PathAR: Structure-First Autoregressive Synthesis of Multimodal Pathology Images
Pith reviewed 2026-06-28 15:48 UTC · model grok-4.3
The pith
PathAR explicitly factorizes structure and appearance tokens to generate anatomically coherent multimodal pathology images.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
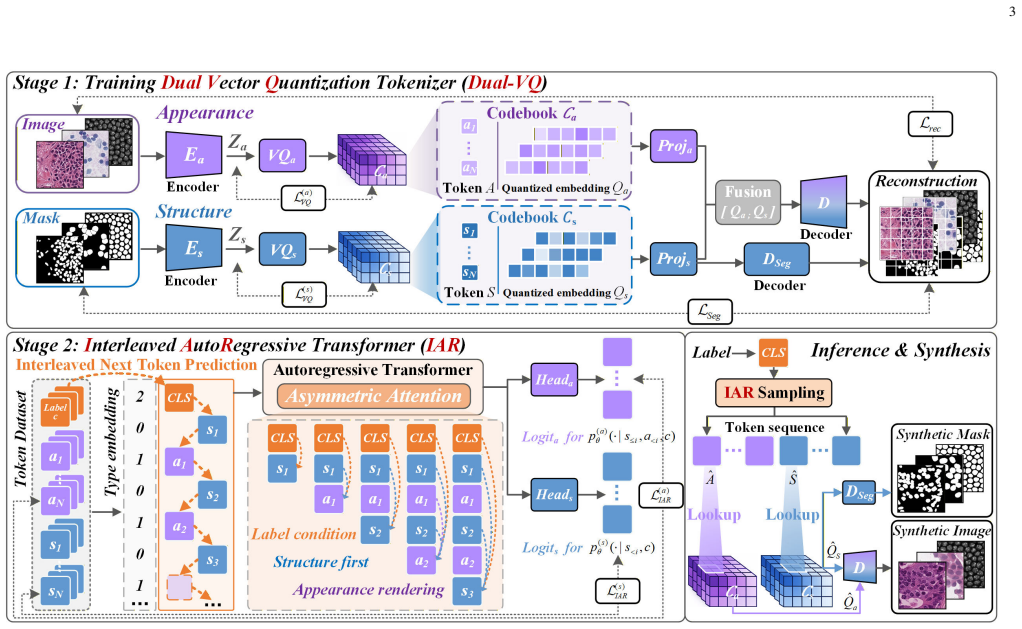
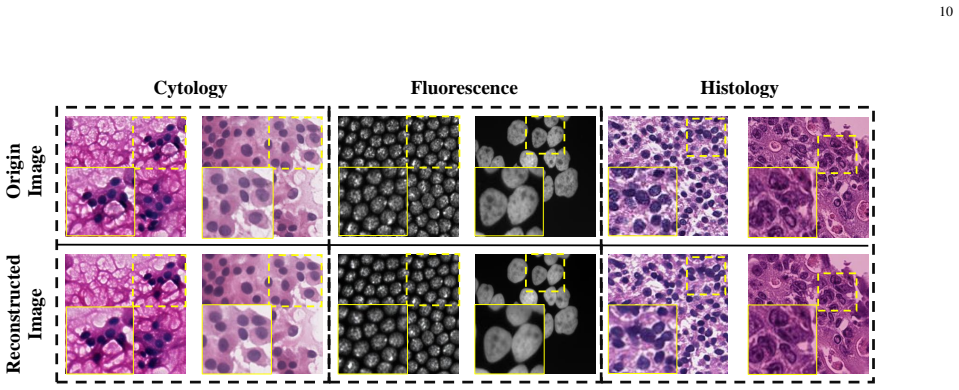
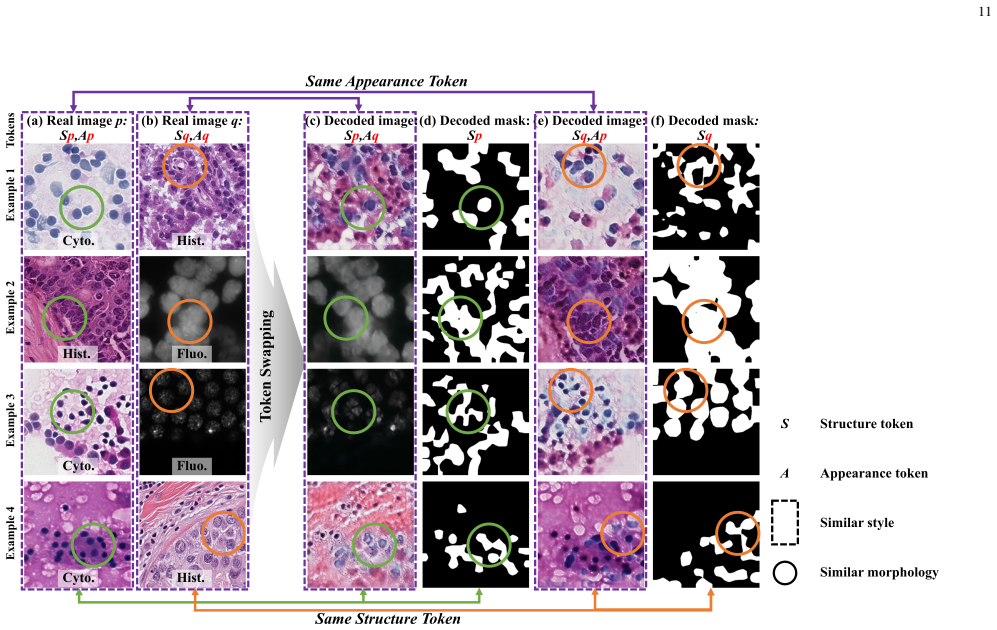
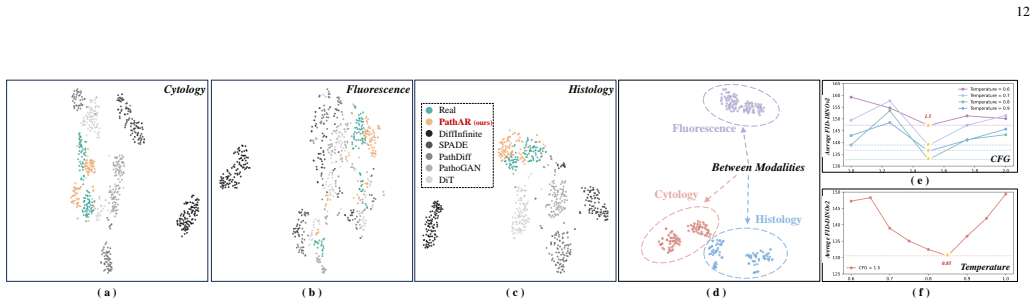
PathAR employs a dual vector quantization tokenizer to decompose samples into mask-grounded structure and appearance tokens, and an interleaved autoregressive transformer with asymmetric attention visibility to enforce structure-to-appearance dependence, stabilizing morphology under heterogeneous modality-specific appearances and enabling spatially aligned image-mask pair generation.
