CAREAgent: Clinical Agent with Structured Reasoning and Tool-Integrated for Order Generation
Pith reviewed 2026-06-28 17:40 UTC · model grok-4.3
The pith
CAREAgent trains on filtered clinical reasoning trajectories to generate executable orders more accurately than prior agent methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
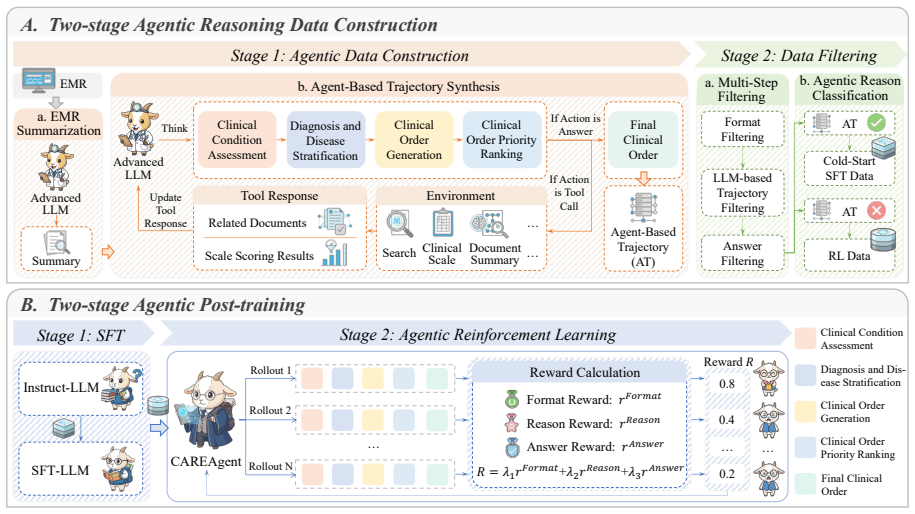
CAREAgent is an agent for clinical order generation whose training rests on a two-stage agentic reasoning data construction method. The first stage builds verifiable trajectories aligned with realistic clinical tool usage; the second stage filters them by format compliance, order validity, and clinical plausibility. The model is first trained by supervised fine-tuning to acquire fundamental reasoning formats and medical knowledge, then optimized by reinforcement learning with multi-dimensional reward functions, producing the reported F1 improvements on ClinicalBench.
What carries the argument
Two-stage agentic reasoning data construction that produces filtered, tool-aligned trajectories for subsequent SFT and RL training.
If this is right
- Supervised fine-tuning equips the model with basic reasoning formats and medical knowledge needed for order generation.
- Reinforcement learning with multi-dimensional rewards further strengthens complex clinical reasoning beyond the initial SFT stage.
- The same trained agent outperforms single-agent, multi-agent, and prior agentic-reasoning baselines on multiple benchmarks including the unseen ClinicalBench.
- Fine-grained, executable clinical orders become reachable once trajectories are made verifiable and filtered for validity.
Where Pith is reading between the lines
- The two-stage construction pipeline could be reused in other tool-heavy domains that require verifiable step-by-step decisions, such as legal document drafting or financial compliance checks.
- Deployment in actual hospitals would need separate validation against live electronic health record systems to confirm that generated orders remain safe when patient data distributions shift.
- If the clinical tools used in trajectory generation are themselves imperfect or incomplete, the learned agent may inherit those tool limitations even after filtering.
Load-bearing premise
The filtering step yields trajectories that stay clinically plausible and free of bias or unrealistic patterns, so that SFT and RL can learn effective behavior from them.
What would settle it
Remove the clinical-plausibility filter during data construction, retrain, and re-evaluate on ClinicalBench; if the F1 gains over baselines disappear, the central claim is falsified.
