MedSyn2: Flexible Control of 3D CT Generation via Text and Semantically-Defined Segmentation Prompts
Pith reviewed 2026-06-28 17:41 UTC · model grok-4.3
The pith
A multimodal diffusion model generates controllable high-resolution 3D CT volumes from optional text reports and partial segmentation prompts defined by text.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
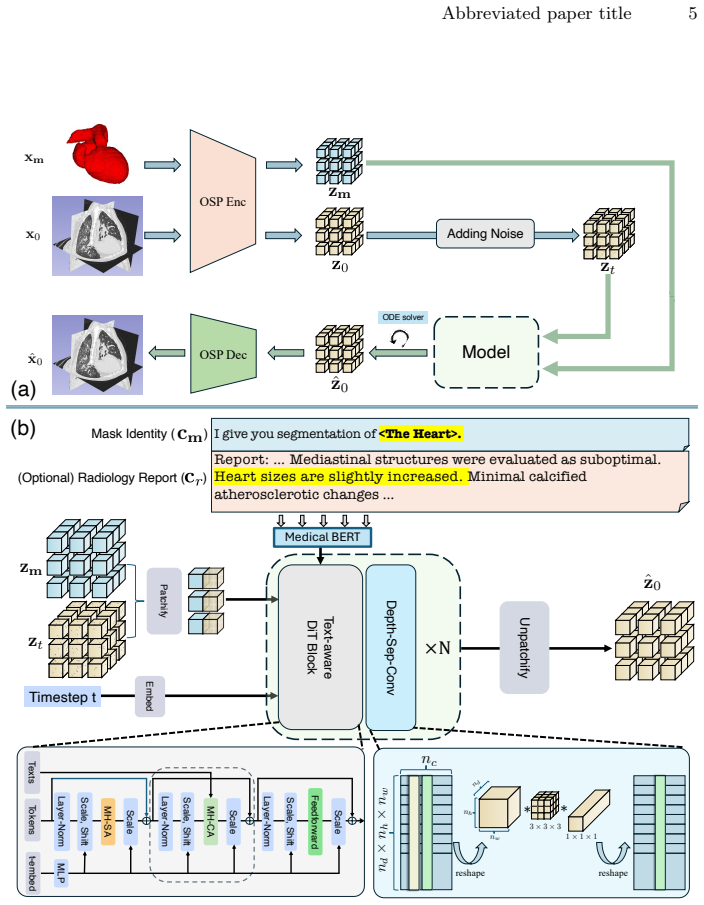
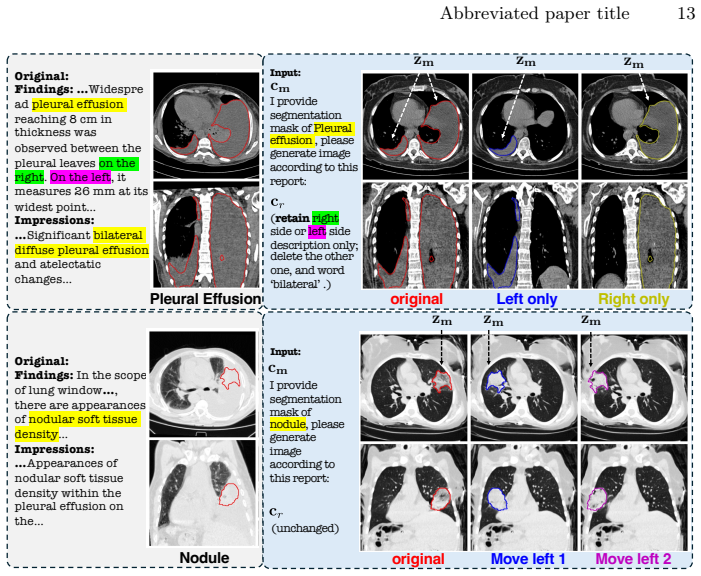
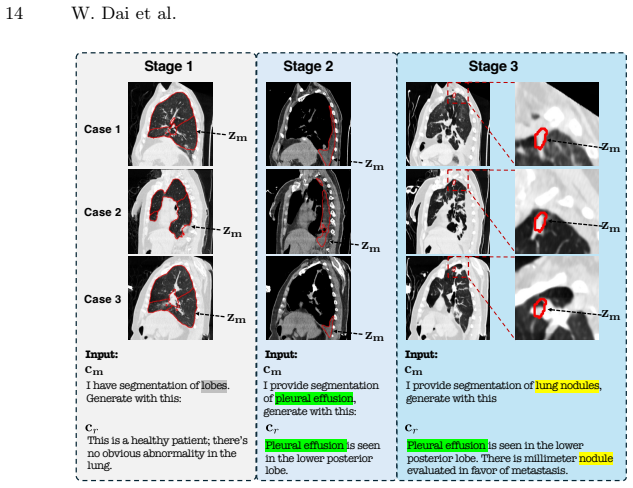
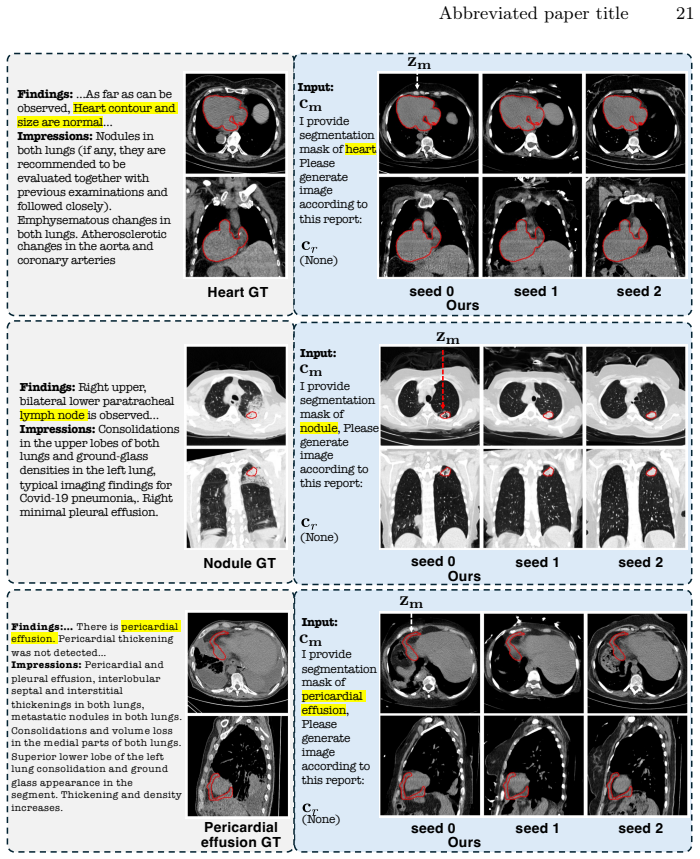
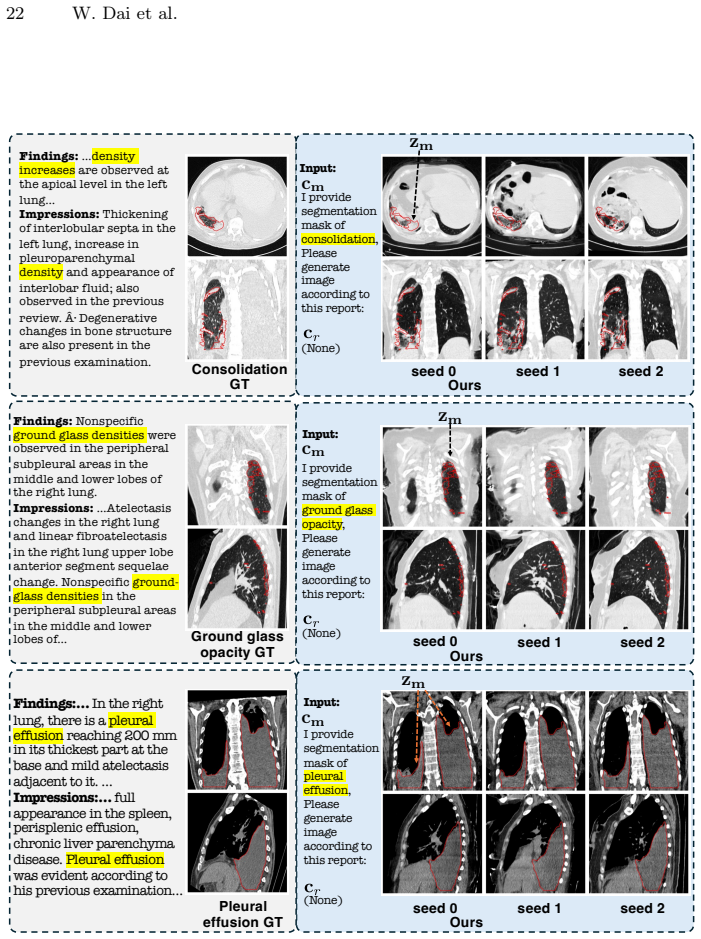
We propose a flexible multimodal framework for controllable volumetric image generation that supports input from radiology reports and segmentation prompts (both optional). Our approach allows users to provide segmentation of a specific anatomy or abnormality without requiring full-organ annotations. The semantic meaning of the segmentation mask is specified