What carries the argument
Dual-VQ tokenizer that produces separate structure and appearance tokens, combined with an IAR transformer using asymmetric attention to enforce structure-to-appearance dependence.
If this is right
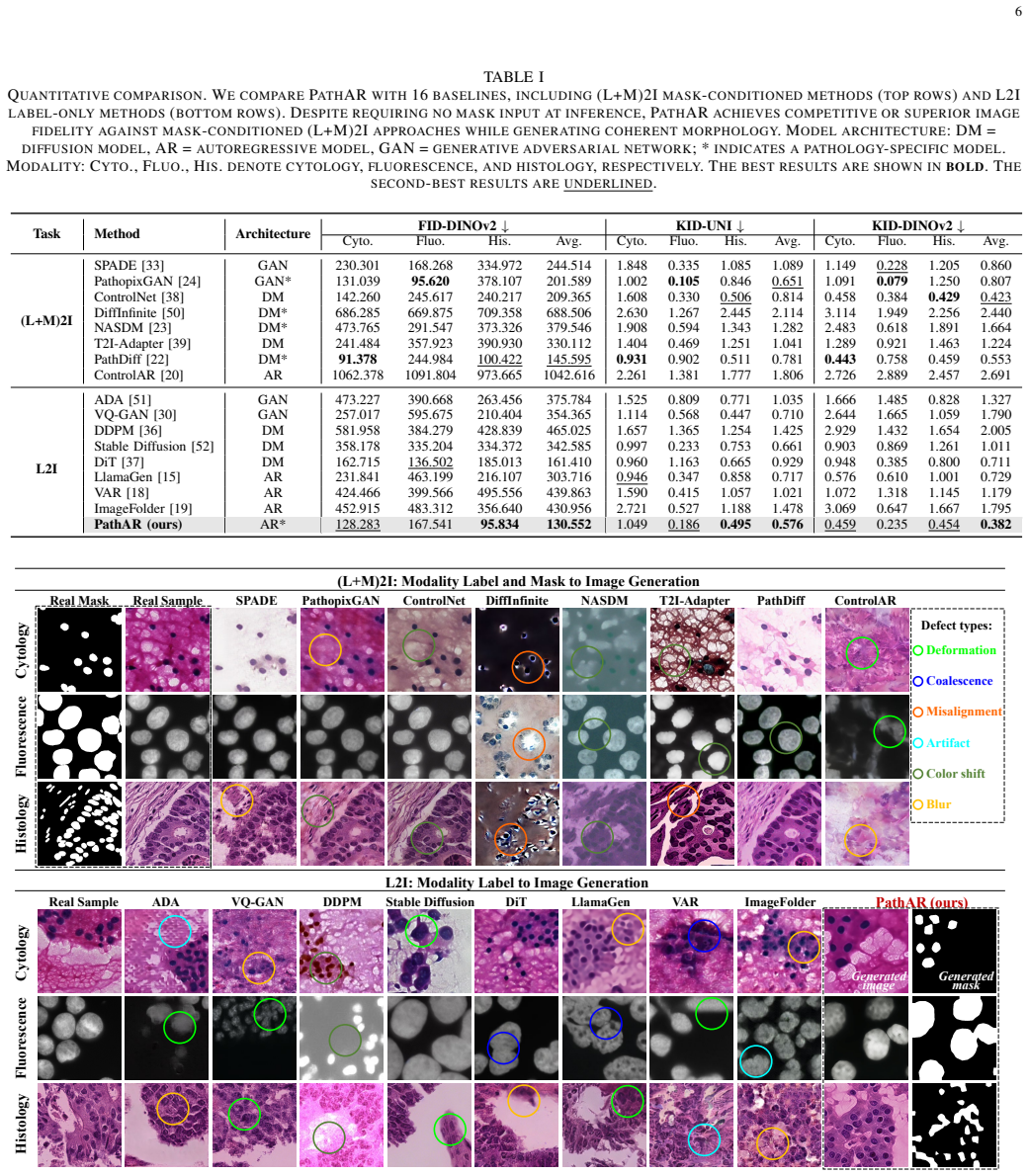
- PathAR improves structural consistency and modality fidelity over baselines.
- The method maintains sample diversity while supporting spatially aligned outputs.
- It enables downstream segmentation training in data-scarce regimes.
- The framework extends to finer-grained intra-modality organ-label variation.
Where Pith is reading between the lines
- The structure-first approach could apply to other medical imaging domains where anatomical features remain stable across different acquisition methods.
- Conditional generation on modality labels might allow efficient adaptation without full model retraining for new imaging protocols.
- Providing explicit structure tokens could support controllable editing of pathology images for augmentation tasks.
Load-bearing premise
Morphological structures such as cellular topology and tissue boundaries are largely preserved across acquisition protocols, allowing explicit factorization of structure and appearance without loss of anatomical coherence.
What would settle it
Generating images from a modality pair where cellular topology or tissue boundaries visibly differ would produce misaligned masks or anatomically incoherent outputs if the factorization premise fails.
