Linear Strategic Classification with Endogenous Improvements
Pith reviewed 2026-06-28 17:52 UTC · model grok-4.3
The pith
The strategic-optimal classifier for endogenous improvements is a parallel shift of the Bayes-optimal decision boundary.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
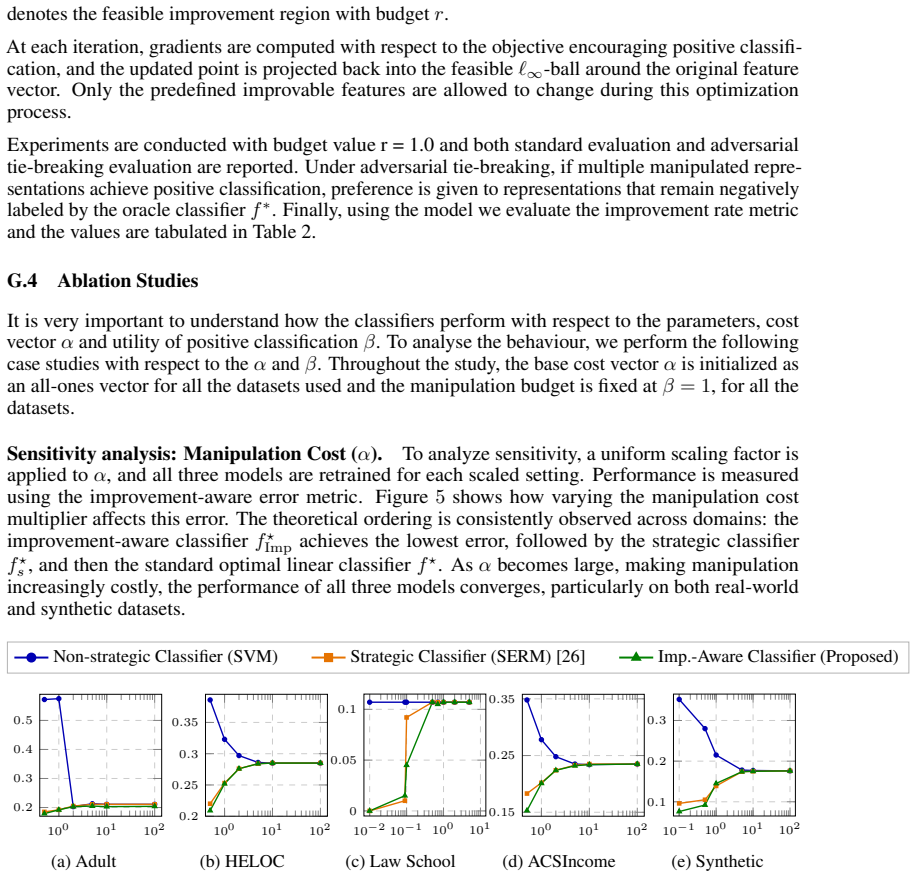
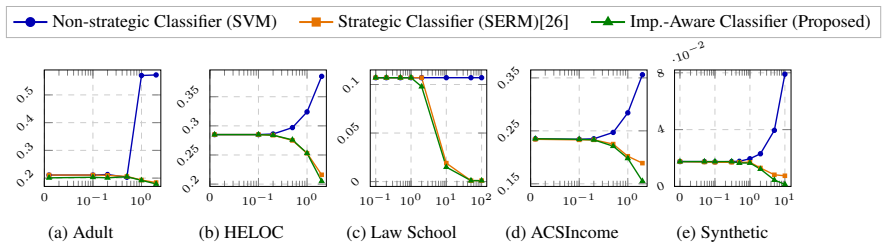
Under the single-index qualification model and linear-decomposable costs, the strategic-optimal classifier is obtained by a parallel shift of the Bayes-optimal decision boundary, and this classifier provides a better surrogate for the improvement-aware objective than the Bayes classifier. Since improvement-aware learning requires post-deployment labels that are typically unavailable before deployment, PAC-style guarantees are provided under an oracle model, a practical plug-in algorithm is proposed, its generalization bound is established, and the method is evaluated on synthetic and real-world datasets.
What carries the argument
Parallel shift of the Bayes-optimal decision boundary, which preserves the linear direction while adjusting the threshold to account for agents' genuine post-deployment improvements.
If this is right
- The shifted classifier outperforms the Bayes classifier as a surrogate for the improvement-aware objective.
