Decoupled Residual Denoising Diffusion Models for Unified and Data Efficient Image-to-Image Translation
Pith reviewed 2026-06-28 17:16 UTC · model grok-4.3
The pith
Decoupling diffusion into separate noise harmonization and residual mapping stages enables unified image-to-image translation with less paired data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
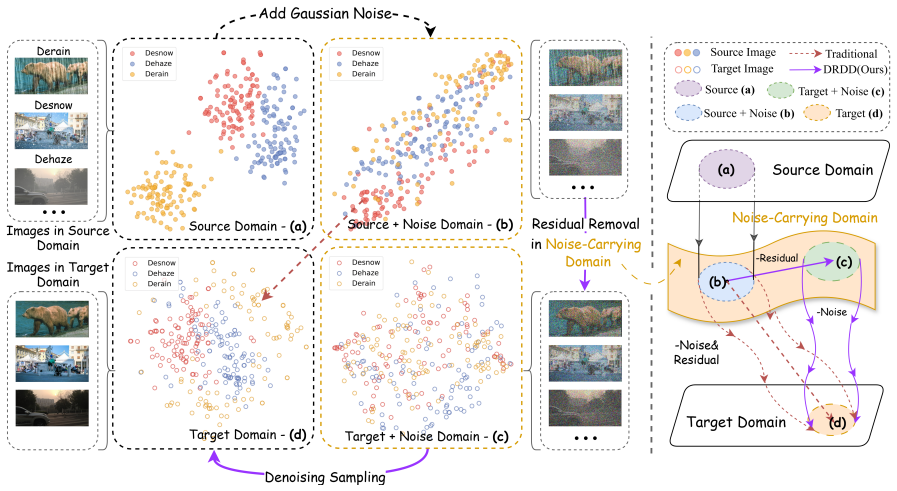
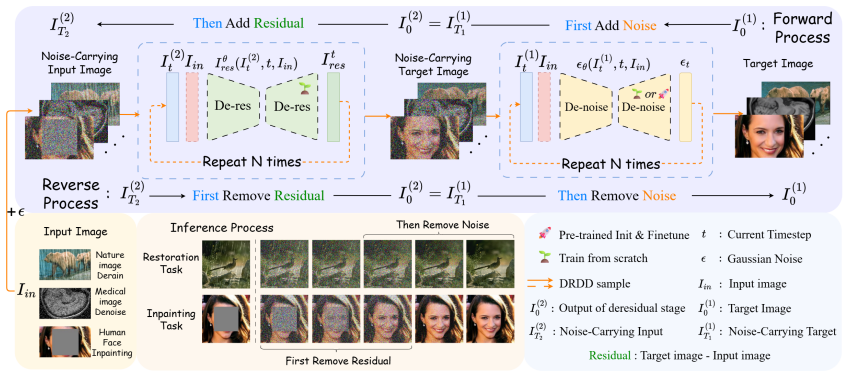
DRDD decouples the diffusion process into two sequential and independent diffusion stages: (1) a stochastic noise diffusion for domain harmonization and manifold lifting, and (2) a deterministic residual diffusion that learns the core semantic mapping entirely within the fixed-noise domain. This decoupling preserves harmonization and manifold lifting effects throughout the transformation, substantially simplifying the learning of unified mappings across diverse tasks and domains. The noise diffusion stage is trained exclusively on abundant, unpaired target-domain images, greatly improving data efficiency.
What carries the argument
Two-stage decoupled diffusion consisting of stochastic noise diffusion for domain harmonization followed by deterministic residual diffusion for semantic mapping inside the fixed-noise domain.
If this is right
- Preserves domain harmonization and manifold lifting effects throughout the transformation rather than eroding them.
- Simplifies learning of a single unified mapping that works across many different tasks and domains.
- Improves data efficiency because the noise stage trains on unpaired target images only.
- Remains compatible with mainstream diffusion models while delivering robust results under limited paired data.
Where Pith is reading between the lines
- The same split might help other generative models where coupled noise removal erodes useful alignment between distributions.
- Applying the method to highly dissimilar domains such as medical and natural images could test how far the unpaired harmonization effect extends.
- Operating the residual stage inside a fixed-noise space could enable more controlled editing or interpolation between domains.
Load-bearing premise
The stochastic noise diffusion stage trained only on unpaired target-domain images will produce and sustain domain harmonization that coupled models lose, without the residual stage interfering or requiring paired data.
