Scalable Counterfactual Risk Estimation for Rare Events in Longitudinal Data
Pith reviewed 2026-06-28 13:48 UTC · model grok-4.3
The pith
A subsampling and reweighting strategy scales ICE estimators for causal effects on rare survival outcomes in longitudinal data while preserving consistency.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a principled subsampling and reweighting strategy for longitudinal survival data can be applied to existing causal effect estimators including the ICE estimator, substantially reducing computational burden while preserving consistency and improving estimation stability in rare-outcome settings.
What carries the argument
A subsampling and reweighting strategy applied to g-formula estimators such as iterative conditional expectation under longitudinal data structure and rare-event regime.
If this is right
- The method applies to a range of g-formula estimators beyond ICE for time-varying treatments on survival outcomes.
- Bootstrap-based variance estimation becomes feasible on large cohorts because the computational load drops.
- Class imbalance at each time point is mitigated, reducing instability and convergence failures in logistic models.
- Analysis of large-scale EHR data for rare events such as suicide risk becomes practical while retaining the original estimator's theoretical guarantees.
Where Pith is reading between the lines
- The same subsampling logic could be tested on other longitudinal causal methods that rely on sequential regression or weighting.
- If the reweighting preserves asymptotic properties, the approach might support sequential updating of estimates as new data arrive in streaming health records.
- Extensions to non-survival longitudinal outcomes with rare binary events would be a direct next check.
Load-bearing premise
