HOLA: Holistic Multi-Modal Alignment for Open-Set 3D Recognition
Pith reviewed 2026-06-28 17:23 UTC · model grok-4.3
The pith
Aligning each 3D point cloud with multiple images and texts via a new contrastive loss yields better open-vocabulary recognition than single-alignment methods.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
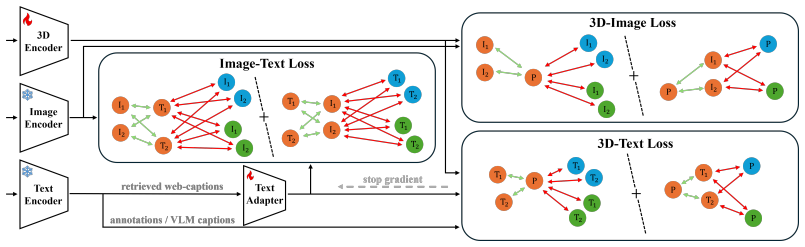
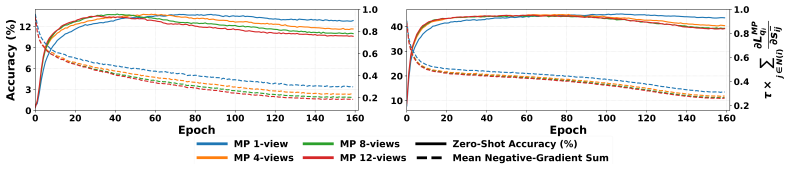
The decoupled multi-positive contrastive loss enables joint alignment of a 3D instance with multiple matched multi-view images and multiple texts by separating positive aggregation from negative competition, which sharpens focus on challenging negatives and avoids spotlight crowding that occurs when many positives share the softmax with all negatives.
What carries the argument
The decoupled multi-positive contrastive loss, which aggregates positives separately before competing with negatives.
If this is right
- State-of-the-art open-vocabulary performance on long-tail 3D benchmarks.
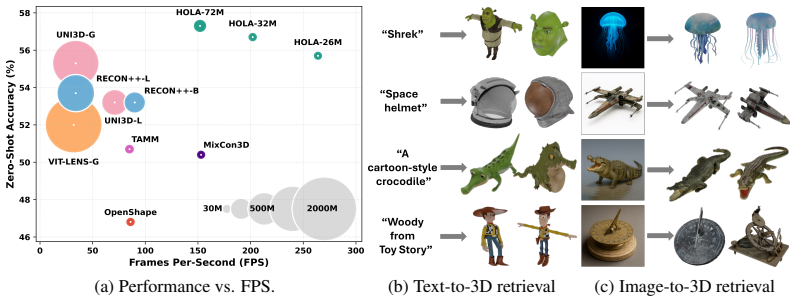
- Substantial zero-shot gains while maintaining high frame rates.
- Effective incorporation of large-scale unsupervised web captions through the text adapter.
- Avoidance of partial-view anchoring that limits earlier distillation approaches.
Where Pith is reading between the lines
- The same loss structure could be tested on 2D or video data where multiple views are available but currently under-used.
- If the number of positives grows too large, performance might eventually degrade; a controlled scaling experiment would reveal the practical limit.
- The approach suggests that open-set 3D systems may benefit more from richer positive sets than from ever-larger negative banks.
- Combining this alignment with geometric invariants already known in 3D vision could further reduce the need for any text supervision.
Load-bearing premise
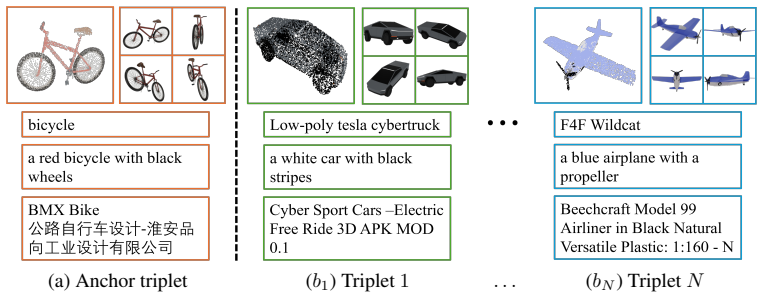
That jointly aligning a 3D instance with multiple matched multi-view images and multiple texts captures a more holistic understanding than single-image or single-caption alignment.
