Chunking Methods on Retrieval-Augmented Generation - Effectiveness Evaluation Against Computational Cost and Limitations
Pith reviewed 2026-06-28 18:37 UTC · model grok-4.3
The pith
Chunking in RAG systems introduces measurable effectiveness, cost, and limitation trade-offs that vary by method and data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
To the best of our knowledge, this study is the first to systematically evaluate the effectiveness of a wide range of chunking methods and emphasize the underlying challenges of chunking strategies in RAG systems. While chunking is commonly treated as a simple preprocessing step, we show that it introduces a range of impactful and often overlooked issues.
What carries the argument
Comparative evaluation of fixed-size, semantic, and other chunking methods measured jointly on retrieval-generation quality and computational cost.
If this is right
- Chunking methods exhibit distinct performance profiles rather than one method dominating all settings.
- Many specialized chunking proposals show limited gains when tested outside their original narrow use cases.
- Computational costs differ substantially across methods, affecting practical scalability.
- Treating chunking as neutral preprocessing underestimates its effect on overall RAG reliability.
Where Pith is reading between the lines
- Teams building RAG applications would benefit from running short benchmarks of several chunking options on their own data.
- Future systems could incorporate lightweight selection logic that picks a chunking strategy based on detected document characteristics.
- The observed limitations point toward possible value in hybrid chunking that switches rules within a single document collection.
Load-bearing premise
The chosen set of chunking methods, datasets, and evaluation metrics adequately represents behavior across the broader range of real-world RAG applications and data types.
What would settle it
A follow-up experiment on a new collection of documents and queries that produces consistent reversals in the relative ranking of the same chunking methods on the original quality and cost metrics.
Figures
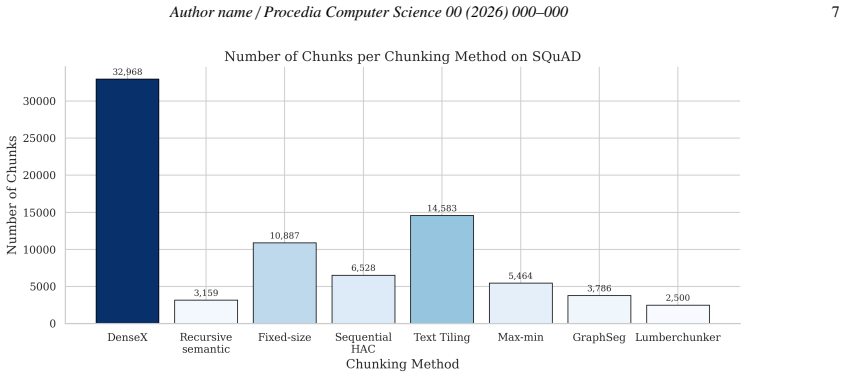
read the original abstract
Retrieval-Augmented Generation (RAG) has demonstrated significant capabilities in enhancing the performance of Large Language Models (LLMs). One of the key tasks in RAG systems is the chunking process. Traditionally, fixed-size chunking and semantic chunking have been the standard approaches. However, interest in chunking strategies has been increasing, leading to a growing number of proposed methods that often claim improved performance over these conventional techniques. Many of these approaches are tailored to specific use cases and data types, with limited evidence of their effectiveness across diverse scenarios. As a result, it remains challenging to directly compare different techniques and assess their relative strengths. To the best of our knowledge, this study is the first to systematically evaluate the effectiveness of a wide range of chunking methods and emphasize the underlying challenges of chunking strategies in RAG systems. While chunking is commonly treated as a simple preprocessing step, we show that it introduces a range of impactful and often overlooked issues.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to be the first systematic evaluation of a wide range of chunking methods (including fixed-size, semantic, and others) in Retrieval-Augmented Generation (RAG) systems. It compares their effectiveness against computational costs, highlights limitations, and argues that chunking is not a simple preprocessing step but introduces impactful overlooked issues across diverse scenarios.
