Fast Generalization after Interpolation via Critically Damped Momentum Optimization
Pith reviewed 2026-06-28 15:54 UTC · model grok-4.3
The pith
GROKtimizer switches to critically damped momentum after interpolation to find low-norm solutions with quadratic speedup over gradient descent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
GROKtimizer combines rapid convergence to interpolation with Critically Damped Momentum-based post-interpolation norm minimization, offering a natural solution for selecting low-norm interpolating solutions. Under a local quadratic model of the post-interpolation basin, GROKtimizer provides a quadratic speedup over classical gradient descent, with provable optimality among first-order optimizers.
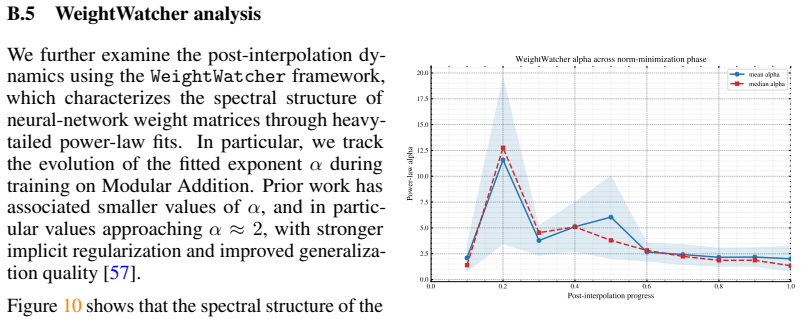
What carries the argument
Critically Damped Momentum (CDM) applied after interpolation for norm minimization within a biphasic schedule.
If this is right
- Post-interpolation dynamics determine which interpolating solution is reached and thus control generalization.
- The biphasic schedule separates loss minimization from subsequent norm minimization.
- Quadratic speedup holds and optimality among first-order methods is provable under the local quadratic model.
- Reconciliation with the flat-minima hypothesis occurs by focusing on dynamics after the interpolation threshold.
Where Pith is reading between the lines
- Explicit detection of the interpolation point could let other first-order methods adopt similar phase switches.
- The quadratic speedup may serve as a benchmark for testing whether real loss surfaces near interpolation are locally quadratic.
- The method suggests that generalization in overparameterized models depends more on post-interpolation behavior than on the path taken before interpolation.
Load-bearing premise
The post-interpolation loss surface can be modeled as a local quadratic basin whose minimum is the low-norm solution that generalizes well.
What would settle it
No quadratic speedup or generalization gain appears when GROKtimizer is run against gradient descent on a problem whose post-interpolation basin is exactly quadratic.
