TwinQuant: Learnable Subspace Decomposition for 4-Bit LLM Quantization
Pith reviewed 2026-06-28 13:05 UTC · model grok-4.3
The pith
TwinQuant learns manifold-based transformations to decompose LLM weight matrices into subspaces that reduce 4-bit quantization error.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
TwinQuant learns quantization-friendly decomposed subspaces and jointly reshapes both the low-rank and residual components via a joint optimization over the Stiefel and general linear manifolds, flattening their distributions and reducing dynamic-range imbalance, while using a fused dual-component kernel for efficient execution that preserves near-FP16 accuracy and delivers up to 1.8× end-to-end speedup over an FP16 baseline across LLaMA3 and Qwen3 models.
What carries the argument
Joint optimization over the Stiefel and general linear manifolds that learns component-specific transformations for the low-rank and residual parts of each weight matrix decomposition.
If this is right
- Preserves near-FP16 accuracy in 4-bit quantized versions of LLaMA3 and Qwen3 models.
- Achieves up to 1.8× end-to-end inference speedup over an FP16 baseline.
- Reduces post-quantization error by reshaping both low-rank and residual components rather than minimizing real-valued energy alone.
- Avoids intermediate global-memory traffic through the fused dual-component kernel that pipelines low-rank computation and merges components in a single epilogue.
Where Pith is reading between the lines
- The same manifold-based objective could be tested on 3-bit or 2-bit quantization where dynamic-range problems are even more severe.
- The learned subspaces might transfer across different model families without full retraining of the transformations.
- The approach suggests that any decomposition method whose objective ignores quantization error can be improved by replacing its loss with a post-quantization surrogate.
Load-bearing premise
