Restoring Initial Noise Sensitivity in Text-to-Image Distillation via Geometric Alignment
Pith reviewed 2026-06-28 15:18 UTC · model grok-4.3
The pith
Matching Jacobian-vector products restores initial noise sensitivity lost in standard text-to-image distillation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
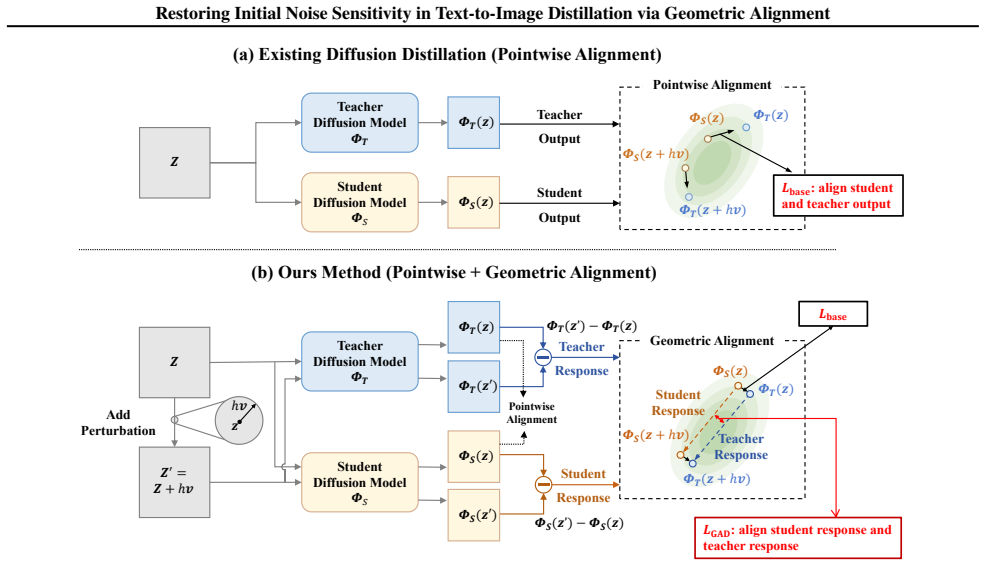
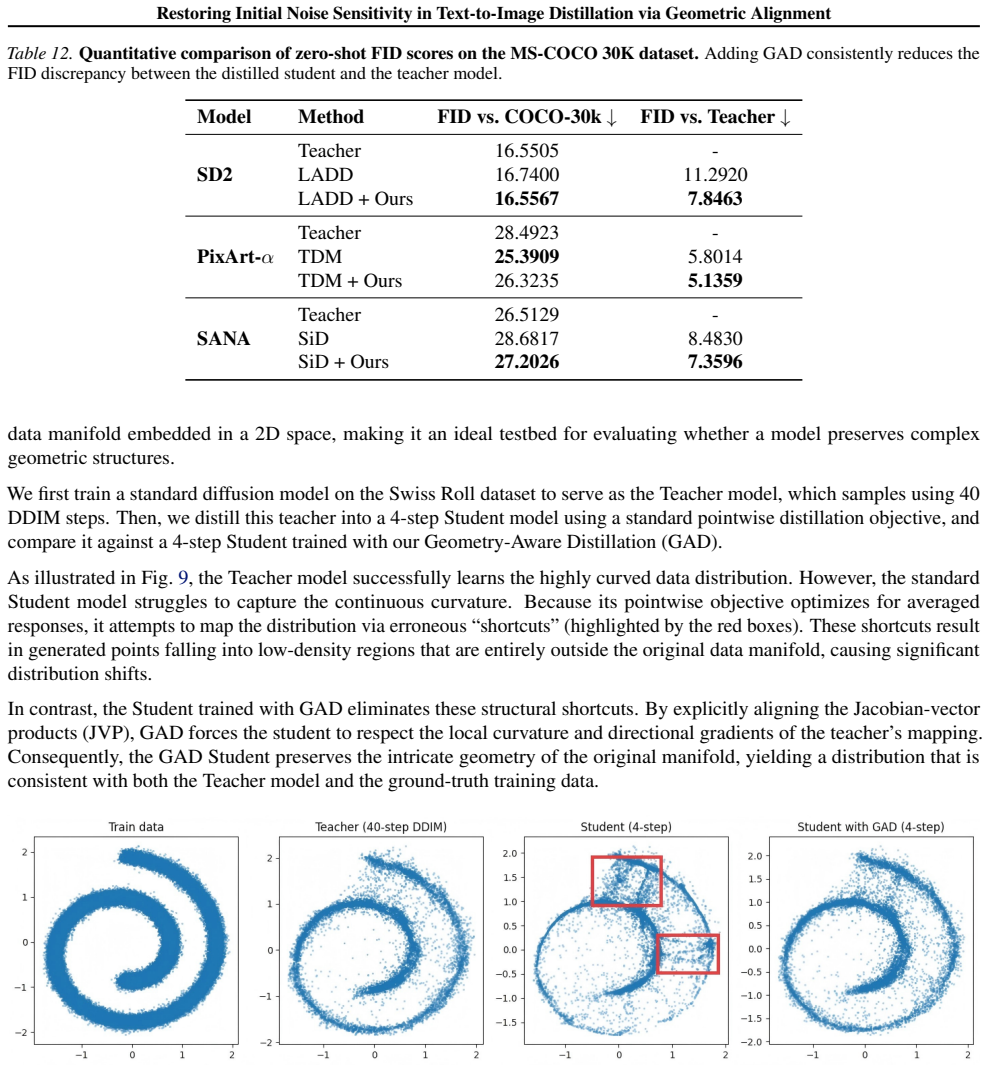
Standard distillation objectives enforce pointwise output alignment and thereby suppress the teacher's local geometric structure around the input noise; Geometry-Aware Distillation restores the missing sensitivity by explicitly matching Jacobian-vector products with respect to input noise so the student reproduces the teacher's differential response to perturbations while preserving perceptual fidelity.
What carries the argument
Geometry-Aware Distillation (GAD), which aligns local functional behavior of teacher and student models by matching their Jacobian-vector products with respect to input noise.
If this is right
- Distilled student models regain support for noise-based optimization and manipulation techniques used in control tasks.
- Generated outputs exhibit greater diversity than those from pointwise distillation.
- High visual fidelity is maintained across multiple text-to-image generation paradigms.
- Downstream noise-driven control tasks show measurable performance gains without retraining the teacher.
Where Pith is reading between the lines
- The same geometric-alignment idea may apply to distilling other generative models where input perturbations carry semantic meaning.
- Practitioners could combine GAD with existing noise-optimization pipelines to obtain both speed and controllable variation in one model.
- Future distillation objectives might need to preserve additional local properties beyond first-order Jacobians to stay faithful to the teacher trajectory.
Load-bearing premise
The loss of noise sensitivity stems primarily from pointwise output alignment in standard distillation, and matching Jacobian-vector products will restore it without compromising fidelity or creating new problems.
What would settle it
Measure output variation under controlled small perturbations to the initial noise in a standard distilled model versus a GAD model; if the GAD model shows variation closer to the teacher while FID or perceptual scores remain comparable, the claim is supported.
