Pave-GRPO: Beyond Instantaneous Guidance through Principled Average Velocity Decomposition
Pith reviewed 2026-06-28 15:31 UTC · model grok-4.3
The pith
Pave-GRPO decomposes each coarse transition into finer sub-trajectories so the same few-step samples supervise many more denoising stages in flow model alignment.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
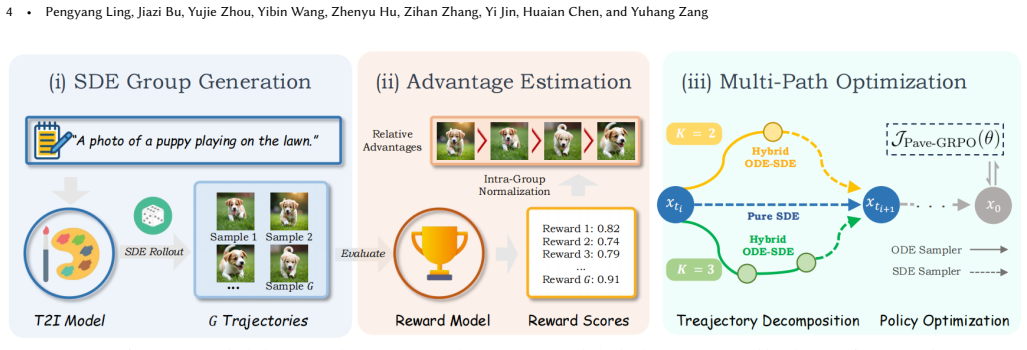
Rather than generating high-step rollouts, Pave-GRPO maintains efficient few-step group sampling but decomposes each coarse transition into an equivalent ensemble of finer sub-trajectories spanning multiple intermediate timesteps; this distributes reward signals across more stages of the denoising process and enables finer-grained preference optimization without additional generation cost.
What carries the argument
Principled average velocity decomposition, the reformulation that treats each instantaneous velocity target as a multi-timestep ensemble while preserving the original policy gradient and reward associations.
If this is right
- The same few-step group samples now supervise a much larger fraction of the denoising trajectory.
- Effective optimization horizon expands under a fixed sampling budget.
- Reward feedback reaches intermediate stages that previously received no direct supervision.
- Performance gains appear across different reward models without raising generation cost.
Where Pith is reading between the lines
- The same decomposition idea could be tested in diffusion or autoregressive models that also face step-cost trade-offs.
- If the equivalence holds, longer-horizon tasks such as video generation might adopt the method without proportional increases in rollout expense.
- The approach suggests a general pattern for turning sparse temporal supervision into dense supervision inside any iterative generative process.
Load-bearing premise
The decomposition of each coarse transition into an equivalent ensemble of finer sub-trajectories preserves the original policy gradient and reward associations exactly.
What would settle it
Compute the policy gradient on the original few-step trajectories and again on the decomposed multi-timestep ensembles; any systematic mismatch in the resulting updates would falsify the claimed equivalence.
Figures



read the original abstract
Post-training via Group Relative Policy Optimization (GRPO) has emerged as a powerful paradigm for aligning flow-based generative models with human preferences. However, the iterative denoising nature of flow models incurs substantial costs when generating group rollouts for policy-gradient updates, compelling existing methods to train with extremely few denoising steps. This temporal sparsity severely restricts preference optimization: reward feedback can only reach a handful of stages per trajectory, leaving the vast majority of intermediate denoising steps without direct supervision and thus compromising alignment granularity. To address this, we propose Pave-GRPO, which reformulates the GRPO objective through Principled average velocity decomposition. Rather than generating expensive high-step rollouts, we maintain efficient few-step group sampling but decompose each coarse transition into an equivalent ensemble of finer sub-trajectories spanning multiple intermediate timesteps. This propagates reward feedback to a denser set of temporal stages for more comprehensive preference alignment without additional generation cost. This design offers two benefits: (i) zero-cost horizon expansion: through the direct reuse of piece-wise group samples and their associated rewards, Pave-GRPO significantly broadens the effective optimization scope under fixed sampling budgets; and (ii) comprehensive temporal supervision: by equivalently decomposing an instantaneous velocity target into a multi-timestep ensemble, it distributes reward signals across more intermediate stages of the denoising process, enabling finer-grained and more thorough preference optimization. Extensive experiments validate that Pave-GRPO effectively advances preference alignment across different reward settings, offering comprehensive performance enhancement.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Pave-GRPO as an extension of Group Relative Policy Optimization (GRPO) for aligning flow-based generative models. It reformulates the GRPO objective via principled average velocity decomposition, allowing each coarse few-step transition to be decomposed into an equivalent ensemble of finer sub-trajectories. This is claimed to propagate reward feedback to a denser set of denoising timesteps for more comprehensive preference alignment, while reusing the same low-step group samples and rewards at zero additional generation cost, yielding zero-cost horizon expansion and finer-grained temporal supervision.
