Training-free image inversion for one-step diffusion models
Pith reviewed 2026-06-28 17:15 UTC · model grok-4.3
The pith
Training-free inversion enables precise real-image editing in one-step diffusion models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors claim that iterative noise alignment minimizes the distance to ideal Gaussian noise and suffix learning reduces caption mismatch, jointly allowing precise inversion of real images into initial noise for one-step diffusion models and enabling high-quality editing that outperforms multistep methods in efficiency.
What carries the argument
iterNA (iterative noise alignment) and suffL (suffix learning) that close the distribution gap and caption gap respectively.
If this is right
- Real images invert directly into usable initial noise without model training.
- One-step models support image editing at speeds far above multistep approaches.
- Mask-based editing allows localized changes while keeping background unchanged.
- Performance reaches state-of-the-art levels on PIE-Bench for one-step diffusion editing.
Where Pith is reading between the lines
- The same noise-alignment and prompt-suffix steps might transfer to other fast generative models if similar distribution and alignment gaps appear.
- Because the method runs in one step, it could support real-time editing pipelines on limited hardware.
- If the caption gap varies strongly across model versions, suffL may require per-model retuning rather than working universally.
Load-bearing premise
The two factors of initial latent editability and caption gap are the main barriers, and iterNA plus suffL will produce reliable inversions without side effects across varied images.
What would settle it
Apply TFinv to real images on PIE-Bench, generate edits, and check whether the results show more visible artifacts or lower fidelity than multistep baselines; consistent underperformance would falsify the claim.
Figures
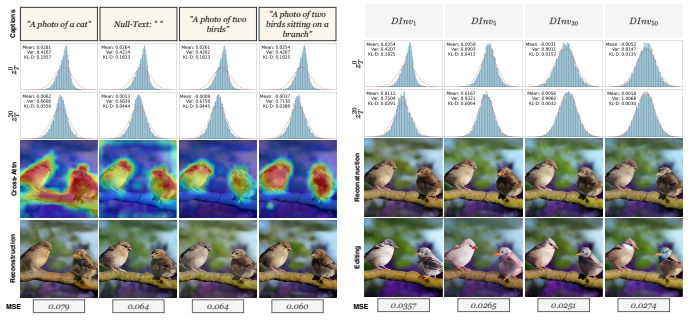
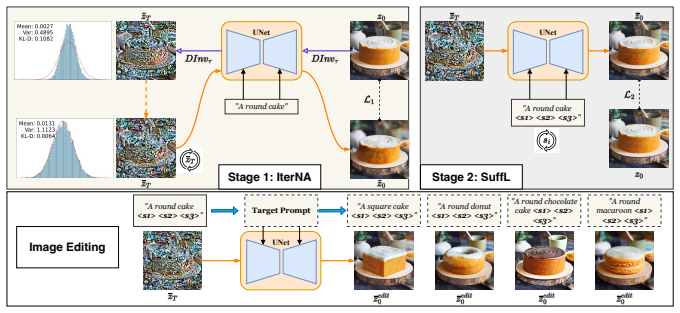


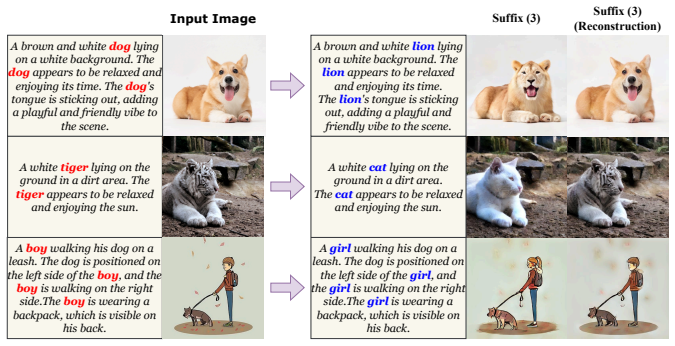
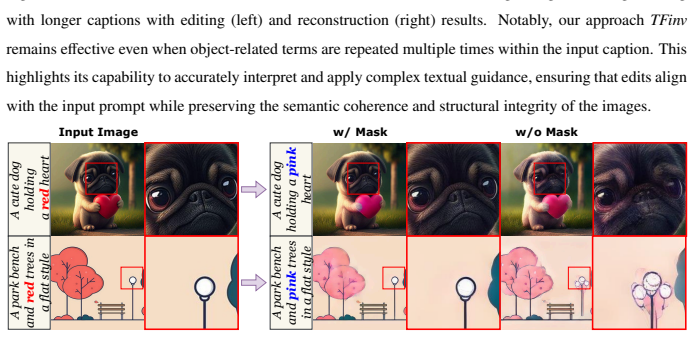
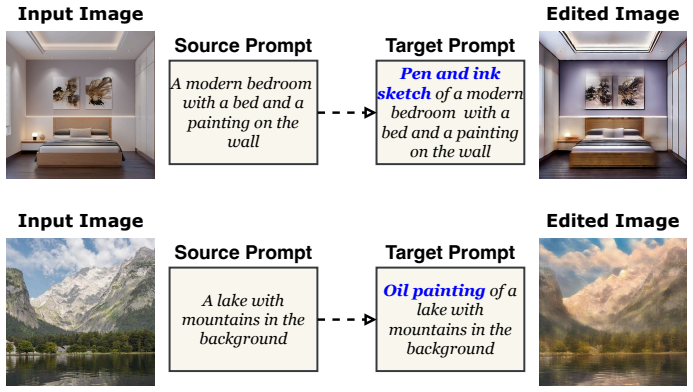
read the original abstract
In this work, we introduce a novel training-free inversion (TFinv) framework for one-step diffusion models,addressing key challenges in real image inversion and editing. We first identify two critical factors hamperingreal-image inversion and editing: (1) Initial Latent Editability, which is related to the distance between theinitial noise and the ideal Gaussian distribution, and (2) Caption Gap, which means the alignment betweentext captions and image representations. Both factors influence inversion efficiency and the editability ofone-step diffusion models. Then, we propose two novel techniques: iterative noise alignment (iterNA), whichminimizes the distribution gap to align with the normal Gaussian distribution, and suffix learning (suffL),which enhances