Agent System Operations: Categorization, Challenges, and Future Directions
Pith reviewed 2026-06-28 12:12 UTC · model grok-4.3
The pith
Agent systems need the AgentOps framework to categorize anomalies as intra-agent or inter-agent and manage them through four operational stages.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
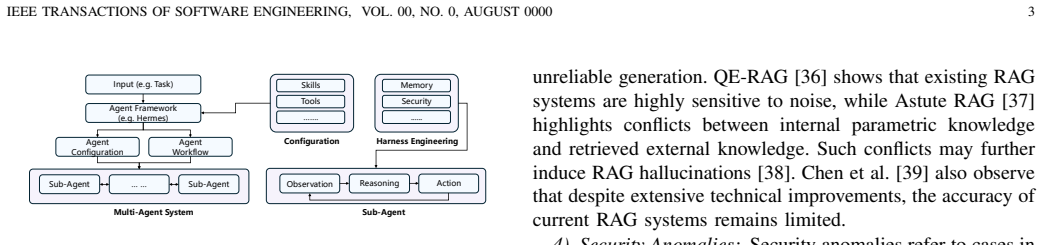
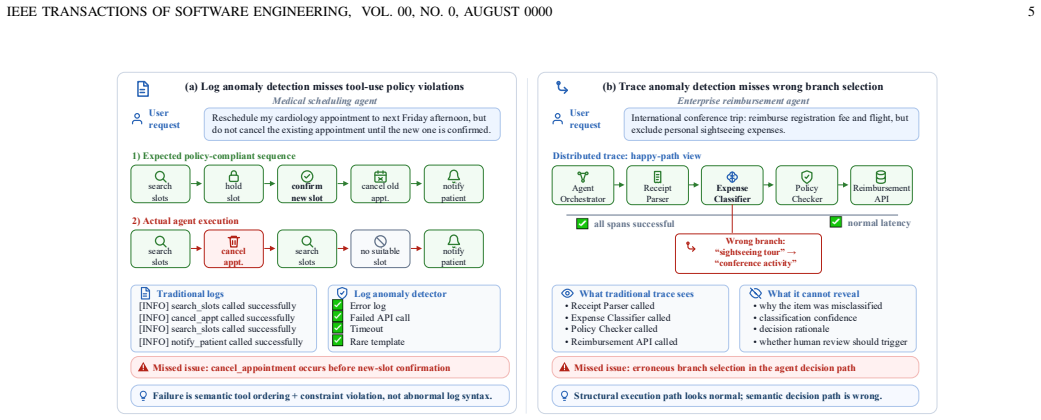
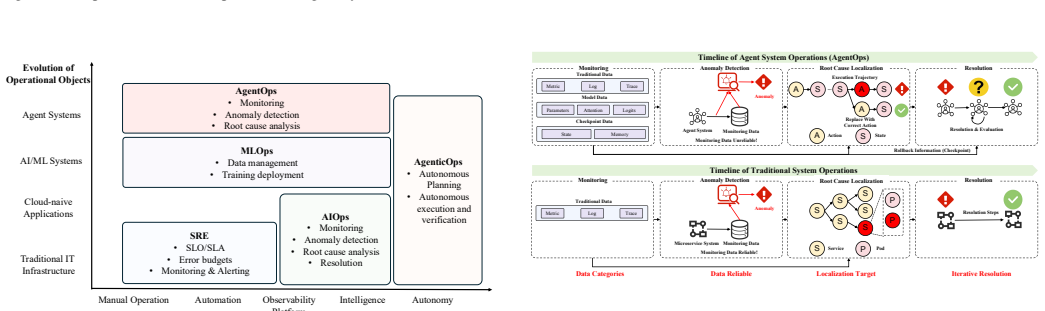
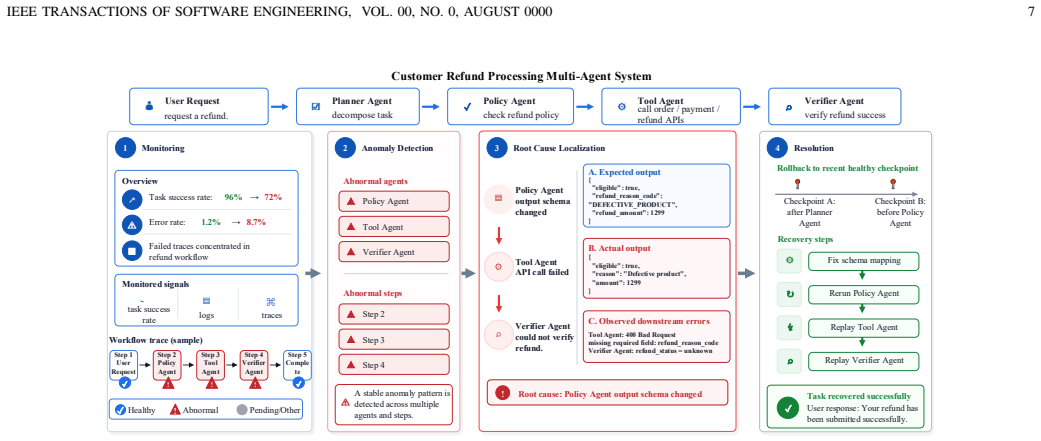
The authors categorize anomalies within agent systems into intra-agent anomalies, which occur within individual agents, and inter-agent anomalies, which emerge from interactions among agents. They introduce the AgentOps framework to structure operations around four stages: monitoring to observe system states, anomaly detection to identify deviations, root cause localization to determine origins of issues, and resolution to apply fixes. This framework is positioned as a comprehensive approach to support stable and secure operation of agent systems.
What carries the argument
The AgentOps framework, which organizes agent system operations into the four stages of monitoring, anomaly detection, root cause localization, and resolution.
If this is right
- The anomaly categorization supplies a shared vocabulary that future studies can use to classify and compare issues across different agent implementations.
- Each of the four AgentOps stages can be developed independently, allowing targeted tools for monitoring or root cause analysis to be built and evaluated.
- Industrial deployments of agent systems can adopt the stages sequentially to reduce instability without requiring entirely new infrastructure.
- The framework highlights specific challenges in each stage, directing research attention toward gaps such as effective resolution methods for inter-agent issues.
Where Pith is reading between the lines
- The intra- versus inter-agent split could be tested by measuring whether resolution success rates differ when failures are isolated to one agent versus spread across several.
- AgentOps might integrate with existing software reliability practices by mapping its stages onto established DevOps pipelines for hybrid systems.
