Early Diagnosis of Wasted Computation in Multi-Agent LLM Systems via Failure-Aware Observability
Pith reviewed 2026-06-28 17:05 UTC · model grok-4.3
The pith
Failure-aware observability framework diagnoses wasted computation in multi-agent LLM systems by mapping trace signals to failure modes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The framework maps recurring failure modes to online trace signals, including tool reliability, execution recovery, orchestration loops, evidence availability, information change, and budget pressure, in order to diagnose wasted computation in multi-agent LLM traces before final answers are produced.
What carries the argument
The failure-aware observability framework, which maps recurring failure modes to specific online trace signals in execution traces.
If this is right
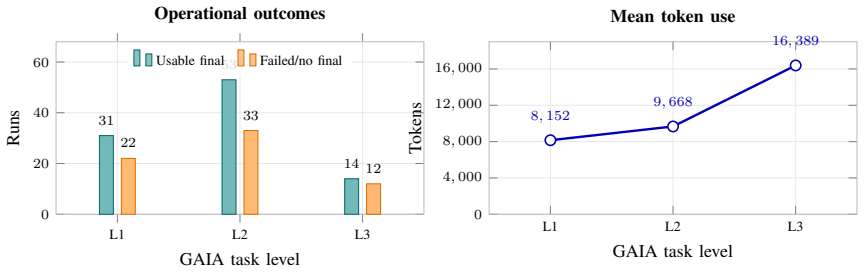
- Operational failures remain common, with 22 of 53 level-1 runs, 33 of 86 level-2 runs, and 12 of 26 level-3 runs failing to produce a usable final answer.
- Mean token use increases from 8,152 tokens at level 1 to 16,389 tokens at level 3.
- Traces expose mechanisms such as insufficient evidence, repeated-action loops, max-step termination, tool-failure streaks, and execution calls that succeed without useful output.
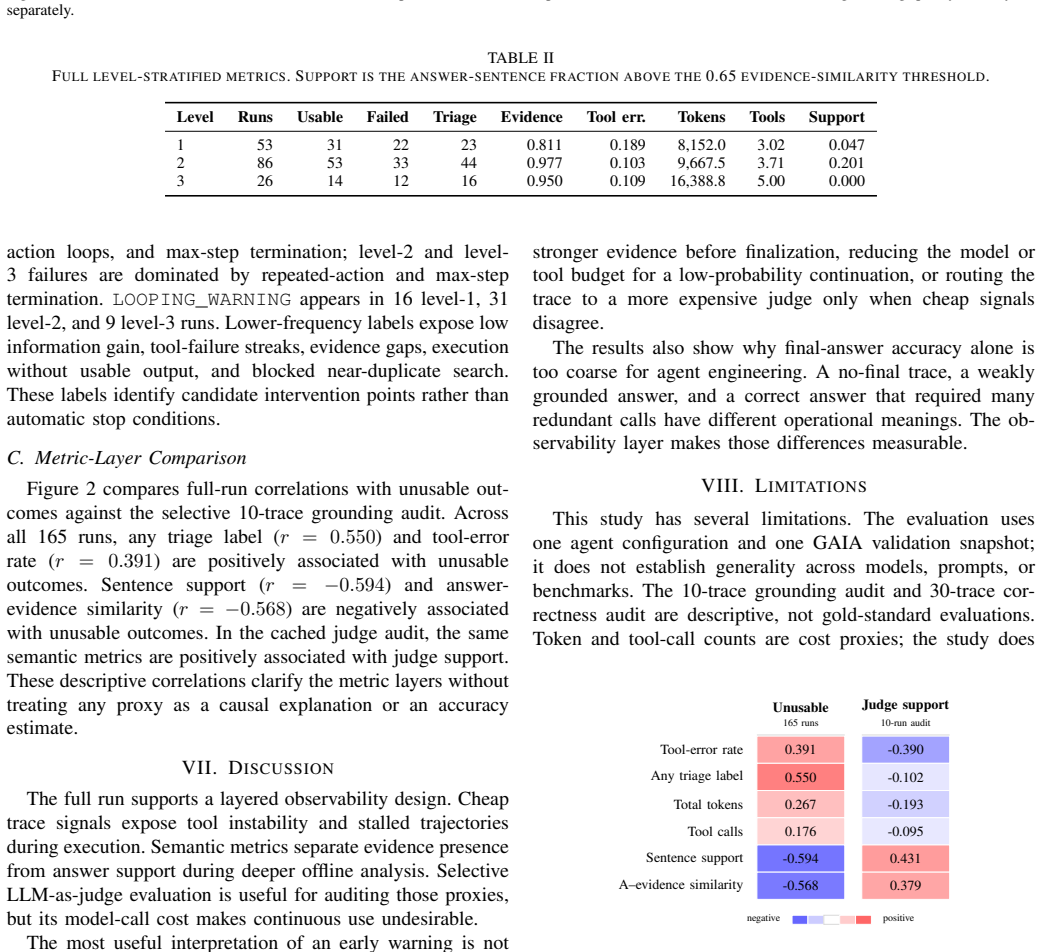
- Evidence availability and sentence-level support diverge across levels.