through an accompanying text description, resulting in a highly flexible and scalable conditioning mechanism. We develop a memory-efficient architecture based on a modified diffusion transformer that jointly processes image and segmentation tokens. The model further incorporates gated attention to effectively attend to long radiology rep
What carries the argument
modified diffusion transformer that jointly processes image and segmentation tokens, using gated attention for long radiology reports
If this is right
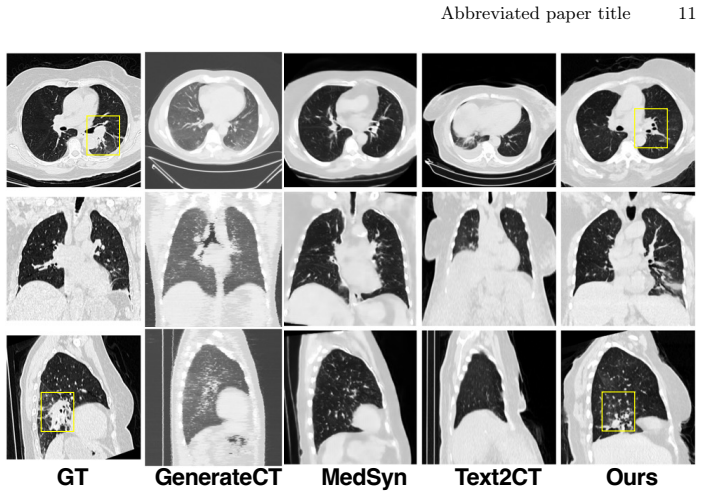
- State-of-the-art perceptual and semantic scores with 24% relative improvement in mean FID
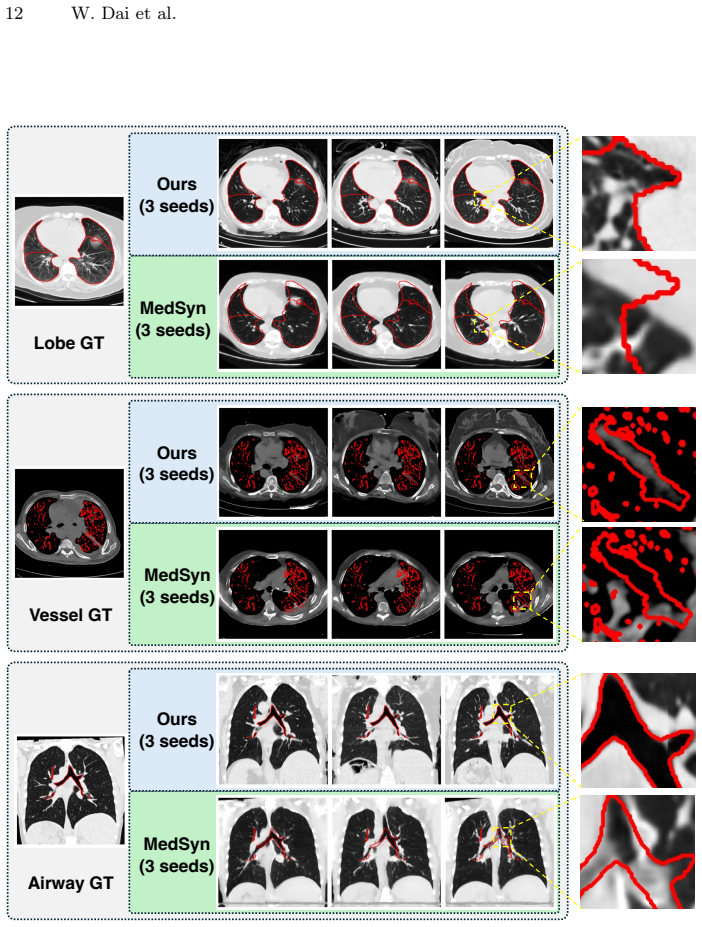
- Generation of high-resolution anatomically consistent CT volumes
- Improved data efficiency when the outputs are used for data augmentation
- Strong alignment between generated and real images confirmed by radiologist evaluation
Where Pith is reading between the lines
- Text-defined partial masks could support quick creation of examples for uncommon conditions by pairing a verbal description with a rough location mark.
- Lower annotation demands might allow training on more varied hospital datasets without full-organ labeling.
- The outputs could serve as priors that improve reconstruction accuracy in clinical inverse problems with sparse real scans.
Load-bearing premise
Segmentation of a specific anatomy or abnormality supplied with an accompanying text description yields a highly flexible and scalable conditioning mechanism that preserves anatomical consistency without requiring full-organ annotations.
What would settle it
If generated volumes fail to place the described abnormality at the location and shape given by the partial mask when checked by radiologists, or if models trained on the augmented data show no accuracy gain over those trained on real scans alone.
