Optimal-Point Variance Reduction For Bayesian Optimization With Regret Guarantee
Pith reviewed 2026-06-28 17:47 UTC · model grok-4.3
The pith
Regularized optimal-point variance reduction achieves a vanishing Bayesian expected simple regret upper bound.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
OVR is a one-step lookahead acquisition function that chooses the next evaluation point to minimize the posterior variance at the current estimate of the optimum; it is realized through posterior sampling and Monte Carlo integration. The paper proves that the Monte Carlo error admits a uniform bound over the domain. When a slight regularization term is added to promote exploration, the resulting procedure yields a vanishing upper bound on the Bayesian expected simple regret.
What carries the argument
optimal-point variance reduction (OVR), the acquisition function that reduces posterior variance at the estimated optimum via Monte Carlo estimates from posterior samples.
If this is right
- A uniform error bound holds for the Monte Carlo estimates of OVR over the full input domain.
- Regularized OVR produces a Bayesian expected simple regret upper bound that vanishes with iteration count.
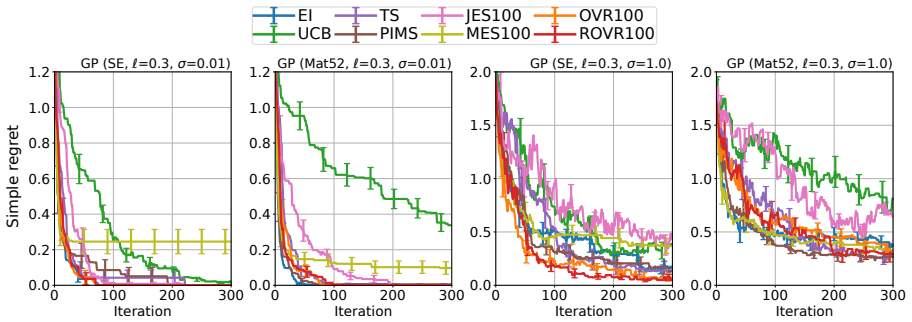
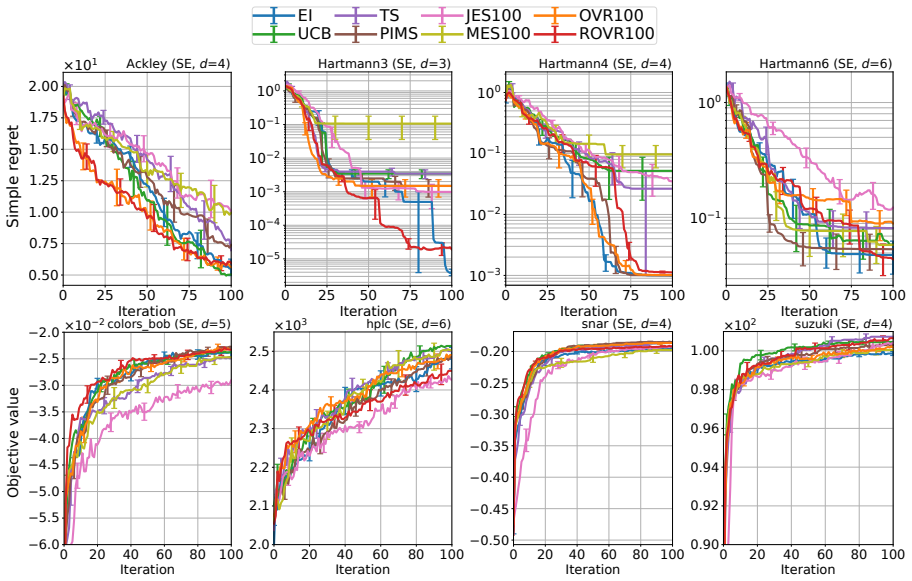
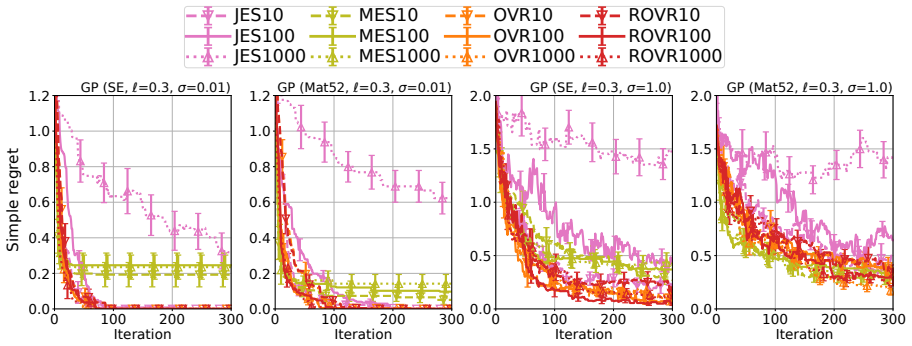
- Numerical experiments on standard test functions show competitive empirical performance.
