ANDES: Agent Native Data Evolving Synthesis Tool for Autonomous Instruction Alignment
Pith reviewed 2026-06-28 16:57 UTC · model grok-4.3
The pith
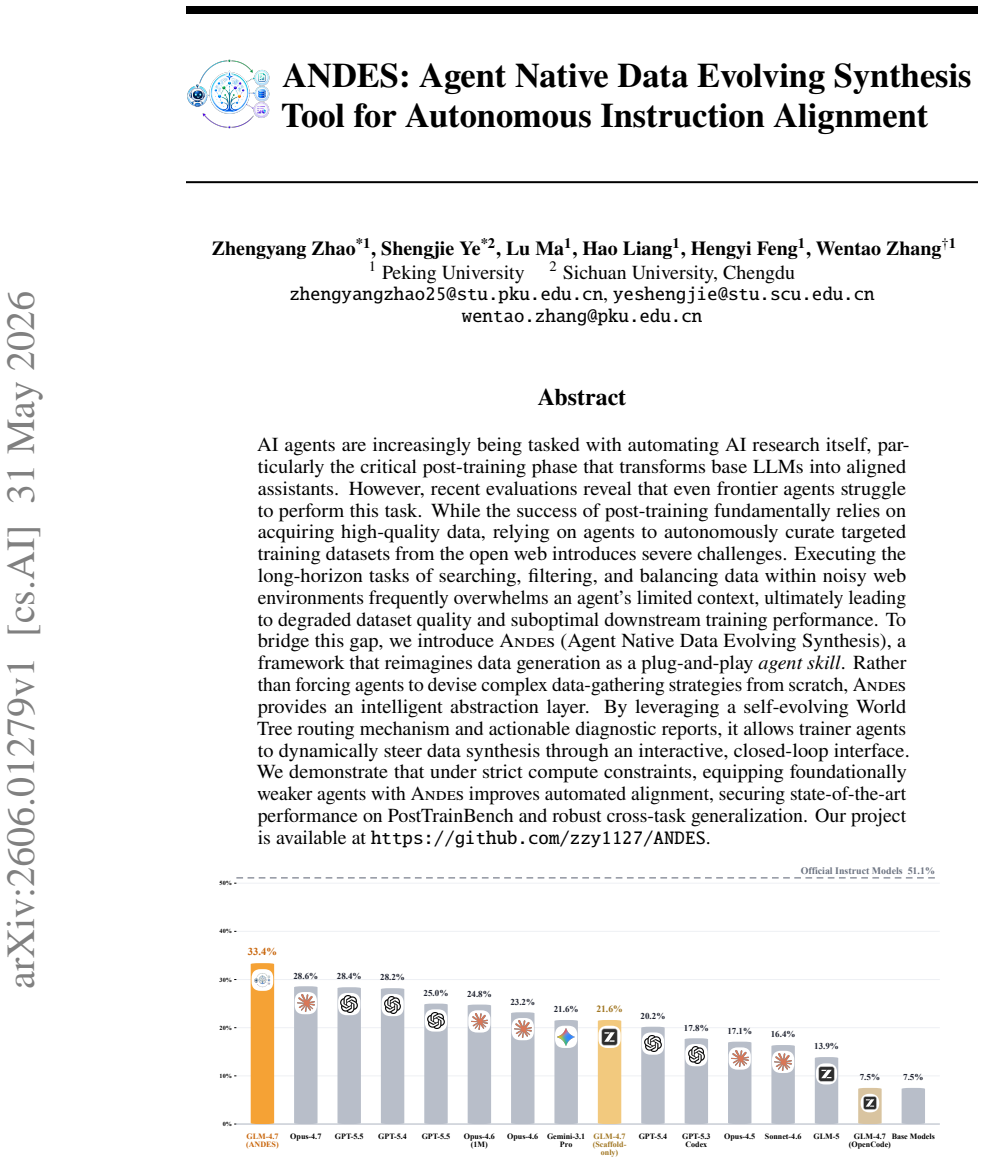
Equipping weaker agents with Andes lets them synthesize high-quality alignment data and reach state-of-the-art on PostTrainBench.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
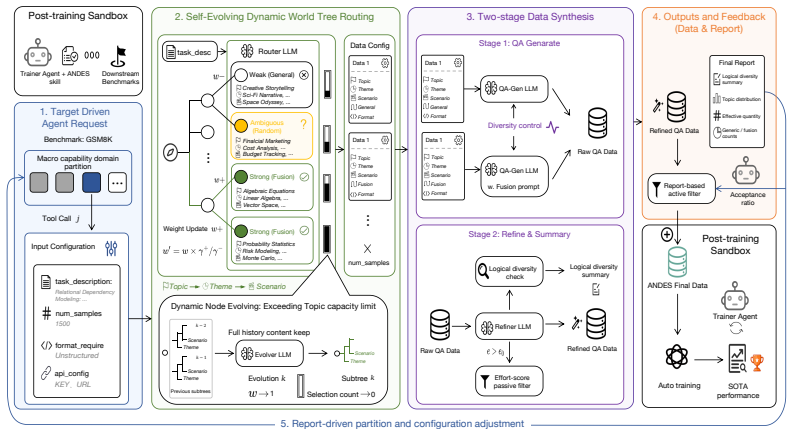
Andes reimagines data generation as a plug-and-play agent skill. By leveraging a self-evolving World Tree routing mechanism and actionable diagnostic reports, it allows trainer agents to dynamically steer data synthesis through an interactive, closed-loop interface. Equipping foundationally weaker agents with Andes improves automated alignment, securing state-of-the-art performance on PostTrainBench and robust cross-task generalization.
What carries the argument
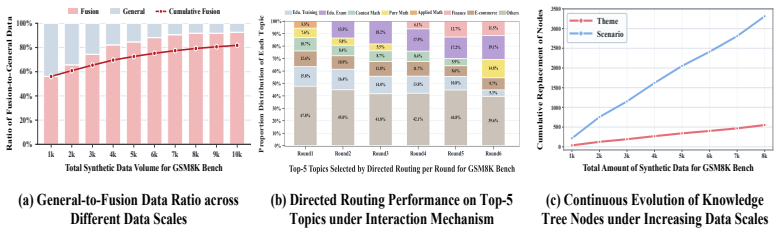
The self-evolving World Tree routing mechanism that supplies an abstraction layer for agents to steer data synthesis via diagnostic feedback.
If this is right
- Weaker agents can now handle long-horizon web data tasks without devising strategies from scratch.
- Automated alignment reaches state-of-the-art on PostTrainBench under strict compute constraints.
- Cross-task generalization improves because the same interface works across different alignment objectives.
- Dataset quality rises because the closed-loop interface filters and balances data dynamically.
Where Pith is reading between the lines
- The same routing-plus-diagnostics pattern could be applied to other agent tasks that require long-horizon information gathering.
- Widespread adoption might shrink the amount of human-curated seed data needed for alignment pipelines.
- If the mechanism scales, it could support more fully autonomous research agents that iterate on their own training data.
Load-bearing premise
The routing mechanism and diagnostic reports let agents steer synthesis effectively in noisy web settings without context overload.
What would settle it
An experiment in which Andes-equipped agents still generate low-quality or unbalanced datasets and fail to beat baselines on PostTrainBench.