text-to-image caption alignment by introducing learned suffix prompt tokens. These techniquesenable precise inversion of input images into their initial noise representations and facilitate image editing.Furthermore, we propose a mask-based editing technique for localized edits while preserving backgroundintegrity. Comprehensive experiments on the PIE-Bench dataset validate that our method TFinv not onlyachieves state-of-the-art performance in one-step diffusion editing, but also significantly outperforms existingmultistep approaches in efficiency. The code is available at https://github.com/tttao-uwu/TFinv.git.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces TFinv, a training-free inversion framework for one-step diffusion models. It identifies two factors limiting real-image inversion and editing—Initial Latent Editability (distance of initial noise from ideal Gaussian) and Caption Gap (text-image alignment)—and proposes iterative noise alignment (iterNA) to close the distribution gap plus suffix learning (suffL) to improve alignment via learned suffix tokens. A mask-based editing technique for localized edits is also presented. Experiments on PIE-Bench are reported to establish state-of-the-art one-step editing performance while significantly outperforming multistep methods in efficiency; code is released at the cited GitHub repository.
Significance. If the performance and efficiency claims hold after verification, the contribution would be significant for diffusion-based image editing: one-step models are computationally attractive, and a reliable training-free inversion method would expand their use on real images. The explicit code release is a clear strength for reproducibility. An efficiency advantage over multistep baselines, if quantitatively substantiated, would be a practical advance in the field.
major comments (2)
- [Abstract and §3 (Method)] Abstract and §3 (Method): The central SOTA and efficiency claims rest on the assertion that iterNA and suffL suffice because Initial Latent Editability and Caption Gap are the primary, sufficient barriers. No derivation, ablation, or analysis is provided showing that other factors (e.g., one-step discretization artifacts or prompt sensitivity outside suffixes) are negligible or that the techniques introduce no new failure modes on diverse images; this assumption is load-bearing for the performance assertions.
- [Experiments section] Experiments section: The manuscript states that 'comprehensive experiments on the PIE-Bench dataset validate' the claims, yet the visible text supplies no quantitative tables, ablation results, or direct efficiency metrics (runtime, steps) comparing TFinv to multistep baselines; without these, the SOTA and efficiency statements cannot be checked against the identified gaps.
minor comments (2)
- [Abstract] Abstract: minor typographical issues exist (e.g., missing spaces in 'models,addressing' and 'hamperingreal-image').
