Conservative Discrete Structure Stabilizes Autoregressive Rollouts in a 1D Drift Diffusion Poisson Benchmark
Pith reviewed 2026-06-28 15:56 UTC · model grok-4.3
The pith
Conservative finite volume structure maintains near roundoff error over long autoregressive rollouts in a 1D drift-diffusion-Poisson benchmark even when one-step neural accuracy is lower.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
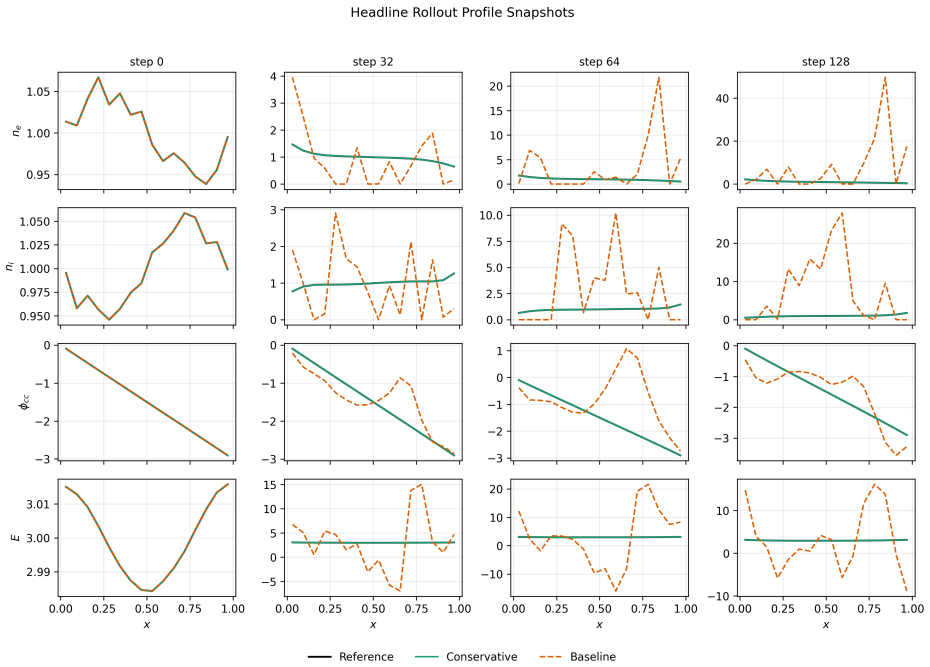
In the controlled 1D drift diffusion Poisson benchmark the classical conservative finite volume core alone reaches near roundoff rollout error, so local conservation enforced at the discrete level is more decisive for stable long-horizon autoregressive prediction than any amount of one-step neural regression accuracy.
What carries the argument
