Emergent Ordinal Geometry in Transformers Trained on Local Comparisons
Pith reviewed 2026-06-28 17:00 UTC · model grok-4.3
The pith
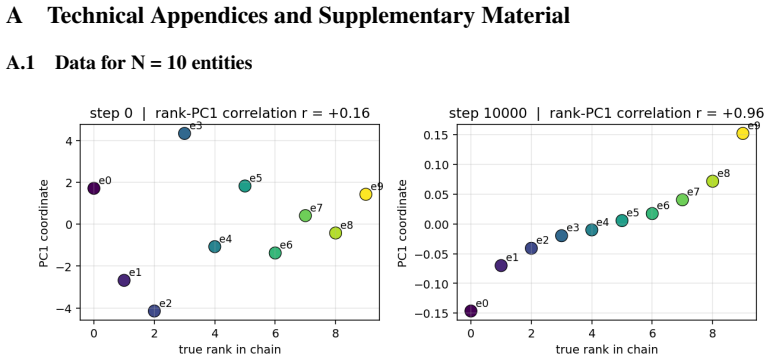
Transformers trained only on adjacent comparisons develop embeddings that collapse onto a one-dimensional manifold aligned with the hidden rank order.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
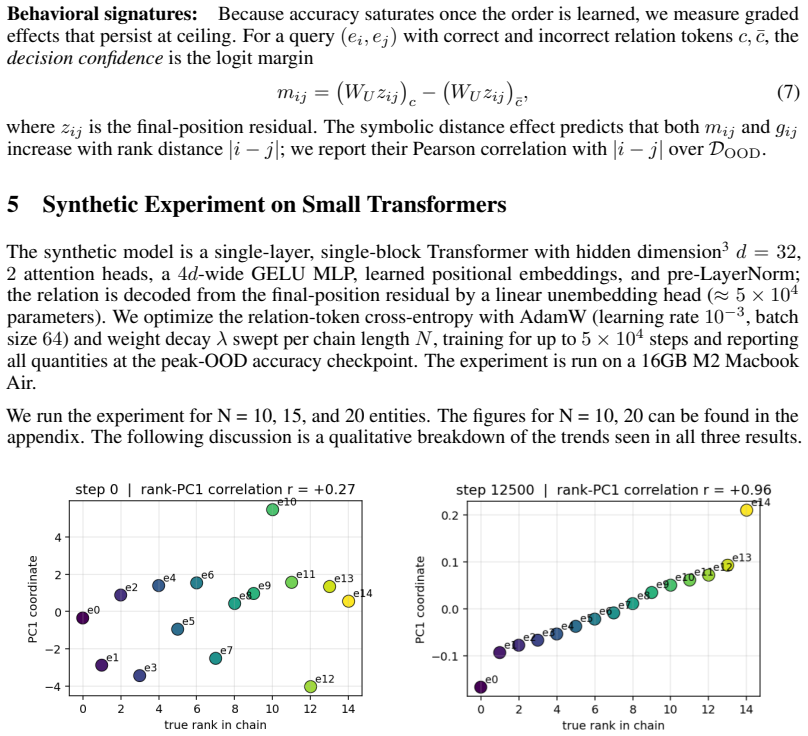
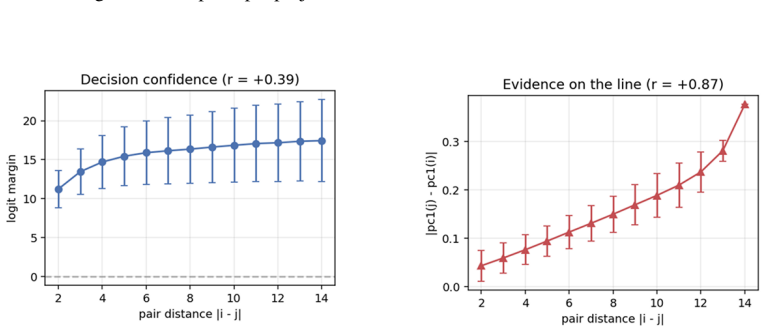
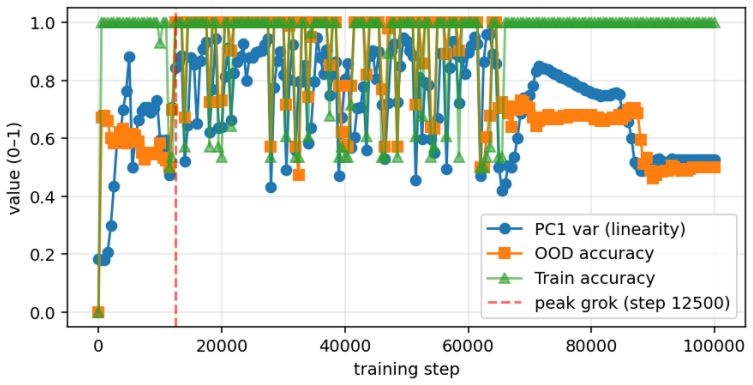
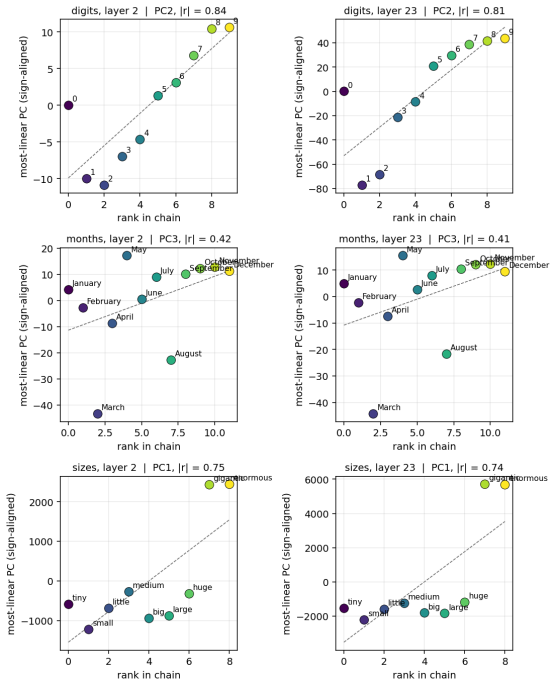
