Exploiting Semantic and Pixel Representations for Ultra-Low Bitrate Image Compression
Pith reviewed 2026-06-28 15:49 UTC · model grok-4.3
The pith
A triple-encoder diffusion model compensates for a frozen VAE by fusing semantic and distortion features, improving both pixel fidelity and perceptual quality below 0.03 bpp.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
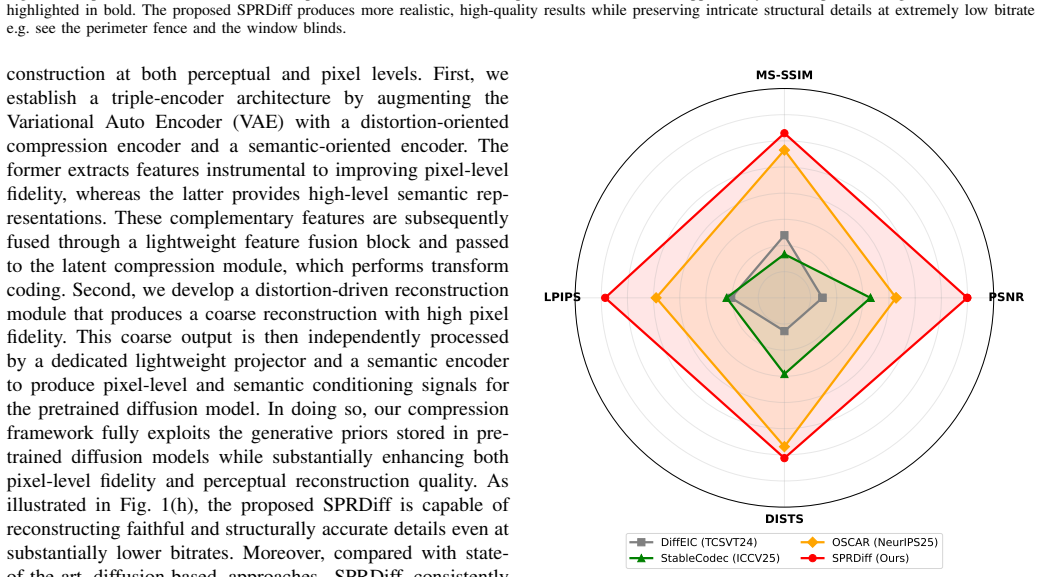
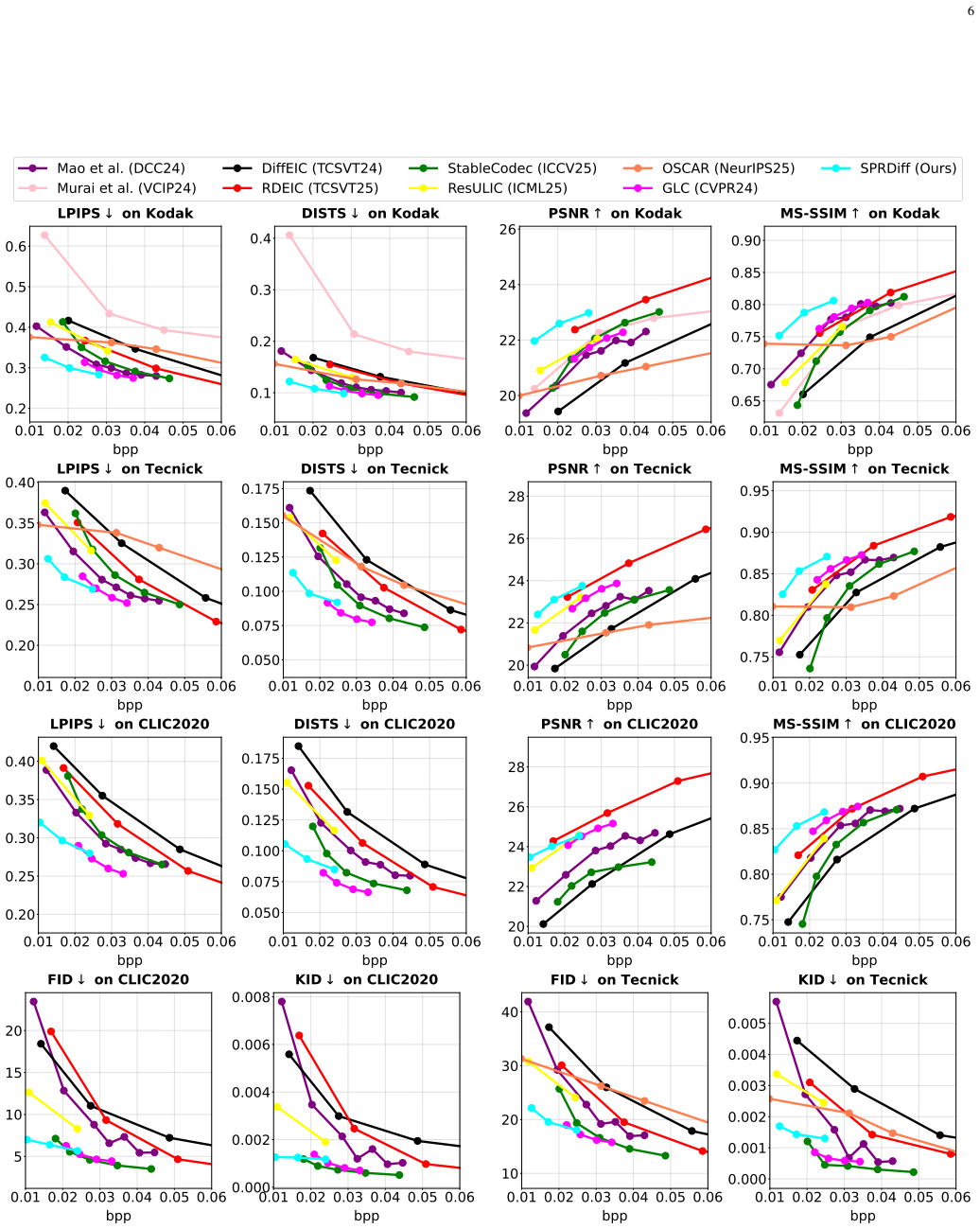
SPRDiff shows that high-fidelity features from pretrained distortion-oriented and semantic-oriented encoders can compensate for the limited representations extracted by a frozen VAE encoder, thereby improving latent compression and entropy modeling, while a distortion-aware reconstruction module supplies accurate conditional signals that let the diffusion model preserve both main structures and fine pixel-level detail at bitrates below 0.03 bpp.