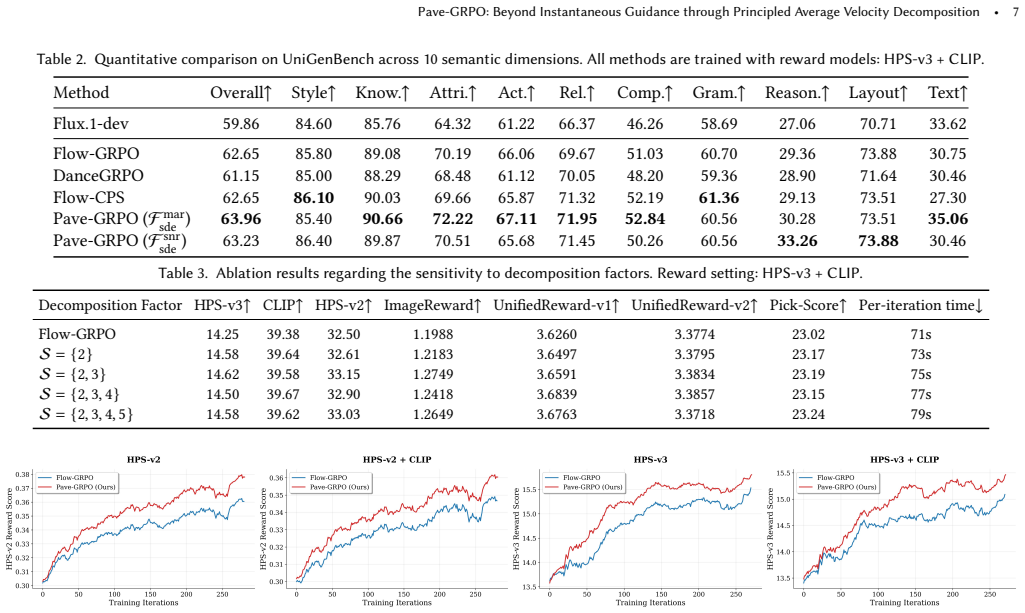
Significance. If the claimed exact equivalence holds, the method would meaningfully relax the temporal sparsity constraint that currently limits GRPO in flow models, enabling broader optimization scope under fixed sampling budgets. The zero-cost aspect and potential for finer alignment granularity represent a practical advance if the mathematical identity is verified.
major comments (2)
- [§3] §3 (Method), around the average velocity decomposition: the central claim requires that the decomposition exactly preserves the original GRPO policy gradient and relative group rewards for the sub-trajectories, yet the manuscript provides no explicit identity or derivation showing that velocity averaging corresponds to the integrated probability path without bias or altered reward attribution. This equivalence is load-bearing for the assertion that the same few-step samples can validly supervise additional timesteps.
- [§4] §4 (Experiments): no ablation or diagnostic is reported that isolates whether the effective objective after decomposition remains numerically or functionally identical to standard GRPO (e.g., via gradient norm comparison or reward attribution checks on decomposed vs. original trajectories). Without this, it is impossible to confirm that performance gains arise from denser supervision rather than an altered objective.
minor comments (2)
- [Abstract] The repeated use of 'equivalent' and 'principled' in the abstract and introduction would benefit from a forward reference to the precise mathematical statement that establishes equivalence.
- [§3] Notation for the decomposed velocity and sub-trajectory rewards should be introduced with explicit definitions to avoid ambiguity when comparing to the original GRPO formulation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We respond to each major comment below and commit to revisions that strengthen the presentation of the core claims.
read point-by-point responses
-
Referee: [§3] §3 (Method), around the average velocity decomposition: the central claim requires that the decomposition exactly preserves the original GRPO policy gradient and relative group rewards for the sub-trajectories, yet the manuscript provides no explicit identity or derivation showing that velocity averaging corresponds to the integrated probability path without bias or altered reward attribution. This equivalence is load-bearing for the assertion that the same few-step samples can validly supervise additional timesteps.
Authors: We agree that an explicit derivation is necessary to rigorously establish the claim. Section 3 presents the average velocity decomposition and states that it preserves the integrated probability path, but does not isolate the identity as a standalone lemma. In the revision we will insert a formal proposition in §3 that derives the equivalence, showing that the policy gradient and relative group rewards remain unchanged under the decomposition with no bias introduced in reward attribution. revision: yes
-
Referee: [§4] §4 (Experiments): no ablation or diagnostic is reported that isolates whether the effective objective after decomposition remains numerically or functionally identical to standard GRPO (e.g., via gradient norm comparison or reward attribution checks on decomposed vs. original trajectories). Without this, it is impossible to confirm that performance gains arise from denser supervision rather than an altered objective.