That a subsampling and reweighting procedure can be applied to ICE and similar g-formula estimators while preserving their consistency properties under the longitudinal data structure and rare-event regime.
What would settle it
If bootstrap variance estimates or point estimates from the subsampled reweighted ICE diverge from those obtained on the full dataset as sample size grows in a simulated longitudinal rare-event setting, the preservation of consistency would be falsified.
Figures
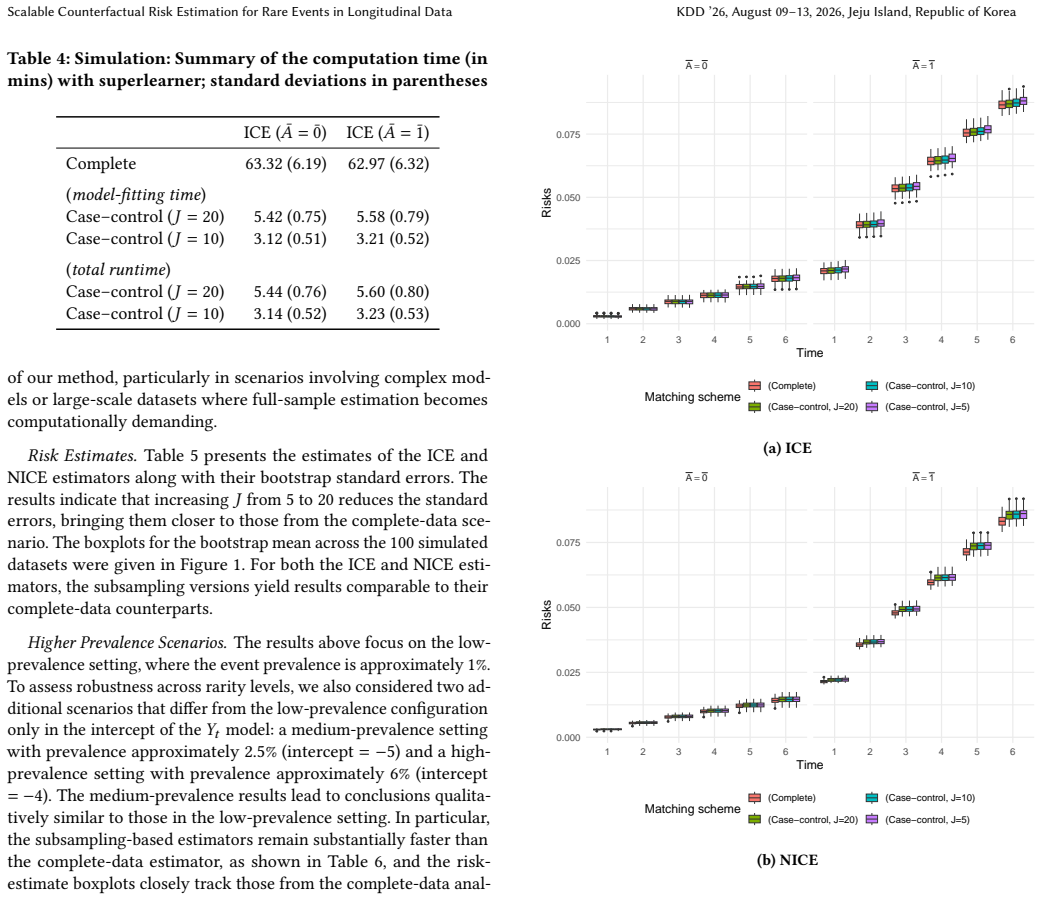
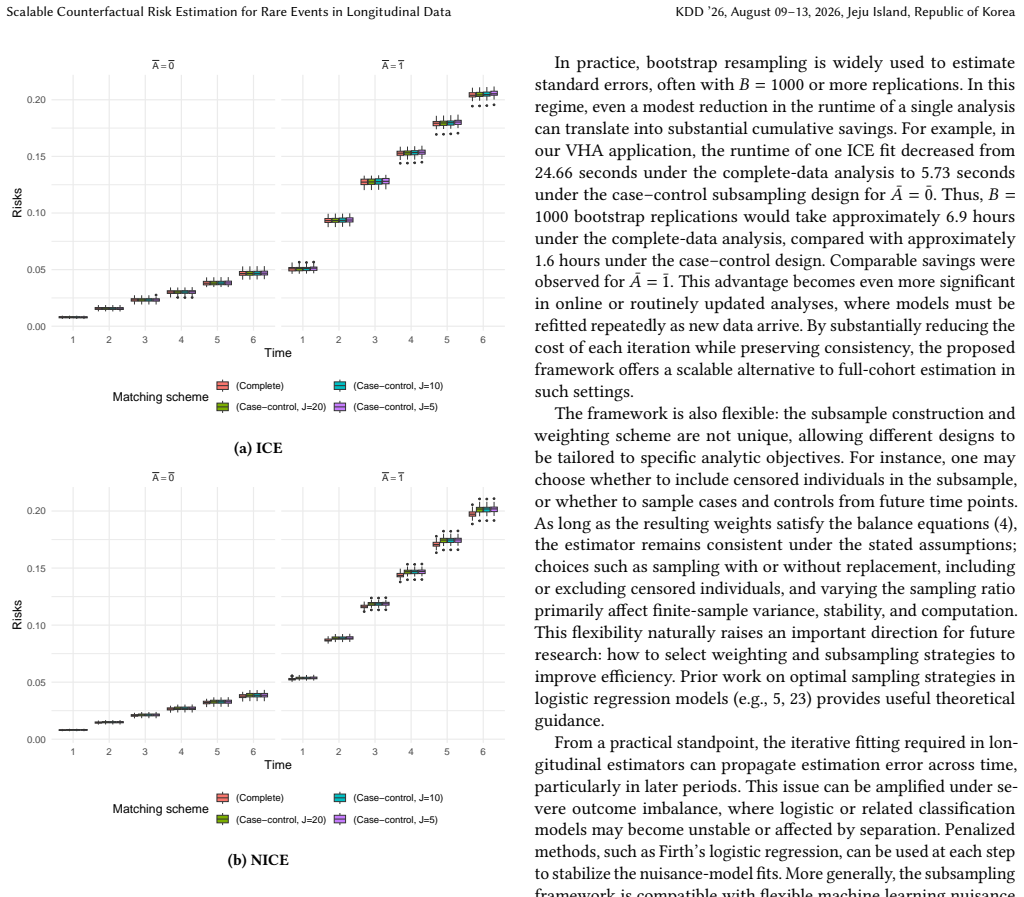
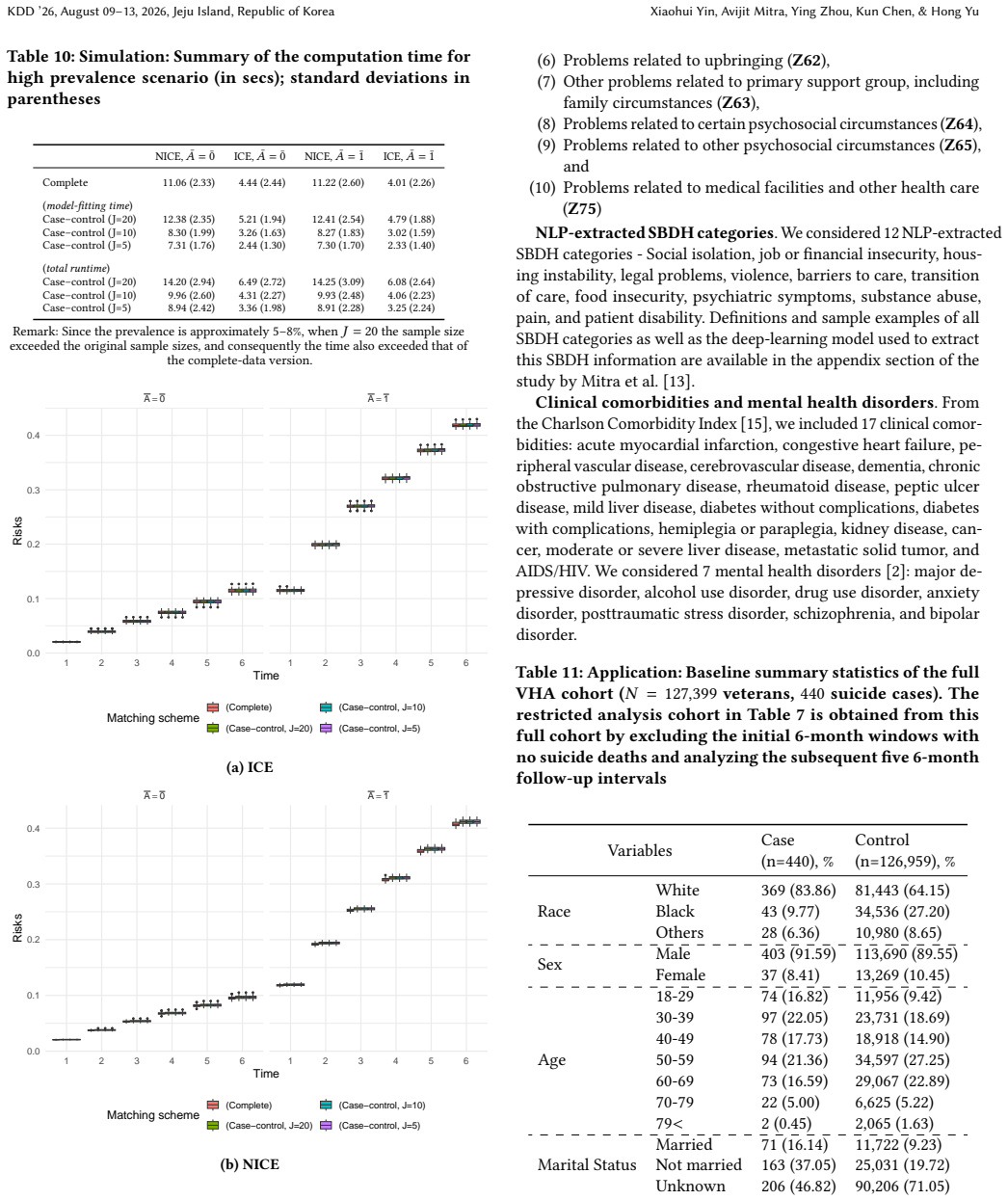
read the original abstract
Estimating the causal effect of time-varying treatments on survival outcomes in large observational studies is computationally demanding, particularly when outcomes are rare. While g-formula-based methods such as the iterative conditional expectation (ICE) estimator provide a principled framework for longitudinal causal inference, they become computationally expensive, especially when bootstrap-based variance estimation is required. In addition, outcome rarity at each time point induces severe class imbalance, leading to instability and convergence issues in logistic regression and related models. To address these challenges, we propose a principled subsampling and reweighting strategy for longitudinal survival data that can be applied to a range of existing causal effect estimators in this setting, including the ICE estimator. The proposed method substantially reduces computational burden while preserving consistency and improving estimation stability in rare-outcome settings. We evaluate the method through simulations and validate it using a large-scale EHR cohort study on social and behavioral determinants of health (SBDH) and suicide risk, demonstrating its effectiveness for modeling rare