Conservative finite volume update with positivity-aware limiting that enforces local charge accounting, admissible densities, and Poisson-compatible field reconstruction at every step.
If this is right
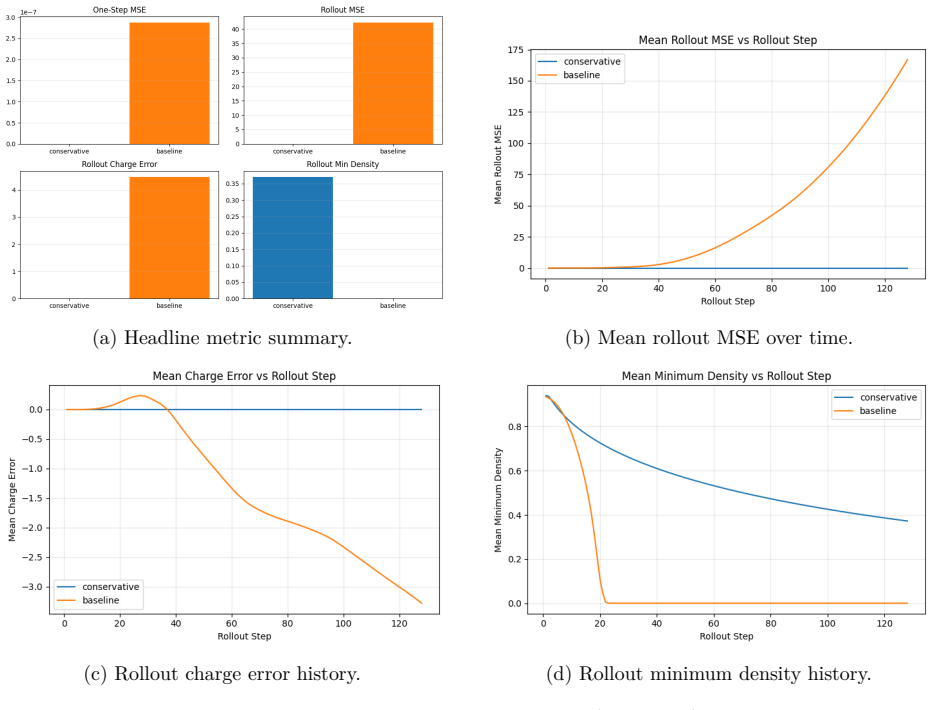
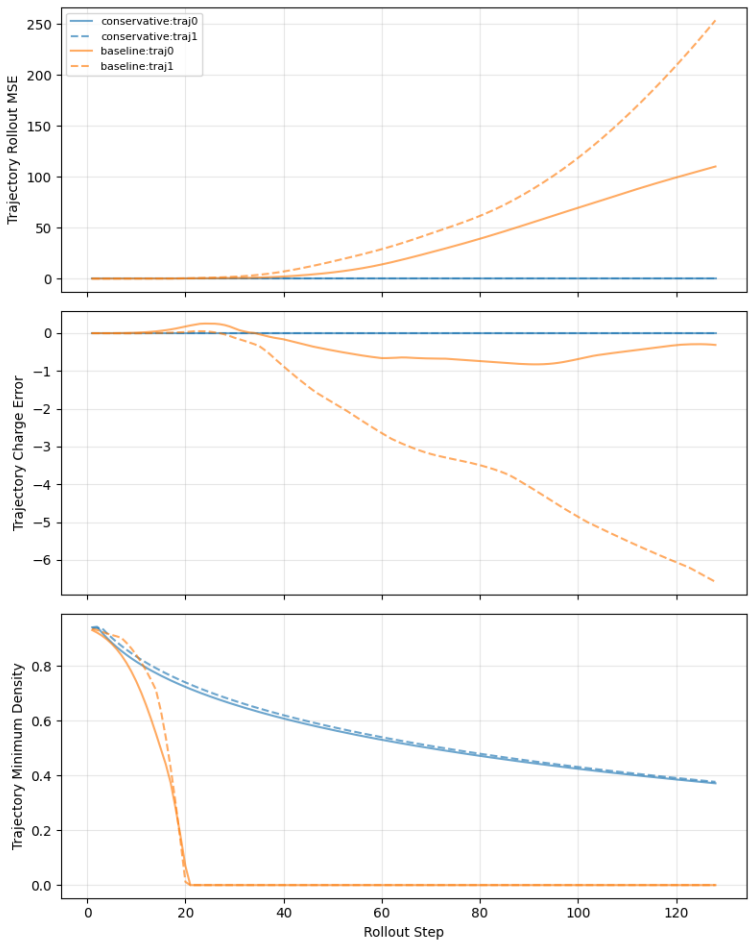
- Rollout mean squared error stays at 7.35 imes10^{-9} for the conservative model while exceeding 10^1 for all tested non-conservative neural variants.
- Method ranking by rollout stability reverses the ranking obtained from single-step mean squared error.
- Adding Poisson recomputation or charge projection after an unconstrained step does not restore long-term stability.
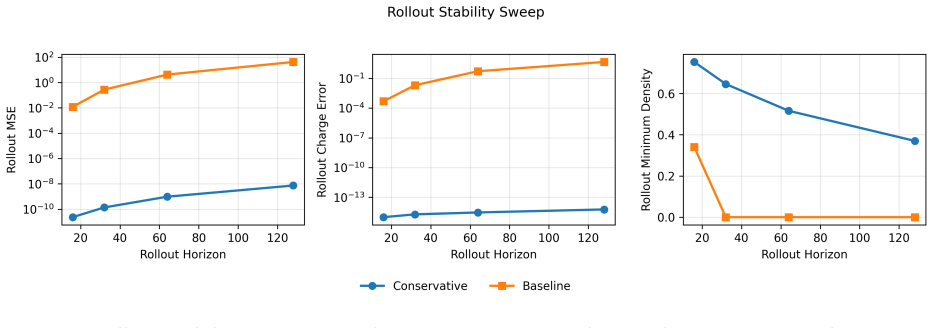
- Four-step rollout training reduces but does not eliminate the stability gap relative to the built-in conservative core.