Figures

read the original abstract
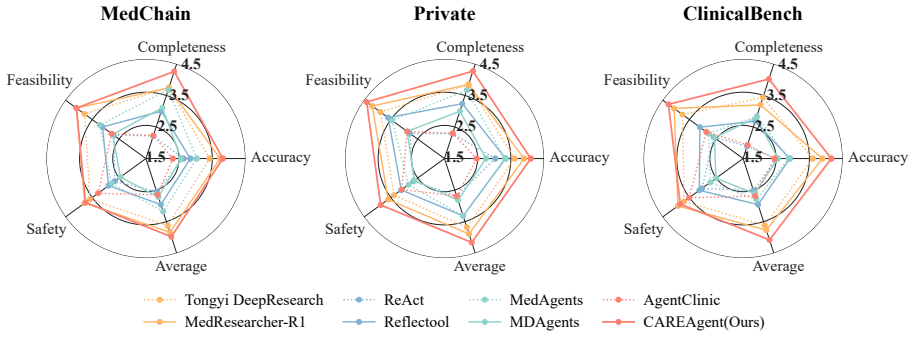
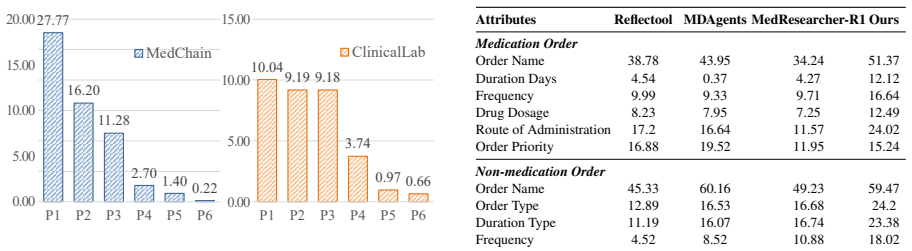
Clinical order generation serves as a critical bridge between clinical decision-making and real-world practice, translating medical decisions into concrete and executable orders. Existing agents mainly focus on coarse-grained decisions and overlook the fine-grained, executable information required for clinical orders. To address this gap, we propose CAREAgent, an agent for clinical order generation. To support its training, we introduce a two-stage agentic reasoning data construction method. First, we design an agent framework that constructs verifiable reasoning trajectories aligned with realistic clinical tool usage. Second, we filter reasoning trajectories by format compliance, order validity, and clinical plausibility. Building on the constructed data, the model is first trained via supervised fine-tuning to acquire fundamental reasoning formats and medical knowledge, and is subsequently optimized through reinforcement learning with multi-dimensional reward functions to enhance complex clinical reasoning capabilities. Experiments on multiple benchmarks demonstrate the effectiveness of CAREAgent. On ClinicalBench (unseen during training), CAREAgent improves the F1 score by 5.05%, 2.09%, and 0.86% over the single-agent, multi-agent, and agentic reasoning methods, respectively.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes CAREAgent, an agent for fine-grained clinical order generation that employs a two-stage agentic reasoning data construction pipeline (verifiable trajectories via an agent framework, followed by filtering on format compliance, order validity, and clinical plausibility), SFT to learn reasoning formats and medical knowledge, and RL with multi-dimensional rewards to improve complex reasoning. It reports F1 gains of 5.05%, 2.09%, and 0.86% on the unseen ClinicalBench benchmark over single-agent, multi-agent, and agentic-reasoning baselines.
Significance. If the data-construction claims hold, the work would advance clinical AI by shifting from coarse decisions to executable orders and by demonstrating that agentic trajectory construction plus staged SFT+RL can yield measurable gains on held-out clinical benchmarks. The explicit use of tool integration and multi-dimensional rewards is a methodological strength worth highlighting.
major comments (2)
- [Data construction method (§3)] Data construction method (abstract and §3): the clinical plausibility filter is described only at the level of 'filter reasoning trajectories by format compliance, order validity, and clinical plausibility' with no concrete criteria, validator identity (LLM vs. clinician), inter-rater agreement, or rejection-rate statistics. Because the headline F1 improvements on ClinicalBench are attributed to the quality of these trajectories, the absence of verifiable filtering details is load-bearing for the central empirical claim.
