DrugClaw and DrugAudit: A Primary-Source-Grounded Agent and Authority-Aware Benchmark for Drug-Information Question Answering
Pith reviewed 2026-06-28 16:51 UTC · model grok-4.3
The pith
DrugClaw is a multi-agent system that grounds drug-information answers in primary regulatory and peer-reviewed records at a 0.918 source rate.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
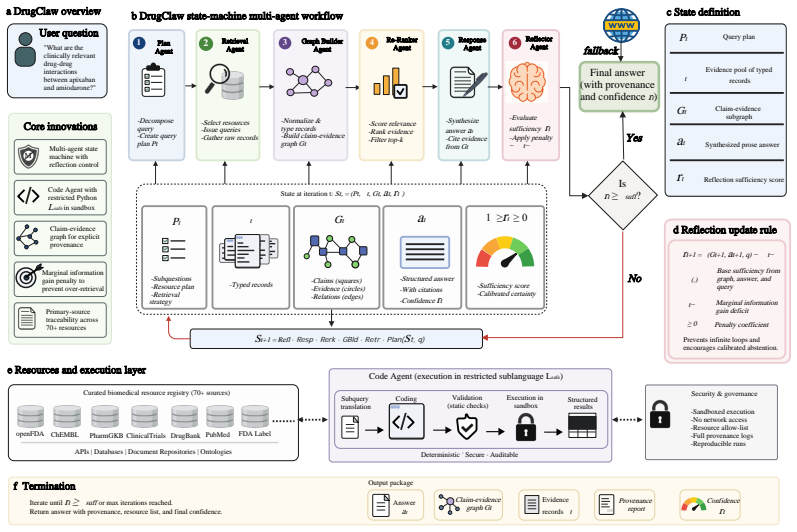
DrugClaw is a multi-agent retrieval-augmented system that queries a registry of drug and pharmacovigilance skills via a reflection-driven state-machine workflow and returns answers grounded in primary regulatory or peer-reviewed records. DrugAudit is a 3,772-item authority-aware benchmark whose evaluation panel scores upstream-of-gold source match, token-level semantic snippet overlap, and citation faithfulness under a dual-judge LLM-as-judge protocol with inter-judge kappa of 0.88. Across DrugAudit plus drug-related subsets of MedQA (751 items) and PubMedQA (512 items), DrugClaw is top-1 on every column of the headline table: composite Evidence Index under both judges, judge-mediated answer
What carries the argument
Multi-agent retrieval-augmented system with reflection-driven state-machine workflow that queries a registry of drug and pharmacovigilance skills to enforce primary-source grounding.
If this is right
- DrugClaw reaches a primary-source rate of 0.918, exceeding the next-best system by 10.1 percentage points.
- Citation faithfulness reaches 0.887, exceeding the next-best system by 5.9 percentage points.
- The system leads on the drug-related subsets of both MedQA (0.920) and PubMedQA (0.693).
- The dual-judge protocol yields almost-perfect agreement (kappa 0.88) on source match and faithfulness.
Where Pith is reading between the lines
- The same workflow could be tested on other regulated domains where provenance of facts is required, such as legal or financial question answering.
- Integration of the state-machine with live regulatory databases might further raise the primary-source rate beyond the reported 0.918.
- The DrugAudit benchmark could serve as a template for authority-aware evaluation in additional medical subfields.
Load-bearing premise
The dual-judge LLM-as-judge protocol with reported kappa of 0.88 provides an unbiased and sufficient measure of upstream source match and citation faithfulness.
What would settle it
A human re-evaluation of the same answer set that produces primary-source rates or faithfulness scores materially lower than the 0.918 and 0.887 reported by the LLM judges.