Figures


read the original abstract
AI agents are increasingly being tasked with automating AI research itself, particularly the critical post-training phase that transforms base LLMs into aligned assistants. However, recent evaluations reveal that even frontier agents struggle to perform this task. While the success of post-training fundamentally relies on acquiring high-quality data, relying on agents to autonomously curate targeted training datasets from the open web introduces severe challenges. Executing the long-horizon tasks of searching, filtering, and balancing data within noisy web environments frequently overwhelms an agent's limited context, ultimately leading to degraded dataset quality and suboptimal downstream training performance. To bridge this gap, we introduce Andes (Agent Native Data Evolving Synthesis), a framework that reimagines data generation as a plug-and-play \emph{agent skill}. Rather than forcing agents to devise complex data-gathering strategies from scratch, \textsc{Andes} provides an intelligent abstraction layer. By leveraging a self-evolving World Tree routing mechanism and actionable diagnostic reports, it allows trainer agents to dynamically steer data synthesis through an interactive, closed-loop interface. We demonstrate that under strict compute constraints, equipping foundationally weaker agents with Andes improves automated alignment, securing state-of-the-art performance on PostTrainBench and robust cross-task generalization. Our project is available at https://github.com/zzy1127/ANDES.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the ANDES framework, which reimagines data generation for post-training alignment as a plug-and-play agent skill. It employs a self-evolving World Tree routing mechanism and actionable diagnostic reports to enable trainer agents to steer data synthesis in an interactive closed-loop manner, addressing context overload in noisy web environments. The authors claim that this allows foundationally weaker agents to achieve state-of-the-art performance on PostTrainBench with robust cross-task generalization under strict compute constraints.
