From Reward-Free Representations to Preferences: Rethinking Offline Preference-Based Reinforcement Learning
Pith reviewed 2026-06-28 17:26 UTC · model grok-4.3
The pith
Learning successor-measure representations from reward-free offline data improves preference efficiency in offline PbRL.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
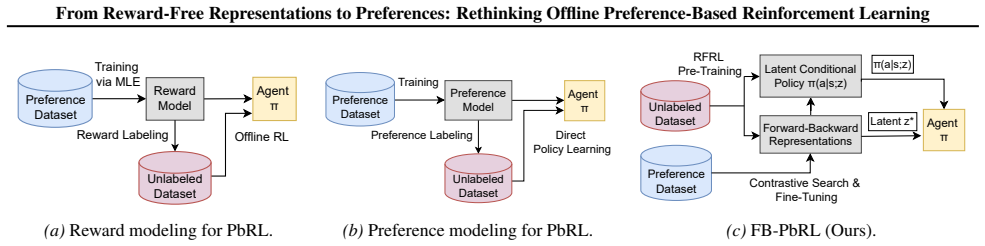
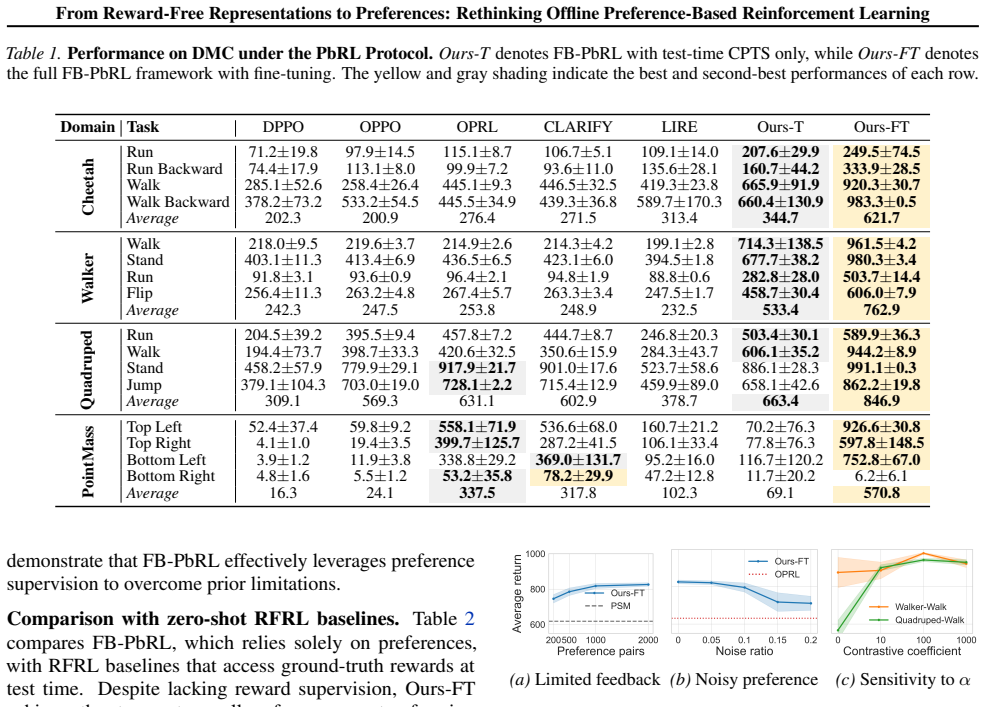
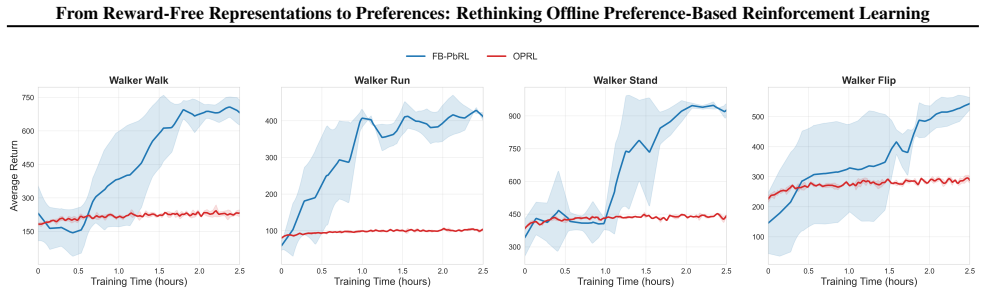
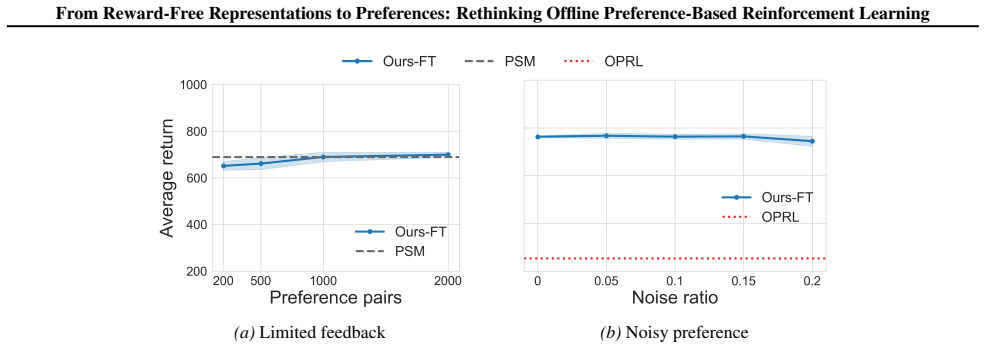
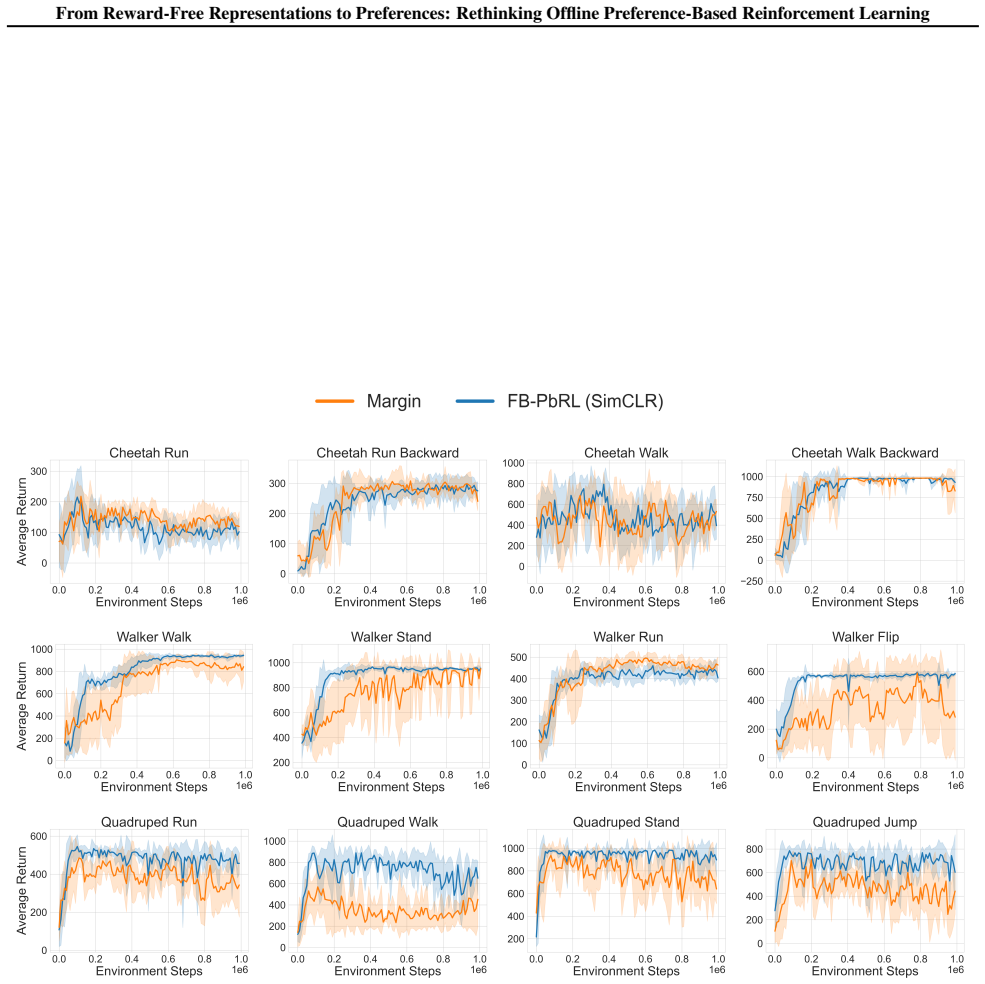
The central claim is that a training framework connecting reward-free representation learning with preference-based RL, by first acquiring latent successor-measure representations from unlabeled offline data and then applying contrastive search plus fine-tuning on preference data, delivers higher preference efficiency than standard offline PbRL pipelines.
What carries the argument
Latent successor-measure representations learned from reward-free offline data, which act as the foundation enabling subsequent contrastive search and fine-tuning with preference labels.
If this is right
- The method achieves superior preference efficiency over offline PbRL baselines.
- It establishes the first explicit connection between RFRL and PbRL.
- It positions reward-free representation learning as a route to feedback-efficient solutions.
Where Pith is reading between the lines
- The same representation-first pattern could be tested in online PbRL settings where preferences arrive incrementally.
- The approach might reduce human labeling costs in domains such as robotic control or language model alignment that rely on preference feedback.
- Similar integrations of reward-free representations could be explored for other costly feedback modalities beyond pairwise preferences.
Load-bearing premise
Successor-measure representations learned from reward-free offline data supply a sufficiently rich basis for the contrastive search and fine-tuning steps that use preference data.
What would settle it
A set of controlled experiments on standard offline PbRL benchmarks in which the proposed method requires at least as many preference labels as existing baselines to reach equivalent performance levels would falsify the efficiency claim.
