HiTokSR: A Coarse-to-Fine Tokenizer with Hierarchical Codebooks for High-Fidelity Real-World Image Super-Resolution
Pith reviewed 2026-06-28 17:30 UTC · model grok-4.3
The pith
HiTokSR partitions latent space into frequency groups with separate sub-codebooks to disentangle structures from textures in real-world image super-resolution.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
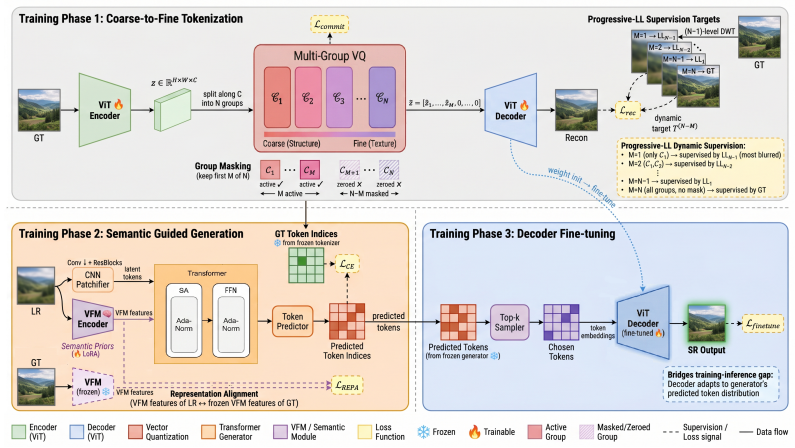
HiTokSR partitions the latent space along the channel dimension into frequency-aware groups, each quantized by an independent sub-codebook. This coarse-to-fine design disentangles global structures from fine details, increases combinatorial expressiveness, and avoids instability in high-dimensional nearest-neighbor search. Semantic consistency is strengthened by adaptive feature modulation and a representation alignment loss drawn from a vision foundation model, while an index-level perturbation strategy during decoder fine-tuning reduces the train-test gap in discrete token prediction.
