Statistical Inference on Gradient Flows
Pith reviewed 2026-06-28 16:24 UTC · model grok-4.3
The pith
Gradient flows from empirical risk minimization obey a uniform central limit theorem as a continuous-time Gaussian process over all nonnegative time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper proves that sqrt(n) times the difference between the empirical gradient flow and the population gradient flow converges in distribution to a continuous-time Gaussian process indexed by the entire nonnegative real line. The same limit supplies the justification for a covariance estimator that evolves jointly with the flow and is shown to be uniformly consistent, which in turn yields confidence intervals for the target parameter that achieve asymptotically valid coverage.
What carries the argument
The uniform central limit theorem that represents the deviation process as a continuous-time Gaussian process over [0, infinity).
If this is right
- The covariance estimator runs alongside the gradient flow and requires neither matrix inversion nor resampling.
- The resulting confidence intervals attain asymptotically correct coverage uniformly over all stopping times.
- The theory directly addresses data-dependent or divergent stopping rules because uniformity holds on the whole time axis.
- Uniform consistency of the covariance estimator follows from the same Gaussian-process limit.
Where Pith is reading between the lines
- The continuous-time formulation could be discretized to obtain inference guarantees for stochastic gradient descent under suitable step-size schedules.
- The approach may connect to anytime-valid inference methods that control error rates across all times simultaneously.
- Extensions to non-convex or nonsmooth objectives would require verifying the same regularity conditions locally around the flow.
Load-bearing premise
The empirical risk and its gradients obey regularity conditions sufficient for the continuous-time Gaussian process limit to exist and remain valid over unbounded time.
What would settle it
Empirical coverage of the constructed intervals falling materially below the nominal level for large n at some large but finite time t would falsify the uniform consistency of the covariance estimator.
Figures
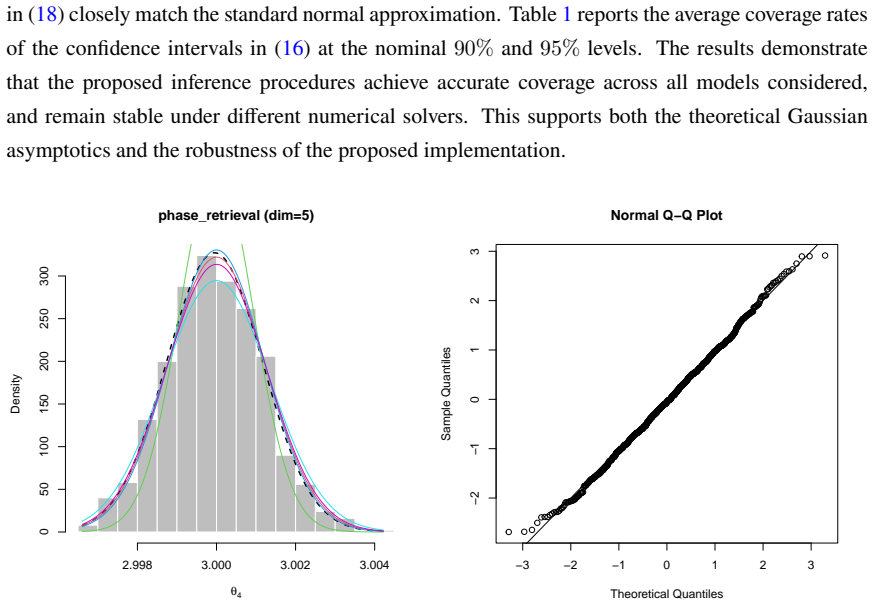
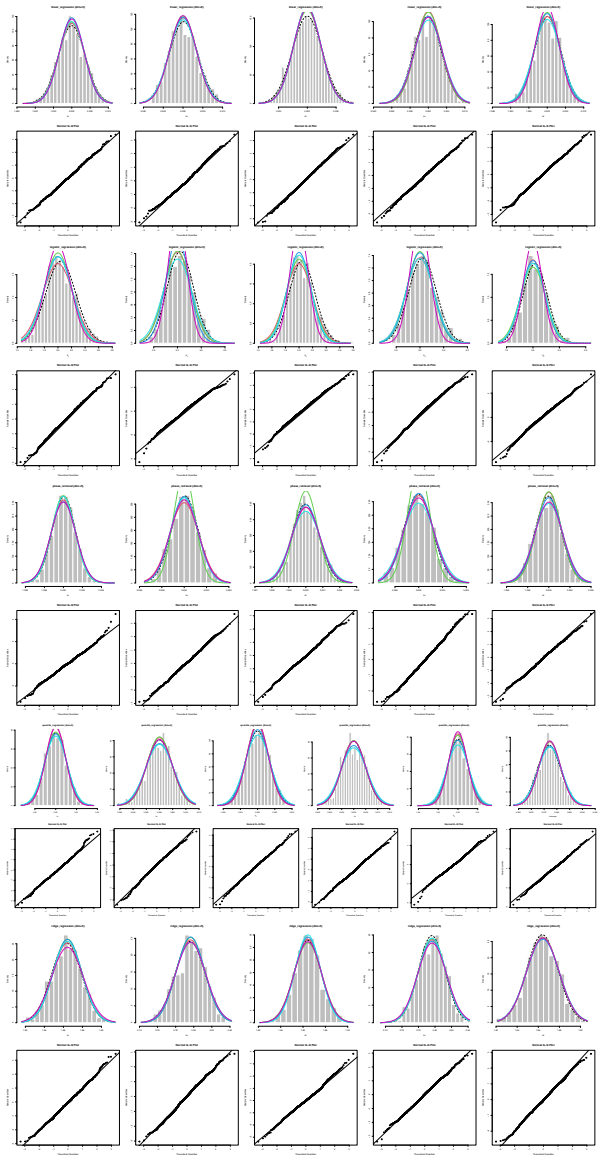
read the original abstract
Gradient-based algorithms are central to modern statistical estimation, yet their statistical analysis is often restricted to fixed-time behavior, such as convergence to a population target or fluctuations at a prescribed iteration. In many applications, however, uncertainty quantification is needed along the entire optimization path, especially when the stopping time is data-dependent or divergent. In this paper, we develop a theory for time-uniform statistical inference on gradient flows arising from empirical risk minimization. We prove a uniform central limit theorem that characterizes the