- Quantifying the relative prevalence of intra-agent versus inter-agent anomalies in real deployments would help prioritize which stage of the framework receives the most tooling effort.
Load-bearing premise
Current research on the operations of agent systems is sparse, creating an urgent need for a survey that defines anomalies and establishes the AgentOps framework.
What would settle it
Empirical data from deployed agent systems showing that observed failures fall outside the intra-agent and inter-agent categories or cannot be addressed by the four proposed stages would challenge the framework's coverage.
Figures



read the original abstract
As the reasoning capabilities of Large Language Models (LLMs) continue to advance, LLM-based agent systems offer advantages in flexibility and interpretability over traditional systems, garnering increasing attention. However, despite the widespread research interest and industrial application of agent systems, these systems, like their traditional counterparts, frequently encounter anomalies. These anomalies lead to instability and insecurity, hindering their further development. Therefore, a comprehensive and systematic approach to the operation and maintenance of agent systems is urgently needed. Unfortunately, current research on the operations of agent systems is sparse. To address this gap, we have undertaken a survey on agent system operations with the aim of establishing a clear framework for the field, defining the challenges, and facilitating further development. Specifically, this paper begins by systematically defining anomalies within agent systems, categorizing them into intra-agent anomalies and inter-agent anomalies. Next, we introduce a novel and comprehensive operational framework for agent systems, dubbed Agent System Operations (AgentOps). We provide detailed definitions and explanations of its four key stages: monitoring, anomaly detection, root cause localization, and resolution.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper surveys operations for LLM-based agent systems. It defines anomalies as intra-agent or inter-agent, then proposes a new AgentOps framework whose four stages are monitoring, anomaly detection, root cause localization, and resolution. The work positions itself as filling an urgent gap created by sparse existing research on these operational topics.
