UniD³: A Knowledge Graph-Enhanced RAG Framework for Drug-Disease Discovery and Reasoning
Pith reviewed 2026-06-28 16:57 UTC · model grok-4.3
The pith
UniD³ combines LLMs with knowledge graph RAG to turn PubMed literature into structured drug-disease datasets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
UniD³ processes 157,849 PubMed articles with Llama 3.3-70B and constructs knowledge graphs via a dual-stage strategy combining paper-level extraction with KG-level consolidation centered on drug and disease entities. These graphs support KG-RAG-based generation of structured datasets for Drug-Disease Matching, Drug Effectiveness Assessment, and Drug-Target Analysis, achieving F1 scores of 0.85-0.87 on external validation and AUROC of 0.90 in clinician review, while KG-RAG models outperform standalone LLMs.
What carries the argument
The dual-stage paper-level extraction and KG-level consolidation centered on drug and disease entities, which feeds consolidated graphs into KG-RAG for evidence-grounded generation of structured outputs.
If this is right
- KG-RAG-augmented models outperform standalone LLMs on the drug-disease tasks.
- The framework produces over 28,915 DDM and 15,042 DEA QA pairs plus more than 4,000 DTA pairs.
- The UniD³ chatbot enables interpretable, citation-supported exploration of drug-disease relationships.
- The overall approach supplies a scalable method for converting unstructured literature into usable knowledge for repurposing and precision medicine.
Where Pith is reading between the lines
- The same dual-stage KG construction could be applied to extract other biomedical relations such as gene-disease or protein-drug links.
- Periodic re-running of the pipeline on new literature releases could maintain up-to-date graphs without full manual re-curation.
- Hybrid use with existing curated databases might further reduce any residual extraction errors.
Load-bearing premise
The dual-stage extraction and consolidation with Llama 3.3-70B on 157,849 articles produces accurate entity relations without substantial hallucination or selection bias.
What would settle it
An independent manual review of a sample of the generated QA pairs or relations that finds agreement rates substantially below the reported F1 of 0.85-0.87 or clinician AUROC of 0.90.
Figures

read the original abstract
Systematic characterization of drug-disease relationships is essential for drug discovery and repurposing, yet is hindered by the heterogeneity and rapid growth of biomedical literature. Existing datasets rely on labor-intensive curation and are often incomplete, while LLM-only approaches suffer from hallucination and weak evidence grounding. We introduce UniD$^3$, a unified framework that integrates Large Language Models with Knowledge Graph-enhanced Retrieval-Augmented Generation (KG-RAG) to extract, organize, and validate drug-disease knowledge across Drug-Disease Matching (DDM), Drug Effectiveness Assessment (DEA), and Drug-Target Analysis (DTA). UniD$^3$ processes 157,849 PubMed articles with Llama 3.3-70B and constructs knowledge graphs via a dual-stage strategy combining paper-level extraction with KG-level consolidation centered on drug and disease entities. These graphs support KG-RAG-based generation of structured datasets, evaluated through external benchmarks, fuzzy matching with curated resources, and clinician review. UniD$^3$ produces six knowledge graphs and large-scale datasets, including 28,915 DDM, 15,042 DEA, and over 4,000 DTA QA pairs. External validation shows strong performance (F1: 0.85-0.87 for DDM/DEA; 0.82 for DTA), with clinician review confirming high reliability (AUROC = 0.90). KG-RAG-augmented models outperform standalone LLMs, and the UniD$^3$ chatbot enables interpretable, citation-supported exploration of drug-disease relationships. UniD$^3$ provides a scalable, extensible framework for transforming unstructured biomedical literature into high-quality, structured drug-disease knowledge, supporting AI-driven discovery, repurposing, and precision medicine.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces UniD³, a KG-RAG framework that applies Llama 3.3-70B to 157,849 PubMed articles via dual-stage paper-level extraction followed by KG-level consolidation around drug/disease entities. It constructs six knowledge graphs and generates large QA datasets (28,915 DDM, 15,042 DEA, >4,000 DTA pairs) for drug-disease matching, effectiveness assessment, and target analysis. External benchmarks report F1 scores of 0.85-0.87 (DDM/DEA) and 0.82 (DTA), clinician review yields AUROC 0.90, KG-RAG outperforms standalone LLMs, and a citation-supported chatbot is provided for exploration.