What would settle it
Measure whether feature distributions between source and target domains remain better aligned in the intermediate fixed-noise space of the decoupled model than in a standard coupled diffusion model; absence of that alignment improvement would falsify the preserved-harmonization claim.
Figures




read the original abstract
We propose Decoupled Residual Denoising Diffusion models (DRDD) for unified and data-efficient image-to-image (I2I) translation. While diffusion models have advanced I2I translation in terms of quality and diversity, we uncover a previously under-explored property in diffusion models. Crucially, beyond its conventional role of manifold lifting (i.e., moving data off low-dimensional manifolds), injecting Gaussian noise facilitates domain harmonization by implicitly aligning feature distributions across domains, a property particularly advantageous for unified I2I translation. However, existing diffusion models prematurely erode this harmonization effect, as noise and residuals are simultaneously removed in a single coupled diffusion process. To address this, DRDD decouples the diffusion process into two sequential and independent diffusion stages: (1) a stochastic noise diffusion for domain harmonization and manifold lifting, and (2) a deterministic residual diffusion that learns the core semantic mapping entirely within the fixed-noise domain. This decoupling preserves harmonization and manifold lifting effects throughout the transformation, substantially simplifying the learning of unified mappings across diverse tasks and domains. Notably, the noise diffusion stage is trained exclusively on abundant, unpaired target-domain images, greatly improving data efficiency. Comprehensive theoretical and empirical analysis demonstrates that DRDD is broadly compatible with mainstream diffusion models and consistently delivers robust, unified I2I translation, even under limited paired data. Our code is available at https://github.com/HKU-HealthAI/DRDD.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Decoupled Residual Denoising Diffusion Models (DRDD) for unified and data-efficient image-to-image translation. It decouples the diffusion process into two sequential stages: (1) a stochastic noise diffusion stage trained exclusively on unpaired target-domain images to achieve domain harmonization and manifold lifting via Gaussian noise injection, and (2) a deterministic residual diffusion stage that learns the semantic mapping entirely within the fixed-noise domain. This is claimed to preserve the harmonization effect that existing coupled diffusion models erode, enabling robust unified I2I across diverse tasks even with limited paired data, with compatibility to mainstream diffusion models supported by theoretical and empirical analysis.
Significance. If the decoupling and the uni-domain training of the noise stage indeed preserve cross-domain alignment without paired data, the method could meaningfully improve data efficiency for unified I2I translation while maintaining quality and diversity advantages of diffusion models.
major comments (1)
- [Abstract] Abstract: the central claim that a stochastic noise diffusion model trained exclusively on unpaired target-domain images produces domain harmonization (via implicit alignment of feature distributions) when applied to source images lacks a concrete derivation or mechanism showing how this occurs without source exposure or paired data; this assumption is load-bearing for both the preservation of harmonization and the data-efficiency claims, and must be explicitly justified to support the decoupling benefit over coupled models.
minor comments (1)
- The abstract states that 'comprehensive theoretical and empirical analysis demonstrates' the claims, but the manuscript should explicitly reference the relevant sections, theorems, or figures that address the cross-domain alignment mechanism for source inputs.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on our manuscript. We address the single major comment below, providing the requested justification from the full paper while noting a minor clarification we can make to the abstract.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that a stochastic noise diffusion model trained exclusively on unpaired target-domain images produces domain harmonization (via implicit alignment of feature distributions) when applied to source images lacks a concrete derivation or mechanism showing how this occurs without source exposure or paired data; this assumption is load-bearing for both the preservation of harmonization and the data-efficiency claims, and must be explicitly justified to support the decoupling benefit over coupled models.