Significance. If the empirical results hold and the evaluation is shown to be representative, the work could inform RAG practitioners on chunking trade-offs. The paper's value would lie in its benchmarking scope, but this is contingent on demonstrating that the chosen methods, datasets, and metrics support general conclusions about challenges rather than being convenience samples.
major comments (1)
- [Abstract] Abstract: The central claim that this is 'the first to systematically evaluate' a wide range and that chunking 'introduces a range of impactful and often overlooked issues' is load-bearing on the representativeness of the evaluated chunking methods, datasets, and metrics. Without explicit justification, coverage analysis, or discussion of why the finite set (fixed-size, semantic, etc.) and standard benchmarks generalize to diverse real-world scenarios and data types, the identified limitations cannot support broad conclusions about challenges in RAG chunking.
Simulated Author's Rebuttal
We thank the referee for the feedback on the abstract claims. We agree that stronger justification for the evaluation's scope is needed to support the conclusions and will revise the manuscript to address this.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that this is 'the first to systematically evaluate' a wide range and that chunking 'introduces a range of impactful and often overlooked issues' is load-bearing on the representativeness of the evaluated chunking methods, datasets, and metrics. Without explicit justification, coverage analysis, or discussion of why the finite set (fixed-size, semantic, etc.) and standard benchmarks generalize to diverse real-world scenarios and data types, the identified limitations cannot support broad conclusions about challenges in RAG chunking.
Authors: We agree this point requires addressing. In the revision we will add a new subsection (likely in Section 3 or 4) providing explicit justification for the selected chunking methods, noting that they encompass the dominant categories in the literature (fixed-size as baseline, semantic, and additional variants proposed in recent work). We will include a coverage analysis mapping the methods to key dimensions such as size-based vs. content-aware. For datasets and metrics we will explain the choice of standard RAG benchmarks to enable direct comparison with prior work, while adding an expanded limitations paragraph that explicitly discusses reduced generalizability to non-benchmark data types (e.g., highly specialized domains or multimodal content) and states that observed issues are demonstrated within the evaluated scope rather than claimed as universal. These changes will allow the abstract claims to be retained in tempered form. revision: yes
Circularity Check
No circularity: empirical benchmarking study with no derivations
full rationale
The paper is a pure empirical benchmarking study that evaluates a range of chunking methods on RAG performance using standard datasets and metrics. It contains no equations, derivations, fitted parameters, predictions, or uniqueness theorems. The central claim of providing the first systematic evaluation rests on the described experimental setup rather than any self-referential reduction or self-citation chain. All load-bearing elements are external measurements and comparisons, making the work self-contained against external benchmarks with no circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Bonomo, T., Gioffr´e, L., Navigli, R., 2025. LiteraryQA: Towards effective evaluation of long-document narrative QA, in: Christodoulopoulos, C., Chakraborty, T., Rose, C., Peng, V . (Eds.), Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, Association for Computational Linguistics, Suzhou, China. pp. 34086–34107. URL:...
-
[2]
Langchain.https://github.com/langchain-ai/langchain
Chase, H., 2022. Langchain.https://github.com/langchain-ai/langchain. Accessed: 2025-05-20
2022
-
[3]
Chen, T., Wang, H., Chen, S., Yu, W., Ma, K., Zhao, X., Zhang, H., Yu, D., 2024. Dense X retrieval: What retrieval granularity should we use?, in: Al-Onaizan, Y ., Bansal, M., Chen, Y .N. (Eds.), Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, Association for Computational Linguistics, Miami, Florida, USA. pp. 15159...
-
[4]
PIRB: A comprehensive benchmark of Polish dense and hybrid text retrieval methods, in: Calzolari, N., Kan, M.Y ., Hoste, V ., Lenci, A., Sakti, S., Xue, N
Dadas, S., Perełkiewicz, M., Po ´swiata, R., 2024. PIRB: A comprehensive benchmark of Polish dense and hybrid text retrieval methods, in: Calzolari, N., Kan, M.Y ., Hoste, V ., Lenci, A., Sakti, S., Xue, N. (Eds.), Proceedings of the 2024 Joint International Conference on Compu- tational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), E...