Figures

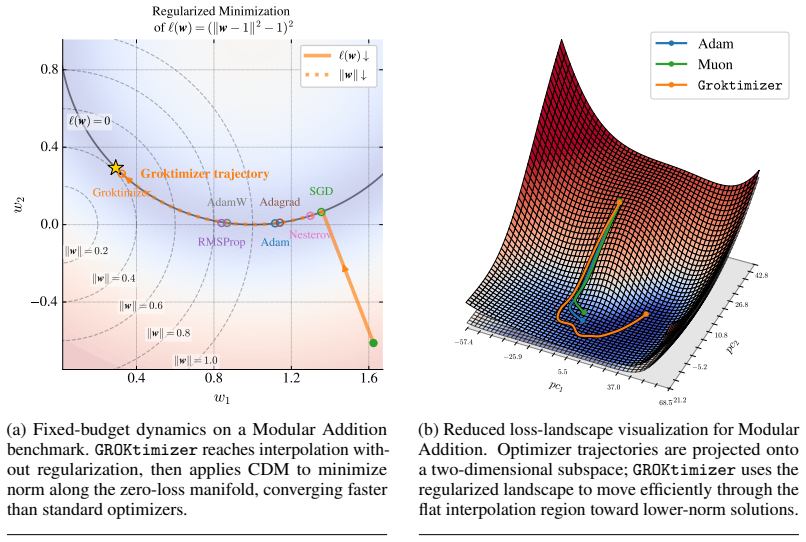
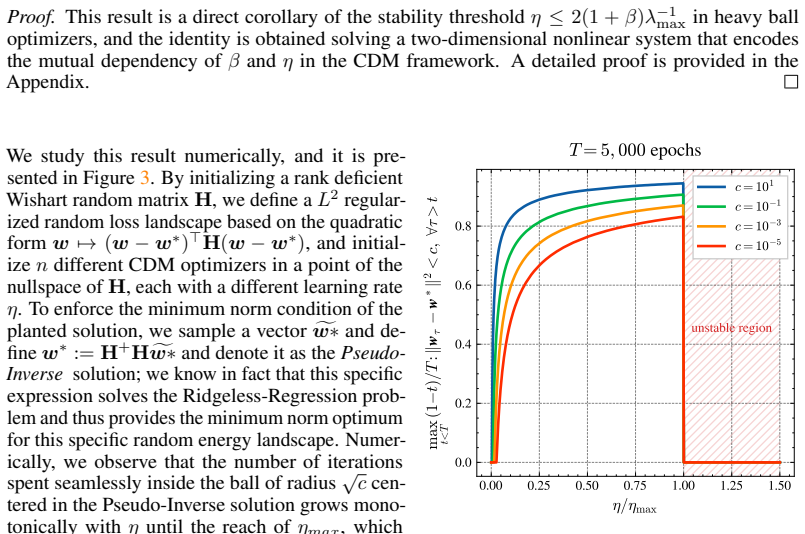
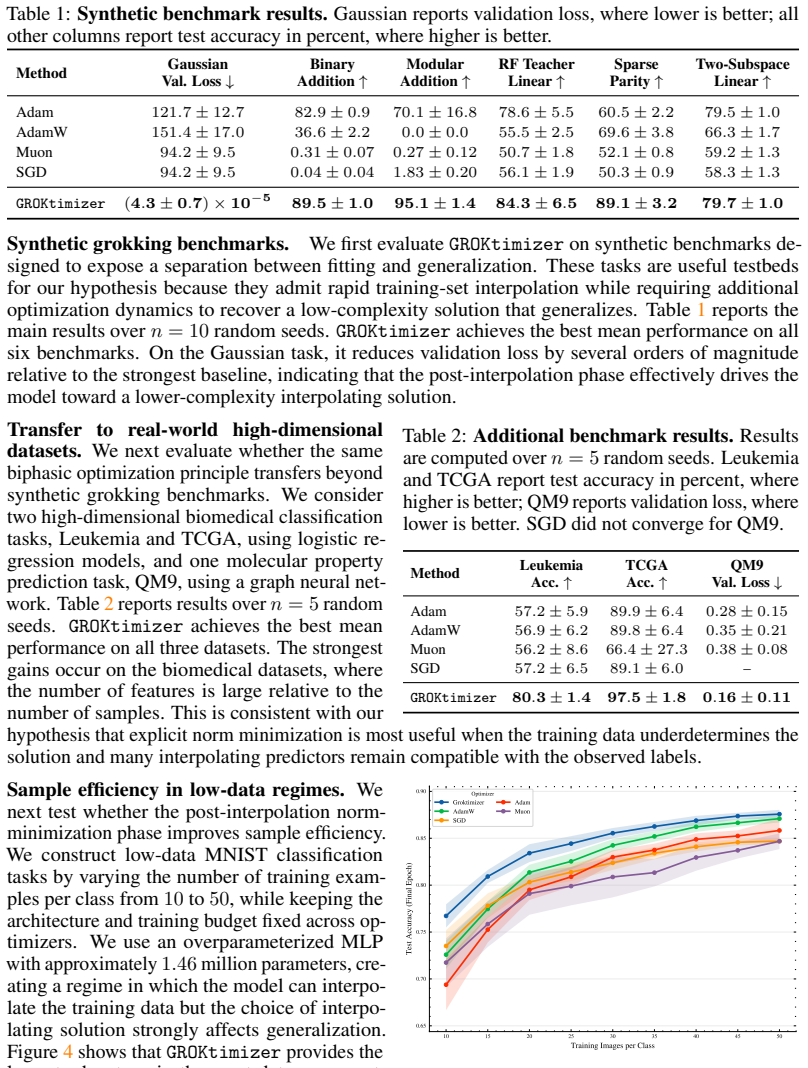
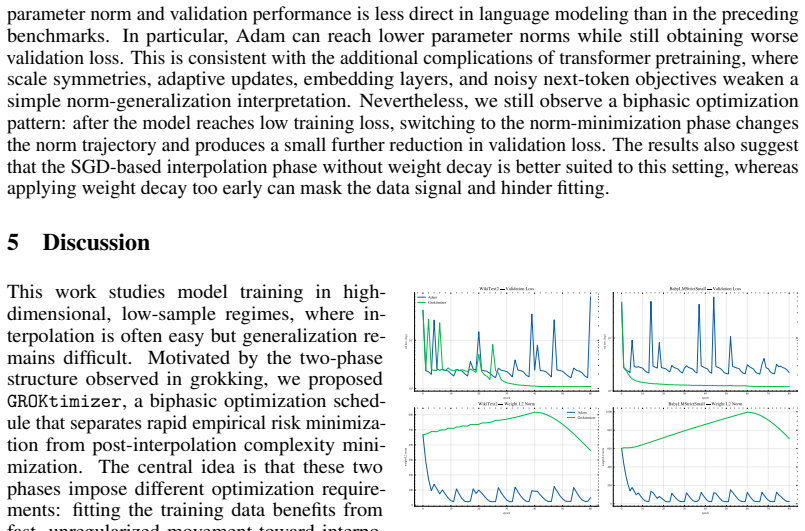
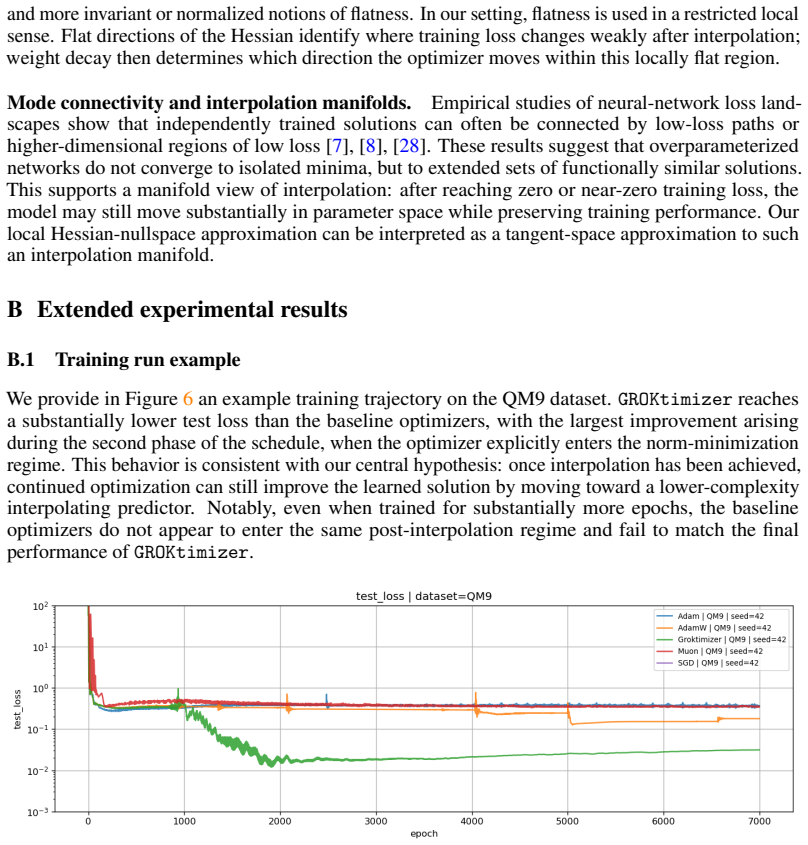
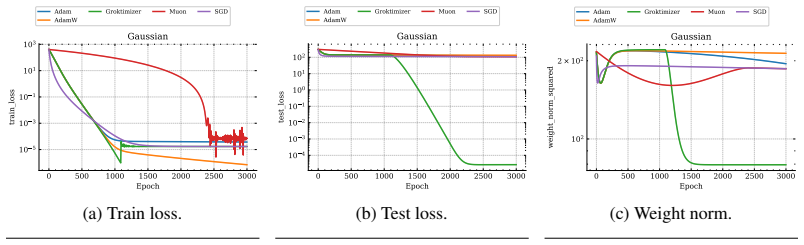
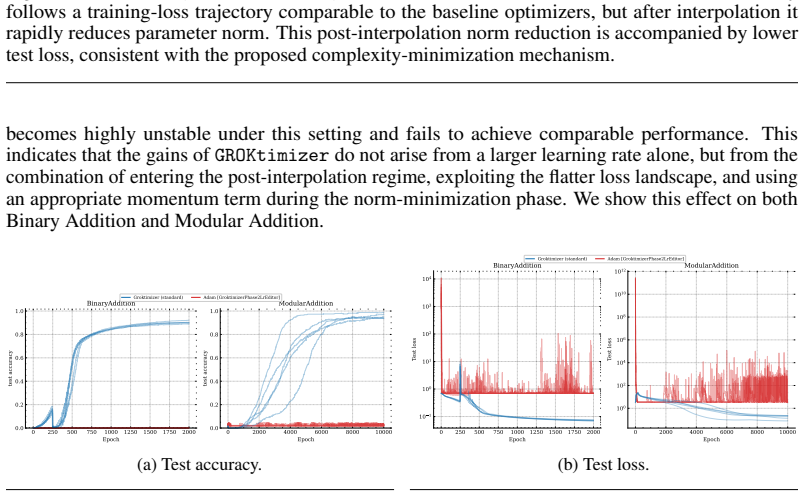
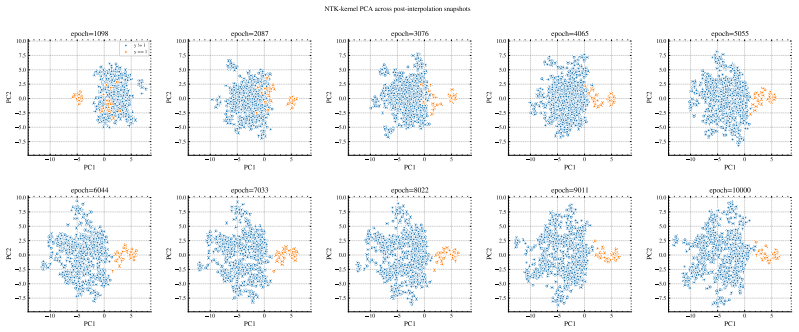
read the original abstract
A central problem in machine learning is that models can achieve near-perfect training performance while generalizing substantially less well to unseen examples. This gap is especially acute in high-dimensional, low-sample regimes, where many interpolating solutions exist and optimization must implicitly select among minima with different generalization properties. Following recent theoretical advances on optimization dynamics near the interpolation threshold, we note that the two-regime structure of risk minimization, with loss minimization followed by complexity minimization, motivates a biphasic optimization schedule. We thus theoretically demonstrate that GROKtimizer, a biphasic strategy that combines rapid convergence to interpolation with Critically Damped Momentum (CDM)-based post-interpolation norm minimization, offers a natural solution for selecting low-norm interpolating solutions. Under a local quadratic model of the post-interpolation basin, GROKtimizer provides a quadratic speedup over classical gradient descent, with provable optimality among first-order optimizers. To showcase the applicability of our method, we evaluate GROKtimizer on several synthetic benchmarks common in the classical grokking literature and on various real-world datasets. Finally, we reconcile our findings with the flat-minima hypothesis, highlighting the importance of post-interpolation dynamics in the construction of high-quality, generalizing models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes GROKtimizer, a biphasic optimizer consisting of rapid convergence to the interpolation threshold followed by Critically Damped Momentum (CDM) for post-interpolation norm minimization. It claims