Significance. If the sparsity premise holds and the categorization proves comprehensive, the survey could provide a useful organizing lens for reliability work on multi-agent LLM systems. The four-stage breakdown mirrors established DevOps practices while highlighting agent-specific issues such as inter-agent coordination failures.
major comments (1)
- [Abstract / Introduction] Abstract and Introduction: The claim that 'current research on the operations of agent systems is sparse' is presented as the load-bearing motivation for both the survey and the novel AgentOps framework. No systematic literature review or citation count is supplied to substantiate the sparsity assertion. Without this demonstration, the asserted gap, urgency, and novelty of the intra-/inter-agent split and four-stage framework cannot be evaluated.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need to substantiate the sparsity claim that motivates our survey. We address this point directly below and outline revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract / Introduction] Abstract and Introduction: The claim that 'current research on the operations of agent systems is sparse' is presented as the load-bearing motivation for both the survey and the novel AgentOps framework. No systematic literature review or citation count is supplied to substantiate the sparsity assertion. Without this demonstration, the asserted gap, urgency, and novelty of the intra-/inter-agent split and four-stage framework cannot be evaluated.
Authors: We agree that the sparsity assertion is central to the paper's motivation and that a more explicit demonstration would strengthen the work. Our claim derives from a broad review of the literature on LLM-based agents, where the overwhelming majority of publications focus on capability development, prompting techniques, and architectural designs rather than operational concerns such as monitoring, anomaly detection, root-cause analysis, and resolution. However, the manuscript does not include a quantified citation analysis or formal systematic literature review protocol. In the revised version we will add a dedicated subsection (likely in Section 2 or a new Appendix) that documents our search methodology, including databases queried, keywords employed, time window considered, and the approximate ratio of operation-focused papers to the total body of agent research. This addition will allow readers to evaluate the gap claim directly while preserving the intra-/inter-agent categorization and four-stage AgentOps framework as the paper's primary contributions. revision: yes
Circularity Check
No circularity: survey categorization with independent literature premise
full rationale
The paper is a survey that defines anomaly categories (intra-/inter-agent) and introduces the AgentOps framework (monitoring, anomaly detection, root cause localization, resolution) as an organizational structure. No equations, fitted parameters, predictions, or derivations exist. The premise that 'current research on the operations of agent systems is sparse' is an external claim about the literature, not a self-referential reduction or self-citation chain that forces the framework. The central contribution is the categorization itself, which stands as an independent synthesis rather than a renaming or definitional loop. This matches the default expectation for non-circular survey papers.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
D. Guo, D. Yang, H. Zhang, J. Song, R. Zhang, R. Xu, Q. Zhu, S. Ma, P. Wang, X. Biet al., “Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning,”arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Anthropic
A. Anthropic. (2024) The claude 3 model family: Opus, sonnet, haiku. claude-3 model card
2024
-
[3]
Econagent: large language model-empowered agents for simulating macroeconomic activities,
N. Li, C. Gao, M. Li, Y . Li, and Q. Liao, “Econagent: large language model-empowered agents for simulating macroeconomic activities,” 2024