Where Pith is reading between the lines
- The sampling-based construction may extend to settings where exact integrals over the posterior become infeasible, such as high-dimensional or non-stationary kernels.
- The same variance-reduction logic could be adapted to multi-step lookahead or to other sequential design criteria that currently rely on expensive acquisition functions.
- If the uniform Monte Carlo control can be maintained under noisy observations, the regret analysis would carry over without new error terms.
Load-bearing premise
The Monte Carlo estimation error remains controlled uniformly over the input domain under the posterior sampling used in OVR.
What would settle it
A sequence of runs in which the Monte Carlo error grows with the number of iterations or the simple regret fails to approach zero would disprove the vanishing-regret claim.
Figures
read the original abstract
This paper studies a one-step lookahead Bayesian optimization (BO) method and its theoretical guarantee. Although the empirical effectiveness of one-step lookahead BO methods, such as entropy search, has been studied extensively, they often rely on computationally intractable approximations, and their regret guarantees remain underdeveloped. Thus, this paper proposes a one-step lookahead BO method called optimal-point variance reduction (OVR), which requires only posterior sampling and Monte Carlo approximations. We obtain a uniform error bound over an input domain for the Monte Carlo estimation in OVR. Furthermore, we show that the regularized OVR, with the slight modification to promote exploration, achieves a vanishing Bayesian expected simple regret upper bound. Finally, we demonstrate the effectiveness of OVR through numerical experiments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Optimal-Point Variance Reduction (OVR), a one-step lookahead Bayesian optimization algorithm that relies only on posterior sampling and Monte Carlo approximations rather than intractable integrals. It derives a uniform error bound on the Monte Carlo estimates over the input domain and shows that a regularized variant of OVR (with an added exploration-promoting term) attains a vanishing upper bound on Bayesian expected simple regret. Numerical experiments are included to illustrate practical performance.
Significance. If the uniform Monte Carlo error bound is shown to be iteration-independent under the regularized acquisition and the regret analysis closes without growing additive terms, the result would supply one of the first regret guarantees for a computationally tractable one-step lookahead BO method, addressing a notable gap relative to entropy search and related approaches.
major comments (2)
- [abstract and regret analysis section] The central regret claim (abstract and §4) requires that the uniform error bound on the Monte Carlo estimates obtained via posterior sampling remains controlled independently of iteration count after regularization. The provided proof sketch must explicitly verify that no hidden dependence on the evolving posterior, discretization, or sample complexity introduces iteration-dependent additive terms that would prevent the simple regret from vanishing; otherwise the bound does not close as stated.
- [uniform error bound derivation] The uniform error bound statement does not list the precise assumptions on the Gaussian process (kernel, domain compactness, posterior sampling procedure) under which the Monte Carlo error is controlled uniformly; without these, it is impossible to confirm that the bound applies to the regularized OVR acquisition used in the regret proof.
minor comments (2)
- [method section] Notation for the regularized acquisition function should be introduced with an explicit equation number rather than inline description.
- [experiments] The numerical experiments section would benefit from reporting the number of posterior samples used per iteration to allow readers to assess the practical cost of maintaining the claimed uniform error.
Simulated Author's Rebuttal
We thank the referee for the thorough review and insightful comments on our work. The points raised concern the explicit verification of iteration-independent bounds in the regret analysis and the precise statement of assumptions for the uniform error bound. We address each below and will revise the manuscript accordingly to strengthen the presentation.
read point-by-point responses
-
Referee: [abstract and regret analysis section] The central regret claim (abstract and §4) requires that the uniform error bound on the Monte Carlo estimates obtained via posterior sampling remains controlled independently of iteration count after regularization. The provided proof sketch must explicitly verify that no hidden dependence on the evolving posterior, discretization, or sample complexity introduces iteration-dependent additive terms that would prevent the simple regret from vanishing; otherwise the bound does not close as stated.