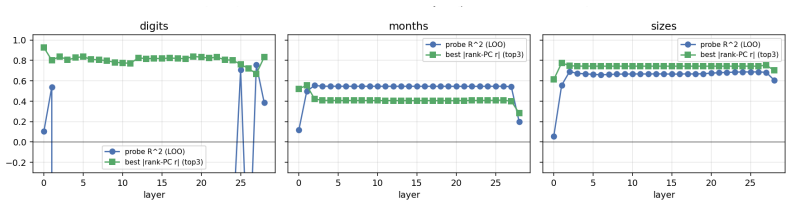
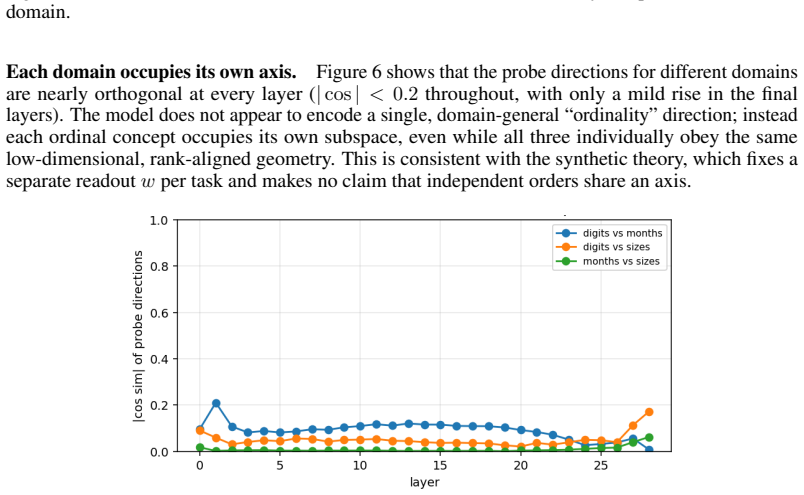
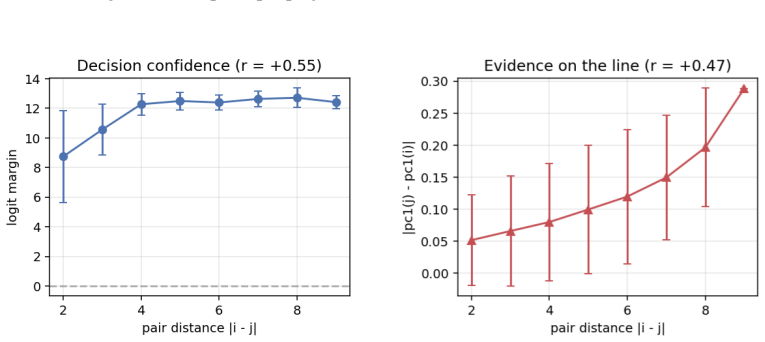
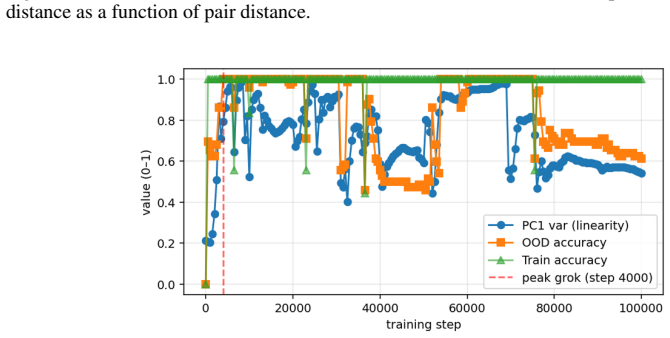
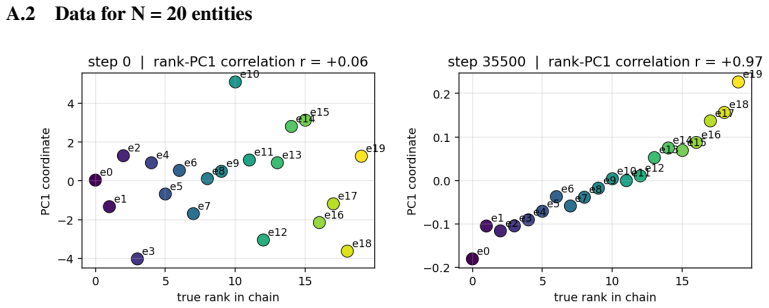
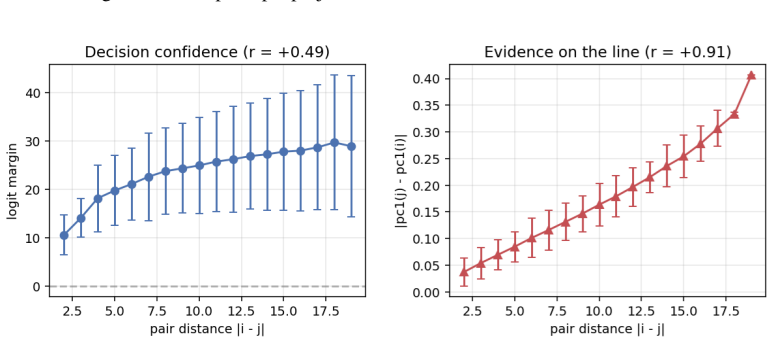
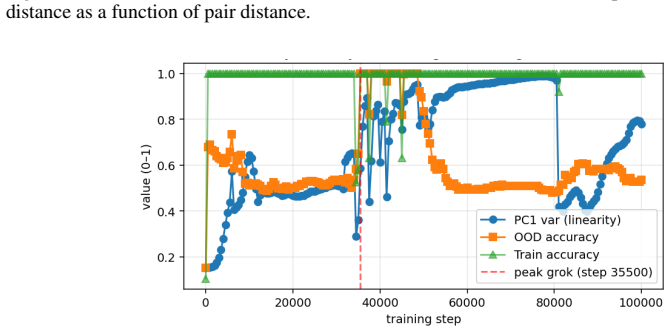
When small transformers are trained exclusively on adjacent comparisons drawn from a hidden total order, their entity embeddings reorganize onto a one-dimensional manifold whose principal axis recovers the hidden rank order with near-perfect fidelity. This reorganization is sensitive to the optimization trajectory and produces grokking-like transient dynamics. Even after accuracy reaches ceiling, both decision confidence and geometric separation scale monotonically with rank distance, reproducing the symbolic distance effect. The identical rank-aligned geometry is recovered in a pretrained large language model, where it follows the topology of each ordinal relation (linear for sizes and digi
What carries the argument
The collapse of entity embeddings onto a one-dimensional manifold whose principal axis recovers the hidden rank order.