- PAC-style guarantees apply when learning proceeds under an oracle model for post-deployment labels.
- A plug-in algorithm achieves the stated generalization bound in practice.
- The approach is validated through evaluation on both synthetic and real-world datasets.
Where Pith is reading between the lines
- The parallel-shift structure may extend to other model families if the single-index assumption is relaxed in a controlled way.
- Accounting for endogenous improvements this way could increase overall agent welfare by rewarding real changes rather than gaming.
- The framework connects to broader questions of how classifiers should internalize agents' capacity to alter their own labels.
Load-bearing premise
Labels continue to be generated by the same conditional outcome law after agents strategically select their post-deployment feature vectors.
What would settle it
A dataset in which post-deployment labels deviate from the pre-deployment conditional law after strategic feature changes would show that the parallel-shift property fails to hold.
Figures
read the original abstract
Strategic classification studies settings in which agents respond to a deployed classifier by modifying observable features at a cost. Classical models typically treat such responses as cosmetic: features may change, but true labels remain fixed. We study an improvement-aware variant in which strategic responses can induce genuine changes in outcome-relevant features. Agents choose post-deployment feature vectors strategically, and labels are then generated according to a stable conditional outcome law that preserves the relationship between features and outcomes. We formalize this problem for linear classifiers under a single-index qualification model and linear-decomposable costs. We show that the strategic-optimal classifier is obtained by a parallel shift of the Bayes-optimal decision boundary, and that it provides a better surrogate for the improvement-aware objective than the Bayes classifier. Since improvement-aware learning requires post-deployment labels, which are typically unavailable before deployment, we provide PAC-style guar- antees under an oracle model, propose a practical plug-in algorithm, establish its generalization bound, and evaluate it on synthetic and real-world datasets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper formalizes improvement-aware strategic classification, where agents' feature modifications can induce genuine outcome changes. Under a single-index qualification model with linear-decomposable costs, it claims the strategic-optimal classifier is exactly a parallel shift of the Bayes-optimal boundary (and a better surrogate for the improvement-aware objective). It provides PAC-style guarantees under an oracle model for post-deployment labels, proposes a plug-in algorithm with a generalization bound, and evaluates on synthetic and real-world data.
Significance. If the parallel-shift characterization holds under the model assumptions, the result offers a simple, interpretable adjustment to standard classifiers that accounts for endogenous improvements without requiring full post-deployment retraining. The oracle-based PAC guarantees and practical algorithm address a key practical barrier in improvement-aware learning, representing a targeted advance in strategic classification.
major comments (2)
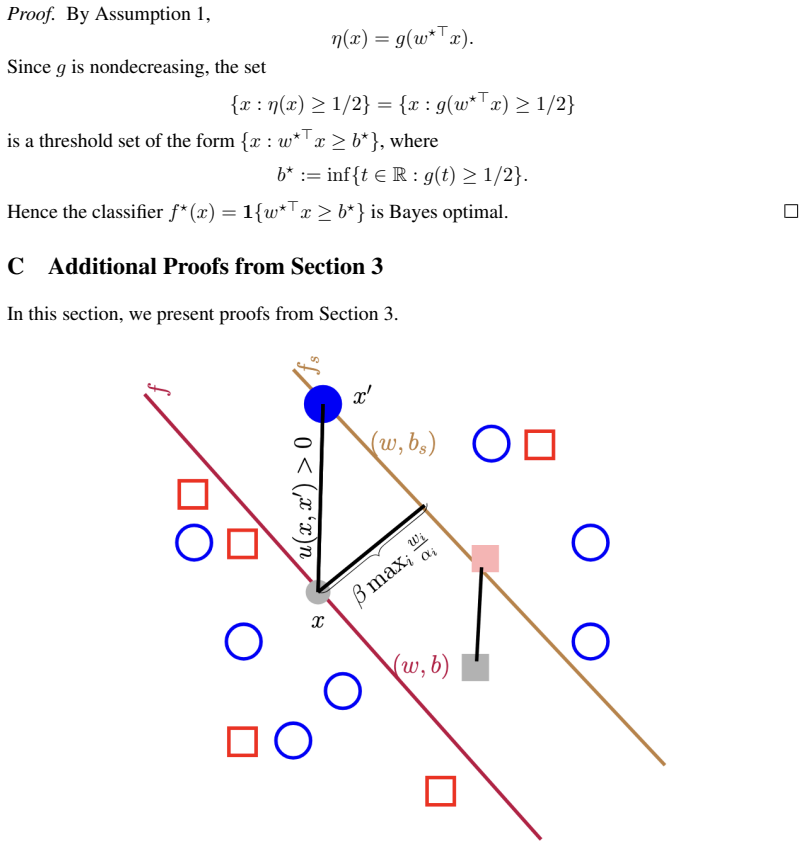
- [Abstract / Model section] Abstract / Model section: The parallel-shift result and the claim that the shifted classifier is a better surrogate are derived under the assumption that labels are generated according to a 'stable conditional outcome law that preserves the relationship between features and outcomes' after agents apply their best-response map. No explicit verification is given that this invariance holds post-strategy (as opposed to holding only on the original distribution), which directly affects whether the improvement-aware objective equals the shifted threshold. This is load-bearing for the central claim.