What carries the argument
The hierarchical token prediction framework that partitions the latent space into frequency-aware groups quantized by independent sub-codebooks, performing coarse-to-fine discretization.
If this is right
- Codebook utilization rises because structure-texture pairings no longer compete inside one lookup table.
- Semantic consistency improves through adaptive modulation and alignment with vision foundation model features.
- Train-test mismatch in token sequences shrinks after index-level perturbation during decoder fine-tuning.
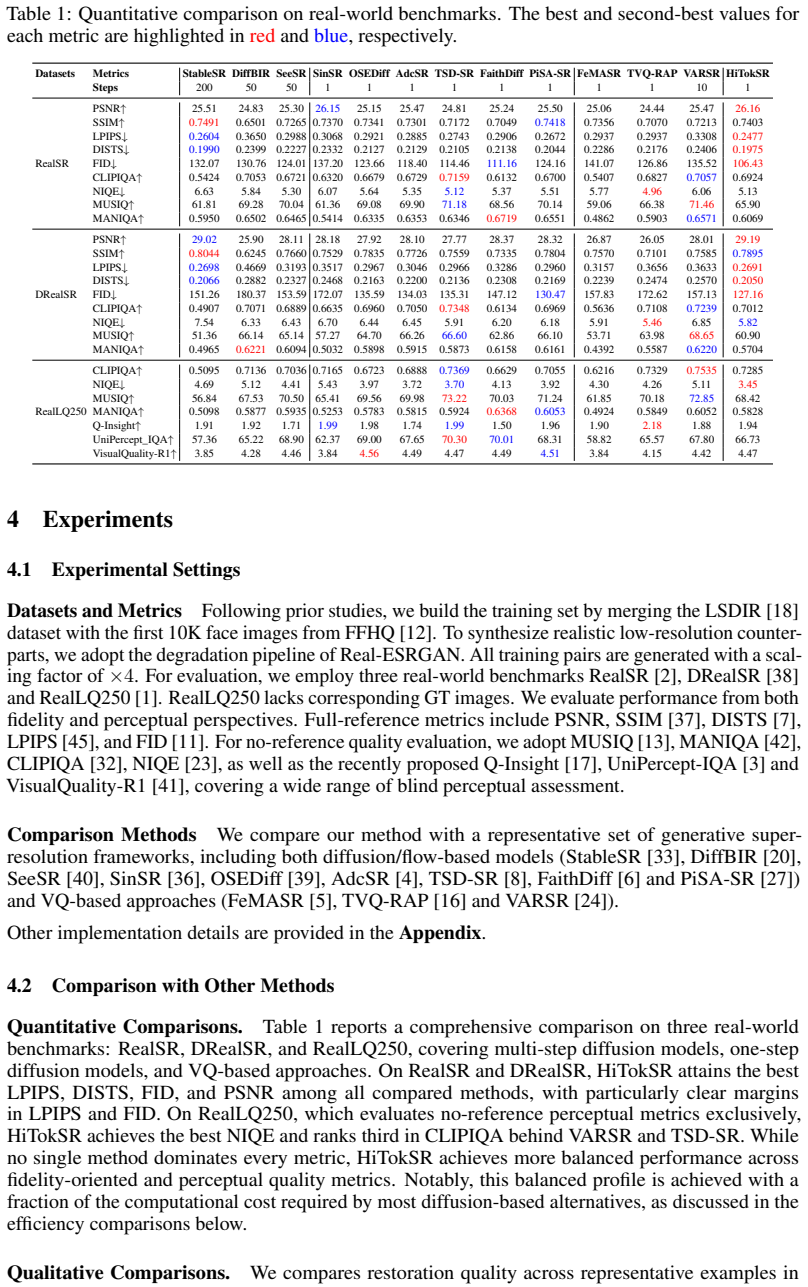
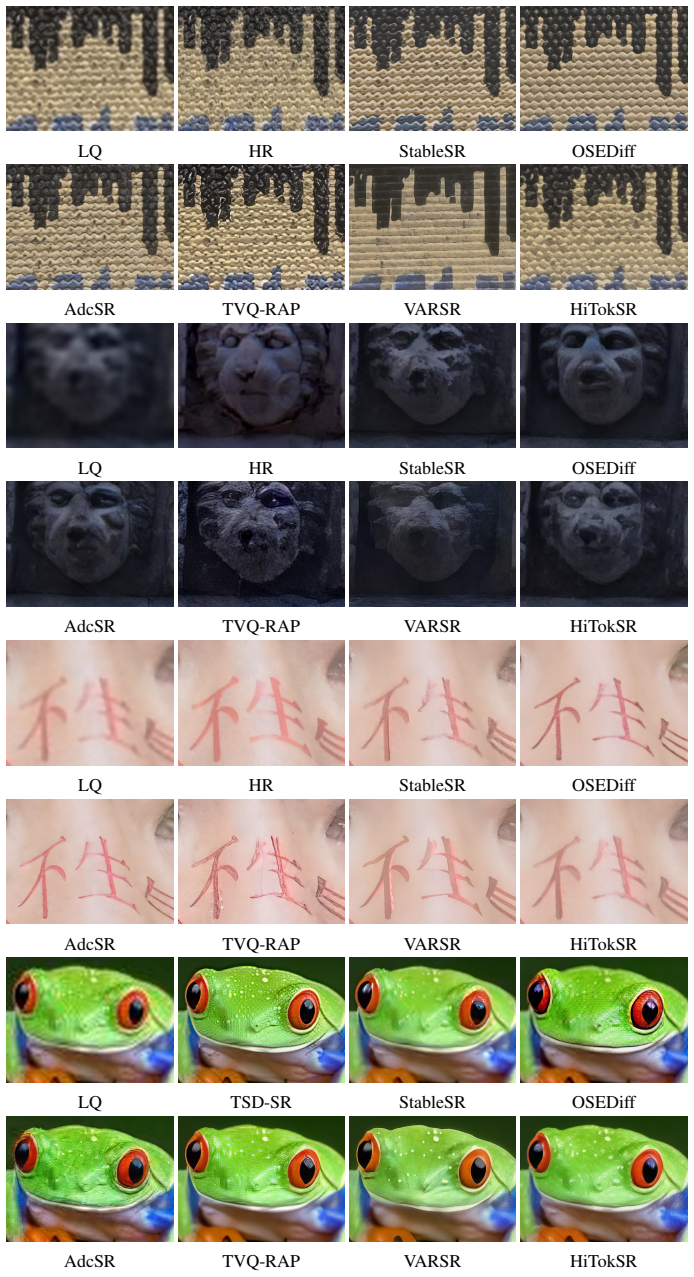
- State-of-the-art scores appear on standard real-world super-resolution benchmarks for both perceptual quality and reconstruction fidelity.