If this is right
- Out-of-distribution generalization to distant pairs emerges without any explicit chaining or distant-pair exposure during training.
- Decision confidence continues to scale with rank distance after accuracy has saturated at ceiling.
- Geometric separation between embeddings increases monotonically with rank distance, directly mirroring the symbolic distance effect.
- The same rank-aligned geometry appears in a pretrained large language model and tracks the distinct topology of different ordinal relations.
Where Pith is reading between the lines
- The finding suggests that ordinal structure can arise from geometric compression of local comparisons rather than from symbolic rule application.
- The reported sensitivity to optimization schedule raises the possibility that similar rank geometry could be induced or suppressed by changes in training dynamics alone.
- If the same manifold formation occurs across model scales, it offers a candidate mechanism for how limited local experience can support transitive inference in both artificial and biological systems.
Load-bearing premise
The training data consists exclusively of adjacent comparisons drawn from a hidden total order, and out-of-distribution generalization to distant pairs is measured without the model having encountered those pairs or any chaining supervision during training.
What would settle it
After training to ceiling accuracy on adjacent pairs only, extract the first principal component of the entity embeddings and test whether its ordering matches the hidden total order; systematic misalignment on multiple independent orders would falsify the claimed collapse.
Figures
read the original abstract
Transitive inference is the challenge of inferring that A < C from knowing only adjacent relations (A < B, B < C). It is solved by humans and animals not through logical chaining but via an analogue mental number line, whose signature is the symbolic distance effect: distant comparisons are easier than nearby ones. We ask whether Transformers acquire the same primitive, training small models exclusively on adjacent comparisons from a hidden total order and evaluating generalization to unseen distant pairs. We find that out-of-distribution generalization emerges alongside a striking geometric reorganization: entity embeddings collapse onto a one-dimensional manifold whose principal axis recovers the hidden rank order with near-perfect fidelity, and this structure is sensitive to optimization in ways that produce grokking-like transient dynamics. Critically, even when accuracy is at ceiling, decision confidence and geometric separation both scale monotonically with rank distance, directly mirroring the symbolic distance effect observed across decades of behavioural experiments on humans, primates, and rodents. We further show the same rank-aligned geometry in a pretrained large language model, where it tracks the topology of each ordinal relation: linear for sizes and digits, cyclic for months. These results ground a 50-year-old behavioural regularity in the geometry of learned representations, offering a mechanistic account of transitive inference that bridges cognitive science and modern neural networks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that small Transformers trained exclusively on adjacent pairwise comparisons drawn from a hidden total order exhibit out-of-distribution generalization to distant pairs. This is accompanied by a geometric reorganization in which entity embeddings collapse onto a one-dimensional manifold whose principal axis recovers the hidden rank order with high fidelity. The structure produces grokking-like transient dynamics during optimization, and even at ceiling accuracy both decision confidence and geometric separation scale monotonically with rank distance, reproducing the symbolic distance effect. The same rank-aligned geometry is reported in a pretrained large language model, where it tracks the topology of different ordinal relations (linear for sizes/digits, cyclic for months).
Significance. If the central empirical findings hold, the work supplies a concrete mechanistic account of transitive inference grounded in the geometry of learned representations rather than explicit logical chaining. It directly links a 50-year behavioral regularity (the symbolic distance effect) to emergent properties of transformer embeddings under local training, with additional value from the extension to pretrained LLMs and the observation of distance-dependent confidence at ceiling performance. The absence of free parameters or ad-hoc axioms in the core claim, together with the focus on verifiable OOD generalization from adjacent-only data, strengthens the contribution as a bridge between cognitive science and modern neural-network geometry.
minor comments (2)
- [Results] The abstract and results sections would benefit from explicit reporting of the number of random seeds, the precise definition of 'near-perfect fidelity' (e.g., Spearman correlation threshold), and whether error bars or confidence intervals accompany the reported monotonic trends in confidence and separation.
- [Methods] Notation for the hidden total order and the embedding principal axis should be introduced with a short equation or diagram in the methods to avoid ambiguity when comparing across the synthetic and LLM experiments.
