PMC-InterCPT: Rethinking Biomedical Interleaved Data for Multimodal Continued Pretraining
Pith reviewed 2026-06-28 17:24 UTC · model grok-4.3
The pith
Reconstructing figure contexts from article text and resampling for modality balance creates a more efficient biomedical multimodal CPT corpus.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
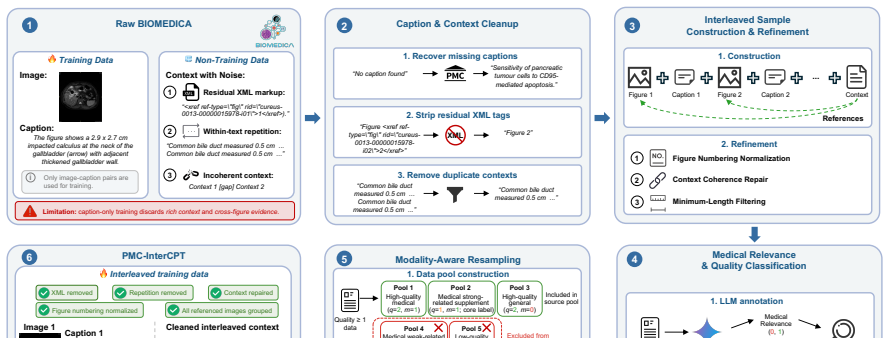
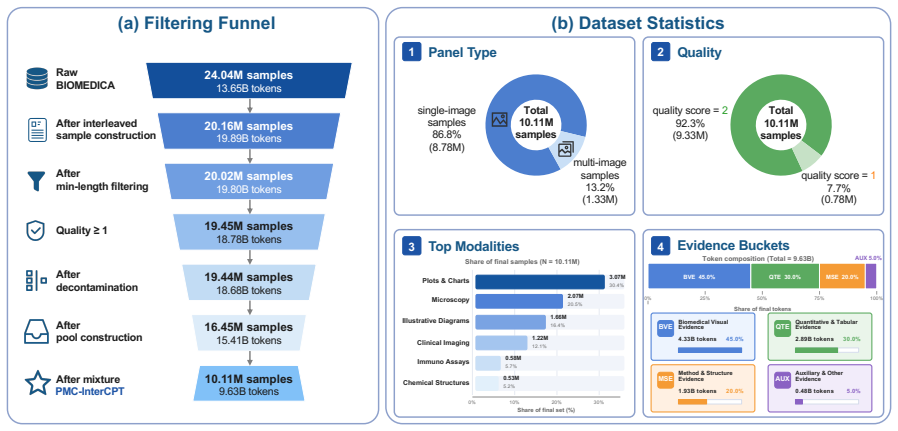
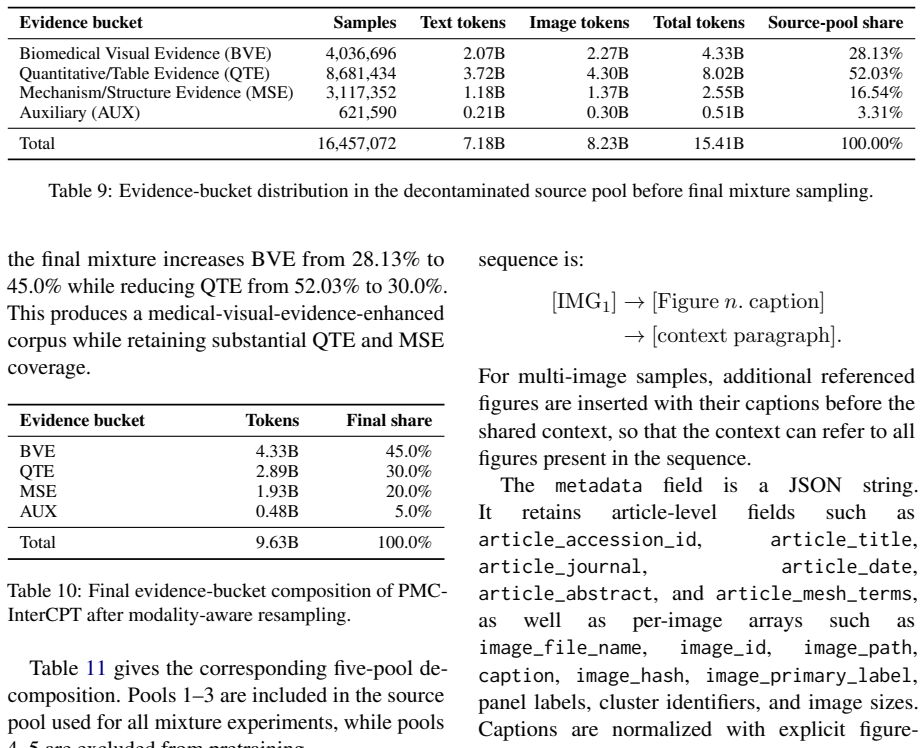
PMC-InterCPT recovers missing captions, cleans caption and context text, reconstructs coherent interleaved image-text samples, and applies LLM-supervised medical relevance and quality classifiers to filter noisy records. It reveals strong modality imbalance in the resulting corpus and introduces a four-bucket evidence taxonomy for modality-aware resampling. Through CPT followed by SFT, PMC-InterCPT effectively improves medical and general multimodal performance while using fewer CPT tokens than the raw source pool, and the results illustrate the complementarity between data quality and modality for medical multimodal CPT.
What carries the argument
The pipeline that adds figure-referencing body text to captions, cleans structural noise, filters via LLM-supervised classifiers, and applies four-bucket evidence taxonomy resampling to produce balanced interleaved samples.
If this is right
- Models show higher medical multimodal performance after CPT and SFT with the processed corpus.
- General multimodal performance also rises after the same training sequence.
- The total number of CPT tokens required is lower than when using the raw source pool.
- Data quality improvements and modality balancing act as complementary factors for medical multimodal CPT.
Where Pith is reading between the lines
- The same context-reconstruction and taxonomy-based resampling steps could be tested on interleaved datasets from other scientific domains to check for similar efficiency gains.
- Lower token counts in pretraining could reduce overall compute needed to reach target medical multimodal accuracy levels.
- The four-bucket taxonomy might serve as a template for correcting modality skew in non-biomedical multimodal corpora.
- Repeating the CPT-plus-SFT experiments on additional base models would test whether the reported gains depend on the specific architecture used.
Load-bearing premise
The LLM-supervised medical relevance and quality classifiers accurately identify useful samples without systematic bias or loss of diversity, and the four-bucket evidence taxonomy correctly captures and corrects the observed modality imbalance.