Significance. If the extraction and consolidation steps are shown to be accurate, the work supplies a scalable pipeline for converting unstructured literature into structured, evidence-linked drug-disease knowledge at a scale (157k articles) that existing curated resources cannot match. The release of the generated datasets and the interpretable KG-RAG chatbot constitute concrete, reusable contributions to biomedical NLP and drug-repurposing research.
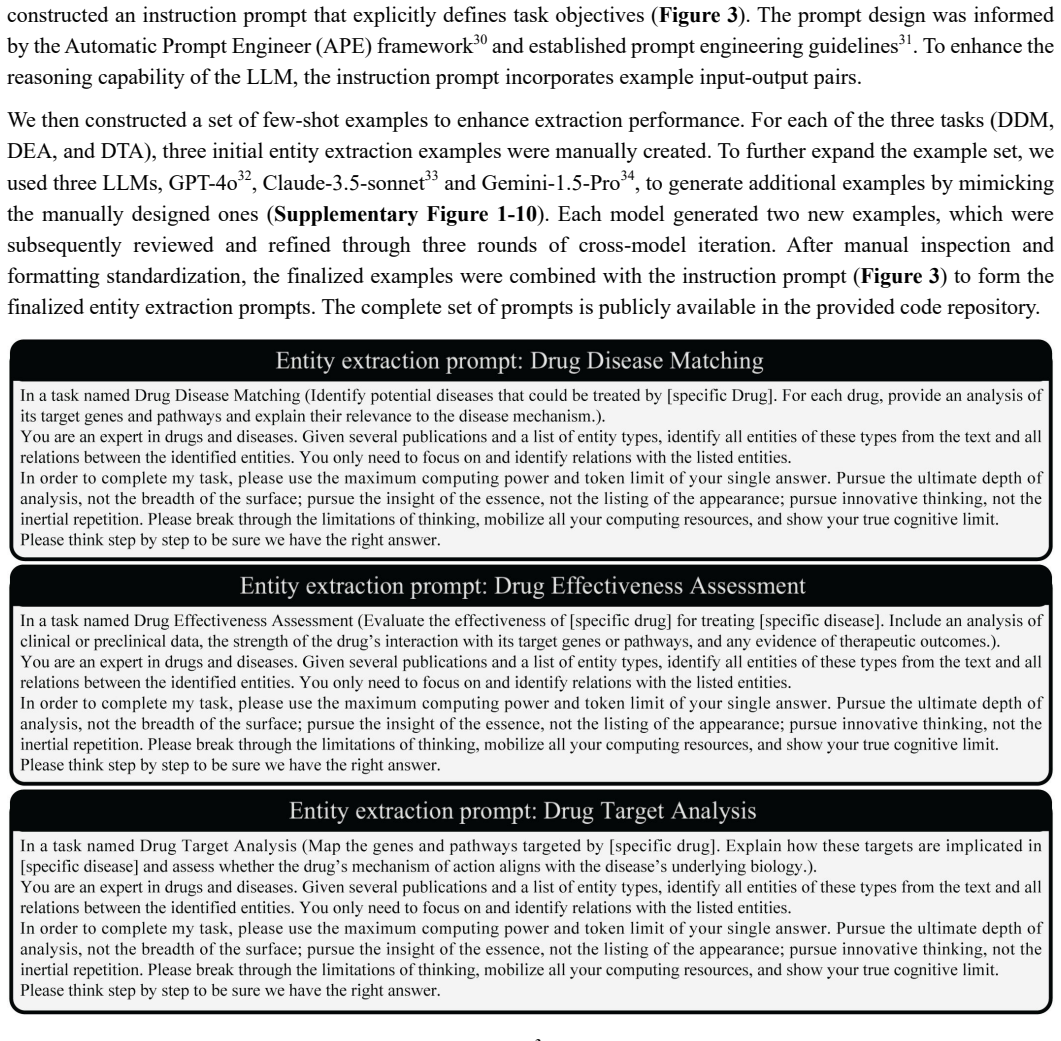
major comments (2)
- [Evaluation] Evaluation section: The reported F1 0.85-0.87 and clinician AUROC 0.90 rest on external benchmarks, fuzzy matching, and clinician review, yet no held-out human-annotated precision/recall, inter-annotator agreement, or error analysis is provided for the paper-level extraction step itself. Because the central claim is that the dual-stage process yields high-quality structured knowledge without substantial hallucination, the absence of an independent extraction-level validation is load-bearing.