Authors: We agree that the proof sketch in §4 should be expanded for full transparency. In the revision we will add a dedicated lemma showing that the regularization term in OVR keeps the posterior variance bounded away from zero in a manner that prevents the Monte Carlo error from accumulating iteration-dependent terms. Specifically, we bound the discretization error uniformly over the compact domain using the continuity of the kernel and a fixed Monte Carlo sample size chosen independently of iteration count via a uniform concentration inequality that depends only on the Lipschitz constant of the acquisition function under regularization. This ensures the additive error in the regret bound remains a constant that can be driven to zero by increasing the sample size, allowing the simple regret to vanish as stated. revision: yes
-
Referee: [uniform error bound derivation] The uniform error bound statement does not list the precise assumptions on the Gaussian process (kernel, domain compactness, posterior sampling procedure) under which the Monte Carlo error is controlled uniformly; without these, it is impossible to confirm that the bound applies to the regularized OVR acquisition used in the regret proof.
Authors: We acknowledge that the assumptions should be stated explicitly rather than left implicit. The uniform error bound holds under the following conditions, which we will list in a new remark preceding the bound: the input domain is compact, the kernel is continuous (e.g., squared exponential or Matérn with sufficient smoothness), the GP posterior is sampled exactly, and the Monte Carlo approximation uses a number of samples that grows only with the desired uniform accuracy via Hoeffding-type bounds that are uniform over the domain. These assumptions are compatible with the regularized acquisition because regularization adds a term whose Lipschitz constant is controlled by the posterior variance, preserving the uniform convergence. We will also reference the relevant theorem from the GP literature for the posterior sampling step. revision: yes
Circularity Check
No circularity; regret bound derived from independent MC uniform error analysis
full rationale
The paper obtains a uniform Monte Carlo error bound over the domain for its OVR acquisition (using posterior sampling), then derives the vanishing Bayesian simple regret bound for the regularized variant from that error control. No step reduces a claimed prediction to a fitted parameter by construction, nor does any load-bearing premise collapse to a self-citation or ansatz smuggled from prior work by the same authors. The derivation chain is self-contained once the uniform error bound is granted; the reader's score of 2 reflects only a minor non-load-bearing self-citation possibility that does not affect the central result.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
and Haberland, Matt and Reddy, Tyler and Cournapeau, David and Burovski, Evgeni and Peterson, Pearu and Weckesser, Warren and Bright, Jonathan and
Virtanen, Pauli and Gommers, Ralf and Oliphant, Travis E. and Haberland, Matt and Reddy, Tyler and Cournapeau, David and Burovski, Evgeni and Peterson, Pearu and Weckesser, Warren and Bright, Jonathan and. Nature Methods , year =
-
[2]
On Regret Bounds of
Takeno, Shion and Iwazaki, Shogo , booktitle =. On Regret Bounds of. 2026 , note=
2026
-
[3]
Tighter Regret Lower Bound for
Shogo Iwazaki , booktitle =. Tighter Regret Lower Bound for. 2026 , note=
2026
-
[4]
Scalable
Vakili, Sattar and Moss, Henry and Artemev, Artem and Dutordoir, Vincent and Picheny, Victor , booktitle =. Scalable
-
[5]
Proceedings of The 28th International Conference on Artificial Intelligence and Statistics , pages =
Tighter Confidence Bounds for Sequential Kernel Regression , author =. Proceedings of The 28th International Conference on Artificial Intelligence and Statistics , pages =. 2025 , volume =
2025
-
[6]
Gaussian Process Upper Confidence Bound Achieves Nearly-Optimal Regret in Noise-Free
Shogo Iwazaki , booktitle=. Gaussian Process Upper Confidence Bound Achieves Nearly-Optimal Regret in Noise-Free
-
[7]
Improved Regret Bounds for
Shogo Iwazaki , booktitle=. Improved Regret Bounds for
-
[8]
Improved Regret Analysis in