What would settle it
If continued pretraining on the raw unprocessed source pool followed by the same SFT produces equal or higher medical and general multimodal scores while using the same or fewer tokens, the claim that the processed corpus is superior would be falsified.
Figures
read the original abstract
Large-scale biomedical image-text datasets extracted from scientific literature provide valuable resources for medical multimodal model training. These datasets are commonly organized as image-caption pairs; however, figure captions are often short, context-dependent, and only partially informative without the surrounding article text. At the same time, large-scale automatic extraction introduces structural noise such as missing captions, residual markup, duplicated context, and incoherent multi-paragraph figure descriptions. We revisit data construction for medical multimodal continued pretraining (CPT) and present PMC-InterCPT, a context-grounded biomedical interleaved corpus that incorporates figure-referencing body text in addition to captions. Our pipeline recovers missing captions, cleans caption and context text, reconstructs coherent interleaved image-text samples, and applies LLM-supervised medical relevance and quality classifiers to filter noisy records. We further reveal strong modality imbalance in the resulting corpus and introduce a four-bucket evidence taxonomy for modality-aware resampling. Through CPT followed by supervised fine-tuning (SFT) on Qwen3.5-4B-Base, PMC-InterCPT effectively improves medical and general multimodal performance while using fewer CPT tokens than the raw source pool. The experimental results also illustrate the complementarity between the data quality and modality for medical multimodal CPT.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces PMC-InterCPT, a context-grounded biomedical interleaved image-text corpus constructed from PMC literature via a pipeline that recovers missing captions, cleans structural noise, reconstructs coherent interleaved samples, applies LLM-supervised medical relevance and quality classifiers for filtering, and employs a four-bucket evidence taxonomy to correct modality imbalance through resampling. Experiments demonstrate that CPT on this filtered corpus followed by SFT on Qwen3.5-4B-Base improves performance on medical and general multimodal benchmarks while consuming fewer tokens than the raw source pool, with results also illustrating complementarity between data quality and modality balance.