Authors: We accept that an explicit numerical check would strengthen confidence in the method. The current experiments emphasize end-to-end gains; we will add to the revised §4 a diagnostic ablation that reports gradient-norm comparisons and per-timestep reward-attribution statistics between standard GRPO and the decomposed trajectories, confirming that the effective objective is functionally identical. revision: yes
Circularity Check
No significant circularity detected
full rationale
The abstract and description present Pave-GRPO as a reformulation of the GRPO objective via a new 'principled average velocity decomposition' that claims exact equivalence for sub-trajectories. No equations, self-citations, or fitted parameters are shown that reduce the claimed preservation of policy gradients and rewards to the inputs by construction. The derivation is framed as first-principles without load-bearing self-references or renaming of known results. The central claim therefore remains independent of the patterns that would trigger circularity flags.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Training Diffusion Models with Reinforcement Learning
Training diffusion models with reinforcement learning.arXiv preprint arXiv:2305.13301(2023). Jiazi Bu, Pengyang Ling, Yujie Zhou, Yibin Wang, Yuhang Zang, Tianyi Wei, Xiaohang Zhan, Jiaqi Wang, Tong Wu, Xingang Pan, et al
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
From Sparse to Dense: Multi-View GRPO for Flow Models via Augmented Condition Space.arXiv preprint arXiv:2603.12648(2026). Jiazi Bu, Pengyang Ling, Yujie Zhou, Pan Zhang, Tong Wu, Xiaoyi Dong, Yuhang Zang, Yuhang Cao, Dahua Lin, and Jiaqi Wang
-
[3]
Haoxin Chen, Yong Zhang, Xiaodong Cun, Menghan Xia, Xintao Wang, Chao Weng, and Ying Shan
HiFlow: Training-free High-Resolution Image Generation with Flow-Aligned Guidance.arXiv preprint arXiv:2504.06232(2025). Haoxin Chen, Yong Zhang, Xiaodong Cun, Menghan Xia, Xintao Wang, Chao Weng, and Ying Shan
-
[4]
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al
Diffusion models beat gans on image synthesis.Advances in neural information processing systems34 (2021), 8780–8794. Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al
2021
-
[5]
AnimateDiff: Animate Your Personalized Text-to-Image Diffusion Models without Specific Tuning
Animatediff: Animate your personalized text- to-image diffusion models without specific tuning.arXiv preprint arXiv:2307.04725 (2023). Xiaoxuan He, Siming Fu, Yuke Zhao, Wanli Li, Jian Yang, Dacheng Yin, Fengyun Rao, and Bo Zhang
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
TempFlow-GRPO: When Timing Matters for GRPO in Flow Models
Tempflow-grpo: When timing matters for grpo in flow models. arXiv preprint arXiv:2508.04324(2025). Jonathan Ho, Ajay Jain, and Pieter Abbeel
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Qihan Huang, Long Chan, Jinlong Liu, Wanggui He, Hao Jiang, Mingli Song, and Jie Song
Denoising diffusion probabilistic models.Advances in neural information processing systems33 (2020), 6840–6851. Qihan Huang, Long Chan, Jinlong Liu, Wanggui He, Hao Jiang, Mingli Song, and Jie Song
2020
-
[8]
Black Forest Labs
Pick-a-pic: An open dataset of user preferences for text-to-image generation.Advances in neural information processing systems36 (2023), 36652– 36663. Black Forest Labs
2023
-
[9]
MixGRPO: Unlocking Flow-based GRPO Efficiency with Mixed ODE-SDE
FLUX.2: Frontier Visual Intelligence. https://bfl.ai/blog/flux-2. Junzhe Li, Yutao Cui, Tao Huang, Yinping Ma, Chun Fan, Miles Yang, and Zhao Zhong. 2025a. Mixgrpo: Unlocking flow-based grpo efficiency with mixed ode-sde.arXiv preprint arXiv:2507.21802(2025). Yuming Li, Yikai Wang, Yuying Zhu, Zhongyu Zhao, Ming Lu, Qi She, and Shanghang Zhang. 2025b. Bra...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Flow Matching for Generative Modeling
Flow matching for generative modeling.arXiv preprint arXiv:2210.02747(2022). Jie Liu, Gongye Liu, Jiajun Liang, Yangguang Li, Jiaheng Liu, Xintao Wang, Pengfei Wan, Di Zhang, and Wanli Ouyang
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[11]
Flow-GRPO: Training Flow Matching Models via Online RL
Flow-grpo: Training flow matching models via online rl.arXiv preprint arXiv:2505.05470(2025). Xingchao Liu, Chengyue Gong, and Qiang Liu