Iwazaki, Shogo and Takeno, Shion , booktitle =. Improved Regret Analysis in. 2025 , volume =
2025
-
[9]
Distributionally Robust Active Learning for
Takeno, Shion and Okura, Yoshito and Inatsu, Yu and Tatsuya, Aoyama and Tanaka, Tomonari and Satoshi, Akahane and Hanada, Hiroyuki and Hashimoto, Noriaki and Murayama, Taro and Lee, Hanju and Kojima, Shinya and Takeuchi, Ichiro , booktitle =. Distributionally Robust Active Learning for. 2025 , volume =
2025
-
[10]
Regret Analysis for Randomized
Shion Takeno and Yu Inatsu and Masayuki Karasuyama , journal=. Regret Analysis for Randomized
-
[11]
Regret Analysis of Posterior Sampling-Based Expected Improvement for
Shion Takeno and Yu Inatsu and Masayuki Karasuyama and Ichiro Takeuchi , journal=. Regret Analysis of Posterior Sampling-Based Expected Improvement for. 2025 , url=
2025
-
[12]
1981 , publisher=
The Geometry of Random Fields , author=. 1981 , publisher=
1981
-
[13]
2007 , series=
Random Fields and Geometry , author=. 2007 , series=
2007
-
[14]
Journal of Machine Learning Research , year =
Charlie Frogner and Sebastian Claici and Edward Chien and Justin Solomon , title =. Journal of Machine Learning Research , year =
-
[15]
Journal of Machine Learning Research , year =
Steven Diamond and Stephen Boyd , title =. Journal of Machine Learning Research , year =
-
[16]
Journal of Control and Decision , year =
Agrawal, Akshay and Verschueren, Robin and Diamond, Steven and Boyd, Stephen , title =. Journal of Control and Decision , year =
-
[17]
Active Learning for Misspecified Models , volume =
Sugiyama, Masashi , booktitle =. Active Learning for Misspecified Models , volume =
-
[18]
Proceedings of the Twenty-Second International Conference on Artificial Intelligence and Statistics , pages =
Distributionally Robust Submodular Maximization , author =. Proceedings of the Twenty-Second International Conference on Artificial Intelligence and Statistics , pages =. 2019 , volume =
2019
-
[19]
Brendan McMahan and Carlos Guestrin and Anupam Gupta , title =
Andreas Krause and H. Brendan McMahan and Carlos Guestrin and Anupam Gupta , title =. Journal of Machine Learning Research , year =
-
[20]
International Conference on Learning Representations , year=
Active Learning for Convolutional Neural Networks: A Core-Set Approach , author=. International Conference on Learning Representations , year=
-
[21]
Proceedings of the Fortieth Annual ACM Symposium on Theory of Computing , pages =
Das, Abhimanyu and Kempe, David , title =. Proceedings of the Fortieth Annual ACM Symposium on Theory of Computing , pages =. 2008 , publisher =
2008
-
[22]
Online learning for linearly parametrized control problems , author=
-
[23]
Nathaël Da Costa and Marvin Pförtner and Lancelot Da Costa and Philipp Hennig , year=. Sample Path Regularity of. 2312.14886 , archivePrefix=
-
[24]
Ramon Van Handel , title =
-
[25]
2006 , publisher=
Optimal design of experiments , author=. 2006 , publisher=
2006
-
[26]
Proceedings of the 34th International Conference on Machine Learning , pages =
Near-Optimal Design of Experiments via Regret Minimization , author =. Proceedings of the 34th International Conference on Machine Learning , pages =. 2017 , volume =
2017
-
[27]
Available at Optimization Online , volume=
Kullback-Leibler divergence constrained distributionally robust optimization , author=. Available at Optimization Online , volume=
-
[28]
Proceedings of the 34th International Conference on Machine Learning , pages =
Guarantees for Greedy Maximization of Non-submodular Functions with Applications , author =. Proceedings of the 34th International Conference on Machine Learning , pages =. 2017 , volume =
2017
-
[29]
1996 , publisher=
Weak Convergence and Empirical Processes: With Applications to Statistics , author=. 1996 , publisher=
1996
-
[30]
Motonobu Kanagawa and Philipp Hennig and Dino Sejdinovic and Bharath K Sriperumbudur , year=
-
[31]
and Zoghi, Masrour , title =
De Freitas, Nando and Smola, Alex J. and Zoghi, Masrour , title =. Proceedings of the 29th International Conference on Machine Learning , pages =. 2012 , publisher =
2012
-
[32]
Proceedings of the 31st Conference On Learning Theory , pages =