Figures



read the original abstract
Generative models for volumetric medical images have found many applications in medical imaging, ranging from data augmentation to serving as priors for inverse problems. For these applications, generating high-resolution 3D images with strong controllability is essential but remains highly challenging. Existing approaches typically control generation either through radiology reports used as text prompts or through full image segmentation. While text-based prompting is flexible, it provides limited spatial control over the location, shape, and boundary of abnormalities. In contrast, segmentation-based methods receive precise spatial guidance but are restrictive in requiring full-organ annotations. In this work, we propose a flexible multimodal framework for controllable volumetric image generation that supports input from radiology reports and segmentation prompts (both optional). Our approach allows users to provide segmentation of a specific anatomy or abnormality without requiring full-organ annotations. The semantic meaning of the segmentation mask is specified through an accompanying text description, resulting in a highly flexible and scalable conditioning mechanism. We develop a memory-efficient architecture based on a modified diffusion transformer that jointly processes image and segmentation tokens. The model further incorporates gated attention to effectively attend to long radiology reports. Experiments demonstrate that our method achieves state-of-the-art perceptual and semantic scores (e.g., 24% relative improvement in mean FID), generates high-resolution anatomically consistent CT volumes, and improves data efficiency when used for data augmentation. Radiologists' evaluation further confirms strong alignment between generated and real medical images.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces MedSyn2, a multimodal framework for controllable 3D CT volume generation based on a modified diffusion transformer that jointly processes image and segmentation tokens with gated attention for radiology reports. It supports optional text prompts and partial segmentation masks whose semantic meaning is supplied via accompanying text descriptions, avoiding the need for full-organ annotations. The central claims are state-of-the-art perceptual and semantic performance (including a 24% relative FID improvement), high-resolution anatomically consistent outputs, improved data efficiency for augmentation, and positive radiologist alignment.
Significance. If the empirical claims hold under rigorous verification, the work would provide a scalable conditioning mechanism that combines the flexibility of text with the spatial precision of partial segmentations, reducing annotation requirements while supporting applications such as data augmentation and priors for inverse problems in medical imaging.
major comments (2)
- [Abstract] Abstract: the assertion that the method 'generates high-resolution anatomically consistent CT volumes' rests on indirect perceptual (FID) and semantic scores plus radiologist evaluation. No quantitative mask-adherence metric (e.g., Dice overlap, boundary distance, or class-specific IoU between the supplied partial mask and the generated anatomy) is reported, which is load-bearing for the central claim that partial segmentation + text preserves exact location, shape, and semantics without full-organ annotations.
- [Abstract] Abstract: the reported '24% relative improvement in mean FID' and 'state-of-the-art perceptual and semantic scores' are stated without naming the baselines, dataset splits, sample counts, variance estimates, or statistical tests. This absence prevents assessment of whether the SOTA claim and the data-efficiency improvement for augmentation are supported.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments on our manuscript. We provide point-by-point responses to the major comments below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion that the method 'generates high-resolution anatomically consistent CT volumes' rests on indirect perceptual (FID) and semantic scores plus radiologist evaluation. No quantitative mask-adherence metric (e.g., Dice overlap, boundary distance, or class-specific IoU between the supplied partial mask and the generated anatomy) is reported, which is load-bearing for the central claim that partial segmentation + text preserves exact location, shape, and semantics without full-organ annotations.
Authors: We agree that a direct quantitative metric for mask adherence would strengthen the evidence for the controllability of partial segmentations. Our current evaluations focus on overall perceptual quality via FID, semantic alignment, and expert radiologist assessment. In the revised manuscript, we will incorporate additional metrics such as Dice overlap and boundary distances to quantify how well the generated anatomy adheres to the provided partial masks. revision: yes
