CanonCGT: Reference-Based Color Grading via Canonical Pivot Representation
Pith reviewed 2026-06-28 15:29 UTC · model grok-4.3
The pith
CanonCGT maps images through a style-neutral canonical pivot for stable reference-based color grading.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
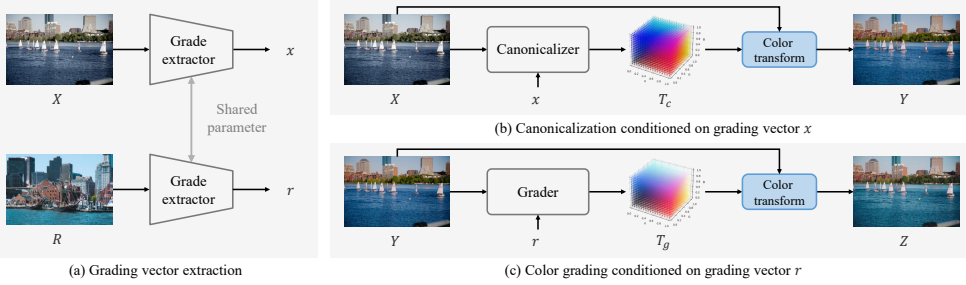
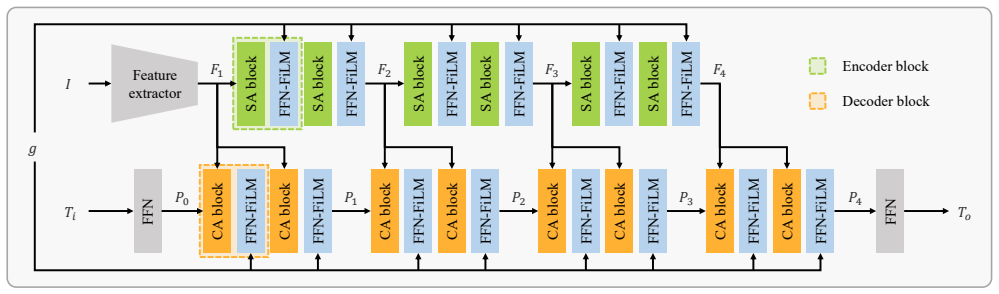
CanonCGT is a two-stage framework built on a canonical pivot -- a style-neutral intermediate representation for stable color mapping. The first stage canonicalizes the input by removing intrinsic tonal bias, and the second color-grades it to match the reference style, trained via DP-CGT that mixes supervised preset learning with self-supervised refinement on unpaired photographs.
What carries the argument
The canonical pivot, a style-neutral intermediate representation that removes tonal bias from the input before applying reference style.
If this is right
- Tone mappings remain stable across diverse datasets without over-shifting.
- Color harmony and scene structure are preserved while matching reference mood.
- Results surpass prior methods in both stability and visual fidelity.
- Self-supervised refinement on unpaired photos extends applicability beyond paired data.
Where Pith is reading between the lines
- The separation into canonicalization and grading stages could support editing pipelines that reuse the same pivot for multiple references.
- Temporal consistency in video might follow if the canonical pivot is computed frame-by-frame with additional smoothing.
- The dual-phase training pattern may transfer to other unpaired image-to-image tasks that require style neutrality.
Load-bearing premise
The canonical pivot acts as a style-neutral intermediate that produces stable color mappings without over-shifting or inconsistent retention.
What would settle it
A set of input-reference pairs where the canonical pivot still produces visible over-shifting or color inconsistency compared with direct mapping methods would falsify the stability claim.