What would settle it
An experiment showing that a model using only single-image or single-text alignment matches or exceeds the multi-alignment version on the same long-tail open-vocabulary benchmarks would falsify the central claim.
Figures








read the original abstract
Open-set 3D recognition requires models that generalize to rare or unseen categories. Recent approaches address this by distilling language-vision knowledge into 3D encoders, typically relying on heavy 2D ViTs and aligning each point cloud with a single image or caption, thus anchoring representations to partial views. We propose aligning each point cloud with multiple images and textual descriptions to capture a more holistic understanding of 3D objects. To realize this idea, it is essential to design a loss function capable of jointly aligning a 3D instance with multiple matched signals, multi-view images and multiple texts, while separating positive aggregation from negative competition. We introduce such a function, termed the decoupled multi-positive contrastive loss. Our formulation enhances the loss's hardness-aware focus on challenging negatives, avoiding the "spotlight crowding" that occurs when many positives share the same softmax with all the negatives. Complementing this, we present a lightweight text adapter applied only to web captions, reducing the domain gap to curated annotations and enabling effective use of large-scale unsupervised text. Our model demonstrates state-of-the-art open-vocabulary performance on long-tail benchmarks, yielding substantial zero-shot improvements while sustaining high frame rates.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes HOLA for open-set 3D recognition, which aligns each point cloud instance with multiple matched multi-view images and multiple textual descriptions (rather than single-image or single-caption alignments) to capture holistic object understanding. It introduces a decoupled multi-positive contrastive loss that separates positive aggregation from negative competition to enhance hardness-aware focus and avoid spotlight crowding in the softmax, plus a lightweight text adapter applied only to web captions to reduce domain gap. The model is reported to achieve state-of-the-art open-vocabulary performance on long-tail benchmarks with substantial zero-shot gains while sustaining high frame rates.
Significance. If the central performance claims hold under full experimental validation, the work could meaningfully advance open-vocabulary 3D recognition by demonstrating that multi-positive multi-modal alignment yields better generalization to rare categories than prior single-alignment distillation approaches, with the efficiency of the text adapter offering practical value for scaling to unsupervised web data.
minor comments (3)
- Abstract: the phrase 'spotlight crowding' is introduced without a brief definition or reference to prior contrastive-learning literature, which would clarify the motivation for the decoupled loss.
- Abstract: 'long-tail benchmarks' and the specific zero-shot metrics (e.g., mAP or accuracy deltas) are not named, making it difficult for readers to immediately locate the supporting tables or compare against the cited baselines.
- Abstract: the claim that the text adapter is 'lightweight' and 'applied only to web captions' would benefit from a short statement on parameter count or inference overhead relative to the 2D ViT backbone.
Simulated Author's Rebuttal
We thank the referee for the positive summary of our work and the recommendation for minor revision. We appreciate the acknowledgment that the multi-positive multi-modal alignment and decoupled contrastive loss could advance open-vocabulary 3D recognition, particularly for long-tail categories.