-
Referee: [Abstract] Abstract: the reported '24% relative improvement in mean FID' and 'state-of-the-art perceptual and semantic scores' are stated without naming the baselines, dataset splits, sample counts, variance estimates, or statistical tests. This absence prevents assessment of whether the SOTA claim and the data-efficiency improvement for augmentation are supported.
Authors: The abstract is intended as a concise summary. The full details regarding the baselines (e.g., comparison methods), dataset splits, sample counts for evaluation, variance estimates, and statistical tests are provided in Section 4 of the manuscript. We will update the abstract to include a brief reference to the experimental protocol and key baselines to make these claims more self-contained. revision: yes
Circularity Check
No circularity: empirical claims rest on external metrics without self-referential reduction
full rationale
The paper proposes an architecture for controllable 3D CT generation and reports empirical results on FID, semantic scores, and radiologist evaluation. No derivation chain, equations, or fitted parameters are presented that reduce by construction to the inputs. The abstract and described claims contain no self-definitional steps, fitted-input predictions, or load-bearing self-citations that would force the central results. The method is evaluated against external benchmarks, satisfying the condition for a self-contained empirical contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Amirrajab, S., Salahuddin, Z., Kuang, S., Woodruff, H.C., Lambin, P.: Radiol- ogy report conditional 3d ct generation with multi encoder latent diffusion model (2025),https://arxiv.org/abs/2509.14780
arXiv 2025
-
[2]
Boecking, B., Usuyama, N., Bannur, S., Castro, D.C., Schwaighofer, A., Hy- land, S., Wetscherek, M., Naumann, T., Nori, A., Alvarez-Valle, J., Poon, H., Oktay, O.: Making the most of text semantics to improve biomedical vision- language processing (2022).https://doi.org/10.48550/ARXIV.2204.09817, https://arxiv.org/abs/2204.09817
-
[3]
Carmo, D.S., Ribeiro, J.A., Comellas, A.P., Reinhardt, J.M., Gerard, S.E., Rittner, L., Lotufo, R.A.: Medpseg: Hierarchical polymorphic multitask learning for the segmentation of ground-glass opacities, consolidation, and pulmonary structures on computed tomography (2024)
2024
-
[4]
Chung, H., Ryu, D., McCann, M.T., Klasky, M.L., Ye, J.C.: Solving 3d inverse problems using pre-trained 2d diffusion models (2023)
2023
-
[5]
Dorjsembe, Z., Pao, H.K., Odonchimed, S., Xiao, F.: Conditional diffusion models for semantic 3d brain mri synthesis. IEEE Journal of Biomedical and Health Infor- matics28(7), 4084–4093 (2024).https://doi.org/10.1109/JBHI.2024.3385504
-
[6]
IEEE Transactions on Medical Imaging39(8), 2626–2637 (2020).https://doi.org/10
Fan, D.P., Zhou, T., Ji, G.P., Zhou, Y., Chen, G., Fu, H., Shen, J., Shao, L.: Inf-net: Automatic covid-19 lung infection segmentation from ct images. IEEE Transactions on Medical Imaging39(8), 2626–2637 (2020).https://doi.org/10. 1109/TMI.2020.2996645
arXiv 2020
-
[7]
Guo, P., Zhao, C., Yang, D., He, Y., Nath, V., Xu, Z., Bassi, P., Zhou, Z., Simon, B., Harmon, S., Turkbey, B., Xu, D.: Text2ct: Towards 3d ct volume generation from free-text descriptions using diffusion model (05 2025).https://doi.org/10. 48550/arXiv.2505.04522
arXiv 2025
-
[8]
Guo, P., Zhao, C., Yang, D., Xu, Z., Nath, V., Tang, Y., Simon, B., Belue, M., Harmon, S., Turkbey, B., Xu, D.: Maisi: Medical ai for synthetic imaging (09 2024). https://doi.org/10.48550/arXiv.2409.11169
-
[9]
Hamamci, I.E., Er, S., Almas, F., Simsek, A.G., Esirgun, S.N., İrem Hatice Doğan, Dasdelen, M.F., Wittmann, B., Simsar, E., Simsar, M., Erdemir, E.B., Alanbay, A., Sekuboyina, A.K., Lafci, B., Ozdemir, M.K., Menze, B.H.: Generalist foundation modelsfromamultimodaldatasetfor3dcomputedtomography.Naturebiomedical engineering (2024),https://api.semanticschola...
2024
-
[10]
Scott Armstrong, ed.Expert Opinions in Forecasting: The Role of the Delphi Technique
Hamamci, I.E., Er, S., Sekuboyina, A., Simsar, E., Tezcan, A., Simsek, A.G., Esir- gun, S.N., Almas, F., Doğan, I., Dasdelen, M.F., Prabhakar, C., Reynaud, H., Pati, S., Bluethgen, C., Ozdemir, M.K., Menze, B.: Generatect: Text-conditional generation of 3d chest ct volumes. In: Computer Vision – ECCV 2024: 18th Eu- ropean Conference, Milan, Italy, Septemb...
-
[11]
In: Greenspan, H., Madabhushi, A., Mousavi, P., Salcudean, S., Duncan, J., Syeda- Mahmood, T., Taylor, R
Han, K., Xiong, Y., You, C., Khosravi, P., Sun, S., Yan, X., Duncan, J.S., Xie, X.: Medgen3d: A deep generative framework for paired 3d image and mask generation. In: Greenspan, H., Madabhushi, A., Mousavi, P., Salcudean, S., Duncan, J., Syeda- Mahmood, T., Taylor, R. (eds.) Medical Image Computing and Computer Assisted Intervention – MICCAI 2023. pp. 759...