Figures




read the original abstract
Reference-based color grading aims to reproduce the tonal mood and lighting of a reference while preserving color harmony and scene structure. Existing photorealistic and filter-based methods often produce unstable tone mappings -- over-shifting or inconsistently retaining colors -- leading to unnatural results. We propose CanonCGT, a two-stage framework built on a canonical pivot -- a style-neutral intermediate representation for stable color mapping. The first stage canonicalizes the input by removing intrinsic tonal bias, and the second color-grades it to match the reference style. A dual-phase training scheme, DP-CGT, combines supervised preset learning with self-supervised refinement on unpaired photographs. CanonCGT delivers photorealistic and tonally consistent results across diverse datasets, surpassing state-of-the-art methods in stability and visual fidelity. Our codes are available at \href{https://github.com/Jinwon-Ko/CanonCGT}{https://github.com/Jinwon-Ko/CanonCGT}
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CanonCGT, a two-stage reference-based color grading framework that relies on a canonical pivot as a style-neutral intermediate representation. The first stage canonicalizes the input image by removing its intrinsic tonal bias; the second stage maps the canonicalized result to the tonal style of a reference image. Training uses a dual-phase scheme (DP-CGT) that combines supervised preset learning with self-supervised refinement on unpaired data. The authors claim that the method produces photorealistic, tonally consistent outputs that surpass prior photorealistic and filter-based approaches in stability and visual fidelity across diverse datasets, with code released at the cited GitHub repository.
Significance. If the central claim holds, the work would offer a concrete architectural solution to the documented instability problems (over-shifting, inconsistent color retention) that affect existing reference-based grading pipelines. The explicit separation into canonicalization and grading stages, together with the dual-phase training protocol and public code release, would constitute a reproducible contribution that could be directly tested and extended by the community.
major comments (2)
- [§3.2] §3.2 (Canonical Pivot Construction): the manuscript must supply the precise mathematical definition of the canonical pivot (including any learned parameters or loss terms that enforce style neutrality). Without an explicit equation or algorithmic listing, it is impossible to verify whether the pivot is truly parameter-free or whether its construction inadvertently encodes reference-specific statistics that would undermine the stability claim.
- [§4.2, Table 2] §4.2 and Table 2 (Quantitative Evaluation): the reported superiority over SOTA methods is stated in the abstract but the specific metrics, baselines, and statistical significance tests are not visible in the provided abstract; the full manuscript must include per-dataset PSNR/SSIM/LPIPS tables with error bars and a clear statement of the number of reference–input pairs used, because the central claim of “surpassing state-of-the-art in stability” rests on these numbers.
minor comments (2)
- The abstract mentions “diverse datasets” but does not name them; the experiments section should list the exact datasets and splits used for both supervised and self-supervised phases.
- Notation for the two stages (canonicalization network vs. grading network) should be introduced once and used consistently; currently the abstract uses only descriptive phrases.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for major revision. We address each major comment below and will update the manuscript to improve clarity and completeness.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Canonical Pivot Construction): the manuscript must supply the precise mathematical definition of the canonical pivot (including any learned parameters or loss terms that enforce style neutrality). Without an explicit equation or algorithmic listing, it is impossible to verify whether the pivot is truly parameter-free or whether its construction inadvertently encodes reference-specific statistics that would undermine the stability claim.
Authors: We agree that an explicit mathematical definition is required for reproducibility and to substantiate the stability claims. Section 3.2 describes the canonical pivot conceptually as a style-neutral intermediate representation obtained via the first-stage canonicalization network, but we acknowledge that the precise equations, including any parameters and the loss terms enforcing neutrality (e.g., the style-invariance loss), were not presented in equation form. In the revised manuscript we will insert the full mathematical formulation of the pivot construction together with the relevant loss terms. revision: yes
-
Referee: [§4.2, Table 2] §4.2 and Table 2 (Quantitative Evaluation): the reported superiority over SOTA methods is stated in the abstract but the specific metrics, baselines, and statistical significance tests are not visible in the provided abstract; the full manuscript must include per-dataset PSNR/SSIM/LPIPS tables with error bars and a clear statement of the number of reference–input pairs used, because the central claim of “surpassing state-of-the-art in stability” rests on these numbers.