deviation between empirical and population gradient flows as a continuous-time Gaussian process over the entire nonnegative real line. Building on this result, we introduce an algorithm-aware covariance estimator that evolves jointly with the gradient flow and avoids matrix inversion, resampling, or sample splitting. We show that the covariance estimator is uniformly consistent over time and use it to construct confidence intervals for the target parameter with asymptotically valid coverage. Our results connect optimization dynamics with statistical inference and provide practical tools for uncertainty quantification in gradient-based methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper develops a theory for time-uniform statistical inference on gradient flows arising from empirical risk minimization. It proves a uniform central limit theorem characterizing the deviation between empirical and population gradient flows as a continuous-time Gaussian process over the entire nonnegative real line. It introduces an algorithm-aware covariance estimator that evolves jointly with the flow, shows the estimator is uniformly consistent over time, and constructs confidence intervals with asymptotically valid coverage.
Significance. If the uniform CLT and associated consistency results hold, the work would connect optimization dynamics with statistical inference in a novel way, enabling uncertainty quantification along the full trajectory (including data-dependent stopping times) without resampling or sample splitting. The covariance estimator's design, which avoids matrix inversion, is a practical strength.
major comments (1)
- [Abstract] The uniform CLT over [0,∞) is asserted under unspecified 'regularity conditions' on the empirical risk and gradients. For tightness of the limiting Gaussian process in a suitable function space on the unbounded interval, standard requirements include uniform Lipschitz gradients or dissipativity of the vector field together with moment bounds that remain valid as t→∞; without the precise hypotheses (e.g., whether the Hessian is globally bounded or only locally Lipschitz), it is impossible to verify that the infinite-horizon argument closes.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for identifying the need to make the regularity conditions more explicit in the abstract. We address the comment below.
read point-by-point responses
-
Referee: [Abstract] The uniform CLT over [0,∞) is asserted under unspecified 'regularity conditions' on the empirical risk and gradients. For tightness of the limiting Gaussian process in a suitable function space on the unbounded interval, standard requirements include uniform Lipschitz gradients or dissipativity of the vector field together with moment bounds that remain valid as t→∞; without the precise hypotheses (e.g., whether the Hessian is globally bounded or only locally Lipschitz), it is impossible to verify that the infinite-horizon argument closes.
