Schedule-Level Shared-Prefix Reuse for LLM RL Training
Pith reviewed 2026-06-28 16:41 UTC · model grok-4.3
The pith
Reordered GRPO training schedule reuses shared prefixes once per group instead of once per trajectory while matching baseline numerically.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
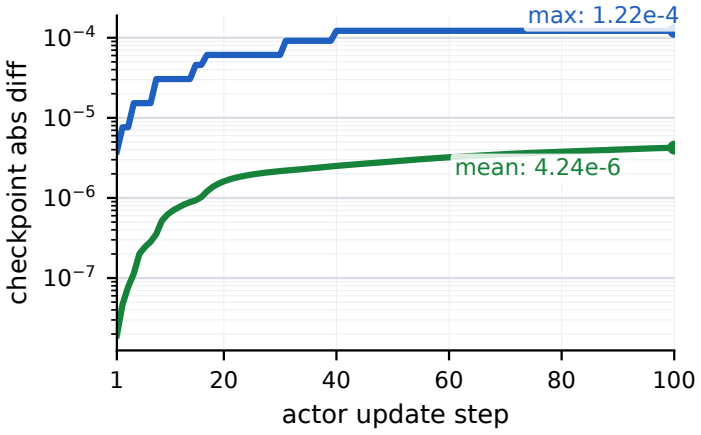
The reordered schedule that decouples prefix and suffix computation is equivalent to baseline training over real arithmetic and aligns numerically within finite-precision tolerance. On dense Llama3-8B, Qwen3-8B, and MoE Qwen3-MoE-30B-A3B models it matches optimizer updates across TP/CP/PP/EP combinations, aligns on a 100-step real GRPO actor-update trace, reaches up to 4.395x speedup as prefix ratio and group size grow, reduces Phase-B peak HBM by up to 59.1 percent, and extends Llama3-8B capacity from 17,920 to 29,696 total tokens.
What carries the argument
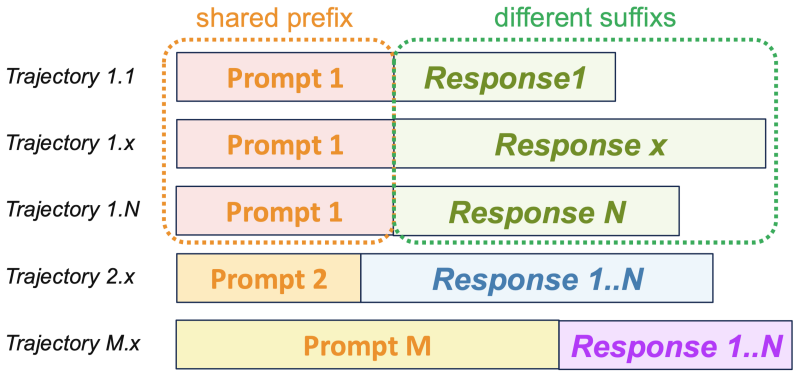
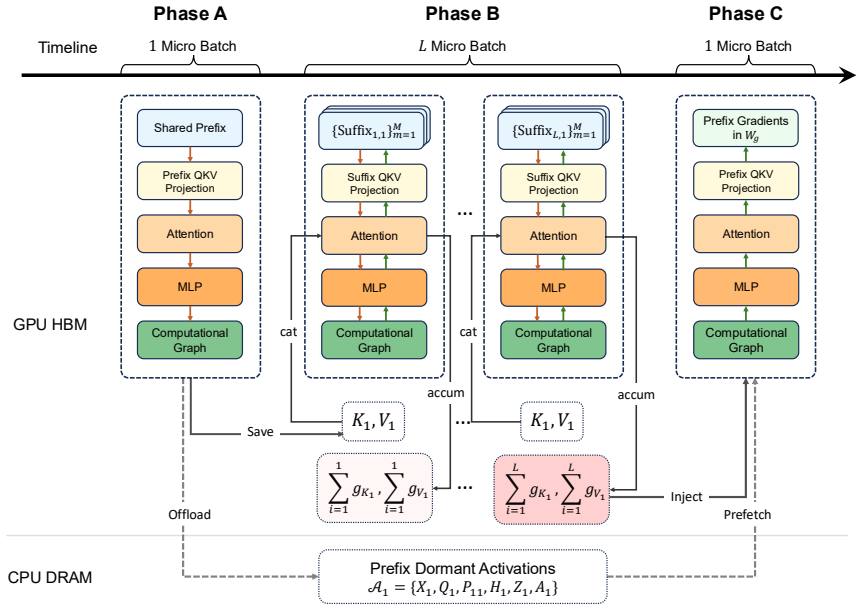
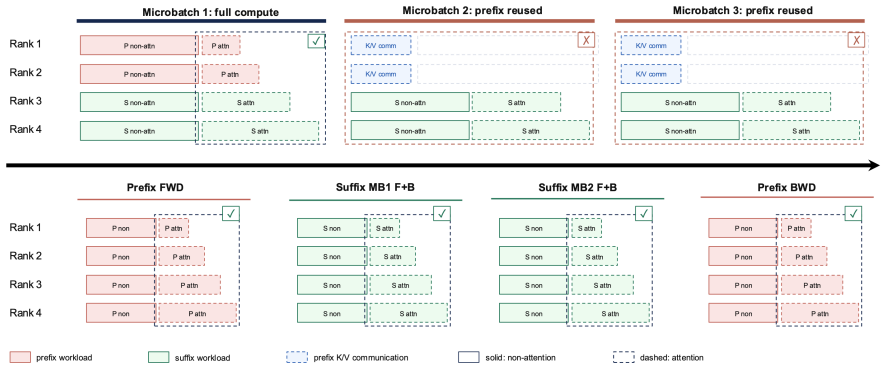
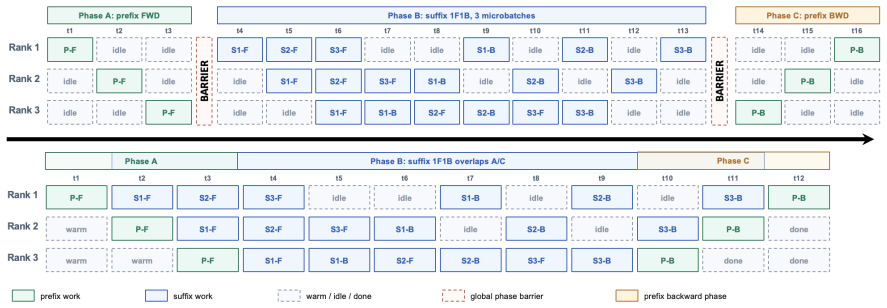
Schedule-level shared-prefix reuse that runs prefix forward once, suffix microbatches that read prefix K/V and accumulate gK/gV, then prefix backward once on the accumulated gradient cache.
If this is right
- Optimizer updates match across all tested TP/CP/PP/EP combinations.
- Numerical results align on a full 100-step real GRPO actor-update trace replay.
- Speedup reaches 4.395x (2.930x under conservative compile-on comparison) as prefix ratio and GRPO group size increase.
- Phase-B peak HBM drops by up to 59.1 percent.
- Llama3-8B capacity frontier extends from 17,920 to 29,696 total tokens.
Where Pith is reading between the lines
- The same reuse pattern could apply to other multi-trajectory RL algorithms such as PPO that also sample multiple responses from one prompt.
- Training throughput gains could let practitioners increase GRPO group size without raising wall-clock time.
- Offloading of prefix activations may combine with existing activation checkpointing or other memory techniques for further savings.
- The approach is testable on additional hardware platforms or with different model scales to measure how speedup scales with context length.