That subspaces produced by this joint manifold optimization will reduce post-quantization error more effectively than SVD decompositions that only minimize real-valued residual energy.
What would settle it
Run the 4-bit TwinQuant procedure on LLaMA3-8B, measure accuracy on a standard benchmark such as MMLU, and compare both accuracy drop and measured end-to-end latency against the FP16 baseline; a drop larger than 'near-FP16' or failure to reach the claimed speedup would falsify the central claim.
Figures
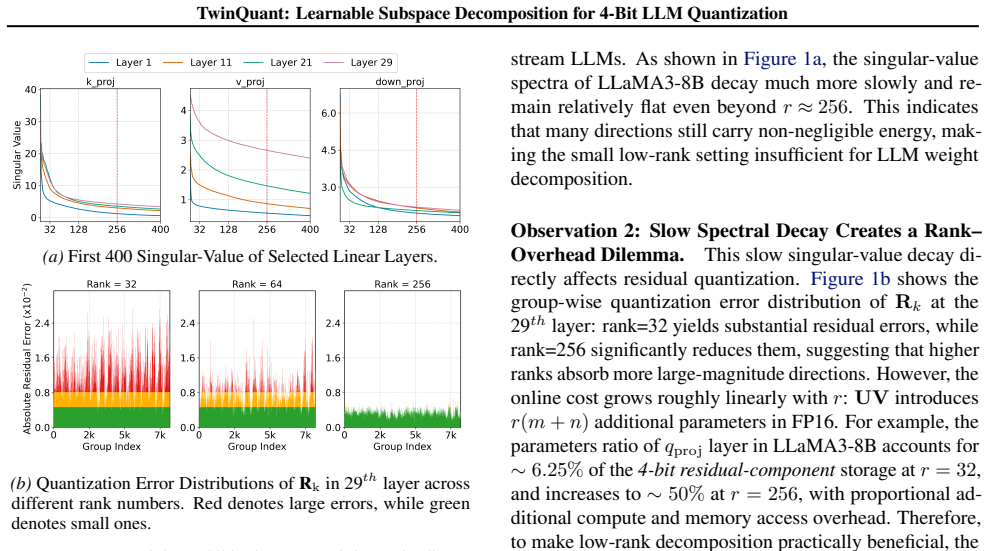
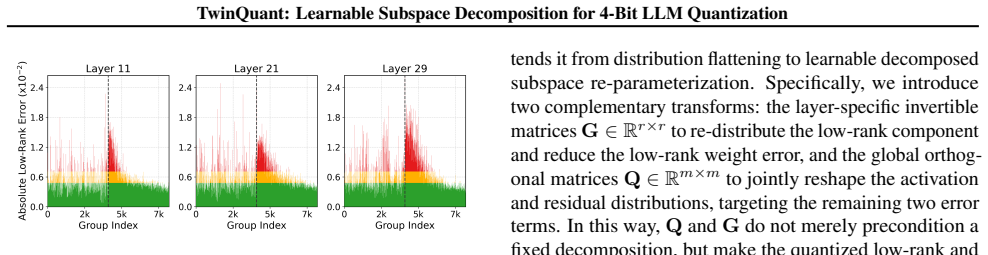
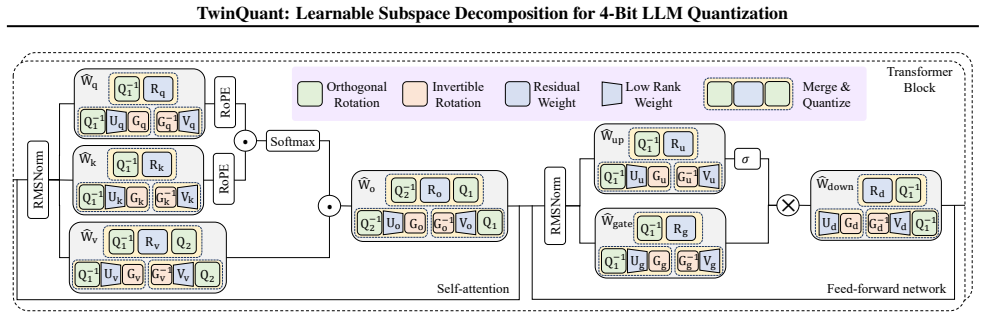

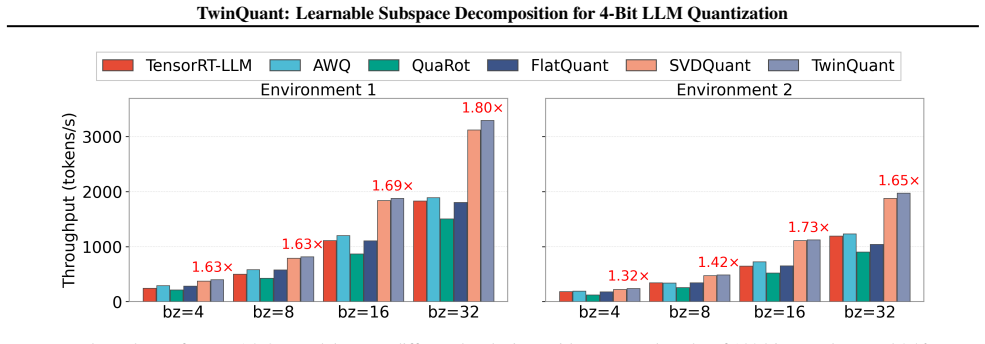
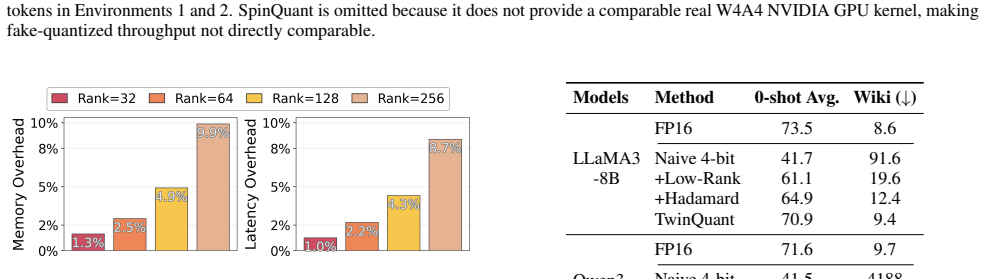
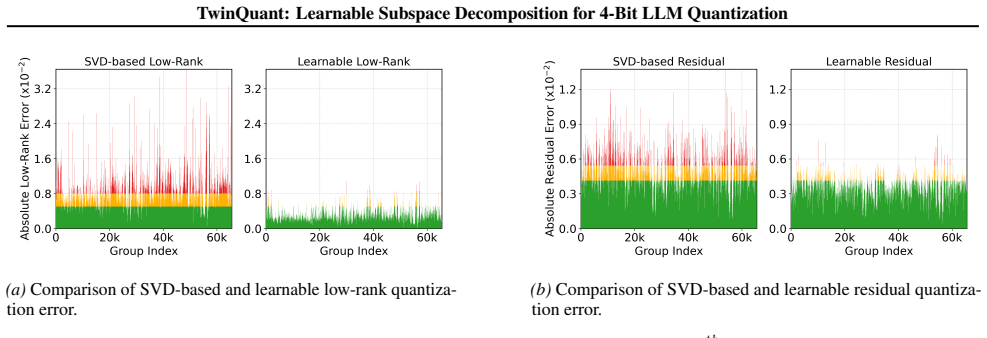
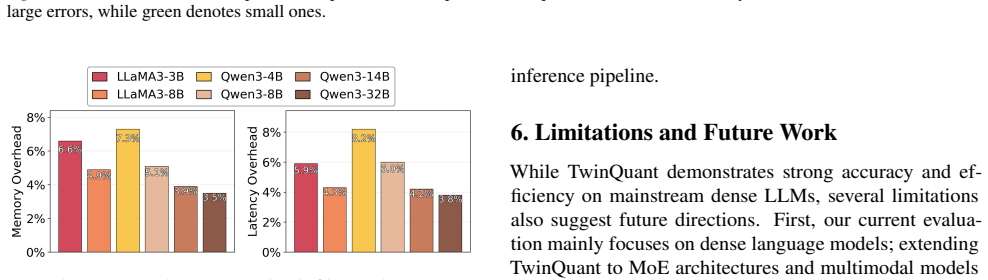
read the original abstract
4-bit quantization reduces the memory footprint and latency of large language model inference, but its aggressive precision reduction can severely degrade accuracy. Prior methods address this by decomposing each weight matrix into two components (e.g., via singular value decomposition) and quantizing them separately, assigning the bulk of values to a low-precision residual component while handling outliers with a high-precision low-rank component. However, such decompositions are designed to minimize the real-valued energy of the residual, rather than the post-quantization error of the residual and low-rank components. We propose TwinQuant, a 4-bit quantization framework that learns quantization-friendly decomposed subspaces and jointly reshapes both the low-rank and residual components. TwinQuant learns component-specific transformations via a joint optimization over the Stiefel and general linear manifolds, flattening their distributions and reducing dynamic-range imbalance. To enable efficient end-to-end execution, we further design a fused dual-component kernel that pipelines the two-stage low-rank computation on-chip and merges both components with a single epilogue, avoiding intermediate global-memory traffic. Across LLaMA3 and Qwen3 models, TwinQuant preserves near-FP16 accuracy and delivers up to $1.8\times$ end-to-end speedup over an FP16 baseline.