Where Pith is reading between the lines
- Enforcing conservation at the discrete update level may reduce or remove the need for learned corrections in other time-dependent conservation-law systems.
- The benchmark's isolation of structure versus accuracy suggests that controlled tests in 2D or 3D geometries could separate the contribution of mesh topology from the conservation property itself.
- If the conservative core is already near machine precision, any learned component can be limited to small, structure-preserving adjustments rather than full state prediction.
Load-bearing premise
The nondimensional 1D benchmark with Dirichlet electrostatic boundaries and zero species wall fluxes captures the essential rollout stability problems that appear in more complete plasma models.
What would settle it
An experiment in which a non-conservative neural model achieves lower long-term rollout error than the conservative finite volume core inside a higher-dimensional or full sheath geometry with the same boundary types.
Figures
read the original abstract
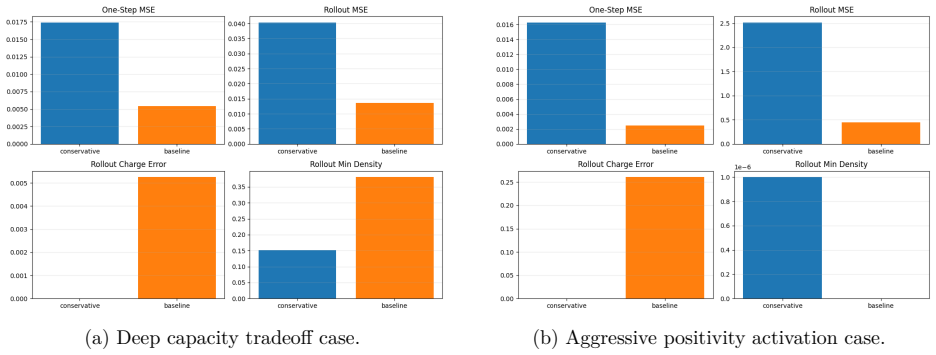
Learned plasma transport surrogates can match short horizon states while failing over long rollouts because charge accounting, density admissibility, and Poisson compatible field reconstruction are not enforced. We study this issue in a controlled nondimensional one dimensional drift diffusion Poisson benchmark with Dirichlet electrostatic potential boundaries and zero species wall fluxes. The benchmark is a conservation and rollout test, not a complete sheath wall model. We compare Conservative FluxNet, a structure preserving flux correction model with a conservative finite volume update and positivity aware limiting, against direct next state regressors, direct variants with Poisson recomputation, charge projection, and rollout training, and a classical conservative core without learned correction. The central result is that the classical finite volume core alone achieves near roundoff rollout error, so the paper is primarily about conservative discrete structure rather than learned closure. On the headline experiment, the conservative model achieves rollout MSE $7.35\times 10^{-9}$ versus $4.23\times 10^{1}$ for the unconstrained baseline, $2.53\times 10^{1}$ with Poisson recomputation, $6.72\times 10^{1}$ with charge projection, and $2.71\times 10^{1}$ with four step rollout training. Across $64$ prespecified configurations, it wins rollout mean squared error in $60/64$ cases despite winning one step mean squared error in only $19/64$. These results show that, for this controlled benchmark and comparison class, local conservative finite volume structure is more important than one step neural regression accuracy for stable autoregressive rollout.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a nondimensional 1D drift-diffusion-Poisson benchmark (Dirichlet electrostatic boundaries, zero species wall fluxes) as a controlled conservation and rollout test. It compares Conservative FluxNet (structure-preserving flux correction with conservative finite-volume update and positivity limiting) against direct next-state regressors and variants incorporating Poisson recomputation, charge projection, and rollout training, plus a classical conservative finite-volume core without learned components. The central empirical result is that the classical core alone attains near-roundoff rollout MSE (7.35×10^{-9}) and wins rollout MSE in 60/64 prespecified configurations, despite winning one-step MSE in only 19/64; neural baselines yield MSE values of order 10^1. The paper concludes that local conservative discrete structure outweighs one-step neural regression accuracy for autoregressive stability in this benchmark.
