GPU Acceleration of Learning With Errors KEMs Using OpenACC for Post-Quantum Cryptography
Pith reviewed 2026-06-28 17:01 UTC · model grok-4.3
The pith
OpenACC GPU code accelerates LWE KEMs up to 208 times on the Grace Hopper Superchip.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
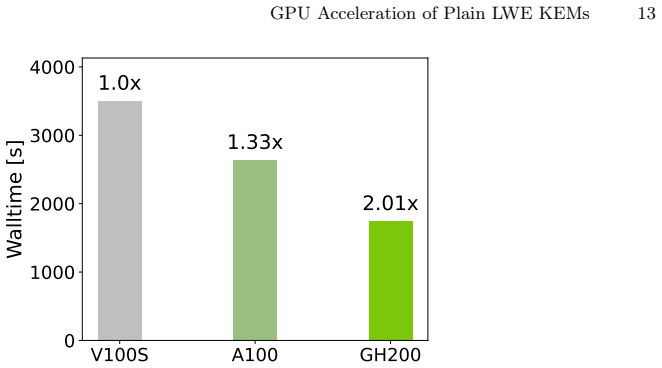
A plain LWE KEM is implemented and accelerated via OpenACC on NVIDIA GPUs; on the Grace Hopper Superchip the approach delivers up to 208× speedup over a multithreaded CPU baseline, enables problem sizes that exceed CPU memory and synchronization capacity, and achieves approximately 2× better energy efficiency than x86 CPU plus H100 GPU combinations.
What carries the argument
OpenACC directives applied to the matrix-vector operations and error sampling inside the LWE KEM to distribute work across GPU threads and memory hierarchy.
If this is right
- Larger LWE parameter sets become practical on GPU hardware that CPU systems cannot run.
- Time-to-solution for LWE KEM encapsulation and decapsulation drops sharply on the tested NVIDIA platforms.
- Energy-to-solution improves by a factor of about two on the Grace Hopper Superchip relative to x86-plus-H100 systems.
- Both bare-metal and containerized deployments show consistent acceleration across GPU generations.
- The same OpenACC approach can be applied to other LWE-derived primitives without changing the underlying math.
Where Pith is reading between the lines