Figures
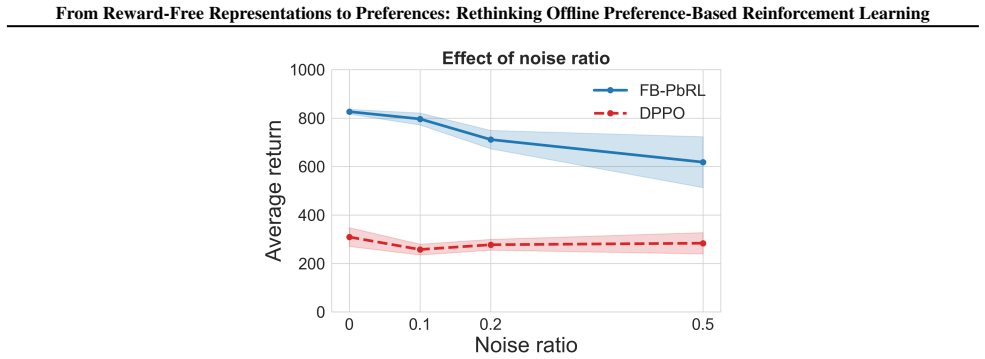
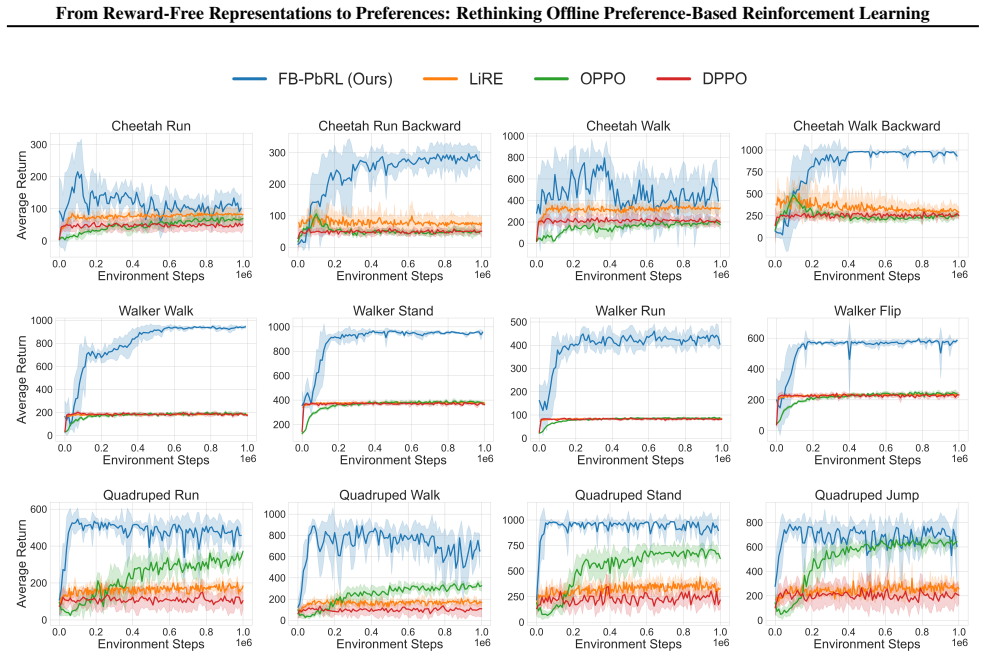
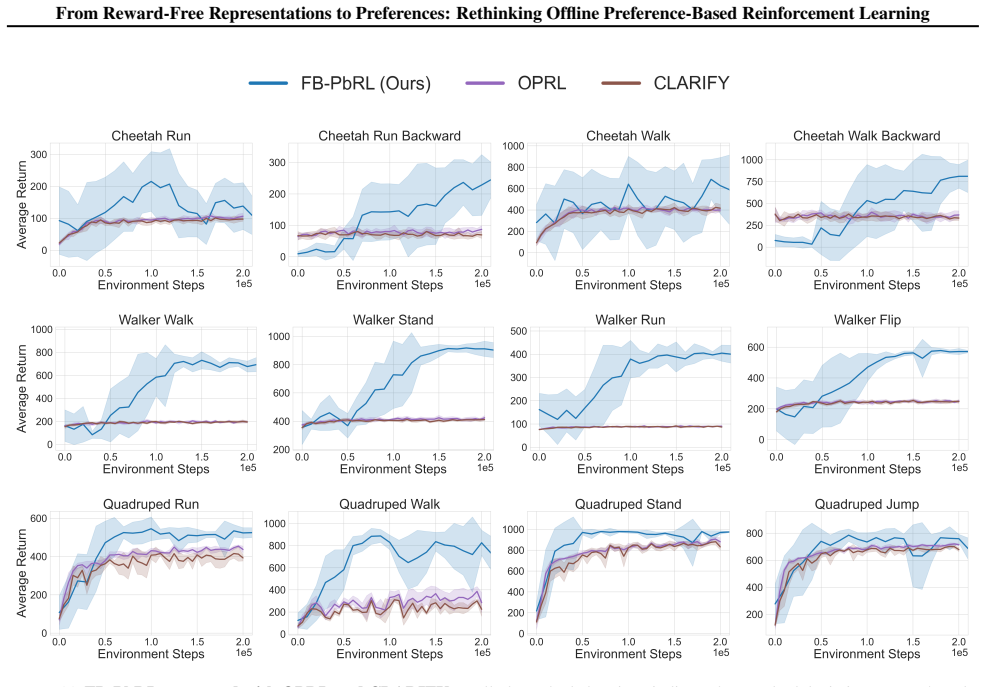
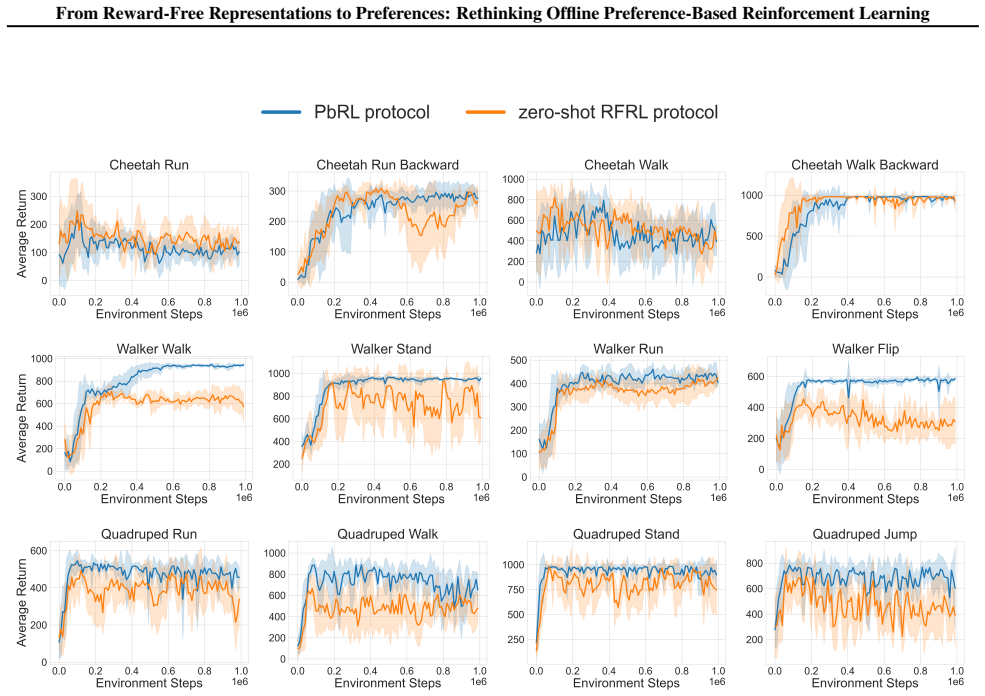
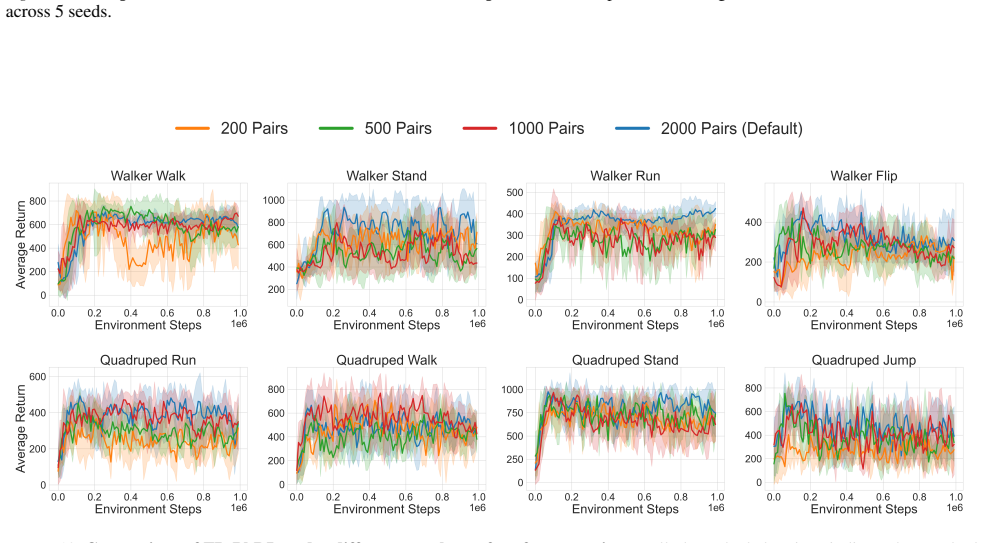
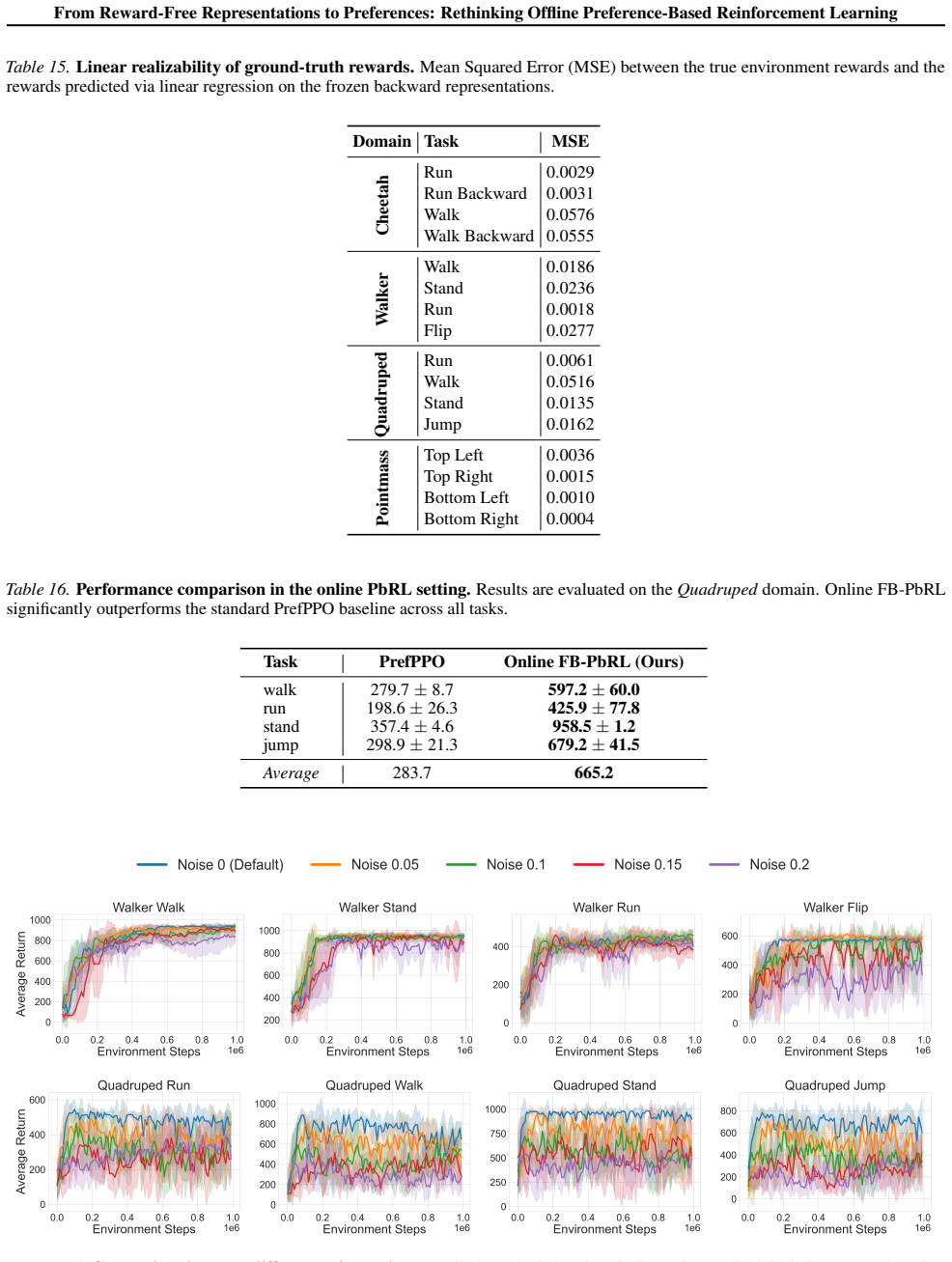
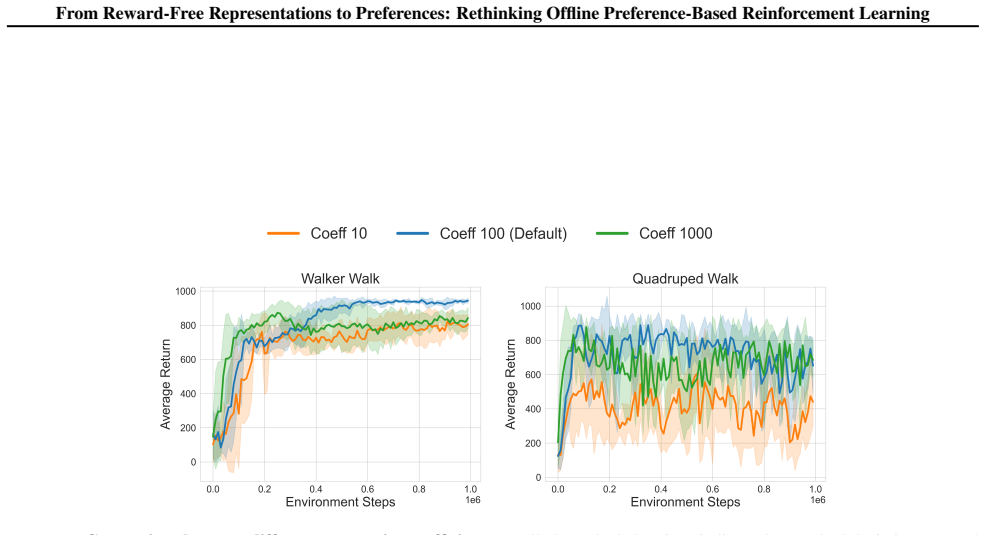
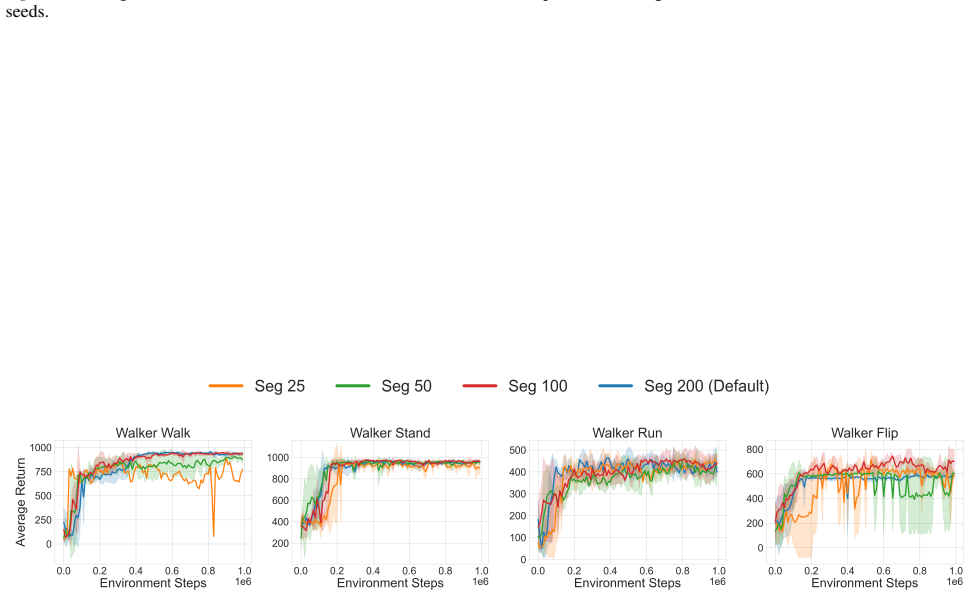
read the original abstract
Preference-based reinforcement learning (PbRL) avoids explicit reward engineering by learning from pairwise human preference feedback. Existing offline PbRL methods typically follow a two-stage pipeline, first learning a reward or preference model from labeled preferences and then performing offline RL on unlabeled data. We revisit offline PbRL through the lens of reward-free representation learning (RFRL) from the zero-shot RL literature, and propose a new training framework that first learns latent successor-measure representations from reward-free offline data, followed by contrastive search and fine-tuning using preference data. Through extensive experiments and ablations, we show that our method achieves superior preference efficiency over offline PbRL baselines. This work is the first to connect RFRL with PbRL, highlighting its potential as a feedback-efficient solution. Our code is publicly available at https://github.com/rl-bandits-lab/FB-PbRL.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes rethinking offline preference-based RL (PbRL) by integrating reward-free representation learning (RFRL). It first learns latent successor-measure representations from reward-free offline data, then applies contrastive search and fine-tuning steps that leverage limited preference data. The central claim is that this yields superior preference efficiency over standard offline PbRL baselines, with the work positioned as the first explicit connection between RFRL and PbRL; code is released publicly.
Significance. If the experimental claims hold, the approach could improve feedback efficiency in PbRL by reusing reward-free data for richer representations, reducing reliance on expensive human preferences. Public code release supports reproducibility, a positive factor in the assessment.
minor comments (1)
- The abstract references 'extensive experiments and ablations' but provides no details on datasets, baselines, or metrics; a results section or table would be needed to evaluate the superiority claim.
