Peacemaker at ATE-IT: Automatic term extraction from Italian text for waste management data using encoder model
Pith reviewed 2026-06-28 16:59 UTC · model grok-4.3
The pith
Fine-tuned encoder extracts terms from Italian waste texts with balanced performance
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Our proposed approach achieves consistent and balanced performance compared to other teams by utilizing fine-tuning extraction strategies that can run on a small amount of computational resources, evaluated using both type-level and micro-level measures of precision, recall, and F1-score.
What carries the argument
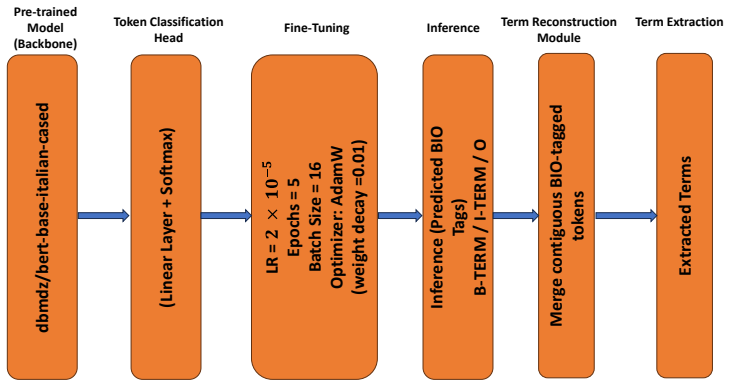
Fine-tuned encoder model that identifies terms in Italian waste management texts through extraction strategies optimized for low resources.
If this is right
- The method can serve as a starting point for low-resource term extraction models.
- Performance remains interpretable while allowing future model expansions.
- It addresses challenges in extracting multi-word expressions in specific domains with limited data.
Where Pith is reading between the lines
- Applying similar fine-tuning to other languages with limited data could yield comparable results in specialized domains.
- The method's simplicity allows easy adaptation for real-time data processing in environmental management systems.
- Further testing on varied domains might reveal how well the balanced performance holds beyond waste management.
Load-bearing premise
The limited number of annotated documents available for training is sufficient to produce generalizable term extraction performance on the target domain and language.
What would settle it
Evaluating the model on a new set of Italian waste management documents and observing if the F1 scores drop significantly below the reported balanced performance.
Figures

read the original abstract
The development of automatic term extraction has become increasingly important in modern technology. Automatic term extraction can be found in virtually every search engine that is currently available to users. Recent advancements have provided promising results for the extraction of automatic terms; however, accurate labeling is difficult because of several factors, such as the limited number of annotated documents available for training and the complexity of extracting multi-word expressions due to shifts in the domain. In this paper, we will present a low-cost and interpretable method of automatic term extraction, developed specifically for Task A of the ATE Shared Task. This new method utilizes fine-tuning extraction strategies that can run on a small amount of computational resources. We evaluated our automated system using both type-level and micro-level measures of precision, recall, and F1-score to measure both complementary aspects of the extraction performance. According to the experimental results, our proposed approach achieves consistent and balanced performance compared to other teams. Even though the technique itself is relatively straightforward, it serves as a good starting point for low-resource models. Overall, the findings point toward the possibility of significant future advancements (in model expansion) with higher-level performance still able to retain their ability to be interpreted.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a fine-tuned encoder model for automatic term extraction (ATE) from Italian texts in the waste management domain, developed for Task A of the ATE Shared Task. The approach is described as low-cost and interpretable, relying on fine-tuning strategies that operate with limited computational resources. The central claim is that the system achieves consistent and balanced performance on type-level and micro-level precision, recall, and F1-score measures relative to other participating teams, positioning the method as a viable starting point for low-resource ATE despite challenges such as limited annotated documents and multi-word expression complexity.
Significance. If the performance claims are substantiated with quantitative evidence, the work could provide a practical, resource-efficient baseline for domain-specific term extraction in under-resourced languages and specialized technical fields. The emphasis on low computational cost and interpretability aligns with needs in applied NLP settings. However, the absence of dataset statistics, model details, numerical results, or comparisons in the current manuscript substantially limits assessment of its potential impact or reproducibility.
major comments (2)
- [Abstract] Abstract: The assertion that 'our proposed approach achieves consistent and balanced performance compared to other teams' is presented without any numerical F1 scores, precision/recall values, baseline comparisons, error analysis, or details on training data size and fine-tuning procedure. This directly undermines verification of the claim that limited annotations produce generalizable results rather than overfitting, which is load-bearing for the paper's main contribution.
