Feature to Dynamics: Feature-space to Autoregression strategy for Zero-shot Time Series Forecasting
Pith reviewed 2026-06-28 17:18 UTC · model grok-4.3
The pith
Mapping from interpretable features to autoregressive strategies enables better zero-shot time series forecasting than direct sequence modeling.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
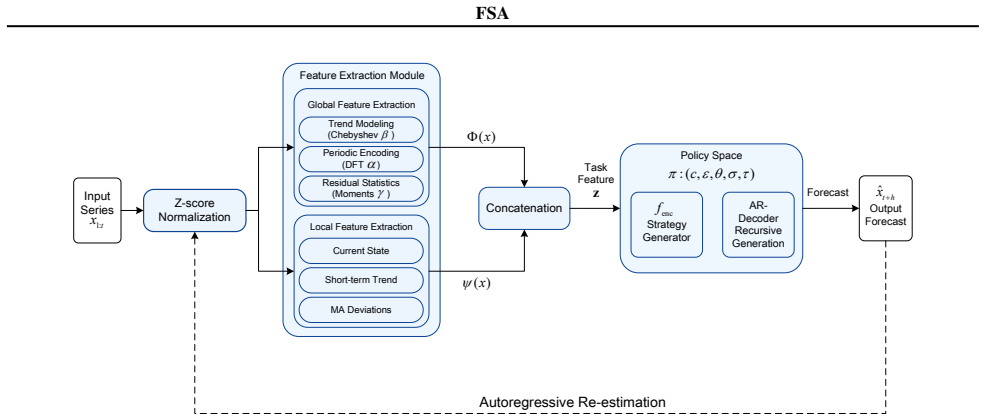
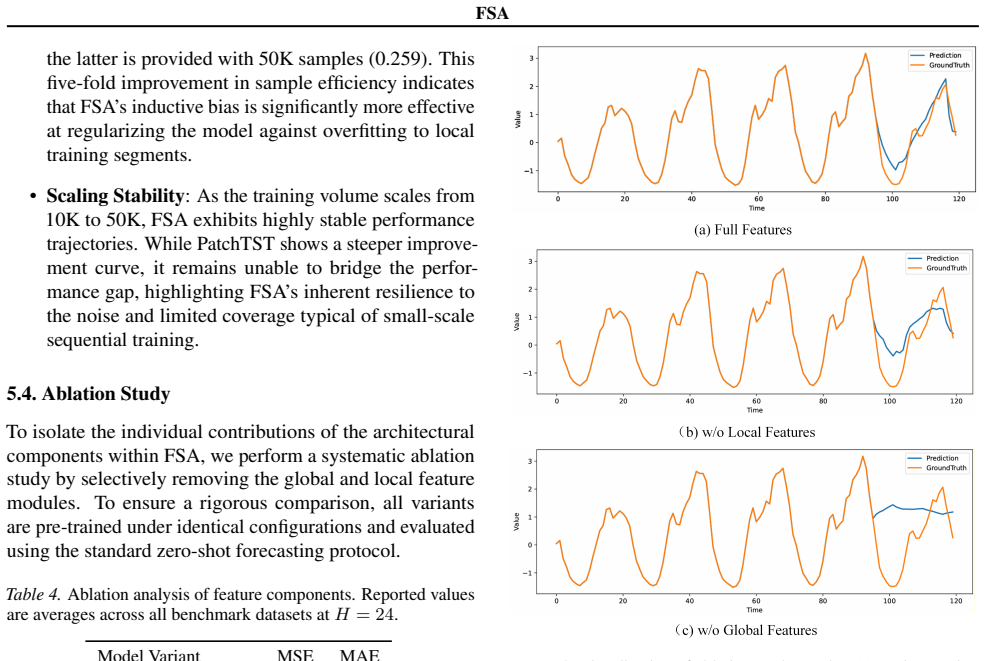
FSA learns a structured mapping from an interpretable feature space to an autoregressive strategy space. This design introduces explicit inductive biases that disentangle global trends, periodic components, and local temporal dynamics, enabling the model to capture transferable time-series structure with fewer data assumptions. Empirical results show that, under identical pretraining data, training protocol, and comparable parameter budgets, FSA outperforms Transformer-based architectures in the controlled zero-shot setting.
What carries the argument
The feature-to-autoregression strategy mapping that explicitly disentangles trends, periodic components, and local dynamics to produce transferable forecasting strategies.
If this is right
- FSA achieves better zero-shot univariate forecasting performance than Transformers under matched pretraining conditions.
- Explicit disentanglement supports generalization when source and target domains are disjoint.
- The model captures transferable structure while relying on fewer implicit assumptions about data patterns.
- Performance gains hold when data coverage is limited compared to broad pretraining approaches.
Where Pith is reading between the lines
- The same feature-to-strategy mapping could be tested on multivariate series by extending the feature extraction step.
- Autoregressive strategies produced by the mapping might be recombined for multi-horizon or hierarchical forecasting tasks.