Significance. If reproducible, the result is significant because it supplies a concrete, head-to-head demonstration that embedding exact conservation and positivity at the discrete level can produce orders-of-magnitude gains in long-horizon stability over purely data-driven or lightly constrained neural surrogates. The controlled benchmark and explicit win counts (60/64 rollout vs. 19/64 one-step) provide a falsifiable reference point for future work on structure-preserving ML closures in plasma transport modeling.
minor comments (3)
- [Abstract] Abstract: the phrase 'near roundoff rollout error' would be more precise if the manuscript stated the floating-point precision employed and the number of autoregressive steps over which the MSE is accumulated.
- [Abstract] Abstract: the 64 prespecified configurations are central to the win-count claim; a short parenthetical description of the parameter ranges or sampling strategy used to generate them would improve reproducibility.
- The manuscript should clarify whether the reported MSE values are averaged over all species and the electrostatic potential or computed on a subset, and whether any normalization (e.g., by reference density) is applied.
Simulated Author's Rebuttal
We thank the referee for the positive assessment, the clear summary of the central result, and the recommendation for minor revision. The controlled benchmark and explicit win counts (60/64 rollout) are intended to provide a falsifiable reference point, and we are pleased that this aspect was recognized as significant.
Circularity Check
No significant circularity; empirical benchmark comparison is self-contained
full rationale
The paper reports direct head-to-head rollout MSE measurements on a fixed nondimensional 1D drift-diffusion-Poisson benchmark across 64 configurations. The classical conservative finite-volume core is defined by standard discretization rules (conservative update, positivity limiting) that are independent of any neural parameters or fitted quantities. No load-bearing step equates a prediction to its own input by construction, invokes a self-citation uniqueness theorem, or renames a fitted result. The central claim—that structure dominates one-step accuracy for autoregressive stability—is supported by the reported numerical outcomes rather than by definitional reduction.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Finite volume discretization with consistent interface fluxes conserves integrated quantities up to roundoff error.
Reference graph
Works this paper leans on
-
[1]
Physics-informed machine learning.Nature Reviews Physics, 3(6):422–440, 2021
George Em Karniadakis, Ioannis G Kevrekidis, Lu Lu, Paris Perdikaris, Sifan Wang, and Liu Yang. Physics-informed machine learning.Nature Reviews Physics, 3(6):422–440, 2021
2021
-
[2]
Zongyi Li, Nikola Kovachki, Kamyar Azizzadenesheli, Burigede Liu, Kaushik Bhattacharya, Andrew Stuart, and Anima Anandkumar. Fourier neural operator for parametric partial differential equations.arXiv preprint arXiv:2010.08895, 2020
Pith/arXiv arXiv 2010
-
[3]
Neural operator: Learning maps between function spaces with applications to pdes.Journal of Machine Learning Research, 24(89):1–97, 2023
Nikola Kovachki, Zongyi Li, Burigede Liu, Kamyar Azizzadenesheli, Kaushik Bhattacharya, Andrew Stuart, and Anima Anandkumar. Neural operator: Learning maps between function spaces with applications to pdes.Journal of Machine Learning Research, 24(89):1–97, 2023
2023
-
[4]
Physics-informed neural operator for learning partial differential equations.ACM/IMS Journal of Data Science, 1(3):1–27, 2024
Zongyi Li, Hongkai Zheng, Nikola Kovachki, David Jin, Haoxuan Chen, Burigede Liu, Kamyar Azizzadenesheli, and Anima Anandkumar. Physics-informed neural operator for learning partial differential equations.ACM/IMS Journal of Data Science, 1(3):1–27, 2024
2024
-
[5]
Principles of plasma discharges and materials processing.MRS Bulletin, 30(12):899–901, 1994