Figures
read the original abstract
Drug-information question answering is a high-stakes setting where hallucinated facts can mislead clinical decision-making and the provenance of each cited fact matters as much as the fact itself. We present DrugClaw, a multi-agent retrieval-augmented system that queries a registry of drug and pharmacovigilance skills via a reflection-driven state-machine workflow and returns answers grounded in primary regulatory or peer-reviewed records. We also contribute DrugAudit, a 3,772-item authority-aware benchmark with an evaluation panel that scores upstream-of-gold source match, token-level semantic snippet overlap, and citation faithfulness under a dual-judge LLM-as-judge protocol with inter-judge kappa = 0.88 (almost-perfect). Across DrugAudit plus drug-related subsets of MedQA (751) and PubMedQA (512), DrugClaw is top-1 on every column of the headline table: composite Evidence Index under both judges, judge-mediated answer correctness, primary-source rate (0.918, +10.1 pp over next-best), faithfulness (0.887, +5.9 pp), MedQA (0.920), and PubMedQA (0.693).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces DrugClaw, a multi-agent retrieval-augmented system that uses a reflection-driven state-machine workflow and a registry of drug/pharmacovigilance skills to produce answers grounded in primary regulatory or peer-reviewed sources. It also contributes DrugAudit, a 3,772-item authority-aware benchmark, and reports evaluations on this benchmark plus drug-related subsets of MedQA (751 items) and PubMedQA (512 items). Using a dual-judge LLM-as-judge protocol with inter-judge kappa of 0.88, the paper claims DrugClaw is top-1 on every metric, including primary-source rate (0.918), faithfulness (0.887), composite Evidence Index, and answer correctness.
Significance. If the evaluation protocol is shown to be unbiased and externally validated, the work would provide a concrete, reproducible agent architecture and benchmark focused on provenance in a high-stakes domain. The emphasis on primary-source grounding and the release of DrugAudit could serve as a useful testbed for future retrieval-augmented systems in pharmacovigilance and clinical QA.
major comments (2)
- [Abstract / Evaluation] Abstract and Evaluation section: The primary-source rate (0.918) and faithfulness (0.887) metrics that underpin all top-1 claims are computed exclusively by the dual-LLM judge protocol. The manuscript supplies neither the judge prompts, a human-expert calibration subset, nor any external validation of the judges against regulatory documents; only kappa=0.88 is reported. This is load-bearing for the headline table and the claim that DrugClaw outperforms baselines on upstream source match.
- [Evaluation] Evaluation protocol: The dual-judge setup for citation faithfulness and source match lacks any disclosed inter-annotator details beyond a single kappa value and does not compare LLM judgments to human experts on even a small held-out set. Without this, the possibility of shared inductive bias between judges and the retrieval-augmented agents cannot be ruled out, directly affecting the composite Evidence Index and cross-benchmark rankings.
minor comments (1)
- [Abstract] Abstract: The exact construction rules for the 3,772-item DrugAudit benchmark (e.g., sampling strategy, authority labeling criteria) are not summarized; a one-sentence description would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our evaluation protocol. We address the major comments point by point below, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract / Evaluation] Abstract and Evaluation section: The primary-source rate (0.918) and faithfulness (0.887) metrics that underpin all top-1 claims are computed exclusively by the dual-LLM judge protocol. The manuscript supplies neither the judge prompts, a human-expert calibration subset, nor any external validation of the judges against regulatory documents; only kappa=0.88 is reported. This is load-bearing for the headline table and the claim that DrugClaw outperforms baselines on upstream source match.
Authors: We agree the judge prompts were omitted from the initial submission and will include the full prompts in an expanded appendix of the revised manuscript. The reported kappa=0.88 reflects agreement between two independently prompted judges applied uniformly to all systems. While we acknowledge the value of human calibration, the specialized regulatory domain makes expert annotation costly; we will add an explicit limitations paragraph discussing this and the potential for shared bias, but the relative rankings remain informative given consistent application across baselines. revision: partial
-
Referee: [Evaluation] Evaluation protocol: The dual-judge setup for citation faithfulness and source match lacks any disclosed inter-annotator details beyond a single kappa value and does not compare LLM judgments to human experts on even a small held-out set. Without this, the possibility of shared inductive bias between judges and the retrieval-augmented agents cannot be ruled out, directly affecting the composite Evidence Index and cross-benchmark rankings.