Authors: The full manuscript justifies this mechanism in Section 3.2. The stochastic noise diffusion stage is trained only on unpaired target images to learn the reverse process from the Gaussian distribution; because Gaussian noise addition is a domain-agnostic operation that maps any input image (source or target) onto the same high-dimensional isotropic Gaussian manifold, the resulting latent representations become implicitly aligned without requiring source-domain data or paired examples during training. This alignment is formalized in Equations (4)–(7), which show that the KL divergence between the noised source and target distributions converges to zero as noise variance increases, independent of the original domain statistics. The noise model is never exposed to source images, yet the harmonization effect transfers because the target distribution of the diffusion process is universal. Empirical confirmation appears in Section 4.2 (feature distribution distances before/after noise injection) and Figure 3. We agree the abstract is concise and will add a one-sentence reference to this derivation; the body already contains the requested concrete justification, which underpins both the decoupling benefit and the data-efficiency result. revision: partial
Circularity Check
No significant circularity; derivation is self-contained design proposal
full rationale
The paper introduces DRDD as a decoupling of existing diffusion processes into stochastic noise (trained on unpaired target images) and deterministic residual stages. The claimed domain harmonization property is presented as an uncovered empirical/theoretical observation rather than derived from equations that reduce to the inputs by construction. No self-definitional loops, fitted parameters renamed as predictions, or load-bearing self-citations appear in the abstract or described chain; the method builds on mainstream diffusion models with an independent architectural separation whose validity is asserted via separate analysis.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Injecting Gaussian noise facilitates domain harmonization by implicitly aligning feature distributions across domains
Reference graph
Works this paper leans on
-
[1]
A high-quality denoising dataset for smartphone cameras
Abdelrahman Abdelhamed, Stephen Lin, and Michael S Brown. A high-quality denoising dataset for smartphone cameras. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 1692–1700, 2018. 8
2018
-
[2]
Contour detection and hierarchical image segmen- tation.IEEE transactions on pattern analysis and machine intelligence, 33(5):898–916, 2010
Pablo Arbelaez, Michael Maire, Charless Fowlkes, and Jiten- dra Malik. Contour detection and hierarchical image segmen- tation.IEEE transactions on pattern analysis and machine intelligence, 33(5):898–916, 2010. 8, 4, 5, 6, 7, 10
2010
-
[3]
Cold diffusion: Inverting arbitrary image transforms without noise.arXiv preprint arXiv:2208.09392,
Arpit Bansal, Eitan Borgnia, Hong-Min Chu, Jie S Li, Hamid Kazemi, Furong Huang, Micah Goldblum, Jonas Geiping, and Tom Goldstein. Cold diffusion: Inverting arbitrary image transforms without noise.arXiv preprint arXiv:2208.09392,
-
[4]
Springer, 2006
Christopher M Bishop and Nasser M Nasrabadi.Pattern recognition and machine learning. Springer, 2006. 2
2006
-
[5]
Gated-gan: Adversarial gated networks for multi-collection style transfer.IEEE Transactions on Image Processing, 28(2):546–560, 2019
Xinyuan Chen, Chang Xu, Xiaokang Yang, Li Song, and Dacheng Tao. Gated-gan: Adversarial gated networks for multi-collection style transfer.IEEE Transactions on Image Processing, 28(2):546–560, 2019. 1
2019
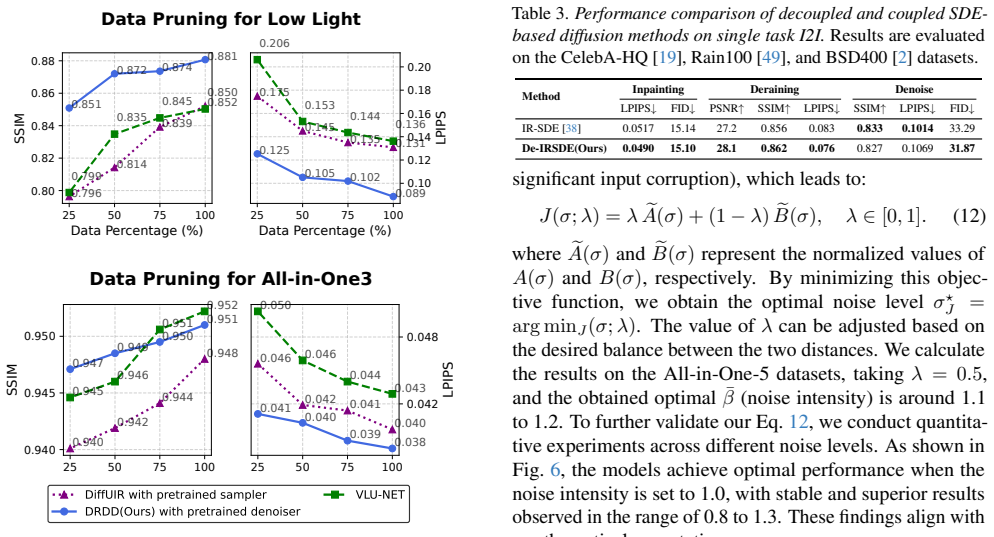
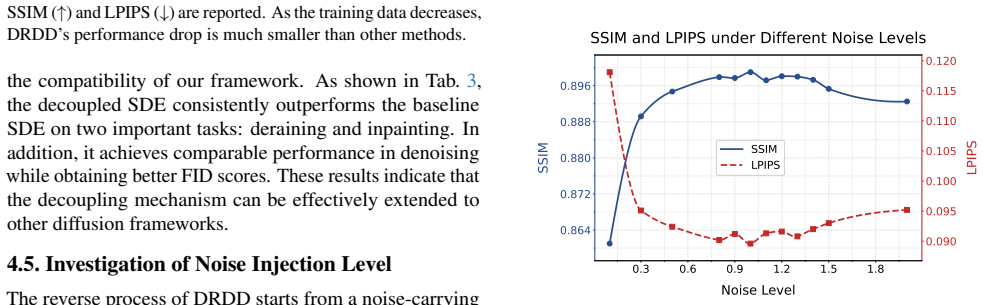
-
[6]