Figures







read the original abstract
Generative distillation significantly accelerates text-to-image (T2I) generation by compressing multi-step trajectories into few-step student models while preserving perceptual quality. However, existing methods primarily optimize efficiency and output fidelity, often neglecting critical properties of the original trajectory. In this work, we identify a key missing property: sensitivity to initial noise, whose degradation impairs downstream control methods relying on noise-based optimization and manipulation. We trace this issue to standard distillation objectives that enforce pointwise output alignment, inadvertently flattening the input-output landscape and suppressing the teacher's local geometric structure. To address this, we propose Geometry-Aware Distillation (GAD), a sensitivity-preserving framework that aligns the local functional behavior of teacher and student models. Specifically, GAD matches Jacobian-vector products with respect to input noise, enabling the student to reproduce the teacher's differential response to perturbations. Extensive experiments across multiple T2I paradigms and noise-driven control tasks demonstrate that GAD significantly restores sensitivity and improves diversity while maintaining high visual fidelity. Code is available at https://github.com/Hannah1102/GAD.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript argues that standard pointwise output alignment in text-to-image distillation flattens the input-output landscape and suppresses sensitivity to initial noise, impairing downstream noise-driven control tasks. It proposes Geometry-Aware Distillation (GAD), which aligns teacher and student models by matching Jacobian-vector products (JVPs) with respect to input noise so that the student reproduces the teacher's local differential response to perturbations. The abstract claims that this geometric matching restores sensitivity and improves diversity while preserving visual fidelity, supported by experiments across multiple T2I paradigms and control tasks.
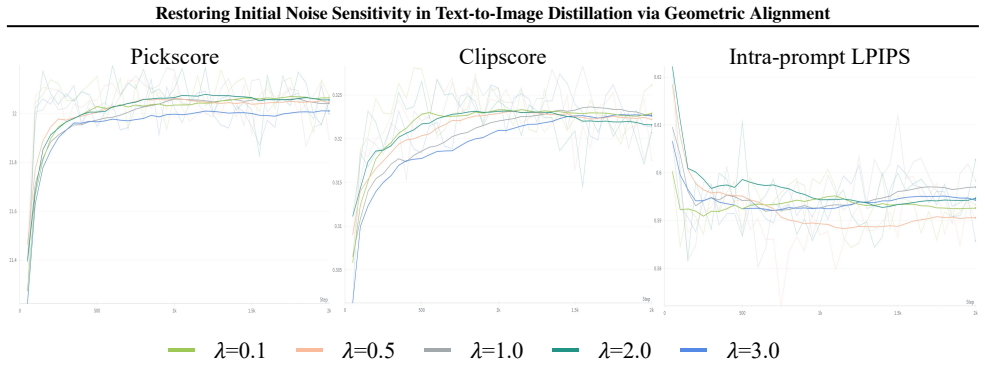
Significance. If the central claim is substantiated, the work would be significant for the distillation literature because it isolates and targets a functional property (noise sensitivity) that is orthogonal to perceptual fidelity yet critical for control applications. The JVP-matching formulation offers a concrete geometric mechanism that could generalize beyond the specific setting, and the public code release aids reproducibility. However, the absence of any quantitative results, implementation details, or error analysis in the abstract limits immediate assessment of whether the experiments actually support the claim.