Michael A Lieberman and Allan J Lichtenberg. Principles of plasma discharges and materials processing.MRS Bulletin, 30(12):899–901, 1994
1994
-
[6]
G. J. M. Hagelaar and L. C. Pitchford. Solving the boltzmann equation to obtain electron transport coefficients and rate coefficients for fluid models.Plasma sources science and technology, 14(4):722–733, 2005
2005
-
[7]
Large-signal analysis of a silicon read diode oscillator.IEEE Transactions on electron devices, 16(1):64–77, 2005
Donald L Scharfetter and Hermann K Gummel. Large-signal analysis of a silicon read diode oscillator.IEEE Transactions on electron devices, 16(1):64–77, 2005
2005
-
[8]
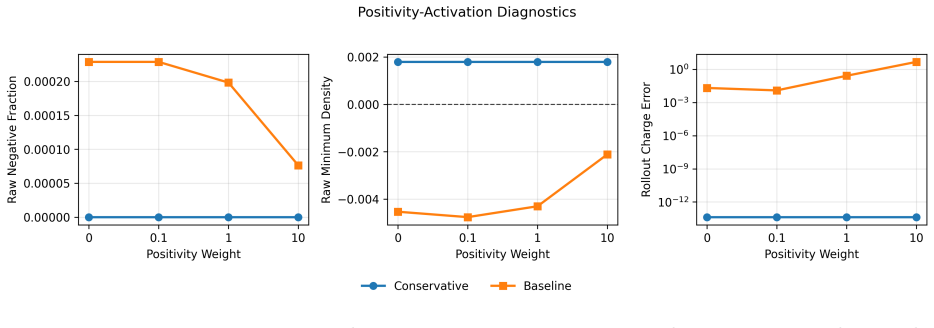
The bohm criterion and sheath formation.Journal of Physics D: Applied Physics, 24(4):493–518, 1991
K-U Riemann. The bohm criterion and sheath formation.Journal of Physics D: Applied Physics, 24(4):493–518, 1991
1991
-
[9]
Shamsulhaq Basir and Inanc Senocak. An adaptive augmented lagrangian method for training physics and equality constrained artificial neural networks.arXiv preprint arXiv:2306.04904, 2023
arXiv 2023
-
[10]
An operator preconditioning perspective on training in physics-informed machine learning
Tim De Ryck, Florent Bonnet, Siddhartha Mishra, and Emmanuel De Bézenac. An operator preconditioning perspective on training in physics-informed machine learning. InInternational Conference on Learning Representations, volume 2024, pages 54886–54914, 2024
2024
-
[12]
Nathan Lichtlé, Alexi Canesse, Zhe Fu, Hossein Nick Zinat Matin, Maria Laura Delle Monache, and Alexandre M Bayen. (u) nfv: Supervised and unsupervised neural finite volume methods for solving hyperbolic pdes.arXiv preprint arXiv:2505.23702, 2025
arXiv 2025
-
[13]
Chenyang Huang, Amal S Sebastian, and Venkatasubramanian Viswanathan. Learning second- order tvd flux limiters using differentiable solvers.arXiv preprint arXiv:2503.09625, 2025
arXiv 2025
-
[14]
Exactly conservative physics-informed neural networks and deep operator networks for dynamical systems.Neural Networks, 181:106826, 2025
Elsa Cardoso-Bihlo and Alex Bihlo. Exactly conservative physics-informed neural networks and deep operator networks for dynamical systems.Neural Networks, 181:106826, 2025
2025
-
[15]
Adaptive correction mechanism for ensuring conservation laws in neural operators
Chaoyu Liu, Yangming Li, Zhongying Deng, Chris Budd, and Carola-Bibiane Schönlieb. Adaptive correction mechanism for ensuring conservation laws in neural operators. 21
-
[16]
Neural entropy-stable conservative flux form neural networks for learning hyperbolic conservation laws.Journal of Computational Physics, page 114719, 2026
Lizuo Liu, Lu Zhang, and Anne Gelb. Neural entropy-stable conservative flux form neural networks for learning hyperbolic conservation laws.Journal of Computational Physics, page 114719, 2026
2026
-
[17]
Benjamin D Shaffer, Shawn Koohy, Brooks Kinch, M Ani Hsieh, and Nathaniel Trask. Structure-preserving learning improves geometry generalization in neural pdes.arXiv preprint arXiv:2602.02788, 2026
Pith/arXiv arXiv 2026
-
[18]
Kinetic theory of the presheath and the bohm criterion.Plasma Sources Science and Technology, 20(2):025013, 2011
SD Baalrud and CC Hegna. Kinetic theory of the presheath and the bohm criterion.Plasma Sources Science and Technology, 20(2):025013, 2011
2011
-
[19]
A finite volume scheme for convection–diffusion equations with nonlinear diffusion derived from the scharfetter–gummel scheme.Numerische Mathematik, 121(4):637–670, 2012
Marianne Bessemoulin-Chatard. A finite volume scheme for convection–diffusion equations with nonlinear diffusion derived from the scharfetter–gummel scheme.Numerische Mathematik, 121(4):637–670, 2012. 22 A Appendix Tables Table A1: Multiseed aggregate (mean±standard deviation). Model One step MSE Rollout MSE Rollout charge error Rollout min density Conser...