Authors: The full manuscript states the required conditions in Assumption 3.1 (global Lipschitz continuity of the gradient of the empirical risk with constant L independent of n, together with dissipativity of the population vector field ensuring uniform-in-time moment bounds) and uses these to obtain tightness on [0,∞) via standard arguments for continuous-time martingales. The Hessian is assumed only locally Lipschitz; global Lipschitz on the gradient is sufficient for the tightness argument. We agree that the abstract is insufficiently precise and will revise it to cite Assumption 3.1 explicitly, along with a short clarifying sentence in the introduction. revision: yes
Circularity Check
No circularity: uniform CLT and covariance estimator derived from independent regularity assumptions
full rationale
The paper derives a uniform central limit theorem for the deviation process √n(hat theta_t - theta_t) converging to a Gaussian process on [0,∞), together with a jointly evolving covariance estimator that is shown to be uniformly consistent. These steps rest on regularity conditions on the empirical risk and gradients that are external to the target limit objects; the construction of the covariance estimator avoids inversion, resampling, or splitting and is not obtained by fitting to the same data used to define the flow. No quoted equation or self-citation reduces the claimed result to a tautology or to a parameter fitted from the output itself. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard regularity conditions on the loss and its gradients that permit a continuous-time functional central limit theorem
Reference graph
Works this paper leans on
-
[1]
Supplement to ``Statistical Inference on Gradient Flows'' , author=
-
[2]
2011 , publisher=
Statistics for high-dimensional data: methods, theory and applications , author=. 2011 , publisher=
2011
-
[3]
2023 , edition=
Weak Convergence and Empirical Processes: With Applications to Statistics , author=. 2023 , edition=
2023
-
[4]
2023 , publisher=
A course in the large sample theory of statistical inference , author=. 2023 , publisher=
2023
-
[5]
1980 , publisher=
Approximation theorems of mathematical statistics , author=. 1980 , publisher=
1980
-
[6]
2016 , publisher=
Mathematical Foundations of Infinite-Dimensional Statistical Models , author=. 2016 , publisher=
2016
-
[7]
Compressed Sensing: Theory and Applications , editor=
Introduction to the non-asymptotic analysis of random matrices , author=. Compressed Sensing: Theory and Applications , editor=. 2012 , publisher=
2012
-
[8]
The Annals of Statistics , volume=
The landscape of empirical risk for nonconvex losses , author=. The Annals of Statistics , volume=. 2018 , publisher=
2018
-
[9]
2000 , publisher=
Empirical Processes in M-estimation , author=. 2000 , publisher=
2000
-
[10]
Oracle inequalities in empirical risk minimization and sparse recovery problems: Ecole D’Et
Koltchinskii, Vladimir , series=. Oracle inequalities in empirical risk minimization and sparse recovery problems: Ecole D’Et. 2011 , publisher=
2011
-
[11]
arXiv preprint arXiv:2602.21501 , year=
A Researcher's Guide to Empirical Risk Minimization , author=. arXiv preprint arXiv:2602.21501 , year=
-
[12]
Physical Review E , volume=
Gradient flows and proximal splitting methods: A unified view on accelerated and stochastic optimization , author=. Physical Review E , volume=. 2021 , publisher=
2021
-
[13]
Advances in Neural Information Processing Systems , volume=
Integration Methods and Optimization Algorithms , author=. Advances in Neural Information Processing Systems , volume=
-
[14]
SIAM review , volume=
Optimization methods for large-scale machine learning , author=. SIAM review , volume=. 2018 , publisher=
2018
-
[15]
2020 , publisher=
First-order and stochastic optimization methods for machine learning , author=. 2020 , publisher=
2020
-
[16]
2022 , publisher=
