GLIDE: Graph-guided Leap Inference for Diffusion Estimation of Spatio-Temporal Point Processes
Pith reviewed 2026-06-28 17:26 UTC · model grok-4.3
The pith
GLIDE guides diffusion models for spatio-temporal point processes with a multi-scale event graph and prior-guided leap inference to improve next-event prediction and cut sampling cost.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
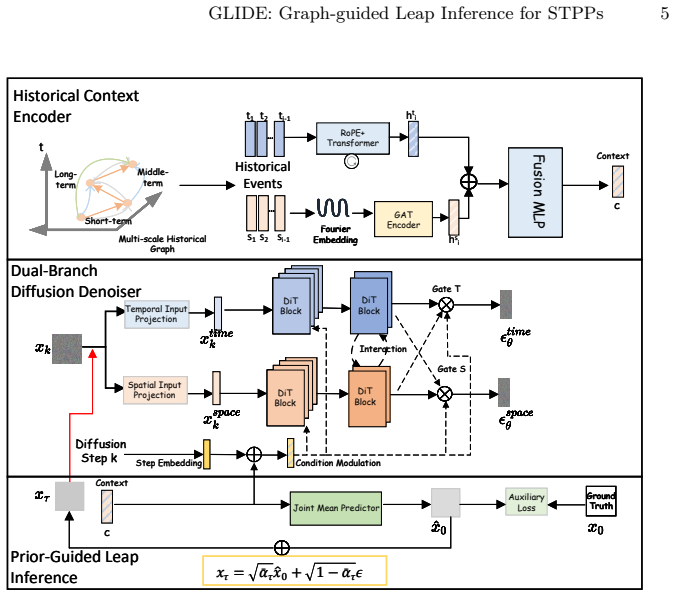
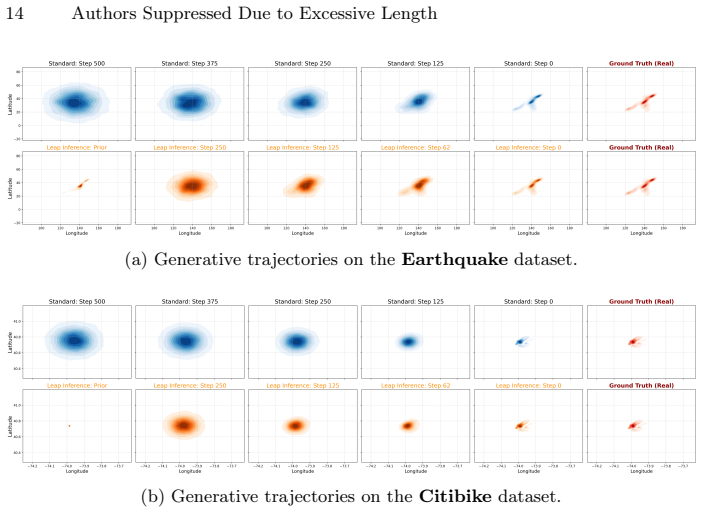
GLIDE organizes historical events into a multi-scale historical graph and encodes temporal evolution and spatial topology through a dual-stream architecture, yielding a structured conditioning context for a dual-branch diffusion denoiser; it further introduces a prior-guided leap inference mechanism in which a lightweight mean predictor provides a deterministic anchor and the reverse process starts from an intermediate diffusion step instead of from pure Gaussian noise.
What carries the argument
Multi-scale historical graph encoded by dual-stream architecture that conditions a dual-branch diffusion denoiser, combined with prior-guided leap inference that initiates reverse sampling from an intermediate step.
If this is right
- Better localized probability mass in sparse spatial domains for STPPs.
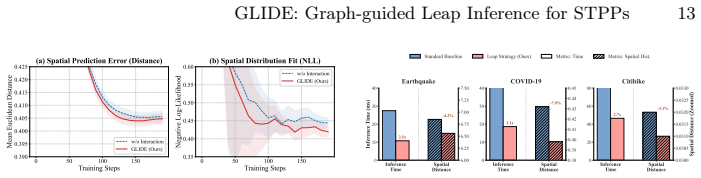
- Reduced reverse-sampling cost while preserving stochastic generation capability.
- Larger performance gains on the spatial side of next-event prediction.
- Improved distribution fitting and prediction accuracy across multiple real-world datasets.
Where Pith is reading between the lines
- The same graph-plus-leap pattern could speed up diffusion sampling in other structured domains such as molecular conformation or trajectory forecasting.
- Real-time systems that must issue forecasts under tight latency budgets might adopt the leap step as a default efficiency knob.