Where Pith is reading between the lines
- The same channel-wise frequency partitioning could be tested in other vector-quantized generative tasks such as unconditional image synthesis.
- Alternative groupings of the latent space, for example learned or spatially organized partitions, could be compared against the frequency split to measure which separation is most effective.
- The index-level perturbation trick might reduce discrepancy in any discrete-token decoder fine-tuning setting, not only super-resolution.
Load-bearing premise
Splitting the latent channels into frequency-aware groups and giving each group its own sub-codebook will separate global structures from fine details and increase the number of usable combinations.
What would settle it
Train a monolithic single-codebook baseline with the same total codebook size and latent dimension on the identical real-world super-resolution benchmarks; if its perceptual and fidelity scores match or exceed HiTokSR, the advantage of the hierarchical split is not demonstrated.
Figures



read the original abstract
Vector-quantized (VQ) generative models have shown promising results in real-world image super-resolution (Real-ISR). However, existing methods typically rely on a monolithic latent space that entangles low-frequency structures with high-frequency textures. This entanglement forces a single codebook to capture a combinatorially complex set of structure-texture pairings, which constrains representational capacity and limits codebook utilization. To address this issue, we present HiTokSR, a hierarchical token prediction framework. Instead of using a single codebook, HiTokSR partitions the latent space along the channel dimension into frequency-aware groups, quantizing each with an independent sub-codebook. This coarse-to-fine design disentangles global structures from fine details, enhancing combinatorial expressiveness while circumventing the optimization instability of high-dimensional nearest-neighbor lookups. To further improve semantic consistency, our generator integrates priors from a vision foundation model via adaptive feature modulation, multi-scale class tokens, and a representation alignment loss. Additionally, we introduce an index-level perturbation strategy during decoder fine-tuning to bridge the train-test discrepancy in discrete token prediction. Extensive experiments on real-world benchmarks demonstrate that HiTokSR achieves state-of-the-art performance in both perceptual quality and reconstruction fidelity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes HiTokSR, a hierarchical token prediction framework for real-world image super-resolution. It replaces a monolithic VQ latent space with channel-wise partitioning into frequency-aware groups, each quantized by an independent sub-codebook, to disentangle global structures from fine details and improve combinatorial expressiveness. The generator incorporates vision foundation model priors via adaptive feature modulation, multi-scale class tokens, and a representation alignment loss; an index-level perturbation strategy is added during decoder fine-tuning. The abstract asserts that these changes yield state-of-the-art performance in both perceptual quality and reconstruction fidelity on real-world benchmarks.
Significance. If the hierarchical design demonstrably improves codebook utilization and the empirical results hold, the work would address a recognized limitation of single-codebook VQ models in handling entangled structure-texture statistics, potentially offering a scalable route to higher-fidelity Real-ISR without increasing codebook size.
major comments (2)
- [Abstract] Abstract: The central modeling claim—that partitioning the latent space along the channel dimension into 'frequency-aware groups' with independent sub-codebooks 'disentangles global structures from fine details'—is presented without any described mechanism (e.g., wavelet-style filters, band-pass losses, or frequency-specific regularization) or post-hoc verification (e.g., spectral analysis of sub-codebook reconstructions) that the resulting channel groups actually align with distinct spatial-frequency bands. Standard VQ encoders do not enforce such separation, so the claimed improvement in combinatorial expressiveness rests on an untested assumption that is load-bearing for the motivation and architecture.