Optimization for data analysis , author=. 2022 , publisher=
2022
-
[17]
2003 , publisher=
Stochastic approximation and recursive algorithms and applications , author=. 2003 , publisher=
2003
-
[18]
2009 , publisher=
Numerical solution of ordinary differential equations , author=. 2009 , publisher=
2009
-
[19]
2024 , publisher=
Lectures on Optimal Transport , author=. 2024 , publisher=
2024
-
[20]
2015 , publisher=
The convergence problem for dissipative autonomous systems: classical methods and recent advances , author=. 2015 , publisher=
2015
-
[21]
Zhurnal vychislitel'noi matematiki i matematicheskoi fiziki , volume=
Gradient methods for minimizing functionals , author=. Zhurnal vychislitel'noi matematiki i matematicheskoi fiziki , volume=. 1963 , publisher=
1963
-
[22]
Linear convergence of gradient and proximal-gradient methods under the polyak-
Karimi, Hamed and Nutini, Julie and Schmidt, Mark , booktitle=. Linear convergence of gradient and proximal-gradient methods under the polyak-. 2016 , organization=
2016
-
[23]
NeurIPS 2019-33rd Conference on Neural Information Processing Systems , pages=
On Lazy Training in Differentiable Programming , author=. NeurIPS 2019-33rd Conference on Neural Information Processing Systems , pages=
2019
-
[24]
2012 , publisher=
Ordinary differential equations and dynamical systems , author=. 2012 , publisher=
2012
-
[25]
2012 , publisher=
Ordinary differential equations: Qualitative theory , author=. 2012 , publisher=
2012
-
[26]
2006 , publisher=
Nonlinear dispersive equations: local and global analysis , author=. 2006 , publisher=
2006
-
[27]
2024 , publisher=
Logarithmic norms , author=. 2024 , publisher=
2024
-
[28]
BIT Numerical Mathematics , volume=
Bounds and perturbation bounds for the matrix exponential , author=. BIT Numerical Mathematics , volume=. 1977 , publisher=
1977
-
[29]
arXiv preprint arXiv:2509.17251 , year=
Risk Comparisons in Linear Regression: Implicit Regularization Dominates Explicit Regularization , author=. arXiv preprint arXiv:2509.17251 , year=
-
[30]
arXiv preprint arXiv:2602.02431 , year=
Full-Batch Gradient Descent Outperforms One-Pass SGD: Sample Complexity Separation in Single-Index Learning , author=. arXiv preprint arXiv:2602.02431 , year=
-
[31]
The Annals of Statistics , volume=
Fast global convergence of gradient methods for high-dimensional statistical recovery , author=. The Annals of Statistics , volume=. 2012 , publisher=
2012
-
[32]
The Annals of Statistics , volume=
Statistical guarantees for the EM algorithm: From population to sample-based analysis , author=. The Annals of Statistics , volume=. 2017 , publisher=
2017
-
[33]
The Annals of Statistics , volume=
Singularity, misspecification and the convergence rate of EM , author=. The Annals of Statistics , volume=. 2020 , publisher=
2020
-
[34]
The Annals of Statistics , volume=
Statistical consistency and asymptotic normality for high-dimensional robust M-estimators , author=. The Annals of Statistics , volume=. 2017 , publisher=
2017
-
[35]
The Annals of Statistics , volume=
Sharp global convergence guarantees for iterative nonconvex optimization with random data , author=. The Annals of Statistics , volume=. 2023 , publisher=
2023
-
[36]
Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=
Robust estimation via robust gradient estimation , author=. Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=. 2020 , publisher=
2020
-
[37]
arXiv preprint arXiv:2601.05669 , year=
Minimax Optimal Robust Sparse Regression with Heavy-Tailed Designs: A Gradient-Based Approach , author=. arXiv preprint arXiv:2601.05669 , year=
-
[38]
Journal of Machine Learning Research , volume=
Path length bounds for gradient descent and flow , author=. Journal of Machine Learning Research , volume=
-
[39]
Transactions of the American Mathematical Society , volume=