major comments (2)
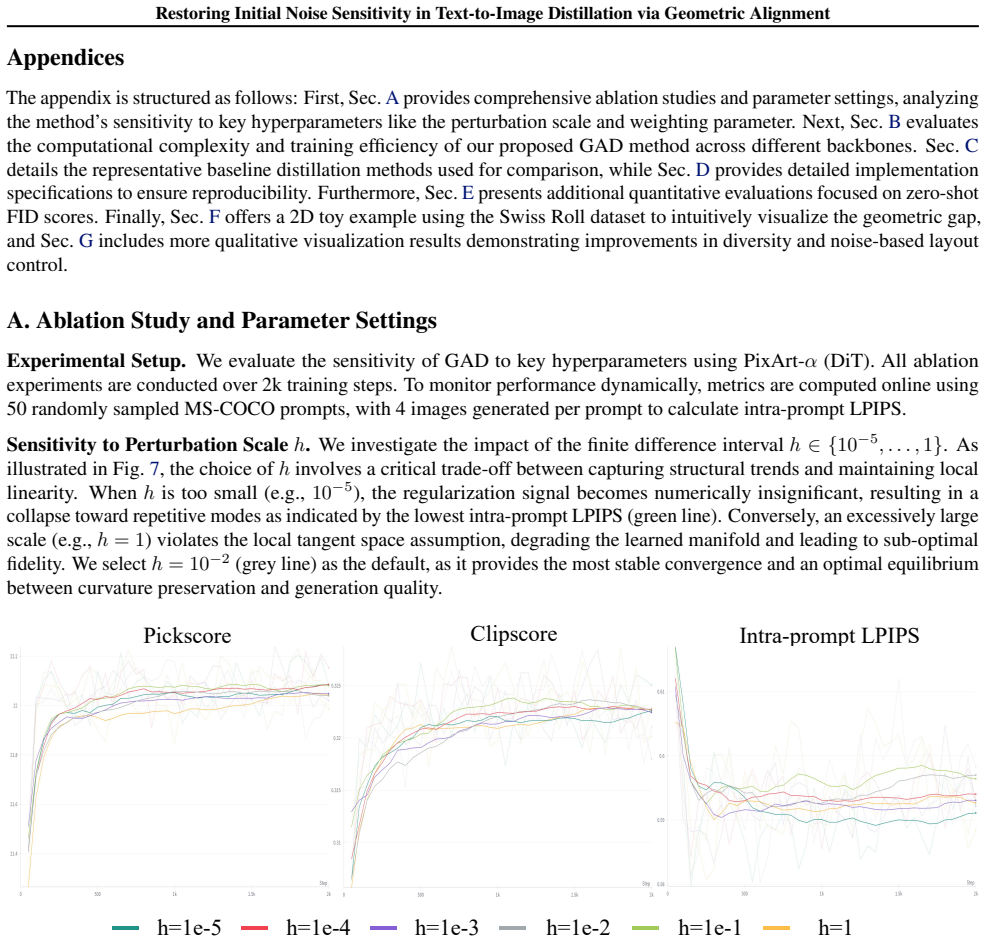
- [Abstract] Abstract: the central assumption that matching JVPs w.r.t. initial noise during training will restore the teacher's differential response under few-step inference is not justified. Because the student realizes a different composition of the diffusion ODE, first-order agreement at sampled training points need not imply agreement of the effective sensitivity after the reduced trajectory; a derivation or targeted experiment showing why local linearization transfers is required to support the claim.
- [Abstract] Abstract: the statement that 'extensive experiments ... demonstrate that GAD significantly restores sensitivity' supplies no numbers, tables, or figures, so it is impossible to evaluate effect sizes, baselines, or whether the reported gains are attributable to JVP matching rather than other factors.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and indicate planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central assumption that matching JVPs w.r.t. initial noise during training will restore the teacher's differential response under few-step inference is not justified. Because the student realizes a different composition of the diffusion ODE, first-order agreement at sampled training points need not imply agreement of the effective sensitivity after the reduced trajectory; a derivation or targeted experiment showing why local linearization transfers is required to support the claim.
Authors: We agree that the transfer of first-order sensitivity from training-time JVP matching to few-step inference requires explicit justification, as the student follows a different ODE composition. The current manuscript provides empirical evidence across control tasks (Sections 4–5) that sensitivity is restored, but lacks a formal derivation. In the revision we will add a short derivation in the appendix showing that, under the Lipschitz continuity assumptions used in the distillation, pointwise JVP agreement at sampled noise levels implies bounded deviation in the integrated sensitivity along the reduced trajectory. We will also include a targeted ablation measuring JVP alignment before and after the reduced steps. revision: yes
-
Referee: [Abstract] Abstract: the statement that 'extensive experiments ... demonstrate that GAD significantly restores sensitivity' supplies no numbers, tables, or figures, so it is impossible to evaluate effect sizes, baselines, or whether the reported gains are attributable to JVP matching rather than other factors.