that the two-regime structure of risk minimization motivates this schedule, and that under a local quadratic model of the post-interpolation basin, GROKtimizer yields a quadratic speedup over gradient descent together with provable optimality among first-order methods. The method is evaluated on synthetic grokking benchmarks and real-world datasets, and the results are reconciled with the flat-minima hypothesis.
Significance. If the local quadratic model is shown to be accurate and the derived rates hold, the work would supply both a practical biphasic schedule for selecting generalizing interpolators and a theoretical account of why post-interpolation dynamics matter, strengthening the link between optimization trajectories and generalization in overparameterized regimes.
major comments (2)
- [theoretical analysis (post-interpolation phase)] Abstract and theoretical claims section: the quadratic speedup and optimality statements are obtained by solving the dynamics under an explicit local quadratic model whose minimum is identified with the low-norm generalizing solution; no a-priori bound on the Taylor remainder or empirical verification that cubic or higher terms remain negligible throughout the CDM phase is supplied, so the claimed rates do not transfer if the loss deviates from quadratic.
- [experimental evaluation] Empirical section: the reported experiments on synthetic and real-world data do not include direct checks (e.g., curvature monitoring or comparison against non-quadratic models) that would confirm the quadratic approximation remains valid on the evaluated benchmarks, leaving the connection between theory and observed generalization gains unverified.
minor comments (2)
- [method description] Notation for the CDM update rule and the biphasic switching criterion should be defined explicitly with equation numbers rather than described only in prose.