2024
-
[4]
Toolllm: Facilitating large language models to master 16000+ real-world apis,
Y . Qin, S. Liang, Y . Ye, K. Zhu, L. Yan, Y . Lu, Y . Lin, X. Cong, X. Tang, B. Qianet al., “Toolllm: Facilitating large language models to master 16000+ real-world apis,” inThe Twelfth International Con- ference on Learning Representations, 2024
2024
-
[5]
Flow-of-action: Sop enhanced llm-based multi- agent system for root cause analysis,
C. Pei, Z. Wang, F. Liu, Z. Li, Y . Liu, X. He, R. Kang, T. Zhang, J. Chen, J. Liet al., “Flow-of-action: Sop enhanced llm-based multi- agent system for root cause analysis,” inCompanion Proceedings of the ACM on Web Conference 2025, 2025, pp. 422–431
2025
-
[6]
Recommender ai agent: Integrating large language models for interactive recommen- dations,
X. Huang, J. Lian, Y . Lei, J. Yao, D. Lian, and X. Xie, “Recommender ai agent: Integrating large language models for interactive recommen- dations,”ACM Transactions on Information Systems, vol. 43, no. 4, pp. 1–33, 2025
2025
-
[8]
Shielda: Structured handling of exceptions in llm-driven agentic workflows,
J. Zhou, J. Chen, Q. Lu, D. Zhao, and L. Zhu, “Shielda: Structured handling of exceptions in llm-driven agentic workflows,”arXiv preprint arXiv:2508.07935, 2025
-
[9]
(2025) SWE-bench: A benchmark for evaluating software engineering agents
SWE-bench Team. (2025) SWE-bench: A benchmark for evaluating software engineering agents. Leaderboard tracking AI agent performance on software engineering tasks. [Online]. Available: https://www.swebench.com
2025
-
[10]
(2025) Llamatrace — hosted phoenix: Llm tracing & evaluation platform
Arize AI, Inc. (2025) Llamatrace — hosted phoenix: Llm tracing & evaluation platform. [Online]. Available: https://phoenix.arize.com/ll amatrace/
2025
-
[11]
G. Ma, J. Zhu, H. Guo, W. Shi, J. Shen, J. Liu, and Y . Liang, “Automatic failure attribution and critical step prediction method for multi-agent systems based on causal inference,”arXiv preprint arXiv:2509.08682, 2025
-
[12]
Agent-pro: Learning to evolve via policy-level reflection and optimization,
W. Zhang, K. Tang, H. Wu, M. Wang, Y . Shen, G. Hou, Z. Tan, P. Li, Y . Zhuang, and W. Lu, “Agent-pro: Learning to evolve via policy-level reflection and optimization,”arXiv preprint arXiv:2402.17574, 2024
-
[13]
Trial and error: Exploration-based trajectory optimization for llm agents,
Y . Song, D. Yin, X. Yue, J. Huang, S. Li, and B. Y . Lin, “Trial and error: Exploration-based trajectory optimization for llm agents,”arXiv preprint arXiv:2403.02502, 2024
-
[14]
Agent AI: Surveying the Horizons of Multimodal Interaction
Z. Durante, Q. Huang, N. Wake, R. Gong, J. S. Park, B. Sarkaret al., “Agent ai: Surveying the horizons of multimodal interaction,”arXiv preprint arXiv:2401.03568, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Hallucination de- tection in foundation models for decision-making: A flexible definition and review of the state of the art,
N. Chakraborty, M. Ornik, and K. Driggs-Campbell, “Hallucination de- tection in foundation models for decision-making: A flexible definition and review of the state of the art,”ACM Computing Surveys, 2025
2025
-
[16]
Ai agents under threat: A survey of key security challenges and future pathways,
Z. Deng, Y . Guo, C. Han, W. Ma, J. Xiong, S. Wen, and Y . Xiang, “Ai agents under threat: A survey of key security challenges and future pathways,”ACM Computing Surveys, vol. 57, no. 7, pp. 1–36, 2025
2025
-
[17]
Towards trustworthy gui agents: A survey,
Y . Shi, W. Yu, W. Yao, W. Chen, and N. Liu, “Towards trustworthy gui agents: A survey,”arXiv preprint arXiv:2503.23434, 2025
-
[18]
Which agent causes task failures and when? on automated failure attribution of LLM multi-agent systems,
S. Zhang, M. Yin, J. Zhang, J. Liu, Z. Han, J. Zhang, B. Li, C. Wang, H. Wang, Y . Chenet al., “Which agent causes task failures and when? on automated failure attribution of LLM multi-agent systems,” inForty- second International Conference on Machine Learning, 2025