Authors: The full manuscript already contains Table 2 in §4.2 reporting PSNR, SSIM and LPIPS on multiple datasets against the listed baselines. To strengthen the presentation we will augment the table with per-dataset error bars (standard deviation across runs), explicitly state the number of reference–input pairs evaluated for each metric, and add a brief note on statistical significance where appropriate. revision: yes
Circularity Check
No significant circularity
full rationale
The provided abstract and description contain no equations, derivations, or explicit parameter-fitting steps that could reduce a claimed result to its inputs by construction. The central claim is a two-stage framework using a canonical pivot for color grading, presented at the level of architectural description without any visible self-definitional loops, fitted-input predictions, or load-bearing self-citations that would require external verification. No load-bearing mathematical steps are supplied that could be inspected for equivalence to inputs, making the derivation self-contained at the level of available text.
Axiom & Free-Parameter Ledger
invented entities (1)
-
canonical pivot
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Ntire 2017 challenge on single image super-resolution: Dataset and study
Eirikur Agustsson and Radu Timofte. Ntire 2017 challenge on single image super-resolution: Dataset and study. InProc. IEEE CVPR Workshops, pages 126–135, 2017. 6
2017
-
[2]
Ultrafast photorealistic style transfer via neural architecture search
Jie An, Haoyi Xiong, Jun Huan, and Jiebo Luo. Ultrafast photorealistic style transfer via neural architecture search. In Proc. AAAI, 2020. 2, 6, 13, 14
2020
-
[3]
Food-101–mining discriminative components with random forests
Lukas Bossard, Matthieu Guillaumin, and Luc Van Gool. Food-101–mining discriminative components with random forests. InProc. ECCV, 2014. 6
2014
-
[4]
Learning photographic global tonal adjustment with a database of input/output image pairs
Vladimir Bychkovsky, Sylvain Paris, Eric Chan, and Fr ´edo Durand. Learning photographic global tonal adjustment with a database of input/output image pairs. InProc. IEEE CVPR,
-
[5]
Stylebank: An explicit representation for neural image style transfer
Dongdong Chen, Lu Yuan, Jing Liao, Nenghai Yu, and Gang Hua. Stylebank: An explicit representation for neural image style transfer. InProc. IEEE CVPR, 2017. 2
2017
-
[6]
Yaosen Chen, Han Yang, Yuexin Yang, Yuegen Liu, Wei Wang, Xuming Wen, and Chaoping Xie. Nlut: Neural-based 3d lookup tables for video photorealistic style transfer.arXiv preprint arXiv:2303.09170, 2023. 3
-
[7]
Deep photo enhancer: Unpaired learning for image enhancement from photographs with gans
Yu-Sheng Chen, Yu-Ching Wang, Man-Hsin Kao, and Yung- Yu Chuang. Deep photo enhancer: Unpaired learning for image enhancement from photographs with gans. InProc. IEEE CVPR, 2018. 6
2018
-
[8]
Photowct2: Compact autoencoder for photorealistic style transfer resulting from blockwise training and skip connections of high-frequency residuals
Tai-Yin Chiu and Danna Gurari. Photowct2: Compact autoencoder for photorealistic style transfer resulting from blockwise training and skip connections of high-frequency residuals. InProc. IEEE WACV, 2022. 1, 2, 6, 13, 14, 15
2022
-
[9]
Stytr2: Image style transfer with transformers
Yingying Deng, Fan Tang, Weiming Dong, Chongyang Ma, Xingjia Pan, Lei Wang, and Changsheng Xu. Stytr2: Image style transfer with transformers. InProc. IEEE CVPR, 2022. 2
2022
-
[10]
A Learned Representation For Artistic Style