Authors: The abstract is intentionally concise; all quantitative results, tables, and figures appear in Sections 4 and 5. To improve evaluability we will revise the abstract to report concrete effect sizes (e.g., diversity and sensitivity metrics relative to baselines) while remaining within length limits. This change will also clarify that gains are measured against pointwise distillation ablations. revision: partial
Circularity Check
No circularity: derivation introduces independent JVP alignment objective
full rationale
The paper traces sensitivity loss to pointwise alignment (abstract) and proposes GAD as a new framework that matches Jacobian-vector products w.r.t. input noise. No quoted equations or steps reduce the claimed prediction or result to fitted inputs, self-definitions, or self-citation chains by construction. The central geometric matching technique is presented as an external addition to standard distillation losses without load-bearing self-references or renaming of known results. The framework remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Teacher and student models are differentiable with respect to input noise.
Reference graph
Works this paper leans on
-
[1]
Langley , title =
P. Langley , title =. Proceedings of the 17th International Conference on Machine Learning (ICML 2000) , address =. 2000 , pages =
2000
-
[2]
T. M. Mitchell. The Need for Biases in Learning Generalizations. 1980
1980
-
[3]
M. J. Kearns , title =
-
[4]
Machine Learning: An Artificial Intelligence Approach, Vol. I. 1983
1983
-
[5]
R. O. Duda and P. E. Hart and D. G. Stork. Pattern Classification. 2000
2000
-
[6]
Suppressed for Anonymity , author=
-
[7]
Newell and P
A. Newell and P. S. Rosenbloom. Mechanisms of Skill Acquisition and the Law of Practice. Cognitive Skills and Their Acquisition. 1981
1981
-
[8]
A. L. Samuel. Some Studies in Machine Learning Using the Game of Checkers. IBM Journal of Research and Development. 1959
1959
-
[9]
International Conference on Machine Learning , volume =
Glide: Towards photorealistic image generation and editing with text-guided diffusion models , author=. International Conference on Machine Learning , volume =
-
[10]
European Conference on Computer Vision , pages=
Microsoft coco: Common objects in context , author=. European Conference on Computer Vision , pages=. 2014 , organization=
2014
-
[11]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Effective real image editing with accelerated iterative diffusion inversion , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[12]
International Conference on Learning Representations , publisher =
Denoising diffusion implicit models , author=. International Conference on Learning Representations , publisher =
-
[13]
International Conference on Machine Learning , pages=
Improved denoising diffusion probabilistic models , author=. International Conference on Machine Learning , pages=. 2021 , organization=
2021
-
[14]
Advances in Neural Information Processing Systems , volume=
Denoising diffusion probabilistic models , author=. Advances in Neural Information Processing Systems , volume=
-
[15]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
The silent assistant: Noisequery as implicit guidance for goal-driven image generation , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[16]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Golden noise for diffusion models: A learning framework , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[17]
Advances in Neural Information Processing Systems , volume=
Reno: Enhancing one-step text-to-image models through reward-based noise optimization , author=. Advances in Neural Information Processing Systems , volume=
-
[18]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
On distillation of guided diffusion models , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[19]
European Conference on Computer Vision , pages=
Adversarial diffusion distillation , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[20]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Boxdiff: Text-to-image synthesis with training-free box-constrained diffusion , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[21]
International Conference on Learning Representations , year=
The Crystal Ball Hypothesis in diffusion models: Anticipating object positions from initial noise , author=. International Conference on Learning Representations , year=
-
[22]
International Conference on Learning Representations , year=
Diversity-Rewarded CFG Distillation , author=. International Conference on Learning Representations , year=
-
[23]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Taming mode collapse in score distillation for text-to-3d generation , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[24]
International Conference on Machine Learning , pages=
Consistency Models , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[25]
arXiv preprint arXiv:2503.10637 , year=
Distilling diversity and control in diffusion models , author=. arXiv preprint arXiv:2503.10637 , year=
-
[26]
International Conference on Learning Representations , publisher =
Score-based generative modeling through stochastic differential equations , author=. International Conference on Learning Representations , publisher =
-
[27]