Simulated Author's Rebuttal
We thank the referee for the positive and insightful summary of our work, the assessment of its significance, and the recommendation for minor revision. No specific major comments were provided in the report.
Circularity Check
No significant circularity
full rationale
The paper reports purely empirical results: transformers are trained on adjacent pairwise comparisons drawn from a hidden total order, after which embedding geometry is inspected and OOD generalization to distant pairs is measured. No derivation chain, equations, or fitted parameters are presented whose outputs are then relabeled as predictions; the central observations (1-D manifold alignment, symbolic distance effect in confidence and separation) are direct measurements on trained models rather than algebraic reductions to the training inputs. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes. The work is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Transitive inferences and memory in young children
Bryant, P E and Trabasso, T. Transitive inferences and memory in young children. Nature
-
[2]
Steirn, Janice N. and Weaver, Janice E. and Zentall, Thomas R. , title=. Animal Learning. 1995 , month=. doi:10.3758/BF03198018 , url=
-
[3]
2026 , eprint=
Emergent Analogical Reasoning in Transformers , author=. 2026 , eprint=
2026
-
[4]
Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets
Alethea Power and Yuri Burda and Harri Edwards and Igor Babuschkin and Vedant Misra , title =. CoRR , volume =. 2022 , url =. 2201.02177 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[5]
The representation of comparative relations and the transitive inference task , journal =
Christine A Riley , abstract =. The representation of comparative relations and the transitive inference task , journal =. 1976 , issn =. doi:https://doi.org/10.1016/0022-0965(76)90085-0 , url =
-
[6]
2023 , eprint=
Progress measures for grokking via mechanistic interpretability , author=. 2023 , eprint=
2023
-
[7]
2025 , eprint=
ICLR: In-Context Learning of Representations , author=. 2025 , eprint=
2025
-
[8]
A positional discriminability model of linear-order judgments
Holyoak, K J and Patterson, K K. A positional discriminability model of linear-order judgments. J Exp Psychol Hum Percept Perform
-
[9]
Time required for judgements of numerical inequality
Moyer, R S and Landauer, T K. Time required for judgements of numerical inequality. Nature
-
[10]
2022 , eprint=
Toy Models of Superposition , author=. 2022 , eprint=
2022
-
[11]
2019 , eprint=
Decoupled Weight Decay Regularization , author=. 2019 , eprint=
2019
-
[12]
Are monkeys logical?
Mcgonigle, Brendan O and Chalmers, Margaret. Are monkeys logical?. Nature
-
[13]
2025 , eprint=
Qwen2.5 Technical Report , author=. 2025 , eprint=
2025
-
[14]
2024 , eprint=
The Quantization Model of Neural Scaling , author=. 2024 , eprint=
2024
-
[15]
Transitive inference in rats (Rattus norvegicus)
Davis, H. Transitive inference in rats (Rattus norvegicus). J Comp Psychol
-
[16]
Linguistic Regularities in Continuous Space Word Representations
Mikolov, Tomas and Yih, Wen-tau and Zweig, Geoffrey. Linguistic Regularities in Continuous Space Word Representations. Proceedings of the 2013 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies. 2013
2013
-
[17]
Distill , year =
Olah, Chris and Cammarata, Nick and Schubert, Ludwig and Goh, Gabriel and Petrov, Michael and Carter, Shan , title =. Distill , year =
-
[18]
2021 , journal=
A Mathematical Framework for Transformer Circuits , author=. 2021 , journal=
2021
-
[19]
2024 , eprint=
The Geometry of Truth: Emergent Linear Structure in Large Language Model Representations of True/False Datasets , author=. 2024 , eprint=
2024
-
[20]
2015 , eprint=
In Search of the Real Inductive Bias: On the Role of Implicit Regularization in Deep Learning , author=. 2015 , eprint=
2015
-
[21]
2017 , eprint=
Understanding deep learning requires rethinking generalization , author=. 2017 , eprint=
2017
-
[22]
2021 , eprint=
Probing Classifiers: Promises, Shortcomings, and Advances , author=. 2021 , eprint=
2021
-
[23]
2024 , eprint=
Language Models Represent Space and Time , author=. 2024 , eprint=
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.