- [Methods] Methods (dual-stage KG construction): The paper asserts that KG-level consolidation improves accuracy over paper-level extraction alone, but supplies no ablation that quantifies hallucination or relation-error rates before versus after consolidation. Without this measurement it is impossible to determine whether the reported downstream metrics reflect true knowledge quality or undetected systematic errors in the 157k-article extraction.
minor comments (2)
- The abstract states that six knowledge graphs are produced; the manuscript should include a table or section explicitly listing their node/edge counts, entity coverage, and construction parameters for reproducibility.
- Clarify the exact prompting templates and few-shot examples used for the Llama 3.3-70B extraction and consolidation stages; current description is high-level and would benefit from an appendix containing the prompts.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on evaluation and methods. We respond point-by-point below.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: The reported F1 0.85-0.87 and clinician AUROC 0.90 rest on external benchmarks, fuzzy matching, and clinician review, yet no held-out human-annotated precision/recall, inter-annotator agreement, or error analysis is provided for the paper-level extraction step itself. Because the central claim is that the dual-stage process yields high-quality structured knowledge without substantial hallucination, the absence of an independent extraction-level validation is load-bearing.
Authors: We agree that the current validations (external benchmarks, fuzzy matching to curated resources, and clinician review) do not isolate the paper-level extraction step with held-out human annotations or inter-annotator agreement. This is a substantive gap for the central claim. In revision we will add a dedicated extraction-level validation subsection reporting precision/recall on a held-out human-annotated sample, inter-annotator agreement, and error analysis. revision: yes
-
Referee: [Methods] Methods (dual-stage KG construction): The paper asserts that KG-level consolidation improves accuracy over paper-level extraction alone, but supplies no ablation that quantifies hallucination or relation-error rates before versus after consolidation. Without this measurement it is impossible to determine whether the reported downstream metrics reflect true knowledge quality or undetected systematic errors in the 157k-article extraction.
Authors: The manuscript describes the consolidation step but does not quantify its effect via ablation on hallucination or relation-error rates. We acknowledge this limits interpretation of the downstream metrics. In the revision we will add an ablation study on a representative subset measuring error rates before and after consolidation. revision: yes
Circularity Check
No circularity; empirical system evaluation without derivations or self-referential reductions
full rationale
The paper presents a descriptive framework for LLM-based extraction and KG construction from PubMed articles, followed by empirical evaluation via external benchmarks, fuzzy matching, and clinician review. No equations, derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. Performance numbers (F1 0.85-0.87, AUROC 0.90) are reported outcomes of the described pipeline rather than quantities defined in terms of the pipeline's own outputs. The central claim therefore does not reduce to its inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Data Collection DDM DEA DTA Llama 3 KG Knowledge Graph Refinement Stage I: Paper-level
-
[2]
Ah, the PI3K pathway
Dual-Stage Extraction (UniD3 Core) Stage II: KG-level Drug Entity Expansion Targets Side Effect Gene Pathway Gene Pathway Gene Gene Side Effect Disease Entity b Structured Datasets & Explainable Chat Which pathway is involved in Disease B treatment with Drug A? Let's use our KG-RAG. Ah, the PI3K pathway. Based on the KG and 150K+ papers, the PI3K/AKT path...