Circularity Check
No significant circularity
full rationale
The paper proposes a new decoupled multi-positive contrastive loss and lightweight text adapter for multi-modal 3D alignment. No derivation chain, equations, or first-principles results are presented that reduce by construction to their own inputs. Claims rest on the empirical performance of the introduced method on benchmarks rather than any fitted parameter renamed as prediction, self-definitional construction, or load-bearing self-citation. The abstract and described content contain no self-referential steps matching the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Crosspoint: Self-supervised cross-modal contrastive learning for 3d point cloud understanding
Mohamed Afham, Isuru Dissanayake, Dinithi Dissanayake, Amaya Dharmasiri, Kanchana Thilakarathna, and Ranga Rodrigo. Crosspoint: Self-supervised cross-modal contrastive learning for 3d point cloud understanding. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9902–9912, 2022
2022
-
[2]
ShapeNet: An Information-Rich 3D Model Repository
Angel X Chang, Thomas Funkhouser, Leonidas Guibas, Pat Hanrahan, Qixing Huang, Zimo Li, Silvio Savarese, Manolis Savva, Shuran Song, Hao Su, et al. Shapenet: An information-rich 3d model repository. arXiv preprint arXiv:1512.03012, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[3]
Pimae: Point cloud and image interactive masked autoencoders for 3d object detection
Anthony Chen, Kevin Zhang, Renrui Zhang, Zihan Wang, Yuheng Lu, Yandong Guo, and Shanghang Zhang. Pimae: Point cloud and image interactive masked autoencoders for 3d object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5291–5301, 2023
2023
-
[4]
Text2shape: Generating shapes from natural language by learning joint embeddings
Kevin Chen, Christopher B Choy, Manolis Savva, Angel X Chang, Thomas Funkhouser, and Silvio Savarese. Text2shape: Generating shapes from natural language by learning joint embeddings. InAsian conference on computer vision, pages 100–116. Springer, 2018
2018
-
[5]
A simple framework for contrastive learning of visual representations
Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. A simple framework for contrastive learning of visual representations. InInternational conference on machine learning, pages 1597–1607. PmLR, 2020
2020
-
[6]
Reproducible scaling laws for contrastive language-image learning
Mehdi Cherti, Romain Beaumont, Ross Wightman, Mitchell Wortsman, Gabriel Ilharco, Cade Gordon, Christoph Schuhmann, Ludwig Schmidt, and Jenia Jitsev. Reproducible scaling laws for contrastive language-image learning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2818–2829, 2023
2023
-
[7]
4d spatio-temporal convnets: Minkowski convolutional neural networks
Christopher Choy, JunYoung Gwak, and Silvio Savarese. 4d spatio-temporal convnets: Minkowski convolutional neural networks. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 3075–3084, 2019. 14
2019
-
[8]
Abo: Dataset and benchmarks for real-world 3d object understanding
Jasmine Collins, Shubham Goel, Kenan Deng, Achleshwar Luthra, Leon Xu, Erhan Gundogdu, Xi Zhang, Tomas F Yago Vicente, Thomas Dideriksen, Himanshu Arora, et al. Abo: Dataset and benchmarks for real-world 3d object understanding. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 21126–21136, 2022
2022
-
[9]
Objaverse: A universe of annotated 3d objects
Matt Deitke, Dustin Schwenk, Jordi Salvador, Luca Weihs, Oscar Michel, Eli VanderBilt, Ludwig Schmidt, Kiana Ehsani, Aniruddha Kembhavi, and Ali Farhadi. Objaverse: A universe of annotated 3d objects. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 13142–13153, 2023
2023
-
[10]
An image is worth 16x16 words: Transformers for image recognition at scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. In International Conference on Learning Representations, 2021
2021
-
[11]
3d-future: 3d furniture shape with texture.International Journal of Computer Vision, 129(12):3313–3337, 2021
Huan Fu, Rongfei Jia, Lin Gao, Mingming Gong, Binqiang Zhao, Steve Maybank, and Dacheng Tao. 3d-future: 3d furniture shape with texture.International Journal of Computer Vision, 129(12):3313–3337, 2021