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces TwinQuant, a 4-bit quantization framework for LLMs that decomposes each weight matrix into low-rank and residual components via learnable component-specific transformations. These are obtained through joint optimization over the Stiefel and general linear manifolds (rather than SVD) to flatten distributions and reduce dynamic-range imbalance, thereby lowering post-quantization error. A fused dual-component kernel is proposed to pipeline the low-rank computation on-chip and merge components with a single epilogue. Experiments on LLaMA3 and Qwen3 models are reported to preserve near-FP16 accuracy while delivering up to 1.8× end-to-end speedup over an FP16 baseline.
Significance. If the central claim holds, the work would demonstrate that manifold-constrained optimization can produce quantization-friendly subspaces superior to energy-minimizing SVD decompositions, addressing a key limitation in prior decomposition-based 4-bit methods. The fused kernel design would additionally provide a practical contribution to efficient inference. The approach is grounded in a concrete contrast between real-valued residual minimization and post-quantization error minimization.
major comments (2)
- [Abstract] Abstract: the central claim requires that joint optimization over the Stiefel and general linear manifolds yields subspaces whose quantized residual plus low-rank error is smaller than that obtained from SVD. No derivation, convergence guarantee, or direct comparison on the 4-bit metric is supplied to establish this; the non-convex joint objective and any surrogate training loss could leave the learned subspaces no better (or worse) than SVD on the actual quantization error.