Authors: The single kappa value is the inter-judge agreement statistic; we will expand the Evaluation section to describe the prompting procedure and judge independence in greater detail. We accept that absence of a human-expert held-out comparison leaves open the possibility of bias and will strengthen the limitations discussion accordingly. However, the dual-judge design with near-perfect agreement was selected precisely to mitigate single-model bias, and all systems were evaluated under identical conditions. revision: partial
- Direct comparison of LLM judge outputs against human experts on a held-out subset of DrugAudit items
Circularity Check
No significant circularity in empirical evaluation chain
full rationale
The paper presents an empirical system (DrugClaw) and benchmark (DrugAudit) whose headline metrics (primary-source rate 0.918, faithfulness 0.887) are reported as direct outputs of running the agent on the test items and scoring via the described dual-judge protocol. No equations, fitted parameters renamed as predictions, or derivation steps appear in the provided text that reduce by construction to the inputs. The LLM-as-judge protocol is an external measurement tool whose internal details are not shown to be self-defined from the agent itself. This is a standard empirical NLP paper whose central claims rest on benchmark results rather than any self-referential derivation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM-as-judge protocol with inter-judge kappa 0.88 is a reliable proxy for human judgment of source faithfulness
Reference graph
Works this paper leans on
-
[1]
International conference on learning representations , volume=
Self-rag: Learning to retrieve, generate, and critique through self-reflection , author=. International conference on learning representations , volume=
-
[2]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 3: System Demonstrations) , pages=
DrugWatch: A comprehensive multi-source data visualisation platform for drug safety information , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 3: System Demonstrations) , pages=
-
[3]
Nature machine intelligence , volume=
Augmenting large language models with chemistry tools , author=. Nature machine intelligence , volume=. 2024 , publisher=
2024
-
[4]
Scientific data , volume=
A standard database for drug repositioning , author=. Scientific data , volume=. 2017 , publisher=
2017
-
[5]
Educational and psychological measurement , volume=
A coefficient of agreement for nominal scales , author=. Educational and psychological measurement , volume=. 1960 , publisher=
1960
-
[6]
Nucleic acids research , volume=
DGIdb 3.0: a redesign and expansion of the drug--gene interaction database , author=. Nucleic acids research , volume=. 2018 , publisher=
2018
-
[7]
Advances in Neural Information Processing Systems , volume=
Adaptive context length optimization with low-frequency truncation for multi-agent reinforcement learning , author=. Advances in Neural Information Processing Systems , volume=
-
[8]
Cell , volume=
Empowering biomedical discovery with AI agents , author=. Cell , volume=. 2024 , publisher=
2024
-
[10]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
Enabling large language models to generate text with citations , author=. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
2023
-
[12]
Bmj , volume=
GRADE: an emerging consensus on rating quality of evidence and strength of recommendations , author=. Bmj , volume=. 2008 , publisher=
2008
-
[13]
Nucleic acids research , volume=
ChEBI in 2016: Improved services and an expanding collection of metabolites , author=. Nucleic acids research , volume=. 2016 , publisher=
2016
-
[14]
Drug-induced liver disease , pages=
LiverTox: a website on drug-induced liver injury , author=. Drug-induced liver disease , pages=. 2013 , publisher=
2013
-
[15]
biorxiv , year=
Biomni: A general-purpose biomedical ai agent , author=. biorxiv , year=
-
[16]
European Union International Conference on Harmonisation
Post-approval safety data management: definitions and standards for expedited reporting E2D , author=. European Union International Conference on Harmonisation. International conference on harmonisation of technical requirements for registration of pharmaceuticals for human use , year=
-
[17]
ACM computing surveys , volume=
Survey of hallucination in natural language generation , author=. ACM computing surveys , volume=. 2023 , publisher=
2023
-
[18]
Applied Sciences , volume=