Information Directed Sampling and Bandits with Heteroscedastic Noise , author =. Proceedings of the 31st Conference On Learning Theory , pages =. 2018 , volume =
2018
-
[33]
2023 , volume=
Shoham, Neta and Avron, Haim , journal=. 2023 , volume=
2023
-
[34]
Paschalidis , title =
Ruidi Chen and Ioannis Ch. Paschalidis , title =. Journal of Machine Learning Research , year =
-
[35]
2022 , volume =
Li, Zihan and Scarlett, Jonathan , booktitle =. 2022 , volume =
2022
-
[36]
The Annals of Statistics , number =
Subhashis Ghosal and Anindya Roy , title =. The Annals of Statistics , number =
-
[37]
Posterior Sampling-Based
Takeno, Shion and Inatsu, Yu and Karasuyama, Masayuki and Takeuchi, Ichiro , booktitle =. Posterior Sampling-Based. 2024 , volume =
2024
-
[38]
Random Exploration in
Salgia, Sudeep and Vakili, Sattar and Zhao, Qing , booktitle =. Random Exploration in. 2024 , volume =
2024
-
[39]
International Conference on Machine Learning , pages=
Improved convergence rates for sparse approximation methods in kernel-based learning , author=. International Conference on Machine Learning , pages=. 2022 , organization=
2022
-
[40]
Bounding Box-based Multi-objective
Inatsu, Yu and Takeno, Shion and Hanada, Hiroyuki and Iwata, Kazuki and Takeuchi, Ichiro , booktitle =. Bounding Box-based Multi-objective. 2024 , volume =
2024
-
[41]
Proceedings of the 38th International Conference on Machine Learning , pages =
Active Learning for Distributionally Robust Level-Set Estimation , author =. Proceedings of the 38th International Conference on Machine Learning , pages =. 2021 , volume =
2021
-
[42]
Transactions on Machine Learning Research , year=
Active Learning for Level Set Estimation Using Randomized Straddle Algorithms , author=. Transactions on Machine Learning Research , year=
-
[43]
Proceedings of the Twenty-Third international joint conference on Artificial Intelligence , pages=
Active learning for level set estimation , author=. Proceedings of the Twenty-Third international joint conference on Artificial Intelligence , pages=
-
[44]
Journal of Statistical Theory and Practice , volume=
Modern experimental design , author=. Journal of Statistical Theory and Practice , volume=. 2007 , publisher=
2007
-
[45]
Ivanova and Freddie Bickford Smith , title =
Tom Rainforth and Adam Foster and Desi R. Ivanova and Freddie Bickford Smith , title =. Statistical Science , number =
-
[46]
Statistical Science , number =
Kathryn Chaloner and Isabella Verdinelli , title =. Statistical Science , number =
-
[47]
D. V. Lindley , title =. The Annals of Mathematical Statistics , number =
-
[48]
International conference on artificial intelligence and statistics , pages=
Active learning under label shift , author=. International conference on artificial intelligence and statistics , pages=. 2021 , organization=
2021
-
[49]
Bayesian Active Learning for Classification and Preference Learning
Houlsby, Neil and Husz. arXiv preprint arXiv:1112.5745 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[50]
Foundations and Trends
Theory of disagreement-based active learning , author=. Foundations and Trends. 2014 , publisher=
2014
-
[51]
Nonmyopic -
Hoang, Trong Nghia and Low, Bryan Kian Hsiang and Jaillet, Patrick and Kankanhalli, Mohan , booktitle=. Nonmyopic -. 2014 , organization=
2014
-
[52]
Foundations and Trends
Distributionally robust learning , author=. Foundations and Trends. 2020 , publisher=
2020
-
[53]
2021 , eprint=
Test Distribution-Aware Active Learning: A Principled Approach Against Distribution Shift and Outliers , author=. 2021 , eprint=
2021
-
[54]
Unifying Approaches in Active Learning and Active Sampling via
Andreas Kirsch and Yarin Gal , journal=. Unifying Approaches in Active Learning and Active Sampling via. 2022 , note=
2022
-
[55]
Neural computation , volume=
Information-based objective functions for active data selection , author=. Neural computation , volume=. 1992 , publisher=
1992
-
[56]
Journal of artificial intelligence research , volume=
Active learning with statistical models , author=. Journal of artificial intelligence research , volume=
-
[57]
Advances in neural information processing systems , volume=
Neural network exploration using optimal experiment design , author=. Advances in neural information processing systems , volume=