outcomes in longitudinal data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a subsampling and reweighting strategy for longitudinal survival data that can be applied to ICE and similar g-formula estimators. The approach is intended to reduce computational burden for bootstrap variance estimation and mitigate instability from class imbalance in rare-outcome settings while preserving consistency of the causal effect estimates. The claims are supported by simulation studies and a real-data application to a large EHR cohort examining social and behavioral determinants of health and suicide risk.
Significance. If the consistency preservation holds under the stated longitudinal and rare-event conditions, the method would address a genuine practical barrier to applying g-formula estimators at scale, enabling more routine use of these methods in large observational datasets with rare survival outcomes. The combination of simulation evidence and real-data validation on suicide risk strengthens the practical relevance.
major comments (2)
- [Abstract] Abstract: the central claim that the subsampling-reweighting strategy preserves consistency for ICE-type g-formula estimators is asserted without an explicit statement of the sampling probabilities, the reweighting formula, or a proof sketch showing that the estimator converges to the same limit as the full-data ICE under the longitudinal data structure.
- [Methods] Methods (assumed location of the estimator definition): the manuscript does not derive or state the conditions (e.g., requirements on the sampling probabilities or the form of the reweighting) under which the subsampled ICE estimator remains consistent in the rare-event regime; without this, the weakest assumption identified by the reader cannot be evaluated.
minor comments (1)