- [PAC guarantees section] PAC guarantees section: The oracle model for PAC-style guarantees assumes access to post-deployment labels under the stable law, but the generalization bound for the plug-in algorithm should explicitly quantify sensitivity to violations of the invariance (e.g., via a robustness term); without this, the bound may not transfer to the endogenous-improvement setting.
minor comments (2)
- [Abstract] The abstract states the shift result but does not preview the key steps (e.g., how linear-decomposable costs yield the exact parallel form); a one-sentence outline would improve readability.
- [Model section] Notation for the single-index qualification model should be introduced with an explicit equation reference in the model section to avoid ambiguity when comparing to the Bayes boundary.
Simulated Author's Rebuttal
We thank the referee for their careful reading and insightful comments. We address the two major comments in turn.
read point-by-point responses
-
Referee: The parallel-shift result and the claim that the shifted classifier is a better surrogate are derived under the assumption that labels are generated according to a 'stable conditional outcome law that preserves the relationship between features and outcomes' after agents apply their best-response map. No explicit verification is given that this invariance holds post-strategy (as opposed to holding only on the original distribution), which directly affects whether the improvement-aware objective equals the shifted threshold. This is load-bearing for the central claim.
Authors: The model explicitly assumes that the stable conditional outcome law applies after the agents' best-response modifications, as described in the model section. This assumption ensures the invariance holds post-strategy by definition. The parallel-shift characterization is derived under this model. We will revise the text to make this assumption more prominent and add a sentence clarifying its role in the post-deployment setting. revision: yes
-
Referee: The oracle model for PAC-style guarantees assumes access to post-deployment labels under the stable law, but the generalization bound for the plug-in algorithm should explicitly quantify sensitivity to violations of the invariance (e.g., via a robustness term); without this, the bound may not transfer to the endogenous-improvement setting.
Authors: Our PAC guarantees and the generalization bound are established under the oracle model that incorporates the stable law. While we agree that analyzing robustness to violations of the invariance would be valuable, it would require additional modeling of potential deviations, which is beyond the scope of this work. We will add a remark in the discussion section acknowledging this limitation of the bound. revision: partial
Circularity Check
No significant circularity; derivation is self-contained from stated assumptions
full rationale
The paper states its modeling assumptions explicitly (stable conditional outcome law P(Y|X) that preserves relationships post-strategic change, single-index qualification model, linear-decomposable costs) and derives the parallel-shift result for the strategic-optimal classifier from those assumptions. No quoted step reduces the claimed result to a fitted parameter, self-referential definition, or load-bearing self-citation; the improvement-aware objective and Bayes classifier are treated as distinct quantities whose comparison follows from the model. The PAC guarantees and plug-in algorithm are presented as separate contributions with generalization bounds, not as tautological restatements of inputs. This is the normal case of a model-derived claim under explicit assumptions.