- The same directive-based porting strategy could be reused for other lattice-based post-quantum schemes that share similar matrix operations.
- High-performance-computing centers could adopt GPU clusters for quantum-resistant key exchange at scale.
- Energy savings might lower the operational cost of running post-quantum protocols in data centers.
- Newer GPU architectures with larger unified memory could push the feasible LWE parameter range even further.
Load-bearing premise
The OpenACC version must produce bitwise-identical results to the CPU reference and must not create new side-channel leaks or correctness errors.
What would settle it
Execute the GPU and CPU implementations on identical inputs and verify that every output bit matches exactly while also checking whether timing or power traces reveal additional information on the GPU path.
Figures


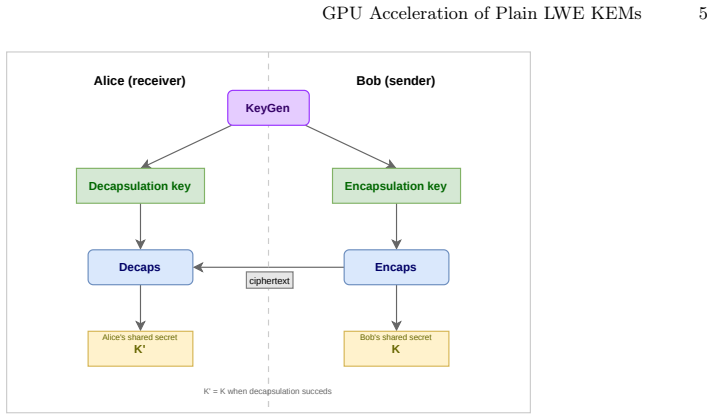
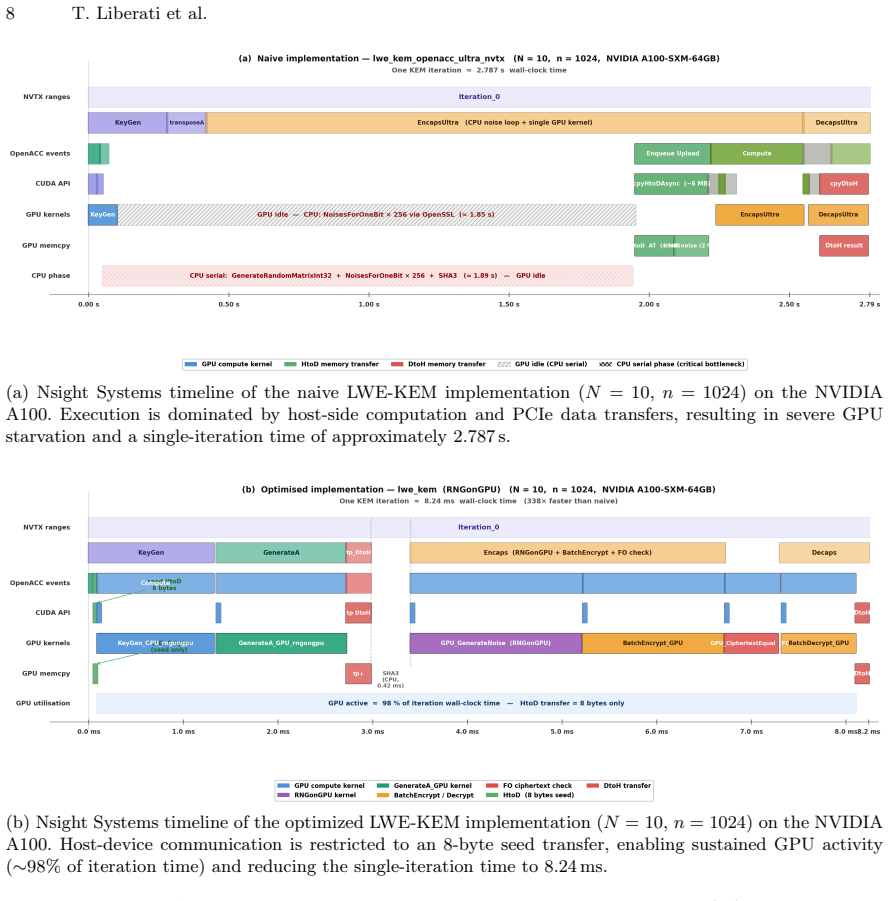
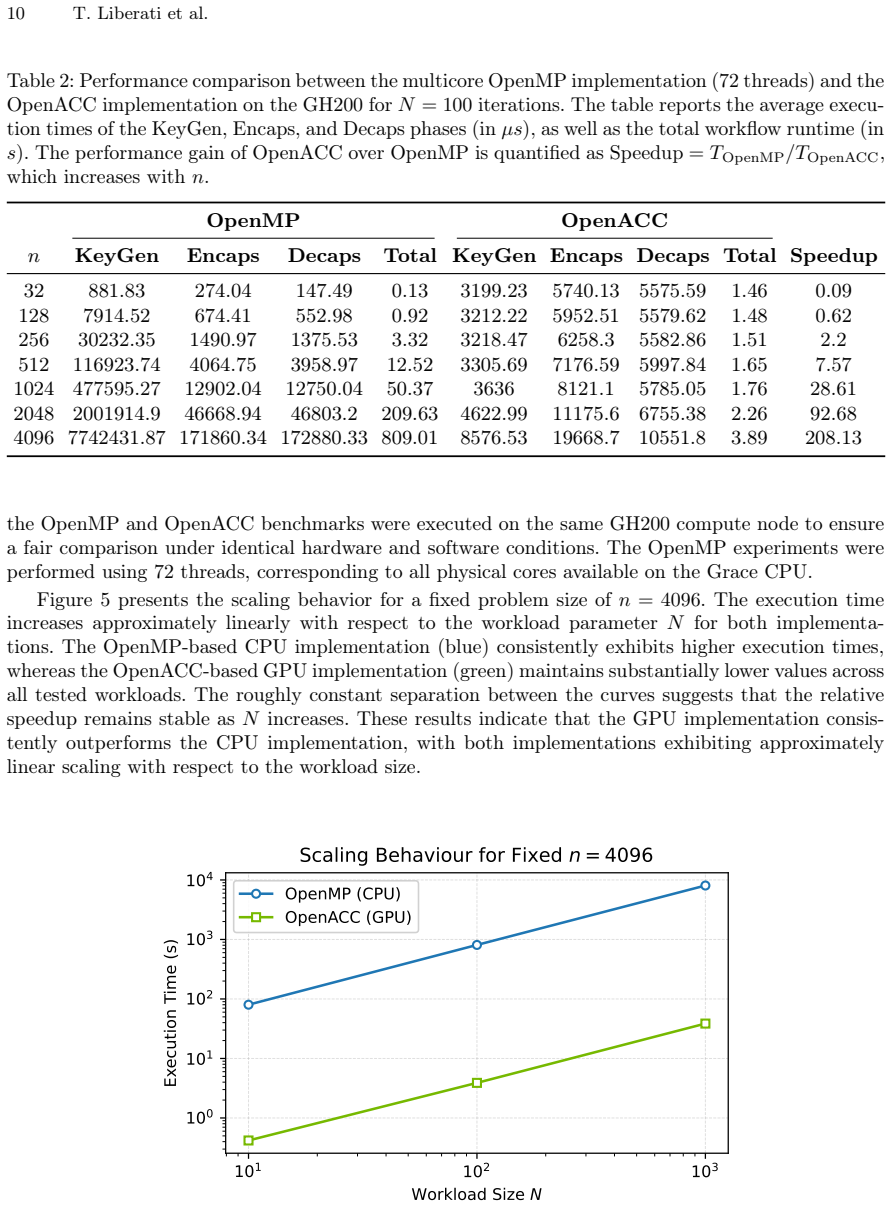
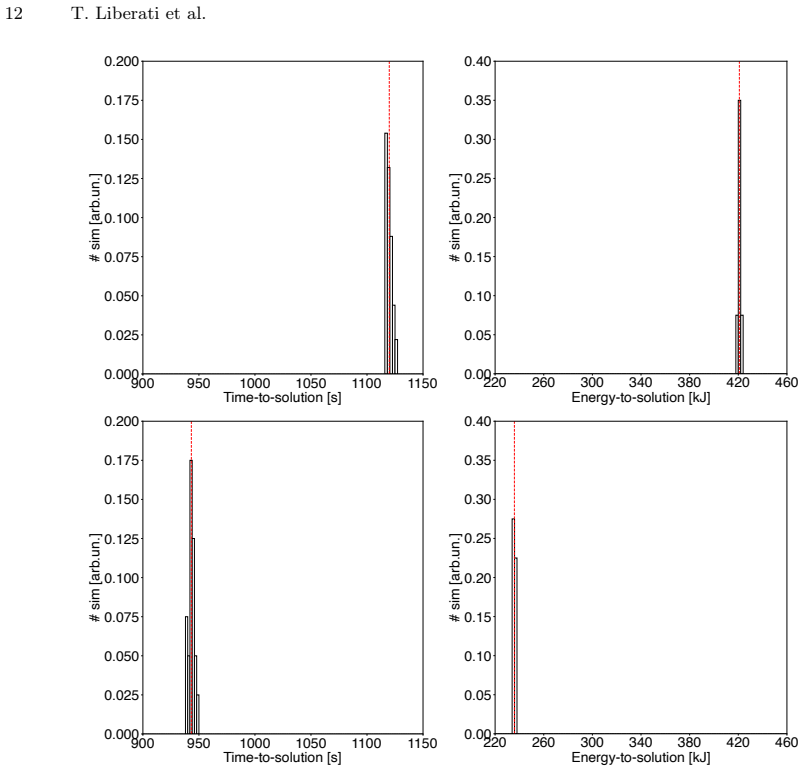
read the original abstract
Shor's algorithm proved that asymmetric cryptographic protocols based on the integer factorization and discrete logarithm problems are no longer safe in a world with large-scale quantum computers. As a result, Post-Quantum Cryptography (PQC) has been developed over the last few years, seeking cryptographic primitives resistant to quantum attacks. One of the main hard problems underlying PQC schemes is the Learning with Errors (LWE) problem, which is significantly more computationally intensive than its classical predecessors. In this work, we present a Key Encapsulation Mechanism (KEM) based on plain LWE and develop a GPU-oriented implementation using OpenACC. We evaluate the performance of our accelerated application in terms of both time-to-solution and energy-to-solution, considering bare-metal and containerized executions across multiple NVIDIA GPU models and generations. Our implementation achieves significant acceleration across all tested GPU platforms. In particular, on the NVIDIA Grace Hopper Superchip, it attains up to a $208\times$ speedup over a multithreaded CPU baseline and enables the execution of problem sizes that are impractical on CPU architectures due to memory and synchronization constraints. Energy consumption analysis also shows $\approx 2\times$ better efficiency when using the Superchip compared to systems equipped with x86-based CPUs and NVIDIA H100 GPUs. These results highlight the effectiveness of GPU acceleration for computationally demanding LWE-based cryptographic workloads.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents an LWE-based KEM and its GPU implementation via OpenACC directives. It reports empirical timing and energy measurements across NVIDIA GPU platforms, claiming up to 208× speedup over a multithreaded CPU baseline on the Grace Hopper Superchip, the ability to handle problem sizes infeasible on CPUs due to memory and synchronization limits, and approximately 2× better energy efficiency versus x86 CPU + H100 GPU systems.
