Profiling Privacy Preservation Against Gradient Inversion Attacks in Tabular Federated Learning
Pith reviewed 2026-06-28 17:41 UTC · model grok-4.3
The pith
Model architecture acts as a controllable privacy factor in tabular federated learning against gradient inversion attacks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
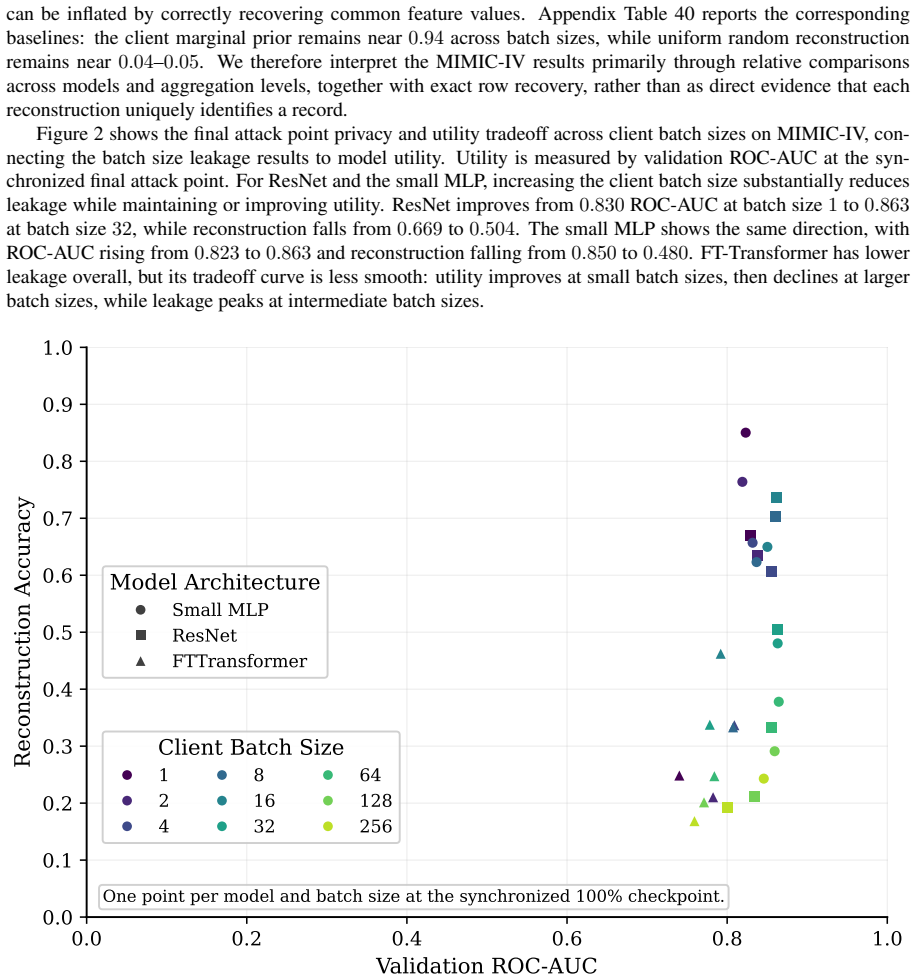