- The approach suggests that making the intermediate representation more interpretable could improve robustness to distribution shifts beyond what scale alone provides.
Load-bearing premise
An interpretable feature space can be constructed whose explicit disentanglement of trends, periodic components, and local dynamics produces transferable autoregressive strategies that generalize beyond the training distribution with fewer data assumptions than direct sequence modeling.
What would settle it
A controlled experiment with identical pretraining data and parameter budgets in which a Transformer-based model matches or exceeds FSA zero-shot performance on unseen series would falsify the superiority claim.
Figures


read the original abstract
Zero-shot time series forecasting aims to predict future values for previously unseen series, requiring models to generalize temporal dynamics beyond the training distribution. While recent foundation models achieve strong in-domain performance through large-scale pretraining, their effectiveness often relies on broad data coverage and implicit pattern memorization, which can limit generalization when data are scarce or source and target domains are disjoint. In this work, we propose FSA, a feature-to-strategy framework for controlled zero-shot univariate forecasting. Instead of directly modeling raw sequences in the observation space, FSA learns a structured mapping from an interpretable feature space to an autoregressive strategy space. This design introduces explicit inductive biases that disentangle global trends, periodic components, and local temporal dynamics, enabling the model to capture transferable time-series structure with fewer data assumptions. Empirical results show that, under identical pretraining data, training protocol, and comparable parameter budgets, FSA outperforms Transformer-based architectures in our controlled zero-shot setting.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes FSA, a feature-to-strategy framework for zero-shot univariate time series forecasting. Instead of direct sequence modeling, it constructs an interpretable feature space that explicitly disentangles global trends, periodic components, and local dynamics, then learns a mapping from this space to autoregressive strategies. The central empirical claim is that, under identical pretraining data, training protocol, and comparable parameter budgets, FSA outperforms Transformer-based architectures in controlled zero-shot settings.
Significance. If the controlled comparison is valid, the explicit inductive biases could improve generalization in data-scarce or domain-disjoint scenarios compared to implicit memorization in large foundation models. The interpretable feature design is a potential strength for transferability, though its advantage depends on whether the feature extraction overhead is truly matched to baselines.
major comments (1)
- [Abstract] Abstract: The headline claim of outperformance 'under identical pretraining data, training protocol, and comparable parameter budgets' is load-bearing for the contribution. The description of an 'interpretable feature space' that 'explicitly disentangles' trends/periodicity/local dynamics implies either hand-crafted extractors or learned modules whose parameter count, forward-pass cost, and any auxiliary losses must be shown to be matched to the Transformer baselines; without this accounting, the performance difference cannot be attributed solely to the autoregressive strategy space.
minor comments (1)
- [Abstract] The abstract states an empirical result but provides no dataset details, number of series, forecast horizons, or exclusion criteria; these should be summarized early to allow assessment of the zero-shot setting.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The concern regarding explicit matching of parameter counts, forward-pass costs, and auxiliary losses is valid and directly impacts the strength of our controlled comparison claim. We address it point-by-point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline claim of outperformance 'under identical pretraining data, training protocol, and comparable parameter budgets' is load-bearing for the contribution. The description of an 'interpretable feature space' that 'explicitly disentangles' trends/periodicity/local dynamics implies either hand-crafted extractors or learned modules whose parameter count, forward-pass cost, and any auxiliary losses must be shown to be matched to the Transformer baselines; without this accounting, the performance difference cannot be attributed solely to the autoregressive strategy space.
Authors: We agree that a transparent accounting of all components is required to support the headline claim. The feature extractors (for global trends, periodic components, and local dynamics) are implemented as lightweight, fixed-structure modules whose parameters are included in the reported comparable budgets; the mapping network itself constitutes the primary learnable component. In the revised version we will add a dedicated subsection under Experimental Setup that tabulates (i) exact parameter counts for each extractor and the full FSA model versus the Transformer baselines, (ii) measured forward-pass FLOPs on identical hardware, and (iii) confirmation that training uses only the standard autoregressive forecasting loss with no auxiliary objectives. This documentation will make explicit that the observed gains are attributable to the learned feature-to-strategy mapping rather than unaccounted capacity or losses. revision: yes
Circularity Check
No circularity detected; abstract and claims contain no equations, self-citations, or derivations that reduce outputs to inputs by construction.