- [Experiments] Experiments section: baseline definitions, statistical significance tests, and data-exclusion rules for the reported F1 deltas are not supplied, making it impossible to assess whether the 5.05/2.09/0.86 % margins are robust or could be artifacts of the two-stage construction process.
minor comments (2)
- [Title] The title contains a grammatical issue ('Tool-Integrated for Order Generation').
- [Method] Notation for the multi-dimensional reward functions should be introduced with explicit equations rather than prose only.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting areas where additional transparency is needed. We address each major comment below and commit to revisions that provide the requested details without altering the core claims or methodology.
read point-by-point responses
-
Referee: [Data construction method (§3)] Data construction method (abstract and §3): the clinical plausibility filter is described only at the level of 'filter reasoning trajectories by format compliance, order validity, and clinical plausibility' with no concrete criteria, validator identity (LLM vs. clinician), inter-rater agreement, or rejection-rate statistics. Because the headline F1 improvements on ClinicalBench are attributed to the quality of these trajectories, the absence of verifiable filtering details is load-bearing for the central empirical claim.
Authors: We agree that the current description in §3 is high-level and that concrete details on the clinical plausibility filter are required to support the empirical claims. In the revised manuscript we will expand this section to specify the exact criteria (e.g., checks against standard guidelines for contraindications and dosage consistency), clarify that an LLM performs initial automated validation with clinician review on a sampled subset, report inter-rater agreement for the clinician portion, and include rejection-rate statistics for each filter stage. These additions will be placed in the main text or a dedicated appendix subsection. revision: yes
-
Referee: [Experiments] Experiments section: baseline definitions, statistical significance tests, and data-exclusion rules for the reported F1 deltas are not supplied, making it impossible to assess whether the 5.05/2.09/0.86 % margins are robust or could be artifacts of the two-stage construction process.
Authors: We acknowledge that the Experiments section lacks explicit baseline definitions, statistical tests, and data-exclusion rules. In the revision we will add precise descriptions of the single-agent, multi-agent, and agentic-reasoning baselines (including their implementation details and training data), report statistical significance (e.g., via bootstrap resampling or paired tests with p-values), and document any data-exclusion criteria applied during evaluation on ClinicalBench and other benchmarks. These clarifications will enable readers to evaluate the robustness of the reported F1 gains. revision: yes
Circularity Check
No circularity detected in derivation chain
full rationale
The paper describes an empirical pipeline consisting of two-stage trajectory construction, filtering, SFT, and RL, followed by benchmark evaluation. No equations, first-principles derivations, or self-citations are present that reduce the reported F1 gains on ClinicalBench to fitted inputs or prior self-referential results by construction. The performance claims rest on experimental outcomes on held-out data rather than any definitional or fitted equivalence, rendering the chain self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
InFindings of the Association for Computational Linguistics: ACL 2024, pages 2453– 2473, Bangkok, Thailand
Integrating physician diagnostic logic into large language models: Preference learning from pro- cess feedback. InFindings of the Association for Computational Linguistics: ACL 2024, pages 2453– 2473, Bangkok, Thailand. Association for Computa- tional Linguistics. Hsin-Ling Hsu, Cong-Tinh Dao, Luning Wang, Zitao Shuai, Thao Nguyen Minh Phan, Jun-En Ding, ...
2024
-
[2]
Agentmd: Empowering language agents for risk prediction with large-scale clinical tool learning. Nature Communications, 16(1):9377. Yubin Kim, Chanwoo Park, Hyewon Jeong, Yik Siu Chan, Xuhai Xu, Daniel McDuff, Hyeonhoon Lee, Marzyeh Ghassemi, Cynthia Breazeal, and Hae Won Park. 2024. Mdagents: An adaptive collaboration of llms for medical decision-making....
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
arXiv preprint arXiv:2503.04691 , year=
Quantifying the reasoning abilities of llms on real-world clinical cases.arXiv preprint arXiv:2503.04691. Keegan Quigley, Teddy Koker, Jonathan Taylor, Vince Mancuso, and Laura Brattain. 2024. Designing retrieval-augmented language models for clinical de- cision support. InAI for Health Equity and Fairness: Leveraging AI to Address Social Determinants of ...