Load-bearing premise
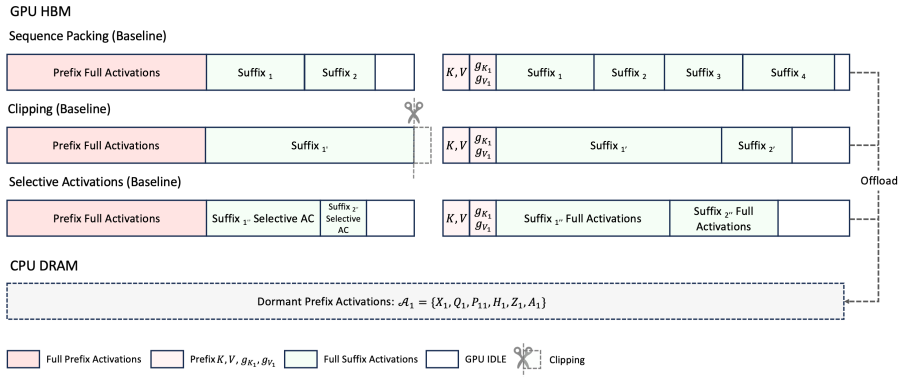
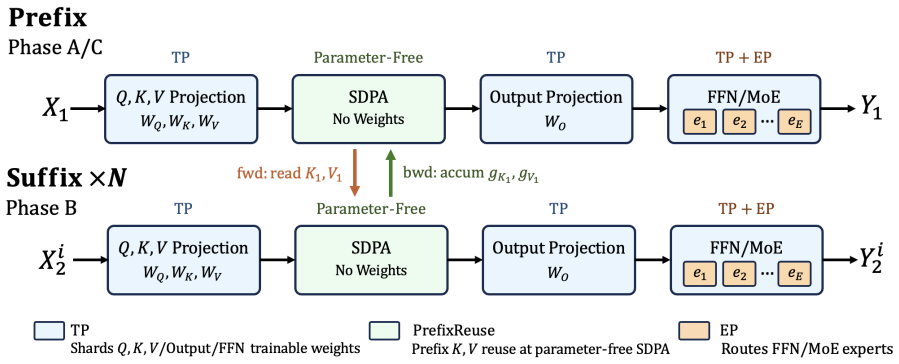
Prefix activations can be safely offloaded and accumulated prefix-side gradients can be applied without altering numerical behavior or MoE router semantics across all supported parallelism combinations.
What would settle it
Execute the baseline schedule and the reordered schedule on an identical GRPO workload with the same random seed and check whether the resulting model weights or per-step losses differ by more than floating-point tolerance.
Figures
read the original abstract
GRPO-based LLM post-training commonly samples multiple trajectories from the same prompt and then trains on the resulting group. In long-context GRPO workloads, this shared prompt-side prefix can contain retrieved passages, visual tokens, tool schemas, system instructions, or task context, while the full rollout group is still too large to pack into one training microbatch. Standard dense trainers therefore recompute the same prefix forward and backward for every trajectory. We present a schedule-level reuse mechanism that decouples prefix and suffix computation. The schedule runs prefix forward once, executes suffixes as ordinary microbatches while reading prefix K/V and accumulating prefix-side gK/gV , and then runs prefix backward once on the accumulated gradient cache. This reordered schedule is equivalent to baseline training over real arithmetic and aligns numerically within finite-precision tolerance. Because only K/V and gK/gV are hot during suffix computation, the approach offloads dormant prefix activations, integrates with TP/EP/CP/PP and DP-style placement at the execution level, and preserves aux-loss-based MoE router semantics through logical prefix-token accounting. On dense Llama3-8B, Qwen3-8B, and MoE Qwen3-MoE-30B-A3B configurations, the schedule matches optimizer updates across TP/CP/PP/EP combinations, aligns on a 100-step real GRPO actor-update trace replay, reaches up to 4.395x speedup (2.930x under a conservative compile-on comparison) as prefix ratio and GRPO group size grow, and reduces Phase-B peak HBM by up to 59.1%, extending the Llama3-8B capacity frontier from 17,920 to 29,696 total tokens.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims a schedule-level shared-prefix reuse mechanism for GRPO-based LLM post-training that decouples prefix and suffix computation: prefix forward is run once, suffixes execute as microbatches while reading prefix K/V and accumulating prefix-side gK/gV, and prefix backward runs once on the accumulated gradient cache. This reordered schedule is asserted to be arithmetically equivalent to the baseline under real arithmetic, to align numerically within finite-precision tolerance, to integrate with TP/EP/CP/PP/DP and MoE aux-loss semantics via logical prefix-token accounting, and to deliver up to 4.395x speedup (2.930x under conservative compile-on comparison) and 59.1% Phase-B HBM reduction, extending Llama3-8B capacity from 17,920 to 29,696 tokens. Validation is via optimizer-update matching on a 100-step GRPO trace replay across parallelism combinations.
