Can LLM Agents Sustain Long-Horizon Organizational Dynamics?
Pith reviewed 2026-06-28 17:19 UTC · model grok-4.3
The pith
A memory cycle enables LLM agents to sustain coherent behavior in long-horizon organizational simulations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
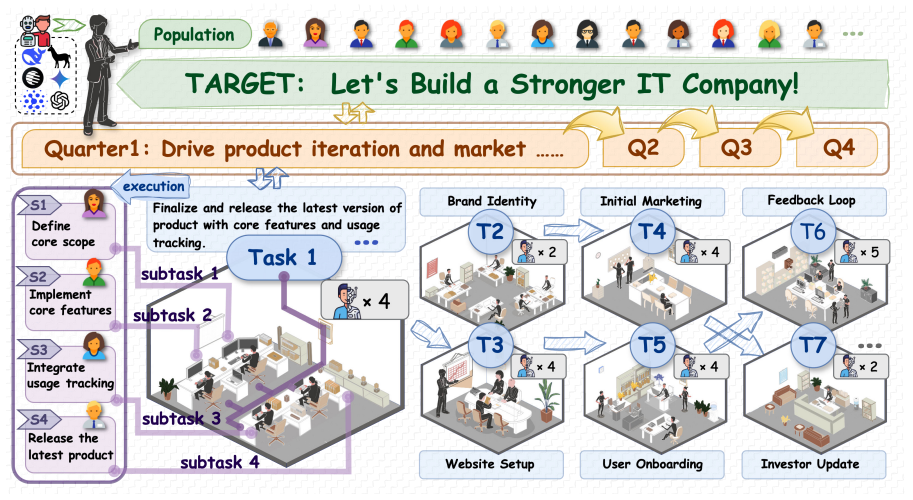
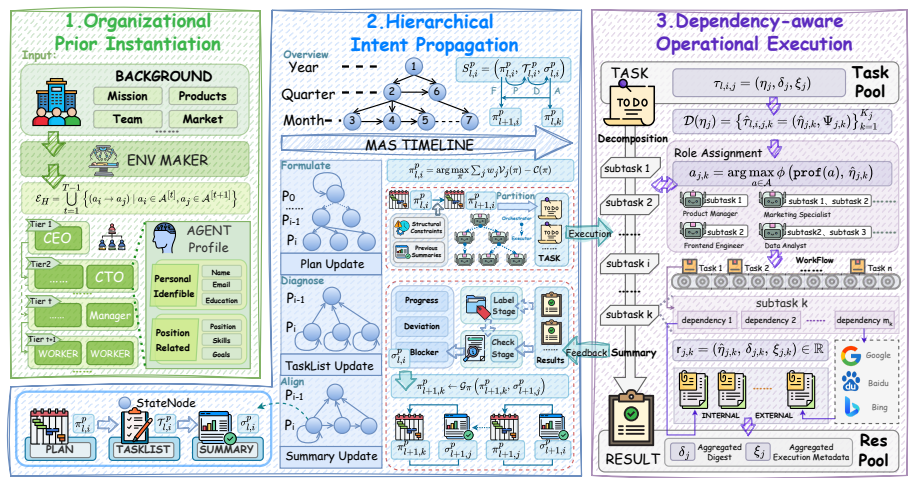
TaskWeave supports coherent and long-horizon organizational dynamics in LLM agent simulations through a Formulate-Partition-Diagnose-Align cycle for planning states and dependency-aware trace memory for execution grounding, leading to improved organizational coherence, grounded artifacts, and adaptation in a year-long IT company simulation.
What carries the argument
The Formulate-Partition-Diagnose-Align cycle and dependency-aware trace memory, which together maintain planning states and ground execution in hierarchical coordination.
If this is right
- Coherent organizational behavior emerges over long time horizons.