Figures


read the original abstract
Data scarcity in multimodal pathology motivates unified generative models that synthesize modality-specific appearance while preserving anatomically coherent structure. Although modalities differ in appearance statistics, morphological structures such as cellular topology and tissue boundaries are largely preserved across acquisition protocols. However, existing methods often model these factors within a homogeneous token stream, implicitly coupling structure with appearance and weakening structural controllability under modality shifts. To address this, we propose pathology Autorgressive modeling (PathAR), a structure-first autoregressive synthesis framework that explicitly factorizes structure and appearance for modality-label-conditioned pathology generation.PathAR employs a dual vector quantization (Dual-VQ) tokenizer to decompose samples into mask-grounded structure and appearance tokens, and an interleaved autoregressive (IAR) transformer with asymmetric attention visibility to enforce structure-to-appearance dependence. PathAR stabilizes morphology under heterogeneous modality-specific appearances and enables spatially aligned image--mask pair generation. Extensive experiments show that PathAR improves structural consistency and modality fidelity over baselines, maintains sample diversity, supports downstream segmentation in data-scarce regimes, and demonstrates extensibility to finer-grained intra-modality organ-label variation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes PathAR, a structure-first autoregressive framework for synthesizing modality-specific pathology images while preserving anatomical coherence. It introduces a Dual-VQ tokenizer that decomposes inputs into mask-grounded structure tokens and appearance tokens, paired with an interleaved autoregressive (IAR) transformer using asymmetric attention to enforce strict structure-to-appearance ordering. The approach is motivated by data scarcity in multimodal pathology and claims to stabilize morphology under heterogeneous appearances, enable spatially aligned image-mask generation, and improve structural consistency, modality fidelity, sample diversity, and downstream segmentation performance over baselines.
Significance. If the empirical results hold, the explicit factorization of structure and appearance via Dual-VQ and ordered autoregressive modeling represents a targeted advance for controllable generation in medical imaging. The ability to produce aligned multimodal pairs could directly aid data augmentation in data-scarce regimes and support tasks such as segmentation. The paper positions its results as direct validation of the factorization without loss of coherence.
major comments (1)
- [Abstract / Introduction] The central claim that Dual-VQ produces mask-grounded structure tokens that remain anatomically coherent across modality shifts rests on the precondition that morphological structures (cellular topology, tissue boundaries) are largely preserved across acquisition protocols. This assumption is stated in the abstract but requires a concrete quantitative test (e.g., cross-modality mask overlap or topology metrics on paired samples) to confirm it does not introduce coherence loss; without such evidence the factorization benefit cannot be isolated from the assumption.
minor comments (1)
- [Abstract] The abstract refers to 'extensive experiments' and 'improved structural consistency' without naming datasets, metrics (e.g., FID, Dice, structural similarity), or baseline methods; adding one or two quantitative highlights would improve readability.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. Below we provide a point-by-point response to the single major comment.
read point-by-point responses
-
Referee: [Abstract / Introduction] The central claim that Dual-VQ produces mask-grounded structure tokens that remain anatomically coherent across modality shifts rests on the precondition that morphological structures (cellular topology, tissue boundaries) are largely preserved across acquisition protocols. This assumption is stated in the abstract but requires a concrete quantitative test (e.g., cross-modality mask overlap or topology metrics on paired samples) to confirm it does not introduce coherence loss; without such evidence the factorization benefit cannot be isolated from the assumption.