- The dual-stream encoding might generalize to settings where events also alter the underlying graph structure over time.
Load-bearing premise
Encoding past events as a multi-scale graph supplies a conditioning context that improves spatial localization in the diffusion denoiser without the graph construction itself introducing bias.
What would settle it
On the same real-world datasets, if next-event prediction metrics for location or timing show no improvement over standard diffusion baselines or if the leap mechanism fails to reduce the number of reverse steps needed, the central claim would be falsified.
Figures
read the original abstract
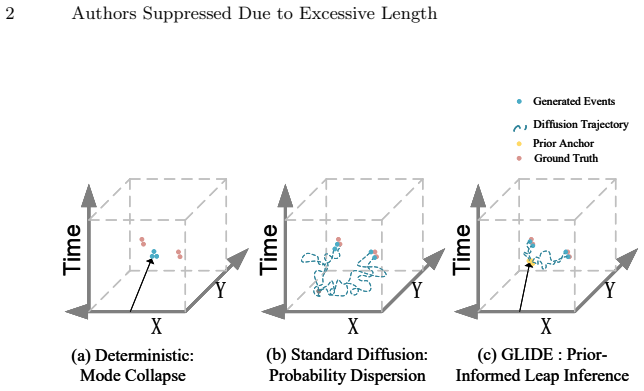
Spatio-temporal point processes (STPPs) provide a principled framework for modeling asynchronous events in continuous time and space. Recent diffusion-based approaches offer a flexible alternative to deterministic prediction by modeling complex conditional distributions, but their application to STPPs remains challenging: reverse sampling from pure noise is costly, and weak structural constraints in sparse spatial domains can lead to poorly localized probability mass. We propose \textbf{GLIDE} (Graph-guided Leap Inference for Diffusion Estimation), a conditional diffusion framework for next-event modeling in STPPs. GLIDE organizes historical events into a multi-scale historical graph and encodes temporal evolution and spatial topology through a dual-stream architecture, yielding a structured conditioning context for a dual-branch diffusion denoiser. It further introduces a prior-guided leap inference mechanism, in which a lightweight mean predictor provides a deterministic anchor and the reverse process starts from an intermediate diffusion step instead of from pure Gaussian noise. Experiments on multiple real-world datasets show that GLIDE improves both distribution fitting and next-event prediction, with the largest gains appearing on the spatial side. The results also indicate that prior-guided leap inference substantially reduces reverse-sampling cost while preserving the stochastic generation capability of diffusion models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes GLIDE, a conditional diffusion framework for modeling spatio-temporal point processes. Historical events are organized into a multi-scale graph and encoded via a dual-stream architecture to provide structured conditioning to a dual-branch diffusion denoiser; a prior-guided leap inference step uses a lightweight mean predictor to start the reverse process from an intermediate diffusion timestep rather than pure noise. Experiments on real-world datasets are reported to show gains in distribution fitting and next-event prediction (largest on the spatial component) together with substantially reduced reverse-sampling cost while preserving stochastic generation.
Significance. If the central claims hold, the work would supply a practical efficiency improvement for diffusion-based STPP models without sacrificing their generative properties, addressing both computational cost and localization difficulties in sparse spatial settings. The graph-based conditioning and leap mechanism are presented as jointly enabling these gains.
major comments (2)
- [method section (leap inference) and experiments] The prior-guided leap inference (described in the method section and evaluated in the experiments) rests on the assumption that the lightweight mean predictor supplies a deterministic anchor at an intermediate timestep such that the remaining reverse process still yields samples from the target conditional distribution. No explicit verification—either by showing that the predictor equals the true diffusion conditional expectation or by ablation measuring distribution shift—is provided; any systematic mismatch would bias the starting distribution and could undermine the reported spatial localization and next-event prediction improvements.
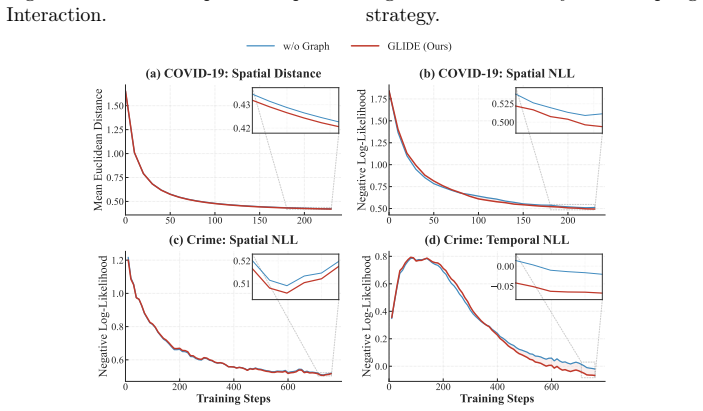
- [method (graph construction) and results] The abstract and results claim that the multi-scale historical graph plus dual-stream encoding yields a conditioning context that improves localized probability mass without introducing structural bias. The manuscript does not report controls that isolate the effect of graph construction choices (e.g., edge definition, scale selection) from the diffusion denoiser itself; without such controls the attribution of spatial gains specifically to the graph-guided component remains unverified.