2021
-
[12]
Sculpting holistic 3d representation in contrastive language-image-3d pre-training
Yipeng Gao, Zeyu Wang, Wei-Shi Zheng, Cihang Xie, and Yuyin Zhou. Sculpting holistic 3d representation in contrastive language-image-3d pre-training. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 22998–23008, June 2024
2024
-
[13]
Lvis: A dataset for large vocabulary instance segmentation
Agrim Gupta, Piotr Dollar, and Ross Girshick. Lvis: A dataset for large vocabulary instance segmentation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5356–5364, 2019
2019
-
[14]
Momentum contrast for unsupervised visual representation learning
Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, and Ross Girshick. Momentum contrast for unsupervised visual representation learning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9729–9738, 2020
2020
-
[15]
A comprehensive survey on contrastive learning.Neurocomputing, 610:128645, 2024
Haigen Hu, Xiaoyuan Wang, Yan Zhang, Qi Chen, and Qiu Guan. A comprehensive survey on contrastive learning.Neurocomputing, 610:128645, 2024
2024
-
[16]
Clip2point: Transfer clip to point cloud classification with image-depth pre-training
Tianyu Huang, Bowen Dong, Yunhan Yang, Xiaoshui Huang, Rynson WH Lau, Wanli Ouyang, and Wangmeng Zuo. Clip2point: Transfer clip to point cloud classification with image-depth pre-training. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 22157–22167, 2023
2023
-
[17]
Hard negative mixing for contrastive learning.Advances in neural information processing systems, 33:21798–21809, 2020
Yannis Kalantidis, Mert Bulent Sariyildiz, Noe Pion, Philippe Weinzaepfel, and Diane Larlus. Hard negative mixing for contrastive learning.Advances in neural information processing systems, 33:21798–21809, 2020
2020
-
[18]
Supervised contrastive learning.Advances in neural information processing systems, 33:18661–18673, 2020
Prannay Khosla, Piotr Teterwak, Chen Wang, Aaron Sarna, Yonglong Tian, Phillip Isola, Aaron Maschinot, Ce Liu, and Dilip Krishnan. Supervised contrastive learning.Advances in neural information processing systems, 33:18661–18673, 2020
2020
-
[19]
Medclip-samv2: Towards universal text-driven medical image segmentation.Medical Image Analysis, page 103749, 2025
Taha Koleilat, Hojat Asgariandehkordi, Hassan Rivaz, and Yiming Xiao. Medclip-samv2: Towards universal text-driven medical image segmentation.Medical Image Analysis, page 103749, 2025
2025
-
[20]
Duoduo clip: Efficient 3d understanding with multi-view images
Han-Hung Lee, Yiming Zhang, and Angel X Chang. Duoduo clip: Efficient 3d understanding with multi-view images. InInternational Conference on Learning Representations (ICLR), 2025
2025
-
[21]
Vit-lens: Towards omni-modal representations
Weixian Lei, Yixiao Ge, Kun Yi, Jianfeng Zhang, Difei Gao, Dylan Sun, Yuying Ge, Ying Shan, and Mike Zheng Shou. Vit-lens: Towards omni-modal representations. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 26647–26657, June 2024
2024
-
[22]
Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation
Junnan Li, Dongxu Li, Caiming Xiong, and Steven Hoi. Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation. InInternational conference on machine learning, pages 12888–12900. PMLR, 2022
2022
-
[23]
Joint embeddings of shapes and images via cnn image purification.ACM transactions on graphics (TOG), 34 (6):1–12, 2015
Yangyan Li, Hao Su, Charles Ruizhongtai Qi, Noa Fish, Daniel Cohen-Or, and Leonidas J Guibas. Joint embeddings of shapes and images via cnn image purification.ACM transactions on graphics (TOG), 34 (6):1–12, 2015
2015
-
[24]
Openshape: Scaling up 3d shape representation towards open-world understanding
Minghua Liu, Ruoxi Shi, Kaiming Kuang, Yinhao Zhu, Xuanlin Li, Shizhong Han, Hong Cai, Fatih Porikli, and Hao Su. Openshape: Scaling up 3d shape representation towards open-world understanding. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors,Advances in Neural Information Processing Systems, volume 36, pages 44860–44879. Cu...
