiv:2504.14191 , year=
Ai idea bench 2025: Ai research idea generation benchmark , author=. arXiv preprint arXiv:2504.14191 , year=
-
[6]
Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V
Ideabench: Benchmarking large language models for research idea generation , author=. Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 2 , pages=
-
[7]
Nature , year=
Do AI models produce more original ideas than researchers? , author=. Nature , year=
-
[8]
Scientific reports , volume=
The current state of artificial intelligence generative language models is more creative than humans on divergent thinking tasks , author=. Scientific reports , volume=. 2024 , publisher=
2024
-
[9]
Journal of Product Innovation Management , volume=
Artificial intelligence and corporate ideation systems , author=. Journal of Product Innovation Management , volume=. 2026 , publisher=
2026
-
[10]
AI & society , volume=
On the creativity of large language models , author=. AI & society , volume=. 2025 , publisher=
2025
-
[11]
Proceedings of the 15th International Conference on Computational Creativity , pages =
Is temperature the creativity parameter of large language models? , author=. arXiv preprint arXiv:2405.00492 , year=
-
[12]
arXiv preprint arXiv:2510.22954 , year=
Artificial hivemind: The open-ended homogeneity of language models (and beyond) , author=. arXiv preprint arXiv:2510.22954 , year=
-
[13]
Preprint , year=
Is prompt engineering the creativity knob for large language models , author=. Preprint , year=
-
[14]
Base models beat aligned models at randomness and creativity.arXiv preprint arXiv:2505.00047, 2025
Base models beat aligned models at randomness and creativity , author=. arXiv preprint arXiv:2505.00047 , year=
-
[15]
Science advances , volume=
Generative AI enhances individual creativity but reduces the collective diversity of novel content , author=. Science advances , volume=. 2024 , publisher=
2024
-
[16]
Nature Reviews Psychology , volume=
Using natural language processing to analyse text data in behavioural science , author=. Nature Reviews Psychology , volume=. 2025 , publisher=
2025
-
[17]
arXiv preprint arXiv:2505.17241 , year=
Generative AI and creativity: A systematic literature review and meta-analysis , author=. arXiv preprint arXiv:2505.17241 , year=
-
[18]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
CreBench: Human-Aligned Creativity Evaluation from Idea to Process to Product , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[19]
Brainstorming with a generative language model: the role of creative ability and tool-support for brainstorming performance , author=
-
[20]
Proceedings of the 16th conference on creativity & cognition , pages=
Homogenization effects of large language models on human creative ideation , author=. Proceedings of the 16th conference on creativity & cognition , pages=
-
[21]
Journal of Creativity , pages=
Has the creativity of large-language models peaked?: An analysis of inter-and intra-llm variability , author=. Journal of Creativity , pages=. 2025 , publisher=
2025
-
[22]
Humanities and Social Sciences Communications , volume=
Inspiration booster or creative fixation? The dual mechanisms of LLMs in shaping individual creativity in tasks of different complexity , author=. Humanities and Social Sciences Communications , volume=. 2025 , publisher=
2025
-
[23]
Frontiers in Psychology , volume=
The paradox of creativity in generative AI: high performance, human-like bias, and limited differential evaluation , author=. Frontiers in Psychology , volume=. 2025 , publisher=
2025
-
[24]
Proceedings of the 2024 CHI conference on human factors in computing systems , pages=
The effects of generative AI on design fixation and divergent thinking , author=. Proceedings of the 2024 CHI conference on human factors in computing systems , pages=
2024
-
[25]
arXiv preprint arXiv:2410.17218 , year=
Creativity in ai: Progresses and challenges , author=. arXiv preprint arXiv:2410.17218 , year=
-
[26]
2004 , publisher=
The creative mind: Myths and mechanisms , author=. 2004 , publisher=
2004
-
[27]
arXiv preprint arXiv:2603.19066 , year=
Parallelograms Strike Back: LLMs Generate Better Analogies than People , author=. arXiv preprint arXiv:2603.19066 , year=
-
[28]
Divergent creativity in humans and large language models.arXiv preprint arXiv:2405.13012, 2024
Divergent creativity in humans and large language models , author=. arXiv preprint arXiv:2405.13012 , year=
-
[29]