Significance. If the reported gains hold under the described controls, the work is significant for biomedical multimodal pretraining: it supplies an explicit, reproducible data-construction pipeline that yields measurable efficiency and performance advantages over unfiltered extraction, introduces a reusable four-bucket taxonomy for modality-aware resampling, and provides ablation evidence on the contribution of each stage. The emphasis on token efficiency and the release of the resulting corpus constitute concrete contributions to the field.
minor comments (3)
- [§3.2] §3.2: the four-bucket taxonomy is introduced with clear definitions, but the exact prompt templates used for the LLM classifiers are only summarized; including the full prompts (or a link to them) would improve reproducibility.
- [Table 4] Table 4: the token-efficiency comparison reports absolute numbers but does not state the variance across random seeds or the number of runs; adding this information would strengthen the claim that fewer tokens suffice.
- [§4.3] §4.3: the complementarity claim between quality filtering and modality resampling is supported by ablations, yet the interaction term is not tested with a crossed design; a brief note on whether the two interventions are additive or synergistic would clarify the interpretation.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation of PMC-InterCPT, the recognition of its contributions to biomedical multimodal pretraining, and the recommendation for minor revision. No specific major comments were raised in the report.
Circularity Check
No significant circularity identified
full rationale
The paper presents an empirical data-construction pipeline (caption recovery, cleaning, LLM-supervised filtering, and four-bucket resampling) followed by CPT + SFT experiments whose gains are measured on external benchmarks. No equations, fitted parameters, or self-referential definitions appear; the reported improvements are experimental outcomes relative to the raw corpus baseline rather than quantities defined in terms of themselves. No self-citation chains or uniqueness theorems are invoked as load-bearing premises.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Mensch, Katherine Millican, Malcolm Reynolds, and 1 others. 2022. Flamingo: a visual language model for few-shot learning. Advances in Neural Information Processing Systems, 35:23716--23736
2022
- [2]
-
[3]
Shruthi Bannur, Kenza Bouzid, Daniel C Castro, Anton Schwaighofer, Anja Thieme, Sam Bond-Taylor, Maximilian Ilse, Fernando P \'e rez-Garc \'i a, Valentina Salvatelli, Harshita Sharma, and 1 others. 2024. MAIRA-2 : Grounded radiology report generation. arXiv preprint arXiv:2406.04449
-
[4]
Ekaterina Borisova, Nikolas Rauscher, and Georg Rehm. 2025. Scivqa 2025: Overview of the first scientific visual question answering shared task. In Proceedings of the Fifth Workshop on Scholarly Document Processing (SDP 2025), pages 182--210
2025
-
[5]
Junying Chen, Chi Gui, Ruyi Ouyang, Anningzhe Gao, Shunian Chen, Guiming Hardy Chen, Xidong Wang, Ruifei Zhang, Zhenyang Cai, Ke Ji, Guangjun Yu, Xiang Wan, and Benyou Wang. 2024. HuatuoGPT-Vision , towards injecting medical visual knowledge into multimodal llms at scale. arXiv preprint arXiv:2406.19280
-
[6]