What carries the argument
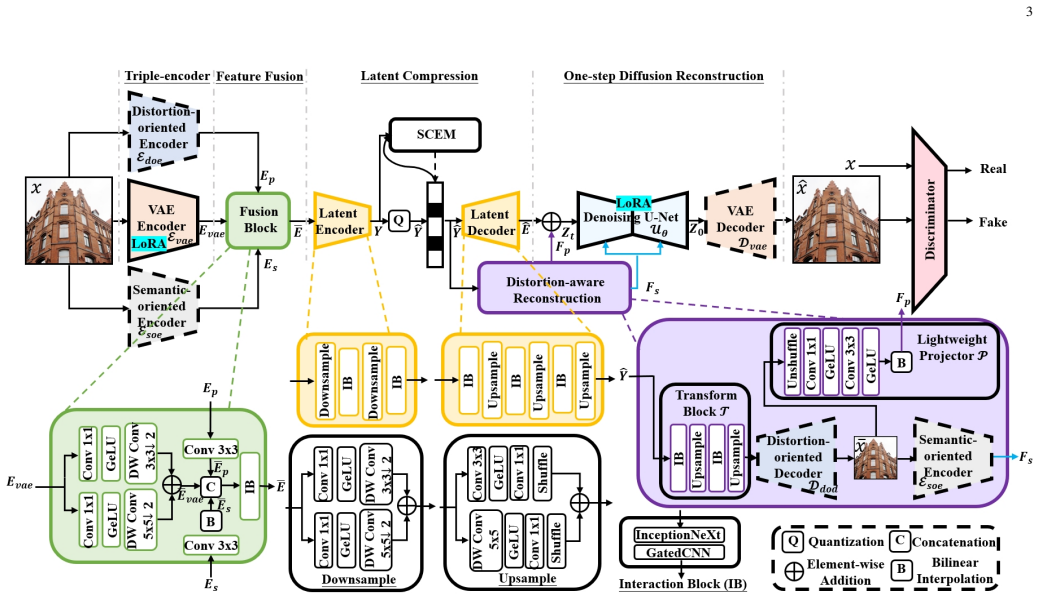
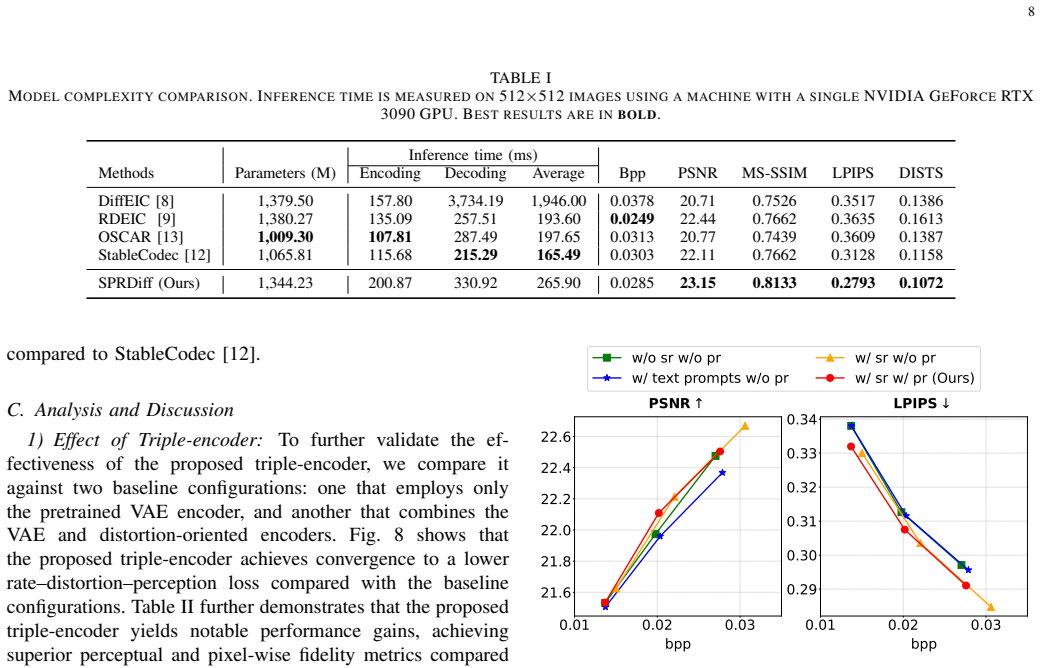
Triple-encoder architecture that fuses features from a frozen VAE encoder with pretrained distortion-oriented and semantic-oriented encoders, paired with a distortion-aware reconstruction module that extracts dual semantic-pixel conditions to guide diffusion reconstruction.