2024
-
[5]
A dataset of information-seeking questions and answers anchored in research papers
Dasigi, P., Lo, K., Beltagy, I., Cohan, A., Smith, N.A., Gardner, M., 2021. A dataset of information-seeking questions and answers anchored in research papers. URL:https://arxiv.org/abs/2105.03011,arXiv:2105.03011
-
[6]
Duarte, A.V ., Marques, J.D., Grac ¸a, M., Freire, M., Li, L., Oliveira, A.L., 2024. LumberChunker: Long-form narrative document segmentation, in: Al-Onaizan, Y ., Bansal, M., Chen, Y .N. (Eds.), Findings of the Association for Computational Linguistics: EMNLP 2024, Association for Computational Linguistics, Miami, Florida, USA. pp. 6473–6486. URL:https:/...
-
[7]
Gomez-Cabello, C.A., Prabha, S., Haider, S.A., Genovese, A., Collaco, B.G., Wood, N.G., Bagaria, S., Forte, A.J., 2025. Comparative eval- uation of advanced chunking for retrieval-augmented generation in large language models for clinical decision support. Bioengineering 12. URL:https://www.mdpi.com/2306-5354/12/11/1194, doi:10.3390/bioengineering12111194
-
[8]
Late chunking: Contextual chunk embeddings using long-context embedding models
G ¨unther, M., Mohr, I., Williams, D.J., Wang, B., Xiao, H., 2025. Late chunking: Contextual chunk embeddings using long-context embedding models. URL:https://arxiv.org/abs/2409.04701,arXiv:2409.04701
-
[9]
Text tiling: Segmenting text into multi-paragraph subtopic passages
Hearst, M.A., 1997. Text tiling: Segmenting text into multi-paragraph subtopic passages. Computational Linguistics 23. URL:https: //aclanthology.org/J97-1003.pdf
1997
-
[10]
Jain, A., Aggarwal, P., Saladi, A., 2025. AutoChunker: Structured text chunking and its evaluation, in: Rehm, G., Li, Y . (Eds.), Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (V olume 6: Industry Track), Association for Computational Linguistics, Vienna, Austria. pp. 983–995. URL:https://aclanthology.org/2025.acl...
-
[11]
Joshi, M., Choi, E., Weld, D., Zettlemoyer, L., 2017. TriviaQA: A large scale distantly supervised challenge dataset for reading comprehension, in: Barzilay, R., Kan, M.Y . (Eds.), Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), Association for Computational Linguistics, Vancouver, Canada. ...
-
[12]
5 levels of text splitting: Semantic chunking.https://github.com/FullStackRetrieval-com/ RetrievalTutorials
Kamradt, G., 2024. 5 levels of text splitting: Semantic chunking.https://github.com/FullStackRetrieval-com/ RetrievalTutorials. Tutorial and Reference Implementation
2024
-
[13]
Dense passage retrieval for open-domain question answering, in: Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pp
Karpukhin, V ., Oguz, B., Min, S., Lewis, P., Wu, L., Edunov, S., Chen, D., Yih, W.t., 2020. Dense passage retrieval for open-domain question answering, in: Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pp. 6769–6781
2020
-
[14]
Max-min semantic chunking
Kiss, A., et al., 2025. Max-min semantic chunking. Discover Computing 28. URL:https://link.springer.com/journal/44227. article number: 117
2025
-
[15]
and Uszkoreit, Jakob and Le, Quoc and Petrov, Slav
Kwiatkowski, T., Palomaki, J., Redfield, O., Collins, M., Parikh, A., Alberti, C., Epstein, D., Polosukhin, I., Devlin, J., Lee, K., Toutanova, K., Jones, L., Kelcey, M., Chang, M.W., Dai, A.M., Uszkoreit, J., Le, Q., Petrov, S., 2019. Natural questions: A benchmark for question answering research. Transactions of the Association for Computational Linguis...