full rationale
The provided abstract proposes FSA as a feature-to-autoregression mapping with explicit disentanglement of trends/periodicity/dynamics and reports empirical outperformance under matched pretraining conditions. No equations, parameter-fitting procedures, uniqueness theorems, or citations appear in the text. The enumerated circularity patterns (self-definitional, fitted-input-called-prediction, self-citation load-bearing, etc.) require specific reductions via equations or citations that are absent here. The central claim is therefore an empirical comparison whose grounding cannot be inspected for circularity from the given material; the derivation chain is self-contained at the level of description.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Gift- EVAL : A benchmark for general time series forecasting model evaluation
Aksu, T., Woo, G., Liu, J., Liu, X., Liu, C., Savarese, S., Xiong, C., and Sahoo, D. Gift-eval: A benchmark for general time series forecasting model evaluation.arXiv preprint arXiv:2410.10393,
-
[2]
Chronos: Learning the Language of Time Series
Ansari, A. F., Stella, L., Turkmen, C., Zhang, X., Mercado, P., Shen, H., Shchur, O., Rangapuram, S. S., Arango, S. P., Kapoor, S., et al. Chronos: Learning the language of time series.arXiv preprint arXiv:2403.07815,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Chronos-2: From Univariate to Universal Forecasting
Ansari, A. F., Shchur, O., K ¨uken, J., Auer, A., Han, B., Mercado, P., Rangapuram, S. S., Shen, H., Stella, L., Zhang, X., et al. Chronos-2: From univariate to universal forecasting.arXiv preprint arXiv:2510.15821,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Cohen, B., Khwaja, E., Doubli, Y ., Lemaachi, S., Lettieri, C., Masson, C., Miccinilli, H., Ram ´e, E., Ren, Q., Ros- tamizadeh, A., et al. This time is different: An observabil- ity perspective on time series foundation models.arXiv preprint arXiv:2505.14766,
-
[5]
Godahewa, R., Bergmeir, C., Webb, G. I., Hyndman, R. J., and Montero-Manso, P. Monash time series forecasting archive.arXiv preprint arXiv:2105.06643,
-
[6]
From tables to time: Extending tabpfn-v2 to time series forecasting
Hoo, S. B., M ¨uller, S., Salinas, D., and Hutter, F. From tables to time: Extending tabpfn-v2 to time series fore- casting.arXiv preprint arXiv:2501.02945,
-
[7]
Panda: A pretrained forecast model for chaotic dynamics.arXiv preprint arXiv:2505.13755,
Lai, J., Bao, A., and Gilpin, W. Panda: A pretrained forecast model for universal representation of chaotic dynamics. arXiv preprint arXiv:2505.13755,
-
[8]
Moirai 2.0: When less is more for time series forecasting
Liu, C., Aksu, T., Liu, J., Liu, X., Yan, H., Pham, Q., Savarese, S., Sahoo, D., Xiong, C., and Li, J. Moirai 2.0: When less is more for time series forecasting.arXiv preprint arXiv:2511.11698, 2025a. Liu, Y ., Qin, G., Shi, Z., Chen, Z., Yang, C., Huang, X., Wang, J., and Long, M. Sundial: A family of highly capable time series foundation models.arXiv pr...
-
[9]
URL https://openreview. net/forum?id=Bkg6RiCqY7. Moroshan, V ., Siems, J., Zela, A., Carstensen, T., and Hutter, F. Tempopfn: Synthetic pre-training of linear rnns for zero-shot time series forecasting.arXiv preprint arXiv:2510.25502,
-
[10]
A Time Series is Worth 64 Words: Long-term Forecasting with Transformers
Nie, Y . A time series is worth 64words: Long-term forecast- ing with transformers.arXiv preprint arXiv:2211.14730,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Shi, X., Wang, S., Nie, Y ., Li, D., Ye, Z., Wen, Q., and Jin, M. Time-moe: Billion-scale time series founda- tion models with mixture of experts.arXiv preprint arXiv:2409.16040,
-
[12]
doi: https://doi.org/10.1016/j.icte.2022.02
ISSN 2405-9595. doi: https://doi.org/10.1016/j.icte.2022.02
- [13]
-
[14]
Experiments use a 90/10 train-validation split of the pretraining corpus; validation MSE is used for early stopping and model selection
with learning rate 10−4, weight decay 0.01, a cosine learning-rate schedule, 10% linear warmup, batch size 64, and gradient clipping at 1.0. Experiments use a 90/10 train-validation split of the pretraining corpus; validation MSE is used for early stopping and model selection. Model Configurations:FSA uses 22 input features, a 3-layer MLP strategy generat...
2023
-
[15]
To avoid redundancy and enhance training diversity, we sample only one instance from each series
hugging face repository. To avoid redundancy and enhance training diversity, we sample only one instance from each series. We conduct Zero-shot experiments on four benchmark time series datasets:ETT(Yu et al., 2018),Electricity(UCI), Exchange Rate(Lai et al., 2018), andWeather(Wetterstation). The ETT dataset contains data collected from electricity transf...
2018
-
[16]
The Electricity dataset consists of the hourly electricity consumption of 321 customers between 2012 and
2012
-
[17]
The Exchange rate dataset records the daily exchange rates of eight foreign countries spanning from 1990 to
1990
-
[18]
11 FSA B.2
The Weather dataset includes meteorological observations recorded every 10 minutes throughout the year 2020, containing 21 weather-related indicators such as air temperature, humidity, and wind speed. 11 FSA B.2. Baseline models We use baseline models from these repositories: https://github.com/google-research/timesfm https://github.com/amazon-science/chr...
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.