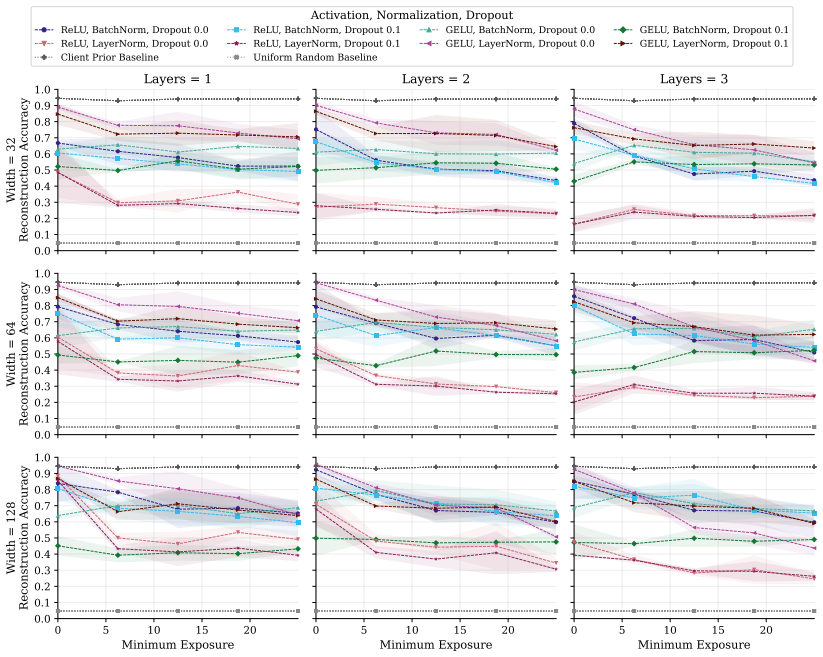
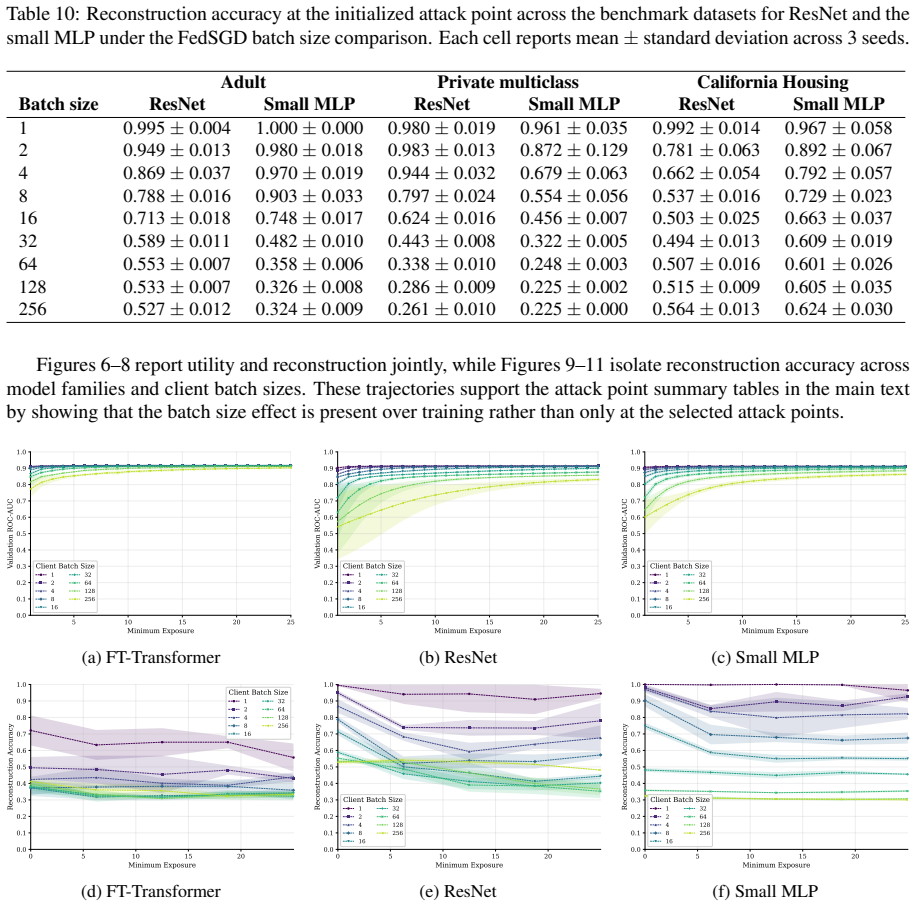
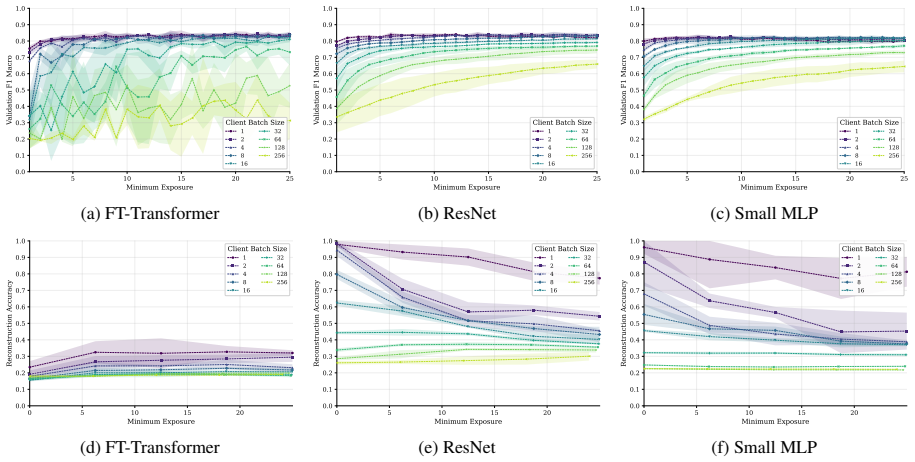
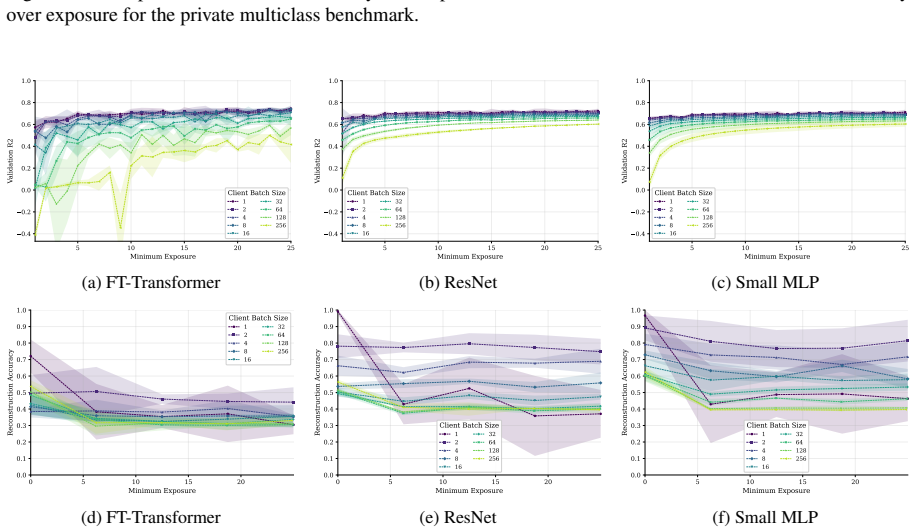
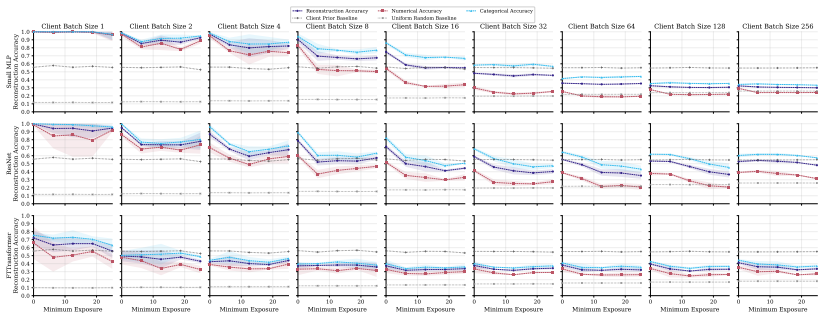
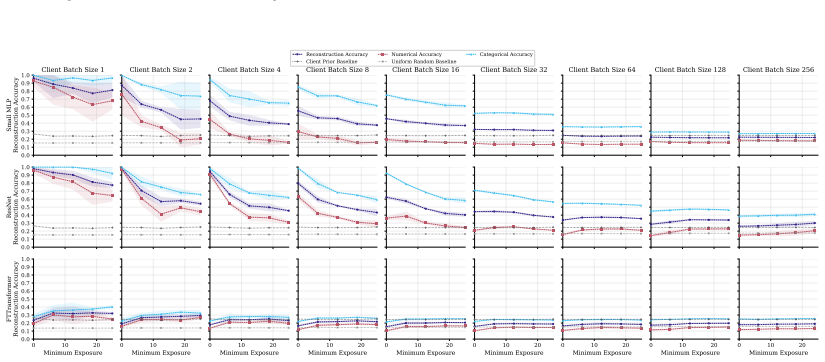
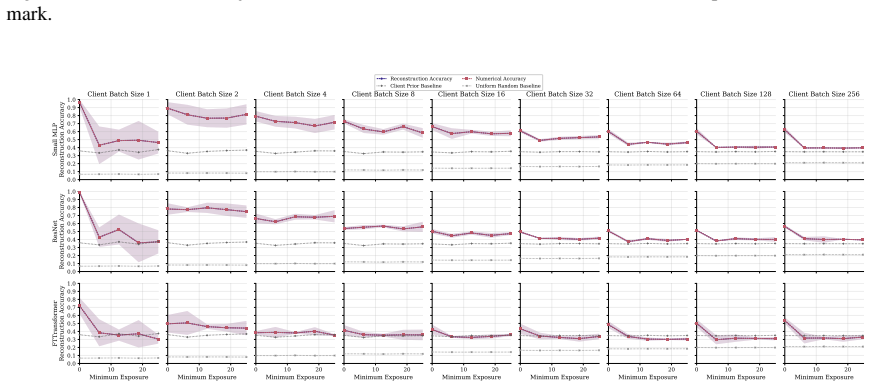
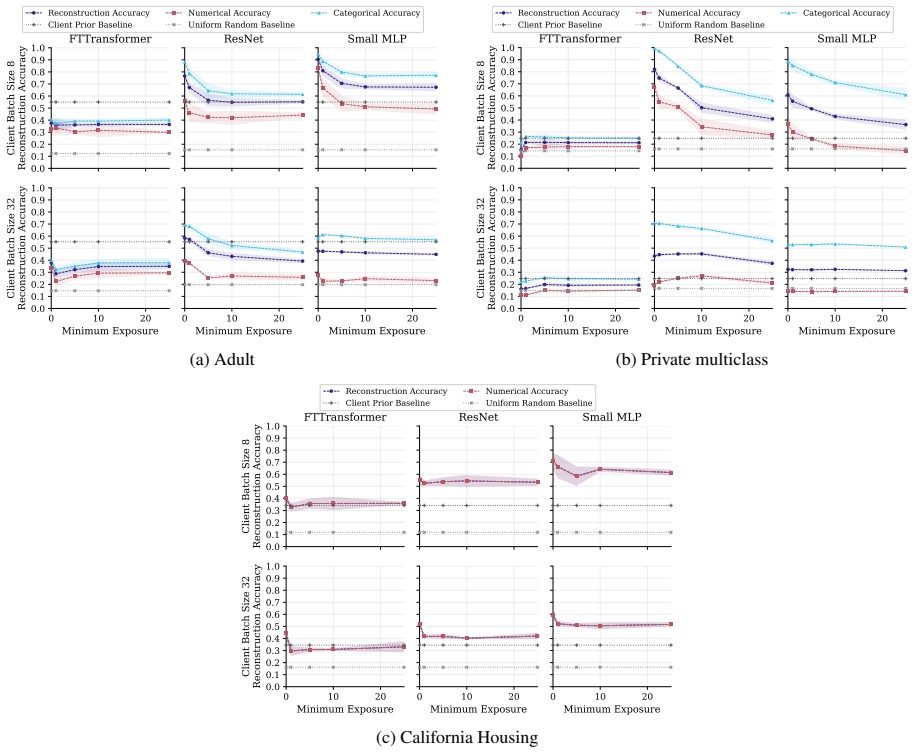