- [Abstract] Abstract: The manuscript identifies 'the limited number of annotated documents available for training' as a core difficulty but supplies no actual dataset sizes, statistics on the training/validation/test splits, or ablation results to demonstrate that the fine-tuned encoder generalizes on the target domain and language.
minor comments (1)
- [Abstract] Abstract: The final sentence ('higher-level performance still able to retain their ability to be interpreted') contains a grammatical error and unclear phrasing that should be revised for precision.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We agree that the abstract requires additional quantitative details and dataset information to substantiate the performance claims and address concerns about generalization. We will revise the abstract and, where appropriate, the manuscript body to include these elements, improving clarity and verifiability without altering the core methodology or results.
read point-by-point responses
-
Referee: [Abstract] Abstract: The assertion that 'our proposed approach achieves consistent and balanced performance compared to other teams' is presented without any numerical F1 scores, precision/recall values, baseline comparisons, error analysis, or details on training data size and fine-tuning procedure. This directly undermines verification of the claim that limited annotations produce generalizable results rather than overfitting, which is load-bearing for the paper's main contribution.
Authors: We agree that the abstract lacks the specific numerical evidence needed to support the claim. In the revised manuscript, we will add the type-level and micro-level precision, recall, and F1 scores achieved by our model, along with direct comparisons to other participating teams in the shared task. We will also include a brief description of the training data size and the fine-tuning procedure (including hyperparameters and computational resources used) to allow readers to assess potential overfitting versus generalization. This addresses the load-bearing nature of the claim. revision: yes
-
Referee: [Abstract] Abstract: The manuscript identifies 'the limited number of annotated documents available for training' as a core difficulty but supplies no actual dataset sizes, statistics on the training/validation/test splits, or ablation results to demonstrate that the fine-tuned encoder generalizes on the target domain and language.
Authors: We concur that explicit dataset statistics are necessary. The revised version will report the total number of annotated documents, the sizes of the training/validation/test splits, and basic statistics such as the proportion of single-word versus multi-word terms. If space permits, we will add a short note on any internal validation steps taken to monitor generalization; otherwise, we will clarify that the evaluation relies on the shared task's held-out test set. This will directly respond to the concern about demonstrating generalization under limited annotations. revision: yes
Circularity Check
No circularity: empirical evaluation on external shared-task benchmark is independent
full rationale
The paper describes a fine-tuned encoder model for term extraction evaluated via type- and micro-level F1 on the ATE Shared Task benchmark. No equations, parameter-fitting steps presented as predictions, self-citations, or ansatzes appear in the provided text. The central performance claim rests on comparison to other teams' results on the same external data rather than any internal reduction to the paper's own inputs or definitions. The low-resource framing is an assumption about data sufficiency but does not create a self-definitional or fitted-input loop.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Banerjee, B
S. Banerjee, B. R. Chakravarthi, J. P. McCrae, Large language models for few-shot automatic term extraction, in: A. Rapp, L. Di Caro, F. Meziane, V. Sugumaran (Eds.), Natural Language Processing and Information Systems, Springer Nature Switzerland, Cham, 2024, pp. 137–150
2024
-
[2]
G. M. Di Nunzio, S. Marchesin, G. Silvello, A systematic review of automatic term extraction: What happened in 2022?, Digital Scholarship in the Humanities 38 (2023) i41–i47. URL: https: //doi.org/10.1093/llc/fqad030. doi:10.1093/llc/fqad030
-
[3]
Heylen, D
K. Heylen, D. D. Hertog, Automatic term extraction, 2014. URL: https://api.semanticscholar.org/ CorpusID:184348418
2014
-
[4]
C. Lang, L. Wachowiak, B. Heinisch, D. Gromann, Transforming term extraction: Transformer- based approaches to multilingual term extraction across domains, in: C. Zong, F. Xia, W. Li, R. Navigli (Eds.), Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, Association for Computational Linguistics, Online, 2021, pp. 3607–3620. URL: h...
-
[5]
Arcan, M
M. Arcan, M. Turchi, S. Topelli, P. Buitelaar, Enhancing statistical machine translation with bilingual terminology in a CAT environment, in: Y. Al-Onaizan, M. Simard (Eds.), Proceedings of the 11th Conference of the Association for Machine Translation in the Americas: MT Researchers Track, Association for Machine Translation in the Americas, Vancouver, C...
2014
-
[6]
QasemiZadeh, A.-K
B. QasemiZadeh, A.-K. Schumann, The ACL RD-TEC 2.0: A language resource for evaluating term extraction and entity recognition methods, in: N. Calzolari, K. Choukri, T. Declerck, S. Goggi, M. Grobelnik, B. Maegaard, J. Mariani, H. Mazo, A. Moreno, J. Odijk, S. Piperidis (Eds.), Proceedings of the Tenth International Conference on Language Resources and Eva...