- [Abstract] The abstract refers to 'a range of existing causal effect estimators' but does not list which additional estimators beyond ICE were tested or how the strategy generalizes.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for greater explicitness regarding the consistency properties of the proposed subsampling-reweighting strategy. We address each major comment below and have revised the manuscript to incorporate the requested details.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the subsampling-reweighting strategy preserves consistency for ICE-type g-formula estimators is asserted without an explicit statement of the sampling probabilities, the reweighting formula, or a proof sketch showing that the estimator converges to the same limit as the full-data ICE under the longitudinal data structure.
Authors: We agree that the abstract would benefit from additional specificity on these points. In the revised manuscript we have added a concise statement of the sampling probabilities (inclusion probabilities inversely proportional to the observed outcome frequency at each time point) and the corresponding inverse-probability reweighting formula directly into the abstract. We have also inserted a brief proof sketch in the Methods section establishing that the subsampled and reweighted ICE estimator converges in probability to the same limit as the full-data ICE estimator under the stated longitudinal data structure. revision: yes
-
Referee: [Methods] Methods (assumed location of the estimator definition): the manuscript does not derive or state the conditions (e.g., requirements on the sampling probabilities or the form of the reweighting) under which the subsampled ICE estimator remains consistent in the rare-event regime; without this, the weakest assumption identified by the reader cannot be evaluated.