Vincent Dumoulin, Jonathon Shlens, and Manjunath Kud- lur. A learned representation for artistic style.arXiv preprint arXiv:1610.07629, 2016. 2
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[11]
Im- age style transfer using convolutional neural networks
Leon A Gatys, Alexander S Ecker, and Matthias Bethge. Im- age style transfer using convolutional neural networks. In Proc. IEEE CVPR, 2016. 1, 2
2016
-
[12]
Con- ditional sequential modulation for efficient global image re- touching
Jingwen He, Yihao Liu, Yu Qiao, and Chao Dong. Con- ditional sequential modulation for efficient global image re- touching. InProc. ECCV, 2020. 6
2020
-
[13]
Gaussian Error Linear Units (GELUs)
Dan Hendrycks and Kevin Gimpel. Gaussian error linear units (GELUs).arXiv preprint arXiv:1606.08415, 2016. 4
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[14]
Deep preset: Blending and retouching photos with color style transfer
Man M Ho and Jinjia Zhou. Deep preset: Blending and retouching photos with color style transfer. InProc. IEEE WACV, 2021. 2, 3, 6, 7, 8, 13, 14, 15
2021
-
[15]
Exposure: A white-box photo post-processing framework.ACM Trans
Yuanming Hu, Hao He, Chenxi Xu, Baoyuan Wang, and Stephen Lin. Exposure: A white-box photo post-processing framework.ACM Trans. Graphics, 37(2):1–17, 2018. 6
2018
-
[16]
A software plat- form for manipulating the camera imaging pipeline
Hakki Can Karaimer and Michael S Brown. A software plat- form for manipulating the camera imaging pipeline. InProc. ECCV, 2016. 3
2016
-
[17]
Neural preset for color style transfer
Zhanghan Ke, Yuhao Liu, Lei Zhu, Nanxuan Zhao, and Ryn- son WH Lau. Neural preset for color style transfer. InProc. IEEE CVPR, 2023. 1, 2, 3, 6, 7, 13, 14, 15
2023
-
[18]
Supervised contrastive learning
Prannay Khosla, Piotr Teterwak, Chen Wang, Aaron Sarna, Yonglong Tian, Phillip Isola, Aaron Maschinot, Ce Liu, and Dilip Krishnan. Supervised contrastive learning. InProc. NeurIPS, 2020. 4, 5, 9
2020
-
[19]
Lutformer: Lookup table transformer for image enhance- ment.Neurocomputing, 2025
Jinwon Ko, Keunsoo Ko, Hanul Kim, and Chang-Su Kim. Lutformer: Lookup table transformer for image enhance- ment.Neurocomputing, 2025. 3
2025
-
[20]
D-lut: Photorealistic style transfer via dif- fusion process
Mujing Li, Guanjie Wang, Xingguang Zhang, Qifeng Liao, and Chenxi Xiao. D-lut: Photorealistic style transfer via dif- fusion process. InProc. IEEE WACV, 2025. 3
2025
-
[21]
Universal style transfer via feature transforms
Yijun Li, Chen Fang, Jimei Yang, Zhaowen Wang, Xin Lu, and Ming-Hsuan Yang. Universal style transfer via feature transforms. InProc. NeurIPS, 2017. 2
2017
-
[22]
A closed-form solution to photorealistic image stylization
Yijun Li, Ming-Yu Liu, Xueting Li, Ming-Hsuan Yang, and Jan Kautz. A closed-form solution to photorealistic image stylization. InProc. ECCV, 2018. 1, 2
2018
-
[23]
Lsdir: A large scale dataset for image restoration
Yawei Li, Kai Zhang, Jingyun Liang, Jiezhang Cao, Ce Liu, Rui Gong, Yulun Zhang, Hao Tang, Yun Liu, Denis Deman- dolx, et al. Lsdir: A large scale dataset for image restoration. InProc. IEEE CVPR, 2023. 6
2023
-
[24]
PPR10K: A large-scale portrait photo retouch- ing dataset with human-region mask and group-level consis- tency
Jie Liang, Hui Zeng, Miaomiao Cui, Xuansong Xie, and Lei Zhang. PPR10K: A large-scale portrait photo retouch- ing dataset with human-region mask and group-level consis- tency. InProc. IEEE CVPR, 2021. 6
2021
-
[25]
Enhanced deep residual networks for single image super-resolution