Ilvr: Conditioning method for denoising diffusion probabilistic models, 2021
Jooyoung Choi, Sungwon Kim, Yonghyun Jeong, Youngjune Gwon, and Sungroh Yoon. Ilvr: Conditioning method for denoising diffusion probabilistic models, 2021. 1, 3
2021
-
[7]
Design and construction of a realistic digital brain phantom
D Louis Collins, Alex P Zijdenbos, Vasken Kollokian, John G Sled, Noor Jehan Kabani, Colin J Holmes, and Alan C Evans. Design and construction of a realistic digital brain phantom. IEEE transactions on medical imaging, 17(3):463–468, 2002. 7, 5
2002
-
[8]
In- structir: High-quality image restoration following human instructions
Marcos V Conde, Gregor Geigle, and Radu Timofte. In- structir: High-quality image restoration following human instructions. InProceedings of the European Conference on Computer Vision (ECCV), 2024. 5, 6, 8
2024
-
[9]
AdaIR: Adap- tive all-in-one image restoration via frequency mining and modulation
Yuning Cui, Syed Waqas Zamir, Salman Khan, Alois Knoll, Mubarak Shah, and Fahad Shahbaz Khan. AdaIR: Adap- tive all-in-one image restoration via frequency mining and modulation. InThe Thirteenth International Conference on Learning Representations, 2025. 6, 7, 9
2025
-
[10]
Inversion by direct iteration: An alternative to denoising diffusion for image restoration, 2024
Mauricio Delbracio and Peyman Milanfar. Inversion by direct iteration: An alternative to denoising diffusion for image restoration, 2024. 1, 2, 3
2024
-
[11]
Imagenet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In2009 IEEE Conference on Computer Vision and Pattern Recognition, pages 248–255, 2009. 7
2009
-
[12]
Diffusion models beat gans on image synthesis.Advances in neural information processing systems, 34:8780–8794, 2021
Prafulla Dhariwal and Alexander Nichol. Diffusion models beat gans on image synthesis.Advances in neural information processing systems, 34:8780–8794, 2021. 1, 6, 4
2021
-
[13]
Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio
Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial networks, 2014. 1
2014
-
[14]
Image inpaint- ing via conditional texture and structure dual generation
Xiefan Guo, Hongyu Yang, and Di Huang. Image inpaint- ing via conditional texture and structure dual generation. In Proceedings of the IEEE/CVF international conference on computer vision, pages 14134–14143, 2021. 7
2021
-
[15]
Onerestore: A universal restoration frame- work for composite degradation
Yu Guo, Yuan Gao, Yuxu Lu, Huilin Zhu, Ryan Wen Liu, and Shengfeng He. Onerestore: A universal restoration frame- work for composite degradation. InEuropean conference on computer vision, pages 255–272. Springer, 2024. 5, 6, 4
2024
-
[16]
Gans trained by a two time-scale update rule converge to a local nash equilibrium
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bern- hard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium. Advances in neural information processing systems, 30, 2017. 4
2017
-
[17]
Denoising diffu- sion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffu- sion probabilistic models. InAdvances in Neural Information Processing Systems, pages 6840–6851. Curran Associates, Inc., 2020. 1, 2, 3, 5
2020
-
[18]
Single image super-resolution from transformed self-exemplars
Jia-Bin Huang, Abhishek Singh, and Narendra Ahuja. Single image super-resolution from transformed self-exemplars. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2015. 6
2015
-
[19]
Progressive growing of GANs for improved quality, stabil- ity, and variation
Tero Karras, Timo Aila, Samuli Laine, and Jaakko Lehtinen. Progressive growing of GANs for improved quality, stabil- ity, and variation. InInternational Conference on Learning Representations, 2018. 5, 7, 8
2018
-
[20]
A style-based generator architecture for generative adversarial networks