2012
-
[20]
10 headline 16 64 64 128 7.35e-09 42.3 5.93e-15 4.48
-
[21]
15 multi seed / seed 001 16 64 64 128 6.56e-09 18.9 6.49e-15 0.358
-
[22]
15 multi seed / seed 002 16 64 64 128 6.14e-09 58.4 3.57e-15 2.22
-
[23]
15 multi seed / seed 003 16 64 64 128 7.19e-09 29.1 8.75e-15 2.72
-
[24]
15 multi seed / seed 004 16 64 64 128 1.19e-08 19.6 6.86e-15 0.257
-
[25]
15 multi seed / seed 005 16 64 64 128 7.05e-09 95.9 8.11e-15 1.27
-
[26]
18 harder regimes / bias stronger 16 64 64 128 7.82e-09 12.5 4.20e-15 1.45
-
[27]
18 harder regimes / data sparse 16 64 8 128 1.32e-08 49.6 4.48e-15 8.84
-
[28]
18 harder regimes / long horizon sparse16 64 8 256 1.19e-07 485 1.60e-14 113
-
[29]
18 harder regimes / stiff transport 16 96 32 160 7.20e-09 54.7 6.50e-15 0.954
-
[30]
19 core ablation / classical core only 16 64 64 128 1.15e-14 42.3 6.88e-15 4.48
-
[31]
19 core ablation / correction scale small 16 64 64 128 2.50e-10 42.3 1.11e-14 4.48
-
[32]
20 stability / rollout 016 16 64 64 16 2.34e-11 0.0122 9.92e-16 4.86e-04
-
[33]
20 stability / rollout 032 16 64 64 32 1.36e-10 0.276 1.89e-15 0.0203
-
[34]
20 stability / rollout 064 16 64 64 64 9.62e-10 4.27 2.95e-15 0.522
-
[35]
20 stability / rollout 128 16 64 64 128 7.35e-09 42.3 5.93e-15 4.48
-
[36]
23 learned value v2 / teacher flux classical core only v2 8 64 64 128 0.0406 1.56 1.09e-14 0.77
-
[37]
23 learned value v2 / teacher flux formal v2 8 64 64 128 0.0404 1.56 1.63e-14 0.77
-
[38]
23 learned value v2 / teacher flux positivity stress classical core only v2 8 64 64 128 0.212 0.96 2.23e-14 0.436
-
[39]
23 learned value v2 / teacher flux positivity stress formal v2 8 64 64 128 0.207 0.96 2.10e-14 0.436
-
[40]
31 generalization v2 / bias mild 8 64 64 128 0.0216 0.45 1.47e-14 0.0955
-
[41]
31 generalization v2 / bias strong 8 64 64 128 0.0713 3.72 1.44e-14 2.39
-
[42]
31 generalization v2 / dt large 8 64 64 128 0.0796 1.56 1.29e-14 0.77
-
[43]
31 generalization v2 / dt small 8 64 64 128 0.0146 1.58 1.70e-14 0.77
-
[44]
31 generalization v2 / electron diffu- sivity high 8 64 64 128 0.0517 1.67 7.93e-15 0.77
-
[45]
31 generalization v2 / electron diffu- sivity low 8 64 64 128 0.0212 1.41 1.38e-14 0.77
-
[46]
31 generalization v2 / electron mobil- ity high 8 64 64 128 0.0735 1.5 1.36e-14 0.77
-
[47]
31 generalization v2 / electron mobil- ity low 8 64 64 128 0.023 1.67 8.11e-15 0.77
-
[48]
31 generalization v2 / ion diffusivity high 8 64 64 128 0.0423 1.57 1.03e-14 0.77
-
[49]
31 generalization v2 / ion diffusivity low 8 64 64 128 0.0407 1.56 1.41e-14 0.77
-
[50]
31 generalization v2 / ion mobility high 8 64 64 128 0.0923 1.55 8.35e-15 0.77
-
[51]