What disease does this patient have? a large-scale open domain question answering dataset from medical exams , author=. Applied Sciences , volume=. 2021 , publisher=
2021
-
[19]
Pubmedqa: A dataset for biomedical research question answering , author=. Proceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP) , pages=
2019
-
[21]
Proceedings of the 2020 conference on empirical methods in natural language processing (EMNLP) , pages=
Dense passage retrieval for open-domain question answering , author=. Proceedings of the 2020 conference on empirical methods in natural language processing (EMNLP) , pages=
2020
-
[22]
Journal of the American Medical Informatics Association , volume=
OpenFDA: an innovative platform providing access to a wealth of FDA's publicly available data , author=. Journal of the American Medical Informatics Association , volume=. 2016 , publisher=
2016
-
[23]
Scientific data , volume=
BioASQ-QA: A manually curated corpus for Biomedical Question Answering , author=. Scientific data , volume=. 2023 , publisher=
2023
-
[24]
Nucleic acids research , volume=
The SIDER database of drugs and side effects , author=. Nucleic acids research , volume=. 2016 , publisher=
2016
-
[25]
biometrics , pages=
The measurement of observer agreement for categorical data , author=. biometrics , pages=. 1977 , publisher=
1977
-
[26]
Advances in neural information processing systems , volume=
Retrieval-augmented generation for knowledge-intensive nlp tasks , author=. Advances in neural information processing systems , volume=
-
[27]
2024 , url=
Liu, Sizhe and Lu, Yizhou and Chen, Siyu and Hu, Xiyang and Zhao, Jieyu and Fu, Tianfan and Zhao, Yue , booktitle=. 2024 , url=
2024
-
[28]
Conference on Language Modeling (COLM) , year=
Aligning with Human Judgement: The Role of Pairwise Preference in Large Language Model Evaluators , author=. Conference on Language Modeling (COLM) , year=
-
[29]
Briefings in bioinformatics , volume=
BioGPT: generative pre-trained transformer for biomedical text generation and mining , author=. Briefings in bioinformatics , volume=. 2022 , publisher=
2022
-
[30]
Proceedings of the 2023 conference on empirical methods in natural language processing , pages=
Selfcheckgpt: Zero-resource black-box hallucination detection for generative large language models , author=. Proceedings of the 2023 conference on empirical methods in natural language processing , pages=
2023
-
[31]
Proceedings of the 58th annual meeting of the association for computational linguistics , pages=
On faithfulness and factuality in abstractive summarization , author=. Proceedings of the 58th annual meeting of the association for computational linguistics , pages=
-
[32]
Nucleic acids research , volume=
ChEMBL: towards direct deposition of bioassay data , author=. Nucleic acids research , volume=. 2019 , publisher=
2019
-
[33]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
Factscore: Fine-grained atomic evaluation of factual precision in long form text generation , author=. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
2023
-
[35]
Nucleic acids research , volume=
The next-generation Open Targets Platform: reimagined, redesigned, rebuilt , author=. Nucleic acids research , volume=. 2023 , publisher=
2023
-
[36]
bmj , volume=
The PRISMA 2020 statement: an updated guideline for reporting systematic reviews , author=. bmj , volume=. 2021 , publisher=
2020
-
[37]
Conference on health, inference, and learning , pages=
Medmcqa: A large-scale multi-subject multi-choice dataset for medical domain question answering , author=. Conference on health, inference, and learning , pages=. 2022 , organization=
2022
-
[38]
Advances in Neural Information Processing Systems , volume=
Llm evaluators recognize and favor their own generations , author=. Advances in Neural Information Processing Systems , volume=
-
[39]
Advances in Neural Information Processing Systems , volume=
Gorilla: Large language model connected with massive apis , author=. Advances in Neural Information Processing Systems , volume=
-
[40]
International Conference on Learning Representations , volume=
Toolllm: Facilitating large language models to master 16000+ real-world apis , author=. International Conference on Learning Representations , volume=
-
[41]
Clinical Pharmacology & Therapeutics , volume=
CPIC: clinical pharmacogenetics implementation consortium of the pharmacogenomics research network , author=. Clinical Pharmacology & Therapeutics , volume=. 2011 , publisher=
2011
-
[42]
Proceedings of the 31st International Conference on Computational Linguistics , pages=