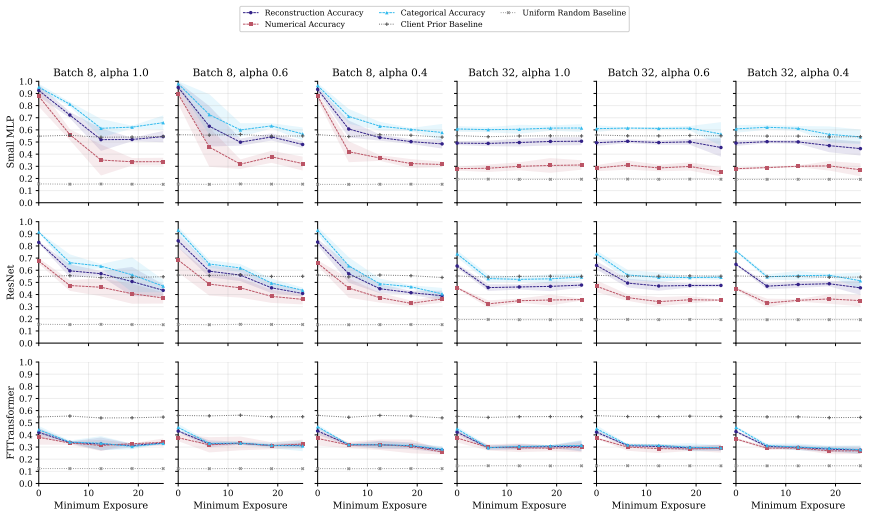
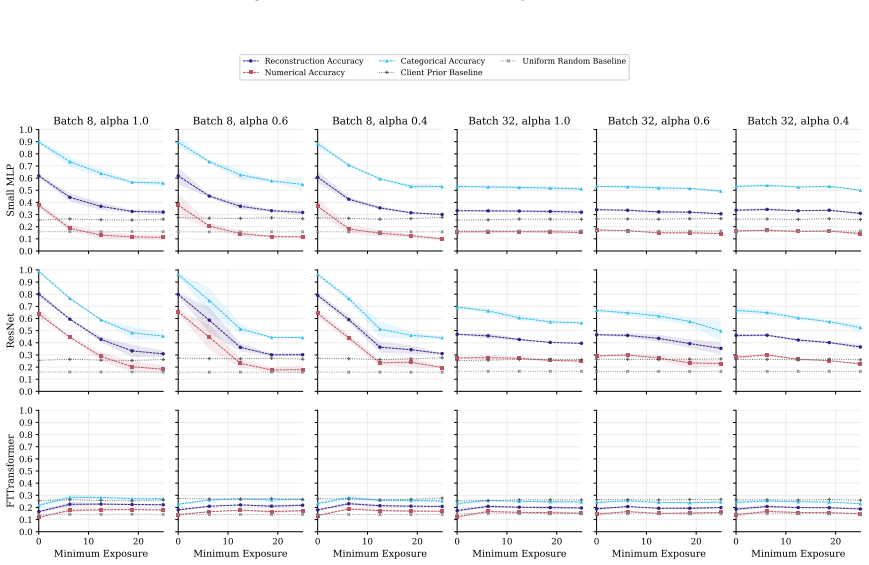
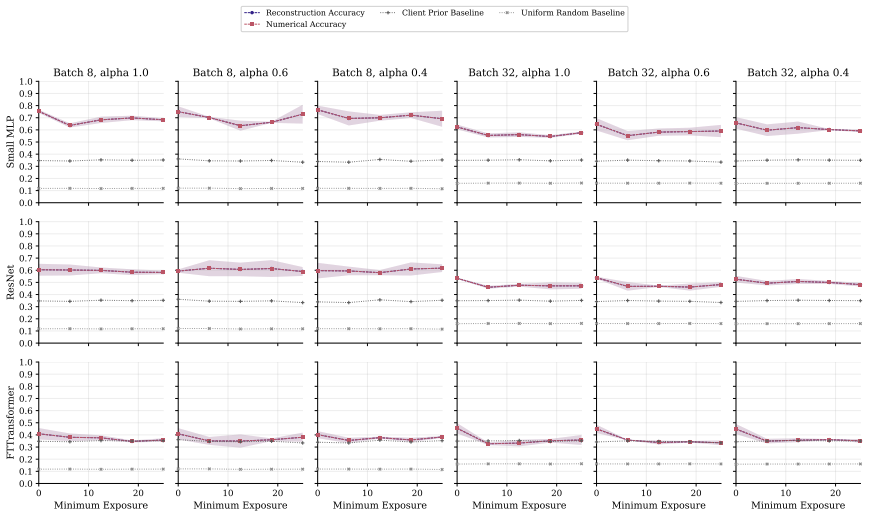
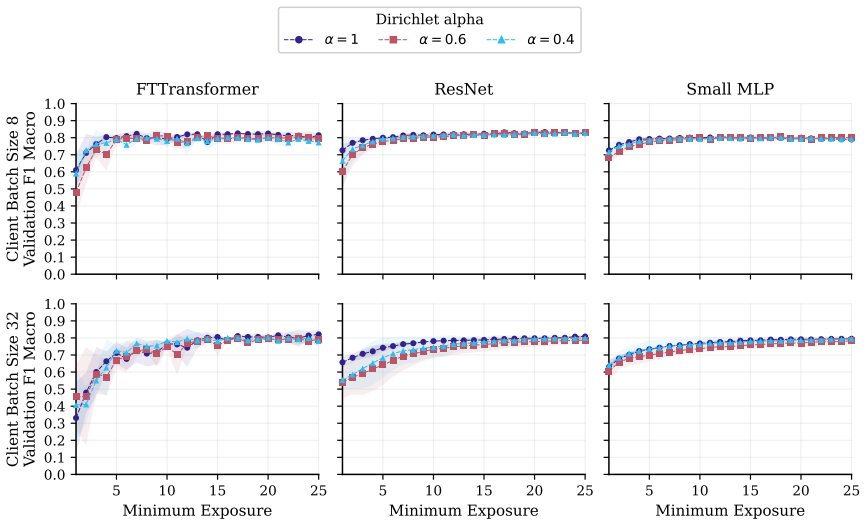
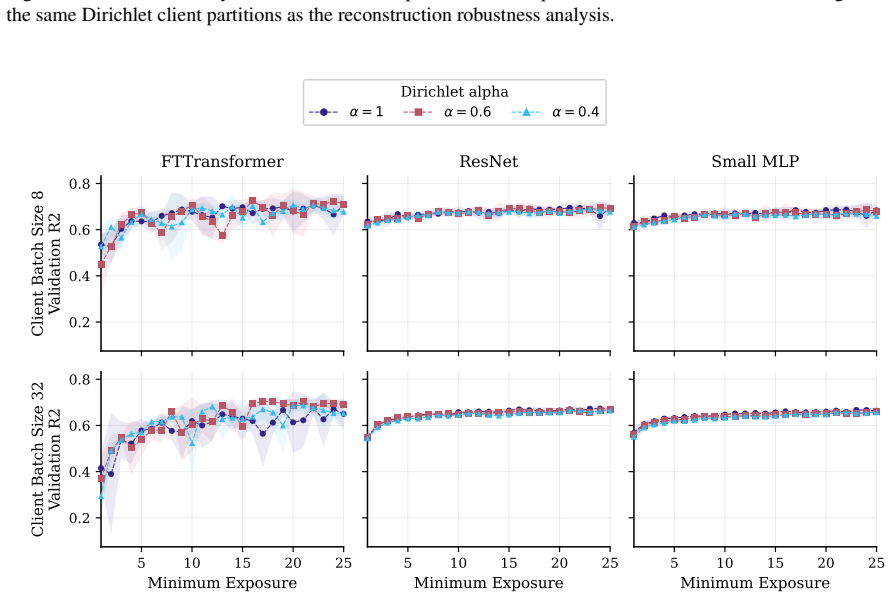
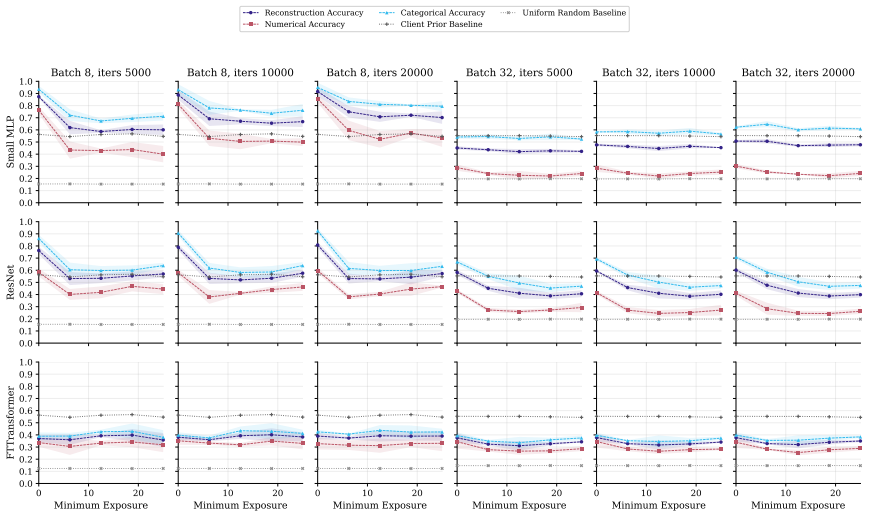
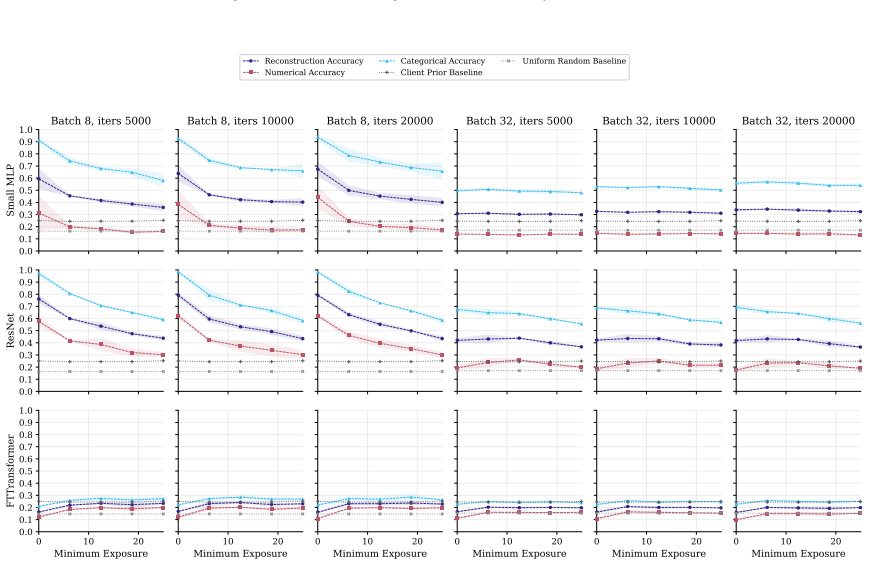
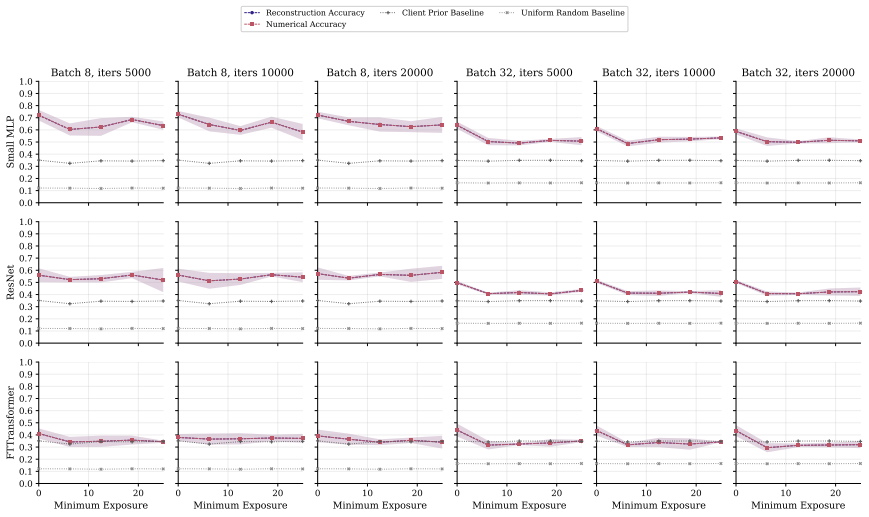
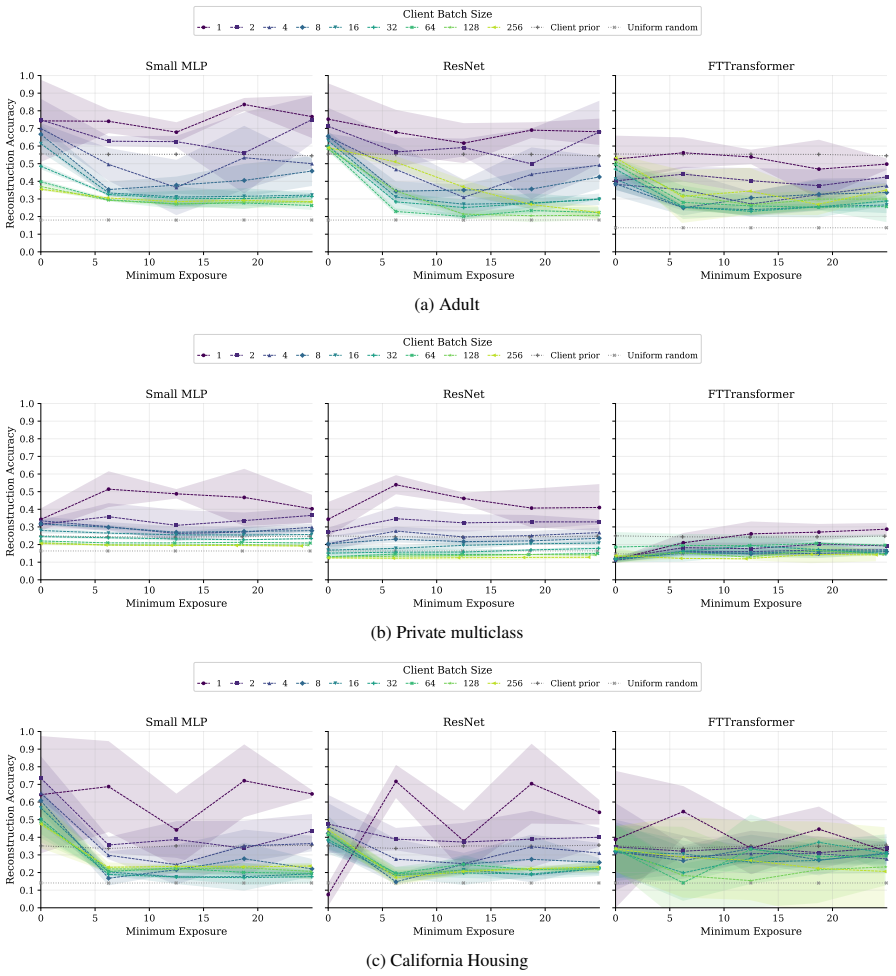