2025
-
[19]
React: Synergizing reasoning and acting in language models,
S. Yao, J. Zhao, D. Yu, N. Du, I. Shafran, K. Narasimhan, and Y . Cao, “React: Synergizing reasoning and acting in language models,” in International Conference on Learning Representations (ICLR), 2023
2023
-
[20]
Finetuned language models are zero-shot learners,
J. Wei, M. Bosma, V . Y . Zhao, K. Guu, A. W. Yu, B. Lester, N. Du, A. M. Dai, and Q. V . Le, “Finetuned language models are zero-shot learners,” inInternational Conference on Learning Representations, 2022
2022
-
[21]
Training language models to follow instructions with human feedback,
L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. Wainwright, P. Mishkin, C. Zhang, S. Agarwal, K. Slama, A. Rayet al., “Training language models to follow instructions with human feedback,”Advances in neural information processing systems, vol. 35, pp. 27 730–27 744, 2022
2022
-
[22]
Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning
B. Jin, H. Zeng, Z. Yue, J. Yoon, S. Arik, D. Wang, H. Zamani, and J. Han, “Search-r1: Training llms to reason and leverage search engines with reinforcement learning,”arXiv preprint arXiv:2503.09516, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
Chain-of-thought prompting elicits reasoning in large language models,
J. Wei, X. Wang, D. Schuurmans, M. Bosma, F. Xia, E. Chi, Q. V . Le, D. Zhouet al., “Chain-of-thought prompting elicits reasoning in large language models,”Advances in neural information processing systems, vol. 35, pp. 24 824–24 837, 2022
2022
-
[24]
Reflexion: Language agents with verbal reinforcement learning,
N. Shinn, F. Cassano, A. Gopinath, K. Narasimhan, and S. Yao, “Reflexion: Language agents with verbal reinforcement learning,” Advances in Neural Information Processing Systems, vol. 36, pp. 8634– 8652, 2023
2023
-
[25]
Self-consistency improves chain of thought rea- soning in language models,
X. Wang, J. Wei, D. Schuurmans, Q. Le, E. Chi, S. Narang, A. Chowd- hery, and D. Zhou, “Self-consistency improves chain of thought rea- soning in language models,” inThe Eleventh International Conference on Learning Representations, 2023
2023
-
[26]
Chain-of-knowledge: Grounding large language models via dynamic knowledge adapting over heterogeneous sources,
X. Li, R. Zhao, Y . K. Chia, B. Ding, S. Joty, S. Poria, and L. Bing, “Chain-of-knowledge: Grounding large language models via dynamic knowledge adapting over heterogeneous sources,” inThe Twelfth In- ternational Conference on Learning Representations, 2024
2024
-
[27]
Take a step back: Evoking reasoning via abstraction in large language models,
H. S. Zheng, S. Mishra, X. Chen, H.-T. Cheng, E. H. Chi, Q. V . Le, and D. Zhou, “Take a step back: Evoking reasoning via abstraction in large language models,” inThe Twelfth International Conference on Learning Representations, 2024
2024
-
[28]
A Survey of Hallucination in Large Foundation Models
V . Rawte, A. Sheth, and A. Das, “A survey of hallucination in large foundation models,”arXiv preprint arXiv:2309.05922, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[29]
Peer review of gpt-4 technical report and systems card,
J. Gallifant, A. Fiske, Y . A. Levites Strekalova, J. S. Osorio-Valencia, R. Parke, R. Mwavu, N. Martinez, J. W. Gichoya, M. Ghassemi, D. Demner-Fushmanet al., “Peer review of gpt-4 technical report and systems card,”PLOS digital health, vol. 3, no. 1, p. e0000417, 2024
2024
-
[30]
Alignment for honesty,
Y . Yang, E. Chern, X. Qiu, G. Neubig, and P. Liu, “Alignment for honesty,”Advances in Neural Information Processing Systems, vol. 37, pp. 63 565–63 598, 2024
2024
-
[31]
Function calling in large language models: Industrial practices, challenges, and future directions,
M. Wang, Y . Zhang, C. Peng, Y . Chen, W. Zhou, J. Gu, C. Zhuang, R. Guo, B. Yu, W. Wanget al., “Function calling in large language models: Industrial practices, challenges, and future directions,” 2025
2025
-
[32]