2023
-
[12]
European Radiology Experimental4, 50 (08 2020)
Hofmanninger, J., Prayer, F., Pan, J., Röhrich, S., Prosch, H., Langs, G.: Auto- matic lung segmentation in routine imaging is primarily a data diversity problem, not a methodology problem. European Radiology Experimental4, 50 (08 2020). https://doi.org/10.1186/s41747-020-00173-2
-
[13]
Jiang, Y., Lemaréchal, Y., Plante, S., Bafaro, J., Abi-Rjeile, J., Joubert, P., De- sprés, P., Manem, V.: Lung-ddpm: Semantic layout-guided diffusion models for thoracic ct image synthesis. IEEE Transactions on Biomedical Engineering73(3), 1134–1145 (2026).https://doi.org/10.1109/TBME.2025.3599011
-
[14]
Physics in Medicine & Biology70(6), 065007 (mar 2025).https://doi
Krishna, A., Wang, G., Mueller, K.: Guided synthesis of annotated lung ct images with pathologies using a multi-conditioned denoising diffusion probabilistic model (mddpm). Physics in Medicine & Biology70(6), 065007 (mar 2025).https://doi. org/10.1088/1361-6560/adb9b3,https://doi.org/10.1088/1361-6560/adb9b3
-
[15]
In: Medical Imaging with Deep Learning (2025),https://openreview.net/forum? id=UpJMAlZNuo
Kumar, A., Kriz, A., Havaei, M., Arbel, T.: PRISM: High-resolution & precise counterfactual medical image generation using language-guided stable diffusion. In: Medical Imaging with Deep Learning (2025),https://openreview.net/forum? id=UpJMAlZNuo
2025
-
[16]
arXiv preprint arXiv:2511.13720 (2025)
Li, T., He, K.: Back to basics: Let denoising generative models denoise. arXiv preprint arXiv:2511.13720 (2025)
Pith/arXiv arXiv 2025
-
[17]
Lin, B., Ge, Y., Cheng, X., Li, Z., Zhu, B., Wang, S., He, X., Ye, Y., Yuan, S., Chen, L., Jia, T., Zhang, J., Tang, Z., Pang, Y., She, B., Yan, C., Hu, Z., Dong, X., Chen, L., Pan, Z., Zhou, X., Dong, S., Tian, Y., Yuan, L.: Open-sora plan: Open-source large video generation model (2024),https://arxiv.org/abs/2412.00131
Pith/arXiv arXiv 2024
-
[18]
In: The Eleventh International Conference on Learning Representations (2023),https://openreview.net/forum?id=PqvMRDCJT9t
Lipman, Y., Chen, R.T.Q., Ben-Hamu, H., Nickel, M., Le, M.: Flow matching for generative modeling. In: The Eleventh International Conference on Learning Representations (2023),https://openreview.net/forum?id=PqvMRDCJT9t
2023
-
[19]
In: Proceedings of the Asian Conference on Computer Vision (ACCV)
Liu, C., Yuan, X., Yu, Z., Wang, Y.: Texdc: Text-driven disease-aware 4d cardiac cine mri images generation. In: Proceedings of the Asian Conference on Computer Vision (ACCV). pp. 3005–3021 (December 2024)
2024
-
[20]
In: The Eleventh International Conference on Learning Representations (2023),https://openreview.net/forum?id=XVjTT1nw5z
Liu, X., Gong, C., qiang liu: Flow straight and fast: Learning to generate and trans- fer data with rectified flow. In: The Eleventh International Conference on Learning Representations (2023),https://openreview.net/forum?id=XVjTT1nw5z
2023
-
[21]
Mei,X.,Liu,Z.,Robson,P.M.,Marinelli,B.,Huang,M.,Doshi,A.,Jacobi,A.,Cao, C., Link, K.E., Yang, T., Wang, Y., Greenspan, H., Deyer, T., Fayad, Z.A., Yang, Y.: Radimagenet: An open radiologic deep learning research dataset for effective transfer learning. Radiology: Artificial Intelligence0(ja), e210315 (0).https:// doi.org/10.1148/ryai.210315,https://doi.or...
-
[22]
In: International Conferenceon LearningRepresentations(2022),https://openreview.net/forum? id=aBsCjcPu_tE
Meng, C., He, Y., Song, Y., Song, J., Wu, J., Zhu, J.Y., Ermon, S.: SDEdit: Guided image synthesis and editing with stochastic differential equations. In: International Conferenceon LearningRepresentations(2022),https://openreview.net/forum? id=aBsCjcPu_tE
2022
-
[23]
Molino, D., Caruso, C.M., Ruffini, F., Soda, P., Guarrasi, V.: Text-to-ct generation via 3d latent diffusion model with contrastive vision-language pretraining (2025), https://arxiv.org/abs/2506.00633
arXiv 2025
-
[24]
Morrison, K., Mathur, A., Bradshaw, A., Wartmann, T., Lundi, S., Zandifar, A., Dai, W., Batmanghelich, K., Eslami, M., Perer, A.: A human-centered approach to identifying promises, risks, & challenges of text-to-image generative ai in radiology (07 2025).https://doi.org/10.48550/arXiv.2507.16207
-
[25]
Nercessian, M., Agrawal, K., Liu, L., Lian, L., Harguindeguy, N., Wu, Y., Mikhael, P., Lin, G., Sequist, L., Fintelmann, F., Darrell, T., Bai, Y., Chung, M., Yala, A.: Pillar-0: A new frontier for radiology foundation models (11 2025).https: //doi.org/10.21203/rs.3.rs-8196619/v1 18 W. Dai et al
-
[26]
In: Submitted to Medical Imag- ing meets EurIPS: MedEurIPS 2025 (2025),https://openreview.net/forum?id= VTQwlZLq0a, under review
Oliveras, A., Marí, R., Redondo, R., Guardià-Olivella, O., Tost, A., Nagarajan, B., Migliorelli, C., Ribas, V., Radeva, P.: LAND: Lung and nodule diffusion for 3d chest CT synthesis with anatomical guidance. In: Submitted to Medical Imag- ing meets EurIPS: MedEurIPS 2025 (2025),https://openreview.net/forum?id= VTQwlZLq0a, under review
2025
-
[27]
arXiv preprint arXiv:2212.09748 (2022)
Peebles, W., Xie, S.: Scalable diffusion models with transformers. arXiv preprint arXiv:2212.09748 (2022)
Pith/arXiv arXiv 2022
-
[28]
arXiv preprint arXiv:2503.09642 (2025)
Peng, X., Zheng, Z., Shen, C., Young, T., Guo, X., Wang, B., Xu, H., Liu, H., Jiang, M., Li, W., Wang, Y., Ye, A., Ren, G., Ma, Q., Liang, W., Lian, X., Wu, X., Zhong, Y., Li, Z., Gong, C., Lei, G., Cheng, L., Zhang, L., Li, M., Zhang, R., Hu, S., Huang, S., Wang, X., Zhao, Y., Wang, Y., Wei, Z., You, Y.: Open-sora 2.0: Training a commercial-level video g...