If this is right
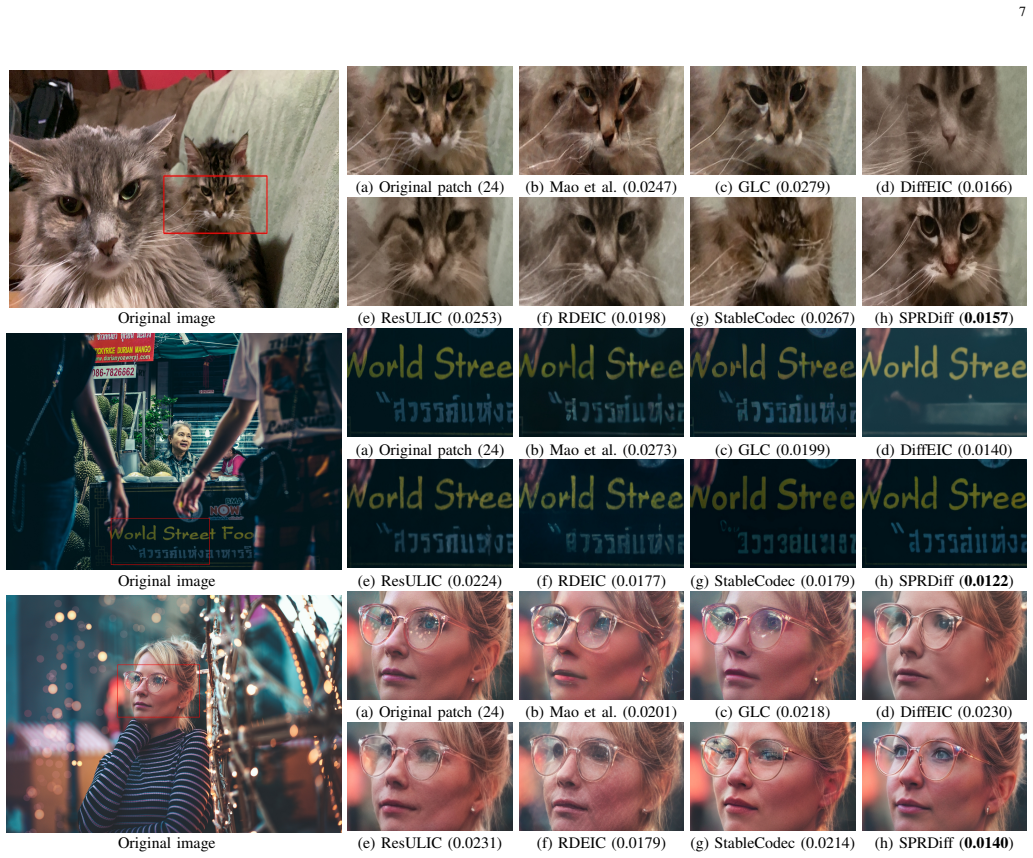
- Images reconstructed below 0.03 bpp retain measurable pixel accuracy while also appearing more realistic than reconstructions from earlier ultra-low-bitrate codecs.
- Latent entropy coding benefits directly from the added semantic and distortion features, lowering the rate needed for a given reconstruction quality.
- The dual-signal conditioning from the distortion-aware module allows the diffusion stage to correct structural errors without introducing new semantic drift.
- The overall rate-distortion-perception surface shifts outward compared with methods that optimize only one or two of the three axes.
Where Pith is reading between the lines
- The same compensation pattern could be tested on other frozen generative backbones, such as those used in video or 3D compression, by swapping in domain-matched semantic encoders.
- If the pretrained encoders are themselves updated on the target domain, the performance gap at ultra-low rates might widen further, offering a route to task-specific extreme compression.
- The explicit separation of coarse structure from fine conditional signals suggests a natural way to add temporal consistency constraints when extending the method to video sequences.
Load-bearing premise
Features from the two pretrained encoders can supply the information missing from the frozen VAE encoder and thereby improve the latent representation used for compression.