The dark side of function calling: Pathways to jailbreaking large language models,
Z. Wu, H. Gao, J. He, and P. Wang, “The dark side of function calling: Pathways to jailbreaking large language models,” inProceedings of the 31st International Conference on Computational Linguistics. Associ- ation for Computational Linguistics, Jan. 2024, pp. 584–592
2024
-
[33]
(2025) Ai-infra-guard
Tencent. (2025) Ai-infra-guard. [Online]. Available: https://github.c om/Tencent/AI-Infra-Guard
2025
-
[34]
Lost in the middle: How language models use long con- texts,
N. F. Liu, K. Lin, J. Hewitt, A. Paranjape, M. Bevilacqua, F. Petroni, and P. Liang, “Lost in the middle: How language models use long con- texts,”Transactions of the Association for Computational Linguistics, vol. 12, pp. 157–173, 2024
2024
-
[35]
Unable to forget: Proactive lnterference reveals working memory limits in llms beyond context length,
C. Wang and J. V . Sun, “Unable to forget: Proactive lnterference reveals working memory limits in llms beyond context length,” inICML 2025 Workshop on Long-Context Foundation Models, 2025
2025
-
[36]
Qe-rag: A robust retrieval-augmented generation benchmark for query entry errors,
K. Zhang, Z. Sun, W. Yu, X. Zang, K. Zheng, Y . Song, H. Li, and J. Xu, “Qe-rag: A robust retrieval-augmented generation benchmark for query entry errors,”arXiv preprint arXiv:2504.04062, 2025. IEEE TRANSACTIONS OF SOFTW ARE ENGINEERING, VOL. 00, NO. 0, AUGUST 0000 15
-
[37]
F. Wang, X. Wan, R. Sun, J. Chen, and S. ¨O. Arık, “Astute rag: Overcoming imperfect retrieval augmentation and knowledge conflicts for large language models,”arXiv preprint arXiv:2410.07176, 2024
-
[38]
Redeep: Detecting hallucination in retrieval-augmented gener- ation via mechanistic interpretability,
Z. Sun, X. Zang, K. Zheng, Y . Song, J. Xu, X. Zhang, W. Yu, and H. Li, “Redeep: Detecting hallucination in retrieval-augmented gener- ation via mechanistic interpretability,” inThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[39]
Benchmarking large language models in retrieval-augmented generation,
J. Chen, H. Lin, X. Han, and L. Sun, “Benchmarking large language models in retrieval-augmented generation,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 38, no. 16, 2024, pp. 17 754– 17 762
2024
-
[40]
(2025) Emergent behavior in multi-agent systems: How com- plex behaviors arise from simple agent interactions
Sanjeev. (2025) Emergent behavior in multi-agent systems: How com- plex behaviors arise from simple agent interactions
2025
-
[41]
Agent security bench (asb): Formalizing and benchmarking attacks and defenses in llm-based agents,
H. Zhang, J. Huang, K. Mei, Y . Yao, Z. Wang, C. Zhan, H. Wang, and Y . Zhang, “Agent security bench (asb): Formalizing and benchmarking attacks and defenses in llm-based agents,” inInternational Conference on Learning Representations, vol. 2025, 2025, pp. 35 331–35 366
2025
-
[42]
Why do multiagent systems fail?
M. Z. Pan, M. Cemri, L. A. Agrawal, S. Yang, B. Chopra, R. Tiwari, K. Keutzer, A. Parameswaran, K. Ramchandran, D. Kleinet al., “Why do multiagent systems fail?” inICLR 2025 Workshop on Building Trust in Language Models and Applications, 2025
2025
-
[43]
Emergence in multi-agent systems: A safety perspective,
P. Altmann, J. Sch ¨onberger, S. Illium, M. Zorn, F. Ritz, T. Haider, S. Burton, and T. Gabor, “Emergence in multi-agent systems: A safety perspective,” inInternational Symposium on Leveraging Applications of Formal Methods. Springer, 2024, pp. 104–120
2024
-
[45]
Modeling exception management in multi-agent systems
E. Platonet al., “Modeling exception management in multi-agent systems.” Ph.D. dissertation, Citeseer, 2007
2007
-
[46]
P. D. OG. (2025) Building high-quality ai agent systems: Best practices
2025
-
[47]
Agentfm: Role-aware failure management for distributed databases with llm- driven multi-agents,