Tero Karras, Samuli Laine, and Timo Aila. A style-based generator architecture for generative adversarial networks. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4401–4410, 2019. 5, 7, 10
2019
-
[21]
An extensible mri simulator for post-processing evaluation
Remi K-S Kwan, Alan C Evans, and G Bruce Pike. An extensible mri simulator for post-processing evaluation. In International conference on visualization in biomedical com- puting, pages 135–140. Springer, 1996. 7, 4, 5
1996
-
[22]
Mri simulation-based evaluation of image-processing and clas- sification methods.IEEE transactions on medical imaging, 18(11):1085–1097, 1999
RK-S Kwan, Alan C Evans, and G Bruce Pike. Mri simulation-based evaluation of image-processing and clas- sification methods.IEEE transactions on medical imaging, 18(11):1085–1097, 1999. 7, 5
1999
-
[23]
The principles of diffusion models, 2025
Chieh-Hsin Lai, Yang Song, Dongjun Kim, Yuki Mitsufuji, and Stefano Ermon. The principles of diffusion models, 2025. 1, 3
2025
-
[24]
Photo-realistic single image super-resolution using a generative adversarial network, 2017
Christian Ledig, Lucas Theis, Ferenc Huszar, Jose Caballero, Andrew Cunningham, Alejandro Acosta, Andrew Aitken, Alykhan Tejani, Johannes Totz, Zehan Wang, and Wenzhe Shi. Photo-realistic single image super-resolution using a generative adversarial network, 2017. 3
2017
-
[25]
Contrast en- hancement based on layered difference representation of 2d histograms.IEEE transactions on image processing, 22(12): 5372–5384, 2013
Chulwoo Lee, Chul Lee, and Chang-Su Kim. Contrast en- hancement based on layered difference representation of 2d histograms.IEEE transactions on image processing, 22(12): 5372–5384, 2013. 8
2013
-
[26]
Benchmarking single- image dehazing and beyond.IEEE Transactions on Image Processing, 28(1):492–505, 2019
Boyi Li, Wenqi Ren, Dengpan Fu, Dacheng Tao, Dan Feng, Wenjun Zeng, and Zhangyang Wang. Benchmarking single- image dehazing and beyond.IEEE Transactions on Image Processing, 28(1):492–505, 2019. 4, 10
2019
-
[27]
All-in-one image restoration for unknown corruption
Boyun Li, Xiao Liu, Peng Hu, Zhongqin Wu, Jiancheng Lv, and Xi Peng. All-in-one image restoration for unknown corruption. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 17452–17462,
-
[28]
Foundir: Unleashing million-scale training data to advance foundation models for image restoration
Hao Li, Xiang Chen, Jiangxin Dong, Jinhui Tang, and Jin- shan Pan. Foundir: Unleashing million-scale training data to advance foundation models for image restoration. InICCV,
-
[29]
Misf: Multi-level interactive siamese filtering for high-fidelity image inpainting
Xiaoguang Li, Qing Guo, Di Lin, Ping Li, Wei Feng, and Song Wang. Misf: Multi-level interactive siamese filtering for high-fidelity image inpainting. InProceedings of the IEEE/CVF conference on computer vision and pattern recog- nition, pages 1869–1878, 2022. 7
2022
-
[30]
Swinir: Image restoration using swin transformer
Jingyun Liang, Jiezhang Cao, Guolei Sun, Kai Zhang, Luc Van Gool, and Radu Timofte. Swinir: Image restoration using swin transformer. InProceedings of the IEEE/CVF international conference on computer vision, pages 1833– 1844, 2021. 3
2021
-
[31]
Flow Matching for Generative Modeling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling. arXiv preprint arXiv:2210.02747, 2022. 1
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[32]
Theodorou, Weili Nie, and Anima Anandkumar
Guan-Horng Liu, Arash Vahdat, De-An Huang, Evangelos A. Theodorou, Weili Nie, and Anima Anandkumar. I2sb: Image- to-image schr¨odinger bridge, 2023. 1, 2, 3
2023
-
[33]
Benchmarking low-light image enhance- ment and beyond.International Journal of Computer Vision, 129(4):1153–1184, 2021