- [discussion] The reconciliation paragraph with the flat-minima hypothesis would benefit from a short quantitative comparison (e.g., Hessian trace or sharpness metrics) between GROKtimizer and baseline trajectories.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the assumptions underlying our theoretical analysis and the need for stronger empirical validation of the local quadratic model. We address each major comment below, indicating the revisions we plan to incorporate.
read point-by-point responses
-
Referee: [theoretical analysis (post-interpolation phase)] Abstract and theoretical claims section: the quadratic speedup and optimality statements are obtained by solving the dynamics under an explicit local quadratic model whose minimum is identified with the low-norm generalizing solution; no a-priori bound on the Taylor remainder or empirical verification that cubic or higher terms remain negligible throughout the CDM phase is supplied, so the claimed rates do not transfer if the loss deviates from quadratic.
Authors: The quadratic speedup and optimality results are derived explicitly under the local quadratic model of the post-interpolation basin, as stated in the abstract and theoretical section. This is a deliberate modeling choice that permits closed-form dynamics and a proof of optimality among first-order methods within the model. We agree that the rates are conditional on the approximation and do not automatically extend to losses with significant higher-order terms. A general a-priori bound on the Taylor remainder would require additional global assumptions on the loss that lie outside the local analysis. In revision we will add a clarifying paragraph in the theoretical claims section that (i) reiterates the modeling assumptions, (ii) states the conditions under which higher-order terms are expected to remain negligible, and (iii) notes the conditional nature of the claimed rates. revision: partial
-
Referee: [experimental evaluation] Empirical section: the reported experiments on synthetic and real-world data do not include direct checks (e.g., curvature monitoring or comparison against non-quadratic models) that would confirm the quadratic approximation remains valid on the evaluated benchmarks, leaving the connection between theory and observed generalization gains unverified.
