MindClaw: Closed-Loop Embodied Mental-State Reasoning for Precision Intervention
Pith reviewed 2026-06-28 17:10 UTC · model grok-4.3
The pith
MindClaw shows that an optimized trigger skill lets embodied agents perform closed-loop mental-state reasoning and intervene only when useful.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
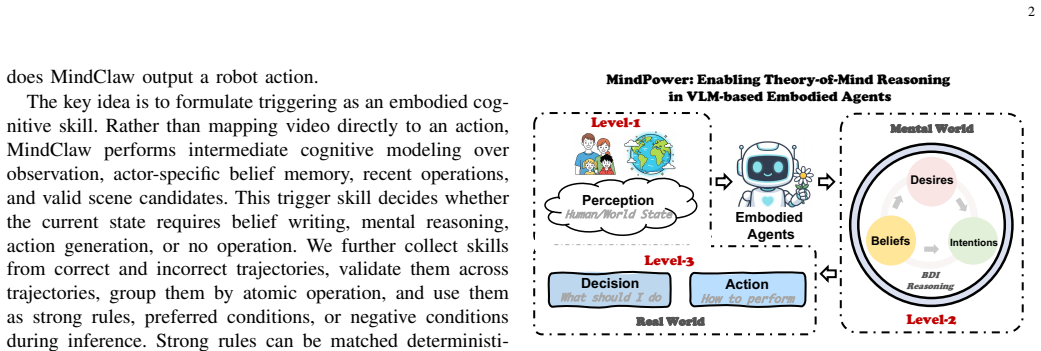
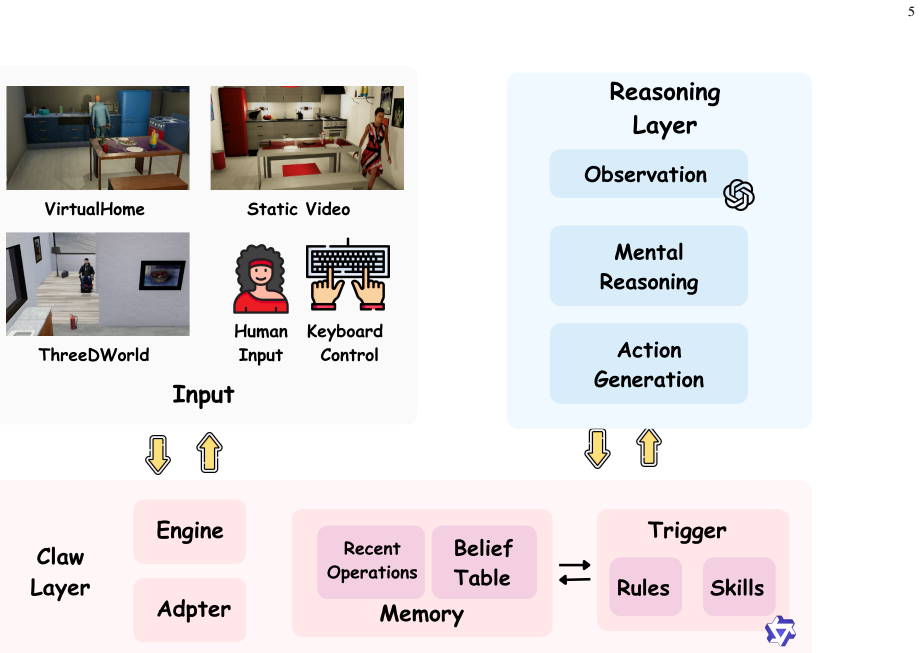
MindClaw connects multi-source inputs, belief memory, an embodied cognitive trigger skill, mental reasoning, and action generation, allowing the agent to output helpful actions at the right time while remaining silent when intervention is unnecessary; experiments show direct VLM baselines struggle with task awareness and intervention calibration, while MindClaw achieves the best overall performance and demonstrates the importance of trigger-skill optimization for closed-loop embodied ToM assistance.