- [Abstract] Abstract: The assertion of 'state-of-the-art performance in both perceptual quality and reconstruction fidelity' is made without any quantitative metrics, comparison tables, ablation studies, or error bars supplied in the manuscript text, rendering the primary empirical claim unverifiable from the provided content.
minor comments (1)
- [Abstract] Abstract: The phrase 'frequency-aware groups' is introduced without a preceding definition or reference to how frequency awareness is realized in the encoder architecture.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and will revise the paper to strengthen the presentation of our claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central modeling claim—that partitioning the latent space along the channel dimension into 'frequency-aware groups' with independent sub-codebooks 'disentangles global structures from fine details'—is presented without any described mechanism (e.g., wavelet-style filters, band-pass losses, or frequency-specific regularization) or post-hoc verification (e.g., spectral analysis of sub-codebook reconstructions) that the resulting channel groups actually align with distinct spatial-frequency bands. Standard VQ encoders do not enforce such separation, so the claimed improvement in combinatorial expressiveness rests on an untested assumption that is load-bearing for the motivation and architecture.
Authors: We agree that the abstract does not detail the mechanism by which channel partitioning produces frequency-aware groups or provide explicit verification such as spectral analysis. The design motivation is that independent sub-codebooks per channel group allow separate modeling of coarse and fine latent components, which our experiments show improves codebook utilization and reconstruction. However, to make this claim more rigorous, we will add in the revision: (i) a precise description of the channel-grouping procedure, and (ii) post-hoc spectral analysis of reconstructions from each sub-codebook to demonstrate frequency separation. revision: yes
-
Referee: [Abstract] Abstract: The assertion of 'state-of-the-art performance in both perceptual quality and reconstruction fidelity' is made without any quantitative metrics, comparison tables, ablation studies, or error bars supplied in the manuscript text, rendering the primary empirical claim unverifiable from the provided content.
Authors: The full manuscript contains quantitative comparisons, ablation studies, and error bars in Section 4 and the associated tables. The abstract summarizes these results at a high level. To improve verifiability directly from the abstract, we will insert the key quantitative metrics (e.g., LPIPS, FID, PSNR on the primary benchmarks) and a reference to the main comparison table in the revised abstract. revision: yes
Circularity Check
No circularity; design is explicit modeling choice with independent empirical claims
full rationale
The paper presents HiTokSR's channel-wise partitioning into frequency-aware groups and independent sub-codebooks as an explicit architectural ansatz to address monolithic latent space entanglement. No equations reduce the claimed disentanglement or performance gains to quantities defined by the partitioning itself, fitted parameters renamed as predictions, or load-bearing self-citations. The derivation chain consists of design decisions justified by stated motivations and benchmark results, without self-referential reductions. This is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Yuang Ai, Xiaoqiang Zhou, Huaibo Huang, Xiaotian Han, Zhengyu Chen, Quanzeng You, and Hongxia Yang. 2024. Dreamclear: High-capacity real-world image restoration with privacy-safe dataset curation. InAdvances in Neural Information Processing Systems 38: Annual Conference on Neural Information Processing Systems 2024, NeurIPS 2024, Vancouver, BC, Canada, De...
2024
-
[2]
Jianrui Cai, Hui Zeng, Hongwei Yong, Zisheng Cao, and Lei Zhang. 2019. Toward real-world single image super-resolution: A new benchmark and a new model. In2019 IEEE/CVF International Conference on Computer Vision, ICCV 2019, Seoul, Korea (South), October 27 - November 2, 2019, pages 3086–3095. IEEE
2019
-
[3]
Shuo Cao, Jiayang Li, Xiaohui Li, Yuandong Pu, Kaiwen Zhu, Yuanting Gao, Siqi Luo, Yi Xin, Qi Qin, Yu Zhou, Xiangyu Chen, Wenlong Zhang, Bin Fu, Yu Qiao, and Yihao Liu. 2025. Unipercept: Towards unified perceptual-level image understanding across aesthetics, quality, structure, and texture.CoRR, abs/2512.21675
-
[4]
Bin Chen, Gehui Li, Rongyuan Wu, Xindong Zhang, Jie Chen, Jian Zhang, and Lei Zhang. 2025. Adver- sarial diffusion compression for real-world image super-resolution. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2025, Nashville, TN, USA, June 11-15, 2025, pages 28208–28220. Computer Vision Foundation / IEEE
2025
-
[5]
Chaofeng Chen, Xinyu Shi, Yipeng Qin, Xiaoming Li, Xiaoguang Han, Tao Yang, and Shihui Guo. 2022. Real-world blind super-resolution via feature matching with implicit high-resolution priors. InMM ’22: The 30th ACM International Conference on Multimedia, Lisboa, Portugal, October 10 - 14, 2022, pages 1329–1338. ACM
2022
-
[6]
Junyang Chen, Jinshan Pan, and Jiangxin Dong. 2025. Faithdiff: Unleashing diffusion priors for faithful image super-resolution. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2025, Nashville, TN, USA, June 11-15, 2025, pages 28188–28197. Computer Vision Foundation / IEEE
2025
-
[7]
Keyan Ding, Kede Ma, Shiqi Wang, and Eero P. Simoncelli. 2020. Image quality assessment: Unifying structure and texture similarity.CoRR, abs/2004.07728
-
[8]
Linwei Dong, Qingnan Fan, Yihong Guo, Zhonghao Wang, Qi Zhang, Jinwei Chen, Yawei Luo, and Changqing Zou. 2025. TSD-SR: one-step diffusion with target score distillation for real-world image super-resolution. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2025, Nashville, TN, USA, June 11-15, 2025, pages 23174–23184. Computer Visio...