2024
-
[3]
effective
and applied them to perform task-specific classification and filtering. Using his approach, the Llama3.3-70B model initially identified 4,701, 4,642, and 4,638 papers for the three tasks, respectiv ely. However, due to potential hallucination effects in the LLM, some of the extracted titles were incomplete or inconsistent with the expected content. To add...
2079
-
[4]
[VD] Context: Influence of baseline airflow obstruction on the patient's ability to detect any further increase in airway resistance
-
[5]
[VD] Context: Effect of eosinophilic inflammation on the airway and its relation to perception of dyspnea
-
[6]
[VD] Study findings on the effect of ICSs on PD during bronchoconstriction
-
[7]
[KG] Asthma pathophysiology and treatment guidelines
-
[8]
Short: yes Base Model Answer Reference Answer UniD3 Answer validated by clinicians and cross -referenced with external datasets
[KG] Role of inhaled corticosteroids in asthma management and their effects on airway inflammation and hyperresponsiveness." IS LATE-NIGHT SALIV ARY CORTISOL A BETTER SCREENING TEST FOR POSSIBLE CORTISOL EXCESS THAN STANDARD SCREENING TESTS IN OBESE PATIENTS WITH TYPE 2 DIABETES? Long: We have shown that eosinophilic inflammation of the airway wall may in...
-
[9]
& Cheng, Y
Yang, J., Li, Z., Fan, X. & Cheng, Y. Drug–disease association and drug-repositioning predictions in complex diseases using causal inference –probabilistic matrix factorization. Journal of chemical information and modeling 54, 2562-2569 (2014)
2014
-
[10]
& Woodcock, J
Corrigan-Curay, J., Sacks, L. & Woodcock, J. Real -world evidence and real -world data for evaluating drug safety and effectiveness. Jama 320, 867-868 (2018)
2018
-
[11]
& MacKenzie, D
Mitchell, O., Wilson, D.B., Eggers, A. & MacKenzie, D. L. Assessing the effectiveness of drug courts on recidivism: A meta-analytic review of traditional and non -traditional drug courts. Journal of Criminal Justice 40, 60-71 (2012)
2012
-
[12]
Liu, X. et al. DrugFormer: Graph‐Enhanced Language Model to Predict Drug Sensitivity. Advanced Science 11, 2405861 (2024)
2024
- [13]
- [14]
-
[15]
-I., Cusick, M.E., Barabási, A
Yıldırım, M.A., Goh, K. -I., Cusick, M.E., Barabási, A. -L. & Vidal, M. Drug —target network. Nature biotechnology 25, 1119-1126 (2007)
2007
-
[16]
Tanoli, Z. et al. Drug Target Commons 2.0: a communit y platform for systematic analysis of drug –target interaction profiles. Database 2018, bay083 (2018)
2018
-
[17]
Ochoa, D. et al. Open Targets Platform: supporting sys tematic drug–target identification and prioritisation. Nucleic acids research 49, D1302-D1310 (2021)
2021
-
[18]
Zhang, W. et al. Predicting drug-disease associations by using similarity constrained matrix factorization. BMC bioinformatics 19, 233 (2018)
2018
-
[19]
-H., Luo, L., Chen, Q
Lai, P.-T., Wei, C. -H., Luo, L., Chen, Q. & Lu, Z. BioREx: improving biomedical r elation extraction by leveraging heterogeneous datasets. Journal of Biomedical Informatics 146, 104487 (2023)
2023
-
[20]
& Wang, F
Zhu, Y ., Elemento, O., Pathak, J. & Wang, F. Drug knowle dge bases and their applications in biomedical informatics research. Briefings in bioinformatics 20, 1308-1321 (2019)
2019
-
[21]
Davis, A.P. et al. Comparative Toxicogenomics Database: a knowledgebase and discovery tool for chemical – gene–disease networks. Nucleic acids research 37, D786-D792 (2009)
2009
-
[22]