What would settle it
Side-by-side evaluation on benchmark images at bitrates strictly below 0.03 bpp measuring whether SPRDiff simultaneously improves both pixel-wise metrics such as PSNR and perceptual metrics such as LPIPS relative to prior methods.
Figures







read the original abstract
Most existing extreme compression methods fail to achieve an optimal rate-distortion-perception trade-off, as they typically prioritize perceptual fidelity and visual realism over pixel-level accuracy. Consequently, the resulting reconstructions often deviate noticeably from the originals. Ultra-low bitrate image compression is therefore crucial-not only for producing extremely compact representations but also for ensuring that reconstructed images remain semantically coherent and faithful to the source at the pixel level. To this end, we propose SPRDiff, a diffusion-based compression method that fully leverages both semantic and pixel representations, thereby enhancing reconstruction fidelity under ultra-low bitrate constraints. Specifically, we develop a triple-encoder architecture that utilizes high-fidelity features from the pretrained distortion-oriented and semantic-oriented encoders to compensate for the limited representations extracted by the frozen VAE encoder, thereby improving latent compression and entropy modeling. To further enhance the reconstruction fidelity of diffusion models, we introduce a distortion-aware reconstruction module with dual feature extraction. This module not only generates a coarse reconstruction that preserves the main structures, but also provides practical and accurate semantic- and pixel-level conditional signals to guide the diffusion model. Extensive experiments on benchmark datasets demonstrate that our method outperforms state-of-the-art approaches in the rate-distortion-perception tradeoff at extremely low bitrates (below 0.03 bpp), effectively preserving both perceptual quality and pixel-wise fidelity in the reconstructed images. We will release the source code and trained models at https://github.com/cshw2021/SPRDiff.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes SPRDiff, a diffusion-based image compression framework that employs a triple-encoder architecture (frozen VAE encoder augmented by pretrained distortion-oriented and semantic-oriented encoders) together with a distortion-aware reconstruction module to improve latent compression, entropy modeling, and diffusion-based decoding. The central claim is that this design yields superior rate-distortion-perception trade-offs at bitrates below 0.03 bpp while preserving both perceptual quality and pixel-wise fidelity, with extensive experiments on benchmark datasets demonstrating outperformance over state-of-the-art methods.
Significance. If the experimental support for the triple-encoder compensation mechanism and the reported RD-P gains holds, the work would address a practically relevant regime of extreme compression where both semantic coherence and pixel accuracy matter, potentially informing future diffusion-based codecs.
major comments (2)
- [Abstract / triple-encoder description] Abstract / method description of the triple-encoder architecture: the assertion that high-fidelity features from the pretrained distortion-oriented and semantic-oriented encoders compensate for the limited representations of the frozen VAE encoder (thereby improving latent compression and entropy modeling) is presented as load-bearing for the claimed gains, yet the provided material contains no ablation study, quantitative contribution analysis, or comparison isolating this compensation effect versus a standard conditional diffusion baseline.
- [Abstract] Abstract: the claim that 'extensive experiments on benchmark datasets demonstrate that our method outperforms state-of-the-art approaches in the rate-distortion-perception tradeoff at extremely low bitrates (below 0.03 bpp)' is made without any reported quantitative results, error bars, dataset statistics, specific baselines, or RD-P curves in the supplied text, rendering the central empirical claim unevaluable.
minor comments (1)
- The manuscript states that source code and trained models will be released; this is a positive step for reproducibility and should be confirmed in the camera-ready version.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and commit to revisions that strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [Abstract / triple-encoder description] Abstract / method description of the triple-encoder architecture: the assertion that high-fidelity features from the pretrained distortion-oriented and semantic-oriented encoders compensate for the limited representations of the frozen VAE encoder (thereby improving latent compression and entropy modeling) is presented as load-bearing for the claimed gains, yet the provided material contains no ablation study, quantitative contribution analysis, or comparison isolating this compensation effect versus a standard conditional diffusion baseline.
Authors: We acknowledge that the manuscript does not contain an ablation that isolates the specific compensation effect of the triple-encoder architecture against a standard conditional diffusion baseline. While the overall rate-distortion-perception results are reported in the experiments section, an explicit quantitative breakdown of each encoder's contribution would make the design rationale more transparent. We will add this ablation study, including comparisons with and without the distortion-oriented and semantic-oriented encoders, in the revised manuscript. revision: yes
-
Referee: [Abstract] Abstract: the claim that 'extensive experiments on benchmark datasets demonstrate that our method outperforms state-of-the-art approaches in the rate-distortion-perception tradeoff at extremely low bitrates (below 0.03 bpp)' is made without any reported quantitative results, error bars, dataset statistics, specific baselines, or RD-P curves in the supplied text, rendering the central empirical claim unevaluable.