Authors: We agree that a direct quantitative validation of cross-modality structural preservation would strengthen the presentation. The assumption is standard in the pathology literature because different modalities (e.g., H&E versus IHC) target the same underlying cellular and tissue morphology. Our Dual-VQ explicitly grounds structure tokens in segmentation masks that are intended to be modality-agnostic, and the reported gains in structural consistency metrics plus downstream segmentation performance provide indirect empirical support for the factorization. However, the training datasets used in the manuscript are unpaired across modalities, precluding the exact overlap or topology metrics suggested. We will add a dedicated paragraph in the revised introduction and methods sections that (i) cites supporting pathology references for the assumption and (ii) explicitly notes the lack of paired cross-modality evaluation as a limitation. This change will better isolate the contribution of Dual-VQ while remaining faithful to the available data. revision: partial
Circularity Check
No significant circularity in derivation chain
full rationale
The paper introduces PathAR as a structure-first autoregressive model that uses a Dual-VQ tokenizer to produce mask-grounded structure tokens and appearance tokens, followed by an IAR transformer with asymmetric attention to enforce ordering. No equations, fitted parameters, or self-citations are shown in the abstract or description that reduce any claimed prediction or uniqueness result to the inputs by construction. The factorization is presented as an explicit design choice whose success is evaluated empirically on structural consistency and modality fidelity, rather than assumed via prior self-referential theorems or renaming of known patterns. The morphological preservation assumption is acknowledged as an empirical precondition, not a derived axiom. The derivation chain is therefore self-contained against external benchmarks with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Synthetic data and its utility in pathology and laboratory medicine,
J. Pantanowitz, C. D. Manko, L. Pantanowitz, and H. H. Rashidi, “Synthetic data and its utility in pathology and laboratory medicine,” Laboratory Investigation, vol. 104, no. 8, p. 102095, 2024
2024
-
[2]
Content generation models in computational pathology: A comprehen- sive survey on methods, applications, and challenges,
Y . Zhang, X. Zhang, X. Qi, X. Wu, F. Chen, G. Yang, and H. Fu, “Content generation models in computational pathology: A comprehen- sive survey on methods, applications, and challenges,”IEEE Reviews in Biomedical Engineering, pp. 1–22, 2025
2025
-
[3]
Clusterseg: A crowd cluster pinpointed nucleus segmentation framework with cross-modality datasets,
J. Ke, Y . Lu, Y . Shen, J. Zhu, Y . Zhou, J. Huang, J. Yao, X. Liang, Y . Guo, Z. Weiet al., “Clusterseg: A crowd cluster pinpointed nucleus segmentation framework with cross-modality datasets,”Medical Image Analysis, vol. 85, p. 102758, 2023
2023
-
[4]
Structure- preserving color normalization and sparse stain separation for histologi- cal images,
A. Vahadane, T. Peng, A. Sethi, S. Albarqouni, L. Wang, M. Baust, K. Steiger, A. M. Schlitter, I. Esposito, and N. Navab, “Structure- preserving color normalization and sparse stain separation for histologi- cal images,”IEEE Transactions on Medical Imaging, vol. 35, no. 8, pp. 1962–1971, 2016
1962
-
[5]
Fluorescence confocal microscopy for pathologists,
M. Ragazzi, S. Piana, C. Longo, F. Castagnetti, M. Foroni, G. Ferrari, G. Gardini, and G. Pellacani, “Fluorescence confocal microscopy for pathologists,”Modern Pathology, vol. 27, no. 3, pp. 460–471, 2014
2014
-
[6]
Maskfactory: Towards high-quality synthetic data generation for dichotomous image segmentation,
H. Qian, Y . Chen, S. Lou, F. Shahbaz Khan, X. Jin, and D.-P. Fan, “Maskfactory: Towards high-quality synthetic data generation for dichotomous image segmentation,”Advances in Neural Information Processing Systems, vol. 37, pp. 66 455–66 478, 2024
2024
-
[7]
Distribution matching losses can hallucinate features in medical image translation,
J. P. Cohen, M. Luck, and S. Honari, “Distribution matching losses can hallucinate features in medical image translation,” inInternational con- ference on medical image computing and computer-assisted intervention. Springer, 2018, pp. 529–536
2018
-
[8]
On hallucinations in tomographic image reconstruction,
S. Bhadra, V . A. Kelkar, F. J. Brooks, and M. A. Anastasio, “On hallucinations in tomographic image reconstruction,”IEEE Transactions on Medical Imaging, vol. 40, no. 11, pp. 3249–3260, 2021