Authors: We agree that explicit verification would strengthen the link between the local quadratic analysis and the observed generalization improvements. In the revised manuscript we will augment the experimental section with direct checks: for both the synthetic grokking benchmarks and selected real-world datasets we will report curvature diagnostics (finite-difference estimates of the Hessian trace and leading eigenvalues) sampled throughout the CDM phase. These additions will confirm that the quadratic regime is a reasonable local description on the evaluated tasks and will make the connection to the theoretical rates more transparent. revision: yes
Circularity Check
No significant circularity; claims derived conditionally from explicit quadratic model assumption
full rationale
The paper's central claims of quadratic speedup and optimality are explicitly conditioned on an upfront modeling assumption of a local quadratic post-interpolation basin, as stated in the abstract. This assumption supplies the dynamics for the closed-form analysis rather than being fitted to or redefined by the derived results. No self-citations, self-definitional structures, fitted parameters renamed as predictions, or ansatzes smuggled via prior work appear in the provided text. The derivation chain is therefore self-contained: the speedup follows mathematically from the stated quadratic model without reducing to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Risk minimization exhibits a two-regime structure consisting of loss minimization followed by complexity minimization.
- domain assumption The post-interpolation loss surface admits a local quadratic model whose basin minimum corresponds to the desired low-norm generalizing solution.
invented entities (1)
-
GROKtimizer
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Understanding deep learning requires rethinking generalization,
C. Zhang, S. Bengio, M. Hardt, B. Recht, and O. Vinyals, “Understanding deep learning requires rethinking generalization,” inInternational Conference on Learning Representations, 2017
2017
-
[2]
Dealing with dimensionality: The application of machine learning to multi-omics data,
D. Feldner-Busztin et al., “Dealing with dimensionality: The application of machine learning to multi-omics data,”Bioinformatics, vol. 39, no. 2, J. Wren, Ed., Jan. 2023,ISSN: 1367-4811
2023
-
[3]
Scalable and accurate deep learning with electronic health records,
A. Rajkomar et al., “Scalable and accurate deep learning with electronic health records,”npj Digital Medicine, vol. 1, no. 1, May 2018,ISSN: 2398-6352
2018
-
[4]
Sparse signals in the cross-section of returns,
A. Chinco, A. D. Clark-Joseph, and M. Ye, “Sparse signals in the cross-section of returns,” The Journal of Finance, vol. 74, no. 1, pp. 449–492, Nov. 2018,ISSN: 1540-6261
2018
-
[5]
Small data machine learning in materials science,
P. Xu, X. Ji, M. Li, and W. Lu, “Small data machine learning in materials science,”npj Computational Materials, vol. 9, no. 1, Mar. 2023,ISSN: 2057-3960
2023
-
[6]
Machine learning methods for small data challenges in molecular science,
B. Dou et al., “Machine learning methods for small data challenges in molecular science,” Chemical Reviews, vol. 123, no. 13, pp. 8736–8780, 2023,ISSN: 1520-6890
2023
-
[7]
Loss surfaces, mode connectivity, and fast ensembling of dnns,
T. Garipov, P. Izmailov, D. Podoprikhin, D. Vetrov, and A. G. Wilson, “Loss surfaces, mode connectivity, and fast ensembling of dnns,” inAdvances in Neural Information Processing Systems, S. Bengio, H. Wallach, H. Larochelle, K. Grauman, N. Cesa-Bianchi, and R. Garnett, Eds., vol. 31, Curran Associates, Inc., 2018
2018
-
[8]
Essentially no barriers in neural network energy landscape,
F. Draxler, K. Veschgini, M. Salmhofer, and F. Hamprecht, “Essentially no barriers in neural network energy landscape,” inInternational conference on machine learning, PMLR, 2018, pp. 1309–1318
2018
-
[9]
Reconciling modern machine-learning practice and the classical bias–variance trade-off,
M. Belkin, D. Hsu, S. Ma, and S. Mandal, “Reconciling modern machine-learning practice and the classical bias–variance trade-off,”Proceedings of the National Academy of Sciences, vol. 116, no. 32, pp. 15 849–15 854, 2019,ISSN: 1091-6490
2019
-
[10]
The implicit bias of gradient descent on separable data,