2025
-
[9]
Linwei Dong, Qingnan Fan, Yuhang Yu, Qi Zhang, Jinwei Chen, Yawei Luo, and Changqing Zou. 2025. Tinysr: Pruning diffusion for real-world image super-resolution.CoRR, abs/2508.17434
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Patrick Esser, Robin Rombach, and Björn Ommer. 2021. Taming transformers for high-resolution image synthesis. InIEEE Conference on Computer Vision and Pattern Recognition, CVPR 2021, virtual, June 19-25, 2021, pages 12873–12883. Computer Vision Foundation / IEEE
2021
-
[11]
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. 2017. Gans trained by a two time-scale update rule converge to a local nash equilibrium. InAdvances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, December 4-9, 2017, Long Beach, CA, USA, pages 6626–6637
2017
-
[12]
Tero Karras, Samuli Laine, and Timo Aila. 2019. A style-based generator architecture for generative adversarial networks. InIEEE Conference on Computer Vision and Pattern Recognition, CVPR 2019, Long Beach, CA, USA, June 16-20, 2019, pages 4401–4410. Computer Vision Foundation / IEEE
2019
-
[13]
Junjie Ke, Qifei Wang, Yilin Wang, Peyman Milanfar, and Feng Yang. 2021. MUSIQ: multi-scale image quality transformer. In2021 IEEE/CVF International Conference on Computer Vision, ICCV 2021, Montreal, QC, Canada, October 10-17, 2021, pages 5128–5137. IEEE
2021
-
[14]
Aitken, Alykhan Tejani, Johannes Totz, Zehan Wang, and Wenzhe Shi
Christian Ledig, Lucas Theis, Ferenc Huszar, Jose Caballero, Andrew Cunningham, Alejandro Acosta, Andrew P. Aitken, Alykhan Tejani, Johannes Totz, Zehan Wang, and Wenzhe Shi. 2017. Photo-realistic single image super-resolution using a generative adversarial network. In2017 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI...
2017
-
[15]
Doyup Lee, Chiheon Kim, Saehoon Kim, Minsu Cho, and Wook-Shin Han. 2022. Autoregressive image generation using residual quantization. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, June 18-24, 2022, pages 11513–11522. IEEE. 10
2022
- [16]
- [17]
-
[18]
Yawei Li, Kai Zhang, Jingyun Liang, Jiezhang Cao, Ce Liu, Rui Gong, Yulun Zhang, Hao Tang, Yun Liu, Denis Demandolx, Rakesh Ranjan, Radu Timofte, and Luc Van Gool. 2023. LSDIR: A large scale dataset for image restoration. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2023 - Workshops, Vancouver, BC, Canada, June 17-24, 2023, pages...