Significance. If the implementation is shown to be functionally equivalent and side-channel safe, the work would provide concrete evidence that directive-based OpenACC parallelization can deliver substantial performance and energy gains for LWE KEMs on modern GPU hardware, including support for larger parameter sets. This would be relevant for high-performance post-quantum cryptography deployments.
major comments (2)
- [Abstract] Abstract: the central claims of 208× speedup and ≈2× energy improvement presuppose that the OpenACC GPU kernels produce bitwise-identical outputs to the reference multithreaded CPU implementation and preserve constant-time behavior. No description of equivalence testing, differential output verification, reduction-order checks, or side-channel timing analysis is supplied, rendering the performance numbers impossible to evaluate.
- [Results] Results section (implied by the performance numbers): the manuscript supplies no experimental setup details, baseline code versions, problem-size definitions (e.g., lattice dimension n, modulus q, error distribution), number of runs, or error bars. Without these, the reported speedups cannot be reproduced or assessed for statistical significance.
minor comments (1)
- [Abstract] The abstract mentions both bare-metal and containerized executions but does not clarify which environment produced the 208× figure.
Simulated Author's Rebuttal
We thank the referee for highlighting the importance of verification and reproducibility. We address each major comment below and will revise the manuscript to incorporate the requested details.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claims of 208× speedup and ≈2× energy improvement presuppose that the OpenACC GPU kernels produce bitwise-identical outputs to the reference multithreaded CPU implementation and preserve constant-time behavior. No description of equivalence testing, differential output verification, reduction-order checks, or side-channel timing analysis is supplied, rendering the performance numbers impossible to evaluate.
Authors: We agree that explicit documentation of functional equivalence and constant-time properties is required to substantiate the reported speedups for a cryptographic primitive. The revised manuscript will add a new subsection under Methodology describing the verification process: bitwise output comparison against the CPU reference for 10,000 random test vectors across all evaluated parameter sets, confirmation that reduction operations are order-independent, and timing measurements on the GPU kernels to verify absence of data-dependent execution paths. These additions will directly support the abstract claims. revision: yes
-
Referee: [Results] Results section (implied by the performance numbers): the manuscript supplies no experimental setup details, baseline code versions, problem-size definitions (e.g., lattice dimension n, modulus q, error distribution), number of runs, or error bars. Without these, the reported speedups cannot be reproduced or assessed for statistical significance.