Axiom & Free-Parameter Ledger
axioms (3)
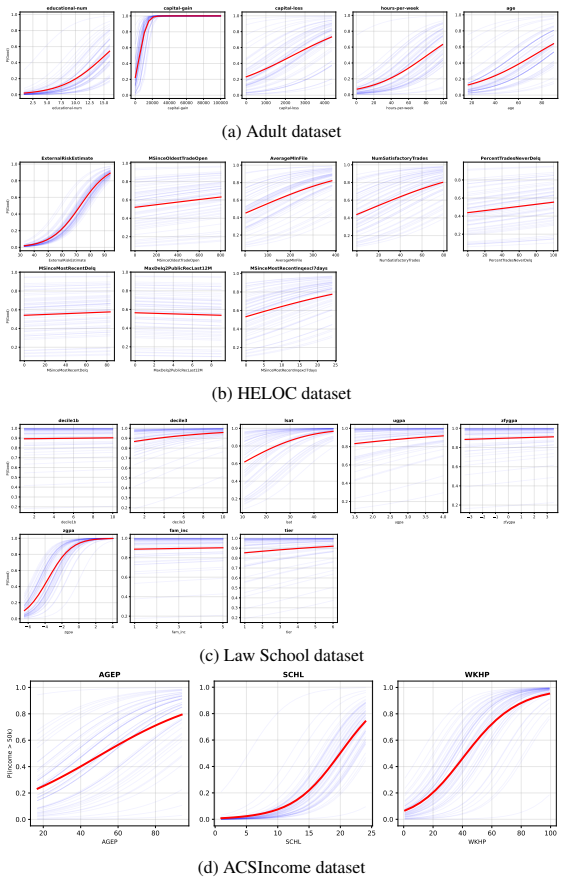
- domain assumption Single-index qualification model
- domain assumption Linear-decomposable costs
- domain assumption Stable conditional outcome law that preserves the feature-outcome relationship post-response
Reference graph
Works this paper leans on
-
[1]
Saba Ahmadi, Hedyeh Beyhaghi, Avrim Blum, and Keziah Naggita. The strategic perceptron. In Proceedings of the 22nd ACM Conference on Economics and Computation, EC ’21, page 6–25, New York, NY , USA, 2021. Association for Computing Machinery. ISBN 9781450385541. doi: 10.1145/3465456.3467629. URLhttps://doi.org/10.1145/3465456.3467629
-
[2]
arXiv preprint arXiv:2203.00124 , year=
Saba Ahmadi, Hedyeh Beyhaghi, Avrim Blum, and Keziah Naggita. On classification of strategic agents who can both game and improve.arXiv preprint arXiv:2203.00124, 2022
-
[3]
Fundamental bounds on online strategic classifi- cation
Saba Ahmadi, Avrim Blum, and Kunhe Yang. Fundamental bounds on online strategic classifi- cation. InProceedings of the 24th ACM Conference on Economics and Computation, pages 22–58, 2023
2023
-
[4]
arXiv preprint arXiv:2505.05594 , year=
Sura Alhanouti and Parinaz Naghizadeh. Anticipating gaming to incentivize improvement: Guiding agents in (fair) strategic classification.arXiv preprint arXiv:2505.05594, 2025
-
[5]
Pac learning with improvements.arXiv preprint arXiv:2503.03184, 2025
Idan Attias, Avrim Blum, Keziah Naggita, Donya Saless, Dravyansh Sharma, and Matthew Walter. Pac learning with improvements.arXiv preprint arXiv:2503.03184, 2025
-
[6]
Fast learning rates for plug-in classifiers
Jean-Yves Audibert and Alexandre B Tsybakov. Fast learning rates for plug-in classifiers. 2007
2007
-
[7]
Gaming helps! learning from strategic interactions in natural dynamics
Yahav Bechavod, Katrina Ligett, Steven Wu, and Juba Ziani. Gaming helps! learning from strategic interactions in natural dynamics. InInternational Conference on Artificial Intelligence and Statistics, pages 1234–1242. PMLR, 2021
2021
-
[8]
Barry Becker and Ronny Kohavi. Adult. UCI Machine Learning Repository, 1996. DOI: https://doi.org/10.24432/C5XW20
-
[9]
HELOC Applicant Risk Performance Evaluation by Topological Hierarchical Decomposition
Kyle Brown, Derek Doran, Ryan Kramer, and Brad Reynolds. Heloc applicant risk performance evaluation by topological hierarchical decomposition, 2018. URL https://arxiv.org/abs/ 1811.10658
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[10]
Learning to incentivize improvements from strategic agents.Transactions on Machine Learning Research, 2023
Yatong Chen, Jialu Wang, and Yang Liu. Learning to incentivize improvements from strategic agents.Transactions on Machine Learning Research, 2023
2023
-
[11]
Sequential strategic screening
Lee Cohen, Saeed Sharifi-Malvajerdi, Kevin Stangl, Ali Vakilian, and Juba Ziani. Sequential strategic screening. InInternational Conference on Machine Learning, pages 6279–6295. PMLR, 2023
2023
-
[12]
Learnability gaps of strategic classification
Lee Cohen, Yishay Mansour, Shay Moran, and Han Shao. Learnability gaps of strategic classification. InThe Thirty Seventh Annual Conference on Learning Theory, pages 1223–1259. PMLR, 2024
2024
-
[13]
Retiring adult: New datasets for fair machine learning, 2022
Frances Ding, Moritz Hardt, John Miller, and Ludwig Schmidt. Retiring adult: New datasets for fair machine learning, 2022. URLhttps://arxiv.org/abs/2108.04884