- [Abstract] Abstract: the definitions of iterNA and suffL would benefit from a short formal description or pseudocode at first mention to improve readability before the experimental claims.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments. We provide point-by-point responses below and will revise the manuscript to address the concerns raised.
read point-by-point responses
-
Referee: [Abstract and §3 (Method)] Abstract and §3 (Method): The central SOTA and efficiency claims rest on the assertion that iterNA and suffL suffice because Initial Latent Editability and Caption Gap are the primary, sufficient barriers. No derivation, ablation, or analysis is provided showing that other factors (e.g., one-step discretization artifacts or prompt sensitivity outside suffixes) are negligible or that the techniques introduce no new failure modes on diverse images; this assumption is load-bearing for the performance assertions.
Authors: We acknowledge that the paper does not include a formal proof or exhaustive analysis demonstrating that these are the only limiting factors. The identification is motivated by our initial investigations into inversion failures. To strengthen this, we will include additional ablations in the revised manuscript examining other factors such as discretization artifacts and prompt sensitivity, along with analysis of potential new failure modes introduced by our methods. revision: yes
-
Referee: [Experiments section] Experiments section: The manuscript states that 'comprehensive experiments on the PIE-Bench dataset validate' the claims, yet the visible text supplies no quantitative tables, ablation results, or direct efficiency metrics (runtime, steps) comparing TFinv to multistep baselines; without these, the SOTA and efficiency statements cannot be checked against the identified gaps.
Authors: We agree that the current version lacks the detailed quantitative tables and metrics. We will incorporate comprehensive tables, ablation studies, and efficiency comparisons (including runtime and number of steps) in the revised Experiments section to substantiate the SOTA and efficiency claims. revision: yes
Circularity Check
No circularity: method consists of independent algorithmic proposals validated empirically
full rationale
The paper presents TFinv as a training-free framework that identifies two factors (Initial Latent Editability and Caption Gap) via observation and introduces iterNA and suffL as new techniques to address them, followed by mask-based editing and evaluation on PIE-Bench. No equations, fitted parameters renamed as predictions, self-citations used as load-bearing uniqueness theorems, or ansatzes smuggled via prior work appear in the provided text. The derivation chain is a sequence of proposed algorithmic steps whose performance claims rest on external dataset results rather than reducing to self-definition or input fitting by construction. This is the normal case of a self-contained empirical method paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Rombach, A
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, B. Ommer, High-resolution im- age synthesis with latent diffusion models, in: Proceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition (CVPR), 2022, pp. 10684– 10695
2022
-
[3]
J. Song, C. Meng, S. Ermon, Denoising diffusion implicit models, in: Interna- tional Conference on Learning Representations, 2021
2021
-
[4]
Sauer, D
A. Sauer, D. Lorenz, A. Blattmann, R. Rombach, Adversarial diffusion distilla- tion, ECCV (2024)
2024
-
[5]
Deutch, R
G. Deutch, R. Gal, D. Garibi, O. Patashnik, D. Cohen-Or, Turboedit: Text-based image editing using few-step diffusion models, in: SIGGRAPH Asia 2024 Con- ference Papers, 2024, pp. 1–12
2024
-
[6]
Z. Wu, N. Kolkin, J. Brandt, R. Zhang, E. Shechtman, Turboedit: Instant text- based image editing, in: European Conference on Computer Vision, Springer, 2025, pp. 365–381
2025
-
[7]
Garibi, O