Authors: The abstract summarizes the experimental findings without embedding specific numerical values, which is common but can limit immediate evaluability. The full manuscript contains the requested quantitative results, including RD-P curves, dataset details, and comparisons against listed baselines in Section 4. To address the concern directly, we will revise the abstract to include key quantitative highlights (e.g., specific PSNR, LPIPS, and bitrate values) while remaining within length constraints. revision: yes
Circularity Check
No circularity: empirical claims rest on experiments, not self-referential derivations
full rationale
The paper's core claims concern empirical outperformance of SPRDiff on rate-distortion-perception metrics below 0.03 bpp, achieved via a proposed triple-encoder design and distortion-aware module. No equations, fitted parameters, or derivations are shown that reduce these results to inputs by construction (e.g., no self-definitional compensation quantified as a prediction, no self-citation load-bearing uniqueness theorems, and no renaming of known patterns). The compensation assumption is a stated design rationale whose validity is asserted via benchmark results rather than circular logic. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Diffusion models can be effectively conditioned on semantic- and pixel-level signals extracted from a coarse reconstruction to improve fidelity under ultra-low bitrate constraints
Reference graph
Works this paper leans on
-
[1]
The jpeg still picture compression standard,
G. K. Wallace, “The jpeg still picture compression standard,”Commu- nications of the ACM, vol. 34, no. 4, pp. 30–44, 1991
1991
-
[2]
Overview of the versatile video coding (vvc) standard and its applications,
B. Bross, Y .-K. Wang, Y . Ye, S. Liu, J. Chen, G. J. Sullivan, and J.- R. Ohm, “Overview of the versatile video coding (vvc) standard and its applications,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 31, no. 10, pp. 3736–3764, 2021
2021
-
[3]
Learned image compression with mixed transformer-cnn architectures,
J. Liu, H. Sun, and J. Katto, “Learned image compression with mixed transformer-cnn architectures,” inProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, 2023, pp. 14 388– 14 397
2023
-
[4]
Frequency- aware transformer for learned image compression,
H. Li, S. Li, W. Dai, C. Li, J. Zou, and H. Xiong, “Frequency- aware transformer for learned image compression,”arXiv preprint arXiv:2310.16387, 2023
-
[5]
Improving statistical fidelity for neural image compression with im- plicit local likelihood models,
M. J. Muckley, A. El-Nouby, K. Ullrich, H. J ´egou, and J. Verbeek, “Improving statistical fidelity for neural image compression with im- plicit local likelihood models,” inInternational Conference on Machine Learning. PMLR, 2023, pp. 25 426–25 443
2023
-
[6]
Generative latent coding for ultra-low bitrate image compression,
Z. Jia, J. Li, B. Li, H. Li, and Y . Lu, “Generative latent coding for ultra-low bitrate image compression,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 26 088–26 098. 10
2024
-
[7]
A lightweight model for perceptual image compression via implicit priors,
H. Wei, Y . Zhou, Y . Jia, C. Ge, S. Anwar, and A. Mian, “A lightweight model for perceptual image compression via implicit priors,”Neural Networks, p. 108279, 2025. [Online]. Available: https://www.sciencedirect.com/science/article/pii/S0893608025011608
2025
-
[8]
Towards extreme image compression with latent feature guidance and diffusion prior,
Z. Li, Y . Zhou, H. Wei, C. Ge, and J. Jiang, “Towards extreme image compression with latent feature guidance and diffusion prior,”IEEE Transactions on Circuits and Systems for Video Technology, 2024
2024
-
[9]
Rdeic: Accelerating diffusion-based extreme image compression with relay residual diffu- sion,
Z. Li, Y . Zhou, H. Wei, C. Ge, and A. Mian, “Rdeic: Accelerating diffusion-based extreme image compression with relay residual diffu- sion,”IEEE Transactions on Circuits and Systems for Video Technology, 2025
2025
-
[10]
J. Song, L. Yang, and M. Feng, “Extremely low-bitrate image com- pression semantically disentangled by lmms from a human perception perspective,”arXiv preprint arXiv:2503.00399, 2025
-
[11]
High- resolution image synthesis with latent diffusion models,
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer, “High- resolution image synthesis with latent diffusion models,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 10 684–10 695
2022
-
[12]
Stablecodec: Taming one-step diffusion for extreme image compression,
T. Zhang, X. Luo, L. Li, and D. Liu, “Stablecodec: Taming one-step diffusion for extreme image compression,”arXiv preprint arXiv:2506.21977, 2025
-
[13]
Oscar: One-step diffusion codec across multiple bit-rates,
J. Guo, Y . Ji, Z. Chen, K. Liu, M. Liu, W. Rao, W. Li, Y . Guo, and Y . Zhang, “Oscar: One-step diffusion codec across multiple bit-rates,” arXiv preprint arXiv:2505.16091, 2025
-
[14]
Steering one-step diffusion model with fidelity-rich decoder for fast image compression,
Z. Chen, M. Zhou, J. Guo, J. Yuan, Y . Ji, and Y . Zhang, “Steering one-step diffusion model with fidelity-rich decoder for fast image compression,”arXiv preprint arXiv:2508.04979, 2025
-
[15]
Diffpc: Diffusion-based high perceptual fidelity image compression with semantic refinement,
Y . Xia, Y . Zhou, J. Wang, B. An, H. Wang, Y . Wang, and B. Chen, “Diffpc: Diffusion-based high perceptual fidelity image compression with semantic refinement,” inThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[16]