2021
-
[9]
Imagenet-trained cnns are biased towards texture; in- creasing shape bias improves accuracy and robustness,
R. Geirhos, P. Rubisch, C. Michaelis, M. Bethge, F. A. Wichmann, and W. Brendel, “Imagenet-trained cnns are biased towards texture; in- creasing shape bias improves accuracy and robustness,” inInternational conference on learning representations, 2018
2018
-
[10]
J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkatet al., “Gpt-4 technical report,”arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[11]
LLaMA: Open and Efficient Foundation Language Models
H. Touvron, T. Lavril, G. Izacard, X. Martinet, M.-A. Lachaux, T. Lacroix, B. Rozi `ere, N. Goyal, E. Hambro, F. Azharet al., “Llama: Open and efficient foundation language models,”arXiv preprint arXiv:2302.13971, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[12]
Llama 2: Open Foundation and Fine-Tuned Chat Models
H. Touvron, L. Martin, K. Stone, P. Albert, A. Almahairi, Y . Babaei, N. Bashlykov, S. Batra, P. Bhargava, S. Bhosaleet al., “Llama 2: Open foundation and fine-tuned chat models,”arXiv preprint arXiv:2307.09288, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[13]
Autoregressive visual tracking,
X. Wei, Y . Bai, Y . Zheng, D. Shi, and Y . Gong, “Autoregressive visual tracking,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 9697–9706
2023
-
[14]
Autoregressive models in vision: A survey,
J. Xiong, G. Liu, L. Huang, C. Wu, T. Wu, Y . Mu, Y . Yao, H. Shen, Z. Wan, J. Huanget al., “Autoregressive models in vision: A survey,” arXiv preprint arXiv:2411.05902, 2024
-
[15]
Autoregressive Model Beats Diffusion: Llama for Scalable Image Generation
P. Sun, Y . Jiang, S. Chen, S. Zhang, B. Peng, P. Luo, and Z. Yuan, “Autoregressive model beats diffusion: Llama for scalable image gener- ation,”arXiv preprint arXiv:2406.06525, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
Emu3: Next-Token Prediction is All You Need
X. Wang, X. Zhang, Z. Luo, Q. Sun, Y . Cui, J. Wang, F. Zhang, Y . Wang, Z. Li, Q. Yuet al., “Emu3: Next-token prediction is all you need,”arXiv preprint arXiv:2409.18869, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
Janus: Decoupling visual encoding for unified multi- modal understanding and generation,
C. Wu, X. Chen, Z. Wu, Y . Ma, X. Liu, Z. Pan, W. Liu, Z. Xie, X. Yu, C. Ruanet al., “Janus: Decoupling visual encoding for unified multi- modal understanding and generation,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 12 966–12 977
2025
-
[18]
Visual autore- gressive modeling: Scalable image generation via next-scale prediction,
K. Tian, Y . Jiang, Z. Yuan, B. Peng, and L. Wang, “Visual autore- gressive modeling: Scalable image generation via next-scale prediction,” Advances in neural information processing systems, vol. 37, pp. 84 839– 84 865, 2024
2024
-
[19]
Imagefolder: Autoregressive image generation with folded tokens,
X. Li, K. Qiu, H. Chen, J. Kuen, J. Gu, B. Raj, and Z. Lin, “Imagefolder: Autoregressive image generation with folded tokens,” inThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[20]
Controlar: Controllable image generation with autoregressive models,
Z. Li, T. Cheng, S. Chen, P. Sun, H. Shen, L. Ran, X. Chen, W. Liu, and X. Wang, “Controlar: Controllable image generation with autoregressive models,” inThe Thirteenth International Conference on Learning Rep- resentations, 2025
2025
-
[21]
Nuclear morphological abnormalities in cancer: a search for unifying mechanisms,
I. Singh and T. P. Lele, “Nuclear morphological abnormalities in cancer: a search for unifying mechanisms,” inNuclear, chromosomal, and genomic architecture in biology and medicine. Springer, 2022, pp. 443–467
2022
-
[22]
Pathdiff: Histopathology image synthesis with unpaired text and mask conditions,
M. Bhosale, A. Wasi, Y . Zhai, Y . Tian, S. Border, N. Xi, P. Sarder, J. Yuan, D. Doermann, and X. Gong, “Pathdiff: Histopathology image synthesis with unpaired text and mask conditions,” 2025. [Online]. Available: https://arxiv.org/abs/2506.23440
-
[23]
Nasdm: Nuclei-aware semantic histopathology image generation using diffusion models,
A. Shrivastava and P. T. Fletcher, “Nasdm: Nuclei-aware semantic histopathology image generation using diffusion models,” ininterna- tional conference on medical image computing and computer-assisted intervention. Springer, 2023, pp. 786–796
2023
-
[24]
A robust image segmentation and synthesis pipeline for histopathology,