Pith/arXiv arXiv 2025
-
[29]
European Journal of Radiology150, 110259 (2022).https://doi.org/10.1016/j.ejrad.2022.110259
Poletti, J., Bach, M., Yang, S., Sexauer, R., Stieltjes, B., Rotzinger, D.C., Bre- merich, J., Walter Sauter, A., Weikert, T.: Automated lung vessel segmentation reveals blood vessel volume redistribution in viral pneumonia. European Journal of Radiology150, 110259 (2022).https://doi.org/10.1016/j.ejrad.2022.110259
-
[30]
In: The Thirty-ninth Annual Conference on Neural Information Processing Systems (2025),https: //openreview.net/forum?id=1b7whO4SfY
Qiu, Z., Wang, Z., Zheng, B., Huang, Z., Wen, K., Yang, S., Men, R., Yu, L., Huang, F., Huang, S., Liu, D., Zhou, J., Lin, J.: Gated attention for large lan- guage models: Non-linearity, sparsity, and attention-sink-free. In: The Thirty-ninth Annual Conference on Neural Information Processing Systems (2025),https: //openreview.net/forum?id=1b7whO4SfY
2025
-
[31]
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models (2021)
2021
-
[32]
Inves- tigative RadiologyPublish Ahead of Print(03 2022).https://doi.org/10
Sexauer, R., Yang, S., Weikert, T., Poletti, J., Bremerich, J., Roth, J., Sauter, A., Anastasopoulos, C.: Automated detection, segmentation, and classification of pleural effusion from computed tomography scans using machine learning. Inves- tigative RadiologyPublish Ahead of Print(03 2022).https://doi.org/10. 1097/RLI.0000000000000869
2022
-
[33]
In: Gee, J.C., Alexander, D.C., Hong, J., Iglesias, J.E., Sudre, C.H., Venkataraman, A., Golland, P., Kim, J.H., Park, J
Shao, M., Miao, X., Duan, H., Wang, Z., Chen, J., Huang, Y., Wu, X., Deng, J., Long, Y., Zheng, Y.: Trace: Temporally reliable anatomically-conditioned 3d ct generation with enhanced efficiency. In: Gee, J.C., Alexander, D.C., Hong, J., Iglesias, J.E., Sudre, C.H., Venkataraman, A., Golland, P., Kim, J.H., Park, J. (eds.) Medical Image Computing and Compu...
-
[34]
pp. 627–637. Springer Nature Switzerland, Cham (2026)
2026
-
[35]
IEEE Transactions on Medical Imaging44, 4960–4972 (2024),https: //api.semanticscholar.org/CorpusID:274789446
Wang, H., Liu, Z., Sun, K., Wang, X., Shen, D., Cui, Z.: 3d meddiffusion: A 3d medical latent diffusion model for controllable and high-quality medical image generation. IEEE Transactions on Medical Imaging44, 4960–4972 (2024),https: //api.semanticscholar.org/CorpusID:274789446
2024
-
[36]
Wang, J., Reynaud, H., Erick, F.X., Kainz, B.: Ctflow: Video-inspired latent flow matching for 3d ct synthesis (2025),https://arxiv.org/abs/2508.12900
arXiv 2025
-
[37]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Wang, Z., Xia, X., Chen, R., Yu, D., Wang, C., Gong, M., Liu, T.: Lavin-dit: Large vision diffusion transformer. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 20060–20070 (2025)
2025
-
[38]
Radiology: Artificial Intelligence (Jul 2023), https://pubs.rsna.org/doi/10.1148/ryai.230024
Wasserthal, J., Breit, H.C., Meyer, M.T., Pradella, M., Hinck, D., Sauter, A.W., Heye, T., Boll, D.T., Cyriac, J., Yang, S., Bach, M., Segeroth, M.: Totalsegmenta- tor: Robust segmentation of 104 anatomic structures in ct images. Radiology: Arti- ficial Intelligence5(5), e230024 (2023).https://doi.org/10.1148/ryai.230024, https://doi.org/10.1148/ryai.2300...