Jiaying Liu, Dejia Xu, Wenhan Yang, Minhao Fan, and Haofeng Huang. Benchmarking low-light image enhance- ment and beyond.International Journal of Computer Vision, 129(4):1153–1184, 2021. 4
2021
-
[34]
Residual denoising diffusion models, 2024
Jiawei Liu, Qiang Wang, Huijie Fan, Yinong Wang, Yan- dong Tang, and Liangqiong Qu. Residual denoising diffusion models, 2024. 1, 2, 3, 6, 7, 9
2024
-
[35]
Transref: Multi-scale reference embedding transformer for reference-guided image inpainting.Neurocomputing, 632:129749, 2025
Taorong Liu, Liang Liao, Delin Chen, Jing Xiao, Zheng Wang, Chia-Wen Lin, and Shin’ichi Satoh. Transref: Multi-scale reference embedding transformer for reference-guided image inpainting.Neurocomputing, 632:129749, 2025. 7
2025
-
[36]
Flow straight and fast: Learning to generate and transfer data with rectified flow
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow. InProc. ICLR, 2023. 3
2023
-
[37]
Repaint: Inpainting using denoising diffusion probabilistic models, 2022
Andreas Lugmayr, Martin Danelljan, Andres Romero, Fisher Yu, Radu Timofte, and Luc Van Gool. Repaint: Inpainting using denoising diffusion probabilistic models, 2022. 1, 3
2022
-
[38]
Gustafsson, Zheng Zhao, Jens Sj¨olund, and Thomas B
Ziwei Luo, Fredrik K. Gustafsson, Zheng Zhao, Jens Sj¨olund, and Thomas B. Sch¨on. Image restoration with mean-reverting stochastic differential equations, 2023. 1, 2, 3, 7, 8, 6
2023
-
[39]
Gustafsson, Zheng Zhao, Jens Sj¨olund, and Thomas B
Ziwei Luo, Fredrik K. Gustafsson, Zheng Zhao, Jens Sj¨olund, and Thomas B. Sch¨on. Controlling vision-language models for multi-task image restoration, 2024. 6
2024
-
[40]
Perceptual quality as- sessment for multi-exposure image fusion.IEEE Transactions on Image Processing, 24(11):3345–3356, 2015
Kede Ma, Kai Zeng, and Zhou Wang. Perceptual quality as- sessment for multi-exposure image fusion.IEEE Transactions on Image Processing, 24(11):3345–3356, 2015. 8
2015
-
[41]
Waterloo exploration database: New challenges for image quality as- sessment models.IEEE Transactions on Image Processing, 26(2):1004–1016, 2017
Kede Ma, Zhengfang Duanmu, Qingbo Wu, Zhou Wang, Hongwei Yong, Hongliang Li, and Lei Zhang. Waterloo exploration database: New challenges for image quality as- sessment models.IEEE Transactions on Image Processing, 26(2):1004–1016, 2017. 4, 5, 6, 7
2017
-
[42]
Sdedit: Guided image synthesis and editing with stochastic differential equations,
Chenlin Meng, Yutong He, Yang Song, Jiaming Song, Jiajun Wu, Jun-Yan Zhu, and Stefano Ermon. Sdedit: Guided image synthesis and editing with stochastic differential equations,
-
[43]
Which training methods for gans do actually converge?, 2018
Lars Mescheder, Andreas Geiger, and Sebastian Nowozin. Which training methods for gans do actually converge?, 2018. 1
2018
-
[44]
Deep multi-scale convolutional neural network for dynamic scene deblurring
Seungjun Nah, Tae Hyun Kim, and Kyoung Mu Lee. Deep multi-scale convolutional neural network for dynamic scene deblurring. InProceedings of the IEEE conference on com- puter vision and pattern recognition, pages 3883–3891, 2017. 7, 4, 5
2017
-
[45]
In-domain representation learning for remote sensing, 2019
Maxim Neumann, Andre Susano Pinto, Xiaohua Zhai, and Neil Houlsby. In-domain representation learning for remote sensing, 2019. 7, 4, 5
2019
-
[46]
Dctdiff: Intriguing properties of image generative modeling in the dct space, 2025
Mang Ning, Mingxiao Li, Jianlin Su, Haozhe Jia, Lanmiao Liu, Martin Bene ˇs, Wenshuo Chen, Albert Ali Salah, and Itir Onal Ertugrul. Dctdiff: Intriguing properties of image generative modeling in the dct space, 2025. 6
2025
-
[47]
Image- to-image translation: Methods and applications, 2021
Yingxue Pang, Jianxin Lin, Tao Qin, and Zhibo Chen. Image- to-image translation: Methods and applications, 2021. 1