- [Abstract] The manuscript contrasts the SVD objective (minimize real-valued residual energy) with the proposed manifold optimization but provides no empirical head-to-head evaluation of post-quantization error (or end-to-end accuracy) between the two decompositions on the same models and bit-width; without this, the claimed advantage over prior decomposition methods remains unverified.
Simulated Author's Rebuttal
Thank you for the detailed review. We appreciate the feedback highlighting the need for stronger evidence supporting the advantage of manifold optimization over SVD in reducing post-quantization error. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim requires that joint optimization over the Stiefel and general linear manifolds yields subspaces whose quantized residual plus low-rank error is smaller than that obtained from SVD. No derivation, convergence guarantee, or direct comparison on the 4-bit metric is supplied to establish this; the non-convex joint objective and any surrogate training loss could leave the learned subspaces no better (or worse) than SVD on the actual quantization error.
Authors: We agree that the manuscript lacks a theoretical derivation or convergence guarantee for the non-convex joint optimization. The design is based on the intuition that optimizing directly for quantization error via manifold constraints can yield better subspaces than energy-minimizing SVD. Empirical results demonstrate the effectiveness through model accuracy preservation. To strengthen the claim, we will add a direct comparison of the 4-bit post-quantization error between SVD and TwinQuant decompositions. revision: partial
-
Referee: [Abstract] The manuscript contrasts the SVD objective (minimize real-valued residual energy) with the proposed manifold optimization but provides no empirical head-to-head evaluation of post-quantization error (or end-to-end accuracy) between the two decompositions on the same models and bit-width; without this, the claimed advantage over prior decomposition methods remains unverified.
Authors: While the manuscript reports end-to-end results for TwinQuant and contrasts it with prior SVD-based methods, we acknowledge that an explicit head-to-head on the post-quantization error of the decompositions themselves is not included. We will incorporate such an evaluation in the revised manuscript to directly verify the advantage on the same models and bit-width. revision: yes
- Theoretical derivation or convergence guarantee for the superiority of the manifold optimization on the quantization error metric.
Circularity Check
No circularity: new optimization procedure independent of inputs
full rationale
The provided abstract and description frame TwinQuant as a novel joint optimization over Stiefel and general linear manifolds to learn component-specific transformations that target post-quantization error, explicitly contrasting this with SVD's real-valued residual minimization. No equations, self-citations, or claims reduce the claimed accuracy/speedup benefits to fitted parameters renamed as predictions, self-definitional loops, or load-bearing prior results by the same authors. The central contribution is an empirical procedure whose superiority is asserted via experimental outcomes rather than by construction from its own inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Wan: Open and Advanced Large-Scale Video Generative Models
Wan: Open and Advanced Large-Scale Video Generative Models , author=. arXiv preprint arXiv:2503.20314 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Open-Sora: Democratizing Efficient Video Production for All
Open-sora: Democratizing efficient video production for all , author=. arXiv preprint arXiv:2412.20404 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , year=
STCast: Adaptive Boundary Alignment for Global and Regional Weather Forecasting , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , year=
-
[4]
Proceedings of the 36th International Conference on Neural Information Processing Systems , articleno =