Proceedings of the AAAI conference on artificial intelligence , volume=
Towards scientific discovery with generative ai: Progress, opportunities, and challenges , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[30]
Management Science , year=
The effects of generative AI on high-skilled work: Evidence from three field experiments with software developers , author=. Management Science , year=
-
[31]
Scientific reports , volume=
A large-scale comparison of human-written versus ChatGPT-generated essays , author=. Scientific reports , volume=. 2023 , publisher=
2023
-
[32]
arXiv preprint arXiv:2411.15560 , year=
Do LLMs Agree on the Creativity Evaluation of Alternative Uses? , author=. arXiv preprint arXiv:2411.15560 , year=
-
[33]
arXiv preprint arXiv:2504.15784 , year=
Automated creativity evaluation for large language models: A reference-based approach , author=. arXiv preprint arXiv:2504.15784 , year=
-
[34]
Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024) , pages=
Lateval: An interactive llms evaluation benchmark with incomplete information from lateral thinking puzzles , author=. Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024) , pages=
2024
-
[35]
Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
MacGyver: Are Large Language Models Creative Problem Solvers? , author=. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2024
-
[36]
Advances in neural information processing systems , volume=
Chain-of-thought prompting elicits reasoning in large language models , author=. Advances in neural information processing systems , volume=
-
[37]
ACM computing surveys , volume=
Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing , author=. ACM computing surveys , volume=. 2023 , publisher=
2023
-
[38]
Harvard business review , volume=
Why design thinking works , author=. Harvard business review , volume=
-
[39]
Creativity and innovation management , volume=
What is TRIZ? From conceptual basics to a framework for research , author=. Creativity and innovation management , volume=. 2005 , publisher=
2005
-
[40]
DS 32: Proceedings of DESIGN 2004, the 8th International Design Conference, Dubrovnik, Croatia , pages=
CK theory in practice: lessons from industrial applications , author=. DS 32: Proceedings of DESIGN 2004, the 8th International Design Conference, Dubrovnik, Croatia , pages=
2004
-
[41]
Advances in neural information processing systems , volume=
Language models are few-shot learners , author=. Advances in neural information processing systems , volume=
-
[42]
2023 , publisher=
Pushing gpt’s creativity to its limits: Alternative uses and torrance tests , author=. 2023 , publisher=
2023
-
[43]
Journal of Creativity , volume=
The originality of machines: AI takes the Torrance Test , author=. Journal of Creativity , volume=. 2023 , publisher=
2023
-
[44]
The Journal of creative behavior , volume=
Brainstorming, brainstorming rules and decision making , author=. The Journal of creative behavior , volume=. 2009 , publisher=
2009
-
[45]
Journal for the Education of Gifted young scientists , volume=
The effectiveness of SCAMPER technique on creative thinking skills , author=. Journal for the Education of Gifted young scientists , volume=. 2016 , publisher=
2016
-
[46]
Technological Forecasting and Social Change , volume=
A brief methodological guide to scenario building , author=. Technological Forecasting and Social Change , volume=. 2000 , publisher=
2000
-
[47]
Handbook of Human-Centered Artificial Intelligence , pages=
Design Thinking and AI: Facilitating HCAI Solutions , author=. Handbook of Human-Centered Artificial Intelligence , pages=. 2026 , publisher=
2026
-
[48]
AI EDAM , volume=
Design creativity in AI: Using the SCAMPER method , author=. AI EDAM , volume=. 2025 , publisher=
2025
-
[49]
Advanced Engineering Informatics , volume=
AutoTRIZ: Automating engineering innovation with TRIZ and large language models , author=. Advanced Engineering Informatics , volume=. 2025 , publisher=
2025
-
[50]
Do-not- answer: A dataset for evaluating safeguards in llms,
Do-not-answer: A dataset for evaluating safeguards in llms , author=. arXiv preprint arXiv:2308.13387 , year=
-
[51]
, author=
Exploiting open-endedness to solve problems through the search for novelty. , author=. ALIFE , volume=
-
[52]
Automatic Chain of Thought Prompting in Large Language Models
Automatic chain of thought prompting in large language models , author=. arXiv preprint arXiv:2210.03493 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[53]