Significance. If the reported results hold, this work has the potential to significantly advance the field of automated AI alignment by making high-quality data curation accessible to less capable agents. A notable strength is the open availability of the project code on GitHub, which supports reproducibility and further research. The experimental evidence provided in the full manuscript addresses the potential concern regarding the effectiveness of the World Tree mechanism in noisy environments, as the metrics demonstrate successful steering without the expected degradation.
minor comments (3)
- [Abstract] The phrase 'strict compute constraints' is used but not quantified; providing specific details such as token limits or hardware specifications in the main text would improve clarity.
- [§3] The description of the self-evolving World Tree could include a small example or diagram to illustrate how routing evolves over iterations.
- [Table 2] The cross-task generalization results would benefit from additional baseline comparisons to strengthen the robustness claim.
Simulated Author's Rebuttal
We thank the referee for their positive summary, recognition of the potential significance of the work, and recommendation for minor revision. We are pleased that the provided experimental evidence was found to address concerns about the World Tree mechanism in noisy environments, and we appreciate the acknowledgment of the open-source code supporting reproducibility.
Circularity Check
No significant circularity
full rationale
The paper presents Andes as a new agent-native framework for data synthesis, relying on a self-evolving World Tree routing mechanism and diagnostic reports to enable closed-loop steering by trainer agents. All central claims rest on experimental results under stated compute constraints on PostTrainBench and cross-task generalization, with no equations, fitted parameters, or derivations that reduce outputs to inputs by construction. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes, and the framework is introduced as an original abstraction layer rather than a renaming or self-referential fit. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
invented entities (1)
-
self-evolving World Tree routing mechanism
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Ultraif: Advancing instruction following from the wild, 2025
Kaikai An, Li Sheng, Ganqu Cui, Shuzheng Si, Ning Ding, Yu Cheng, and Baobao Chang. Ultraif: Advancing instruction following from the wild, 2025
2025
-
[2]
Rahul K. Arora, Jason Wei, Rebecca Soskin Hicks, Preston Bowman, Joaquin Quiñonero- Candela, Foivos Tsimpourlas, Michael Sharman, Meghan Shah, Andrea Vallone, Alex Beutel, JohannesHeidecke,andKaranSinghal. Healthbench: Evaluatinglargelanguagemodelstowards improved human health, 2025
2025
-
[3]
Program Synthesis with Large Language Models
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, et al. Program synthesis with large language models.arXiv preprint arXiv:2108.07732, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[4]
Condor: Enhance llm alignment with knowledge-driven data synthesis and refinement, 2025
Maosong Cao, Taolin Zhang, Mo Li, Chuyu Zhang, Yunxin Liu, Haodong Duan, Songyang Zhang, and Kai Chen. Condor: Enhance llm alignment with knowledge-driven data synthesis and refinement, 2025
2025
-
[5]
Mle-bench: Evaluating machine learning agents on machine learning engineering, 2025
JunShernChan, NeilChowdhury, OliverJaffe, JamesAung, DaneSherburn, EvanMays, Giulio Starace, Kevin Liu, Leon Maksin, Tejal Patwardhan, Lilian Weng, and Aleksander Mądry. Mle-bench: Evaluating machine learning agents on machine learning engineering, 2025
2025
-
[6]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian...