2021
-
[48]
Promptir: Prompting for all-in-one image restoration
Vaishnav Potlapalli, Syed Waqas Zamir, Salman Khan, and Fahad Khan. Promptir: Prompting for all-in-one image restoration. InThirty-seventh Conference on Neural Informa- tion Processing Systems, 2023. 6
2023
-
[49]
Attentive generative adversarial network for raindrop removal from a single image
Rui Qian, Robby T Tan, Wenhan Yang, Jiajun Su, and Jiaying Liu. Attentive generative adversarial network for raindrop removal from a single image. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 2482–2491, 2018. 7, 8, 4, 5
2018
-
[50]
Real-world blur dataset for learning and benchmarking de- blurring algorithms
Jaesung Rim, Haeyun Lee, Jucheol Won, and Sunghyun Cho. Real-world blur dataset for learning and benchmarking de- blurring algorithms. InEuropean conference on computer vision, pages 184–201. Springer, 2020. 9
2020
-
[51]
U-net: Convolutional networks for biomedical image segmentation
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks for biomedical image segmentation. InInternational Conference on Medical image computing and computer-assisted intervention, pages 234–241. Springer,
-
[52]
Fleet, and Mohammad Norouzi
Chitwan Saharia, Jonathan Ho, William Chan, Tim Sali- mans, David J. Fleet, and Mohammad Norouzi. Image super- resolution via iterative refinement, 2021. 1, 3
2021
-
[53]
Palette: Image-to-image diffusion models
Chitwan Saharia, William Chan, Huiwen Chang, Chris Lee, Jonathan Ho, Tim Salimans, David Fleet, and Mohammad Norouzi. Palette: Image-to-image diffusion models. InACM SIGGRAPH 2022 conference proceedings, pages 1–10, 2022. 1, 3
2022
-
[54]
Denoising Diffusion Implicit Models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models.arXiv preprint arXiv:2010.02502,
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[55]
Generative modeling by estimating gradients of the data distribution.Advances in neural information processing systems, 32, 2019
Yang Song and Stefano Ermon. Generative modeling by estimating gradients of the data distribution.Advances in neural information processing systems, 32, 2019. 1, 3
2019
-
[56]
Score-based generative modeling through stochastic differential equations
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Ab- hishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations. InInternational Conference on Learning Representations,
-
[57]
Degradation-aware feature perturbation for all-in-one image restoration
Xiangpeng Tian, Xiangyu Liao, Xiao Liu, Meng Li, and Chao Ren. Degradation-aware feature perturbation for all-in-one image restoration. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 28165–28175, 2025. 6
2025
-
[58]
Hebaixu Wang, Jing Zhang, Haonan Guo, Di Wang, Jiayi Ma, and Bo Du. Dgsolver: Diffusion generalist solver with universal posterior sampling for image restoration.arXiv preprint arXiv:2504.21487, 2025. 4
-
[59]
Nat- uralness preserved enhancement algorithm for non-uniform illumination images.IEEE transactions on image processing, 22(9):3538–3548, 2013
Shuhang Wang, Jin Zheng, Hai-Miao Hu, and Bo Li. Nat- uralness preserved enhancement algorithm for non-uniform illumination images.IEEE transactions on image processing, 22(9):3538–3548, 2013. 8
2013
-
[60]
Image quality assessment: from error visibility to structural similarity.IEEE transactions on image processing, 13(4):600–612, 2004
Zhou Wang, Alan C Bovik, Hamid R Sheikh, and Eero P Simoncelli. Image quality assessment: from error visibility to structural similarity.IEEE transactions on image processing, 13(4):600–612, 2004. 4
2004
-
[61]
Deep Retinex Decomposition for Low-Light Enhancement