Significance. If the equivalence and numerical fidelity hold across the claimed configurations, the technique provides a practical, implementation-level optimization for long-context GRPO workloads that reuses expensive prefix activations without altering training semantics. The reported speedups and memory savings scale with prefix ratio and group size, and the compatibility with standard parallelism and MoE routing is a concrete engineering contribution. The trace-replay validation on real GRPO actor updates strengthens the practical claim over purely synthetic benchmarks.
major comments (2)
- [Abstract] Abstract and schedule description: the central claim of arithmetic equivalence (prefix forward once + suffix microbatches with K/V read + accumulated gK/gV + single prefix backward) is asserted to follow from linearity of gradient accumulation, but no derivation, proof sketch, or explicit walk-through of the forward/backward passes is supplied; this is load-bearing for the equivalence guarantee.
- [Experimental validation] Experimental validation section (trace replay): the reported numerical alignment and optimizer-update match across TP/CP/PP/EP combinations provides no error-bar reporting, measurement methodology details, or data-exclusion rules, leaving the finite-precision tolerance claim dependent on unshown implementation evidence.
minor comments (1)
- [Abstract] The abstract states concrete speedup and memory numbers without indicating whether they are measured under identical compile settings or include variance across runs.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments below and will revise the manuscript to strengthen the equivalence claim and validation details.
read point-by-point responses
-
Referee: [Abstract] Abstract and schedule description: the central claim of arithmetic equivalence (prefix forward once + suffix microbatches with K/V read + accumulated gK/gV + single prefix backward) is asserted to follow from linearity of gradient accumulation, but no derivation, proof sketch, or explicit walk-through of the forward/backward passes is supplied; this is load-bearing for the equivalence guarantee.
Authors: We agree that an explicit derivation is needed. In the revised manuscript we will add a dedicated subsection (or appendix) providing a step-by-step walk-through: (1) prefix forward computes and caches K/V once; (2) each suffix microbatch reads the cached prefix K/V and, during its backward, accumulates the corresponding prefix-side gK/gV; (3) a single prefix backward is then executed on the accumulated gradient cache. We will show that this is arithmetically identical to the baseline by linearity of gradient accumulation under real arithmetic, with the finite-precision behavior following from the same accumulation order. revision: yes
-
Referee: [Experimental validation] Experimental validation section (trace replay): the reported numerical alignment and optimizer-update match across TP/CP/PP/EP combinations provides no error-bar reporting, measurement methodology details, or data-exclusion rules, leaving the finite-precision tolerance claim dependent on unshown implementation evidence.