M. Jehanzaib, Y . Almalioglu, K. B. Ozyoruk, D. F. Williamson, T. Ab- dullah, K. Basak, D. Demir, G. E. Keles, K. Zafar, and M. Turan, “A robust image segmentation and synthesis pipeline for histopathology,” Medical Image Analysis, vol. 99, p. 103344, 2025
2025
-
[25]
Accelerating histopathology workflows with generative ai- based virtually multiplexed tumour profiling,
P. Pati, S. Karkampouna, F. Bonollo, E. Comp ´erat, M. Radi ´c, M. Spahn, A. Martinelli, M. Wartenberg, M. Kruithof-de Julio, and M. Rap- somaniki, “Accelerating histopathology workflows with generative ai- based virtually multiplexed tumour profiling,”Nature machine intelli- gence, vol. 6, no. 9, pp. 1077–1093, 2024
2024
-
[26]
Virtual staining for histology by deep learning,
L. Latonen, S. Koivukoski, U. Khan, and P. Ruusuvuori, “Virtual staining for histology by deep learning,”Trends in Biotechnology, vol. 42, no. 9, pp. 1177–1191, 2024
2024
-
[27]
Deep learning- based transformation of h&e stained tissues into special stains,
K. De Haan, Y . Zhang, J. E. Zuckerman, T. Liu, A. E. Sisk, M. F. Diaz, K.-Y . Jen, A. Nobori, S. Liou, S. Zhanget al., “Deep learning- based transformation of h&e stained tissues into special stains,”Nature communications, vol. 12, no. 1, p. 4884, 2021
2021
-
[28]
Next token prediction towards multimodal in- telligence: A comprehensive survey,
L. Chen, Z. Wang, S. Ren, L. Li, H. Zhao, Y . Li, Z. Cai, H. Guo, L. Zhang, Y . Xionget al., “Next token prediction towards multimodal in- telligence: A comprehensive survey,”arXiv preprint arXiv:2412.18619, 2024
-
[29]
Neural discrete representation learning,
A. Van Den Oord, O. Vinyalset al., “Neural discrete representation learning,”Advances in neural information processing systems, vol. 30, 2017
2017
-
[30]
Taming transformers for high- resolution image synthesis,
P. Esser, R. Rombach, and B. Ommer, “Taming transformers for high- resolution image synthesis,” inProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR), June 2021, pp. 12 873–12 883
2021
-
[31]
Maskgit: Masked generative image transformer,
H. Chang, H. Zhang, L. Jiang, C. Liu, and W. T. Freeman, “Maskgit: Masked generative image transformer,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 11 315–11 325
2022
-
[32]
Structure and intensity unbiased translation for 2d medical image segmentation,
T. Zhang, S. Zheng, J. Cheng, X. Jia, J. Bartlett, X. Cheng, Z. Qiu, H. Fu, J. Liu, A. Leonardiset al., “Structure and intensity unbiased translation for 2d medical image segmentation,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 46, no. 12, pp. 10 060– 10 075, 2024
2024
-
[33]
Semantic image synthesis with spatially-adaptive normalization,
T. Park, M.-Y . Liu, T.-C. Wang, and J.-Y . Zhu, “Semantic image synthesis with spatially-adaptive normalization,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 2337–2346
2019
-
[34]
Efficient semantic image synthesis via class-adaptive normalization,
Z. Tan, D. Chen, Q. Chu, M. Chai, J. Liao, M. He, L. Yuan, G. Hua, and N. Yu, “Efficient semantic image synthesis via class-adaptive normalization,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 44, no. 9, pp. 4852–4866, 2021
2021
-
[35]
Edge guided gans with multi-scale contrastive learning for semantic image synthesis,
H. Tang, G. Sun, N. Sebe, L. Van Goolet al., “Edge guided gans with multi-scale contrastive learning for semantic image synthesis,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 45, no. 12, pp. 14 435–14 452, 2023
2023
-
[36]
Denoising diffusion probabilistic models,
J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion probabilistic models,” Advances in neural information processing systems, vol. 33, pp. 6840– 6851, 2020
2020
-
[37]
Scalable diffusion models with transformers,
W. Peebles and S. Xie, “Scalable diffusion models with transformers,” inProceedings of the IEEE/CVF international conference on computer vision, 2023, pp. 4195–4205
2023
-
[38]
Adding conditional control to text-to-image diffusion models,
L. Zhang, A. Rao, and M. Agrawala, “Adding conditional control to text-to-image diffusion models,” inProceedings of the IEEE/CVF international conference on computer vision, 2023, pp. 3836–3847
2023
-
[39]
T2i- adapter: Learning adapters to dig out more controllable ability for text- to-image diffusion models,
C. Mou, X. Wang, L. Xie, Y . Wu, J. Zhang, Z. Qi, and Y . Shan, “T2i- adapter: Learning adapters to dig out more controllable ability for text- to-image diffusion models,” inProceedings of the AAAI conference on artificial intelligence, vol. 38, no. 5, 2024, pp. 4296–4304