Xi Chen, Xiao Wang, Soravit Changpinyo, Anthony J Piergiovanni, Piotr Padlewski, Daniel Salz, Sebastian Goodman, Adam Grycner, Basil Mustafa, Lucas Beyer, and 1 others. 2022. Pali: A jointly-scaled multilingual language-image model. arXiv preprint arXiv:2209.06794
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[7]
Yutao Hu, Tianbin Li, Quanfeng Lu, Wenqi Shao, Junjun He, Yu Qiao, and Ping Luo. 2024. OmniMedVQA : A new large-scale comprehensive evaluation benchmark for medical LVLM . Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22170--22183
2024
-
[8]
Hugo Lauren c on, Lucile Saulnier, L \'e o Tronchon, Stas Bekman, Amanpreet Singh, Anton Lozhkov, Thomas Wang, Siddharth Karamcheti, Alexander Rush, Douwe Kiela, and 1 others. 2023. OBELICS : An open web-scale filtered dataset of interleaved image-text documents. Advances in Neural Information Processing Systems, 36:71683--71702
2023
-
[9]
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Ziwei Liu, and 1 others. 2024 a . Llava-onevision: Easy visual task transfer. arXiv preprint arXiv:2408.03326
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
Chunyuan Li, Cliff Wong, Sheng Zhang, Naoto Usuyama, Haotian Liu, Jianwei Yang, Tristan Naumann, Hoifung Poon, and Jianfeng Gao. 2023. LLaVA-Med : Training a large language-and-vision assistant for biomedicine in one day. Advances in Neural Information Processing Systems, 36:28541--28564
2023
-
[11]
Jeffrey Li, Alex Fang, Georgios Smyrnis, Maor Ivgi, Matt Jordan, Samir Gadre, Hritik Bansal, Etash Guha, Sedrick Keh, Kushal Arora, and 1 others. 2024 b . DataComp-LM : In search of the next generation of training sets for language models. Advances in Neural Information Processing Systems, 37:14200--14282
2024
-
[12]
Alejandro Lozano, Min Woo Sun, James Burgess, Liangyu Chen, Jeffrey J Nirschl, Jeffrey Gu, Ivan Lopez, Josiah Aklilu, Anita Rau, Austin Wolfgang Katzer, and 1 others. 2025. Biomedica: An open biomedical image-caption archive, dataset, and vision-language models derived from scientific literature. In Proceedings of the Computer Vision and Pattern Recogniti...
2025
-
[13]
Ahmed Masry, Do Long, Jia Qing Tan, Shafiq Joty, and Enamul Hoque. 2022. ChartQA : A benchmark for question answering about charts with visual and logical reasoning. In Findings of the Association for Computational Linguistics: ACL 2022, pages 2263--2279
2022
-
[14]
Michael Moor, Qian Huang, Shirley Wu, Michihiro Yasunaga, Yash Dalmia, Jure Leskovec, Cyril Zakka, Eduardo Pontes Reis, and Pranav Rajpurkar. 2023. Med-Flamingo : a multimodal medical few-shot learner. In Machine Learning for Health (ML4H), pages 353--367. PMLR
2023
-
[15]
Guilherme Penedo, Hynek Kydl \'i c ek, Anton Lozhkov, Margaret Mitchell, Colin Raffel, Leandro Von Werra, Thomas Wolf, and 1 others. 2024. The FineWeb datasets: Decanting the web for the finest text data at scale. Advances in Neural Information Processing Systems, 37:30811--30849
2024
-
[16]
Guilherme Penedo, Quentin Malartic, Daniel Hesslow, Ruxandra Cojocaru, Alessandro Cappelli, Hamza Alobeidli, Baptiste Pannier, Ebtesam Almazrouei, and Julien Launay. 2023. The RefinedWeb dataset for falcon LLM : Outperforming curated corpora with web data, and web data only. arXiv preprint arXiv:2306.01116
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[17]
Qwen Team . 2026. https://www.alibabacloud.com/blog/qwen3-5-towards-native-multimodal-agents_602894 Qwen3.5 : Towards native multimodal agents . Alibaba Cloud Community Blog