- A cached 10-trace LLM-judge grounding audit shows that cheap online signals and deeper semantic metrics capture complementary layers of failure.
Where Pith is reading between the lines
- Such a framework could enable systems to terminate unproductive trajectories early and conserve computational resources.
- The signal mappings might be adapted to other multi-agent LLM applications beyond the three-agent QA system tested.
- Integrating these observability signals with existing monitoring tools could improve overall system reliability in agent-based workflows.
Load-bearing premise
The trace signals can be mapped to failure modes in a manner that accurately diagnoses when a trajectory ceases to make recoverable progress.
What would settle it
A controlled experiment continuing execution on trajectories flagged by the framework as non-recoverable and checking whether they produce correct answers at rates no higher than random chance would falsify the diagnostic utility.
Figures
read the original abstract
Tool-using multi-agent large language model (LLM) systems spend computation through model tokens, tool calls, retries, and code execution before producing an answer. When a run fails, final-answer evaluation reveals the endpoint but usually not the point at which the trajectory stopped making recoverable progress. This paper introduces a failure-aware observability framework for diagnosing wasted computation in multi-agent LLM traces. The framework maps recurring failure modes to online trace signals, including tool reliability, execution recovery, orchestration loops, evidence availability, information change, and budget pressure. We instantiate the framework in a three- agent question-answering system and evaluate it on 165 GAIA validation traces under identical execution caps. Operational failures remain common: 22/53 level-1 runs, 33/86 level-2 runs, and 12/26 level-3 runs fail to produce a usable final answer. The traces expose different mechanisms behind these outcomes, including insufficient evidence, repeated-action loops, max-step termination, tool-failure streaks, and execution calls that succeed without useful output. Mean token use rises from 8,152 tokens at level 1 to 16,389 tokens at level 3, while evidence availability and sentence-level support diverge. A cached 10-trace LLM-judge grounding audit shows that cheap online signals and deeper semantic metrics capture complementary layers of failure. The results position failure-aware observability as a diagnostic layer between raw execution logs and final-answer accuracy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a failure-aware observability framework for identifying wasted computation in multi-agent LLM systems. It maps recurring failure modes to online trace signals including tool reliability, execution recovery, orchestration loops, evidence availability, information change, and budget pressure. The framework is instantiated in a three-agent QA system and evaluated on 165 GAIA validation traces, reporting operational failure rates of 22/53 for level-1, 33/86 for level-2, and 12/26 for level-3, along with increasing mean token usage from 8,152 to 16,389 tokens across levels, and insights from a 10-trace LLM-judge audit.
Significance. If the results hold and the framework enables early online detection, it would offer a practical diagnostic layer for multi-agent systems, helping to reduce wasted tokens by identifying non-recoverable trajectories. The paper provides concrete empirical data from 165 traces and a grounding audit, which are strengths in grounding the failure mode analysis.
major comments (2)
- [Abstract] The central claim requires demonstrating that the listed trace signals can diagnose in an online fashion the point at which a trajectory stops making recoverable progress. However, the evaluation runs all traces to completion under fixed caps and retrospectively identifies failures, without results on real-time monitoring thresholds or precision of early detection.
- [Evaluation] No methods are described for how the signal-to-failure mapping is performed or how the evaluation supports the claim that these signals enable early diagnosis, making it impossible to assess the data against the central claim.
minor comments (1)
- [Abstract] The abstract mentions 'a cached 10-trace LLM-judge grounding audit' but does not specify the criteria used for the audit or how it complements the cheap online signals.
Simulated Author's Rebuttal
We thank the referee for identifying key gaps between our claims and the presented evaluation. We address each major comment below and will make revisions to clarify scope and methods.
read point-by-point responses
-
Referee: [Abstract] The central claim requires demonstrating that the listed trace signals can diagnose in an online fashion the point at which a trajectory stops making recoverable progress. However, the evaluation runs all traces to completion under fixed caps and retrospectively identifies failures, without results on real-time monitoring thresholds or precision of early detection.
Authors: We agree the evaluation is retrospective on completed traces under fixed caps and provides no real-time monitoring thresholds or early-detection precision metrics. The signals are defined to be observable during execution, but the study characterizes their presence in failing traces rather than demonstrating online diagnosis. We will revise the abstract and claims to remove implications of online early detection results and add explicit discussion of this limitation. revision: yes
-
Referee: [Evaluation] No methods are described for how the signal-to-failure mapping is performed or how the evaluation supports the claim that these signals enable early diagnosis, making it impossible to assess the data against the central claim.