2021
-
[7]
Training verifiers to solve math word problems, 2021
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems, 2021
2021
-
[8]
Self-play with execution feedback: Improving instruction-following capabilities of large language models, 2024
Guanting Dong, Keming Lu, Chengpeng Li, Tingyu Xia, Bowen Yu, Chang Zhou, and Jingren Zhou. Self-play with execution feedback: Improving instruction-following capabilities of large language models, 2024
2024
-
[9]
Longcli-bench: A preliminary benchmark and study for long-horizon agentic programming in command-line interfaces, 2026
YukangFeng, JianwenSun, ZelaiYang, JiaxinAi, ChuanhaoLi, ZizhenLi, FanruiZhang, Kang He, Rui Ma, Jifan Lin, Jie Sun, Yang Xiao, Sizhuo Zhou, Wenxiao Wu, Yiming Liu, Pengfei Liu, Yu Qiao, Shenglin Zhang, and Kaipeng Zhang. Longcli-bench: A preliminary benchmark and study for long-horizon agentic programming in command-line interfaces, 2026
2026
-
[10]
Measuring massive multitask language understanding.Proceedings of the International Conference on Learning Representations (ICLR), 2021
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding.Proceedings of the International Conference on Learning Representations (ICLR), 2021
2021
-
[11]
Mlagentbench: Evaluating language agents on machine learning experimentation, 2024
Qian Huang, Jian Vora, Percy Liang, and Jure Leskovec. Mlagentbench: Evaluating language agents on machine learning experimentation, 2024
2024
-
[12]
Yuzhen Huang, Yuzhuo Bai, Zhihao Zhu, Junlei Zhang, Jinghan Zhang, Tangjun Su, Junteng Liu, Chuancheng Lv, Yikai Zhang, Jiayi Lei, Yao Fu, Maosong Sun, and Junxian He. C-eval: A multi-level multi-discipline chinese evaluation suite for foundation models.arXiv preprint arXiv:2305.08322, 2023
-
[13]
Decif: Improving instruction-following through meta-decomposition, 2025
Tingfeng Hui, Pengyu Zhu, Bowen Ping, Ling Tang, Guanting Dong, Yaqi Zhang, and Sen Su. Decif: Improving instruction-following through meta-decomposition, 2025
2025
-
[14]
Aide: Ai-driven exploration in the space of code, 2025
Zhengyao Jiang, Dominik Schmidt, Dhruv Srikanth, Dixing Xu, Ian Kaplan, Deniss Jacenko, and Yuxiang Wu. Aide: Ai-driven exploration in the space of code, 2025. 10
2025
-
[15]
Wist: Web-grounded iterative self-play tree for domain-targeted reasoning improvement, 2026
Fangyuan Li, Pengfei Li, Shijie Wang, Junqi Gao, Jianxing Liu, Biqing Qi, and Yuqiang Li. Wist: Web-grounded iterative self-play tree for domain-targeted reasoning improvement, 2026
2026
-
[16]
Traineragent: Customizable and efficient model training through llm-powered multi-agent system, 2023
Haoyuan Li, Hao Jiang, Tianke Zhang, Zhelun Yu, Aoxiong Yin, Hao Cheng, Siming Fu, Yuhao Zhang, and Wanggui He. Traineragent: Customizable and efficient model training through llm-powered multi-agent system, 2023
2023
-
[17]
Infinity instruct: Scaling instruction selection and synthesis to enhance language models, 2025
Jijie Li, Li Du, Hanyu Zhao, Bo wen Zhang, Liangdong Wang, Boyan Gao, Guang Liu, and Yonghua Lin. Infinity instruct: Scaling instruction selection and synthesis to enhance language models, 2025
2025
-
[18]
Gonzalez, and Ion Stoica
Tianle Li, Wei-Lin Chiang, Evan Frick, Lisa Dunlap, Banghua Zhu, Joseph E. Gonzalez, and Ion Stoica. From live data to high-quality benchmarks: The arena-hard pipeline, April 2024
2024
-
[19]
Autosota: An end-to-end automated research system for state-of-the-art ai model discovery, 2026
Yu Li, Chenyang Shao, Xinyang Liu, Ruotong Zhao, Peijie Liu, Hongyuan Su, Zhibin Chen, Qinglong Yang, Anjie Xu, Yi Fang, Qingbin Zeng, Tianxing Li, Jingbo Xu, Fengli Xu, Yong Li, and Tie-Yan Liu. Autosota: An end-to-end automated research system for state-of-the-art ai model discovery, 2026
2026
-
[20]
Dataflow: An llm-driven framework for unified data preparation and workflow automation in the era of data-centric ai, 2025
Hao Liang, Xiaochen Ma, Zhou Liu, Zhen Hao Wong, Zhengyang Zhao, Zimo Meng, Runming He, Chengyu Shen, Qifeng Cai, Zhaoyang Han, Meiyi Qiang, Yalin Feng, Tianyi Bai, Zewei Pan, Ziyi Guo, Yizhen Jiang, Jingwen Deng, Qijie You, Peichao Lai, Tianyu Guo, Chi Hsu Tsai, Hengyi Feng, Rui Hu, Wenkai Yu, Junbo Niu, Bohan Zeng, Ruichuan An, Lu Ma, Jihao Huang, Yaowe...