Dettmers, Tim and Lewis, Mike and Belkada, Younes and Zettlemoyer, Luke , title =. Proceedings of the 36th International Conference on Neural Information Processing Systems , articleno =. 2022 , isbn =
2022
-
[5]
Barke, Shraddha and James, Michael B. and Polikarpova, Nadia , title =. 2023 , issue_date =. doi:10.1145/3586030 , journal =
-
[6]
2024 , howpublished=
Black Forest Labs , title=. 2024 , howpublished=
2024
-
[7]
2024 , eprint=
Sana: Efficient High-Resolution Image Synthesis with Linear Diffusion Transformer , author=. 2024 , eprint=
2024
-
[8]
European Conference on Computer Vision (ECCV) , pages=
Pixart- : Weak-to-strong training of diffusion transformer for 4k text-to-image generation , author=. European Conference on Computer Vision (ECCV) , pages=. 2024 , organization=
2024
-
[9]
2025 , howpublished=
ggml-org , title=. 2025 , howpublished=
2025
-
[10]
Xu, Daliang and Zhang, Hao and Yang, Liming and Liu, Ruiqi and Huang, Gang and Xu, Mengwei and Liu, Xuanzhe , title =. 2025 , isbn =. doi:10.1145/3669940.3707239 , booktitle =
-
[11]
Zhao, Tianchen and Fang, Tongcheng and Huang, Haofeng and Liu, Enshu and Wan, Rui and Soedarmadji, Widyadewi and Li, Shiyao and Lin, Zinan and Dai, Guohao and Yan, Shengen and others , booktitle=
-
[12]
European Conference on Computer Vision (ECCV) , pages=
Mixdq: Memory-efficient few-step text-to-image diffusion models with metric-decoupled mixed precision quantization , author=. European Conference on Computer Vision (ECCV) , pages=. 2024 , organization=
2024
-
[13]
International Conference on Learning Representations (ICLR) , year=
SVDQuant: Absorbing Outliers by Low-Rank Components for 4-Bit Diffusion Models , author=. International Conference on Learning Representations (ICLR) , year=
-
[14]
Advances in Neural Information Processing Systems (NeurIPS) , year=
PTQ4DiT: Post-training Quantization for Diffusion Transformers , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[15]
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
Q-DiT: Accurate Post-Training Quantization for Diffusion Transformers , author =. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
-
[16]
GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium , volume =
Heusel, Martin and Ramsauer, Hubert and Unterthiner, Thomas and Nessler, Bernhard and Hochreiter, Sepp , booktitle =. GANs Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium , volume =
-
[17]
International Conference on Neural Information Processing Systems (NeurIPS) , pages=
ImageReward: learning and evaluating human preferences for text-to-image generation , author=. International Conference on Neural Information Processing Systems (NeurIPS) , pages=
-
[18]
CLIPS core: A Reference-free Evaluation Metric for Image Captioning
Hessel, Jack and Holtzman, Ari and Forbes, Maxwell and Le Bras, Ronan and Choi, Yejin. CLIPS core: A Reference-free Evaluation Metric for Image Captioning. Conference on Empirical Methods in Natural Language Processing (EMNLP). 2021
2021
-
[19]
International Conference on Machine Learning (ICML) , pages=
Learning transferable visual models from natural language supervision , author=. International Conference on Machine Learning (ICML) , pages=
-
[20]
European conference on computer vision (ECCV) , pages=
Raft: Recurrent all-pairs field transforms for optical flow , author=. European conference on computer vision (ECCV) , pages=. 2020 , organization=
2020
-
[21]
and Shechtman, Eli and Wang, Oliver , booktitle=
Zhang, Richard and Isola, Phillip and Efros, Alexei A. and Shechtman, Eli and Wang, Oliver , booktitle=. The Unreasonable Effectiveness of Deep Features as a Perceptual Metric , year=
-
[22]
arXiv preprint arXiv:2402.04324 , year=
Consisti2v: Enhancing visual consistency for image-to-video generation , author=. arXiv preprint arXiv:2402.04324 , year=
-
[23]
IEEE/CVF International Conference on Computer Vision (ICCV) , pages=
Exploring video quality assessment on user generated contents from aesthetic and technical perspectives , author=. IEEE/CVF International Conference on Computer Vision (ICCV) , pages=
-
[24]
arXiv preprint arXiv:2104.14806 , year=
Godiva: Generating open-domain videos from natural descriptions , author=. arXiv preprint arXiv:2104.14806 , year=
-
[25]