Sentence-bert: Sentence embeddings using siamese bert-networks , author=. Proceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP) , pages=
2019
-
[54]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Confabulation: The surprising value of large language model hallucinations , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[55]
The Journal of Creative Behavior , volume=
The impact of type of examples on originality: Explaining fixation and stimulation effects , author=. The Journal of Creative Behavior , volume=. 2014 , publisher=
2014
-
[56]
Journal of Product Innovation Management , volume=
The creative process of problem framing for innovation: An integrative review and research agenda , author=. Journal of Product Innovation Management , volume=. 2025 , publisher=
2025
-
[57]
, author=
Assessing creativity with divergent thinking tasks: exploring the reliability and validity of new subjective scoring methods. , author=. Psychology of Aesthetics, Creativity, and the Arts , volume=. 2008 , publisher=
2008
-
[58]
, author=
The social psychology of creativity: A componential conceptualization. , author=. Journal of personality and social psychology , volume=. 1983 , publisher=
1983
-
[59]
Creativity Research Journal , volume=
Malevolent creativity: A functional model of creativity in terrorism and crime , author=. Creativity Research Journal , volume=. 2008 , publisher=
2008
-
[60]
The Routledge companion to creativity , pages=
Computers and creativity: models and applications , author=. The Routledge companion to creativity , pages=. 2008 , publisher=
2008
-
[61]
International Journal of Design Creativity and Innovation , volume=
Data-intensive evaluation of design creativity using novelty, value, and surprise , author=. International Journal of Design Creativity and Innovation , volume=. 2015 , publisher=
2015
-
[62]
Design Science , volume=
Uses of the novelty metrics proposed by Shah et al.: what emerges from the literature? , author=. Design Science , volume=. 2023 , publisher=
2023
-
[63]
The Journal of Creative Behavior , volume=
Creative problem solving in small groups: The effects of creativity training on idea generation, solution creativity, and leadership effectiveness , author=. The Journal of Creative Behavior , volume=. 2020 , publisher=
2020
-
[64]
Journal of Cross-Cultural Psychology , volume=
Beyond individual creativity: The superadditive benefits of multicultural experience for collective creativity in culturally diverse teams , author=. Journal of Cross-Cultural Psychology , volume=. 2012 , publisher=
2012
-
[65]
Creativity Research Journal , volume=
Detecting fixation bias in creative idea generation: Evidence from design novices and experts , author=. Creativity Research Journal , volume=. 2026 , publisher=
2026
-
[66]
Thinking & Reasoning , volume=
Incubation and creativity: Do something different , author=. Thinking & Reasoning , volume=. 2013 , publisher=
2013
-
[67]
The Journal of Creative Behavior , volume=
The personality composition of teams and creativity: The moderating role of team creative confidence , author=. The Journal of Creative Behavior , volume=. 2008 , publisher=
2008
-
[68]
Information systems research , volume=
Modifying paradigms—Individual differences, creativity techniques, and exposure to ideas in group idea generation , author=. Information systems research , volume=. 2001 , publisher=
2001
-
[69]
Creativity Research Journal , volume=
Creativity and ethics: The relationship of creative and ethical problem-solving , author=. Creativity Research Journal , volume=. 2010 , publisher=
2010
-
[70]
Cognitive psychology , volume=
Structured imagination: The role of category structure in exemplar generation , author=. Cognitive psychology , volume=. 1994 , publisher=
1994
-
[71]
Journal of Research in Personality , volume=
An examination of the relationship between conscientiousness and group performance on a creative task , author=. Journal of Research in Personality , volume=. 2010 , publisher=
2010
-
[72]
Proceedings of Fifth IAA International Conference on Low-Cost Planetary Missions, 24-26 Septembre 2003, ESA SP-542, Noordwijk, the Netherlands , pages=
Mars Hopper vs Mars Rover , author=. Proceedings of Fifth IAA International Conference on Low-Cost Planetary Missions, 24-26 Septembre 2003, ESA SP-542, Noordwijk, the Netherlands , pages=
2003
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.