-
[14]
Strategic classification from revealed preferences
Jinshuo Dong, Aaron Roth, Zachary Schutzman, Bo Waggoner, and Zhiwei Steven Wu. Strategic classification from revealed preferences. InProceedings of the 2018 ACM Conference on Economics and Computation, pages 55–70, 2018
2018
-
[15]
Valia Efthymiou, Ekaterina Fedorova, and Chara Podimata. Desirable effort fairness and optimality trade-offs in strategic learning.arXiv preprint arXiv:2510.19098, 2025. 10
-
[16]
arXiv preprint arXiv:2502.06749 , year=
Valia Efthymiou, Chara Podimata, Diptangshu Sen, and Juba Ziani. Incentivizing desirable effort profiles in strategic classification: The role of causality and uncertainty.arXiv preprint arXiv:2502.06749, 2025
-
[17]
Strategic classification in the dark
Ganesh Ghalme, Vineet Nair, Itay Eilat, Inbal Talgam-Cohen, and Nir Rosenfeld. Strategic classification in the dark. In Marina Meila and Tong Zhang, editors,Proceedings of the 38th International Conference on Machine Learning, volume 139 ofProceedings of Machine Learning Research, pages 3672–3681. PMLR, 18–24 Jul 2021. URL https://proceedings. mlr.press/v...
2021
-
[18]
arXiv preprint arXiv:2011.01956 , year=
Nika Haghtalab, Nicole Immorlica, Brendan Lucier, and Jack Z Wang. Maximizing welfare with incentive-aware evaluation mechanisms.arXiv preprint arXiv:2011.01956, 2020
-
[19]
Strategic classi- fication
Moritz Hardt, Nimrod Megiddo, Christos Papadimitriou, and Mary Wootters. Strategic classi- fication. InProceedings of the 2016 ACM conference on innovations in theoretical computer science, pages 111–122, 2016
2016
-
[20]
Causal strategic classification: A tale of two shifts
Guy Horowitz and Nir Rosenfeld. Causal strategic classification: A tale of two shifts. In International Conference on Machine Learning, pages 13233–13253. PMLR, 2023
2023
-
[21]
Ziyuan Huang, Lina Alkarmi, and Mingyan Liu. Multi-level strategic classification: Incentiviz- ing improvement through promotion and relegation dynamics.arXiv preprint arXiv:2602.11439, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[22]
Incentive mechanisms for strategic classification and regression problems
Kun Jin, Xueru Zhang, Mohammad Mahdi Khalili, Parinaz Naghizadeh, and Mingyan Liu. Incentive mechanisms for strategic classification and regression problems. InProceedings of the 23rd ACM Conference on Economics and Computation, pages 760–790, 2022
2022
-
[23]
How do classifiers induce agents to invest effort strategi- cally?ACM Transactions on Economics and Computation (TEAC), 8(4):1–23, 2020
Jon Kleinberg and Manish Raghavan. How do classifiers induce agents to invest effort strategi- cally?ACM Transactions on Economics and Computation (TEAC), 8(4):1–23, 2020
2020
-
[24]
Strategic classification made practical: reproduction
Guilly Kolkman, Maks kulicki, Jan Athmer, and Alex Labro. Strategic classification made practical: reproduction. InML Reproducibility Challenge 2021 (Fall Edition), 2022. URL https://openreview.net/forum?id=rNgg03fXnRY
2021
-
[25]
Tai Le Quy, Arjun Roy, Vasileios Iosifidis, Wenbin Zhang, and Eirini Ntoutsi. A sur- vey on datasets for fairness-aware machine learning.WIREs Data Mining and Knowl- edge Discovery, 12(3):e1452, 2022. doi: https://doi.org/10.1002/widm.1452. URL https: //wires.onlinelibrary.wiley.com/doi/abs/10.1002/widm.1452
-
[26]
Generalized strategic classification and the case of aligned incentives