2024
-
[40]
Roformer: En- hanced transformer with rotary position embedding,
J. Su, M. Ahmed, Y . Lu, S. Pan, W. Bo, and Y . Liu, “Roformer: En- hanced transformer with rotary position embedding,”Neurocomputing, vol. 568, p. 127063, 2024
2024
-
[41]
Classifier-Free Diffusion Guidance
J. Ho and T. Salimans, “Classifier-free diffusion guidance,” 2022. [Online]. Available: https://arxiv.org/abs/2207.12598 14
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[42]
arXiv preprint arXiv:2003.10778 (2020)
J. Gamper, N. A. Koohbanani, K. Benes, S. Graham, M. Jahanifar, S. A. Khurram, A. Azam, K. Hewitt, and N. Rajpoot, “Pannuke dataset extension, insights and baselines,”arXiv preprint arXiv:2003.10778, 2020
-
[43]
Gans trained by a two time-scale update rule converge to a local nash equilibrium,
M. Heusel, H. Ramsauer, T. Unterthiner, B. Nessler, and S. Hochreiter, “Gans trained by a two time-scale update rule converge to a local nash equilibrium,”Advances in neural information processing systems, vol. 30, 2017
2017
-
[44]
M. Bi ´nkowski, D. J. Sutherland, M. Arbel, and A. Gretton, “Demysti- fying mmd gans,”arXiv preprint arXiv:1801.01401, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[45]
DINOv2: Learning Robust Visual Features without Supervision
M. Oquab, T. Darcet, T. Moutakanni, H. V o, M. Szafraniec, V . Khalidov, P. Fernandez, D. Haziza, F. Massa, A. El-Noubyet al., “Dinov2: Learning robust visual features without supervision,”arXiv preprint arXiv:2304.07193, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[46]
Towards a general-purpose foundation model for computational pathology,
R. J. Chen, T. Ding, M. Y . Lu, D. F. Williamson, G. Jaume, A. H. Song, B. Chen, A. Zhang, D. Shao, M. Shabanet al., “Towards a general-purpose foundation model for computational pathology,”Nature medicine, vol. 30, no. 3, pp. 850–862, 2024
2024
-
[47]
Measures of the amount of ecologic association between species,
L. R. Dice, “Measures of the amount of ecologic association between species,”Ecology, vol. 26, no. 3, pp. 297–302, 1945
1945
-
[48]
The unreasonable effectiveness of deep features as a perceptual metric,
R. Zhang, P. Isola, A. A. Efros, E. Shechtman, and O. Wang, “The unreasonable effectiveness of deep features as a perceptual metric,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 586–595
2018
-
[49]
Im- proved precision and recall metric for assessing generative models,
T. Kynk ¨a¨anniemi, T. Karras, S. Laine, J. Lehtinen, and T. Aila, “Im- proved precision and recall metric for assessing generative models,” Advances in neural information processing systems, vol. 32, 2019
2019
-
[50]
Diffinfinite: Large mask-image synthesis via parallel random patch diffusion in histopathology,
M. Aversa, G. Nobis, M. H ¨agele, K. Standvoss, M. Chirica, R. Murray- Smith, A. M. Alaa, L. Ruff, D. Ivanova, W. Sameket al., “Diffinfinite: Large mask-image synthesis via parallel random patch diffusion in histopathology,”Advances in Neural Information Processing Systems, vol. 36, pp. 78 126–78 141, 2023
2023
-
[51]
Training generative adversarial networks with limited data,
T. Karras, M. Aittala, J. Hellsten, S. Laine, J. Lehtinen, and T. Aila, “Training generative adversarial networks with limited data,”Advances in neural information processing systems, vol. 33, pp. 12 104–12 114, 2020
2020
-
[52]
High- resolution image synthesis with latent diffusion models,
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer, “High- resolution image synthesis with latent diffusion models,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 10 684–10 695
2022
-
[53]
Efficientnet: Rethinking model scaling for con- volutional neural networks,
M. Tan and Q. Le, “Efficientnet: Rethinking model scaling for con- volutional neural networks,” inInternational conference on machine learning. PMLR, 2019, pp. 6105–6114
2019
-
[54]
nnu-net: a self-configuring method for deep learning-based biomedical image segmentation,
F. Isensee, P. F. Jaeger, S. A. Kohl, J. Petersen, and K. H. Maier-Hein, “nnu-net: a self-configuring method for deep learning-based biomedical image segmentation,”Nature methods, vol. 18, no. 2, pp. 203–211, 2021. VI. BIOGRAPHYSECTION Yuan ZhangYuan Zhang received the B.S. degree in 2019 from Northwestern Polytechnical University, Xi’an, China, and the M...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.