Bee Lim, Sanghyun Son, Heewon Kim, Seungjun Nah, and Kyoung Mu Lee. Enhanced deep residual networks for single image super-resolution. InProc. IEEE CVPR Workshops, pages 136–144, 2017. 6
2017
-
[26]
Adacm: adaptive colormlp for real-time universal photo-realistic style transfer
Tianwei Lin, Honglin Lin, Fu Li, Dongliang He, Wenhao Wu, Meiling Wang, Xin Li, and Yong Liu. Adacm: adaptive colormlp for real-time universal photo-realistic style transfer. InProc. AAAI, 2023. 3
2023
-
[27]
Adaattn: Revisit attention mechanism in arbitrary neural style transfer
Songhua Liu, Tianwei Lin, Dongliang He, Fu Li, Meiling Wang, Xin Li, Zhengxing Sun, Qian Li, and Errui Ding. Adaattn: Revisit attention mechanism in arbitrary neural style transfer. InProc. IEEE ICCV, 2021. 2
2021
-
[28]
Sgdr: Stochastic gradient descent with warm restarts
Ilya Loshchilov and Frank Hutter. Sgdr: Stochastic gradient descent with warm restarts. InProc. ICLR, 2017. 9
2017
-
[29]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. InProc. ICLR, 2019. 9
2019
-
[30]
Structure-preserving super resolution with gradient guidance
Cheng Ma, Yongming Rao, Yean Cheng, Ce Chen, Jiwen Lu, and Jie Zhou. Structure-preserving super resolution with gradient guidance. InProc. IEEE CVPR, 2020. 9
2020
-
[31]
Visualizing data using t-sne.Journal of machine learning research, 9,
Laurens van der Maaten and Geoffrey Hinton. Visualizing data using t-sne.Journal of machine learning research, 9,
-
[32]
The relationship between photo retouching and color grading
Isabelle Magrin-Chagnolleau. The relationship between photo retouching and color grading. Technical report, Chap- man University Presidential Fellows Research, 2022. 1
2022
-
[33]
Deeplpf: Deep local para- metric filters for image enhancement
Sean Moran, Pierre Marza, Steven McDonagh, Sarah Parisot, and Gregory Slabaugh. Deeplpf: Deep local para- metric filters for image enhancement. InProc. IEEE CVPR,
-
[34]
Comparing im- ages using color coherence vectors
Greg Pass, Ramin Zabih, and Justin Miller. Comparing im- ages using color coherence vectors. InProc. ACM Multime- dia, 1997. 6 22
1997
-
[35]
Film: Visual reasoning with a general conditioning layer
Ethan Perez, Florian Strub, Harm De Vries, Vincent Du- moulin, and Aaron Courville. Film: Visual reasoning with a general conditioning layer. InProc. AAAI, 2018. 4
2018
-
[36]
N- dimensional probability density function transfer and its ap- plication to color transfer
Francois Pitie, Anil C Kokaram, and Rozenn Dahyot. N- dimensional probability density function transfer and its ap- plication to color transfer. InProc. IEEE ICCV, 2005. 2
2005
-
[37]
Au- tomated colour grading using colour distribution transfer
Franc ¸ois Piti´e, Anil C Kokaram, and Rozenn Dahyot. Au- tomated colour grading using colour distribution transfer. Comput. Vis. Image Understand., 107:123–137, 2007
2007
-
[38]
Color transfer between images.IEEE CGA, 21:34– 41, 2002
Erik Reinhard, Michael Adhikhmin, Bruce Gooch, and Peter Shirley. Color transfer between images.IEEE CGA, 21:34– 41, 2002. 2
2002
-
[39]
Imagenet large scale visual recognition challenge.Int
Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, San- jeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, et al. Imagenet large scale visual recognition challenge.Int. J. Comput. Vis., 115: 211–252, 2015. 10
2015
-
[40]
Mobilenetv2: Inverted residuals and linear bottlenecks
Mark Sandler, Andrew Howard, Menglong Zhu, Andrey Zh- moginov, and Liang-Chieh Chen. Mobilenetv2: Inverted residuals and linear bottlenecks. InProc. IEEE CVPR, 2018. 3, 9
2018
-
[41]
Video color grading via look-up table generation