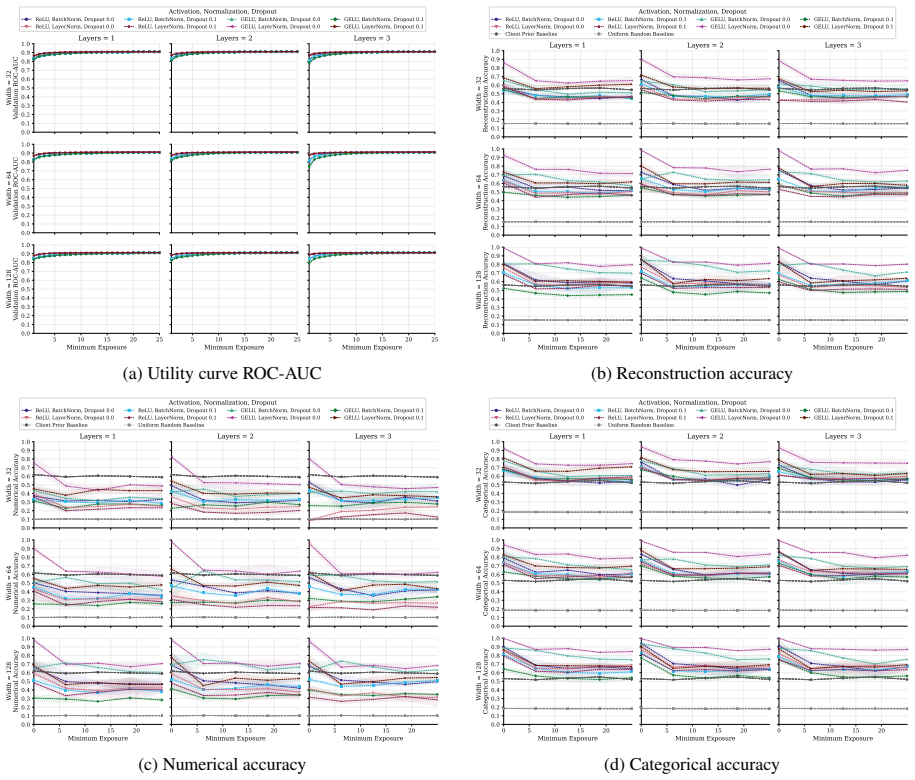
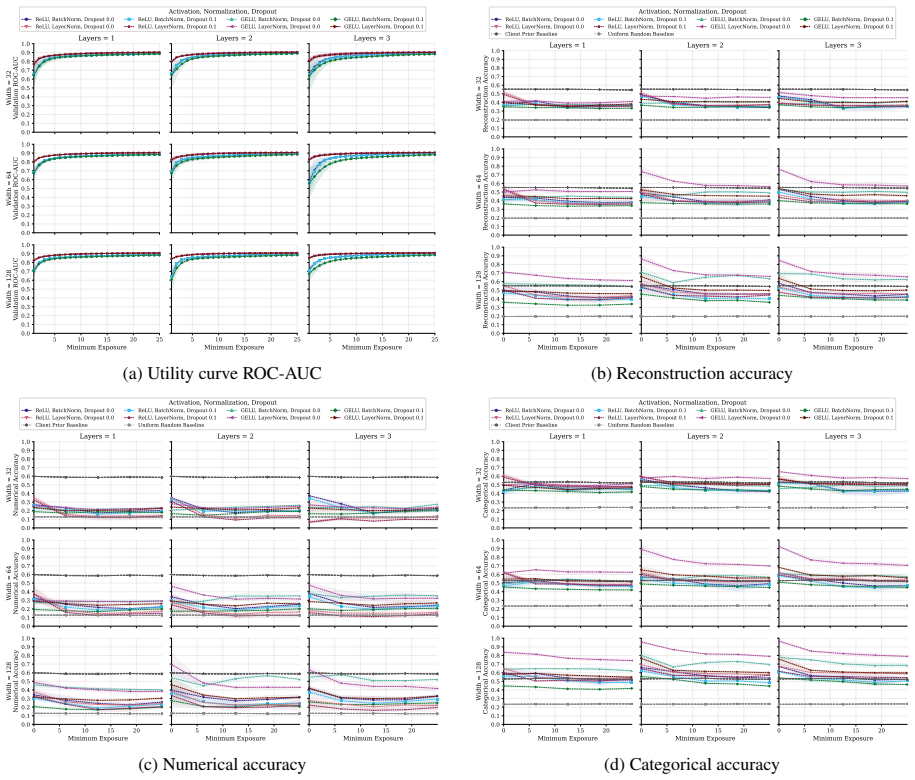
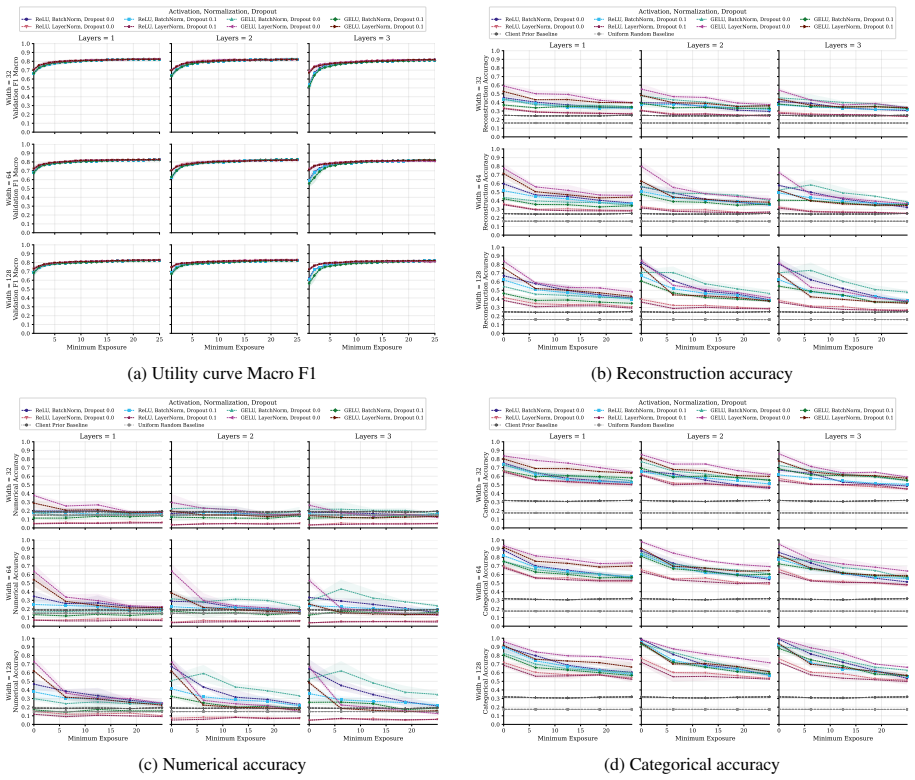
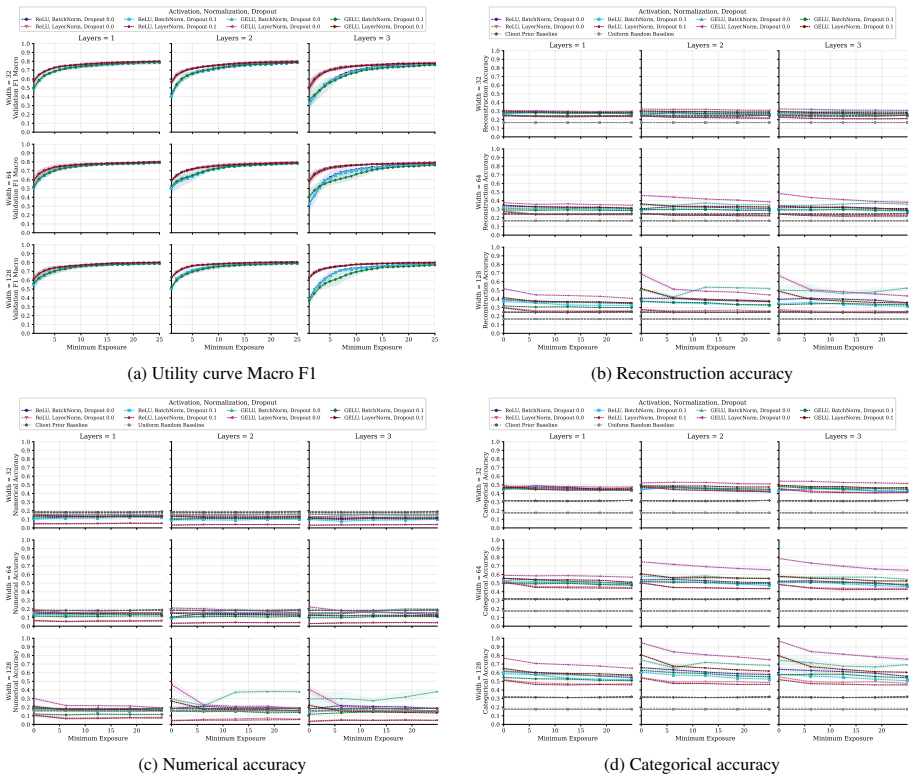
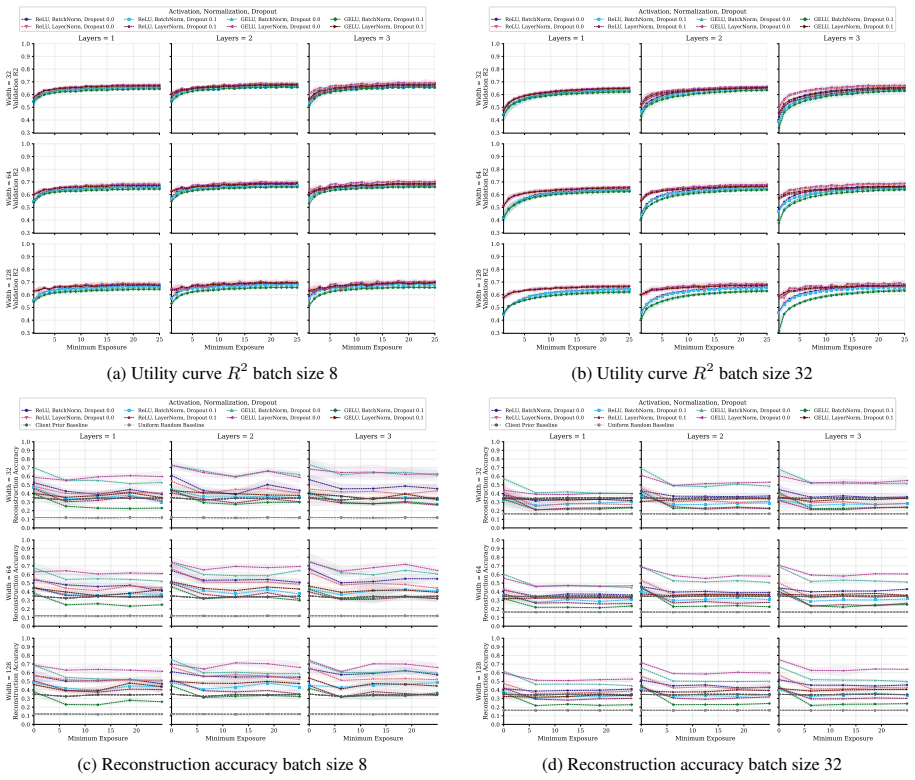
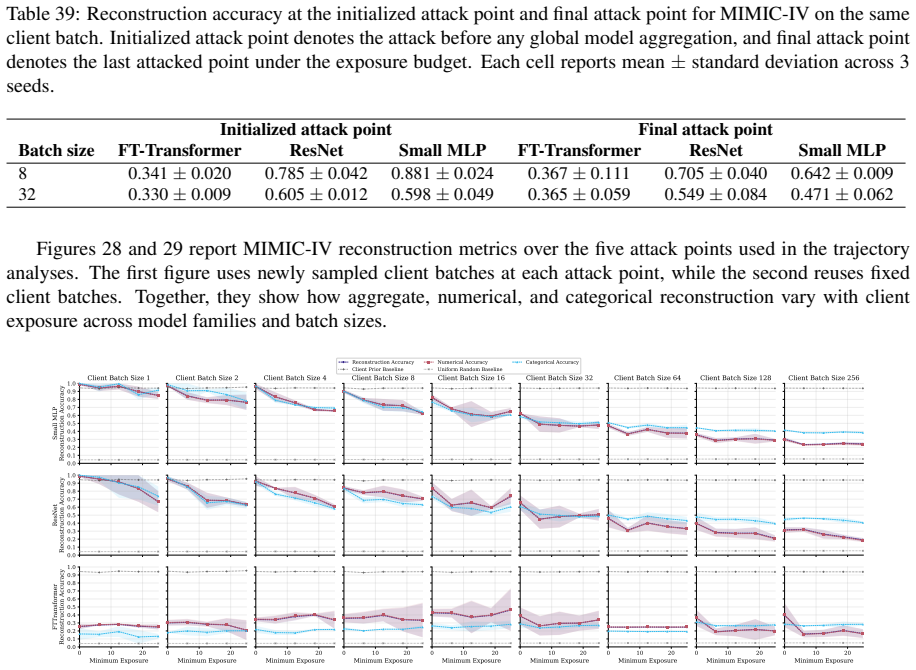
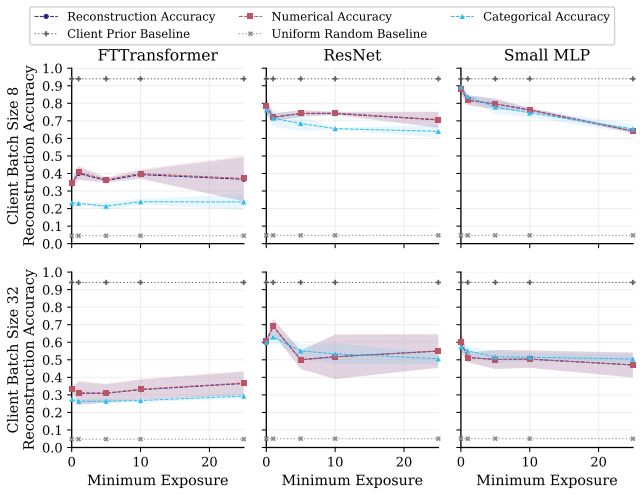
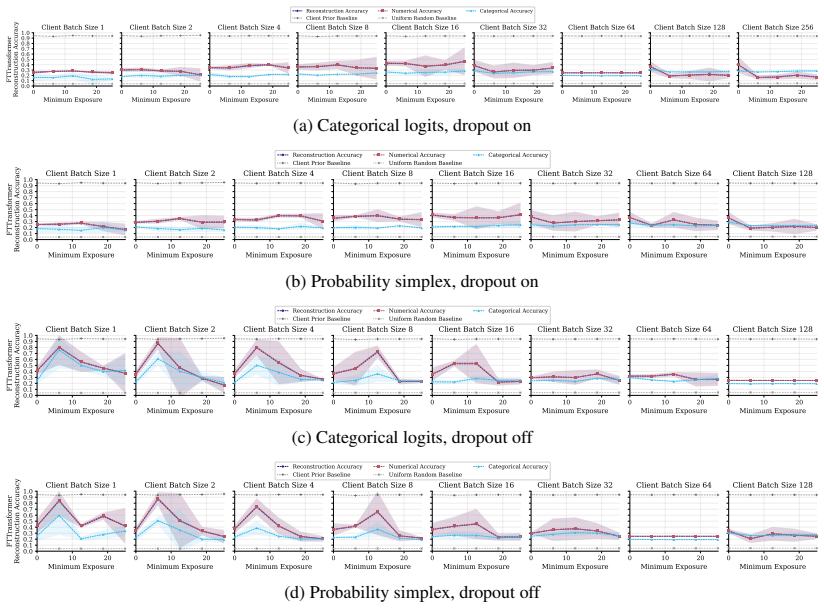
FT-Transformer is consistently harder to invert than one-hot baselines; reconstructability varies substantially within the MLP family; small client batches and updates representing few distinct records are most vulnerable; larger local batches and stronger aggregation reduce but do not eliminate leakage; aggregate reconstruction accuracy can overstate complete record recovery in sparse data.