Elic: Efficient learned image compression with unevenly grouped space- channel contextual adaptive coding,
D. He, Z. Yang, W. Peng, R. Ma, H. Qin, and Y . Wang, “Elic: Efficient learned image compression with unevenly grouped space- channel contextual adaptive coding,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 5718– 5727
2022
-
[17]
T. M. Cover,Elements of information theory. John Wiley & Sons, 1999
1999
-
[18]
End-to-end optimized image compression,
J. Ball ´e, V . Laparra, and E. P. Simoncelli, “End-to-end optimized image compression,” inInternational Conference on Learning Representations, 2017
2017
-
[19]
Learned image com- pression with discretized gaussian mixture likelihoods and attention modules,
Z. Cheng, H. Sun, M. Takeuchi, and J. Katto, “Learned image com- pression with discretized gaussian mixture likelihoods and attention modules,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 7939–7948
2020
-
[20]
Enhanced invertible encoding for learned image compression,
Y . Xie, K. L. Cheng, and Q. Chen, “Enhanced invertible encoding for learned image compression,” inProceedings of the 29th ACM international conference on multimedia, 2021, pp. 162–170
2021
-
[21]
The devil is in the details: Window- based attention for image compression,
R. Zou, C. Song, and Z. Zhang, “The devil is in the details: Window- based attention for image compression,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 17 492–17 501
2022
-
[22]
Llic: Large receptive field transform coding with adaptive weights for learned image compression,
W. Jiang, P. Ning, J. Yang, Y . Zhai, F. Gao, and R. Wang, “Llic: Large receptive field transform coding with adaptive weights for learned image compression,”IEEE Transactions on Multimedia, vol. 26, pp. 10 937– 10 951, 2024
2024
-
[23]
Mambaic: State space models for high-performance learned image compression,
F. Zeng, H. Tang, Y . Shao, S. Chen, L. Shao, and Y . Wang, “Mambaic: State space models for high-performance learned image compression,” inProceedings of the Computer Vision and Pattern Recognition Confer- ence, 2025, pp. 18 041–18 050
2025
-
[24]
Linear attention modeling for learned image compression,
D. Feng, Z. Cheng, S. Wang, R. Wu, H. Hu, G. Lu, and L. Song, “Linear attention modeling for learned image compression,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 7623–7632
2025
-
[25]
Joint autoregressive and hierarchical priors for learned image compression,
D. Minnen, J. Ball ´e, and G. D. Toderici, “Joint autoregressive and hierarchical priors for learned image compression,”Advances in neural information processing systems, vol. 31, 2018
2018
-
[26]
Causal contextual prediction for learned image compression,
Z. Guo, Z. Zhang, R. Feng, and Z. Chen, “Causal contextual prediction for learned image compression,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 32, no. 4, pp. 2329–2341, 2021
2021
-
[27]
Checkerboard context model for efficient learned image compression,
D. He, Y . Zheng, B. Sun, Y . Wang, and H. Qin, “Checkerboard context model for efficient learned image compression,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 14 771–14 780
2021
-
[28]
Channel-wise autoregressive entropy models for learned image compression,
D. Minnen and S. Singh, “Channel-wise autoregressive entropy models for learned image compression,” in2020 IEEE International Conference on Image Processing (ICIP). IEEE, 2020, pp. 3339–3343
2020
-
[29]
Mlic: Multi- reference entropy model for learned image compression,
W. Jiang, J. Yang, Y . Zhai, P. Ning, F. Gao, and R. Wang, “Mlic: Multi- reference entropy model for learned image compression,” inProceedings of the 31st ACM International Conference on Multimedia, 2023, pp. 7618–7627
2023
-
[30]
Mlic++: Linear com- plexity multi-reference entropy modeling for learned image compres- sion,
W. Jiang, J. Yang, Y . Zhai, F. Gao, and R. Wang, “Mlic++: Linear com- plexity multi-reference entropy modeling for learned image compres- sion,”ACM Transactions on Multimedia Computing, Communications and Applications, vol. 21, no. 5, pp. 1–25, 2025
2025
-
[31]
Learned image compression with dictionary-based entropy model,
J. Lu, L. Zhang, X. Zhou, M. Li, W. Li, and S. Gu, “Learned image compression with dictionary-based entropy model,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 12 850–12 859
2025
-
[32]
Rethinking lossy compression: The rate- distortion-perception tradeoff,
Y . Blau and T. Michaeli, “Rethinking lossy compression: The rate- distortion-perception tradeoff,” inInternational Conference on Machine Learning. PMLR, 2019, pp. 675–685
2019
-
[33]
High- fidelity generative image compression,
F. Mentzer, G. D. Toderici, M. Tschannen, and E. Agustsson, “High- fidelity generative image compression,”Advances in neural information processing systems, vol. 33, pp. 11 913–11 924, 2020
2020
-
[34]
Multi-realism image compression with a conditional generator,
E. Agustsson, D. Minnen, G. Toderici, and F. Mentzer, “Multi-realism image compression with a conditional generator,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 22 324–22 333
2023
-
[35]
Neural image compression with text-guided encoding for both pixel-level and perceptual fidelity,
H. Lee, M. Kim, J.-H. Kim, S. Kim, D. Oh, and J. Lee, “Neural image compression with text-guided encoding for both pixel-level and perceptual fidelity,”arXiv preprint arXiv:2403.02944, 2024
-
[36]
A resid- ual diffusion model for high perceptual quality codec augmentation,