2026
-
[18]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, and 1 others. 2021. Learning transferable visual models from natural language supervision. In International conference on machine learning, pages 8748--8763. PmLR
2021
-
[19]
Zirui Wang, Mengzhou Xia, Luxi He, Howard Chen, Yitao Liu, Richard Zhu, Kaiqu Liang, Xindi Wu, Haotian Liu, Sadhika Malladi, and 1 others. 2024. Charxiv: Charting gaps in realistic chart understanding in multimodal llms. Advances in Neural Information Processing Systems, 37:113569--113697
2024
-
[20]
Sang Michael Xie, Hieu Pham, Xuanyi Dong, Nan Du, Hanxiao Liu, Yifeng Lu, Percy S Liang, Quoc V Le, Tengyu Ma, and Adams Wei Yu. 2023. DoReMi : Optimizing data mixtures speeds up language model pretraining. Advances in Neural Information Processing Systems, 36:69798--69818
2023
-
[21]
Weiwen Xu, Hou Pong Chan, Long Li, Mahani Aljunied, Ruifeng Yuan, Jianyu Wang, Chenghao Xiao, Guizhen Chen, Chaoqun Liu, Zhaodonghui Li, and 1 others. 2025. Lingshu : A generalist foundation model for unified multimodal medical understanding and reasoning. arXiv preprint arXiv:2506.07044
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
Xiang Yue, Yuansheng Ni, Kai Zhang, Tianyu Zheng, Ruoqi Liu, Ge Zhang, Samuel Stevens, Dongfu Jiang, Weiming Ren, Yuxuan Sun, and 1 others. 2024. MMMU : A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9556--9567
2024
-
[23]
Xiang Yue, Tianyu Zheng, Yuansheng Ni, Yubo Wang, Kai Zhang, Shengbang Tong, Yuxuan Sun, Botao Yu, Ge Zhang, Huan Sun, and 1 others. 2025. Mmmu-pro: A more robust multi-discipline multimodal understanding benchmark. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 15134--15186
2025
-
[24]
Sheng Zhang, Yanbo Xu, Naoto Usuyama, Hanwen Xu, Jaspreet Bagga, Robert Tinn, Sam Preston, Rajesh Rao, Mu Wei, Naveen Valluri, and 1 others. 2023 a . BiomedCLIP : a multimodal biomedical foundation model pretrained from fifteen million scientific image-text pairs. arXiv preprint arXiv:2303.00915
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[25]
Xiaoman Zhang, Chaoyi Wu, Ziheng Zhao, Weixiong Lin, Ya Zhang, Yanfeng Wang, and Weidi Xie. 2023 b . PMC-VQA : Visual instruction tuning for medical visual question answering. arXiv preprint arXiv:2305.10415
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[26]
Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Chuyue Sun, Jeff Huang, Cody H Yu, Shiyi Cao, Christos Kozyrakis, Ion Stoica, Joseph E Gonzalez, and 1 others. 2024 a . Sglang: Efficient execution of structured language model programs. Advances in neural information processing systems, 37:62557--62583
2024
-
[27]
Yaowei Zheng, Richong Zhang, Junhao Zhang, Yanhan Ye, and Zheyan Luo. 2024 b . Llamafactory: Unified efficient fine-tuning of 100+ language models. In Proceedings of the 62nd annual meeting of the association for computational linguistics (volume 3: system demonstrations), pages 400--410
2024
-
[28]
Wanrong Zhu, Jack Hessel, Anas Awadalla, Samir Yitzhak Gadre, Jesse Dodge, Alex Fang, Youngjae Yu, Ludwig Schmidt, William Yang Wang, and Yejin Choi. 2023. Multimodal C4 : An open, billion-scale corpus of images interleaved with text. Advances in Neural Information Processing Systems, 36:8958--8974
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.