Investigating the factual knowledge boundary of large language models with retrieval augmentation , author=. Proceedings of the 31st International Conference on Computational Linguistics , pages=
-
[43]
Advances in neural information processing systems , volume=
Toolformer: Language models can teach themselves to use tools , author=. Advances in neural information processing systems , volume=
-
[44]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
Medadapter: Efficient test-time adaptation of large language models towards medical reasoning , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
2024
-
[45]
Nature , volume=
Large language models encode clinical knowledge , author=. Nature , volume=. 2023 , publisher=
2023
-
[46]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
The curious case of hallucinatory (un) answerability: Finding truths in the hidden states of over-confident large language models , author=. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
2023
-
[48]
Nucleic acids research , pages=
DrugCentral: online drug compendium , author=. Nucleic acids research , pages=. 2016 , publisher=
2016
-
[51]
Clinical Pharmacology & Therapeutics , volume=
An evidence-based framework for evaluating pharmacogenomics knowledge for personalized medicine , author=. Clinical Pharmacology & Therapeutics , volume=. 2021 , publisher=
2021
-
[52]
Nucleic acids research , volume=
DrugBank 5.0: a major update to the DrugBank database for 2018 , author=. Nucleic acids research , volume=. 2018 , publisher=
2018
-
[54]
Findings of the Association for Computational Linguistics: ACL 2024 , pages=
Benchmarking retrieval-augmented generation for medicine , author=. Findings of the Association for Computational Linguistics: ACL 2024 , pages=
2024
-
[55]
Yao, Shunyu and Zhao, Jeffrey and Yu, Dian and Du, Nan and Shafran, Izhak and Narasimhan, Karthik and Cao, Yuan , booktitle=
-
[56]
Nejm ai , volume=
Almanac---retrieval-augmented language models for clinical medicine , author=. Nejm ai , volume=. 2024 , publisher=
2024
-
[57]
Advances in neural information processing systems , volume=
Judging llm-as-a-judge with mt-bench and chatbot arena , author=. Advances in neural information processing systems , volume=
-
[58]
, author=
Overview of the medical question answering task at TREC 2017 LiveQA. , author=. TREC , pages=
2017
-
[59]
Proceedings of the 2023 conference on empirical methods in natural language processing , pages=
G-eval: NLG evaluation using gpt-4 with better human alignment , author=. Proceedings of the 2023 conference on empirical methods in natural language processing , pages=
2023
-
[60]
Introducing Deep Research , howpublished =
-
[61]
Asma Ben Abacha, Eugene Agichtein, Yuval Pinter, and Dina Demner-Fushman. 2017. Overview of the medical question answering task at trec 2017 liveqa. In TREC, pages 1--12
2017
-
[62]
Akari Asai, Zeqiu Wu, Yizhong Wang, Avi Sil, and Hannaneh Hajishirzi. 2024. Self-rag: Learning to retrieve, generate, and critique through self-reflection. In International conference on learning representations, volume 2024, pages 9112--9141
2024
-
[63]
Artem Bobrov, Domantas Saltenis, Zhaoyue Sun, Gabriele Pergola, and Yulan He. 2024. Drugwatch: A comprehensive multi-source data visualisation platform for drug safety information. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 3: System Demonstrations), pages 180--189
2024
-
[64]
Adam S Brown and Chirag J Patel. 2017. A standard database for drug repositioning. Scientific data, 4(1):170029
2017
-
[65]
Jacob Cohen. 1960. A coefficient of agreement for nominal scales. Educational and psychological measurement, 20(1):37--46
1960
-
[66]
Kelsy C Cotto, Alex H Wagner, Yang-Yang Feng, Susanna Kiwala, Adam C Coffman, Gregory Spies, Alex Wollam, Nicholas C Spies, Obi L Griffith, and Malachi Griffith. 2018. Dgidb 3.0: a redesign and expansion of the drug--gene interaction database. Nucleic acids research, 46(D1):D1068--D1073
2018
-
[67]
Wenchang Duan, Yaoliang Yu, Jiwan He, and Yi Shi. 2026. Adaptive context length optimization with low-frequency truncation for multi-agent reinforcement learning. Advances in Neural Information Processing Systems, 38:97685--97716
2026
-
[68]
Shanghua Gao, Ada Fang, Yepeng Huang, Valentina Giunchiglia, Ayush Noori, Jonathan Richard Schwarz, Yasha Ektefaie, Jovana Kondic, and Marinka Zitnik. 2024. Empowering biomedical discovery with ai agents. Cell, 187(22):6125--6151
2024
- [69]
-
[70]
Tianyu Gao, Howard Yen, Jiatong Yu, and Danqi Chen. 2023. Enabling large language models to generate text with citations. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 6465--6488