Simulated Author's Rebuttal
We thank the referee for their summary of the manuscript, recognition of its potential impact on feedback efficiency in PbRL, and positive note on the public code release. The recommendation is listed as uncertain, but the MAJOR COMMENTS section contains no specific points or questions. We therefore have no individual comments to address point-by-point and remain available to provide further clarification or additional experiments if requested.
Circularity Check
No significant circularity; derivation is self-contained
full rationale
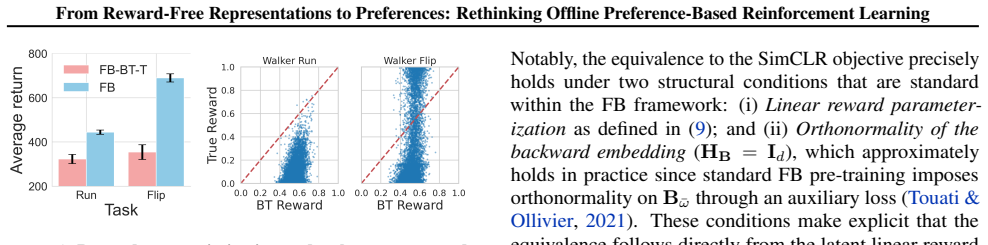
The paper proposes applying existing reward-free representation learning (RFRL) techniques—specifically successor-measure representations learned from unlabeled offline data—to the offline preference-based RL setting, followed by contrastive search and fine-tuning on preference labels. No equations, derivations, or load-bearing steps are shown that reduce a claimed prediction or uniqueness result to a fitted quantity defined by the same data, a self-citation chain, or an ansatz smuggled via prior work by the same authors. The abstract and described pipeline treat RFRL as an external starting point and present the connection plus empirical results as the contribution, without any of the six enumerated circular patterns. The central claim therefore remains independent of its own inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Latent successor-measure representations can be learned from reward-free offline data and transferred to preference-based fine-tuning
Reference graph
Works this paper leans on
-
[1]
Edward J Hu and yelong shen and Phillip Wallis and Zeyuan Allen-Zhu and Yuanzhi Li and Shean Wang and Lu Wang and Weizhu Chen , booktitle=
-
[2]
ACM Computing Surveys , volume=
A Survey on Document-level Neural Machine Translation: Methods and Evaluation , author=. ACM Computing Surveys , volume=
-
[4]
International Conference on Learning Representations (ICLR) , year=
Zero-Shot Whole-Body Humanoid Control via Behavioral Foundation Models , author=. International Conference on Learning Representations (ICLR) , year=
-
[5]
Advances in Neural Information Processing Systems (NeurIPS) , volume=
Zero-shot reinforcement learning from low quality data , author=. Advances in Neural Information Processing Systems (NeurIPS) , volume=
-
[6]
Reinforcement Learning Conference (RLC) , year=
Fast Adaptation with Behavioral Foundation Models , author=. Reinforcement Learning Conference (RLC) , year=
-
[7]
Advances in Neural Information Processing Systems (NeurIPS) , volume=
Distributional successor features enable zero-shot policy optimization , author=. Advances in Neural Information Processing Systems (NeurIPS) , volume=
-
[8]
International Conference on Machine Learning (ICML) , year=
Temporal Difference Flows , author=. International Conference on Machine Learning (ICML) , year=
-
[9]
International Conference on Learning Representations (ICLR) , year=
Intention-Conditioned Flow Occupancy Models , author=. International Conference on Learning Representations (ICLR) , year=
-
[10]
Workshop on Reinforcement Learning Beyond Rewards@ Reinforcement Learning Conference 2025 , year=
Zero-Shot Constraint Satisfaction with Forward-Backward Representations , author=. Workshop on Reinforcement Learning Beyond Rewards@ Reinforcement Learning Conference 2025 , year=
2025
-
[11]
Workshop on Reinforcement Learning Beyond Rewards@ Reinforcement Learning Conference 2025 , year=
Regularized latent dynamics prediction is a strong baseline for behavioral foundation models , author=. Workshop on Reinforcement Learning Beyond Rewards@ Reinforcement Learning Conference 2025 , year=
2025
-
[12]
International Conference on Learning Representations (ICLR) , year=
Unsupervised Zero-Shot Reinforcement Learning via Dual-Value Forward-Backward Representation , author=. International Conference on Learning Representations (ICLR) , year=
-
[13]
Marco Bagatella and Matteo Pirotta and Ahmed Touati and Alessandro Lazaric and Andrea Tirinzoni , booktitle=
-
[14]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Shift Before You Learn: Enabling Low-Rank Representations in Reinforcement Learning , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[15]
Reinforcement Learning Conference (RLC) , year=
Zero-Shot Reinforcement Learning Under Partial Observability , author=. Reinforcement Learning Conference (RLC) , year=
-
[16]
International Conference on Machine Learning (ICML) , pages=
A distributional analogue to the successor representation , author=. International Conference on Machine Learning (ICML) , pages=
-
[17]
International Conference on Learning Representations (ICLR) , year=
Zero-Shot Adaptation of Behavioral Foundation Models to Unseen Dynamics , author=. International Conference on Learning Representations (ICLR) , year=
-
[18]
International Conference on Learning Representations (ICLR) , year=
Fast Imitation via Behavior Foundation Models , author=. International Conference on Learning Representations (ICLR) , year=
-
[19]
International Conference on Machine Learning (ICML) , pages=
Unsupervised Zero-Shot Reinforcement Learning via Functional Reward Encodings , author=. International Conference on Machine Learning (ICML) , pages=
-
[20]
Sikchi, Harshit and Agarwal, Siddhant and Jajoo, Pranaya and Parajuli, Samyak and Chuck, Caleb and Rudolph, Max and Stone, Peter and Zhang, Amy and Niekum, Scott , journal=
-
[21]
International Conference on Learning Representations (ICLR) , year=
Does Zero-Shot Reinforcement Learning Exist? , author=. International Conference on Learning Representations (ICLR) , year=
-
[22]
Advances in Neural Information Processing Systems (NeurIPS) , volume=
Learning one representation to optimize all rewards , author=. Advances in Neural Information Processing Systems (NeurIPS) , volume=