2016
-
[7]
Scansani, L
R. Scansani, L. Bentivogli, S. Bernardini, A. Ferraresi, MAGMATic: A multi-domain academic gold standard with manual annotation of terminology for machine translation evaluation, in: M. Forcada, A. Way, B. Haddow, R. Sennrich (Eds.), Proceedings of Machine Translation Summit XVII: Research Track, European Association for Machine Translation, Dublin, Irela...
2019
-
[8]
A. Rigouts Terryn, V. Hoste, E. Lefever, In no uncertain terms: a dataset for monolingual and multilingual automatic term extraction from comparable corpora, Language Resources and Evaluation 54 (2020) 385–418. URL: https://doi.org/10.1007/s10579-019-09453-9. doi: 10.1007/ s10579-019-09453-9
-
[9]
Tiwari, S
P. Tiwari, S. Uprety, S. Dehdashti, M. S. Hossain, TermInformer: unsupervised term mining and analysis in biomedical literature, Neural Comput. Appl. 37 (2020) 1–14
2020
- [10]
-
[11]
Improving Term Extraction with Terminological Resources
S. Aubin, T. Hamon, Improving term extraction with terminological resources, 2006. URL: https: //arxiv.org/abs/cs/0609019.arXiv:cs/0609019
work page internal anchor Pith review Pith/arXiv arXiv 2006
-
[12]
J. Vivaldi, H. Rodríguez, Evaluation of terms and term extraction systems: A practical approach, Terminology 13 (2007) 225–248. doi:10.1075/term.13.2.06viv
-
[13]
Schmidt, A
L. Schmidt, A. N. Finnerty Mutlu, R. Elmore, B. K. Olorisade, J. Thomas, J. P. T. Higgins, Data extraction methods for systematic review (semi)automation: Update of a living systematic review, F1000Res. 10 (2021) 401
2021
-
[14]
E. E. Milios, Y. Zhang, B. He, L. Dong, Automatic term extraction and document similarity in special text corpora, 2003. URL: https://api.semanticscholar.org/CorpusID:3128871
2003
-
[15]
Zhang, J
Z. Zhang, J. Iria, C. Brewster, F. Ciravegna, A comparative evaluation of term recognition al- gorithms, in: N. Calzolari, K. Choukri, B. Maegaard, J. Mariani, J. Odijk, S. Piperidis, D. Tapias (Eds.), Proceedings of the Sixth International Conference on Language Resources and Evaluation (LREC’08), European Language Resources Association (ELRA), Marrakech...
2008
-
[16]
D. Bourigault, C. Jacquemin, Term extraction + term clustering: an integrated platform for computer-aided terminology, in: Proceedings of the Ninth Conference on European Chapter of the Association for Computational Linguistics, EACL ’99, Association for Computational Linguistics, USA, 1999, p. 15–22. URL: https://doi.org/10.3115/977035.977039. doi:10.311...
-
[17]
L.-F. Chien, Pat-tree-based keyword extraction for chinese information retrieval, SIGIR Forum 31 (1997) 50–58. URL: https://doi.org/10.1145/278459.258534. doi:10.1145/278459.258534
-
[18]
E. Morin, C. Jacquemin, Projecting corpus-based semantic links on a thesaurus, in: Proceedings of the 37th Annual Meeting of the Association for Computational Linguistics on Computational Linguistics, ACL ’99, Association for Computational Linguistics, USA, 1999, p. 389–396. URL: https://doi.org/10.3115/1034678.1034739. doi:10.3115/1034678.1034739
-
[19]
N. Kaushik, N. Chatterjee, Automatic relationship extraction from agricultural text for ontol- ogy construction, Information Processing in Agriculture 5 (2018) 60–73. URL: https://www. sciencedirect.com/science/article/pii/S2214317317300227. doi:https://doi.org/10.1016/j. inpa.2017.11.003
work page doi:10.1016/j 2018
-
[20]
Cirillo, G
N. Cirillo, G. M. Di Nunzio, F. Vezzani, Ate-it at evalita 2026: Overview of the automatic term extraction italian testbed task, in: Proceedings of the Ninth Evaluation Campaign of Natural Language Processing and Speech Tools for Italian. Final Workshop (EVALITA 2026), CEUR.org, Bari, Italy, 2026
2026
-
[21]
M. Röder, R. Usbeck, A.-C. N. Ngomo, Gerbil – benchmarking named en- tity recognition and linking consistently, Semantic Web 9 (2018) 605–625. URL: https://journals.sagepub.com/doi/abs/10.3233/SW-170286. doi: 10.3233/SW-170286. arXiv:https://journals.sagepub.com/doi/pdf/10.3233/SW-170286
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.