Structure and Content-Guided Video Synthesis with Diffusion Models , year=
Esser, Patrick and Chiu, Johnathan and Atighehchian, Parmida and Granskog, Jonathan and Germanidis, Anastasis , booktitle=. Structure and Content-Guided Video Synthesis with Diffusion Models , year=
-
[26]
Towards Accurate Generative Models of Video: A New Metric & Challenges
Towards accurate generative models of video: A new metric & challenges , author=. arXiv preprint arXiv:1812.01717 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
Evalcrafter: Benchmarking and evaluating large video generation models , author=. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
-
[28]
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
Vbench: Comprehensive benchmark suite for video generative models , author=. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
-
[29]
Microsoft COCO Captions: Data Collection and Evaluation Server
Microsoft coco captions: Data collection and evaluation server , author=. arXiv preprint arXiv:1504.00325 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
Playground v2.5: Three Insights towards Enhancing Aesthetic Quality in Text-to-Image Generation
Playground v2. 5: Three insights towards enhancing aesthetic quality in text-to-image generation , author=. arXiv preprint arXiv:2402.17245 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
IEEE Trans
Scaling Autoregressive Models for Content-Rich Text-to-Image Generation , author=. IEEE Trans. Mach. Learn. Res. , year=
-
[32]
Scaling rectified flow transformers for high-resolution image synthesis , year =
Esser, Patrick and Kulal, Sumith and Blattmann, Andreas and Entezari, Rahim and M\". Scaling rectified flow transformers for high-resolution image synthesis , year =. International Conference on Machine Learning (ICML) , articleno =
-
[33]
and Mahendran, Aravindh and Yu, Fisher and Oliver, Avital and Huot, Fantine and Bastings, Jasmijn and Collier, Mark Patrick and Gritsenko, Alexey A
Dehghani, Mostafa and Djolonga, Josip and Mustafa, Basil and Padlewski, Piotr and Heek, Jonathan and Gilmer, Justin and Steiner, Andreas and Caron, Mathilde and Geirhos, Robert and Alabdulmohsin, Ibrahim and Jenatton, Rodolphe and Beyer, Lucas and Tschannen, Michael and Arnab, Anurag and Wang, Xiao and Riquelme, Carlos and Minderer, Matthias and Puigcerve...
-
[34]
Improved Video VAE for Latent Video Diffusion Model , year=
Wu, Pingyu and Zhu, Kai and Liu, Yu and Zhao, Liming and Zhai, Wei and Cao, Yang and Zha, Zheng-Jun , booktitle=. Improved Video VAE for Latent Video Diffusion Model , year=
-
[35]
Qwen2.5: A Party of Foundation Models , url =
Qwen Team , month =. Qwen2.5: A Party of Foundation Models , url =
-
[36]
Language Model Beats Diffusion - Tokenizer is key to visual generation , volume =
Yu, Lijun and Lezama, Jos\'. Language Model Beats Diffusion - Tokenizer is key to visual generation , volume =. International Conference on Learning Representations (ICLR) , pages =
-
[37]
Latte: Latent Diffusion Transformer for Video Generation
Latte: Latent diffusion transformer for video generation , author=. arXiv preprint arXiv:2401.03048 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[38]
Scalable Diffusion Models with Transformers , year=
Peebles, William and Xie, Saining , booktitle=. Scalable Diffusion Models with Transformers , year=
-
[39]
DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation , year=
Ruiz, Nataniel and Li, Yuanzhen and Jampani, Varun and Pritch, Yael and Rubinstein, Michael and Aberman, Kfir , booktitle=. DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation , year=
-
[40]
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
Instructvideo: Instructing video diffusion models with human feedback , author=. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
-
[41]
arXiv preprint arXiv:2503.20822 , year=
Synthetic video enhances physical fidelity in video synthesis , author=. arXiv preprint arXiv:2503.20822 , year=
-
[42]
19th USENIX Symposium on Operating Systems Design and Implementation (OSDI 25) , year=
WaferLLM: Large Language Model Inference at Wafer Scale , author=. 19th USENIX Symposium on Operating Systems Design and Implementation (OSDI 25) , year=