Brown, T. et al. Language models are few-shot learners. Advances in neural information processing systems 33, 1877-1901 (2020)
1901
-
[23]
Touvron, H. et al. Llama: Open and efficient foundat ion language models. arXiv preprint arXiv:2302.13971 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[24]
& van der Schaar, M
Seedat, N., Huynh, N., van Breugel, B. & van der Schaar, M. Curated llm: Synergy of llms and data curation for tabular augmentation in ultra low-data regimes. (2023)
2023
- [25]
-
[26]
Silberg, J. et al. UniTox: leveraging LLMs to curate a unified dataset of drug-induced toxicity from FDA labels. Advances in Neural Information Processing Systems 37, 12078-12093 (2024)
2024
-
[27]
Han, H. et al. Retrieval-augmented generation with graphs (graphrag). arXiv preprint arXiv:2501.00309 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
& Zhang, R
Li, M., Kilicoglu, H., Xu, H. & Zhang, R. Biomedrag: A retr ieval augmented large language model for biomedicine. Journal of Biomedical Informatics 162, 104769 (2025)
2025
- [29]
-
[30]
Zhao, X., Liu, S., Yang, S. -Y. & M i a o , C . i n P r o c e e d i n g s o f t h e A C M o n We b C o n f er e n c e 2 0 2 5 4 4 4 2-4457 (2025)
2025
- [31]
-
[32]
Matsumoto, N. et al. KRAGEN: a knowledge graph-enhanced RAG framework for biomedical problem solving using large language models. Bioinformatics 40, btae353 (2024)
2024
-
[33]
LightRAG: Simple and Fast Retrieval-Augmented Generation
Guo, Z., Xia, L., Yu, Y ., Ao, T. & Huang, C. Lightrag: Simple and fast retrieval-augmented generation. arXiv preprint arXiv:2410.05779 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[34]
Fan, T., Wang, J., Ren, X. & Huang, C. Minirag: Towards extremely simple retr ieval-augmented generation. arXiv preprint arXiv:2501.06713 (2025)
-
[35]
Edge, D. et al. From local to global: A graph rag app roach to query -focused summarization. arXiv preprint arXiv:2404.16130 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[36]
Wang, S., Fang, Y., Zhou, Y., Liu, X. & Ma, Y. ArchRAG: Attributed Community-based Hierarchical Retrieval- Augmented Generation. arXiv preprint arXiv:2502.09891 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
RapidFuzz: Rapid fuzzy string matching in Python and C++
contributors, M.B.a. RapidFuzz: Rapid fuzzy string matching in Python and C++. (2024)
2024
-
[38]
Zhou, Y . et al. in The eleventh international conference on learning representations (2022)
2022
-
[39]
White, J. et al. A prompt pattern catalog to enhance prompt engineering with chatgpt. arXiv preprint arXiv:2302.11382 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[40]
Hurst, A. et al. Gpt-4o system card. arXiv preprint arXiv:2410.21276 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[41]
Anthropic (Anthropic, 2024)
2024
-
[42]
Team, G. et al. Gemini: a family of highly capable multimodal models. arXiv preprint arXiv:2312.11805 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[43]
& Tchounwou, P.B
Dasari, S. & Tchounwou, P.B. Cisplatin in cancer therapy: molecular mechanisms of action. European journal of pharmacology 740, 364-378 (2014)
2014
-
[44]
Cisplatin: The first metal based anticancer drug
Ghosh, S. Cisplatin: The first metal based anticancer drug. Bioorganic chemistry 88, 102925 (2019)
2019
-
[45]
Druker, B.J. et al. Five -year follow -up of patients receiving imatinib for chronic myeloid leukemia. New England Journal of Medicine 355, 2408-2417 (2006)
2006
-
[46]