2023
-
[19]
Jie Liang, Hui Zeng, and Lei Zhang. 2022. Details or artifacts: A locally discriminative learning approach to realistic image super-resolution. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition
2022
- [20]
-
[21]
Xin Luo, Yunan Zhu, Shunxin Xu, and Dong Liu. 2023. On the effectiveness of spectral discriminators for perceptual quality improvement. InICCV
2023
-
[22]
Cheng Ma, Yongming Rao, Yean Cheng, Ce Chen, Jiwen Lu, and Jie Zhou. 2020. Structure-preserving super resolution with gradient guidance. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
2020
-
[23]
completely blind
Anish Mittal, Rajiv Soundararajan, and Alan C. Bovik. 2013. Making a "completely blind" image quality analyzer.IEEE Signal Process. Lett., 20(3):209–212
2013
-
[24]
Yunpeng Qu, Kun Yuan, Jinhua Hao, Kai Zhao, Qizhi Xie, Ming Sun, and Chao Zhou. 2025. Visual autoregressive modeling for image super-resolution. InForty-second International Conference on Machine Learning, ICML 2025, Vancouver, BC, Canada, July 13-19, 2025, Proceedings of Machine Learning Research. PMLR / OpenReview.net
2025
-
[25]
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. 2021. Learning transferable visual models from natural language supervision. InProceedings of the 38th International Conference on Machine Learning, ICML 2021, 18-24 July ...
2021
-
[26]
Oriane Siméoni, Huy V . V o, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seung Eun Yi, Michaël Ramamonjisoa, Francisco Massa, Daniel Haziza, Luca Wehrstedt, Jianyuan Wang, Timothée Darcet, Théo Moutakanni, Leonel Sentana, Claire Roberts, Andrea Vedaldi, and 7 others. 2025. Dinov3.CoRR, abs/2508.10104
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
Lingchen Sun, Rongyuan Wu, Zhiyuan Ma, Shuaizheng Liu, Qiaosi Yi, and Lei Zhang. 2025. Pixel-level and semantic-level adjustable super-resolution: A dual-lora approach. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2025, Nashville, TN, USA, June 11-15, 2025, pages 2333–2343. Computer Vision Foundation / IEEE
2025
-
[28]
Keyu Tian, Yi Jiang, Zehuan Yuan, Bingyue Peng, and Liwei Wang. 2024. Visual autoregressive modeling: Scalable image generation via next-scale prediction. InAdvances in Neural Information Processing Systems 38: Annual Conference on Neural Information Processing Systems 2024, NeurIPS 2024, Vancouver, BC, Canada, December 10 - 15, 2024
2024
-
[29]
Michael Tschannen, Alexey A. Gritsenko, Xiao Wang, Muhammad Ferjad Naeem, Ibrahim Alabdulmohsin, Nikhil Parthasarathy, Talfan Evans, Lucas Beyer, Ye Xia, Basil Mustafa, Olivier J. Hénaff, Jeremiah Harmsen, Andreas Steiner, and Xiaohua Zhai. 2025. Siglip 2: Multilingual vision-language encoders with improved semantic understanding, localization, and dense ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
Aäron van den Oord, Oriol Vinyals, and Koray Kavukcuoglu. 2017. Neural discrete representation learning. InAdvances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, December 4-9, 2017, Long Beach, CA, USA, pages 6306–6315
2017
-
[31]
Gomez, Lukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. InAdvances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, December 4-9, 2017, Long Beach, CA, USA, pages 5998–6008. 11
2017
-
[32]
Jianyi Wang, Kelvin C. K. Chan, and Chen Change Loy. 2023. Exploring CLIP for assessing the look and feel of images. InThirty-Seventh AAAI Conference on Artificial Intelligence, AAAI 2023, Thirty-Fifth Conference on Innovative Applications of Artificial Intelligence, IAAI 2023, Thirteenth Symposium on Educational Advances in Artificial Intelligence, EAAI ...