N. F. Ghouse, J. Petersen, A. Wiggers, T. Xu, and G. Sautiere, “A resid- ual diffusion model for high perceptual quality codec augmentation,” arXiv preprint arXiv:2301.05489, 2023
-
[37]
Consistency guided dif- fusion model with neural syntax for perceptual image compression,
H. Kuang, Y . Ma, W. Yang, Z. Guo, and J. Liu, “Consistency guided dif- fusion model with neural syntax for perceptual image compression,” in Proceedings of the 32nd ACM International Conference on Multimedia, 2024, pp. 1622–1631
2024
-
[38]
Controllable distortion-perception tradeoff through latent diffusion for neural image compression,
C. Zhou, G. Lu, J. Li, X. Chen, Z. Cheng, L. Song, and W. Zhang, “Controllable distortion-perception tradeoff through latent diffusion for neural image compression,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 10, 2025, pp. 10 725–10 733
2025
-
[39]
Lossy image compression with conditional diffusion models,
R. Yang and S. Mandt, “Lossy image compression with conditional diffusion models,”Advances in Neural Information Processing Systems, vol. 36, pp. 64 971–64 995, 2023
2023
-
[40]
Correcting diffusion-based perceptual image compression with privileged end-to-end decoder,
Y . Ma, W. Yang, and J. Liu, “Correcting diffusion-based perceptual image compression with privileged end-to-end decoder,” inProceedings of the 41st International Conference on Machine Learning, 2024, pp. 34 075–34 093
2024
-
[41]
Multi-modality deep network for extreme learned image compression,
X. Jiang, W. Tan, T. Tan, B. Yan, and L. Shen, “Multi-modality deep network for extreme learned image compression,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 37, no. 1, 2023, pp. 1033–1041
2023
-
[42]
Towards image compression with perfect realism at ultra-low bitrates,
M. Careil, M. J. Muckley, J. Verbeek, and S. Lathuili`ere, “Towards image compression with perfect realism at ultra-low bitrates,” inThe Twelfth International Conference on Learning Representations, 2023
2023
-
[43]
Text+ sketch: Image compression at ultra low rates,
E. Lei, Y . B. Uslu, H. Hassani, and S. S. Bidokhti, “Text+ sketch: Image compression at ultra low rates,”arXiv preprint arXiv:2307.01944, 2023
-
[44]
Misc: Ultra-low bitrate image semantic compression driven by large multimodal model,
C. Li, G. Lu, D. Feng, H. Wu, Z. Zhang, X. Liu, G. Zhai, W. Lin, and W. Zhang, “Misc: Ultra-low bitrate image semantic compression driven by large multimodal model,”IEEE Transactions on Image Processing, 2024
2024
-
[45]
Linearly transformed color guide for low- bitrate diffusion based image compression,
T. Bordin and T. Maugey, “Linearly transformed color guide for low- bitrate diffusion based image compression,”IEEE Transactions on Image Processing, 2024
2024
-
[46]
Extreme image compression using fine-tuned vqgans,
Q. Mao, T. Yang, Y . Zhang, Z. Wang, M. Wang, S. Wang, L. Jin, and S. Ma, “Extreme image compression using fine-tuned vqgans,” in2024 Data Compression Conference (DCC). IEEE, 2024, pp. 203–212
2024
-
[47]
Taming transformers for high- resolution image synthesis,
P. Esser, R. Rombach, and B. Ommer, “Taming transformers for high- resolution image synthesis,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 12 873–12 883
2021
-
[48]
Toward extreme image rescaling with generative prior and invertible prior,
H. Wei, C. Ge, Z. Li, X. Qiao, and P. Deng, “Toward extreme image rescaling with generative prior and invertible prior,”IEEE Transactions on Circuits and Systems for Video Technology, vol. 34, no. 7, pp. 6181– 6193, 2024
2024
-
[49]
Hybridflow: Infusing continuity into masked codebook for extreme low-bitrate image compression,
L. Lu, Y . Xie, W. Jiang, W. Wang, X. Lin, and Y . Wang, “Hybridflow: Infusing continuity into masked codebook for extreme low-bitrate image compression,” inProceedings of the 32nd ACM International Conference on Multimedia, 2024, pp. 3010–3018
2024
-
[50]
Dlf: Extreme image compression with dual-generative latent fusion,
N. Xue, Z. Jia, J. Li, B. Li, Y . Zhang, and Y . Lu, “Dlf: Extreme image compression with dual-generative latent fusion,”arXiv preprint arXiv:2503.01428, 2025. 11
-
[51]
Lmm-driven semantic image-text coding for ultra low-bitrate learned image compression,
S. Murai, H. Sun, and J. Katto, “Lmm-driven semantic image-text coding for ultra low-bitrate learned image compression,” in2024 IEEE Inter- national Conference on Visual Communications and Image Processing (VCIP). IEEE, 2024, pp. 1–5
2024
-
[52]
Ultra lowrate image compression with semantic residual coding and compression-aware diffusion,
A. Ke, X. Zhang, T. Chen, M. Lu, C. Zhou, J. Gu, and Z. Ma, “Ultra lowrate image compression with semantic residual coding and compression-aware diffusion,”arXiv preprint arXiv:2505.08281, 2025
-
[53]
Diffo: Single-step diffusion for image compression at ultra-low bitrates,
C. Park, J. C. Lee, and J. H. Ko, “Diffo: Single-step diffusion for image compression at ultra-low bitrates,”arXiv preprint arXiv:2506.16572, 2025
-
[54]
Adversarial diffusion distillation,
A. Sauer, D. Lorenz, A. Blattmann, and R. Rombach, “Adversarial diffusion distillation,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 87–103
2024
-
[55]
Inceptionnext: When inception meets convnext,
W. Yu, P. Zhou, S. Yan, and X. Wang, “Inceptionnext: When inception meets convnext,” inProceedings of the IEEE/cvf conference on computer vision and pattern recognition, 2024, pp. 5672–5683
2024
-
[56]
Mambaout: Do we really need mamba for vision?