Authors: The reported matches are exact optimizer-update equality on a deterministic 100-step real GRPO trace replay (no stochastic sampling), so statistical error bars are not applicable. We will expand the validation section with: (a) precise description of the replay harness and how updates were compared (element-wise equality within machine epsilon after identical optimizer steps), (b) the full set of parallelism configurations tested, and (c) explicit statement that no data points were excluded. This will make the finite-precision claim fully reproducible from the provided evidence. revision: yes
Circularity Check
No significant circularity
full rationale
The paper derives algebraic equivalence of the reordered prefix-suffix schedule to baseline training directly from the linearity of gradient accumulation (a standard property of backpropagation) and verifies numerical fidelity via explicit 100-step trace replay matching optimizer updates across parallelism combinations. No equations are self-definitional, no parameters are fitted then renamed as predictions, and no load-bearing claims reduce to self-citations or imported uniqueness theorems. The central result is a reordering whose correctness is independently checkable against the baseline forward/backward passes and external numerical traces.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Prefix forward and suffix microbatch computations can be decoupled while preserving exact equivalence in real arithmetic
- domain assumption Accumulated prefix-side gradients can be applied in a single backward pass without changing MoE router behavior
Reference graph
Works this paper leans on
-
[1]
Tulu 3: Pushing Frontiers in Open Language Model Post-Training
Allen Institute for AI. Tulu 3: Pushing frontiers in open language model post-training, 2024. URLhttps://arxiv.org/abs/2411.15124
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Training Deep Nets with Sublinear Memory Cost
Tianqi Chen, Bing Xu, Chiyuan Zhang, and Carlos Guestrin. Training deep nets with sublinear memory cost, 2016. URLhttps://arxiv.org/abs/1604.06174
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[3]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
DeepSeek-AI. DeepSeekMath: Pushing the limits of mathematical reasoning in open language models, 2024. URLhttps://arxiv.org/abs/2402.03300
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-AI. DeepSeek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning, 2025. URLhttps://arxiv.org/abs/2501.12948
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity.Journal of Machine Learning Research, 23(120):1--39, 2022
William Fedus, Barret Zoph, and Noam Shazeer. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity.Journal of Machine Learning Research, 23(120):1--39, 2022. URLhttps://www.jmlr.org/papers/v23/21-0998.html
2022
-
[6]
Gai et al. DualKV: Shared-prompt FlashAttention for efficient RL training with large rollouts and long contexts, 2026. URLhttps://arxiv.org/abs/2605.15422
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[7]
Sam Ade Jacobs, Masahiro Tanaka, Chengming Zhang, Minjia Zhang, Shuaiwen Leon Song, Samyam Rajbhandari, and Yuxiong He. DeepSpeed Ulysses: System optimizations for enabling 20 training of extreme long sequence transformer models, 2023. URL https://arxiv.org/abs/ 2309.14509
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[8]
Gonzalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with PagedAttention. InProceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles, pages 611--626, 2023. doi: 10.1145/3600006. 3613165
-
[9]
GShard: Scaling giant models with conditional computation and automatic sharding, 2020
Dmitry Lepikhin, HyoukJoong Lee, Yuanzhong Xu, Dehao Chen, Orhan Firat, Yanping Huang, Maxim Krikun, Noam Shazeer, and Zhifeng Chen. GShard: Scaling giant models with conditional computation and automatic sharding, 2020. URL https://arxiv.org/abs/2006. 16668
2020
-
[10]
BASE layers: Simplifying training of large, sparse models
Mike Lewis, Shruti Bhosale, Tim Dettmers, Naman Goyal, and Luke Zettlemoyer. BASE layers: Simplifying training of large, sparse models. InProceedings of the 38th International Conference on Machine Learning, volume 139 ofProceedings of Machine Learning Research, pages 6265--