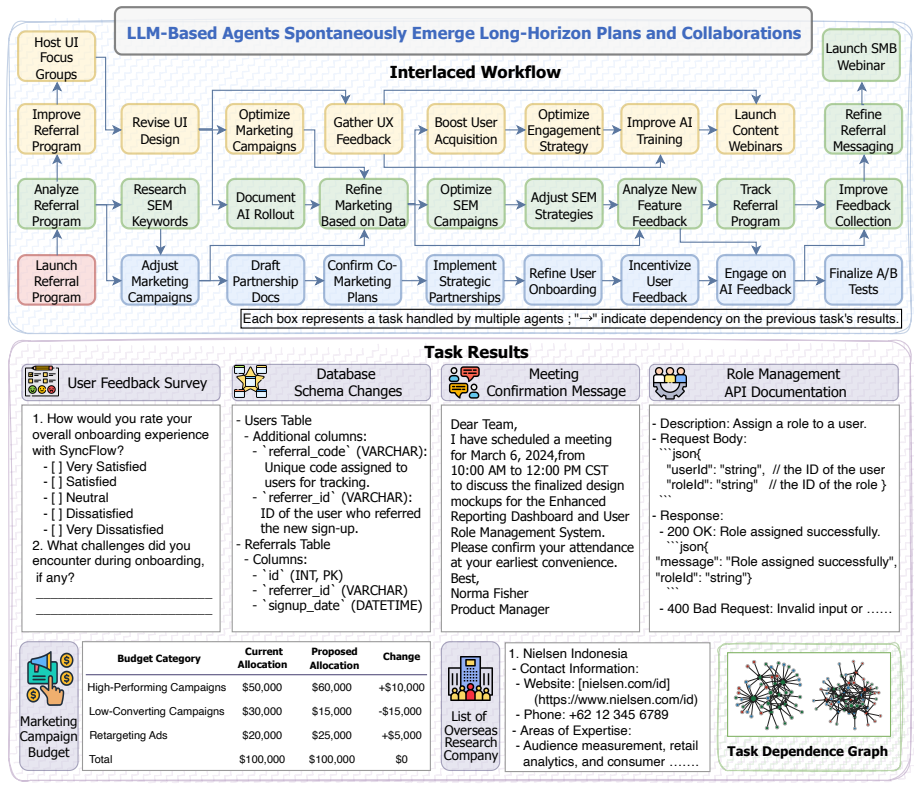
- Execution produces grounded and usable artifacts.
- The framework adapts to external environment changes.
- Downstream enterprise NLP tasks gain utility from the simulation outputs.
Where Pith is reading between the lines
- Memory structures like this could extend to simulations of other types of organizations.
- Testing with simulations longer than one year could expose scalability issues.
- Connecting the simulation to real external data sources might better validate adaptation.
Load-bearing premise
Success in a single year-long IT company simulation accurately measures the ability to sustain real-world organizational dynamics.
What would settle it
Observing a breakdown in coherence when TaskWeave is applied to a simulation exceeding one year or in a non-IT domain.
Figures



read the original abstract
Large language agents are increasingly used for social simulation, yet it remains unclear whether they can sustain coherent behavior in structured organizations, where goals must propagate through hierarchy, tasks depend on prior execution, and artifacts accumulate over long horizons. We formulate long-horizon organizational simulation as a memory-centered coordination problem and introduce TaskWeave, a hierarchical agentic framework that maintains planning states through a Formulate-Partition-Diagnose-Align cycle and grounds execution through dependency-aware trace memory. We evaluate TaskWeave in a year-long IT company simulation and compare it with other multi-agent frameworks on organizational coherence, execution grounding, and downstream enterprise NLP utility. Experiments show that TaskWeave supports coherent and long-horizon organizational dynamics while producing grounded artifacts and adapting to external environments. These findings suggest that structured simulation memory is a key mechanism for building reliable LLM-based organizational simulators.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper formulates long-horizon organizational simulation as a memory-centered coordination problem and introduces TaskWeave, a hierarchical agentic framework that uses a Formulate-Partition-Diagnose-Align cycle together with dependency-aware trace memory. It evaluates the framework in a year-long IT company simulation, reporting that TaskWeave achieves superior organizational coherence, execution grounding, and downstream enterprise NLP utility relative to other multi-agent frameworks, and concludes that structured simulation memory is key for reliable LLM-based organizational simulators.