What carries the argument
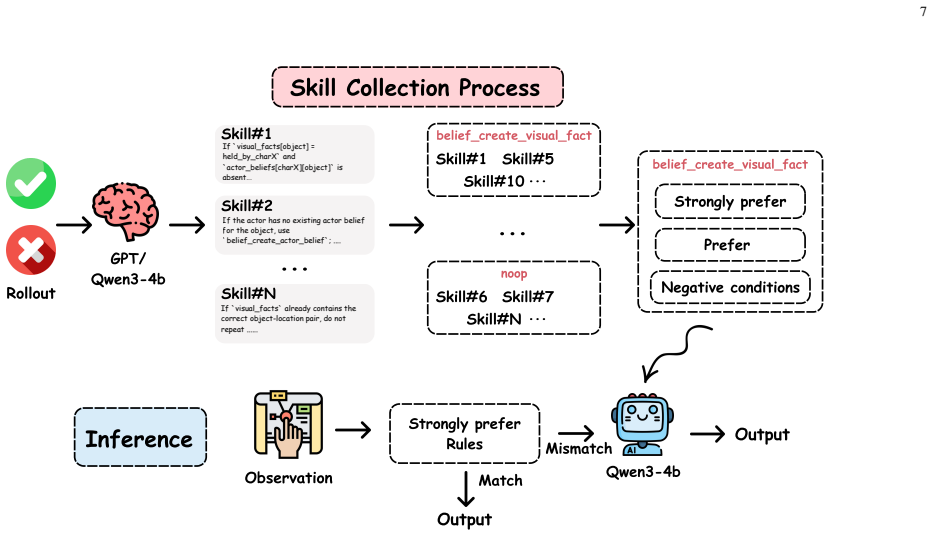
The embodied cognitive trigger skill, which uses multi-source inputs and belief memory updates to decide when mental reasoning and intervention are required.
Load-bearing premise
The trigger skill, once optimized, can reliably judge from inputs and memory when reasoning and intervention will be useful rather than intrusive.
What would settle it
A test in which the trigger skill is removed or left unoptimized and the resulting system shows no gain or performs worse than direct VLM baselines on the same closed-loop ToM tasks.
Figures
read the original abstract
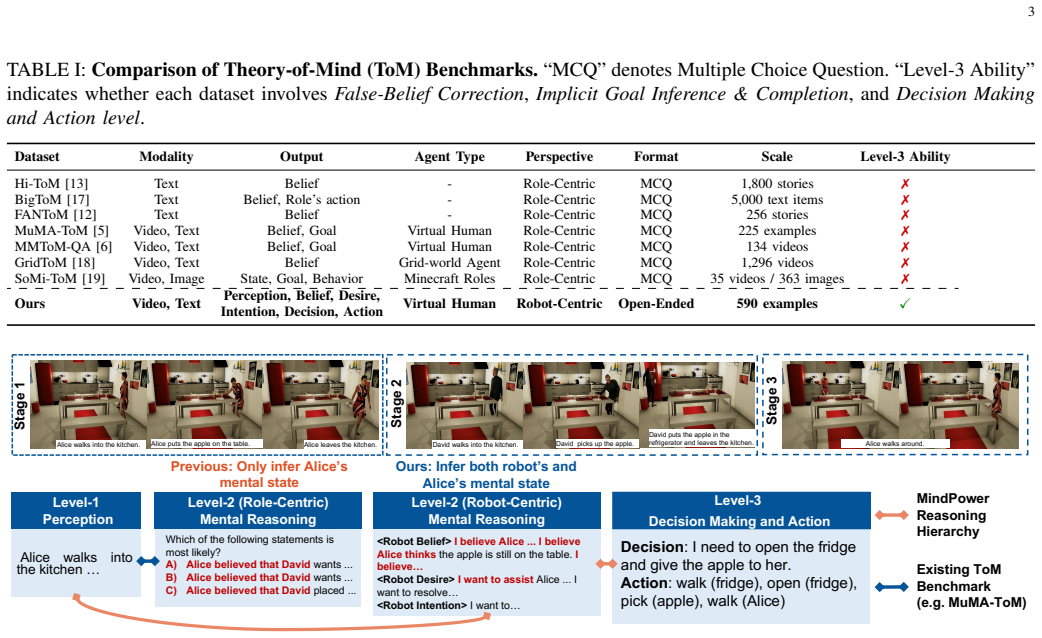
Theory of Mind (ToM) enables an agent to reason about another actor's beliefs, goals, and intentions, which is essential for human-centered embodied assistance. Existing ToM benchmarks have advanced text and multimodal mental-state recognition, but they mostly evaluate offline question answering or final action prediction. They do not fully test whether an embodied agent can stay connected to a changing environment, update actor-specific beliefs, decide when reasoning is needed, and intervene only when help is useful. Building on MindPower, we extend robot-centric ToM reasoning to a real-time closed-loop setting and introduce MindClaw, a framework for embodied mental-state reasoning with precision intervention. MindClaw connects multi-source inputs, belief memory, an embodied cognitive trigger skill, mental reasoning, and action generation, allowing the agent to output helpful actions at the right time while remaining silent when intervention is unnecessary. Experiments show that direct VLM baselines struggle with task awareness and intervention calibration, while MindClaw achieves the best overall performance, demonstrating the importance of trigger-skill optimization for closed-loop embodied ToM assistance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces MindClaw, a framework extending robot-centric Theory of Mind (ToM) reasoning to a real-time closed-loop embodied setting. It integrates multi-source inputs, belief memory, an embodied cognitive trigger skill, mental reasoning, and action generation to enable timely precision interventions while remaining silent when unnecessary. The central claim is that experiments demonstrate MindClaw outperforms direct VLM baselines on task awareness and intervention calibration, establishing the importance of trigger-skill optimization.