-
[16]
Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V ., Goyal, N., K ¨uttler, H., Lewis, M., Yih, W.t., Rockt ¨aschel, T., Riedel, S., Kiela, D., 2020. Retrieval-augmented generation for knowledge-intensive nlp tasks, in: Proceedings of the 34th International Conference on Neural Information Processing Systems, Curran Associates Inc., Red Hook, NY , USA
2020
-
[17]
Hichunk: Evaluating and enhancing retrieval-augmented generation with hierarchical chunking
Lu, W., Chen, K., Qiao, R., Sun, X., 2026. Hichunk: Evaluating and enhancing retrieval-augmented generation with hierarchical chunking. URL:https://openreview.net/forum?id=yCyv2Ij3bS
2026
-
[18]
Pavlu, V ., Rajput, S., Golbus, P.B., Aslam, J.A., 2012. Ir system evaluation using nugget-based test collections, in: Proceedings of the Fifth ACM International Conference on Web Search and Data Mining, Association for Computing Machinery, New York, NY , USA. p. 393–402. URL:https://doi.org/10.1145/2124295.2124343, doi:10.1145/2124295.2124343
-
[19]
Pradeep, R., Thakur, N., Upadhyay, S., Campos, D., Craswell, N., Soboroff, I., Dang, H.T., Lin, J., 2025. The great nugget recall: Automating fact extraction and rag evaluation with large language models, in: Proceedings of the 48th International ACM SIGIR Conference on Research and Development in Information Retrieval, Association for Computing Machinery...
-
[20]
Is semantic chunking worth the computational cost?, in: Chiruzzo, L., Ritter, A., Wang, L
Qu, R., Tu, R., Bao, F.S., 2025. Is semantic chunking worth the computational cost?, in: Chiruzzo, L., Ritter, A., Wang, L. (Eds.), Findings of the Association for Computational Linguistics: NAACL 2025, Association for Computational Linguistics, Albuquerque, New Mexico. pp. 2155–2177. URL:https://aclanthology.org/2025.findings-naacl.114/, doi:10.18653/v1/...
-
[21]
SQuAD: 100,000+ Questions for Machine Comprehension of Text
Rajpurkar, P., Zhang, J., Lopyrev, K., Liang, P., 2016. Squad: 100,000+questions for machine comprehension of text. URL:https://arxiv. org/abs/1606.05250,arXiv:1606.05250
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[22]
Sentence-bert: Sentence embeddings using siamese bert-networks, in: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing, pp
Reimers, N., Gurevych, I., 2019. Sentence-bert: Sentence embeddings using siamese bert-networks, in: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing, pp. 3982–3992
2019
-
[23]
Large language models can be easily distracted by irrelevant context, in: Proceedings of the 40th International Conference on Machine Learning, JMLR.org
Shi, F., Chen, X., Misra, K., Scales, N., Dohan, D., Chi, E., Sch ¨arli, N., Zhou, D., 2023. Large language models can be easily distracted by irrelevant context, in: Proceedings of the 40th International Conference on Machine Learning, JMLR.org
2023
-
[24]
Tuora, R., Zwierzchowska, A., Zawadzka-Paluektau, N., Klamra, C., Kobyli ´nski, L., 2023. Poquad - the polish question answering dataset - description and analysis, in: Proceedings of the 12th Knowledge Capture Conference 2023, Association for Computing Machinery, New York, NY , USA. p. 105–113. URL:https://doi.org/10.1145/3587259.3627548, doi:10.1145/358...
-
[25]
Verma, P., 2025. S2 chunking: A hybrid framework for document segmentation through integrated spatial and semantic analysis. URL: https://arxiv.org/abs/2501.05485,arXiv:2501.05485
-
[26]
Novelqa: Benchmarking question answering on documents exceeding 200k tokens
Wang, C., Ning, R., Pan, B., Wu, T., Guo, Q., Deng, C., Bao, G., Hu, X., Zhang, Z., Wang, Q., Zhang, Y ., 2025a. Novelqa: Benchmarking question answering on documents exceeding 200k tokens. URL:https://arxiv.org/abs/2403.12766,arXiv:2403.12766
-
[27]
Wang, H., Zhang, D., Li, J., Feng, Z., Zhang, F., 2025b. Entropy-optimized dynamic text segmentation and rag-enhanced llms for construction engineering knowledge base. Applied Sciences 15. URL:https://www.mdpi.com/2076-3417/15/6/3134, doi:10.3390/app15063134
-
[28]
Wang, X., Wang, Z., Gao, X., Zhang, F., Wu, Y ., Xu, Z., Shi, T., Wang, Z., Li, S., Qian, Q., Yin, R., Lv, C., Zheng, X., Huang, X., 2024. Searching for best practices in retrieval-augmented generation, in: Al-Onaizan, Y ., Bansal, M., Chen, Y .N. (Eds.), Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, Association f...