D. Soudry, E. Hoffer, M. S. Nacson, S. Gunasekar, and N. Srebro, “The implicit bias of gradient descent on separable data,”Journal of Machine Learning Research, vol. 19, no. 70, pp. 1–57, 2018
2018
-
[11]
A simple weight decay can improve generalization,
A. Krogh and J. Hertz, “A simple weight decay can improve generalization,” inAdvances in Neural Information Processing Systems, J. Moody, S. Hanson, and R. Lippmann, Eds., vol. 4, Morgan-Kaufmann, 1991
1991
-
[12]
C. E. Rasmussen and C. K. I. Williams,Gaussian Processes for Machine Learning. The MIT Press, Nov. 2005,ISBN: 9780262256834
2005
-
[13]
Statistical inference, occam’s razor, and statistical mechanics on the space of probability distributions,
V . Balasubramanian, “Statistical inference, occam’s razor, and statistical mechanics on the space of probability distributions,”Neural computation, vol. 9, no. 2, pp. 349–368, 1997
1997
-
[14]
Surprises in high-dimensional ridgeless least squares interpolation,
T. Hastie, A. Montanari, S. Rosset, and R. J. Tibshirani, “Surprises in high-dimensional ridgeless least squares interpolation,”Annals of statistics, vol. 50, no. 2, p. 949, 2022
2022
-
[15]
Power, Y
A. Power, Y . Burda, H. Edwards, I. Babuschkin, and V . Misra,Grokking: Generalization beyond overfitting on small algorithmic datasets, 2022
2022
-
[16]
Mechanisms of grokking: Loss landscape separation and negative learning momentum,
T. Kumar et al., “Mechanisms of grokking: Loss landscape separation and negative learning momentum,”arXiv preprint, 2023
2023
-
[17]
Towards understanding grokking: An effective theory of representation learning,
Z. Liu, O. Kitouni, N. S. Nolte, E. Michaud, M. Tegmark, and M. Williams, “Towards understanding grokking: An effective theory of representation learning,”Advances in Neural Information Processing Systems, vol. 35, pp. 34 651–34 663, 2022
2022
-
[18]
Not all explanations for deep learning phenomena are equally valuable,
A. Jeffares and M. van der Schaar, “Not all explanations for deep learning phenomena are equally valuable,”arXiv preprint arXiv:2506.23286, 2025
-
[19]
Flat minima,
S. Hochreiter and J. Schmidhuber, “Flat minima,”Neural Computation, vol. 9, no. 1, pp. 1–42, Jan. 1997,ISSN: 1530-888X
1997
-
[20]
Flat minima,
S. Hochreiter and J. Schmidhuber, “Flat minima,”Neural computation, vol. 9, no. 1, pp. 1–42, 1997
1997
-
[21]
Neural tangent kernel: Convergence and generalization in neural networks,
A. Jacot, F. Gabriel, and C. Hongler, “Neural tangent kernel: Convergence and generalization in neural networks,”Advances in neural information processing systems, vol. 31, 2018
2018
-
[22]
Benign overfitting in linear regression,
P. L. Bartlett, P. M. Long, G. Lugosi, and A. Tsigler, “Benign overfitting in linear regression,” Proceedings of the National Academy of Sciences, vol. 117, no. 48, pp. 30 063–30 070, 2020
2020
-
[23]
Musat,The geometry of grokking: Norm minimization on the zero-loss manifold, 2025
T. Musat,The geometry of grokking: Norm minimization on the zero-loss manifold, 2025. 10
2025
-
[24]
A theoretical framework for grokking: Interpola- tion followed by riemannian norm minimisation,
E. Boursier, S. Pesme, and R.-A. Dragomir, “A theoretical framework for grokking: Interpola- tion followed by riemannian norm minimisation,” inThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026
2026
-
[25]
Wide neural networks of any depth evolve as linear models under gradient descent,
J. Lee et al., “Wide neural networks of any depth evolve as linear models under gradient descent,”Advances in neural information processing systems, vol. 32, 2019
2019
-
[26]
A convergence theory for deep learning via over- parameterization,
Z. Allen-Zhu, Y . Li, and Z. Song, “A convergence theory for deep learning via over- parameterization,” inInternational conference on machine learning, PMLR, 2019, pp. 242– 252
2019
-
[27]
Loss surfaces, mode connectivity, and fast ensembling of dnns,
T. Garipov, P. Izmailov, D. Podoprikhin, D. P. Vetrov, and A. G. Wilson, “Loss surfaces, mode connectivity, and fast ensembling of dnns,”Advances in neural information processing systems, vol. 31, 2018
2018
-
[28]
Loss surface simplexes for mode connecting volumes and fast ensembling,
G. Benton, W. Maddox, S. Lotfi, and A. G. G. Wilson, “Loss surface simplexes for mode connecting volumes and fast ensembling,” inInternational Conference on Machine Learning, PMLR, 2021, pp. 769–779