What carries the argument
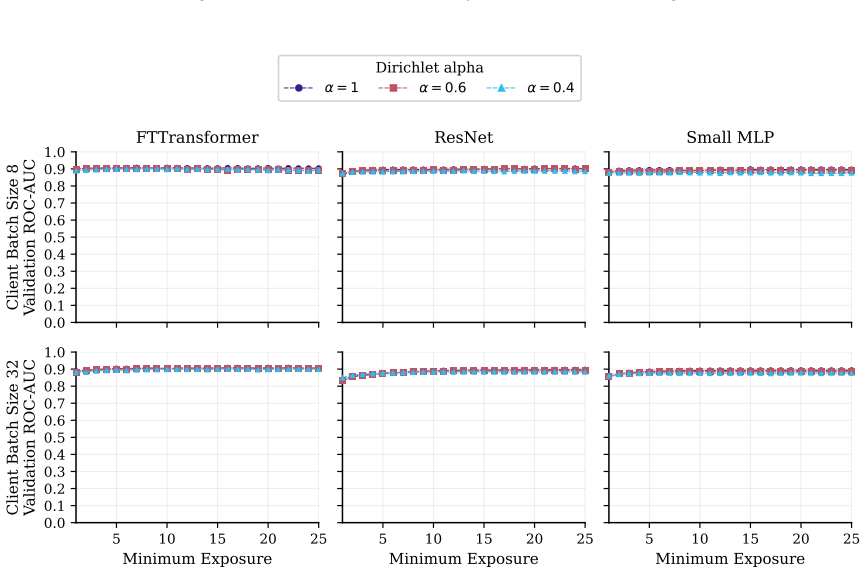
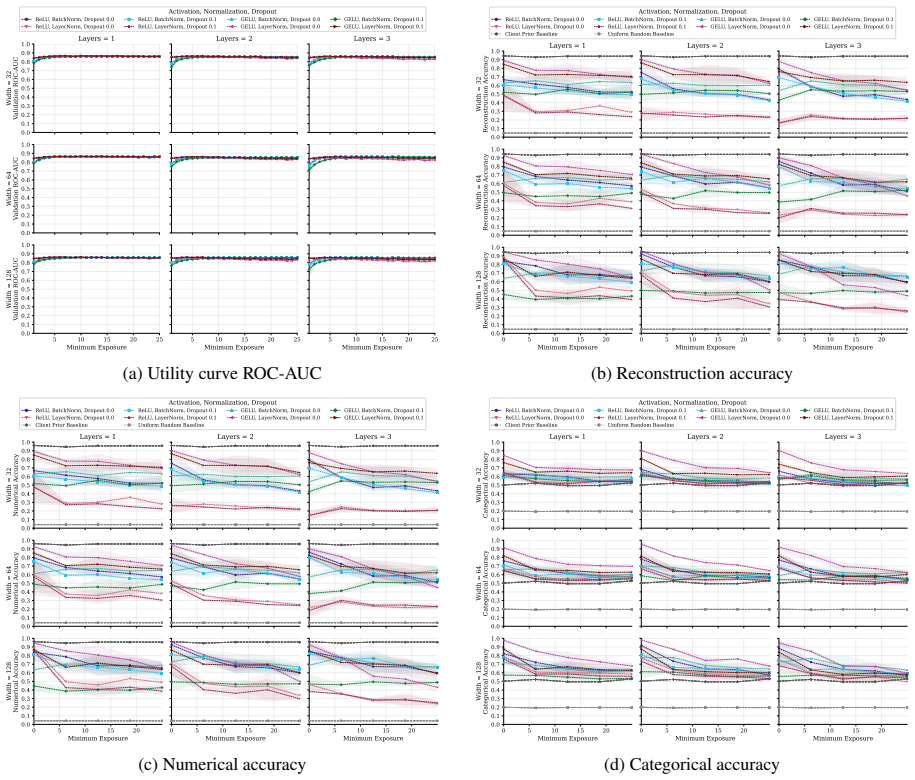
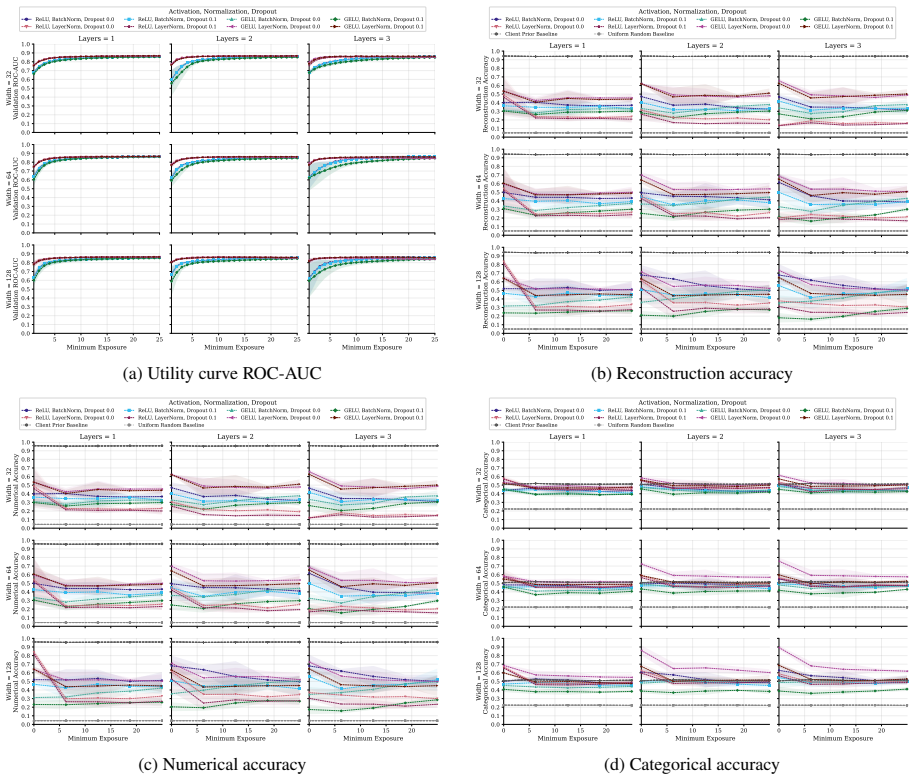
Exposure-aligned evaluation protocol that compares attacked models after matched client data exposure, together with separate tracking of numerical versus categorical recovery, exact match rate, and baseline recoverability across MLP, ResNet, and FT-Transformer architectures.
If this is right
- Small client batches remain the most vulnerable setting across tasks and protocols.
- FT-Transformer reduces reconstruction success relative to one-hot MLP baselines under matched exposure.
- Exact match rate plus baseline comparisons are required to judge whether full records are recovered in sparse data.
- Architecture choice can be treated as a tunable privacy lever alongside batch size and aggregation strength.
Where Pith is reading between the lines
- Practitioners could add architecture search to the existing trade-off between accuracy and privacy leakage.
- Sparse medical datasets may require even stricter metrics than those used here to certify record-level privacy.
- The same exposure-aligned comparison method could be applied to other data modalities to test whether architecture effects generalize.
Load-bearing premise
The chosen datasets, attacker assumptions, and exposure-aligned protocol accurately reflect realistic tabular FL deployments and threat models in privacy-sensitive domains.
What would settle it
An experiment on a new tabular dataset with similar sparsity showing that FT-Transformer is no harder to invert than MLP under the same exposure-aligned protocol, or that aggregate accuracy predicts exact match rate without needing separate baselines.
Figures
read the original abstract
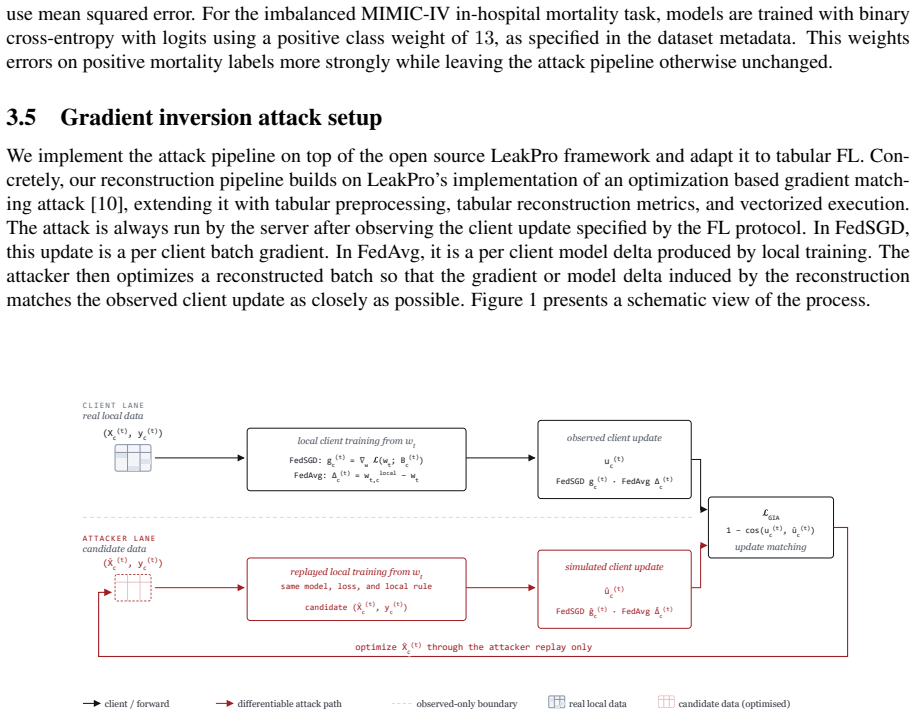
Federated learning (FL) enables multiple data holders to train machine learning models collaboratively without centralizing raw data, making it useful in privacy sensitive domains such as healthcare and institutional data sharing. FL keeps data local to clients while communicating only model updates, such as gradients or model deltas. Nevertheless, these updates can expose private client data through gradient inversion attacks (GIAs). We study this risk for tabular FL under an honest-but-curious server threat model across FL protocols, client batch sizes, training stages, attacker assumptions, model architectures, and binary classification, multiclass classification, and regression tasks. We use MIMIC-IV and complementary benchmark datasets. Our evaluation distinguishes numerical and categorical recovery, baseline recoverability, feature level recovery, and exact match rate (EMR). We evaluate FedSGD gradients and FedAvg model deltas with an exposure aligned protocol, comparing attacked models after matched client data exposure rather than matched communication rounds. We compare multilayer perceptron (MLP), ResNet, and FT-Transformer models, and isolate architecture effects through an MLP grid over width, depth, activation, normalization, and dropout. The results show that small client batches and updates representing few distinct records are most vulnerable. Larger local batches and stronger aggregation reduce reconstruction but do not eliminate leakage. FT-Transformer is consistently harder to invert than one-hot baselines, while reconstructability also varies substantially within the MLP family. These findings identify architecture as a practical privacy variable in tabular FL. We also show that aggregate reconstruction accuracy can overstate complete record recovery in sparse data, making EMR and baseline comparisons essential.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper empirically profiles the risk of gradient inversion attacks (GIAs) in tabular federated learning under an honest-but-curious server. It evaluates leakage across FedSGD/FedAvg protocols, client batch sizes, training stages, attacker assumptions, and tasks (binary/multiclass classification, regression) on MIMIC-IV and benchmark datasets. Architectures compared include MLP, ResNet, and FT-Transformer, with an MLP hyperparameter grid to isolate effects. Key findings are that small batches and low-record updates are most vulnerable, FT-Transformer shows lower reconstructability than one-hot baselines, reconstructability varies within the MLP family, and exact match rate (EMR) plus baseline comparisons are needed because aggregate accuracy can overstate full record recovery in sparse data. The work concludes that architecture is a practical privacy variable in tabular FL.