L. Zhang, Y . Zhai, T. Jia, X. Huang, C. Duan, and Y . Li, “Agentfm: Role-aware failure management for distributed databases with llm- driven multi-agents,” inProceedings of the 33rd ACM International Conference on the Foundations of Software Engineering, 2025, p. 947–958
2025
-
[48]
A survey on llm- based multi-agent systems: workflow, infrastructure, and challenges,
X. Li, S. Wang, S. Zeng, Y . Wu, and Y . Yang, “A survey on llm- based multi-agent systems: workflow, infrastructure, and challenges,” Vicinagearth, vol. 1, no. 1, p. 9, 2024
2024
-
[49]
Autogen: Enabling next-gen llm applications via multi-agent conversations,
Q. Wu, G. Bansal, J. Zhang, Y . Wu, B. Li, E. Zhu, L. Jiang, X. Zhang, S. Zhang, J. Liuet al., “Autogen: Enabling next-gen llm applications via multi-agent conversations,” inFirst conference on language modeling, 2024
2024
-
[50]
Camel: Communicative agents for
G. Li, H. Hammoud, H. Itani, D. Khizbullin, and B. Ghanem, “Camel: Communicative agents for” mind” exploration of large language model society,”Advances in neural information processing systems, vol. 36, pp. 51 991–52 008, 2023
2023
-
[51]
Bronsdon
C. Bronsdon. (2025) Real-time anomaly detection for multi-agent ai systems
2025
-
[52]
Cut the crap: An economical communication pipeline for llm-based multi-agent systems,
G. Zhang, Y . Yue, Z. Li, S. Yun, G. Wan, K. Wang, D. Cheng, J. X. Yu, and T. Chen, “Cut the crap: An economical communication pipeline for llm-based multi-agent systems,” inThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[53]
Taxonomy of failure mode in agentic ai systems,
Microsoft, “Taxonomy of failure mode in agentic ai systems,” 2025
2025
-
[54]
Smurfs: Multi-agent system using context-efficient dfsdt for tool planning,
J. Chen, J. Liang, and B. Wang, “Smurfs: Multi-agent system using context-efficient dfsdt for tool planning,” inProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), 2025, pp. 3281–3298
2025
-
[55]
Redel: A toolkit for llm- powered recursive multi-agent systems,
A. Zhu, L. Dugan, and C. Callison-Burch, “Redel: A toolkit for llm- powered recursive multi-agent systems,” inProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, 2024, pp. 162–171
2024
-
[56]
S. Drake, “’neural howlround’in large language models: a self- reinforcing bias phenomenon, and a dynamic attenuation solution,” arXiv preprint arXiv:2504.07992, 2025
-
[57]
Devops: a definition and perceived adoption impediments,
J. Smeds, K. Nybom, and I. Porres, “Devops: a definition and perceived adoption impediments,” inInternational conference on agile software development. Springer, 2015, pp. 166–177
2015
-
[58]
Ai for it operations (aiops) on cloud platforms: Reviews, opportunities and challenges,
Q. Cheng, D. Sahoo, A. Saha, W. Yang, C. Liu, G. Woo, M. Singh, S. Saverese, and S. C. Hoi, “Ai for it operations (aiops) on cloud platforms: Reviews, opportunities and challenges,”arXiv preprint arXiv:2304.04661, 2023
-
[59]
What is agentic operations (agenticops)?
Cisco, “What is agentic operations (agenticops)?” https://www.cisco. com/site/us/en/learn/topics/artificial-intelligence/what-is-agentic-opera tions-agenticops.html, 2026, accessed: 2026-05-15
2026
-
[60]
Opentelemetry: A cloud native observability framework,
O. Authors, “Opentelemetry: A cloud native observability framework,” https://opentelemetry.io, 2019
2019
-
[62]
arXiv preprint arXiv:2411.05285 , year=
——, “Agentops: Enabling observability of llm agents,” no. arXiv:2411.05285, Nov. 2024, arXiv:2411.05285 [cs.AI]. [Online]. Available: http://arxiv.org/abs/2411.05285
-
[63]
Architecting agentops needs change,
S. Biswas, H. Bhatt, and K. Vaidhyanathan, “Architecting agentops needs change,” no. arXiv:2601.06456, Jan. 2026, arXiv:2601.06456 [cs.SE]. [Online]. Available: http://arxiv.org/abs/2601.06456
-
[64]
Taming uncertainty via automation: Observing, analyzing, and optimizing agentic ai systems,
D. Moshkovich and S. Zeltyn, “Taming uncertainty via automation: Observing, analyzing, and optimizing agentic ai systems,” no. arXiv:2507.11277, Nov. 2025, arXiv:2507.11277 [cs.AI]. [Online]. Available: http://arxiv.org/abs/2507.11277