Authors: We acknowledge that the original submission did not provide an explicit derivation of the consistency conditions. The revised manuscript now contains a new subsection in Methods that (i) states the precise form of the reweighting, (ii) specifies the requirements on the sampling probabilities (bounded away from zero and one, with the rare-event adjustment ensuring the effective sample size remains sufficient), and (iii) derives the conditions under which the subsampled estimator remains consistent for the g-formula functional in the rare-event longitudinal setting. These additions allow the weakest assumptions to be directly evaluated. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper introduces a subsampling-reweighting procedure for ICE/g-formula estimators under longitudinal rare-event regimes and asserts that the procedure preserves consistency while reducing computation. This claim is framed as a property of the new method, validated externally via simulation studies and real-data application rather than being tautological or defined by construction from the inputs. No load-bearing derivation step reduces to a self-citation chain, a fitted parameter renamed as a prediction, or an ansatz smuggled via prior work by the same authors. The central consistency result is presented as independently verifiable against external benchmarks (simulations, EHR cohort), making the derivation self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Heejung Bang and James M. Robins. 2005. Doubly robust estimation in missing data and causal inference models.Biometrics61, 4 (2005), 962–973
2005
-
[2]
John R Blosnich, Ann Elizabeth Montgomery, Melissa E Dichter, Adam J Gordon, Dio Kavalieratos, Laura Taylor, Bryan Ketterer, and Robert M Bossarte. 2020. Social determinants and military veterans’ suicide ideation and attempt: a cross- sectional analysis of electronic health record data.Journal of General Internal Medicine35 (2020), 1759–1767
2020
-
[3]
Anusha Bompelli, Yanshan Wang, Ruyuan Wan, Esha Singh, Yuqi Zhou, Lin Xu, David Oniani, Bhavani Singh Agnikula Kshatriya, Joyce Joy E Balls-Berry, and Rui Zhang. 2021. Social and Behavioral Determinants of Health in the Era of Artificial Intelligence with Electronic Health Records: A Scoping Review.Health Data Science(2021). doi:10.34133/2021/9759016 eCol...
-
[4]
Norman E Breslow. 1996. Statistics in epidemiology: the case-control study. Journal of the American Statistical Association91, 433 (1996), 14–28
1996
-
[5]
William Fithian and Trevor Hastie. 2014. Local case–control sampling: Efficient subsampling in imbalanced data sets.The Annals of Statistics42, 5 (2014), 1693– 1724
2014
-
[6]
Hernán and James M
Miguel A. Hernán and James M. Robins. 2006. Estimating causal effects from epidemiological data.Journal of Epidemiology and Community Health60, 7 (2006), 578–586
2006
-
[7]
Hernán and James M
Miguel A. Hernán and James M. Robins. 2020.Causal Inference: What If. CRC Press, Boca Raton
2020
-
[8]
Keil, Jessie K
Alexander P. Keil, Jessie K. Edwards, David B. Richardson, Ashley I. Naimi, and Stephen R. Cole. 2014. The Parametric g-Formula for Time-to-Event Data: Intuition and a Worked Example.Epidemiology25, 6 (2014), 889–897
2014
-
[9]
Kenfield, Esther K
Stacey A. Kenfield, Esther K. Wei, Meir J. Stampfer, Bernard A. Rosner, and Graham A. Colditz. 2008. Comparison of aspects of smoking among the four histological types of lung cancer.Tobacco Control17, 3 (2008), 198–204
2008
-
[10]
Gary King and Langche Zeng. 2001. Logistic regression in rare events data. Political Analysis9, 2 (2001), 137–163
2001
-
[11]
Knowler, Elizabeth Barrett-Connor, Sarah E