D. Garibi, O. Patashnik, A. V oynov, H. Averbuch-Elor, D. Cohen-Or, Renoise: Real image inversion through iterative noising, in: European Conference on Com- puter Vision, Springer, 2024, pp. 395–413
2024
-
[8]
Huberman-Spiegelglas, V
I. Huberman-Spiegelglas, V . Kulikov, T. Michaeli, An edit friendly ddpm noise space: Inversion and manipulations, in: Proceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition, 2024, pp. 12469–12478
2024
-
[9]
S. Wang, Y . Yan, X. Yang, R. Zhang, Q. Wang, G. Cheng, K. Huang, Point2pix- zero: Point-driven refined diffusion for multi-object image editing, Pattern Recog- nition 170 (2026) 112041
2026
-
[10]
Hertz, R
A. Hertz, R. Mokady, J. Tenenbaum, K. Aberman, Y . Pritch, D. Cohen-Or, Prompt-to-prompt image editing with cross attention control, ICLR (2023)
2023
-
[11]
Tumanyan, M
N. Tumanyan, M. Geyer, S. Bagon, T. Dekel, Plug-and-play diffusion features for text-driven image-to-image translation, in: Proceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, 2023, pp. 1921–1930
2023
- [12]
-
[13]
K. Wang, F. Yang, S. Yang, M. A. Butt, J. van de Weijer, Dynamic prompt learn- ing: Addressing cross-attention leakage for text-based image editing, NeurIPS (2023)
2023
- [14]
-
[15]
Mokady, A
R. Mokady, A. Hertz, K. Aberman, Y . Pritch, D. Cohen-Or, Null-text inversion for editing real images using guided diffusion models, CVPR (2023)
2023
-
[16]
S. Li, J. van de Weijer, T. Hu, F. S. Khan, Q. Hou, Y . Wang, J. Yang, Stylediffu- sion: Prompt-embedding inversion for text-based editing, Computational Visual Media Conference (2024)
2024
-
[17]
Zhang, J
Y . Zhang, J. Xing, E. Lo, J. Jia, Real-world image variation by aligning diffusion inversion chain, Advances in Neural Information Processing Systems 36 (2024)
2024
-
[18]
M. N. Everaert, A. Fitsios, M. Bocchio, S. Arpa, S. Süsstrunk, R. Achanta, Exploiting the signal-leak bias in diffusion models, in: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2024, pp. 4025–4034
2024
-
[19]
H. Liu, C. Li, Q. Wu, Y . J. Lee, Visual instruction tuning, Advances in neural information processing systems 36 (2024)
2024
-
[20]
H. Liu, C. Li, Y . Li, Y . J. Lee, Improved baselines with visual instruction tuning, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 26296–26306
2024
-
[22]
Saharia, W
C. Saharia, W. Chan, S. Saxena, L. Li, J. Whang, E. Denton, S. K. S. Ghasemipour, B. K. Ayan, S. S. Mahdavi, R. G. Lopes, et al., Photorealistic text- to-image diffusion models with deep language understanding, NeurIPS (2022). 25
2022
-
[23]
T. Yin, M. Gharbi, R. Zhang, E. Shechtman, F. Durand, W. T. Freeman, T. Park, One-step diffusion with distribution matching distillation, in: CVPR, 2024, pp. 6613–6623
2024
-
[24]
W. Luo, T. Hu, S. Zhang, J. Sun, Z. Li, Z. Zhang, Diff-instruct: A universal approach for transferring knowledge from pre-trained diffusion models, NeurIPS 36 (2023)
2023
-
[25]
T. H. Nguyen, A. Tran, Swiftbrush: One-step text-to-image diffusion model with variational score distillation, CVPR (2024)
2024
-
[26]
Karras, M
T. Karras, M. Aittala, S. Laine, E. Härkönen, J. Hellsten, J. Lehtinen, T. Aila, Alias-free generative adversarial networks, in: NeurIPS, V ol. 34, 2021, pp. 852– 863
2021
-
[27]
Pernuš, C
M. Pernuš, C. Fookes, V . Štruc, S. Dobrišek, Fice: Text-conditioned fashion- image editing with guided gan inversion, Pattern Recognition 158 (2025) 111022
2025
-
[28]
D. P. Kingma, M. Welling, Auto-encoding variational bayes, arXiv preprint arXiv:1312.6114 (2013)
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[29]
Esser, R
P. Esser, R. Rombach, B. Ommer, Taming transformers for high-resolution image synthesis, in: CVPR, 2021, pp. 12873–12883
2021
-
[30]
Razavi, A
A. Razavi, A. Van den Oord, O. Vinyals, Generating diverse high-fidelity images with vq-vae-2, in: NeurIPS, 2019
2019
-
[31]
Van Den Oord, N
A. Van Den Oord, N. Kalchbrenner, K. Kavukcuoglu, Pixel recurrent neural net- works, in: ICML, 2016