Authors: We acknowledge that the current manuscript lacks sufficient experimental detail for reproducibility. The revised version will expand the Results section (and add an Experimental Setup subsection) to specify: exact LWE parameters (n, q, error distribution σ) for each reported data point; baseline CPU implementation (OpenMP multithreaded reference with version and compiler flags); number of timed runs (minimum 100 per configuration with warm-up); and statistical reporting including mean, standard deviation, and error bars on all speedup and energy figures. Problem sizes will be tabulated explicitly. revision: yes
Circularity Check
No circularity: purely empirical performance measurements
full rationale
The paper consists of implementation details and direct empirical measurements of runtime and energy on GPU platforms versus a multithreaded CPU baseline. No derivations, equations, fitted parameters, or self-citations are used to support the central claims of speedup and efficiency. Results are obtained by running the OpenACC code and recording wall-clock time and power draw; these are falsifiable against external hardware without any reduction to the paper's own inputs by construction. The work is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Almerol, J.L., et al.: Accelerating gravitational n-body simulations using the risc-v-based tenstorrent wormhole. In: SC25-W: Workshops of the International Conference for High Performance Computing, Networking, Storage and Analysis. pp. 1729–1735 (2025). https://doi.org/10.1145/3731599.3767528
-
[2]
Astronomy and Computing56, 101121 (2026)
Almerol, J.L., et al.: Assessing performance and porting strategies for gravitational n-body simulations on the risc-v-based tenstorrent wormhole™. Astronomy and Computing56, 101121 (2026). https://doi.org/ https://doi.org/10.1016/j.ascom.2026.101121
-
[3]
Amati, G., et al.: Experience on clock rate adjustment for energy-efficient gpu-accelerated real-world codes. p. 245–257. Springer-Verlag, Berlin, Heidelberg (2025). https://doi.org/10.1007/978-3-032-07612-0_19, https://doi.org/10.1007/978-3-032-07612-0_19
-
[4]
Cryptology ePrint Archive, Paper 2024/1895 (2024)
Biasioli, B., et al.: A tool for fast and secure LWE parameter selection: the FHE case. Cryptology ePrint Archive, Paper 2024/1895 (2024)
2024
-
[5]
Boella, E., et al.: Accelerating the particle-in-cell code ecsim with openacc (2026)
2026
-
[6]
Fujisaki, E., et al.: Secure integration of asymmetric and symmetric encryption schemes. J. Cryptol.26, 80–101 (2013). https://doi.org/10.1007/s00145-011-9114-1, https://doi.org/10.1007/s00145-011-9114-1
-
[7]
IEEE Transactions on Parallel and Distributed Systems32(3), 575–586 (2021)
Gupta, N., et al.: Pqc acceleration using gpus: Frodokem, newhope, and kyber. IEEE Transactions on Parallel and Distributed Systems32(3), 575–586 (2021). https://doi.org/10.1109/TPDS.2020.3025691
-
[8]
Gustafson, J.L.: Amdahl’s Law, pp. 53–60. Springer US, Boston, MA (2011). https://doi.org/10.1007/ 978-0-387-09766-4_77
2011
-
[9]
Kumar, M.: Post-quantum cryptography algorithm’s standardization and performance analysis. Array15, 100242 (08 2022). https://doi.org/10.1016/j.array.2022.100242
-
[10]
National Institute of Standards and Technology: FIPS 203: Module-Lattice-Based Key-Encapsulation Mechanism Standard. Tech. Rep. FIPS 203, U.S. Department of Commerce, National Institute of Stan- dards and Technology (2024)
2024
-
[11]
Regev, O.: On lattices, learning with errors, random linear codes, and cryptography. J. ACM56(6) (2009). https://doi.org/10.1145/1568318.1568324
-
[12]
IEEE Transactions on Parallel and Distributed Systems35(11), 1964–1976 (2024)
Shen, S., et al.: High-throughput gpu implementation of dilithium post-quantum digital signature. IEEE Transactions on Parallel and Distributed Systems35(11), 1964–1976 (2024). https://doi.org/10.1109/ TPDS.2024.3453289
arXiv 1964
-
[13]
In: Proceedings 35th Annual Symposium on Foundations of Computer Science
Shor, P.: Algorithms for quantum computation: discrete logarithms and factoring. In: Proceedings 35th Annual Symposium on Foundations of Computer Science. pp. 124–134 (1994). https://doi.org/10.1109/ SFCS.1994.365700
arXiv 1994
-
[14]
Computing in Science & Engineering24(5), 53–63 (2022)
Stack, M., et al.: Openacc acceleration of an agent-based biological simulation framework. Computing in Science & Engineering24(5), 53–63 (2022). https://doi.org/10.1109/MCSE.2022.3226602
-
[15]
Turisini, M., et al.: Leonardo: A pan-european pre-exascale supercomputer for hpc and ai applications (2023)
2023
-
[16]
The Inter- national Journal of High Performance Computing Applications39(4), 502–518 (2025)
Vignolo, A., et al.: A tale of two codes: Cuda vs openacc for mass-zero constrained dynamics. The Inter- national Journal of High Performance Computing Applications39(4), 502–518 (2025). https://doi.org/ 10.1177/10943420251331673
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.