-
[4]
Tongyi DeepResearch Technical Report
Tongyi deepresearch technical report.arXiv preprint arXiv:2510.24701. Wenxuan Wang, Zizhan Ma, Zheng Wang, Chenghan Wu, Jiaming Ji, Wenting Chen, Xiang Li, and Yix- uan Yuan. 2025. A survey of LLM-based agents in medicine: How far are we from baymax? In Findings of the Association for Computational Lin- guistics: ACL 2025, pages 10345–10359, Vienna, Austr...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
name”: “Search
Troponin: 2 points (significantly elevated, based on clinical records). Total HEART Score: 3 Clinical Interpretation: Low risk (estimated MACE ˜2.5%); discharge may be considered. </observation> <thought> ## 2. Diagnosis and Stratification.The current diagnoses include: (1) acute ST-segment elevation myocardial infarction (STEMI), Killip class I with mild...
2023
-
[6]
name”: “Pegylated Interferon-α2b“, “duration_days
</observation> <thought> ## 2. Diagnosis and Stratification.The patient has a confirmed diagnosis of chronic hepatitis C and is currently receiving combination therapy with pegylated interferon-α2b and ribavirin. Laboratory results show an absolute neutrophil count of 0.92×10 9/L (<1.0×10 9/L), meeting the criteria for drug-induced neutropenia consistent ...
-
[7]
Return format.You must return an integer list whose length is exactly the same as model_predict_order (i.e., List[int])
-
[8]
Matching rules.If a model-generated order can be matched to an item in the reference order list, return the 0-based index of the matched item in golden_order_names. If the model-generated order does not match any reference item and cannot be reasonably mapped via synonym substitution, therapeutic-class substitution, or appropriate adjunctive treatment, return-1
-
[9]
Synonyms, therapeutic equivalents, and reasonable adjunctive care.Reasonable mappings are allowed for synonymous terms, therapeutically equivalent medications, or examination and test items with different naming conventions but equivalent clinical meaning
-
[10]
Preference for the most direct match.If multiple reference orders could match a model-generated order, return the index of the most reasonable and clinically direct match
-
[11]
answer”: [0, -1, 2, . . . ]} ## Example: Reference Order List: [{
Name mismatch tolerance.Differences in naming alone should not be considered sufficient grounds for rejection; as long as the clinical purpose is consistent and medically plausible, the orders may still be regarded as a match. ## Output Format: {“answer”: [0, -1, 2, . . . ]} ## Example: Reference Order List: [{ "idx_type": "order_medication","name": "Cefu...
-
[12]
answer": {
Evaluate only the clinical rationale (reason) itself, and do not assess whether the clinical order content is correct. ## Output Requirements (Strict Compliance): - Output only JSON; do not include any explanatory text. - All scores must be integers in the range 0–5. - The JSON output must strictly follow the structure below: { "answer": { "soundness": 0,...
-
[13]
Clinical condition assessment
-
[14]
Diagnosis and disease stratification
-
[15]
Clinical order generation
-
[16]
## Diagnosis and Classification. \n The current diagnosis is XXX
Clinical order priority ranking ## Task Description: You are required to first evaluate the large language model’s capability in tool usage, and then separately assess the quality of completion of the above four tasks within the reasoning chain. There are a total of five evaluation dimensions, each scored from 0–5, with a total score of 25. ### 1. Tool Us...
-
[17]
- Identify duplicate or mutually conflicting orders
Conflict and Inappropriate Medication Checks - Assess potential drug–drug interactions. - Identify duplicate or mutually conflicting orders. - Evaluate whether dosage, route, and frequency of administration are appropriate. - Check for conflicts with contraindications, allergy history, or major comorbidities
-
[18]
Tool_Use
Priority Classification Based on importance and urgency, classify each order as: - P1: Measures that directly affect vital sign stability or survival probability and must be executed immediately. - P2: Core treatments that prevent disease progression. - P3: Measures used to monitor key therapeutic effects or high-risk adverse events. - P4: Maintenance tre...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.