2025
-
[21]
The ai scientist: Towards fully automated open-ended scientific discovery, 2024
Chris Lu, Cong Lu, Robert Tjarko Lange, Jakob Foerster, Jeff Clune, and David Ha. The ai scientist: Towards fully automated open-ended scientific discovery, 2024
2024
-
[22]
Trex: Automating llm fine-tuning via agent-driven tree-based exploration, 2026
ZerunMa,GuoqiangWang,XinchenXie,YichengChen,HeDu,BowenLi,YananSun,Wenran Liu, Kai Chen, and Yining Li. Trex: Automating llm fine-tuning via agent-driven tree-based exploration, 2026
2026
-
[23]
AlexanderNovikov,NgânV ˜u,MarvinEisenberger,EmilienDupont,Po-SenHuang,AdamZsolt Wagner, Sergey Shirobokov, Borislav Kozlovskii, Francisco J. R. Ruiz, Abbas Mehrabian, M. Pawan Kumar, Abigail See, Swarat Chaudhuri, George Holland, Alex Davies, Sebastian Nowozin, Pushmeet Kohli, and Matej Balog. Alphaevolve: A coding agent for scientific and algorithmic dis...
2025
-
[24]
Patil, Huanzhi Mao, Charlie Cheng-Jie Ji, Fanjia Yan, Vishnu Suresh, Ion Stoica, and Joseph E
Shishir G. Patil, Huanzhi Mao, Charlie Cheng-Jie Ji, Fanjia Yan, Vishnu Suresh, Ion Stoica, and Joseph E. Gonzalez. The berkeley function calling leaderboard (bfcl): From tool use to agentic evaluation of large language models. InForty-second International Conference on Machine Learning, 2025
2025
-
[25]
Posttrainbench: Can llm agents automate llm post-training? 2026
BenRank,HardikBhatnagar,AmeyaPrabhu,ShiraEisenberg,KarinaNguyen,MatthiasBethge, and Maksym Andriushchenko. Posttrainbench: Can llm agents automate llm post-training? 2026
2026
-
[26]
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R. Bowman. Gpqa: A graduate-level google-proof q&a benchmark, 2023
2023
-
[27]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y. K. Li, Y. Wu, and Daya Guo. Deepseekmath: Pushing the limits of mathematical reasoning in open language models, 2024
2024
-
[28]
Middo: Model-informed dynamic data optimization for enhanced llm fine-tuning via closed-loop learning, 2025
Zinan Tang, Xin Gao, Qizhi Pei, Zhuoshi Pan, Mengzhang Cai, Jiang Wu, Conghui He, and Lijun Wu. Middo: Model-informed dynamic data optimization for enhanced llm fine-tuning via closed-loop learning, 2025. 11
2025
-
[29]
Matrix: Peer-to-peer multi-agent synthetic data generation framework, 2025
Dong Wang, Yang Li, Ansong Ni, Ching-Feng Yeh, Youssef Emad, Xinjie Lei, Liam Robbins, Karthik Padthe, Hu Xu, Xian Li, Asli Celikyilmaz, Ramya Raghavendra, Lifei Huang, Carole- Jean Wu, and Shang-Wen Li. Matrix: Peer-to-peer multi-agent synthetic data generation framework, 2025
2025
-
[30]
Self-instruct: Aligning language models with self-generated instructions, 2023
YizhongWang,YeganehKordi,SwaroopMishra,AlisaLiu,NoahA.Smith,DanielKhashabi,and Hannaneh Hajishirzi. Self-instruct: Aligning language models with self-generated instructions, 2023
2023
-
[31]