-
[43]
AWQ: Activation-aware Weight Quantization for On-Device LLM Compression and Acceleration , volume =
Lin, Ji and Tang, Jiaming and Tang, Haotian and Yang, Shang and Chen, Wei-Ming and Wang, Wei-Chen and Xiao, Guangxuan and Dang, Xingyu and Gan, Chuang and Han, Song , booktitle =. AWQ: Activation-aware Weight Quantization for On-Device LLM Compression and Acceleration , volume =
-
[44]
Nvidia blackwell architecture technical brief , url =
NVIDIA , year =. Nvidia blackwell architecture technical brief , url =
-
[45]
2024 , month =
Intel Architecture Instruction Set Extensions and Future Features Programming Reference , author =. 2024 , month =
2024
-
[46]
Proceedings of Machine Learning and Systems (MLSys) , year =
Zhao, Yilong and Lin, Chien-Yu and Zhu, Kan and Ye, Zihao and Chen, Lequn and Zheng, Size and Ceze, Luis and Krishnamurthy, Arvind and Chen, Tianqi and Kasikci, Baris , title =. Proceedings of Machine Learning and Systems (MLSys) , year =
-
[47]
Proceedings of Machine Learning and Systems (MLSys) , year=
QServe: W4A8KV4 Quantization and System Co-design for Efficient LLM Serving , author=. Proceedings of Machine Learning and Systems (MLSys) , year=
-
[48]
and Li, Bo and Cameron, Pashmina and Jaggi, Martin and Alistarh, Dan and Hoefler, Torsten and Hensman, James , title =
Ashkboos, Saleh and Mohtashami, Amirkeivan and Croci, Maximilian L. and Li, Bo and Cameron, Pashmina and Jaggi, Martin and Alistarh, Dan and Hoefler, Torsten and Hensman, James , title =. 2025 , booktitle =
2025
-
[49]
Svirschevski and Vage Egiazarian and Denis Kuznedelev and Elias Frantar and Saleh Ashkboos and Alexander Borzunov and Torsten Hoefler and Dan Alistarh , booktitle=
Tim Dettmers and Ruslan A. Svirschevski and Vage Egiazarian and Denis Kuznedelev and Elias Frantar and Saleh Ashkboos and Alexander Borzunov and Torsten Hoefler and Dan Alistarh , booktitle=. Sp
-
[50]
Wei Huang and Haotong Qin and Yangdong Liu and Yawei Li and Qinshuo Liu and Xianglong Liu and Luca Benini and Michele Magno and Shiming Zhang and XIAOJUAN QI , booktitle=. SliM-
-
[51]
International Conference on Machine Learning (ICML) , pages=
Smoothquant: Accurate and efficient post-training quantization for large language models , author=. International Conference on Machine Learning (ICML) , pages=
-
[52]
Scaling Vision Transformers , year=
Zhai, Xiaohua and Kolesnikov, Alexander and Houlsby, Neil and Beyer, Lucas , booktitle=. Scaling Vision Transformers , year=
-
[53]
IEEE/CVF international conference on computer vision (CVPR) , pages=
Vivit: A video vision transformer , author=. IEEE/CVF international conference on computer vision (CVPR) , pages=
-
[54]
International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI) , pages=
U-net: Convolutional networks for biomedical image segmentation , author=. International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI) , pages=. 2015 , organization=
2015
-
[55]
2020 , booktitle =
Ho, Jonathan and Jain, Ajay and Abbeel, Pieter , title =. 2020 , booktitle =
2020
-
[56]
Snap Video: Scaled Spatiotemporal Transformers for Text-to-Video Synthesis , year=
Menapace, Willi and Siarohin, Aliaksandr and Skorokhodov, Ivan and Deyneka, Ekaterina and Chen, Tsai-Shien and Kag, Anil and Fang, Yuwei and Stoliar, Aleksei and Ricci, Elisa and Ren, Jian and Tulyakov, Sergey , booktitle=. Snap Video: Scaled Spatiotemporal Transformers for Text-to-Video Synthesis , year=
-
[57]
2022 , booktitle =
Lu, Cheng and Zhou, Yuhao and Bao, Fan and Chen, Jianfei and Li, Chongxuan and Zhu, Jun , title =. 2022 , booktitle =
2022
-
[58]
International Conference on Learning Representations (ICLR) , year=
Fast Sampling of Diffusion Models with Exponential Integrator , author=. International Conference on Learning Representations (ICLR) , year=
-
[59]
2023 , booktitle =
Shih, Andy and Belkhale, Suneel and Ermon, Stefano and Sadigh, Dorsa and Anari, Nima , title =. 2023 , booktitle =
2023
-
[60]
International Conference on Learning Representations (ICLR) , year =
Progressive Distillation for Fast Sampling of Diffusion Models , author=. International Conference on Learning Representations (ICLR) , year =