2021
-
[29]
A method for solving the convex programming problem with convergence rate O(1/k2),
Y . Nesterov, “A method for solving the convex programming problem with convergence rate O(1/k2),”Proceedings of the USSR Academy of Sciences, vol. 269, pp. 543–547, 1983
1983
-
[30]
Nesterov,Introductory lectures on convex optimization: A basic course
Y . Nesterov,Introductory lectures on convex optimization: A basic course. Springer Science & Business Media, 2013, vol. 87
2013
-
[31]
Some methods of speeding up the convergence of iteration methods,
B. Polyak, “Some methods of speeding up the convergence of iteration methods,”USSR Computational Mathematics and Mathematical Physics, vol. 4, no. 5, pp. 1–17, Jan. 1964, ISSN: 0041-5553
1964
-
[32]
On the importance of initialization and momentum in deep learning,
I. Sutskever, J. Martens, G. Dahl, and G. Hinton, “On the importance of initialization and momentum in deep learning,” inProceedings of the 30th International Conference on Ma- chine Learning, S. Dasgupta and D. McAllester, Eds., ser. Proceedings of Machine Learning Research, vol. 28, Atlanta, Georgia, USA: PMLR, 17–19 Jun 2013, pp. 1139–1147
2013
-
[33]
Adam: A method for stochastic optimization,
D. P. Kingma and J. Ba, “Adam: A method for stochastic optimization,” inInternational Conference on Learning Representations (ICLR), 2015
2015
-
[34]
Decoupled weight decay regularization,
I. Loshchilov and F. Hutter, “Decoupled weight decay regularization,” inInternational Confer- ence on Learning Representations, 2017
2017
-
[35]
Ogata,Modern Control Engineering, 4th
K. Ogata,Modern Control Engineering, 4th. USA: Prentice Hall PTR, 2001,ISBN: 0130609072
2001
-
[36]
The implicit bias of gradient descent on separable data,
D. Soudry, E. Hoffer, and N. Srebro, “The implicit bias of gradient descent on separable data,” inInternational Conference on Learning Representations, 2018
2018
-
[37]
Implicit bias of gradient descent on linear convolutional networks,
S. Gunasekar, J. D. Lee, D. Soudry, and N. Srebro, “Implicit bias of gradient descent on linear convolutional networks,” inAdvances in Neural Information Processing Systems, S. Bengio, H. Wallach, H. Larochelle, K. Grauman, N. Cesa-Bianchi, and R. Garnett, Eds., vol. 31, Curran Associates, Inc., 2018
2018
-
[38]
Neyshabur,Implicit regularization in deep learning, 2017
B. Neyshabur,Implicit regularization in deep learning, 2017
2017
-
[39]
Grokking as the transition from lazy to rich training dynamics,
T. Kumar, B. Bordelon, S. J. Gershman, and C. Pehlevan, “Grokking as the transition from lazy to rich training dynamics,” inThe Twelfth International Conference on Learning Repre- sentations, 2024
2024
-
[40]
Varma, R
V . Varma, R. Shah, Z. Kenton, J. Kramár, and R. Kumar,Explaining grokking through circuit efficiency, 2023
2023
-
[41]
Thilak, E
V . Thilak, E. Littwin, S. Zhai, O. Saremi, R. Paiss, and J. Susskind,The slingshot mechanism: An empirical study of adaptive optimizers and the grokking phenomenon, 2022
2022
-
[42]
Progress measures for grokking via mechanistic interpretability,
N. Nanda, L. Chan, T. Lieberum, J. Smith, and J. Steinhardt, “Progress measures for grokking via mechanistic interpretability,” inThe Eleventh International Conference on Learning Representations, 2023
2023
-
[43]
J. Lee, B. G. Kang, K. Kim, and K. M. Lee,Grokfast: Accelerated grokking by amplifying slow gradients, 2024
2024
-
[44]
X. Zhou, S. Fan, M. Jaggi, and J. Fu,Neuralgrok: Accelerate grokking by neural gradient transformation, 2025
2025
-
[45]
Tveit, B
A. Tveit, B. Remseth, and A. Skogvold,Muon optimizer accelerates grokking, 2025
2025
-
[46]
Acceleration of grokking in learning arithmetic operations via kolmogorov–arnold representation,
Y . Park, M. Kim, and Y . Kim, “Acceleration of grokking in learning arithmetic operations via kolmogorov–arnold representation,”Neurocomputing, vol. 640, p. 130 347, Aug. 2025,ISSN: 0925-2312. 11
2025
-
[47]
Grokking in the wild: Data augmentation for real-world multi-hop reasoning with transformers,
R. Abramov, F. Steinbauer, and G. Kasneci, “Grokking in the wild: Data augmentation for real-world multi-hop reasoning with transformers,” inForty-second International Conference on Machine Learning, 2025
2025
-
[48]
When do flat minima optimizers work?