2023
-
[25]
SGDR: Stochastic Gradient Descent with Warm Restarts
Ilya Loshchilov and Frank Hutter. Sgdr: Stochastic gradient descent with warm restarts.arXiv preprint arXiv:1608.03983, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[26]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[27]
Slip: Self-supervision meets language- image pre-training
Norman Mu, Alexander Kirillov, David Wagner, and Saining Xie. Slip: Self-supervision meets language- image pre-training. InEuropean conference on computer vision, pages 529–544. Springer, 2022
2022
-
[28]
Representation Learning with Contrastive Predictive Coding
Aaron van den Oord, Yazhe Li, and Oriol Vinyals. Representation learning with contrastive predictive coding.arXiv preprint arXiv:1807.03748, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[29]
Pointnet: Deep learning on point sets for 3d classification and segmentation
Charles R Qi, Hao Su, Kaichun Mo, and Leonidas J Guibas. Pointnet: Deep learning on point sets for 3d classification and segmentation. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 652–660, 2017
2017
-
[30]
Pointnet++: Deep hierarchical feature learning on point sets in a metric space.Advances in neural information processing systems, 30, 2017
Charles Ruizhongtai Qi, Li Yi, Hao Su, and Leonidas J Guibas. Pointnet++: Deep hierarchical feature learning on point sets in a metric space.Advances in neural information processing systems, 30, 2017
2017
-
[31]
Shapellm: Universal 3d object understanding for embodied interaction
Zekun Qi, Runpei Dong, Shaochen Zhang, Haoran Geng, Chunrui Han, Zheng Ge, Li Yi, and Kaisheng Ma. Shapellm: Universal 3d object understanding for embodied interaction. InEuropean Conference on Computer Vision, pages 214–238. Springer, 2024
2024
-
[32]
Learn from zoom: Decoupled supervised contrastive learning for wce image classification
Kunpeng Qiu, Zhiying Zhou, and Yongxin Guo. Learn from zoom: Decoupled supervised contrastive learning for wce image classification. InICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 2245–2249. IEEE, 2024
2024
-
[33]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021
2021
-
[34]
arXiv preprint arXiv:2010.04592 , year=
Joshua Robinson, Ching-Yao Chuang, Suvrit Sra, and Stefanie Jegelka. Contrastive learning with hard negative samples.arXiv preprint arXiv:2010.04592, 2020
-
[35]
Laion-5b: An open large-scale dataset for training next generation image-text models.Advances in neural information processing systems, 35:25278–25294, 2022
Christoph Schuhmann, Romain Beaumont, Richard Vencu, Cade Gordon, Ross Wightman, Mehdi Cherti, Theo Coombes, Aarush Katta, Clayton Mullis, Mitchell Wortsman, et al. Laion-5b: An open large-scale dataset for training next generation image-text models.Advances in neural information processing systems, 35:25278–25294, 2022
2022
-
[36]
Sun rgb-d: A rgb-d scene understanding benchmark suite
Shuran Song, Samuel P Lichtenberg, and Jianxiong Xiao. Sun rgb-d: A rgb-d scene understanding benchmark suite. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 567–576, 2015
2015
-
[37]
Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results.Advances in neural information processing systems, 30, 2017
Antti Tarvainen and Harri Valpola. Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results.Advances in neural information processing systems, 30, 2017
2017
-
[38]
Stablerep: Synthetic images from text-to-image models make strong visual representation learners.Advances in Neural Information Processing Systems, 36:48382–48402, 2023
Yonglong Tian, Lijie Fan, Phillip Isola, Huiwen Chang, and Dilip Krishnan. Stablerep: Synthetic images from text-to-image models make strong visual representation learners.Advances in Neural Information Processing Systems, 36:48382–48402, 2023
2023
-
[39]
Yao-Hung Hubert Tsai, Martin Q Ma, Muqiao Yang, Han Zhao, Louis-Philippe Morency, and Ruslan Salakhutdinov. Self-supervised representation learning with relative predictive coding.arXiv preprint arXiv:2103.11275, 2021
-
[40]
Revisiting point cloud classification: A new benchmark dataset and classification model on real-world data
Mikaela Angelina Uy, Quang-Hieu Pham, Binh-Son Hua, Thanh Nguyen, and Sai-Kit Yeung. Revisiting point cloud classification: A new benchmark dataset and classification model on real-world data. In Proceedings of the IEEE/CVF international conference on computer vision, pages 1588–1597, 2019
2019
-
[41]
Understanding the behaviour of contrastive loss