-
[61]
Latent Consistency Models: Synthesizing High-Resolution Images with Few-Step Inference
Latent consistency models: Synthesizing high-resolution images with few-step inference , author=. arXiv preprint arXiv:2310.04378 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[62]
Proceedings of the 40th International Conference on Machine Learning (ICML) , pages =
Consistency Models , author =. Proceedings of the 40th International Conference on Machine Learning (ICML) , pages =. 2023 , volume =
2023
-
[63]
Proceedings of the AAAI Conference on Artificial Intelligence (AAAI) , volume=
Adaptive guidance: Training-free acceleration of conditional diffusion models , author=. Proceedings of the AAAI Conference on Artificial Intelligence (AAAI) , volume=
-
[64]
IEEE/CVF conference on computer vision and pattern recognition (CVPR) , pages=
Align your latents: High-resolution video synthesis with latent diffusion models , author=. IEEE/CVF conference on computer vision and pattern recognition (CVPR) , pages=
-
[65]
2023 , booktitle =
Li, Yanyu and Wang, Huan and Jin, Qing and Hu, Ju and Chemerys, Pavlo and Fu, Yun and Wang, Yanzhi and Tulyakov, Sergey and Ren, Jian , title =. 2023 , booktitle =
2023
-
[66]
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
DeepCache: Accelerating Diffusion Models for Free , author=. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year=
-
[67]
Cache Me if You Can: Accelerating Diffusion Models through Block Caching , year=
Wimbauer, Felix and Wu, Bichen and Schoenfeld, Edgar and Dai, Xiaoliang and Hou, Ji and He, Zijian and Sanakoyeu, Artsiom and Zhang, Peizhao and Tsai, Sam and Kohler, Jonas and Rupprecht, Christian and Cremers, Daniel and Vajda, Peter and Wang, Jialiang , booktitle=. Cache Me if You Can: Accelerating Diffusion Models through Block Caching , year=
-
[68]
and Kaiser,
Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N. and Kaiser,. Attention is all you need , year =. Proceedings of the 31st International Conference on Neural Information Processing Systems , pages =
-
[69]
Zhihang Yuan and Hanling Zhang and Lu Pu and Xuefei Ning and Linfeng Zhang and Tianchen Zhao and Shengen Yan and Guohao Dai and Yu Wang , booktitle=. Di
-
[70]
arXiv preprint arXiv:2506.03065 , year=
Sparse-vDiT: Unleashing the Power of Sparse Attention to Accelerate Video Diffusion Transformers , author=. arXiv preprint arXiv:2506.03065 , year=
-
[71]
International Conference on Learning Representations (ICLR) , year=
SpinQuant: LLM Quantization with Learned Rotations , author=. International Conference on Learning Representations (ICLR) , year=
-
[72]
Q-Diffusion: Quantizing Diffusion Models , year=
Li, Xiuyu and Liu, Yijiang and Lian, Long and Yang, Huanrui and Dong, Zhen and Kang, Daniel and Zhang, Shanghang and Keutzer, Kurt , booktitle=. Q-Diffusion: Quantizing Diffusion Models , year=
-
[73]
International Conference on Learning Representations (ICLR) , year=
OmniQuant: Omnidirectionally Calibrated Quantization for Large Language Models , author=. International Conference on Learning Representations (ICLR) , year=
-
[74]
Wei, Jianyu and Cao, Shijie and Cao, Ting and Ma, Lingxiao and Wang, Lei and Zhang, Yanyong and Yang, Mao , booktitle=
-
[75]
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[76]
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[77]
Gpt-4 technical report , author=. arXiv preprint arXiv:2303.08774 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[78]
Gemini: A Family of Highly Capable Multimodal Models
Gemini: a family of highly capable multimodal models , author=. arXiv preprint arXiv:2312.11805 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[79]
Nature Medicine , year =
Thirunavukarasu, Arun James and Ting, Darren Shu Jeng and Elangovan, Kabilan and Gutierrez, Laura and Tan, Ting Fang and Ting, Daniel Shu Wei , title =. Nature Medicine , year =
-
[80]
International Conference on Machine Learning (ICML) , year =
FlatQuant: Flatness Matters for LLM Quantization , author=. International Conference on Machine Learning (ICML) , year =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.