Significance. If the central empirical comparisons hold after addressing attack equivalence, the results would establish model architecture as a controllable factor for reducing gradient leakage in tabular FL deployments, particularly relevant for healthcare (MIMIC-IV) and other privacy-sensitive tabular domains. The broad coverage across protocols, batch sizes, stages, and tasks, combined with the distinction between numerical/categorical recovery and the emphasis on EMR over aggregate metrics, provides actionable guidance beyond prior GIA studies focused on images or dense models. The isolation of architecture effects via the MLP grid is a strength for interpretability.
major comments (1)
- [Abstract / Experimental Protocol] Abstract and experimental protocol: the central claim that 'FT-Transformer is consistently harder to invert than one-hot baselines' and that 'architecture [is] a practical privacy variable' rests on direct comparability of GIA success rates. The manuscript provides no indication that the attack implementation was adapted or validated for equivalence across architectures; FT-Transformer’s feature tokenization, attention, and embedding layers produce qualitatively different gradient structures than dense MLPs, so observed differences could arise from attack mismatch rather than intrinsic privacy properties. This is load-bearing for the architecture conclusion and requires explicit methods detail or ablation showing attack parity.
minor comments (1)
- [Abstract] The abstract states that models are compared 'after matched client data exposure rather than matched communication rounds,' but the precise definition of exposure alignment and how it is enforced across FedSGD and FedAvg is not visible in the provided summary; a short clarifying paragraph or pseudocode would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the thorough review and for highlighting the importance of attack equivalence in our architecture comparisons. We address the major comment below and will revise the manuscript to strengthen the experimental protocol description.
read point-by-point responses
-
Referee: [Abstract / Experimental Protocol] Abstract and experimental protocol: the central claim that 'FT-Transformer is consistently harder to invert than one-hot baselines' and that 'architecture [is] a practical privacy variable' rests on direct comparability of GIA success rates. The manuscript provides no indication that the attack implementation was adapted or validated for equivalence across architectures; FT-Transformer’s feature tokenization, attention, and embedding layers produce qualitatively different gradient structures than dense MLPs, so observed differences could arise from attack mismatch rather than intrinsic privacy properties. This is load-bearing for the architecture conclusion and requires explicit methods detail or ablation showing attack parity.
Authors: We agree that explicit validation of attack equivalence is necessary to support the architecture-related claims. The GIA implementation follows a standard optimization-based inversion approach (minimizing reconstruction loss on received gradients) applied uniformly to all models without architecture-specific modifications to the attack objective or optimizer. However, the manuscript does not currently detail how the attack was configured or validated across differing gradient structures. In the revision we will add a dedicated subsection in Methods describing the attack implementation, hyperparameter selection process, and any handling of embeddings/attention gradients for FT-Transformer. We will also include a new ablation that applies the attack to synthetic gradient inputs of matched dimensionality and structure to confirm comparable attack efficacy before architecture comparisons. These changes will be made in the next version. revision: yes
Circularity Check
Empirical evaluation with no derivations or self-referential predictions
full rationale
The paper is a purely empirical comparison study. It reports direct measurements of reconstruction accuracy (EMR, feature-level recovery, etc.) on MIMIC-IV and benchmark datasets under specified FL protocols and attacker assumptions. No equations, derivations, fitted parameters, or predictions are claimed; results are obtained by running existing GIA implementations against trained models. No self-citation chains, uniqueness theorems, or ansatzes appear in the provided text. The central claim that architecture affects privacy is supported by experimental variation across MLP, ResNet, and FT-Transformer, not by any reduction to inputs by construction. This matches the default expectation for non-circular empirical work.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Honest-but-curious server threat model is the appropriate setting for evaluating gradient inversion risk in this tabular FL context.
- domain assumption MIMIC-IV and the complementary benchmark datasets are representative of real-world tabular data distributions encountered in privacy-sensitive FL applications.
Reference graph
Works this paper leans on
-
[1]
Brendan McMahan, Eider Moore, Daniel Ramage, Seth Hampson, and Blaise Ag ¨uera y Arcas
H. Brendan McMahan, Eider Moore, Daniel Ramage, Seth Hampson, and Blaise Ag ¨uera y Arcas. Communication-efficient learning of deep networks from decentralized data. In Aarti Singh and Jerry Zhu, editors,Proceedings of the 20th International Conference on Artificial Intelligence and Statistics, volume 54 ofProceedings of Machine Learning Research, pages 1...
2017
-
[2]
Brendan McMahan, Brendan Avent, Aur ´elien Bellet, Mehdi Bennis, Arjun Nitin Bhagoji, Kallista Bonawitz, Zachary Charles, Graham Cormode, Rachel Cummings, Rafael G
Peter Kairouz, H. Brendan McMahan, Brendan Avent, Aur ´elien Bellet, Mehdi Bennis, Arjun Nitin Bhagoji, Kallista Bonawitz, Zachary Charles, Graham Cormode, Rachel Cummings, Rafael G. L. D’Oliveira, Hu- bert Eichner, Salim El Rouayheb, David Evans, Josh Gardner, Zachary Garrett, Adri`a Gasc´on, Badih Ghazi, Phillip B. Gibbons, Marco Gruteser, Zaid Harchaou...
2021
-
[3]
Federated machine learning: Concept and appli- cations.ACM Transactions on Intelligent Systems and Technology, 10(2), January 2019
Qiang Yang, Yang Liu, Tianjian Chen, and Yongxin Tong. Federated machine learning: Concept and appli- cations.ACM Transactions on Intelligent Systems and Technology, 10(2), January 2019
2019
-
[4]
Federated learning for healthcare: Systematic review and architecture proposal.ACM Transactions on Intelligent Systems and Technology, 13(4), May 2022
Rodolfo Stoffel Antunes, Cristiano Andr ´e da Costa, Arne K ¨uderle, Imrana Abdullahi Yari, and Bj ¨orn Es- kofier. Federated learning for healthcare: Systematic review and architecture proposal.ACM Transactions on Intelligent Systems and Technology, 13(4), May 2022
2022
-
[5]
Glicksberg, Chang Su, Peter Walker, Jiang Bian, and Fei Wang
Jie Xu, Benjamin S. Glicksberg, Chang Su, Peter Walker, Jiang Bian, and Fei Wang. Federated learning for healthcare informatics.Journal of Healthcare Informatics Research, 5(1):1–19, 2021
2021
-
[6]
Akhil Vaid, Suraj K Jaladanki, Jie Xu, Shelly Teng, Arvind Kumar, Samuel Lee, Sulaiman Somani, Ishan Paranjpe, Jessica K De Freitas, Tingyi Wanyan, Kipp W Johnson, Mesude Bicak, Eyal Klang, Young Joon Kwon, Anthony Costa, Shan Zhao, Riccardo Miotto, Alexander W Charney, Erwin B¨ottinger, Zahi A Fayad, Girish N Nadkarni, Fei Wang, and Benjamin S Glicksberg...
2021
-
[7]
An adaptive federated learning framework for clinical risk prediction with electronic health records from multiple hospitals.Patterns, 5(1):100898, 2024
Weishen Pan, Zhenxing Xu, Suraj Rajendran, and Fei Wang. An adaptive federated learning framework for clinical risk prediction with electronic health records from multiple hospitals.Patterns, 5(1):100898, 2024
2024
-
[8]
Deep leakage from gradients
Ligeng Zhu, Zhijian Liu, and Song Han. Deep leakage from gradients. In H. Wallach, H. Larochelle, A. Beygelzimer, F. d'Alch´e-Buc, E. Fox, and R. Garnett, editors,Advances in Neural Information Processing Systems, volume 32. Curran Associates, Inc., 2019
2019
-
[9]
idlg: Improved deep leakage from gradients,
Bo Zhao, Konda Reddy Mopuri, and Hakan Bilen. iDLG: Improved deep leakage from gradients. arXiv preprint arXiv:2001.02610, 2020
-
[10]
Inverting gradients - how easy is it to break privacy in federated learning? In H
Jonas Geiping, Hartmut Bauermeister, Hannah Dr ¨oge, and Michael Moeller. Inverting gradients - how easy is it to break privacy in federated learning? In H. Larochelle, M. Ranzato, R. Hadsell, M.F. Balcan, and H. Lin, editors,Advances in Neural Information Processing Systems, volume 33, pages 16937–16947. Curran Associates, Inc., 2020
2020
-
[11]
Evaluating gradient inversion attacks and defenses in federated learning
Yangsibo Huang, Samyak Gupta, Zhao Song, Kai Li, and Sanjeev Arora. Evaluating gradient inversion attacks and defenses in federated learning. In M. Ranzato, A. Beygelzimer, Y . Dauphin, P.S. Liang, and J. Wortman Vaughan, editors,Advances in Neural Information Processing Systems, volume 34, pages 7232–
-
[12]
Curran Associates, Inc., 2021
2021
-
[13]
TabLeak: Tabular data leakage in federated learning
Mark Vero, Mislav Balunovi ´c, Dimitar Iliev Dimitrov, and Martin Vechev. TabLeak: Tabular data leakage in federated learning. In Andreas Krause, Emma Brunskill, Kyunghyun Cho, Barbara Engelhardt, Sivan Sabato, and Jonathan Scarlett, editors,Proceedings of the 40th International Conference on Machine Learn- ing, volume 202 ofProceedings of Machine Learnin...