Significance. If the empirical results hold with appropriate controls and metrics, the work would address a recognized gap between offline ToM benchmarks and online embodied assistance, potentially improving the timing and usefulness of robot interventions in human-centered tasks.
major comments (1)
- [Abstract] Abstract: The claim that 'experiments show that direct VLM baselines struggle with task awareness and intervention calibration, while MindClaw achieves the best overall performance' supplies no metrics, dataset descriptions, baseline implementations, ablation results, or statistical tests. This absence makes the central empirical contribution impossible to evaluate and is load-bearing for the paper's primary assertion.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive assessment of the work's potential significance. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that 'experiments show that direct VLM baselines struggle with task awareness and intervention calibration, while MindClaw achieves the best overall performance' supplies no metrics, dataset descriptions, baseline implementations, ablation results, or statistical tests. This absence makes the central empirical contribution impossible to evaluate and is load-bearing for the paper's primary assertion.
Authors: We agree that the abstract, as a concise summary, does not include the quantitative details. The full manuscript provides these in the Experiments section (including dataset descriptions, baseline implementations, ablation studies, metrics on task awareness and intervention calibration, and statistical tests comparing MindClaw to direct VLM baselines). To address the concern and strengthen the abstract's support for the central claim, we will revise the abstract to incorporate a brief statement of key results (e.g., specific performance deltas and significance). revision: yes
Circularity Check
No significant circularity detected
full rationale
The manuscript presents an empirical framework (MindClaw) extending prior work (MindPower) and reports comparative performance on closed-loop ToM tasks. No equations, fitted parameters renamed as predictions, self-definitional constructs, or load-bearing uniqueness theorems appear in the abstract or described content. The central claim rests on experimental outcomes rather than any derivation that reduces to its own inputs by construction. Self-citation to MindPower is present but does not substitute for the reported results.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Core mechanisms in ‘theory of mind’,
A. M. Leslie, O. Friedman, and T. P. German, “Core mechanisms in ‘theory of mind’,”Trends in Cognitive Sciences, vol. 8, no. 12, pp. 528–533, 2004. [Online]. Available: https://www.sciencedirect.com/ science/article/pii/S1364661304002608
2004
-
[2]
Do 15-month-old infants understand false beliefs?
K. Onishi and R. Baillargeon, “Do 15-month-old infants understand false beliefs?”Science (New York, N.Y.), vol. 308, pp. 255–8, 05 2005
2005
-
[3]
Theory of mind,
C. Frith and U. Frith, “Theory of mind,”Current biology, vol. 15, no. 17, pp. R644–R645, 2005
2005
-
[4]
Bdi agents: From theory to practice
A. S. Rao, M. P. Georgeffet al., “Bdi agents: From theory to practice.” inIcmas, vol. 95, 1995, pp. 312–319
1995
-
[5]
Muma- tom: Multi-modal multi-agent theory of mind,
H. Shi, S. Ye, X. Fang, C. Jin, L. Isik, Y .-L. Kuo, and T. Shu, “Muma- tom: Multi-modal multi-agent theory of mind,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 2, 2025, pp. 1510–1519
2025
-
[6]
MMToM-QA: Multimodal theory of mind question answering,
C. Jin, Y . Wu, J. Cao, J. Xiang, Y .-L. Kuo, Z. Hu, T. Ullman, A. Torralba, J. Tenenbaum, and T. Shu, “MMToM-QA: Multimodal theory of mind question answering,” inProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), L.-W. Ku, A. Martins, and V . Srikumar, Eds. Bangkok, Thailand: Association for C...