-
[58]
and Graepel, T
Sambu Seo and Wallat, M. and Graepel, T. and Obermayer, K. , booktitle=. 2000 , volume=
2000
-
[59]
Proceedings of the 23rd international conference on Machine learning , pages=
Active learning via transductive experimental design , author=. Proceedings of the 23rd international conference on Machine learning , pages=
-
[60]
Proceedings of the 22nd International Conference on Machine Learning , pages =
Guestrin, Carlos and Krause, Andreas and Singh, Ajit Paul , title =. Proceedings of the 22nd International Conference on Machine Learning , pages =. 2005 , publisher =
2005
-
[61]
Krause, Andreas and Singh, Ajit and Guestrin, Carlos , title =. J. Mach. Learn. Res. , pages =. 2008 , volume =
2008
-
[62]
Active Learning Literature Survey , Type =
Burr Settles , Institution =. Active Learning Literature Survey , Type =
-
[63]
Prediction-Oriented
Bickford Smith, Freddie and Kirsch, Andreas and Farquhar, Sebastian and Gal, Yarin and Foster, Adam and Rainforth, Tom , booktitle =. Prediction-Oriented. 2023 , volume =
2023
-
[64]
Theoretical analysis of
Wang, Ziyu and de Freitas, Nando , journal=. Theoretical analysis of
-
[65]
and Bannock, James H
Walker, Barnaby E. and Bannock, James H. and Nightingale, Adrian M. and deMello, John C. Tuning reaction products by constrained optimisation. React. Chem. Eng. 2017
2017
-
[66]
Machine Learning: Science and Technology , volume=
Olympus: a benchmarking framework for noisy optimization and experiment planning , author=. Machine Learning: Science and Technology , volume=. 2021 , publisher=
2021
-
[67]
Schoellig and Andreas Krause , title =
Felix Berkenkamp and Angela P. Schoellig and Andreas Krause , title =. Journal of Machine Learning Research , year =
-
[68]
Misspecified
Bogunovic, Ilija and Krause, Andreas , journal=. Misspecified
-
[69]
Regret bounds for meta
Wang, Zi and Kim, Beomjoon and Kaelbling, Leslie Pack , booktitle =. Regret bounds for meta
-
[70]
INFORMS journal on Computing , volume=
The knowledge-gradient policy for correlated normal beliefs , author=. INFORMS journal on Computing , volume=. 2009 , publisher=
2009
-
[71]
Biometrika , volume=
On the likelihood that one unknown probability exceeds another in view of the evidence of two samples , author=. Biometrika , volume=. 1933 , publisher=
1933
-
[72]
Randomized
Takeno, Shion and Inatsu, Yu and Karasuyama, Masayuki , booktitle =. Randomized. 2023 , series =
2023
-
[73]
Joint Entropy Search for Multi-Objective
Tu, Ben and Gandy, Axel and Kantas, Nikolas and Shafei, Behrang , booktitle =. Joint Entropy Search for Multi-Objective
-
[74]
Joint Entropy Search For Maximally-Informed
Hvarfner, Carl and Hutter, Frank and Nardi, Luigi , booktitle=. Joint Entropy Search For Maximally-Informed. 2022 , pages =
2022
-
[75]
Benchmarking the performance of
Liang, Q and Gongora, AE and Ren, Z and Tiihonen, A and Liu, Z and Sun, S and Deneault, JR and Bash, D and Mekki-Berrada, F and Khan, SA and others , journal =. Benchmarking the performance of
-
[76]
npj Computational Materials , volume=
Two-step machine learning enables optimized nanoparticle synthesis , author=. npj Computational Materials , volume=. 2021 , publisher=
2021
-
[77]
Multi-Fidelity High-Throughput Optimization of Electrical Conductivity in
Bash, Daniil and Cai, Yongqiang and Chellappan, Vijila and Wong, Swee Liang and Yang, Xu and Kumar, Pawan and Tan, Jin Da and Abutaha, Anas and Cheng, Jayce JW and Lim, Yee-Fun and others , journal=. Multi-Fidelity High-Throughput Optimization of Electrical Conductivity in. 2021 , publisher=
2021
-
[78]
Toward autonomous additive manufacturing:
Deneault, James R and Chang, Jorge and Myung, Jay and Hooper, Daylond and Armstrong, Andrew and Pitt, Mark and Maruyama, Benji , journal=. Toward autonomous additive manufacturing:. 2021 , publisher=
2021
-
[79]
Matter , volume=
A data fusion approach to optimize compositional stability of halide perovskites , author=. Matter , volume=. 2021 , publisher=
2021
-
[80]
Gongora, Aldair E and Xu, Bowen and Perry, Wyatt and Okoye, Chika and Riley, Patrick and Reyes, Kristofer G and Morgan, Elise F and Brown, Keith A , journal=. A. 2020 , publisher=
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.