2023
-
[71]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, and 1 others. 2024. The llama 3 herd of models. arXiv preprint arXiv:2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[72]
ICH Harmonised Tripartite Guideline. 2003. Post-approval safety data management: definitions and standards for expedited reporting e2d. In European Union International Conference on Harmonisation. International conference on harmonisation of technical requirements for registration of pharmaceuticals for human use
2003
-
[73]
Gordon H Guyatt, Andrew D Oxman, Gunn E Vist, Regina Kunz, Yngve Falck-Ytter, Pablo Alonso-Coello, and Holger J Sch \"u nemann. 2008. Grade: an emerging consensus on rating quality of evidence and strength of recommendations. Bmj, 336(7650):924--926
2008
-
[74]
Janna Hastings, Gareth Owen, Adriano Dekker, Marcus Ennis, Namrata Kale, Venkatesh Muthukrishnan, Steve Turner, Neil Swainston, Pedro Mendes, and Christoph Steinbeck. 2016. Chebi in 2016: Improved services and an expanding collection of metabolites. Nucleic acids research, 44(D1):D1214--D1219
2016
-
[75]
Jay H Hoofnagle. 2013. Livertox: a website on drug-induced liver injury. In Drug-induced liver disease, pages 725--732. Elsevier
2013
-
[76]
Kexin Huang, Serena Zhang, Hanchen Wang, Yuanhao Qu, Yingzhou Lu, Yusuf Roohani, Ryan Li, Lin Qiu, Gavin Li, Junze Zhang, and 1 others. 2025. Biomni: A general-purpose biomedical ai agent. biorxiv
2025
-
[77]
Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yan Xu, Etsuko Ishii, Ye Jin Bang, Andrea Madotto, and Pascale Fung. 2023. Survey of hallucination in natural language generation. ACM computing surveys, 55(12):1--38
2023
-
[78]
Di Jin, Eileen Pan, Nassim Oufattole, Wei-Hung Weng, Hanyi Fang, and Peter Szolovits. 2021. What disease does this patient have? a large-scale open domain question answering dataset from medical exams. Applied Sciences, 11(14):6421
2021
-
[79]
Qiao Jin, Bhuwan Dhingra, Zhengping Liu, William Cohen, and Xinghua Lu. 2019. Pubmedqa: A dataset for biomedical research question answering. In Proceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP), pages 2567--2577
2019
-
[80]
Saurav Kadavath, Tom Conerly, Amanda Askell, Tom Henighan, Dawn Drain, Ethan Perez, Nicholas Schiefer, Zac Hatfield-Dodds, Nova DasSarma, Eli Tran-Johnson, and 1 others. 2022. Language models (mostly) know what they know. arXiv preprint arXiv:2207.05221
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[81]
Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. 2020. Dense passage retrieval for open-domain question answering. In Proceedings of the 2020 conference on empirical methods in natural language processing (EMNLP), pages 6769--6781
2020
-
[82]
Taha A Kass-Hout, Zhiheng Xu, Matthew Mohebbi, Hans Nelsen, Adam Baker, Jonathan Levine, Elaine Johanson, and Roselie A Bright. 2016. Openfda: an innovative platform providing access to a wealth of fda's publicly available data. Journal of the American Medical Informatics Association, 23(3):596--600
2016
-
[83]
Anastasia Krithara, Anastasios Nentidis, Konstantinos Bougiatiotis, and Georgios Paliouras. 2023. Bioasq-qa: A manually curated corpus for biomedical question answering. Scientific data, 10(1):170
2023
-
[84]
Michael Kuhn, Ivica Letunic, Lars Juhl Jensen, and Peer Bork. 2016. The sider database of drugs and side effects. Nucleic acids research, 44(D1):D1075--D1079
2016
-
[85]
J Richard Landis and Gary G Koch. 1977. The measurement of observer agreement for categorical data. biometrics, pages 159--174
1977
-
[86]
u ttler, Mike Lewis, Wen-tau Yih, Tim Rockt \
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich K \"u ttler, Mike Lewis, Wen-tau Yih, Tim Rockt \"a schel, and 1 others. 2020. Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in neural information processing systems, 33:9459--9474
2020
-
[87]
Sizhe Liu, Yizhou Lu, Siyu Chen, Xiyang Hu, Jieyu Zhao, Tianfan Fu, and Yue Zhao. 2024 a . https://openreview.net/forum?id=YWzIw7yYnR DrugAgent : Automating AI -aided drug discovery programming through LLM multi-agent collaboration . In 2nd AI4Research Workshop: Towards a Knowledge-grounded Scientific Research Lifecycle
2024
-
[88]
Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang, Ruochen Xu, and Chenguang Zhu. 2023. G-eval: Nlg evaluation using gpt-4 with better human alignment. In Proceedings of the 2023 conference on empirical methods in natural language processing, pages 2511--2522
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.