Significance. If the experimental results prove robust and the simulation is shown not to embed design biases favoring the proposed mechanisms, the work would be significant for multi-agent LLM research by supplying a concrete, memory-centric architecture and an extended simulation testbed that could serve as a benchmark for long-horizon coordination.
major comments (3)
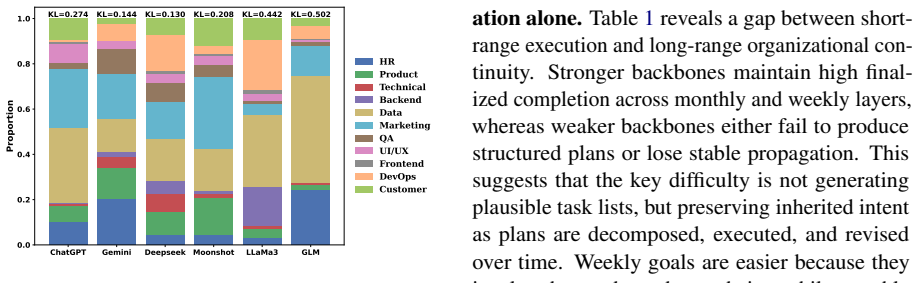
- [Abstract / Experiments] Abstract and Experiments section: The abstract asserts positive comparative results on organizational coherence, execution grounding, and downstream NLP utility, yet supplies no quantitative metrics, baseline implementations, statistical tests, or controls. This absence is load-bearing for the central claim that TaskWeave sustains long-horizon dynamics.
- [Experiments] Experiments section: No information is given on how external events, task dependencies, or artifact accumulation were generated in the year-long IT simulation, nor whether the environment or rubrics were tuned after observing baseline failures. Without such details or an ablation isolating the Formulate-Partition-Diagnose-Align cycle and trace memory from generic prompting or shared state, it is impossible to rule out that observed gains arise from simulation construction rather than the proposed mechanisms.
- [Experiments] Experiments section: The paper reports no ablation studies that remove or replace the dependency-aware trace memory while keeping other components fixed, leaving the contribution of the memory mechanism unisolated.
minor comments (2)
- [Abstract] The phrase 'grounded artifacts' is used repeatedly but never given an operational definition or measurement procedure.
- [Experiments] The downstream enterprise NLP utility task is mentioned but its construction, data, and evaluation protocol are not described.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments regarding experimental transparency and controls. We address each major point below and will make targeted revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract and Experiments section: The abstract asserts positive comparative results on organizational coherence, execution grounding, and downstream NLP utility, yet supplies no quantitative metrics, baseline implementations, statistical tests, or controls. This absence is load-bearing for the central claim that TaskWeave sustains long-horizon dynamics.
Authors: The experiments section contains quantitative comparisons against other multi-agent frameworks, including tables reporting coherence, grounding, and utility scores along with baseline implementations. The abstract, however, is written at a summary level without specific numbers. We will revise the abstract to include representative quantitative metrics and note the presence of statistical comparisons in the main text. revision: partial
-
Referee: [Experiments] Experiments section: No information is given on how external events, task dependencies, or artifact accumulation were generated in the year-long IT simulation, nor whether the environment or rubrics were tuned after observing baseline failures. Without such details or an ablation isolating the Formulate-Partition-Diagnose-Align cycle and trace memory from generic prompting or shared state, it is impossible to rule out that observed gains arise from simulation construction rather than the proposed mechanisms.
Authors: We will add a new subsection in Experiments that fully specifies the stochastic generation process for external events, the dependency graph construction for tasks, and the artifact logging mechanism. We will also explicitly state that the simulation parameters and rubrics were fixed before any agent runs and were not adjusted after observing baseline performance. In addition, we will include an ablation comparing the full Formulate-Partition-Diagnose-Align cycle against a generic prompting baseline with shared state only. revision: yes
-
Referee: [Experiments] Experiments section: The paper reports no ablation studies that remove or replace the dependency-aware trace memory while keeping other components fixed, leaving the contribution of the memory mechanism unisolated.