-
[39]
Diagnostics12(5) (2022).https://doi.org/10.3390/ diagnostics12051045,https://www.mdpi.com/2075-4418/12/5/1045
Wilder-Smith, A.J., Yang, S., Weikert, T., Bremerich, J., Haaf, P., Segeroth, M., Ebert, L.C., Sauter, A., Sexauer, R.: Automated detection, segmentation, and classification of pericardial effusions on chest ct using a deep convolu- tional neural network. Diagnostics12(5) (2022).https://doi.org/10.3390/ diagnostics12051045,https://www.mdpi.com/2075-4418/12/5/1045
2022
-
[40]
arXiv preprint arXiv:2410.13823 (2024)
Xing, X., Ning, J., Nan, Y., Yang, G.: Deep generative models unveil pat- terns in medical images through vision-language conditioning. arXiv preprint arXiv:2410.13823 (2024)
arXiv 2024
-
[41]
IEEE Transactions on Medical Imag- ing (2024).https://doi.org/10.1109/TMI.2024.3415032
Xu, Y., Sun, L., Peng, W., Jia, S., Morrison, K., Perer, A., Zandifar, A., Visweswaran, S., Eslami, M., Batmanghelich, K.: Medsyn: Text-guided anatomy- aware synthesis of high-fidelity 3d ct images. IEEE Transactions on Medical Imag- ing (2024).https://doi.org/10.1109/TMI.2024.3415032
-
[42]
Zhang, L., Rao, A., Agrawala, M.: Adding conditional control to text-to-image diffusion models (2023)
2023
-
[43]
Zhao, C., Guo, P., Yang, D., Tang, Y., He, Y., Simon, B., Belue, M., Harmon, S., Turkbey, B., Xu, D.: Maisi-v2: Accelerated 3d high-resolution medical image synthesis with rectified flow and region-specific contrastive loss (2025),https: //arxiv.org/abs/2508.05772
arXiv 2025
-
[44]
arXiv preprint arXiv:2412.20404 (2024)
Zheng, Z., Peng, X., Yang, T., Shen, C., Li, S., Liu, H., Zhou, Y., Li, T., You, Y.: Open-sora: Democratizing efficient video production for all. arXiv preprint arXiv:2412.20404 (2024)
Pith/arXiv arXiv 2024
-
[45]
Zhuang, Y., Hou, B., Mathai, T.S., Mukherjee, P., Kim, B., Summers, R.M.: Semantic image synthesis for abdominal ct. In: Deep Generative Models: Third MICCAI Workshop, DGM4MICCAI 2023, Held in Conjunction with MICCAI 2023, Vancouver, BC, Canada, October 8, 2023, Proceedings. p. 214–224. Springer- Verlag, Berlin, Heidelberg (2023).https://doi.org/10.1007/9...
-
[46]
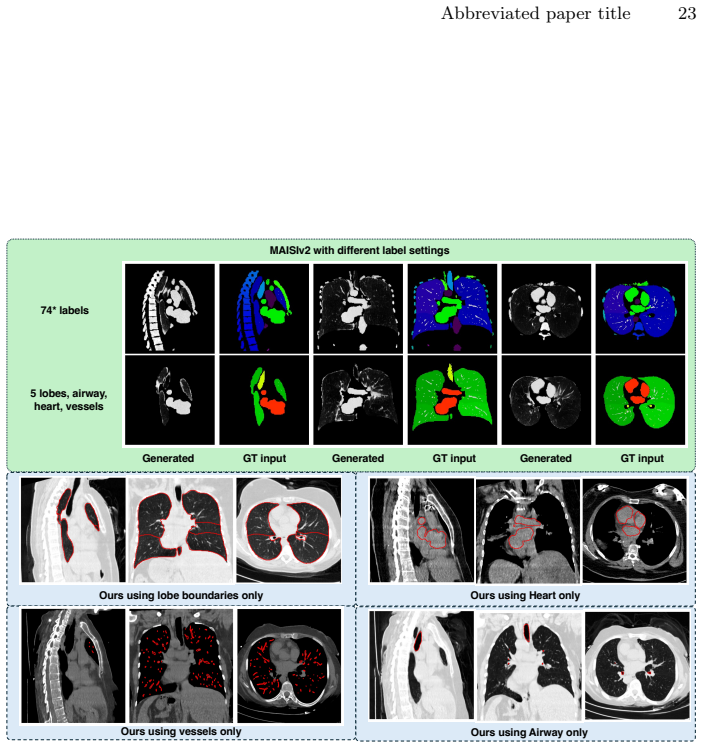
* the overlap of MAISI labels and TotalSegmentator labels, namely 74 labels,and2. using five lobes, airway, heart, vessels (anatomies our model accepts).The results show MAISIv2 fails to generate tissues outside given masks (e.g., soft tissues within skin), leading to its restrictions. Moreover,it depends on theskin maskto generate soft tissues of human b...
2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.