Sagi Levanon and Nir Rosenfeld. Generalized strategic classification and the case of aligned incentives. InInternational Conference on Machine Learning, pages 12593–12618. PMLR, 2022
2022
-
[27]
Strategic classification is causal modeling in disguise
John Miller, Smitha Milli, and Moritz Hardt. Strategic classification is causal modeling in disguise. InInternational Conference on Machine Learning, pages 6917–6926. PMLR, 2020
2020
-
[28]
The social cost of strategic classification
Smitha Milli, John Miller, Anca D Dragan, and Moritz Hardt. The social cost of strategic classification. InProceedings of the conference on fairness, accountability, and transparency, pages 230–239, 2019
2019
-
[29]
Performative prediction
Juan Perdomo, Tijana Zrnic, Celestine Mendler-Dünner, and Moritz Hardt. Performative prediction. InInternational Conference on Machine Learning, pages 7599–7609. PMLR, 2020
2020
-
[30]
Strategic classification under unknown person- alized manipulation.Advances in Neural Information Processing Systems, 36:26452–26484, 2023
Han Shao, Avrim Blum, and Omar Montasser. Strategic classification under unknown person- alized manipulation.Advances in Neural Information Processing Systems, 36:26452–26484, 2023
2023
-
[31]
Dravyansh Sharma and Alec Sun. Conservative classifiers do consistently well with improving agents: characterizing statistical and online learning.arXiv preprint arXiv:2506.05252, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
Pac-learning for strategic classifica- tion.Journal of Machine Learning Research, 24(192):1–38, 2023
Ravi Sundaram, Anil Vullikanti, Haifeng Xu, and Fan Yao. Pac-learning for strategic classifica- tion.Journal of Machine Learning Research, 24(192):1–38, 2023. 11
2023
-
[33]
Actionable recourse in linear classification
Berk Ustun, Alexander Spangher, and Yang Liu. Actionable recourse in linear classification. InProceedings of the conference on fairness, accountability, and transparency, pages 10–19, 2019
2019
-
[34]
Algorithmic decision-making under agents with persistent improvement
Tian Xie, Xuwei Tan, and Xueru Zhang. Algorithmic decision-making under agents with persistent improvement. InProceedings of the AAAI/ACM Conference on AI, Ethics, and Society, volume 7, pages 1672–1683, 2024
2024
-
[35]
Tian Xie, Zhiqun Zuo, Mohammad Mahdi Khalili, and Xueru Zhang. Learning under imitative strategic behavior with unforeseeable outcomes.arXiv preprint arXiv:2405.01797, 2024
-
[36]
Nonparametric logistic regression with deep learning
Atsutomo Yara and Yoshikazu Terada. Nonparametric logistic regression with deep learning. Bernoulli, 32(2):952–977, 2026
2026
-
[37]
Incentive-aware pac learning
Hanrui Zhang and Vincent Conitzer. Incentive-aware pac learning. InProceedings of the AAAI Conference on Artificial Intelligence, volume 35, pages 5797–5804, 2021. 12 A Notation Table 3: Notation used in the paper. Notation Description X ⊆R d Valid feature space; both original features and reported/post-response features lie inX. X0 = supp(D)⊆ XSupport of...
2021
-
[38]
The details of the implementations as follows
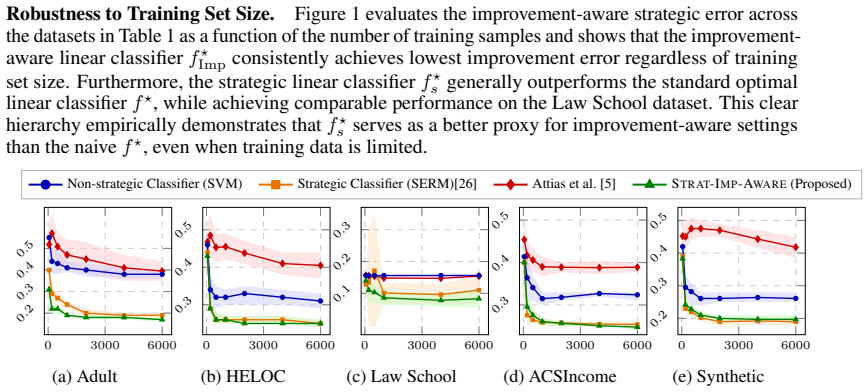
and an Improvement aware classifier from Attias et al.[5] and use them for performance analysis of our Improvement aware classifier STRAT-IMP-AWARE. The details of the implementations as follows. SERM [26]:We implement a strategic learning baseline that explicitly accounts for feature ma- nipulation under the decomposable cost framework. Let the classifie...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.