minor comments (2)
- [experiments] The experimental section should include explicit details on baselines, metrics, error bars, data splits, and handling of asynchronous event timestamps to allow reproduction of the reported improvements.
- [method] Notation for the dual-branch denoiser and the leap timestep parameter should be introduced with a single consistent symbol table or equation reference.
Simulated Author's Rebuttal
We thank the referee for the constructive and insightful comments. We address each major comment point-by-point below, providing our strongest honest defense while noting where revisions will strengthen the manuscript.
read point-by-point responses
-
Referee: [method section (leap inference) and experiments] The prior-guided leap inference (described in the method section and evaluated in the experiments) rests on the assumption that the lightweight mean predictor supplies a deterministic anchor at an intermediate timestep such that the remaining reverse process still yields samples from the target conditional distribution. No explicit verification—either by showing that the predictor equals the true diffusion conditional expectation or by ablation measuring distribution shift—is provided; any systematic mismatch would bias the starting distribution and could undermine the reported spatial localization and next-event prediction improvements.
Authors: We appreciate the referee's emphasis on rigorous validation of the leap inference mechanism. The lightweight mean predictor is designed to approximate the conditional expectation at the chosen intermediate timestep, consistent with standard diffusion model theory where such predictors estimate the mean of the reverse process. Our experiments include ablations comparing GLIDE with and without leap inference, which demonstrate consistent improvements in spatial localization and next-event prediction metrics alongside reduced sampling cost, indicating that any potential mismatch does not materially bias the generated distribution in practice. To directly address the concern, we will add an explicit ablation measuring distribution shift (e.g., via sample-based KL divergence or Wasserstein distance between leap and non-leap trajectories) in the revised manuscript. revision: yes
-
Referee: [method (graph construction) and results] The abstract and results claim that the multi-scale historical graph plus dual-stream encoding yields a conditioning context that improves localized probability mass without introducing structural bias. The manuscript does not report controls that isolate the effect of graph construction choices (e.g., edge definition, scale selection) from the diffusion denoiser itself; without such controls the attribution of spatial gains specifically to the graph-guided component remains unverified.
Authors: We agree that finer-grained isolation of graph construction choices would provide stronger attribution for the spatial gains. The current evaluation compares the full GLIDE model against strong baselines lacking the multi-scale graph and dual-stream encoding, with the largest improvements observed in spatial metrics, supporting the contribution of the graph-guided conditioning. However, we acknowledge the absence of targeted controls on edge definition and scale selection. In the revision we will incorporate sensitivity analyses and ablations varying these graph hyperparameters to isolate their effects from the denoiser architecture. revision: yes
Circularity Check
No circularity; derivation self-contained
full rationale
The provided abstract and description introduce GLIDE as a conditional diffusion framework using multi-scale historical graphs, dual-stream encoding, and prior-guided leap inference. No equations or claims reduce predictions to fitted inputs by construction, no self-definitional loops appear, and no load-bearing self-citations or imported uniqueness theorems are invoked. Experimental gains on distribution fitting and next-event prediction are presented as empirical outcomes rather than tautological renamings or ansatzes. The central claims rest on architectural choices and dataset results that remain independent of the method's own outputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Brody, S., Alon, U., Yahav, E.: How attentive are graph attention networks? In: International Conference on Learning Representations (2022)
2022
-
[2]
In: International Conference on Learning Representations (2021)