Chen Wei, Wenjing Wang, Wenhan Yang, and Jiaying Liu. Deep retinex decomposition for low-light enhancement.arXiv preprint arXiv:1808.04560, 2018. 5, 7, 4
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[62]
De- blurring via stochastic refinement
Jay Whang, Mauricio Delbracio, Hossein Talebi, Chitwan Saharia, Alexandros G Dimakis, and Peyman Milanfar. De- blurring via stochastic refinement. InProc. CVPR, pages 16293–16303, 2022. 3
2022
-
[63]
Unleashing the potential of large language models for text-to-image generation through autoregressive representation alignment, 2025
Xing Xie, Jiawei Liu, Ziyue Lin, Huijie Fan, Zhi Han, Yan- dong Tang, and Liangqiong Qu. Unleashing the potential of large language models for text-to-image generation through autoregressive representation alignment, 2025. 3
2025
-
[64]
Deep joint rain detection and removal from a single image
Wenhan Yang, Robby T Tan, Jiashi Feng, Jiaying Liu, Zong- ming Guo, and Shuicheng Yan. Deep joint rain detection and removal from a single image. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 1357–1366, 2017. 6, 8
2017
-
[65]
Com- plexity experts are task-discriminative learners for any image restoration
Eduard Zamfir, Zongwei Wu, Nancy Mehta, Yuedong Tan, Danda Pani Paudel, Yulun Zhang, and Radu Timofte. Com- plexity experts are task-discriminative learners for any image restoration. InProceedings of the Computer Vision and Pat- tern Recognition Conference, pages 12753–12763, 2025. 6
2025
-
[66]
Restormer: Efficient transformer for high-resolution image restoration
Syed Waqas Zamir, Aditya Arora, Salman Khan, Mu- nawar Hayat, Fahad Shahbaz Khan, and Ming-Hsuan Yang. Restormer: Efficient transformer for high-resolution image restoration. InCVPR, 2022. 3, 6
2022
-
[67]
Vision-language gradient descent-driven all-in-one deep unfolding networks
Haijin Zeng, Xiangming Wang, Yongyong Chen, Jingyong Su, and Jie Liu. Vision-language gradient descent-driven all-in-one deep unfolding networks. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 7524–7533, 2025. 6, 7
2025
-
[68]
The unreasonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 586–595, 2018. 4
2018
-
[69]
Selective hourglass mapping for universal image restoration based on diffusion model
Dian Zheng, Xiao-Ming Wu, Shuzhou Yang, Jian Zhang, Jian- Fang Hu, and Wei-Shi Zheng. Selective hourglass mapping for universal image restoration based on diffusion model. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 25445–25455, 2024. 1, 6, 7
2024
-
[70]
Fedvlmbench: Benchmarking federated fine-tuning of vision-language models, 2025
Weiying Zheng, Ziyue Lin, Pengxin Guo, Yuyin Zhou, Feifei Wang, and Liangqiong Qu. Fedvlmbench: Benchmarking federated fine-tuning of vision-language models, 2025. 3
2025
-
[71]
Jun-Yan Zhu, Taesung Park, Phillip Isola, and Alexei A. Efros. Unpaired image-to-image translation using cycle-consistent adversarial networks, 2020. 1
2020
-
[72]
Learning weather- general and weather-specific features for image restoration under multiple adverse weather conditions
Yurui Zhu, Tianyu Wang, Xueyang Fu, Xuanyu Yang, Xin Guo, Jifeng Dai, Yu Qiao, and Xiaowei Hu. Learning weather- general and weather-specific features for image restoration under multiple adverse weather conditions. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 21747–21758, 2023. 6
2023
-
[73]
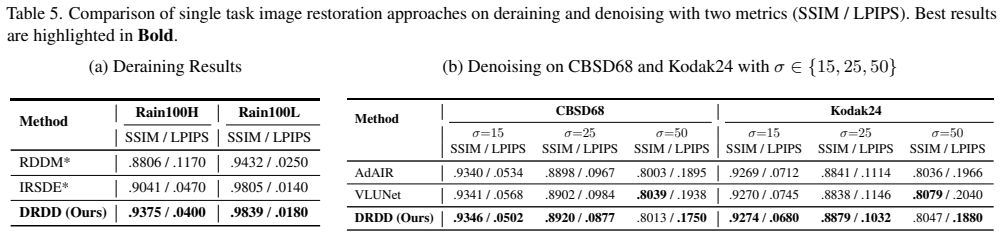
4.3.Performance on Limited Training Data
Ozan ¨Ozdenizci and Robert Legenstein. Restoring vision in adverse weather conditions with patch-based denoising diffusion models.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(8):10346–10357, 2023. 1 Decoupled Residual Denoising Diffusion Models for Unified and Data Efficient Image-to-Image Translation Supplementary Material A. Deriva...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.