International Conference on Learning Representations , year=
Flow Matching for Generative Modeling , author=. International Conference on Learning Representations , year=
-
[28]
SDXL-Lightning: Progressive Adversarial Diffusion Distillation
Sdxl-lightning: Progressive adversarial diffusion distillation , author=. arXiv preprint arXiv:2402.13929 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
SIGGRAPH Asia , pages=
Fast high-resolution image synthesis with latent adversarial diffusion distillation , author=. SIGGRAPH Asia , pages=
-
[30]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
One-step diffusion with distribution matching distillation , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[31]
Advances in Neural Information Processing Systems , volume=
Improved distribution matching distillation for fast image synthesis , author=. Advances in Neural Information Processing Systems , volume=
-
[32]
International Conference on Learning Representations , year=
Improved Techniques for Training Consistency Models , author=. International Conference on Learning Representations , year=
-
[33]
International Conference on Machine Learning , pages=
Knowledge transfer with jacobian matching , author=. International Conference on Machine Learning , pages=. 2018 , organization=
2018
-
[34]
International Conference on Learning Representations , year=
What Secrets Do Your Manifolds Hold? Understanding the Local Geometry of Generative Models , author=. International Conference on Learning Representations , year=
-
[35]
International Conference on Machine Learning , year=
Boost-and-Skip: A Simple Guidance-Free Diffusion for Minority Generation , author=. International Conference on Machine Learning , year=
-
[36]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Minority-Focused Text-to-Image Generation via Prompt Optimization , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[37]
International Conference on Learning Representations , year=
CADS: Unleashing the Diversity of Diffusion Models through Condition-Annealed Sampling , author=. International Conference on Learning Representations , year=
-
[38]
International Conference on Learning Representations , year=
Enhancing compositional text-to-image generation with reliable random seeds , author=. International Conference on Learning Representations , year=
-
[39]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages =
Learning Few-Step Diffusion Models by Trajectory Distribution Matching , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages =
-
[40]
Neural computation , volume=
Fast exact multiplication by the Hessian , author=. Neural computation , volume=. 1994 , publisher=
1994
-
[41]
JMLR , volume=
Automatic differentiation in machine learning: a survey , author=. JMLR , volume=
-
[42]
International Conference on Machine Learning , pages=
How to train your neural ode: the world of jacobian and kinetic regularization , author=. International Conference on Machine Learning , pages=. 2020 , organization=
2020
-
[43]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Coco-stuff: Thing and stuff classes in context , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[44]
YOLOv4: Optimal Speed and Accuracy of Object Detection
Yolov4: Optimal speed and accuracy of object detection , author=. arXiv preprint arXiv:2004.10934 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2004
-
[45]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Image synthesis from layout with locality-aware mask adaption , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[46]
International Conference on Machine Learning , pages=
Learning transferable visual models from natural language supervision , author=. International Conference on Machine Learning , pages=. 2021 , organization=
2021
-
[47]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
High-resolution image synthesis with latent diffusion models , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[48]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Swiftbrush: One-step text-to-image diffusion model with variational score distillation , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[49]
European Conference on Computer Vision , pages=
Swiftbrush v2: Make your one-step diffusion model better than its teacher , author=. European Conference on Computer Vision , pages=. 2024 , organization=
2024
-
[50]
Latent Consistency Models: Synthesizing High-Resolution Images with Few-Step Inference
Latent consistency models: Synthesizing high-resolution images with few-step inference , author=. arXiv preprint arXiv:2310.04378 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[51]
Trajectory Consistency Distillation: Improved Latent Consistency Distillation by Semi-Linear Consistency Function with Trajectory Mapping , author=. arXiv preprint arXiv:2402.19159 , year=
-
[52]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Conceptual 12m: Pushing web-scale image-text pre-training to recognize long-tail visual concepts , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[53]
Transactions on Machine Learning Research , issn=
The Vendi Score: A Diversity Evaluation Metric for Machine Learning , author=. Transactions on Machine Learning Research , issn=
-
[54]
International Conference on Learning Representations , year=