2023
-
[33]
Jianyi Wang, Zongsheng Yue, Shangchen Zhou, Kelvin C. K. Chan, and Chen Change Loy. 2024. Exploiting diffusion prior for real-world image super-resolution.Int. J. Comput. Vis., 132(12):5929–5949
2024
-
[34]
Xintao Wang, Liangbin Xie, Chao Dong, and Ying Shan. 2021. Real-esrgan: Training real-world blind super-resolution with pure synthetic data. InIEEE/CVF International Conference on Computer Vision Workshops, ICCVW 2021, Montreal, QC, Canada, October 11-17, 2021, pages 1905–1914. IEEE
2021
-
[35]
Xintao Wang, Ke Yu, Shixiang Wu, Jinjin Gu, Yihao Liu, Chao Dong, Yu Qiao, and Chen Change Loy
-
[36]
InComputer Vision - ECCV 2018 Workshops - Munich, Germany, September 8-14, 2018, Proceedings, Part V, volume 11133 ofLecture Notes in Computer Science, pages 63–79
ESRGAN: enhanced super-resolution generative adversarial networks. InComputer Vision - ECCV 2018 Workshops - Munich, Germany, September 8-14, 2018, Proceedings, Part V, volume 11133 ofLecture Notes in Computer Science, pages 63–79. Springer
2018
-
[37]
Kot, and Bihan Wen
Yufei Wang, Wenhan Yang, Xinyuan Chen, Yaohui Wang, Lanqing Guo, Lap-Pui Chau, Ziwei Liu, Yu Qiao, Alex C. Kot, and Bihan Wen. 2024. Sinsr: Diffusion-based image super-resolution in a single step. In IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2024, Seattle, WA, USA, June 16-22, 2024, pages 25796–25805. IEEE
2024
-
[38]
Bovik, Hamid R
Zhou Wang, Alan C. Bovik, Hamid R. Sheikh, and Eero P. Simoncelli. 2004. Image quality assessment: from error visibility to structural similarity.IEEE Trans. Image Process., 13(4):600–612
2004
-
[39]
Pengxu Wei, Ziwei Xie, Hannan Lu, Zongyuan Zhan, Qixiang Ye, Wangmeng Zuo, and Liang Lin. 2020. Component divide-and-conquer for real-world image super-resolution. InComputer Vision - ECCV 2020 - 16th European Conference, Glasgow, UK, August 23-28, 2020, Proceedings, Part VIII, volume 12353 of Lecture Notes in Computer Science, pages 101–117. Springer
2020
-
[40]
Rongyuan Wu, Lingchen Sun, Zhiyuan Ma, and Lei Zhang. 2024. One-step effective diffusion network for real-world image super-resolution. InAdvances in Neural Information Processing Systems 38: Annual Conference on Neural Information Processing Systems 2024, NeurIPS 2024, Vancouver, BC, Canada, December 10 - 15, 2024
2024
-
[41]
Rongyuan Wu, Tao Yang, Lingchen Sun, Zhengqiang Zhang, Shuai Li, and Lei Zhang. 2024. Seesr: Towards semantics-aware real-world image super-resolution. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2024, Seattle, WA, USA, June 16-22, 2024, pages 25456–25467. IEEE
2024
- [42]
-
[43]
Sidi Yang, Tianhe Wu, Shuwei Shi, Shanshan Lao, Yuan Gong, Mingdeng Cao, Jiahao Wang, and Yujiu Yang. 2022. MANIQA: multi-dimension attention network for no-reference image quality assessment. In IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, CVPR Workshops 2022, New Orleans, LA, USA, June 19-20, 2022, pages 1190–1199. IEEE
2022
-
[44]
Zongsheng Yue, Jianyi Wang, and Chen Change Loy. 2023. Resshift: Efficient diffusion model for image super-resolution by residual shifting. InAdvances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023
2023
- [45]
-
[46]
Efros, Eli Shechtman, and Oliver Wang
Richard Zhang, Phillip Isola, Alexei A. Efros, Eli Shechtman, and Oliver Wang. 2018. The unreasonable effectiveness of deep features as a perceptual metric. In2018 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2018, Salt Lake City, UT, USA, June 18-22, 2018, pages 586–595. Computer Vision Foundation / IEEE Computer Society
2018
-
[47]
Shangchen Zhou, Kelvin C. K. Chan, Chongyi Li, and Chen Change Loy. 2022. Towards robust blind face restoration with codebook lookup transformer. InAdvances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, NeurIPS 2022, New Orleans, LA, USA, November 28 - December 9, 2022
2022
-
[48]
Lei Zhu, Fangyun Wei, Yanye Lu, and Dong Chen. 2024. Scaling the codebook size of VQGAN to 100,000 with a utilization rate of 99%.CoRR, abs/2406.11837. 12 A Implementation details We present the full training configuration of HiTokSR across its three stages (Tokenizer, Generator, and Decoder) in Table 6. All stages share the same dataset, patch ratio, and...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.