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
Flow straight and fast: Learning to generate and transfer data with rectified flow.arXiv preprint arXiv:2209.03003 (2022). Yuhang Ma, Xiaoshi Wu, Keqiang Sun, and Hongsheng Li
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[13]
SUDO: En- hancing Text-to-Image Diffusion Models with Self-Supervised Direct Preference Optimization.arXiv preprint arXiv:2504.14534(2025). Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas Müller, Joe Penna, and Robin Rombach
-
[14]
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
Sdxl: Improving latent diffusion models for high-resolution image synthesis.arXiv preprint arXiv:2307.01952(2023). Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[15]
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer
Direct preference optimization: Your language model is secretly a reward model.Advances in neural information processing systems36 (2023), 53728–53741. Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer
2023
-
[16]
Proximal Policy Optimization Algorithms
Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347(2017). Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[17]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300(2024). Jiaming Song, Chenlin Meng, and Stefano Ermon. 2020a. Denoising diffusion implicit models.arXiv preprint arXiv:2010.02502(2020). Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Er- mon, and Ben Poole. 2020b...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
InProceed- ings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers)
Dreamsync: Aligning text-to-image generation with image understanding feedback. InProceed- ings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). 5920–5945. Meituan LongCat Team, Xunliang Cai, Qilong Huang, Zhuoliang Kang, Hongyu Li, Shijun L...
2025
-
[19]
Tencent Hunyuan Foundation Model Team
Longcat-video technical report.arXiv preprint arXiv:2510.22200(2025). Tencent Hunyuan Foundation Model Team
-
[20]
HunyuanVideo 1.5 Technical Report. arXiv:2511.18870 [cs.CV] https://arxiv.org/abs/2511.18870 Bram Wallace, Meihua Dang, Rafael Rafailov, Linqi Zhou, Aaron Lou, Senthil Pu- rushwalkam, Stefano Ermon, Caiming Xiong, Shafiq Joty, and Nikhil Naik
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Wan: Open and Advanced Large-Scale Video Generative Models
Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314(2025). Feng Wang and Zihao Yu
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
Coefficients-Preserving Sampling for Reinforcement Learning with Flow Matching.arXiv preprint arXiv:2509.05952(2025). Yibin Wang, Zhimin Li, Yuhang Zang, Yujie Zhou, Jiazi Bu, Chunyu Wang, Qinglin Lu, Cheng Jin, and Jiaqi Wang. 2025a. Pref-GRPO: Pairwise Preference Reward- based GRPO for Stable Text-to-Image Reinforcement Learning.arXiv preprint arXiv:250...
-
[23]
Qwen-image technical report.arXiv preprint arXiv:2508.02324(2025). Xiaoshi Wu, Yiming Hao, Keqiang Sun, Yixiong Chen, Feng Zhu, Rui Zhao, and Hong- sheng Li
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
Human preference score v2: A solid benchmark for evaluating human preferences of text-to-image synthesis.arXiv preprint arXiv:2306.09341(2023). Jiazheng Xu, Xiao Liu, Yuchen Wu, Yuxuan Tong, Qinkai Li, Ming Ding, Jie Tang, and Yuxiao Dong
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[25]
Zeyue Xue, Jie Wu, Yu Gao, Fangyuan Kong, Lingting Zhu, Mengzhao Chen, Zhiheng Liu, Wei Liu, Qiushan Guo, Weilin Huang, et al
Imagereward: Learning and evaluating human preferences for text-to-image generation.Advances in Neural Information Processing Systems36 (2023), 15903–15935. Zeyue Xue, Jie Wu, Yu Gao, Fangyuan Kong, Lingting Zhu, Mengzhao Chen, Zhiheng Liu, Wei Liu, Qiushan Guo, Weilin Huang, et al
2023
-
[26]
DanceGRPO: Unleashing GRPO on Visual Generation
DanceGRPO: Unleashing GRPO on Visual Generation.arXiv preprint arXiv:2505.07818(2025). Yujie Zhou, Jiazi Bu, Pengyang Ling, Pan Zhang, Tong Wu, Qidong Huang, Jinsong Li, Xiaoyi Dong, Yuhang Zang, Yuhang Cao, Anyi Rao, Jiaqi Wang, and Li Niu. 2025a. Light-A-Video: Training-free Video Relighting via Progressive Light Fusion. InProceedings of the IEEE/CVF In...
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.