Seunghyun Shin, Dongmin Shin, Jisu Shin, Hae-Gon Jeon, and Joon-Young Lee. Video color grading via look-up table generation. InProc. IEEE ICCV, 2025. 3
2025
-
[42]
Very deep convo- lutional networks for large-scale image recognition.Proc
Karen Simonyan and Andrew Zisserman. Very deep convo- lutional networks for large-scale image recognition.Proc. ICLR, 2015. 10
2015
-
[43]
Ldc: Lightweight dense cnn for edge detection.IEEE Access, 10:68281–68290, 2022
Xavier Soria, Gonzalo Pomboza-Junez, and Angel Domingo Sappa. Ldc: Lightweight dense cnn for edge detection.IEEE Access, 10:68281–68290, 2022. 6
2022
-
[44]
Attention is all you need
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszko- reit, Llion Jones, Aidan N Gomez, Ł ukasz Kaiser, and Illia Polosukhin. Attention is all you need. InProc. NeurIPS,
-
[45]
Underexposed photo enhance- ment using deep illumination estimation
Ruixing Wang, Qing Zhang, Chi-Wing Fu, Xiaoyong Shen, Wei-Shi Zheng, and Jiaya Jia. Underexposed photo enhance- ment using deep illumination estimation. InProc. IEEE CVPR, 2019. 6
2019
-
[46]
Cap- vstnet: Content affinity preserved versatile style transfer
Linfeng Wen, Chengying Gao, and Changqing Zou. Cap- vstnet: Content affinity preserved versatile style transfer. In Proc. IEEE CVPR, 2023. 2, 6, 13, 14, 15
2023
-
[47]
Google landmarks dataset v2-a large-scale benchmark for instance-level recognition and retrieval
Tobias Weyand, Andre Araujo, Bingyi Cao, and Jack Sim. Google landmarks dataset v2-a large-scale benchmark for instance-level recognition and retrieval. InProc. IEEE CVPR, 2020. 6
2020
-
[48]
Adaint: Learning adaptive intervals for 3d lookup tables on real-time image enhancement
Canqian Yang, Meiguang Jin, Xu Jia, Yi Xu, and Ying Chen. Adaint: Learning adaptive intervals for 3d lookup tables on real-time image enhancement. InProc. IEEE CVPR, 2022. 3
2022
-
[49]
Seplut: Separable image-adaptive lookup tables for real-time image enhancement
Canqian Yang, Meiguang Jin, Yi Xu, Rui Zhang, Ying Chen, and Huaida Liu. Seplut: Separable image-adaptive lookup tables for real-time image enhancement. InProc. ECCV,
-
[50]
Filter style transfer between photos
Jonghwa Yim, Jisung Yoo, Won-joon Do, Beomsu Kim, and Jihwan Choe. Filter style transfer between photos. InProc. ECCV, 2020. 2, 3
2020
-
[51]
Photorealistic style transfer via wavelet transforms
Jaejun Yoo, Youngjung Uh, Sanghyuk Chun, Byeongkyu Kang, and Jung-Woo Ha. Photorealistic style transfer via wavelet transforms. InProc. IEEE ICCV, 2019. 1, 2, 7
2019
-
[52]
Learning image-adaptive 3d lookup tables for high perfor- mance photo enhancement in real-time.IEEE Trans
Hui Zeng, Jianrui Cai, Lida Li, Zisheng Cao, and Lei Zhang. Learning image-adaptive 3d lookup tables for high perfor- mance photo enhancement in real-time.IEEE Trans. Pattern Anal. Mach. Intell., 44(4):2058–2073, 2020. 3, 6
2058
-
[53]
The unreasonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. InProc. IEEE CVPR, 2018. 6, 9
2018
-
[54]
Research on color management and color grading applications in new media movies.Journal of New Media Arts and Technology, 7(1):45–53, 2025
Yifan Zhang and Lei Wang. Research on color management and color grading applications in new media movies.Journal of New Media Arts and Technology, 7(1):45–53, 2025. 1
2025
-
[55]
Do- main enhanced arbitrary image style transfer via contrastive learning
Yuxin Zhang, Fan Tang, Weiming Dong, Haibin Huang, Chongyang Ma, Tong-Yee Lee, and Changsheng Xu. Do- main enhanced arbitrary image style transfer via contrastive learning. InACM SIGGRAPH 2022 conference proceedings,
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.