Authors: We agree that an explicit ablation isolating the dependency-aware trace memory is necessary. We will add results from a controlled ablation in which the trace memory is replaced by a standard shared memory buffer (while retaining the planning cycle and all other components) and report the resulting impact on long-horizon coherence metrics. revision: yes
Circularity Check
No circularity: empirical evaluation is external to framework definition
full rationale
The paper formulates organizational simulation as a memory-centered coordination problem and introduces TaskWeave with its Formulate-Partition-Diagnose-Align cycle plus trace memory. It then reports results from a year-long IT company simulation on external metrics (coherence, grounding, NLP utility). No equations, fitted parameters, or 'predictions' are described that reduce by construction to the framework's own definitions or inputs. No self-citation chains, uniqueness theorems, or ansatzes are invoked as load-bearing. The simulation is presented as an independent test environment; any concerns about its construction favoring the method fall under validity rather than circular derivation. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM agents can sustain coherent organizational behavior when equipped with explicit hierarchical planning cycles and dependency-aware memory
invented entities (1)
-
TaskWeave framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Autogen: Enabling next-gen llm applica- tions via multi-agent conversation.arXiv preprint arXiv:2308.08155. Tianbao Xie, Danyang Zhang, Jixuan Chen, Xiaochuan Li, Siheng Zhao, Ruisheng Cao, Toh Jing Hua, Zhou- jun Cheng, Dongchan Shin, Fangyu Lei, Yitao Liu, Yiheng Xu, Shuyan Zhou, Silvio Savarese, Caiming Xiong, Victor Zhong, and Tao Yu. 2024. OSWorld: B...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
arXiv preprint arXiv:2410.11782 , year=
Graph-of-agents: A graph-based framework for multi-agent LLM collaboration. InThe F our- teenth International Conference on Learning Repre- sentations. Guibin Zhang, Yanwei Yue, Xiangguo Sun, Guancheng Wan, Miao Yu, Junfeng Fang, Kun Wang, Tianlong Chen, and Dawei Cheng. 2025. G-designer: Archi- tecting multi-agent communication topologies via graph neura...
-
[3]
You will receive a document from enterprise operations
-
[4]
Analyze the document and classify it using the hierarchical classification system
-
[5]
Assign the most specific applicable label(s) to the document
-
[6]
If a document does not fit an existing label, propose a new label under the appropriate category
-
[7]
Output the classification result in LIST format
-
[8]
Avoid adding extra commentary or explanation outside the final classification output
-
[9]
Strictly output in the expected format
-
[10]
Category > Subcategory > Label
Multiple labels are allowed when necessary. EXPECTED OUTPUT: ("Category > Subcategory > Label", "reason") Where "reason" is a short explanation of why the document fits this label. DOCUMENT TO BE CLASSIFIED: {file_content} ITHC REVIEW PROMPT AGENT ROLE: You are a Classification Review Agent at PriGen. Your responsibility is to review and validate existing...
-
[11]
You will receive a document and its initial classification result
-
[12]
Review whether each label is broadly reflective of the document content
-
[13]
If a label is clearly wrong, misleading, or unrelated, replace it with a more suitable one
-
[14]
If a label is generally acceptable, even if not perfect, retain it
-
[15]
Be conservative in making changes and minimize revisions unless strongly justified
-
[16]
Maintain the existing label hierarchy and structure
-
[17]
Output the revised classification result in LIST format
-
[18]
Category > Subcategory > Label
Do not include extra comments outside the required format. EXPECTED OUTPUT: ("Category > Subcategory > Label", "reason") DOCUMENT TO BE REVIEWED: {file_content} ORIGINAL LABELS: {original_labels} In the first stage, GPT-4o-mini assigns a top- level category based solely on the original model output. In the second stage, it self-reviews the same input with...
-
[19]
Understand the task purpose
-
[20]
Review the summaries and output files
-
[21]
The goal was initiated or achieved
Consider a task completed if: a. The goal was initiated or achieved. b. Indirect outcomes fulfill the task's intent. c. Partial work clearly contributes to the task
-
[22]
Reasoning..., yes
Mark the task uncompleted if there is no meaningful evidence of progress. OUTPUT FORMAT: Return exactly one of the following: "Reasoning..., yes" "Reasoning..., no" TASK: {task} CONTEXT: {context} G.4 Sliding-Window Lifecycle Tracking If a task remains uncompleted, it is carried into the next week’s evaluation pool, provided that it still falls within the...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.