-
[23]
Proto Successor Measure: Representing the Behavior Space of an
Agarwal, Siddhant and Sikchi, Harshit and Stone, Peter and Zhang, Amy , booktitle=. Proto Successor Measure: Representing the Behavior Space of an
-
[24]
Foundation Policies with
Park, Seohong and Kreiman, Tobias and Levine, Sergey , booktitle=. Foundation Policies with
-
[25]
Wu, Yifan and Tucker, George and Nachum, Ofir , booktitle=. The
-
[26]
Reinforcement Learning Conference (RLC) , year=
Finer Behavioral Foundation Models via Auto-Regressive Features and Advantage Weighting , author=. Reinforcement Learning Conference (RLC) , year=
-
[27]
Huang, Nai-Chieh and Hsieh, Ping-Chun and Ho, Kuo-Hao and Wu, I-Chen , booktitle=
-
[28]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Towards Robust Zero-Shot Reinforcement Learning , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[29]
Lee, Kimin and Smith, Laura M and Abbeel, Pieter , booktitle=
-
[30]
Park, Jongjin and Seo, Younggyo and Shin, Jinwoo and Lee, Honglak and Abbeel, Pieter and Lee, Kimin , booktitle=
-
[31]
Advances in Neural Information Processing Systems (NeurIPS) , year=
B-Pref: Benchmarking Preference-Based Reinforcement Learning , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[32]
International Conference on Learning Representations (ICLR) , year=
Reward Uncertainty for Exploration in Preference-based Reinforcement Learning , author=. International Conference on Learning Representations (ICLR) , year=
-
[33]
Cheng, Jie and Xiong, Gang and Dai, Xingyuan and Miao, Qinghai and Lv, Yisheng and Wang, Fei-Yue , booktitle=
-
[34]
IEEE International Conference on Robotics and Automation (ICRA) , pages=
Multi-Type Preference Learning: Empowering Preference-Based Reinforcement Learning with Equal Preferences , author=. IEEE International Conference on Robotics and Automation (ICRA) , pages=
-
[35]
Luan, Yao and Mu, Ni and Yang, Yiqin and XU, Bo and Jia, Qing-Shan , booktitle=
-
[36]
Bai, Fengshuo and Zhao, Rui and Zhang, Hongming and Cui, Sijia and Zhang, Shao and Han, Lei and Wen, Ying and Yang, Yaodong and others , booktitle=
-
[37]
2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) , pages=
SENIOR: Efficient Query Selection and Preference-Guided Exploration in Preference-based Reinforcement Learning , author=. 2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) , pages=
2025
-
[38]
International Conference on Learning Representations (ICLR) , year=
Query-Policy Misalignment in Preference-Based Reinforcement Learning , author=. International Conference on Learning Representations (ICLR) , year=
-
[39]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Improving Reward Models with Proximal Policy Exploration for Preference-Based Reinforcement Learning , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[40]
International Conference on Learning Representations (ICLR) , year=
Preference Transformer: Modeling Human Preferences using Transformers for RL , author=. International Conference on Learning Representations (ICLR) , year=
-
[41]
Advances in Neural Information Processing Systems (NeurIPS) , volume=
Direct preference-based policy optimization without reward modeling , author=. Advances in Neural Information Processing Systems (NeurIPS) , volume=
-
[42]
Transactions on Machine Learning Research (TMLR) , year=
Benchmarks and Algorithms for Offline Preference-Based Reward Learning , author=. Transactions on Machine Learning Research (TMLR) , year=
-
[43]
Advances in neural information processing systems (NeurIPS) , pages=
Inverse preference learning: preference-based rl without a reward function , author=. Advances in neural information processing systems (NeurIPS) , pages=
-
[44]
International Conference on Machine Learning (ICML) , pages=
Beyond reward: Offline preference-guided policy optimization , author=. International Conference on Machine Learning (ICML) , pages=
-
[45]
International Conference on Learning Representations (ICLR) , year=
Flow to better: Offline preference-based reinforcement learning via preferred trajectory generation , author=. International Conference on Learning Representations (ICLR) , year=
-
[46]
International Conference on Learning Representations (ICLR) , year=
Contrastive Preference Learning: Learning from Human Feedback without Reinforcement Learning , author=. International Conference on Learning Representations (ICLR) , year=
-
[47]
International Conference on Machine Learning (ICML) , pages=
Listwise Reward Estimation for Offline Preference-based Reinforcement Learning , author=. International Conference on Machine Learning (ICML) , pages=. 2024 , organization=
2024
-
[48]
Proceedings of the AAAI Conference on Artificial Intelligence (AAAI) , volume=
In-dataset trajectory return regularization for offline preference-based reinforcement learning , author=. Proceedings of the AAAI Conference on Artificial Intelligence (AAAI) , volume=
-
[49]
Mu, Ni and Hu, Hao and Hu, Xiao and Yang, Yiqin and XU, Bo and Jia, Qing-Shan , booktitle=
-
[50]
Kang, Sehyeok and Jeong, Jaewook and Yun, Se-Young , booktitle=
-
[51]
International Conference on Learning Representations (ICLR) , year=
Adversarial Policy Optimization for Offline Preference-based Reinforcement Learning , author=. International Conference on Learning Representations (ICLR) , year=
-
[52]
International Conference on Learning Representations (ICLR) , year=
Provable Offline Preference-Based Reinforcement Learning , author=. International Conference on Learning Representations (ICLR) , year=
-
[55]
Advances in neural information processing systems (NeurIPS) , volume=
Survival instinct in offline reinforcement learning , author=. Advances in neural information processing systems (NeurIPS) , volume=
-
[56]
International Conference on Learning Representations (ICLR) , year=