-
[65]
Langdb: Llm-enhanced database exploration,
langdb, “Langdb: Llm-enhanced database exploration,” 2025. [Online]. Available: https://github.com/langdb/ai-gateway
2025
-
[66]
Langfuse: Open-source llm tracing and observability,
Langfuse, “Langfuse: Open-source llm tracing and observability,”
-
[67]
Available: https://github.com/langfuse/langfuse
[Online]. Available: https://github.com/langfuse/langfuse
-
[68]
MLflow for GenAI: Build Production-Ready AI Applications,
MLflow Project, a Series of LF Projects, LLC, “MLflow for GenAI: Build Production-Ready AI Applications,” https://mlflow.org/genai, 2025
2025
-
[69]
Helicone: Llm observability platform,
Helicone, “Helicone: Llm observability platform,” 2025. [Online]. Available: https://github.com/Helicone/helicone
2025
-
[70]
Langwatch,
LangWatch, “Langwatch,” 2025. [Online]. Available: https://github.c om/langwatch
2025
-
[71]
(2025) Openllmetry: Open-source observability for your llm application
Traceloop. (2025) Openllmetry: Open-source observability for your llm application. [Online]. Available: https://github.com/traceloop/ope nllmetry
2025
-
[72]
(2025) Arize phoenix: Open-source llm tracing & evaluation platform
Arize AI, Inc. (2025) Arize phoenix: Open-source llm tracing & evaluation platform. [Online]. Available: https://phoenix.arize.com/
2025
-
[73]
(2025) Literal ai: Rag llm evaluation & observability platform
Literal AI, Inc. (2025) Literal ai: Rag llm evaluation & observability platform. [Online]. Available: https://www.literalai.com/
2025
-
[74]
(2025) Opik — open-source llm evaluation platform
Comet ML, Inc. (2025) Opik — open-source llm evaluation platform. [Online]. Available: https://www.comet.com/site/products/opik/
2025
-
[75]
(2025) Openinference: Opentelemetry instrumentation for ai observability
Arize AI, Inc. (2025) Openinference: Opentelemetry instrumentation for ai observability. [Online]. Available: https://github.com/Arize-ai/ openinference
2025
-
[76]
(2025) Trulens: Open-source llm evaluation & observability platform
TruEra Inc. (2025) Trulens: Open-source llm evaluation & observability platform. [Online]. Available: https://www.trulens.org/
2025
-
[77]
(2025) Honeyhive: Ai observability and evaluation platform
HoneyHive AI, Inc. (2025) Honeyhive: Ai observability and evaluation platform. [Online]. Available: https://www.honeyhive.ai/
2025
-
[78]
(2025) Promptlayer: Platform for prompt engineering, management, evaluation, and llm observability
Magniv, Inc. (2025) Promptlayer: Platform for prompt engineering, management, evaluation, and llm observability. [Online]. Available: https://www.promptlayer.com/
2025
-
[79]
(2025) Agentops: Developer platform for ai agent observability
AgentOps.ai. (2025) Agentops: Developer platform for ai agent observability. [Online]. Available: https://www.agentops.ai/
2025
-
[80]
(2024) Deepeval: The llm evaluation framework
confident-ai. (2024) Deepeval: The llm evaluation framework. [Online]. Available: https://github.com/confident-ai/deepeval
2024
-
[81]
LangSmith: The Agent Engineering Platform,
LangChain, “LangSmith: The Agent Engineering Platform,” 2026. [Online]. Available: https://www.langchain.com/langsmith-platform
2026
-
[82]
Mlcapsule: Guarded offline deployment of machine learning as a service,
L. Hanzlik, Y . Zhang, K. Grosse, A. Salem, M. Augustin, M. Backes, and M. Fritz, “Mlcapsule: Guarded offline deployment of machine learning as a service,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 3300–3309
2021
-
[83]
Opera: Alleviating hallucination in multi- modal large language models via over-trust penalty and retrospection- allocation,
Q. Huang, X. Dong, P. Zhang, B. Wang, C. He, J. Wang, D. Lin, W. Zhang, and N. Yu, “Opera: Alleviating hallucination in multi- modal large language models via over-trust penalty and retrospection- allocation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 13 418–13 427
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.