Local conditions for global convergence of gradient flows and proximal point sequences in metric spaces , author=. Transactions of the American Mathematical Society , volume=
-
[40]
Transactions on Machine Learning Research , year=
Almost sure convergence of stochastic gradient methods under gradient domination , author=. Transactions on Machine Learning Research , year=
-
[41]
International Conference on Learning Representations , year=
Symmetries, flat minima, and the conserved quantities of gradient flow , author=. International Conference on Learning Representations , year=
-
[42]
arXiv preprint arXiv:2511.10362 , year=
Gradient Flow Equations for Deep Linear Neural Networks: A Survey from a Network Perspective , author=. arXiv preprint arXiv:2511.10362 , year=
-
[43]
arXiv preprint arXiv:2601.10483 , year=
High-dimensional analysis of gradient flow for extensive-width quadratic neural networks , author=. arXiv preprint arXiv:2601.10483 , year=
-
[44]
arXiv preprint arXiv:2511.16976 , year=
Gradient flow for deep equilibrium single-index models , author=. arXiv preprint arXiv:2511.16976 , year=
-
[45]
arXiv preprint arXiv:2509.23527 , year=
Learning single index model with gradient descent: spectral initialization and precise asymptotics , author=. arXiv preprint arXiv:2509.23527 , year=
-
[46]
arXiv preprint arXiv:2504.19089 , year=
Semiparametric M-estimation with overparameterized neural networks , author=. arXiv preprint arXiv:2504.19089 , year=
-
[47]
arXiv preprint arXiv:2505.04898 , year=
Precise gradient descent training dynamics for finite-width multi-layer neural networks , author=. arXiv preprint arXiv:2505.04898 , year=
-
[48]
The Annals of Statistics , volume=
Entrywise dynamics and universality of general first order methods , author=. The Annals of Statistics , volume=. 2025 , publisher=
2025
-
[49]
arXiv preprint arXiv:2112.07572 , year=
The high-dimensional asymptotics of first order methods with random data , author=. arXiv preprint arXiv:2112.07572 , year=
-
[50]
arXiv preprint arXiv:2507.19611 , year=
State evolution beyond first-order methods I: Rigorous predictions and finite-sample guarantees , author=. arXiv preprint arXiv:2507.19611 , year=
-
[51]
Annals of Statistics , volume=
Statistical inference for model parameters in stochastic gradient descent , author=. Annals of Statistics , volume=. 2020 , publisher=
2020
-
[52]
arXiv preprint arXiv:2412.09498 , year=
Gradient descent inference in empirical risk minimization , author=. arXiv preprint arXiv:2412.09498 , year=
-
[53]
arXiv preprint arXiv:2404.17856 , year=
Uncertainty quantification for iterative algorithms in linear models with application to early stopping , author=. arXiv preprint arXiv:2404.17856 , year=
-
[54]
SIAM Journal on Mathematics of Data Science , volume=
Rigorous dynamical mean-field theory for stochastic gradient descent methods , author=. SIAM Journal on Mathematics of Data Science , volume=. 2024 , publisher=
2024
-
[55]
Communications on Pure and Applied Mathematics , volume=
High-dimensional limit theorems for SGD: Effective dynamics and critical scaling , author=. Communications on Pure and Applied Mathematics , volume=. 2024 , publisher=
2024
-
[56]
arXiv preprint arXiv:2601.21093 , year=
High-dimensional learning dynamics of multi-pass Stochastic Gradient Descent in multi-index models , author=. arXiv preprint arXiv:2601.21093 , year=
-
[57]
arXiv preprint arXiv:2602.06320 , year=
High-Dimensional Limit of Stochastic Gradient Flow via Dynamical Mean-Field Theory , author=. arXiv preprint arXiv:2602.06320 , year=
-
[58]
arXiv preprint arXiv:2502.06719 , year=
Gaussian approximation and multiplier bootstrap for stochastic gradient descent , author=. arXiv preprint arXiv:2502.06719 , year=
-
[59]
arXiv preprint arXiv:2510.12375 , year=
Improved Central Limit Theorem and Bootstrap Approximations for Linear Stochastic Approximation , author=. arXiv preprint arXiv:2510.12375 , year=
-
[60]
Journal of the American Statistical Association , volume=