Feng Wang and Huaping Liu. Understanding the behaviour of contrastive loss. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2495–2504, 2021
2021
-
[42]
Cross-modal retrieval: a systematic review of methods and future directions.Proceedings of the IEEE, 112(11):1716–1754, 2025
Tianshi Wang, Fengling Li, Lei Zhu, Jingjing Li, Zheng Zhang, and Heng Tao Shen. Cross-modal retrieval: a systematic review of methods and future directions.Proceedings of the IEEE, 112(11):1716–1754, 2025
2025
-
[43]
Dynamic graph cnn for learning on point clouds.ACM Transactions on Graphics (tog), 38(5):1–12, 2019
Yue Wang, Yongbin Sun, Ziwei Liu, Sanjay E Sarma, Michael M Bronstein, and Justin M Solomon. Dynamic graph cnn for learning on point clouds.ACM Transactions on Graphics (tog), 38(5):1–12, 2019. 16
2019
-
[44]
Pointnet++ pytorch
Erik Wijmans. Pointnet++ pytorch. https: // github. com/ erikwijmans/ Pointnet2_ PyTorch, 2018
2018
-
[45]
3d shapenets: A deep representation for volumetric shapes
Zhirong Wu, Shuran Song, Aditya Khosla, Fisher Yu, Linguang Zhang, Xiaoou Tang, and Jianxiong Xiao. 3d shapenets: A deep representation for volumetric shapes. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 1912–1920, 2015
1912
-
[46]
Ulip: Learning a unified representation of language, images, and point clouds for 3d understanding
Le Xue, Mingfei Gao, Chen Xing, Roberto Martín-Martín, Jiajun Wu, Caiming Xiong, Ran Xu, Juan Carlos Niebles, and Silvio Savarese. Ulip: Learning a unified representation of language, images, and point clouds for 3d understanding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 1179–1189, June 2023
2023
-
[47]
Ulip-2: Towards scalable multimodal pre-training for 3d understanding
Le Xue, Ning Yu, Shu Zhang, Artemis Panagopoulou, Junnan Li, Roberto Martín-Martín, Jiajun Wu, Caiming Xiong, Ran Xu, Juan Carlos Niebles, and Silvio Savarese. Ulip-2: Towards scalable multimodal pre-training for 3d understanding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 27091–27101, June 2024
2024
-
[48]
Decoupled contrastive learning
Chun-Hsiao Yeh, Cheng-Yao Hong, Yen-Chi Hsu, Tyng-Luh Liu, Yubei Chen, and Yann LeCun. Decoupled contrastive learning. InEuropean conference on computer vision, pages 668–684. Springer, 2022
2022
-
[49]
Mvimgnet: A large-scale dataset of multi-view images
Xianggang Yu, Mutian Xu, Yidan Zhang, Haolin Liu, Chongjie Ye, Yushuang Wu, Zizheng Yan, Chenming Zhu, Zhangyang Xiong, Tianyou Liang, et al. Mvimgnet: A large-scale dataset of multi-view images. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9150–9161, 2023
2023
-
[50]
Point-bert: Pre-training 3d point cloud transformers with masked point modeling
Xumin Yu, Lulu Tang, Yongming Rao, Tiejun Huang, Jie Zhou, and Jiwen Lu. Point-bert: Pre-training 3d point cloud transformers with masked point modeling. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 19313–19322, 2022
2022
-
[51]
Clip2: Contrastive language-image-point pretraining from real-world point cloud data
Yihan Zeng, Chenhan Jiang, Jiageng Mao, Jianhua Han, Chaoqiang Ye, Qingqiu Huang, Dit-Yan Yeung, Zhen Yang, Xiaodan Liang, and Hang Xu. Clip2: Contrastive language-image-point pretraining from real-world point cloud data. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 15244–15253, 2023
2023
-
[52]
Pointclip: Point cloud understanding by clip
Renrui Zhang, Ziyu Guo, Wei Zhang, Kunchang Li, Xupeng Miao, Bin Cui, Yu Qiao, Peng Gao, and Hongsheng Li. Pointclip: Point cloud understanding by clip. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 8552–8562, June 2022
2022
-
[53]
Tamm: Triadapter multi-modal learning for 3d shape understanding
Zhihao Zhang, Shengcao Cao, and Yu-Xiong Wang. Tamm: Triadapter multi-modal learning for 3d shape understanding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 21413–21423, June 2024
2024
-
[54]
Uni3d: Exploring unified 3d representation at scale
Junsheng Zhou, Jinsheng Wang, Baorui Ma, Yu-Shen Liu, Tiejun Huang, and Xinlong Wang. Uni3d: Exploring unified 3d representation at scale. InInternational Conference on Learning Representations (ICLR), 2024
2024
-
[55]
Ensembled
Xiangyang Zhu, Renrui Zhang, Bowei He, Ziyu Guo, Ziyao Zeng, Zipeng Qin, Shanghang Zhang, and Peng Gao. Pointclip v2: Prompting clip and gpt for powerful 3d open-world learning. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 2639–2650, October 2023. 17 Supplementary Material Supplementary material overview.Section ...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.