2016
-
[32]
L. Dinh, J. Sohl-Dickstein, S. Bengio, Density estimation using real nvp, ICLR (2017)
2017
-
[33]
Y . Song, P. Dhariwal, M. Chen, I. Sutskever, Consistency models, in: Interna- tional Conference on Machine Learning, PMLR, 2023, pp. 32211–32252. 26
2023
-
[34]
S. Luo, Y . Tan, L. Huang, J. Li, H. Zhao, Latent consistency models: Synthesizing high-resolution images with few-step inference, arXiv preprint arXiv:2310.04378 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[35]
C. Tang, K. Wang, J. van de Weijer, Iterinv: Iterative inversion for pixel-level t2i models, Neurips 2023 workshop on Diffusion Models (2023)
2023
- [36]
-
[37]
Lin, Y .-W
Y . Lin, Y .-W. Chen, Y .-H. Tsai, L. Jiang, M.-H. Yang, Text-driven image editing via learnable regions, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2024, pp. 7059–7068
2024
- [38]
-
[39]
Chang, H
H. Chang, H. Zhang, J. Barber, A. Maschinot, J. Lezama, L. Jiang, M.-H. Yang, K. Murphy, W. T. Freeman, M. Rubinstein, et al., Muse: Text-to-image gener- ation via masked generative transformers, International Conference on Machine Learning (2023)
2023
-
[40]
Hierarchical Text-Conditional Image Generation with CLIP Latents
A. Ramesh, P. Dhariwal, A. Nichol, C. Chu, M. Chen, Hierarchical text- conditional image generation with clip latents, arXiv preprint arXiv:2204.06125 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[41]
Kawar, S
B. Kawar, S. Zada, O. Lang, O. Tov, H. Chang, T. Dekel, I. Mosseri, M. Irani, Imagic: Text-based real image editing with diffusion models, CVPR (2023)
2023
- [42]
-
[43]
Dhariwal, A
P. Dhariwal, A. Nichol, Diffusion models beat gans on image synthesis, Advances in Neural Information Processing Systems 34 (2021) 8780–8794
2021
-
[44]
Radford, J
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, et al., Learning transferable visual models from 27 natural language supervision, in: International conference on machine learning, PMLR, 2021, pp. 8748–8763
2021
-
[45]
C. Lu, Y . Zhou, F. Bao, J. Chen, C. Li, J. Zhu, Dpm-solver: A fast ode solver for diffusion probabilistic model sampling in around 10 steps, Advances in Neural Information Processing Systems 35 (2022) 5775–5787
2022
-
[46]
J. Song, C. Meng, S. Ermon, Denoising diffusion implicit models, ICLR (2021)
2021
-
[47]
Starodubcev, M
N. Starodubcev, M. Khoroshikh, A. Babenko, D. Baranchuk, Invertible consis- tency distillation for text-guided image editing in around 7 steps, NeurIPS (2024)
2024
-
[48]
Tumanyan, O
N. Tumanyan, O. Bar-Tal, S. Bagon, T. Dekel, Splicing vit features for semantic appearance transfer, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 10748–10757
2022
-
[49]
Zhang, P
R. Zhang, P. Isola, A. A. Efros, E. Shechtman, O. Wang, The unreasonable ef- fectiveness of deep features as a perceptual metric, in: Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 586–595
2018
-
[50]
Z. Wang, E. P. Simoncelli, A. C. Bovik, Multiscale structural similarity for im- age quality assessment, in: The Thrity-Seventh Asilomar Conference on Signals, Systems & Computers, 2003, V ol. 2, Ieee, 2003, pp. 1398–1402
2003
-
[51]
J. Kim, Y . Hong, J. Park, J. C. Ye, Flowalign: Trajectory-regularized, inversion- free flow-based image editing, ICLR (2026)
2026
-
[52]
Decoupled Weight Decay Regularization
I. Loshchilov, F. Hutter, Decoupled weight decay regularization, arXiv preprint arXiv:1711.05101 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[53]
Tumanyan, M
N. Tumanyan, M. Geyer, S. Bagon, T. Dekel, Plug-and-play diffusion features for text-driven image-to-image translation, CVPR (2023)
2023
-
[54]
LLaMA: Open and Efficient Foundation Language Models
H. Touvron, T. Lavril, G. Izacard, X. Martinet, M.-A. Lachaux, T. Lacroix, B. Rozière, N. Goyal, E. Hambro, F. Azhar, et al., Llama: Open and efficient foundation language models, arXiv preprint arXiv:2302.13971 (2023). 28
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.