2024
-
[7]
Bdiqa: A new dataset for video question answering to explore cognitive reasoning through theory of mind,
Y . Mao, X. Lin, Q. Ni, and L. He, “Bdiqa: A new dataset for video question answering to explore cognitive reasoning through theory of mind,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 38, no. 1, 2024, pp. 583–591
2024
-
[8]
Mindpower: Enabling theory-of-mind reasoning in vlm-based embodied agents,
R. Zhang, Q. Zheng, Z. Zhou, Z. Liao, S. Wu, J.-Y . Jiang-Lin, B. Wen, H. Xie, J. Fu, and W.-H. Cheng, “Mindpower: Enabling theory-of-mind reasoning in vlm-based embodied agents,” 2026
2026
-
[9]
Smart help: Strate- gic opponent modeling for proactive and adaptive robot assistance in households,
Z. Cao, Z. Wang, S. Xie, A. Liu, and L. Fan, “Smart help: Strate- gic opponent modeling for proactive and adaptive robot assistance in households,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 18 091–18 101
2024
-
[10]
Virtualhome: Simulating household activities via programs,
X. Puig, K. Ra, M. Boben, J. Li, T. Wang, S. Fidler, and A. Tor- ralba, “Virtualhome: Simulating household activities via programs,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 8494–8502
2018
-
[11]
Threedworld: A platform for interactive multi-modal physical simulation,
C. Gan, J. Schwartz, S. Alter, M. Schrimpf, J. Traer, J. De Freitas, J. Kubilius, A. Bhandwaldar, N. Haber, M. Sanoet al., “Threedworld: A platform for interactive multi-modal physical simulation,”Advances in Neural Information Processing Systems (NeurIPS), 2021
2021
-
[12]
Fantom: A benchmark for stress-testing machine theory of mind in interactions,
H. Kim, M. Sclar, X. Zhou, R. Bras, G. Kim, Y . Choi, and M. Sap, “Fantom: A benchmark for stress-testing machine theory of mind in interactions,” inProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, 2023, pp. 14 397–14 413
2023
-
[13]
Hi-ToM: A benchmark for evaluating higher-order theory of mind reasoning in large language models,
Y . Wu, Y . He, Y . Jia, R. Mihalcea, Y . Chen, and N. Deng, “Hi-ToM: A benchmark for evaluating higher-order theory of mind reasoning in large language models,” inFindings of the Association for Computational Linguistics: EMNLP 2023, H. Bouamor, J. Pino, and K. Bali, Eds. Singapore: Association for Computational Linguistics, Dec. 2023, pp. 10 691–10 706....
2023
-
[14]
Openclaw: Personal ai assistant,
OpenClaw Contributors, “Openclaw: Personal ai assistant,” https:// github.com/openclaw/openclaw, 2026, open-source software
2026
-
[15]
Roboclaw: An agentic framework for scalable long-horizon robotic tasks,
R. Li, Y . Zhou, Y . Zhu, K. Chen, J. Wang, S. Wang, K. Hu, M. Yu, B. Jiang, Z. Su, J. Ma, X. He, Y . Shen, Yangyang, G. Ren, M. Yao, W. Wang, and Y . Mu, “Roboclaw: An agentic framework for scalable long-horizon robotic tasks,” 2026. [Online]. Available: https://arxiv.org/abs/2603.11558
-
[16]
Abot-claw: A foundation for persistent, cooperative, and self-evolving robotic agents,
D. Huo, H. Liu, G. Liu, D. Qi, Z. Sun, M. Gao, J. He, Y . Yang, X. Chang, F. Xiong, X. Wei, Z. Ma, and M. Xu, “Abot-claw: A foundation for persistent, cooperative, and self-evolving robotic agents,”
-
[17]
ABot-Claw: A Foundation for Persistent, Cooperative, and Self-Evolving Robotic Agents
[Online]. Available: https://arxiv.org/abs/2604.10096 9
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Under- standing social reasoning in language models with language models,
K. Gandhi, J.-P. Fr ¨anken, T. Gerstenberg, and N. Goodman, “Under- standing social reasoning in language models with language models,” Advances in Neural Information Processing Systems, vol. 36, pp. 13 518–13 529, 2023