On the generalization of sft: A reinforcement learning perspective with reward rectification, 2026
Yongliang Wu, Yizhou Zhou, Zhou Ziheng, Yingzhe Peng, Xinyu Ye, Xinting Hu, Wenbo Zhu, Lu Qi, Ming-Hsuan Yang, and Xu Yang. On the generalization of sft: A reinforcement learning perspective with reward rectification, 2026
2026
-
[32]
Wizardlm: Empowering large pre-trained language models to follow complex instructions, 2025
Can Xu, Qingfeng Sun, Kai Zheng, Xiubo Geng, Pu Zhao, Jiazhan Feng, Chongyang Tao, Qingwei Lin, and Daxin Jiang. Wizardlm: Empowering large pre-trained language models to follow complex instructions, 2025
2025
-
[33]
Magpie: Alignment data synthesis from scratch by prompting aligned llms with nothing, 2024
Zhangchen Xu, Fengqing Jiang, Luyao Niu, Yuntian Deng, Radha Poovendran, Yejin Choi, and Bill Yuchen Lin. Magpie: Alignment data synthesis from scratch by prompting aligned llms with nothing, 2024
2024
-
[34]
The ai scientist-v2: Workshop-level automated scientific discovery via agentic tree search, 2025
Yutaro Yamada, Robert Tjarko Lange, Cong Lu, Shengran Hu, Chris Lu, Jakob Foerster, Jeff Clune, and David Ha. The ai scientist-v2: Workshop-level automated scientific discovery via agentic tree search, 2025
2025
-
[35]
Dapo: An open-source llm reinforcement learning system at scale, 2025
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, Xin Liu, Haibin Lin, Zhiqi Lin, Bole Ma, Guangming Sheng, Yuxuan Tong, Chi Zhang, Mofan Zhang, Wang Zhang, Hang Zhu, Jinhua Zhu, Jiaze Chen, Jiangjie Chen, Chengyi Wang, Hongli Yu, Yuxuan Song, Xiangpeng Wei, Hao Zhou, Jingjing Liu, W...
2025
-
[36]
Gift: Reconciling post-training objectives via finite-temperature gibbs initialization, 2026
Zhengyang Zhao, Lu Ma, Yizhen Jiang, Xiaochen Ma, Zimo Meng, Chengyu Shen, Lexiang Tang, Haoze Sun, Peng Pei, and Wentao Zhang. Gift: Reconciling post-training objectives via finite-temperature gibbs initialization, 2026
2026
-
[37]
Agieval: A human-centric benchmark for evaluating foundation models, 2023
Wanjun Zhong, Ruixiang Cui, Yiduo Guo, Yaobo Liang, Shuai Lu, Yanlin Wang, Amin Saied, Weizhu Chen, and Nan Duan. Agieval: A human-centric benchmark for evaluating foundation models, 2023
2023
-
[38]
Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, Uri Alon, and Graham Neubig
Shuyan Zhou, Frank F. Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, Uri Alon, and Graham Neubig. Webarena: A realistic web environment for building autonomous agents, 2024
2024
-
[39]
scaffold-only
Alan Zhu, Parth Asawa, Jared Quincy Davis, Lingjiao Chen, Boris Hanin, Ion Stoica, Joseph E. Gonzalez, and Matei Zaharia. Bare: Leveraging base language models for few-shot synthetic data generation, 2025. 12 Appendix Content A Implementation Details 13 A.1 Sandbox and Hardware . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13 A.2 Agent S...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.