PixArt- : Fast Training of Diffusion Transformer for Photorealistic Text-to-Image Synthesis , author=. International Conference on Learning Representations , year=
-
[55]
International Conference on Learning Representations , year=
SANA: Efficient high-resolution text-to-image synthesis with linear diffusion transformers , author=. International Conference on Learning Representations , year=
-
[56]
arXiv preprint arXiv:2509.25127 , year=
Score Distillation of Flow Matching Models , author=. arXiv preprint arXiv:2509.25127 , year=
-
[57]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Flash diffusion: Accelerating any conditional diffusion model for few steps image generation , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[58]
International Conference on Learning Representations , year=
You Only Sample Once: Taming One-Step Text-to-Image Synthesis by Self-Cooperative Diffusion GANs , author=. International Conference on Learning Representations , year=
-
[59]
Advances in Neural Information Processing Systems , volume=
Photorealistic text-to-image diffusion models with deep language understanding , author=. Advances in Neural Information Processing Systems , volume=
-
[60]
Human preference score v2: A solid benchmark for evaluating human preferences of text-to-image synthesis , author=. arXiv preprint arXiv:2306.09341 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[61]
Advances in Neural Information Processing Systems , volume=
Pick-a-pic: An open dataset of user preferences for text-to-image generation , author=. Advances in Neural Information Processing Systems , volume=
-
[62]
Journal of Machine Learning Research , volume=
Visualizing data using t-SNE , author=. Journal of Machine Learning Research , volume=
-
[63]
Advances in Neural Information Processing Systems , volume=
Efficientformer: Vision transformers at mobilenet speed , author=. Advances in Neural Information Processing Systems , volume=
-
[64]
International Conference on Learning Representations , year=
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow , author=. International Conference on Learning Representations , year=
-
[65]
Advances in Neural Information Processing Systems , volume=
Elucidating the design space of diffusion-based generative models , author=. Advances in Neural Information Processing Systems , volume=
-
[66]
Communications in Statistics-Simulation and Computation , volume=
A stochastic estimator of the trace of the influence matrix for Laplacian smoothing splines , author=. Communications in Statistics-Simulation and Computation , volume=. 1989 , publisher=
1989
-
[67]
Advances in Neural Information Processing Systems , volume=
Sobolev training for neural networks , author=. Advances in Neural Information Processing Systems , volume=
-
[68]
International Conference on Learning Representations , year=
Consistency Trajectory Models: Learning Probability Flow ODE Trajectory of Diffusion , author=. International Conference on Learning Representations , year=
-
[69]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Adversarial distribution matching for diffusion distillation towards efficient image and video synthesis , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[70]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Nitrofusion: High-fidelity single-step diffusion through dynamic adversarial training , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[71]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Supercharged One-step Text-to-Image Diffusion Models with Negative Prompts , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[72]
Advances in Neural Information Processing Systems , volume=
Invertible consistency distillation for text-guided image editing in around 7 steps , author=. Advances in Neural Information Processing Systems , volume=
-
[73]
International Conference on Machine Learning , pages =
Shielded Diffusion: Generating Novel and Diverse Images using Sparse Repellency , author=. International Conference on Machine Learning , pages =
-
[74]
International Conference on Learning Representations , year=
DreamFusion: Text-to-3D using 2D Diffusion , author=. International Conference on Learning Representations , year=
-
[75]
arXiv preprint arXiv:2505.12674 , year=
Few-step diffusion via score identity distillation , author=. arXiv preprint arXiv:2505.12674 , year=
-
[76]
International Conference on Learning Representations , year=
Guided Score identity Distillation for Data-Free One-Step Text-to-Image Generation , author=. International Conference on Learning Representations , year=
-
[77]
IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Relational knowledge distillation , author=. IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[78]
IEEE/CVF International Conference on Computer Vision , pages=
Similarity-preserving knowledge distillation , author=. IEEE/CVF International Conference on Computer Vision , pages=
-
[79]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Fedseg: Class-heterogeneous federated learning for semantic segmentation , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[80]
International Conference on Learning Representations , year=
Towards One-step Causal Video Generation via Adversarial Self-Distillation , author=. International Conference on Learning Representations , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.