2023
-
[19]
From black boxes to transparent minds: Evaluating and enhancing the theory of mind in multimodal large language models,
X. Li, S. Liu, B. Zou, J. Chen, and H. Ma, “From black boxes to transparent minds: Evaluating and enhancing the theory of mind in multimodal large language models,” inForty-second International Conference on Machine Learning, 2025. [Online]. Available: https://openreview.net/forum?id=CDillQjA7N
2025
-
[20]
Somi-tom: Evaluating multi-perspective theory of mind in embodied social interactions,
X. Fan, X. Zhou, C. Jin, K. Nottingham, H. Zhu, and M. Sap, “Somi-tom: Evaluating multi-perspective theory of mind in embodied social interactions,” inThe Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2025. [Online]. Available: https://openreview.net/forum?id=7zFLFtqBm0
2025
-
[21]
A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lv, C. Zheng, D. Liu, F. Zhou, F. Huang, F. Hu, H. Ge, H. Wei, H. Lin, J. Tang, J. Yang, J. Tu, J. Zhang, J. Yang, J. Yang, J. Zhou, J. Zhou, J. Lin, K. Dang, K. Bao, K. Yang, L. Yu, L. Deng, M. Li, M. Xue, M. Li, P. Zhang, P. Wang, Q. Zhu, R. Men, R. Gao, S. Liu, S. Luo, T. ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
Gpt-5.5 system card,
OpenAI, “Gpt-5.5 system card,” https://openai.com/index/ gpt-5-5-system-card/, 2026, accessed: 2026-05-31
2026
-
[23]
Gpt-5.4 thinking system card,
——, “Gpt-5.4 thinking system card,” https://openai.com/index/ gpt-5-4-thinking-system-card/, 2026, accessed: 2026-05-31
2026
-
[24]
Gemini 3.1 Pro Model Card,
Gemini Team, “Gemini 3.1 Pro Model Card,” https://deepmind.google/ models/model-cards/gemini-3-1-pro/, 2026, google DeepMind Techni- cal Report. Accessed: 2026-05-31
2026
-
[25]
S. Bai, Y . Cai, R. Chen, K. Chen, X. Chen, Z. Cheng, L. Deng, W. Ding, C. Gao, C. Ge, W. Ge, Z. Guo, Q. Huang, J. Huang, F. Huang, B. Hui, S. Jiang, Z. Li, M. Li, M. Li, K. Li, Z. Lin, J. Lin, X. Liu, J. Liu, C. Liu, Y . Liu, D. Liu, S. Liu, D. Lu, R. Luo, C. Lv, R. Men, L. Meng, X. Ren, X. Ren, S. Song, Y . Sun, J. Tang, J. Tu, J. Wan, P. Wang, P. Wang,...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
VideoLLaMA 3: Frontier Multimodal Foundation Models for Image and Video Understanding
[Online]. Available: https://arxiv.org/abs/2501.13106
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
W. Wang, Z. Gao, L. Gu, H. Pu, L. Cui, X. Wei, Z. Liu, L. Jing, S. Ye, J. Shaoet al., “Internvl3.5: Advancing open-source multi- modal models in versatility, reasoning, and efficiency,”arXiv preprint arXiv:2508.18265, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Video-R1: Reinforcing Video Reasoning in MLLMs
K. Feng, K. Gong, B. Li, Z. Guo, Y . Wang, T. Peng, B. Wang, and X. Yue, “Video-r1: Reinforcing video reasoning in mllms,”arXiv preprint arXiv:2503.21776, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
OneThinker: All-in-one Reasoning Model for Image and Video
K. Feng, M. Zhang, H. Li, K. Fan, S. Chen, Y . Jiang, D. Zheng, P. Sun, Y . Zhang, H. Sunet al., “Onethinker: All-in-one reasoning model for image and video,”arXiv preprint arXiv:2512.03043, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
Videoauto-r1: Video auto reasoning via thinking once, answering twice,
S. Liu, M. Zhuge, C. Zhao, J. Chen, L. Wu, Z. Liu, C. Zhu, Z. Cai, C. Zhou, H. Liu, E. Chang, S. Suri, H. Xu, Q. Qian, W. Wen, B. Varadarajan, Z. Liu, H. Xu, F. Bordes, R. Krishnamoor- thi, B. Ghanem, V . Chandra, and Y . Xiong, “Videoauto-r1: Video auto reasoning via thinking once, answering twice,”arXiv preprint arXiv:2601.05175, 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.