Exploration by random network distillation , author=. International Conference on Learning Representations (ICLR) , year=
-
[57]
Conference on robot learning (CoRL) , pages=
Meta-world: A benchmark and evaluation for multi-task and meta reinforcement learning , author=. Conference on robot learning (CoRL) , pages=
-
[58]
Generalizable Policy Learning in the Physical World Workshop (ICLR) , year=
Don't change the algorithm, change the data: Exploratory data for offline reinforcement learning , author=. Generalizable Policy Learning in the Physical World Workshop (ICLR) , year=
-
[59]
the method of paired comparisons , author=
Rank analysis of incomplete block designs: I. the method of paired comparisons , author=. Biometrika , volume=. 1952 , publisher=
1952
-
[60]
Advances in Neural Information Processing Systems (NeurIPS) , volume=
Online iterative reinforcement learning from human feedback with general preference model , author=. Advances in Neural Information Processing Systems (NeurIPS) , volume=
-
[61]
Advances in Neural Information Processing Systems (NeurIPS) , volume=
Sequential preference ranking for efficient reinforcement learning from human feedback , author=. Advances in Neural Information Processing Systems (NeurIPS) , volume=
-
[62]
Advances in Neural Information Processing Systems (NeurIPS) , volume=
Deep reinforcement learning from human preferences , author=. Advances in Neural Information Processing Systems (NeurIPS) , volume=
-
[63]
Advances in Neural Information Processing Systems (NeurIPS) , volume=
Training language models to follow instructions with human feedback , author=. Advances in Neural Information Processing Systems (NeurIPS) , volume=
-
[64]
International Conference on Machine Learning (ICML) , pages=
A simple framework for contrastive learning of visual representations , author=. International Conference on Machine Learning (ICML) , pages=
-
[65]
Silver, David and Huang, Aja and Maddison, Chris J and Guez, Arthur and Sifre, Laurent and Van Den Driessche, George and Schrittwieser, Julian and Antonoglou, Ioannis and Panneershelvam, Veda and Lanctot, Marc and others , journal=
-
[66]
nature , volume=
Vinyals, Oriol and Babuschkin, Igor and Czarnecki, Wojciech M and Mathieu, Micha. nature , volume=
-
[67]
Zheng, Guanjie and Zhang, Fuzheng and Zheng, Zihan and Xiang, Yang and Yuan, Nicholas Jing and Xie, Xing and Li, Zhenhui , booktitle=
-
[68]
ACM Computing Surveys , volume=
Reinforcement learning based recommender systems: A survey , author=. ACM Computing Surveys , volume=
-
[69]
Advances in Neural Information Processing Systems (NeurIPS) , volume=
Learning to dispatch for job shop scheduling via deep reinforcement learning , author=. Advances in Neural Information Processing Systems (NeurIPS) , volume=
-
[70]
Advances in Neural Information Processing Systems (NeurIPS) , volume=
Learning combinatorial optimization algorithms over graphs , author=. Advances in Neural Information Processing Systems (NeurIPS) , volume=
-
[71]
Advances in Neural Information Processing Systems (NeurIPS) , volume=
Defining and characterizing reward gaming , author=. Advances in Neural Information Processing Systems (NeurIPS) , volume=
-
[72]
International Conference on Learning Representations (ICLR) , year=
Uni-RLHF: Universal Platform and Benchmark Suite for Reinforcement Learning with Diverse Human Feedback , author=. International Conference on Learning Representations (ICLR) , year=
-
[73]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Successor features for transfer in reinforcement learning , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[74]
International Conference on Learning Representations (ICLR) , year=
Universal Successor Features Approximators , author=. International Conference on Learning Representations (ICLR) , year=
-
[75]
Neural computation , year=
Improving generalization for temporal difference learning: The successor representation , author=. Neural computation , year=
-
[76]
Advances in neural information processing systems (NeurIPS) , volume=
Conservative q-learning for offline reinforcement learning , author=. Advances in neural information processing systems (NeurIPS) , volume=
-
[77]
International Conference on Learning Representations (ICLR) , year=
Offline Reinforcement Learning with Implicit Q-Learning , author=. International Conference on Learning Representations (ICLR) , year=
-
[78]
International Conference on Machine Learning (ICML) , pages=
Principled reinforcement learning with human feedback from pairwise or k-wise comparisons , author=. International Conference on Machine Learning (ICML) , pages=. 2023 , organization=
2023
-
[79]
International Conference on Learning Representations (ICLR) , year=
A Reward-Free Viewpoint on Multi-Objective Reinforcement Learning , author=. International Conference on Learning Representations (ICLR) , year=
-
[80]
Learning Human-Like
Guo, Jian-Ting and Chen, Yu-Cheng and Hsieh, Ping-Chun and Ho, Kuo-Hao and Huang, Po-Wei and Wu, Ti-Rong and Wu, I and others , journal=. Learning Human-Like
-
[81]
M., Crump, T., and Far, B
Afsar, M. M., Crump, T., and Far, B. Reinforcement learning based recommender systems: A survey. ACM Computing Surveys, 55 0 (7): 0 1--38, 2022
2022
-
[82]
Proto successor measure: Representing the behavior space of an RL agent
Agarwal, S., Sikchi, H., Stone, P., and Zhang, A. Proto successor measure: Representing the behavior space of an RL agent. In International Conference on Machine Learning (ICML), 2025
2025
-
[83]
An, G., Lee, J., Zuo, X., Kosaka, N., Kim, K.-M., and Song, H. O. Direct preference-based policy optimization without reward modeling. Advances in Neural Information Processing Systems (NeurIPS), 36: 0 70247--70266, 2023
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.