J. Kaddour, L. Liu, R. Silva, and M. J. Kusner, “When do flat minima optimizers work?” Advances in Neural Information Processing Systems, vol. 35, pp. 16 577–16 595, 2022
2022
-
[49]
Sharp minima can generalize for deep nets,
L. Dinh, R. Pascanu, S. Bengio, and Y . Bengio, “Sharp minima can generalize for deep nets,” inInternational Conference on Machine Learning, PMLR, 2017, pp. 1019–1028
2017
-
[50]
J. M. Lee,Riemannian manifolds: an introduction to curvature. Springer Science & Business Media, 2006
2006
-
[51]
Adaptive subgradient methods for online learning and stochastic optimization,
J. Duchi, E. Hazan, and Y . Singer, “Adaptive subgradient methods for online learning and stochastic optimization,”Journal of Machine Learning Research, vol. 12, no. 61, pp. 2121– 2159, 2011
2011
-
[52]
Dropout: A simple way to prevent neural networks from overfitting,
N. Srivastava, G. Hinton, A. Krizhevsky, I. Sutskever, and R. Salakhutdinov, “Dropout: A simple way to prevent neural networks from overfitting,”Journal of Machine Learning Research, vol. 15, no. 56, pp. 1929–1958, 2014
1929
-
[53]
Overfitting in neural nets: Backpropagation, conjugate gradient, and early stopping,
R. Caruana, S. Lawrence, and C. Giles, “Overfitting in neural nets: Backpropagation, conjugate gradient, and early stopping,” inAdvances in Neural Information Processing Systems, T. Leen, T. Dietterich, and V . Tresp, Eds., vol. 13, MIT Press, 2000
2000
-
[54]
On early stopping in gradient descent learning,
Y . Yao, L. Rosasco, and A. Caponnetto, “On early stopping in gradient descent learning,” Constructive Approximation, vol. 26, no. 2, pp. 289–315, Apr. 2007,ISSN: 1432-0940
2007
-
[55]
Sharp minima can generalize for deep nets,
L. Dinh, R. Pascanu, S. Bengio, and Y . Bengio, “Sharp minima can generalize for deep nets,” inProceedings of the 34th International Conference on Machine Learning - Volume 70, ser. ICML’17, Sydney, NSW, Australia: JMLR.org, 2017, pp. 1019–1028
2017
-
[56]
Martin, Christopher Hinrichs,SETOL: A Semi-Empirical Theory of (Deep) Learning
C. H. Martin and C. Hinrichs, “Setol: A semi-empirical theory of (deep) learning,”arXiv preprint arXiv:2507.17912, 2025
-
[57]
H. K. Prakash and C. H. Martin, “Grokking and generalization collapse: Insights from htsr theory,”arXiv preprint arXiv:2506.04434, 2025
-
[58]
Comprehensive molecular characterization of clear cell renal cell carcinoma,
T. R. Network, “Comprehensive molecular characterization of clear cell renal cell carcinoma,” Nature, vol. 499, no. 7456, pp. 43–49, 2013
2013
-
[59]
Molecular classification of cancer: Class discovery and class prediction by gene expression monitoring,
T. R. Golub et al., “Molecular classification of cancer: Class discovery and class prediction by gene expression monitoring,”science, vol. 286, no. 5439, pp. 531–537, 1999. 12 SUPPLEMENTARY INFORMATION A Extended Related Work Optimizer families in deep learning.Deep-learning optimization is dominated by several families of first-order methods. Stochastic ...
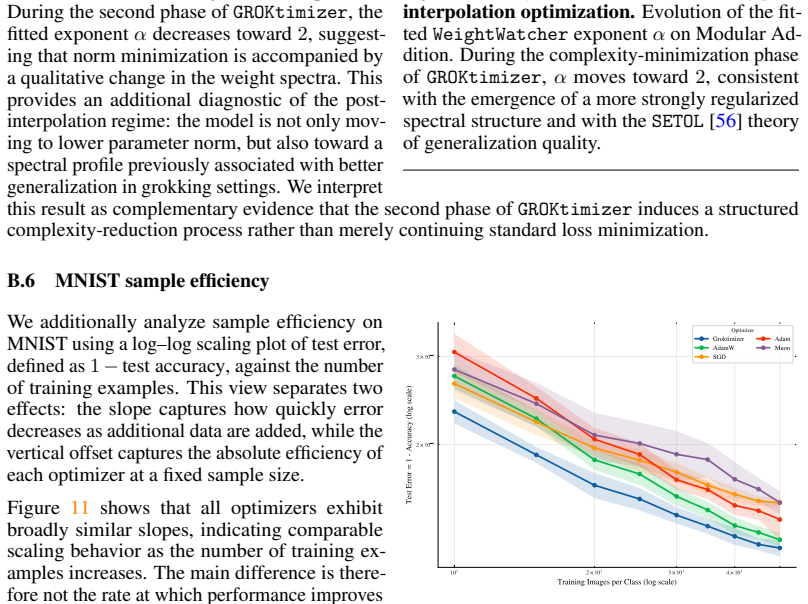
1999
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.