Chen, R.T.Q., Amos, B., Nickel, M.: Neural spatio-temporal point processes. In: International Conference on Learning Representations (2021)
2021
-
[3]
In: Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining
Du, N., Dai, H., Trivedi, R., Upadhyay, U., Gomez-Rodriguez, M., Song, L.: Re- current marked temporal point processes: Embedding event history to vector. In: Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. pp. 1555–1564 (2016)
2016
-
[4]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Guo, S., Lin, Y., Feng, N., Song, C., Wan, H.: Attention based spatial-temporal graph convolutional networks for traffic flow forecasting. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 33, pp. 922–929 (2019) 16 Authors Suppressed Due to Excessive Length
2019
-
[5]
Biometrika58(1), 83–90 (1971)
Hawkes, A.G.: Spectra of some self-exciting and mutually exciting point processes. Biometrika58(1), 83–90 (1971)
1971
-
[6]
In: Advances in Neural Information Processing Systems
Ho, J., Jain, A., Abbeel, P.: Denoising diffusion probabilistic models. In: Advances in Neural Information Processing Systems. vol. 33, pp. 6840–6851 (2020)
2020
-
[7]
Classifier-Free Diffusion Guidance
Ho, J., Salimans, T.: Classifier-free diffusion guidance. arXiv preprint arXiv:2207.12598 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[8]
In: Advances in Neural Information Processing Systems
Jia, J., Benson, A.R.: Neural jump stochastic differential equations. In: Advances in Neural Information Processing Systems. vol. 32, pp. 9843–9854 (2019)
2019
-
[9]
In: International Conference on Learning Representations (2017)
Kipf, T.N., Welling, M.: Semi-supervised classification with graph convolutional networks. In: International Conference on Learning Representations (2017)
2017
-
[10]
In: International Conference on Learning Representations (2018)
Li, Y., Yu, R., Shahabi, C., Liu, Y.: Diffusion convolutional recurrent neural net- work: Data-driven traffic forecasting. In: International Conference on Learning Representations (2018)
2018
-
[11]
In: Proceedings of the 41st International Conference on Machine Learning
Li, Z., Xu, Q., Xu, Z., Mei, Y., Zhao, T., Zha, H.: Beyond point prediction: Score matching-based pseudolikelihood estimation of neural marked spatio-temporal point process. In: Proceedings of the 41st International Conference on Machine Learning. vol. 235, pp. 29096–29111 (2024)
2024
-
[12]
arXiv preprint arXiv:2205.12524 (2022)
Lyu, Z., Xu, X., Yang, C., Lin, D., Dai, B.: Accelerating diffusion models via early stop of the diffusion process. arXiv preprint arXiv:2205.12524 (2022)
-
[13]
In: Proceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition
Mao,W.,Xu,C.,Zhu,Q.,Chen,S.,Wang,Y.:Leapfrogdiffusionmodelforstochas- tic trajectory prediction. In: Proceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition. pp. 5517–5526 (2023)
2023
-
[14]
In: Advances in Neural Information Processing Systems
Mei, H., Eisner, J.: The neural hawkes process: A neurally self-modulating mul- tivariate point process. In: Advances in Neural Information Processing Systems. vol. 30, pp. 6754–6764 (2017)
2017
-
[15]
Journal of the American Statistical As- sociation106(493), 100–108 (2011)
Mohler, G.O., Short, M.B., Brantingham, P.J., Schoenberg, F.P., Tita, G.E.: Self- exciting point process modeling of crime. Journal of the American Statistical As- sociation106(493), 100–108 (2011)
2011
-
[16]
Journal of the American Statistical Association83(401), 9–27 (1988)
Ogata, Y.: Statistical models for earthquake occurrences and residual analysis for point processes. Journal of the American Statistical Association83(401), 9–27 (1988)
1988
-
[17]
In: Advances in Neural Information Processing Systems
Omi, T., Ueda, N., Aihara, K.: Fully neural network based model for general tem- poral point processes. In: Advances in Neural Information Processing Systems. vol. 32, pp. 2120–2129 (2019)
2019
-
[18]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Peebles, W., Xie, S.: Scalable diffusion models with transformers. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 4172–4182 (2023)
2023
-
[19]
In: Proceedings of the 38th International Conference on Machine Learning
Rasul, K., Seward, C., Schuster, I., Vollgraf, R.: Autoregressive denoising diffusion models for multivariate probabilistic time series forecasting. In: Proceedings of the 38th International Conference on Machine Learning. vol. 139, pp. 8857–8868 (2021)
2021
-