W. Yu and X. Wang, “Mambaout: Do we really need mamba for vision?” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 4484–4496
2025
-
[57]
Lsdir: A large scale dataset for image restoration,
Y . Li, K. Zhang, J. Liang, J. Cao, C. Liu, R. Gong, Y . Zhang, H. Tang, Y . Liu, D. Demandolxet al., “Lsdir: A large scale dataset for image restoration,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 1775–1787
2023
-
[58]
A unified end-to-end framework for efficient deep image compression,
J. Liu, G. Lu, Z. Hu, and D. Xu, “A unified end-to-end framework for efficient deep image compression,”arXiv preprint arXiv:2002.03370, 2020
-
[59]
Kodak photocd dataset,
R. Franzen, “Kodak photocd dataset,” 1999. [Online]. Available: http://r0k.us/graphics/kodak/
1999
-
[60]
Clic 2020: Challenge on learned image compression,
G. Toderici, L. Theis, N. Johnston, E. Agustsson, F. Mentzer, J. Ball ´e, W. Shi, and R. Timofte, “Clic 2020: Challenge on learned image compression,” 2020
2020
-
[61]
Testimages: a large-scale archive for testing visual devices and basic image processing algorithms
N. Asuni and A. Giachetti, “Testimages: a large-scale archive for testing visual devices and basic image processing algorithms.” inSTAG, 2014, pp. 63–70
2014
-
[62]
The unreasonable effectiveness of deep features as a perceptual metric,
R. Zhang, P. Isola, A. A. Efros, E. Shechtman, and O. Wang, “The unreasonable effectiveness of deep features as a perceptual metric,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 586–595
2018
-
[63]
Image quality assessment: Unifying structure and texture similarity,
K. Ding, K. Ma, S. Wang, and E. P. Simoncelli, “Image quality assessment: Unifying structure and texture similarity,”IEEE transactions on pattern analysis and machine intelligence, vol. 44, no. 5, pp. 2567– 2581, 2020
2020
-
[64]
Gans trained by a two time-scale update rule converge to a local nash equilibrium,
M. Heusel, H. Ramsauer, T. Unterthiner, B. Nessler, and S. Hochreiter, “Gans trained by a two time-scale update rule converge to a local nash equilibrium,”Advances in neural information processing systems, vol. 30, 2017
2017
-
[65]
M. Bi ´nkowski, D. J. Sutherland, M. Arbel, and A. Gretton, “Demysti- fying mmd gans,”arXiv preprint arXiv:1801.01401, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[66]
Multiscale structural similarity for image quality assessment,
Z. Wang, E. P. Simoncelli, and A. C. Bovik, “Multiscale structural similarity for image quality assessment,” inThe thrity-seventh asilomar conference on signals, systems & computers, 2003, vol. 2. Ieee, 2003, pp. 1398–1402
2003
-
[67]
Lora: Low-rank adaptation of large language models
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, W. Chenet al., “Lora: Low-rank adaptation of large language models.” ICLR, vol. 1, no. 2, p. 3, 2022
2022
-
[68]
Dinov2: Learning robust visual features without supervision,
M. Oquab, T. Darcet, T. Moutakanni, H. V o, M. Szafraniec, V . Khalidov, P. Fernandez, D. Haziza, F. Massa, A. El-Noubyet al., “Dinov2: Learning robust visual features without supervision,”Transactions on Machine Learning Research Journal, 2024
2024
-
[69]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clarket al., “Learning transferable visual models from natural language supervision,” inInternational conference on machine learning, 2021, pp. 8748–8763. Hao Weiis currently a Ph.D. candidate with the Institute of Artificial Intelligence and Robotics at...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.