Online statistical inference for stochastic optimization via kiefer-wolfowitz methods , author=. Journal of the American Statistical Association , volume=. 2024 , publisher=
2024
-
[61]
Journal of the American Statistical Association , volume=
Statistical inference for high-dimensional models via recursive online-score estimation , author=. Journal of the American Statistical Association , volume=. 2021 , publisher=
2021
-
[62]
Biometrika , volume=
Online inference with debiased stochastic gradient descent , author=. Biometrika , volume=. 2024 , publisher=
2024
-
[63]
arXiv preprint arXiv:2505.17300 , year=
Statistical inference for online algorithms , author=. arXiv preprint arXiv:2505.17300 , year=
-
[64]
Journal of the American Statistical Association , volume=
Online covariance matrix estimation in stochastic gradient descent , author=. Journal of the American Statistical Association , volume=. 2023 , publisher=
2023
-
[65]
arXiv preprint arXiv:2302.12717 , year=
Statistical Inference with Stochastic Gradient Methods under -mixing Data , author=. arXiv preprint arXiv:2302.12717 , year=
-
[66]
The Annals of Statistics , volume=
Differentially private inference via noisy optimization , author=. The Annals of Statistics , volume=. 2023 , publisher=
2023
-
[67]
arXiv preprint arXiv:2507.20560 , year=
Statistical Inference for Differentially Private Stochastic Gradient Descent , author=. arXiv preprint arXiv:2507.20560 , year=
-
[68]
IEEE Journal on Selected Areas in Information Theory , volume=
Statistical inference with limited memory: A survey , author=. IEEE Journal on Selected Areas in Information Theory , volume=. 2024 , publisher=
2024
-
[69]
Journal of the American Statistical Association , volume=
Optimal one-pass nonparametric estimation under memory constraint , author=. Journal of the American Statistical Association , volume=. 2024 , publisher=
2024
-
[70]
arXiv preprint arXiv:2601.01371 , year=
SGD with dependent data: Optimal estimation, regret, and inference , author=. arXiv preprint arXiv:2601.01371 , year=
-
[71]
arXiv preprint arXiv:2410.16340 , year=
Limit theorems for stochastic gradient descent with infinite variance , author=. arXiv preprint arXiv:2410.16340 , year=
-
[72]
arXiv preprint arXiv:2605.26000 , year=
Statistical inference for stochastic gradient descent beyond finite variance , author=. arXiv preprint arXiv:2605.26000 , year=
-
[73]
Statistical Inference for Linear Functionals of Online Least-Squares SGD When t d^
Agrawalla, Bhavya and Balasubramanian, Krishnakumar and Ghosal, Promit , journal=. Statistical Inference for Linear Functionals of Online Least-Squares SGD When t d^. 2025 , publisher=
2025
-
[74]
arXiv preprint arXiv:2509.11426 , year=
Long-time dynamics and universality of nonconvex gradient descent , author=. arXiv preprint arXiv:2509.11426 , year=
-
[75]
arXiv preprint arXiv:2511.18273 , year=
Time-uniform concentration bounds for iterative algorithms , author=. arXiv preprint arXiv:2511.18273 , year=
-
[76]
arXiv preprint arXiv:2603.14514 , year=
High-Probability Bounds for SGD under the Polyak-Lojasiewicz Condition with Markovian Noise , author=. arXiv preprint arXiv:2603.14514 , year=
-
[77]
arXiv preprint arXiv:2410.15057 , year=
Asymptotic time-uniform inference for parameters in averaged stochastic approximation , author=. arXiv preprint arXiv:2410.15057 , year=
-
[78]
arXiv preprint arXiv:2602.15538 , year=
Functional Central Limit Theorem for Stochastic Gradient Descent , author=. arXiv preprint arXiv:2602.15538 , year=
-
[79]
Statistics Surveys , volume=
A comprehensive review of bias reduction methods for logistic regression , author=. Statistics Surveys , volume=. 2024 , publisher=
2024
-
[80]
arXiv preprint arXiv:2412.07401 , year=
Noisy phase retrieval from subgaussian measurements , author=. arXiv preprint arXiv:2412.07401 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.