-
[11]
URLhttps://proceedings.mlr.press/v139/lewis21a.html
PMLR, 2021. URLhttps://proceedings.mlr.press/v139/lewis21a.html
2021
-
[12]
arXiv preprint arXiv:2506.05433 , year=
Liu et al. Prefix grouper: Efficient GRPO training through shared-prefix forward, 2025. URL https://arxiv.org/abs/2506.05433
-
[13]
Ring Attention with blockwise transformers for near-infinite context
Hao Liu, Matei Zaharia, and Pieter Abbeel. Ring Attention with blockwise transformers for near-infinite context. InInternational Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=WsRHpHH4s0
2024
-
[14]
OpenRLHF: An easy-to-use, scalable and high-performance RLHF framework, 2024
OpenRLHF Contributors. OpenRLHF: An easy-to-use, scalable and high-performance RLHF framework, 2024. URLhttps://github.com/OpenRLHF/OpenRLHF
2024
-
[15]
TorchTitan: A native PyTorch library for large model training, 2024
PyTorch Contributors. TorchTitan: A native PyTorch library for large model training, 2024. URLhttps://github.com/pytorch/torchtitan
2024
-
[16]
ZeRO: Memory optimizations toward training trillion parameter models
Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, and Yuxiong He. ZeRO: Memory optimizations toward training trillion parameter models. InProceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, 2020
2020
-
[17]
ZeRO-Offload: Democratizing billion-scale model training
Jie Ren, Samyam Rajbhandari, Reza Yazdani Aminabadi, Olatunji Ruwase, Shaden Smith, Minjia Zhang, and Yuxiong He. ZeRO-Offload: Democratizing billion-scale model training. In 2021 USENIX Annual Technical Conference, pages 551--564, 2021
2021
-
[18]
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc V. Le, Geoffrey E. Hinton, and Jeff Dean. Outrageously large neural networks: The sparsely-gated mixture- of-experts layer. InInternational Conference on Learning Representations, 2017. URL https://arxiv.org/abs/1701.06538
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[19]
Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper, and Bryan Catanzaro. Megatron-LM: Training multi-billion parameter language models using model parallelism, 2019. URLhttps://arxiv.org/abs/1909.08053
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[20]
verl: Volcano engine reinforcement learning for large language models, 2024
verl Contributors. verl: Volcano engine reinforcement learning for large language models, 2024. URLhttps://github.com/volcengine/verl. 21
2024
-
[21]
Accelerating direct preference optimization with prefix sharing, 2024
Wang and Hegde. Accelerating direct preference optimization with prefix sharing, 2024. URL https://arxiv.org/abs/2410.20305
-
[22]
Tree Training: Accelerating Agentic LLMs Training via Shared Prefix Reuse
Wang et al. Tree training: Accelerating agentic LLMs training via shared prefix reuse, 2026. URLhttps://arxiv.org/abs/2511.00413. Version 5
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[23]
Zhang et al. AREAL-DTA: Dynamic tree attention for efficient reinforcement learning of large language models, 2026. URLhttps://arxiv.org/abs/2602.00482
-
[24]
SGLang: Efficient execution of structured language model programs,
Lianmin Zheng et al. SGLang: Efficient execution of structured language model programs,
-
[25]
URLhttps://arxiv.org/abs/2312.07104
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
Yanqi Zhou, Tao Lei, Hanxiao Liu, Nan Du, Yanping Huang, Vincent Y. Zhao, Andrew M. Dai, Zhifeng Chen, Quoc V. Le, and James Laudon. Mixture-of-experts with expert choice routing. InAdvances in Neural Information Processing Systems, 2022. URL https://arxiv. org/abs/2202.09368
-
[27]
ST-MoE: Designing Stable and Transferable Sparse Expert Models
Barret Zoph, Irwan Bello, Sameer Kumar, Nan Du, Yanping Huang, Jeff Dean, Noam Shazeer, and William Fedus. ST-MoE: Designing stable and transferable sparse expert models, 2022. URLhttps://arxiv.org/abs/2202.08906. A Backward-Centric Derivation of Prefix-Gradient Superposition This appendix expands the prefix-suffix reuse boundary and Proposition 1 from Se...
work page internal anchor Pith review Pith/arXiv arXiv 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.