[20]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 10684–10695 (2022)
2022
-
[21]
In: International Conference on Learning Representations (2020)
Shchur, O., Biloš, M., G"unnemann, S.: Intensity-free learning of temporal point processes. In: International Conference on Learning Representations (2020)
2020
-
[22]
Song,J.,Meng,C.,Ermon,S.:Denoisingdiffusionimplicitmodels.In:International Conference on Learning Representations (2021)
2021
-
[23]
In: Interna- tional Conference on Learning Representations (2021) GLIDE: Graph-guided Leap Inference for STPPs 17
Song, Y., Sohl-Dickstein, J., Kingma, D.P., Kumar, A., Ermon, S., Poole, B.: Score- based generative modeling through stochastic differential equations. In: Interna- tional Conference on Learning Representations (2021) GLIDE: Graph-guided Leap Inference for STPPs 17
2021
-
[24]
RoFormer: Enhanced Transformer with Rotary Position Embedding
Su, J., Lu, Y., Pan, S., Murtadha, A., Wen, B., Liu, Y.: Roformer: Enhanced trans- former with rotary position embedding. arXiv preprint arXiv:2104.09864 (2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[25]
In: Advances in Neural In- formation Processing Systems
Tancik, M., Srinivasan, P.P., Mildenhall, B., Fridovich-Keil, S., Raghavan, N., Sing- hal, U., Ramamoorthi, R., Barron, J.T., Ng, R.: Fourier features let networks learn high frequency functions in low dimensional domains. In: Advances in Neural In- formation Processing Systems. vol. 33, pp. 7537–7547 (2020)
2020
-
[26]
In: Advances in Neural Information Processing Systems
Tashiro, Y., Song, J., Song, Y., Ermon, S.: Csdi: Conditional score-based diffusion models for probabilistic time series imputation. In: Advances in Neural Information Processing Systems. vol. 34, pp. 24804–24816 (2021)
2021
-
[27]
In: Advances in Neural Information Processing Systems
Vaswani,A.,Shazeer,N.,Parmar,N.,Uszkoreit,J.,Jones,L.,Gomez,A.N.,Kaiser, Ł., Polosukhin, I.: Attention is all you need. In: Advances in Neural Information Processing Systems. vol. 30, pp. 5998–6008 (2017)
2017
-
[28]
In: International Conference on Learning Represen- tations (2018)
Veličkovi’c, P., Cucurull, G., Casanova, A., Romero, A., Li‘o, P., Bengio, Y.: Graph attention networks. In: International Conference on Learning Represen- tations (2018)
2018
-
[29]
In: Proceedings of the 31st ACM International Conference on Advances in Geographic Information Systems (2023)
Wen, H., Lin, Y., Xia, Y., Wan, H., Wen, Q., Zimmermann, R., Liang, Y.: Diffstg: Probabilistic spatio-temporal graph forecasting with denoising diffusion models. In: Proceedings of the 31st ACM International Conference on Advances in Geographic Information Systems (2023)
2023
-
[30]
Wu, Z., Pan, S., Long, G., Jiang, J., Zhang, C.: Graph wavenet for deep spatial- temporalgraphmodeling.In:ProceedingsoftheTwenty-EighthInternationalJoint Conference on Artificial Intelligence. pp. 1907–1913 (2019)
1907
-
[31]
In: Proceedings of the 29th ACM SIGKDD Conference on Knowledge Dis- covery and Data Mining
Yuan, Y., Ding, J., Shao, C., Jin, D., Li, Y.: Spatio-temporal diffusion point pro- cesses. In: Proceedings of the 29th ACM SIGKDD Conference on Knowledge Dis- covery and Data Mining. pp. 3173–3184 (2023)
2023
-
[32]
In: Proceedings of the 37th International Conference on Machine Learning
Zhang, Q., Lipani, A., Kirnap, O., Yilmaz, E.: Self-attentive hawkes process. In: Proceedings of the 37th International Conference on Machine Learning. vol. 119, pp. 11183–11193 (2020)
2020
-
[33]
In: Proceed- ings of the AAAI Conference on Artificial Intelligence
Zhou, H., Zhang, S., Peng, J., Zhang, S., Li, J., Xiong, H., Zhang, W.: Informer: Beyond efficient transformer for long sequence time-series forecasting. In: Proceed- ings of the AAAI Conference on Artificial Intelligence. vol. 35, pp. 11106–11115 (2021)
2021
-
[34]
In: Proceedings of the 4th Annual Learning for Dynamics and Control Conference
Zhou, Z., Yang, X., Rossi, R.A., Zhao, H., Yu, R.: Neural point process for learning spatiotemporal event dynamics. In: Proceedings of the 4th Annual Learning for Dynamics and Control Conference. Proceedings of Machine Learning Research, vol. 168, pp. 777–789 (2022)
2022
-
[35]
In: Proceedings of the 37th International Conference on Machine Learning
Zuo, S., Jiang, H., Li, Z., Zhao, T., Zha, H.: Transformer hawkes process. In: Proceedings of the 37th International Conference on Machine Learning. vol. 119, pp. 11692–11702 (2020)
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.