William C. Knowler, Elizabeth Barrett-Connor, Sarah E. Fowler, Richard F. Ham- man, John M. Lachin, Elizabeth A. Walker, and David M. Nathan. 2002. Reduction in the incidence of type 2 diabetes with lifestyle intervention or metformin.The New England Journal of Medicine346, 6 (2002), 393–403
2002
-
[12]
Sean McGrath, Victoria Lin, Zilu Zhang, Lucia C Petito, Roger W Logan, Miguel A Hernán, and Jessica G Young. 2020. gfoRmula: an R package for estimating the effects of sustained treatment strategies via the parametric g-formula.Patterns1, 3 (2020)
2020
-
[13]
Avijit Mitra, Richeek Pradhan, Rachel D Melamed, Kun Chen, David C Hoaglin, Katherine L Tucker, Joel I Reisman, Zhichao Yang, Weisong Liu, Jack Tsai, et al
-
[14]
Associations between natural language processing–enriched social deter- minants of health and suicide death among US veterans.JAMA Network Open6, 3 (2023), e233079
2023
-
[15]
2019.SuperLearner: Super Learner Prediction
Eric Polley, Erin LeDell, Chris Kennedy, Sam Lendle, and Mark van der Laan. 2019.SuperLearner: Super Learner Prediction. R package
2019
-
[16]
Hude Quan, Bing Li, Chantal M Couris, Kiyohide Fushimi, Patrick Graham, Phil Hider, Jean-Marie Januel, and Vijaya Sundararajan. 2011. Updating and validating the Charlson comorbidity index and score for risk adjustment in hospital discharge abstracts using data from 6 countries.American Journal of Epidemiology173, 6 (2011), 676–682
2011
-
[17]
James Robins. 1986. A new approach to causal inference in mortality studies with a sustained exposure period—application to control of the healthy worker survivor effect.Mathematical Modelling7, 9-12 (1986), 1393–1512
1986
-
[18]
James M. Robins, Miguel A. Hernán, and Babette Brumback. 2000. Marginal structural models and causal inference in epidemiology.Epidemiology11, 5 (2000), 550–560. doi:10.1097/00001648-200009000-00011
-
[19]
Mark J van der Laan. 2008. Estimation based on case-control designs with known prevalence probability.The International Journal of Biostatistics4, 1 (2008)
2008
-
[20]
van der Laan and Susan Gruber
Mark J. van der Laan and Susan Gruber. 2012. Targeted maximum likelihood estimation of causal effects of multiple time point interventions.The International Journal of Biostatistics8, 1 (2012), 1–40
2012
-
[21]
Stijn Vansteelandt and Marshall Joffe. 2014. Structural Nested Models and G- estimation: The Partially Realized Promise.Statistical Science29, 4 (2014), 707–731. doi:10.1214/14-STS486
-
[22]
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need.Advances in Neural Information Processing Systems30 (2017)
2017
-
[23]
HaiYing Wang. 2020. Logistic regression for massive data with rare events. In Proceedings of the 37th International Conference on Machine Learning (ICML’20). JMLR.org, Article 911, 8 pages
2020
-
[24]
HaiYing Wang, Aonan Zhang, and Chong Wang. 2021. Nonuniform negative sampling and log odds correction with rare events data.Advances in Neural Information Processing Systems34 (2021), 19847–19859
2021
-
[25]
Lan Wen, Jessica G. Young, James M. Robins, and Miguel A. Hernán. 2021. Para- metric g-formula implementations for causal survival analyses.Biometrics77, 2 (2021), 740–753. doi:10.1111/biom.13278
-
[26]
Young, Lauren E
Jessica G. Young, Lauren E. Cain, James M. Robins, Eilis J. O’Reilly, and Miguel A. Hernán. 2011. Comparative effectiveness of dynamic treatment regimes: an application of the parametric g-formula.Statistics in Biosciences3, 1 (2011), 119–143. A Additional Weight Combinations Below we give 4 sets of possible weights for the illustrative example with 2 tim...
2011
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.