-
[29]
Learning to filter context for retrieval-augmented generation
Wang, Z., Araki, J., Jiang, Z., Parvez, M.R., Neubig, G., 2023. Learning to filter context for retrieval-augmented generation. URL:https: //arxiv.org/abs/2311.08377,arXiv:2311.08377
-
[30]
Wang, Z., Gao, C., Xiao, C., Huang, Y ., Si, S., Luo, K., Bai, Y ., Li, W., Duan, T., Lv, C., Lu, G., Chen, G., Qi, F., Sun, M., 2025c. Document segmentation matters for retrieval-augmented generation, in: Findings of the Association for Computational Linguistics: ACL 2025, Associ- ation for Computational Linguistics, Vienna, Austria. pp. 8063–8075. URL:h...
-
[31]
Zhang, Y ., Zhao, X., Wang, Z.Z., Yang, C., Wei, J., Wu, T., 2025. cAST: Enhancing code retrieval-augmented generation with structural chunking via abstract syntax tree, in: Christodoulopoulos, C., Chakraborty, T., Rose, C., Peng, V . (Eds.), Findings of the Association for Computational Linguistics: EMNLP 2025, Association for Computational Linguistics, ...
-
[32]
Zhao, J., Ji, Z., Fan, Z., Wang, H., Niu, S., Tang, B., Xiong, F., Li, Z., 2025a. MoC: Mixtures of text chunking learners for retrieval-augmented generation system, in: Che, W., Nabende, J., Shutova, E., Pilehvar, M.T. (Eds.), Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), Association for ...
-
[33]
Meta-chunking: Learning text segmentation and semantic completion via logical perception
Zhao, J., Ji, Z., Feng, Y ., Qi, P., Niu, S., Tang, B., Xiong, F., Li, Z., 2025b. Meta-chunking: Learning text segmentation and semantic completion via logical perception. URL:https://arxiv.org/abs/2410.12788,arXiv:2410.12788
-
[34]
Zheng, L., Chiang, W.L., Sheng, Y ., Zhuang, S., Wu, Z., Zhuang, Y ., Lin, Z., Li, Z., Li, D., Xing, E.P., Zhang, H., Gonzalez, J.E., Stoica, I.,
-
[35]
Judging llm-as-a-judge with mt-bench and chatbot arena, in: Proceedings of the 37th International Conference on Neural Information Processing Systems, Curran Associates Inc., Red Hook, NY , USA
-
[36]
Mix-of-granularity: Optimize the chunking granularity for retrieval-augmented gen- eration, in: Rambow, O., Wanner, L., Apidianaki, M., Al-Khalifa, H., Eugenio, B.D., Schockaert, S
Zhong, Z., Liu, H., Cui, X., Zhang, X., Qin, Z., 2025. Mix-of-granularity: Optimize the chunking granularity for retrieval-augmented gen- eration, in: Rambow, O., Wanner, L., Apidianaki, M., Al-Khalifa, H., Eugenio, B.D., Schockaert, S. (Eds.), Proceedings of the 31st Inter- national Conference on Computational Linguistics, Association for Computational L...
2025
-
[37]
Zhou, Y ., Wang, S., Koopman, B., Zuccon, G., 2026. Beyond chunk-then-embed: A comprehensive taxonomy and evaluation of document chunking strategies for information retrieval. URL:https://arxiv.org/abs/2602.16974,arXiv:2602.16974
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.