Slamon, D.J. et al. Use of chemotherapy plus a monoclonal antibody against HER2 for metastatic breast cancer that overexpresses HER2. New England journal of medicine 344, 783-792 (2001)
2001
-
[47]
Llovet, J.M. et al. Sorafenib in advanced hepatocellular carcinoma. New England journal of medicine 359, 378- 390 (2008)
2008
-
[48]
Dixon, S.J. et al. Ferroptosis: an iron-dependent form of nonapoptotic cell death. cell 149, 1060-1072 (2012)
2012
-
[49]
Singhal, A. et al. Metformin as adjunct antituberculosis therapy. Science translational medicine 6, 263ra159- 263ra159 (2014)
2014
- [50]
-
[51]
https://huggingface.co/datasets/YufeiHFUT/CDR_with_all_info (2024)
YufeiHFUT CDR_with_all_info. https://huggingface.co/datasets/YufeiHFUT/CDR_with_all_info (2024)
2024
-
[52]
https://huggingface.co/datasets/flxclxc/encoded_drug_reviews (2024)
flxclxc encoded_drug_reviews. https://huggingface.co/datasets/flxclxc/encoded_drug_reviews (2024)
2024
-
[53]
https://huggingface.co/datasets/P3ps/condition_to_drug (2024)
P3ps condition_to_drug. https://huggingface.co/datasets/P3ps/condition_to_drug (2024)
2024
-
[54]
https://huggingface.co/datasets/truehealth/medicationqa (2024)
TrueHealth medicationqa. https://huggingface.co/datasets/truehealth/medicationqa (2024)
2024
-
[55]
& Sankarasubbu, M
Pal, A. & Sankarasubbu, M. OpenBioLLMs: Advancing Open-Source Large Language Models for Healthcare and Life Sciences. Hugging Face repository (2024)
2024
-
[56]
JSL-MedLlama-3-8B-v2.0
Labs, J.S. JSL-MedLlama-3-8B-v2.0. https://huggingface.co/johnsnowlabs/JSL-MedLlama-3-8B-v2.0 (2024)
2024
-
[57]
https://huggingface.co/skumar9/Llama-medx_v3.2 (2024)
skumar9 Llama-medx_v3.2. https://huggingface.co/skumar9/Llama-medx_v3.2 (2024)
2024
-
[58]
Chen, J. et al. Huatuogpt-o1, towards medical complex reasoning with llms. arXiv preprint arXiv:2412.18925 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[59]
Luo, R. et al. BioGPT: generative pre-trained transformer for biomedical text generation and mining. Briefings in bioinformatics 23, bbac409 (2022)
2022
-
[60]
Grattafiori, A. et al. The llama 3 herd of models. arXiv preprint arXiv:2407.21783 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[61]
Open Life Science AI
AI, O.L.S. Open Life Science AI. https://huggingface.co/openlifescienceai (2024)
2024
-
[62]
& Sanderson, M
Tombros, A. & Sanderson, M. in Proceedings of the 21 st annual international ACM SIGIR conference on Research and development in information retrieval 2-10 (1998)
1998
-
[63]
& Zhu, W.-J
Papineni, K., Roukos, S., Ward, T. & Zhu, W.-J. in Proceedings of the 40th annual meeting of the Association for Computational Linguistics 311-318 (2002)
2002
-
[64]
i n Te x t s u m m a r i z a t i o n b r a n c h e s o u t 7 4-81 (2004)
Lin, C.-Y. i n Te x t s u m m a r i z a t i o n b r a n c h e s o u t 7 4-81 (2004)
2004
-
[65]
BERTScore: Evaluating Text Generation with BERT
Zhang, T., Kishore, V ., Wu, F., Weinberger, K.Q. & Artzi, Y . Bertscore: Evaluating text generation with bert. arXiv preprint arXiv:1904.09675 (2019)
work page internal anchor Pith review Pith/arXiv arXiv 1904
-
[66]
Hancock, D.Y . et al. in Practice and Experience in Advanced Research Computing 2021: Evolution Across All Dimensions 1-8 (2021)
2021
-
[67]
& Towns, J
Boerner, T.J., Deems, S., Furlani, T.R., Knuth, S.L. & Towns, J. in Practice and experience in advanced research computing 2023: Computing for the common good 173-176 (2023)
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.