31 generalization v2 / ion mobility low 8 64 64 128 0.0327 1.57 2.24e-14 0.77
-
[52]
41 mesh resolution v2 / grid 008 8 64 64 128 0.0404 1.56 1.63e-14 0.77
-
[53]
41 mesh resolution v2 / grid 016 16 64 64 128 0.119 14.2 4.04e-15 1.48
-
[54]
41 mesh resolution v2 / grid 032 32 64 64 128 0.459 13.4 1.32e-14 0.245
-
[55]
41 mesh resolution v2 / grid 064 64 64 64 128 0.704 10.3 9.04e-15 0.0948
-
[56]
51 data regime v2 / trajectories 004 8 64 4 128 0.0404 8.76 2.09e-14 0.561
-
[57]
51 data regime v2 / trajectories 008 8 64 8 128 0.0401 12.6 9.20e-15 8.32
-
[58]
51 data regime v2 / trajectories 016 8 64 16 128 0.0401 28.8 1.20e-14 0.375
-
[59]
51 data regime v2 / trajectories 032 8 64 32 128 0.0402 2.03 9.36e-15 0.739
-
[60]
51 data regime v2 / trajectories 064 8 64 64 128 0.0404 1.56 1.63e-14 0.77
-
[61]
61 training duration v2 / epochs 002 8 64 64 128 0.04 9.91 1.08e-14 1.25
-
[62]
61 training duration v2 / epochs 010 8 64 64 128 0.0392 4.3 1.34e-14 0.803
-
[63]
61 training duration v2 / epochs 025 8 64 64 128 0.0405 4.04 1.42e-14 1.67
-
[64]
61 training duration v2 / epochs 050 8 64 64 128 0.0405 2.86 1.50e-14 1.12
-
[65]
61 training duration v2 / epochs 100 8 64 64 128 0.0404 1.56 1.63e-14 0.77
-
[66]
71 model capacity v2 / hidden 016 8 64 64 128 0.039 0.0548 1.52e-14 0.0633
-
[67]
71 model capacity v2 / hidden 032 8 64 64 128 0.0401 0.206 1.18e-14 0.0467
-
[68]
71 model capacity v2 / hidden 064 8 64 64 128 0.0404 1.56 1.63e-14 0.77
-
[69]
Eval Cons
71 model capacity v2 / layers 2 8 64 64 128 0.0404 0.363 1.57e-14 0.265 24 CaseN x Steps Traj. Eval Cons. MSE Base MSE Cons. CE Base CE
-
[70]
71 model capacity v2 / layers 3 8 64 64 128 0.0404 1.56 1.63e-14 0.77
-
[71]
71 model capacity v2 / layers 4 8 64 64 128 0.0403 0.0136 1.08e-14 5.25e-03
-
[72]
81 loss weights v2 / conservation 0p0 8 64 64 128 0.0404 2.43 1.01e-14 0.582
-
[73]
81 loss weights v2 / conservation 0p1 8 64 64 128 0.0404 1.56 1.63e-14 0.77
-
[74]
81 loss weights v2 / conservation 10p0 8 64 64 128 0.0405 0.28 2.41e-14 0.0393
-
[75]
81 loss weights v2 / conservation 1p0 8 64 64 128 0.0403 0.298 1.68e-14 0.0153
-
[76]
81 loss weights v2 / positivity 0p0 8 64 64 128 0.214 3.91 2.28e-14 2.95
-
[77]
81 loss weights v2 / positivity 0p1 8 64 64 128 0.214 3.91 2.28e-14 2.95
-
[78]
81 loss weights v2 / positivity 10p0 8 64 64 128 0.214 3.91 2.28e-14 2.95
-
[79]
81 loss weights v2 / positivity 1p0 8 64 64 128 0.214 3.91 2.28e-14 2.95
-
[80]
82 positivity activation v3 / positivity 0p0 8 64 64 128 2.52 0.446 4.26e-14 0.0206
-
[81]
82 positivity activation v3 / positivity 0p1 8 64 64 128 2.52 0.278 4.26e-14 0.0124
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.