2023
-
[14]
Alvarez, Jan Kautz, and Pavlo Molchanov
Hongxu Yin, Arun Mallya, Arash Vahdat, Jose M. Alvarez, Jan Kautz, and Pavlo Molchanov. See through gradients: Image batch recovery via GradInversion. In2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 16332–16341, 2021
2021
-
[15]
GradViT: Gradient inversion of vision transformers
Ali Hatamizadeh, Hongxu Yin, Holger Roth, Wenqi Li, Jan Kautz, Daguang Xu, and Pavlo Molchanov. GradViT: Gradient inversion of vision transformers. In2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 10011–10020, 2022
2022
-
[16]
Revisiting deep learning models for tabular data
Yury Gorishniy, Ivan Rubachev, Valentin Khrulkov, and Artem Babenko. Revisiting deep learning models for tabular data. In M. Ranzato, A. Beygelzimer, Y . Dauphin, P.S. Liang, and J. Wortman Vaughan, editors, Advances in Neural Information Processing Systems, volume 34, pages 18932–18943. Curran Associates, Inc., 2021
2021
-
[17]
Deep neural networks and tabular data: A survey.IEEE Transactions on Neural Networks and Learning Systems, 35(6):7499–7519, 2024
Vadim Borisov, Tobias Leemann, Kathrin Seßler, Johannes Haug, Martin Pawelczyk, and Gjergji Kasneci. Deep neural networks and tabular data: A survey.IEEE Transactions on Neural Networks and Learning Systems, 35(6):7499–7519, 2024
2024
-
[18]
A comprehensive benchmark of machine and deep learning models on structured data for regression and classification.Neurocomputing, 655:131337, 2025
Assaf Shmuel, Oren Glickman, and Teddy Lazebnik. A comprehensive benchmark of machine and deep learning models on structured data for regression and classification.Neurocomputing, 655:131337, 2025
2025
-
[19]
Arik and Tomas Pfister
Sercan ¨O. Arik and Tomas Pfister. TabNet: Attentive interpretable tabular learning.Proceedings of the AAAI Conference on Artificial Intelligence, 35(8):6679–6687, May 2021
2021
-
[20]
TabTransformer: Tabular Data Modeling Using Contextual Embeddings
Xin Huang, Ashish Khetan, Milan Cvitkovic, and Zohar Karnin. TabTransformer: Tabular data modeling using contextual embeddings. arXiv preprint arXiv:2012.06678, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2012
-
[21]
A federated learning benchmark on tabular data: Comparing tree-based models and neural networks
William Lindskog and Christian Prehofer. A federated learning benchmark on tabular data: Comparing tree-based models and neural networks. In2023 Eighth International Conference on Fog and Mobile Edge Computing (FMEC), pages 239–246, 2023
2023
-
[22]
Federated learning for tabular data using TabNet: A vehicular use- case
William Lindskog and Christian Prehofer. Federated learning for tabular data using TabNet: A vehicular use- case. In2022 IEEE 18th International Conference on Intelligent Computer Communication and Processing (ICCP), pages 105–111, 2022
2022
-
[23]
Brendan McMahan, Sarvar Patel, Daniel Ramage, Aaron Segal, and Karn Seth
Keith Bonawitz, Vladimir Ivanov, Ben Kreuter, Antonio Marcedone, H. Brendan McMahan, Sarvar Patel, Daniel Ramage, Aaron Segal, and Karn Seth. Practical secure aggregation for privacy-preserving machine learning. InProceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, CCS ’17, pages 1175–1191, New York, NY , USA, 2017. Asso...
2017
-
[24]
Data leakage in feder- ated averaging.Transactions on Machine Learning Research, 2022
Dimitar Iliev Dimitrov, Mislav Balunovic, Nikola Konstantinov, and Martin Vechev. Data leakage in feder- ated averaging.Transactions on Machine Learning Research, 2022
2022
-
[25]
Brendan McMahan, Ilya Mironov, Kunal Talwar, and Li Zhang
Martin Abadi, Andy Chu, Ian Goodfellow, H. Brendan McMahan, Ilya Mironov, Kunal Talwar, and Li Zhang. Deep learning with differential privacy. InProceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, CCS ’16, pages 308–318, New York, NY , USA, 2016. Association for Com- puting Machinery
2016
-
[26]
Brendan McMahan, Daniel Ramage, Kunal Talwar, and Li Zhang
H. Brendan McMahan, Daniel Ramage, Kunal Talwar, and Li Zhang. Learning differentially private recurrent language models. InInternational Conference on Learning Representations, 2018
2018
-
[27]
Blaschko
Junyi Zhu and Matthew B. Blaschko. R-GAP: Recursive gradient attack on privacy. InInternational Con- ference on Learning Representations, 2021
2021
-
[28]
Dropout is not all you need to prevent gradient leakage
Daniel Scheliga, Patrick Maeder, and Marco Seeland. Dropout is not all you need to prevent gradient leakage. Proceedings of the AAAI Conference on Artificial Intelligence, 37(8):9733–9741, June 2023. 24
2023
-
[29]
Ali Hatamizadeh, Hongxu Yin, Pavlo Molchanov, Andriy Myronenko, Wenqi Li, Prerna Dogra, Andrew Feng, Mona G Flores, Jan Kautz, Daguang Xu, and Holger R. Roth. Do gradient inversion attacks make federated learning unsafe?IEEE Transactions on Medical Imaging, 42(7):2044–2056, 2023
2044
-
[30]
Prac- tical feasibility of gradient inversion attacks in federated learning
Viktor Valadi, Mattias ˚Akesson, Johan ¨Ostman, Fazeleh Hoseini, Salman Toor, and Andreas Hellander. Prac- tical feasibility of gradient inversion attacks in federated learning. arXiv preprint arXiv:2508.19819, 2026
-
[31]
LAMP: Extracting text from gradients with language model priors
Mislav Balunovi ´c, Dimitar Dimitrov, Nikola Jovanovi ´c, and Martin Vechev. LAMP: Extracting text from gradients with language model priors. In S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, editors,Advances in Neural Information Processing Systems, volume 35, pages 7641–7654. Curran Associates, Inc., 2022
2022
-
[32]
Adult [data set], 1996
Barry Becker and Ronny Kohavi. Adult [data set], 1996
1996
-
[33]
Pedregosa, G
F. Pedregosa, G. Varoquaux, A. Gramfort, V . Michel, B. Thirion, O. Grisel, M. Blondel, P. Prettenhofer, R. Weiss, V . Dubourg, J. Vanderplas, A. Passos, D. Cournapeau, M. Brucher, M. Perrot, and E. Duchesnay. Scikit-learn: Machine learning in Python.Journal of Machine Learning Research, 12:2825–2830, 2011
2011
-
[34]
Kelley Pace and Ronald Barry
R. Kelley Pace and Ronald Barry. Sparse spatial autoregressions.Statistics & Probability Letters, 33(3):291– 297, 1997
1997
-
[35]
MIMIC-IV [data set].PhysioNet, October 2024
Alistair Johnson, Lucas Bulgarelli, Tom Pollard, Brian Gow, Benjamin Moody, Steven Horng, Leo Anthony Celi, and Roger Mark. MIMIC-IV [data set].PhysioNet, October 2024. Version 3.1
2024
-
[36]
Kingma and Jimmy Ba
Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization. In Yoshua Bengio and Yann LeCun, editors,3rd International Conference on Learning Representations, ICLR 2015, 2015
2015
-
[37]
H. W. Kuhn. The hungarian method for the assignment problem.Naval Research Logistics Quarterly, 2(1-2):83–97, 1955. A Benchmark Robustness and Sensitivity Analyses The benchmark robustness results support the main tabular FL analysis by extending the main attack point sum- mary tables with exposure trajectories, exact row recovery summaries, fixed batch c...
1955
-
[38]
Scores are reported as mean±standard deviation across seeds at the best validation checkpoint for each configuration. Rank Width Layers Normalization Activation Dropout Val ROC-AUC 1 32 1 LayerNorm ReLU 0.1 0.868±0.005 2 32 2 LayerNorm ReLU 0.1 0.868±0.005 3 32 1 LayerNorm GELU 0.1 0.867±0.005 4 32 2 LayerNorm GELU 0.1 0.867±0.005 5 64 1 LayerNorm GELU 0....
-
[39]
This setting weakens the main label known attacker by replacing the true labels with dummy labels while keeping the same observed client updates, model families, and reconstruction pipeline. Table 51: Label unknown reconstruction accuracy at the initialized attack point and final attack point for MIMIC- IV under FedSGD, reported for the completed batch si...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.