Authors: The mappings were derived from author inspection of the 165 traces, identifying patterns such as repeated-action loops and tool-failure streaks, with grounding from the 10-trace LLM-judge audit. We will add a subsection detailing the mapping process with trace examples. We will also adjust language to state that the data shows associations with eventual failure in completed runs, without claiming support for online early diagnosis. revision: yes
Circularity Check
No circularity; framework is descriptive mapping plus retrospective trace analysis
full rationale
The paper introduces a failure-aware observability framework that maps failure modes to trace signals and evaluates the mapping on 165 completed GAIA traces. No equations, fitted parameters, predictions, or derivations are present. No self-citations are invoked as load-bearing premises. The central claim reduces to empirical observation of logs rather than any self-referential construction, satisfying the criteria for a self-contained non-circular analysis.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
ReAct: Synergizing reasoning and acting in language models,
S. Yao et al., “ReAct: Synergizing reasoning and acting in language models,” inProc. International Conference on Learning Representa- tions, 2023
2023
-
[2]
Toolformer: Language models can teach themselves to use tools,
T. Schick et al., “Toolformer: Language models can teach themselves to use tools,” inProc. Advances in Neural Information Processing Systems, 2023
2023
-
[3]
AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation
Q. Wu et al., “AutoGen: Enabling next-gen LLM applications via multi- agent conversation,” arXiv:2308.08155, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
GAIA: a benchmark for General AI Assistants
G. Mialon et al., “GAIA: A benchmark for general AI assistants,” arXiv:2311.12983, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
Dapper, a large-scale distributed systems tracing infrastructure,
B. H. Sigelman et al., “Dapper, a large-scale distributed systems tracing infrastructure,” Google, Tech. Rep., 2010
2010
-
[6]
Sentence-BERT: Sentence embeddings using Siamese BERT-networks,
N. Reimers and I. Gurevych, “Sentence-BERT: Sentence embeddings using Siamese BERT-networks,” inProc. Conference on Empirical Methods in Natural Language Processing, 2019
2019
-
[7]
Tiny-Critic RAG: Empowering agentic fallback with parameter-efficient small language models,
Y . Wu, P. Liang, Y . Xiang, M. Yuan, J. Liu, J. Yang, X. Li, and W. Yan, “Tiny-Critic RAG: Empowering agentic fallback with parameter-efficient small language models,” arXiv preprint arXiv:2603.00846, 2026
-
[8]
TA-Mem: Tool-augmented autonomous memory retrieval for LLM in long-term conversational QA,
M. Yuan, J. Liu, J. Yang, X. Li, W. Yan, Y . Wu, and P. Liang, “TA-Mem: Tool-augmented autonomous memory retrieval for LLM in long-term conversational QA,” inProc. 9th Int. Conf. Advanced Algorithms and Control Engineering (ICAACE), 2026, pp. 2684–2688, doi: 10.1109/ICAACE69793.2026.11509181
-
[9]
In: 2026 9th International Symposium on Big Data and Applied Statistics (ISBDAS)
P. Liang, M. Yuan, J. Liu, J. Yang, X. Li, W. Yan, and Y . Wu, “Dy- naRAG: Bridging static and dynamic knowledge in retrieval-augmented generation,” inProc. 9th Int. Symp. Big Data and Applied Statistics (ISB- DAS), 2026, pp. 442–445, doi: 10.1109/ISBDAS69350.2026.11484130
-
[10]
PRISM: Pipeline for root-cause investigation via special- ized multi-agents,
W. Yan, Y . Wu, P. Liang, M. Yuan, J. Liu, J. Yang, and X. Li, “PRISM: Pipeline for root-cause investigation via special- ized multi-agents,” inProc. Int. Conf. Generative Artificial Intelli- gence and Information Security (GAIIS), 2026, pp. 709–712, doi: 10.1109/GAIIS69281.2026.11519347
-
[11]
J. Liu, J. Yang, X. Li, W. Yan, Y . Wu, P. Liang, and M. Yuan, “Architecture matters more than scale: A comparative study of retrieval and memory augmentation for financial QA under SME compute con- straints,” arXiv preprint arXiv:2604.17979, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[12]
J. Yang, Y . Wu, J. Liu, P. Liang, M. Yuan, X. Li, and W. Yan, “Recursive multi-agent trading system: Iterative optimized portfolio strategy under geopolitical uncertainty,” arXiv preprint arXiv:2605.25311, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[13]
Learning skill equiv- alencies across platform taxonomies,
Z. Li, C. Ren, X. Li, and Z. A. Pardos, “Learning skill equiv- alencies across platform taxonomies,” inProc. 11th Int. Learning Analytics and Knowledge Conf. (LAK’21), 2021, pp. 354–363, doi: 10.1145/3448139.3448173
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.